LTR 재랭킹 + 카테고리 자동 분류: XGBoost4J + LLM-as-a-Judge
목차
이전 글
쿼리 확장 + Query Understanding에서 동의어 확장, DirectSpellChecker 오타 교정, UnifiedHighlighter snippet 개선, 12,156,589건 전체 재색인 인프라를 구축했습니다.
| 지표 | 결과 |
|---|---|
| 동의어 확장 | ”AI” → “인공지능” 1위 (Recall 개선) |
| 오타 교정 | ”프로그래링” → “프로그래밍” 제안 성공 |
| Snippet | UnifiedHighlighter + snippetSource 500자 |
| 재색인 인프라 | Directory Swap + SearcherManager 재생성 (무중단) |
검색 쿼리가 올바르게 해석되고 확장되지만, 랭킹 모델이 여전히 수동 규칙에 의존합니다. 또한 카테고리 검색 필터링에서 보류했던 Lucene 네이티브 Facet 전환을 이 글에서 완료합니다.
1. 정상 상태: 현재 랭킹 모델

검색 품질 평가에서 구현한 이 랭킹은 수동 가중치 기반입니다. 이 가중치들이 실제로 사용자가 원하는 결과 순서와 일치하는지 데이터 기반으로 검증되지 않았다.
2. 문제 상황
문제 1: 수동 가중치의 한계

문제 2: Facet, DB GROUP BY 간이 집계의 한계
카테고리 검색 필터링에서 DB GROUP BY로 간이 Facet을 구현했지만, Top-1,000건에 대한 근사 집계였다. Lucene 네이티브 SortedSetDocValuesFacetCounts로 전환하여 전체 매칭 문서에 대한 정확한 Facet이 필요합니다. 이를 위해 SortedSetDocValuesFacetField + 전체 재색인이 필요합니다.
문제 3: 카테고리가 namespace 기반이라 Facet이 무의미
위키 데이터 임포트 시 할당된 카테고리가 “일반 문서” 97%로 편중되어 있어, Facet을 표시해도 의미가 없습니다. 주제별 카테고리 28개로 재분류가 선행되어야 합니다.
3. 대안 검토
LTR 모델 선택
| 모델 | 장점 | 단점 | 판단 |
|---|---|---|---|
| LambdaMART (XGBoost) | NDCG 최적화, 검색 랭킹 업계 표준 | Python 학습 → Java 추론 변환 필요 | 선택 |
| Linear Model | 단순, 해석 가능, Java 네이티브 | 비선형 관계 학습 불가 | 탈락 (수동 boosting과 동일) |
| Neural (BERT) | 문맥 이해 가능 | 추론 지연 수백 ms, GPU 필요 | 탈락 (240ms SLA) |
| Elasticsearch LTR | ES 생태계 통합 | 별도 클러스터 필요 (최소 6G RAM) | 탈락 (Free Tier 불가) |
Linear Model을 탈락시킨 근거: OpenSource Connections는 *“Elasticsearch boosts are nothing but coefficients in a linear regression”*라고 분석한다. 같은 3개 피처(viewCount, likeCount, recency)로 Linear Model을 학습해도 기존 수동 가중치와 거의 동일한 결과가 나온다. tree model(LambdaMART)은 피처 간 interaction(예: titleLength가 짧으면서 tagOverlap이 높은 경우)을 학습할 수 있어 비선형 관계를 포착합니다.
Java 추론 런타임 선택
| 옵션 | 결과 | 사유 |
|---|---|---|
| xgboost-predictor-java | 탈락 | XGBoost 2.x 모델 포맷(UBJSON) 비호환, deprecated |
| ONNX Runtime | 탈락 | onnxmltools가 XGBRanker → ONNX 변환 미지원 (Issue #382) |
| XGBoost4J | 선택 | Python save_model() → Java XGBoost.loadModel() 변환 없이 직접 로드. ARM64 Linux 네이티브 라이브러리 JAR 번들 포함. inplace_predict()가 thread-safe |
OCI Free Tier는 ARM Ampere A1입니다. XGBoost4J JAR(ml.dmlc:xgboost4j_2.12:2.1.4)에 lib/linux/aarch64/libxgboost4j.so가 번들되어 있어 별도 컴파일 없이 동작합니다.
학습 데이터: LLM-as-a-Judge
현재 사용자 트래픽이 거의 없어 클릭 로그가 축적되지 않습니다. LLM으로 relevance 판정을 대신합니다.
현업 근거: SIGIR 2024 (Thomas et al.)에 따르면 GPT-4의 relevance 판정이 crowdsource annotator와 Cohen’s Kappa 0.6~0.7로 일치하며, crowdsource 간 일치율(0.4~0.6)과 동등 이상이다.
4. 구현
Part 1: 카테고리 28개 자동 분류
기존 namespace 기반 카테고리(“일반 문서” 97%)를 주제별 28개 카테고리(컴퓨터 과학, 수학, 물리학, 역사, 음악, 게임, 스포츠 등)로 재분류했다.
