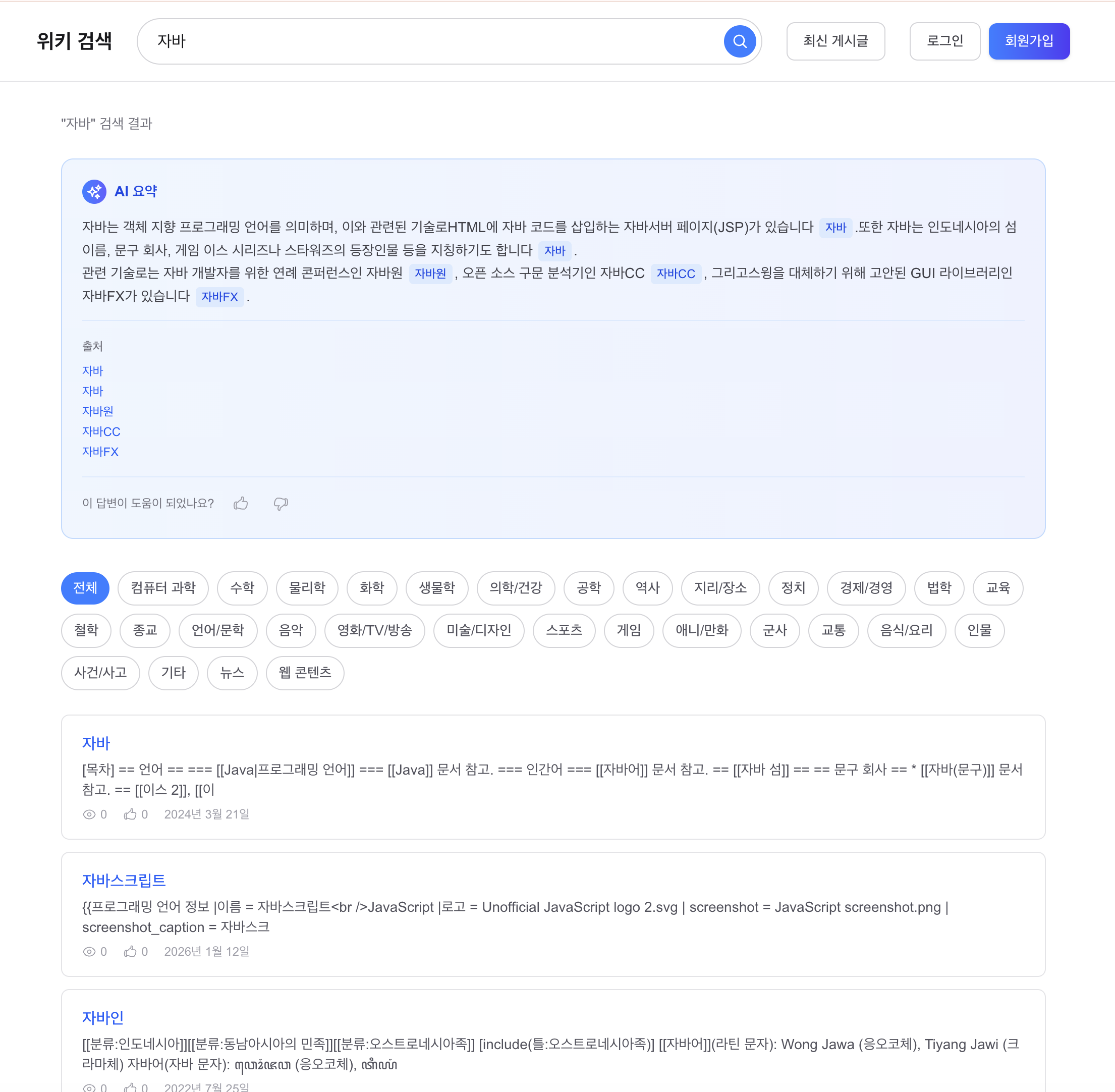
WikiEngine 총정리: 1,215만 건 검색 엔진의 설계부터 RAG까지
나무위키+한국어 위키백과+영어 위키백과+뉴스+웹텍스트+C4 한국어 코퍼스 1,215만 건 검색 엔진 프로젝트를 2개월간 26편의 기술 블로그로 기록하고 총정리합니다. MySQL LIKE 5,000ms 타임아웃에서 시작하여 임베디드 Lucene + Nori 한국어 형태소 분석으로 전환하고, Caffeine+Redis 2계층 캐시(82% 히트율), MySQL Replication R/W 분리, Nginx 스케일아웃(에러율 13.25%→0%), Debezium+Kafka CDC, Redis 3노드 Consistent Hashing까지 분산 아키텍처를 완성합니다. 검색 품질은 동의어 확장, 오타 교정, UnifiedHighlighter snippet, LTR(NDCG +4.8%p), 카테고리 28개 자동 분류, Aho-Corasick 금칙어 필터링으로 고도화하고, RAG(Gemini SSE 스트리밍)로 AI 검색 요약을 제공합니다. 자동완성 시스템 설계(CQRS + MapReduce + CDC)의 이론과 실제 구현의 매핑, 26편 전체 시리즈 링크, 핵심 수치 총정리를 포함합니다.