분류 방식: 키워드 기반 배치 분류 (CategoryClassificationService). 각 카테고리에 대표 키워드 목록을 정의하고, 게시글 제목+태그에 매칭되는 키워드가 가장 많은 카테고리로 분류.
분류 정확도 검증 (90건 수동 확인):
| 카테고리 | 정확 | 애매 | 오분류 | 정확도 |
|---|---|---|---|---|
| 컴퓨터 과학 | 10 | 0 | 0 | 100% |
| 역사 | 10 | 0 | 0 | 100% |
| 음악 | 10 | 0 | 0 | 100% |
| 게임 | 10 | 0 | 0 | 100% |
| 스포츠 | 10 | 0 | 0 | 100% |
| 물리학 | 8 | 2 | 0 | 80% |
| 수학 | 6 | 4 | 0 | 60% |
| 교육 | 6 | 3 | 1 | 60% |
| 인물 | 5 | 5 | 0 | 50% |
| 평균 | ~83% |
키워드 기반 분류의 한계: “수능시험”이 “수학” 키워드에 매칭되어 수학으로 분류됨. 애니 캐릭터명이 “인물” 키워드에 매칭됨. 키워드 간 우선순위/배타성 로직이 없어 경계 케이스에서 정확도 저하. 83%는 Facet 탐색용으로 충분하지만, MoreLikeThis 기반 재분류로 개선 가능.
Part 2: Facet 네이티브 전환 + 태그 인덱싱
카테고리 검색 필터링에서 보류했던 Lucene 네이티브 Facet을 구현합니다. 1회 재색인으로 모든 변경사항을 통합 반영합니다.
재색인에 포함된 변경사항:
| 변경 | 내용 |
|---|---|
| Facet 필드 | SortedSetDocValuesFacetField("category", categoryName) |
| 태그 인덱싱 | TextField("tags", tagNames, Store.YES), 216만 고유 태그 |
| Nori 사용자 사전 | 158,539개 (수동 30 + open-korean-text 158,509) |
| snippetSource 정제 | raw 마크업 → clean plain text |
| 배치 태그 프리로딩 | N+1 방지 (배치당 1회 JOIN 쿼리) |
성능 최적화:
SortedSetDocValuesReaderStateRefreshListener 기반 캐싱:SearcherManager.addListener()로 reader 갱신 시 사전 빌드. 검색 경로에서 lock 없이 volatile read만 수행. Lucene 공식 Javadoc: “create it once and re-use for a given IndexReader”. LUCENE-7905에서 OrdinalMap 빌드 비용이 26.6M terms에 ~106초로 보고되어, 검색 요청마다 생성하면 안 됩니다.MultiCollectorManager로 TopDocs + FacetsCollector 단일 패스 수집: 동일 쿼리의searcher.search()2회 호출 → 1회로 통합, I/O 절감.
태그 Facet 제거 결정: 216만 고유 태그에 대한 Facet은 고카디널리티 안티패턴이다 (Elasticsearch 공식도 경고). 태그는 검색 품질 향상용(TextField로 인덱싱되어 검색에 매칭)으로만 사용하고, Facet은 카테고리(30개)만 유지합니다.
Facet 실측:
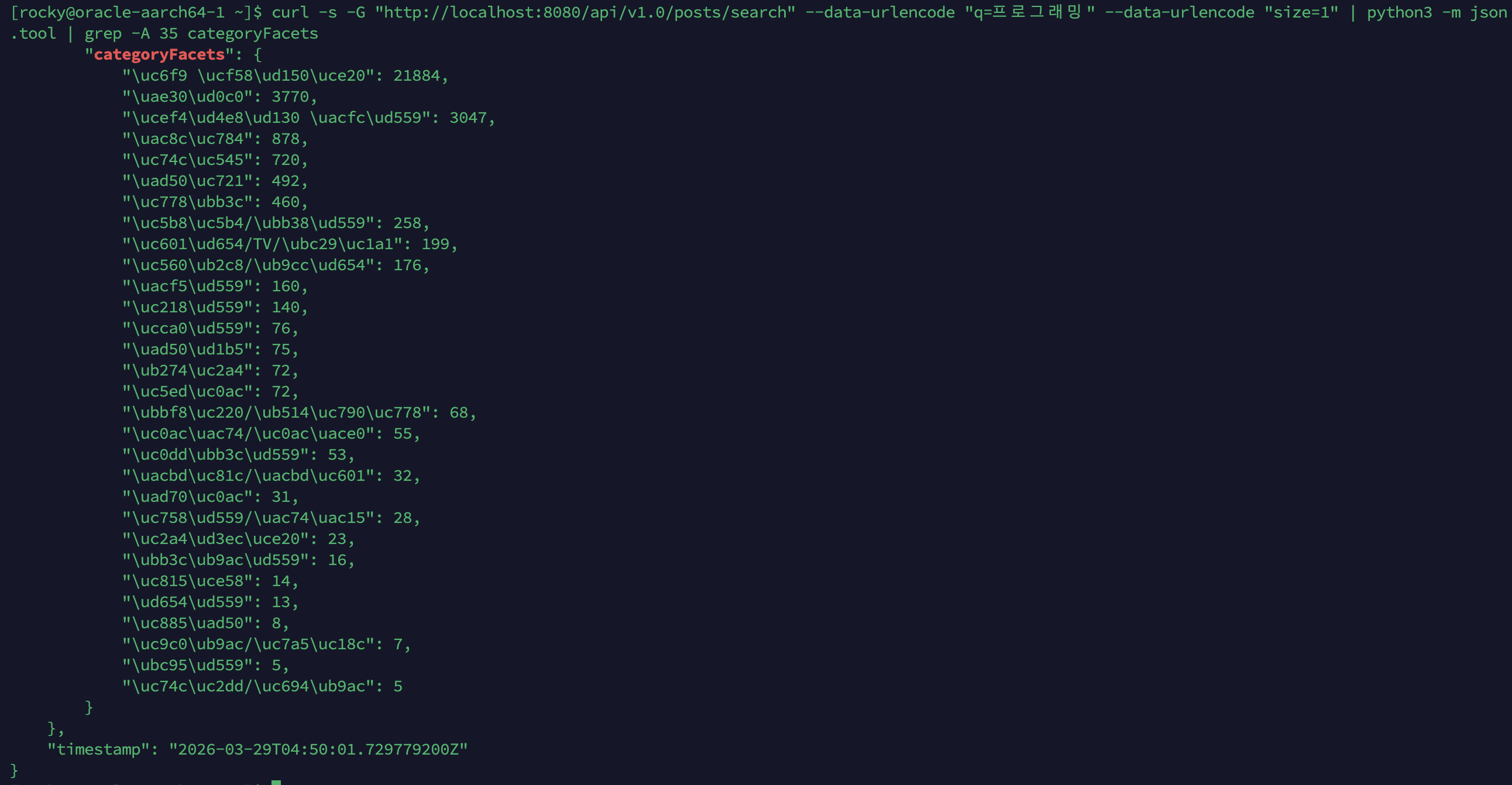
SortedSetDocValuesFacetCounts기반 전체 매칭 문서 집계. “프로그래밍” 검색 시 웹 콘텐츠(21,884) > 기타(3,770) > 컴퓨터 과학(3,047) > 게임(878) > 음악(720) … 음식/요리(5) 순. 30개 카테고리 전체 집계 정상.
Part 3: LTR (LambdaMART + XGBoost4J)
3-1. 학습 데이터 생성: LLM-as-a-Judge (Gemini)
검색어 45개를 수집하고 각 쿼리에 대해 BM25 Top-20 결과를 추출하여 900 (query, doc) 쌍을 생성. Gemini API로 4-point scale relevance 판정:
- 0: Irrelevant, 문서가 쿼리와 무관
- 1: Marginally relevant, 주제 언급만
- 2: Relevant, 부분적 답변
- 3: Highly relevant, 직접적이고 완전한 답변
Non-deterministic 대응(3회 호출 평균 반올림): LLM은 temperature=0이어도 완전히 deterministic하지는 않다 (GPU batch 구성 변동, 부동소수점 비결합성). Graded relevance에서는 averaging + 반올림이 정석 (TREC LLMJudge 참가팀 RMIT-IR: 3회 생성 → 평균 → 반올림).
1차 실행 실패 (2% 성공률):

45쿼리 x 20문서 = 900건 처리 완료로 표시되었으나 CSV export 시 18건만 추출. 서버 로그 분석 결과 882건이
Failed to generate content.
근본 원인: 라운드 간 딜레이 2초 → 3회 호출이 ~6초 → 분당 30요청으로 15 RPM 초과. Spring AI 기본 retry가 HTTP 429를 NonTransientAiException으로 분류하여 재시도하지 않음. 또한 데이터가 메모리 전용(ArrayList)으로 status API에 성공/실패 구분이 없어 98% 실패를 인지 못함.
수정:
| 항목 | Before | After |
|---|---|---|
| 라운드 간 딜레이 | 2초 (30 RPM, 초과) | 5초 (12 RPM, 15 RPM 이내) |
| API 실패 시 | 재시도 없음 | 지수 백오프 (10초 → 20초, 최대 2회/라운드) |
| 데이터 저장 | 메모리 전용 (유실 위험) | CSV append + flush (판정 즉시 디스크) |
| 재실행 | 처음부터 | resume, 완료된 (qid, postId) 건너뛰기 |
| Status API | dataSize만 | success, fail 별도 표시 |
수정 후 10쿼리 x 20문서 = 200쌍, Gemini 3.1 Flash Lite로 200/200 성공 (100%).

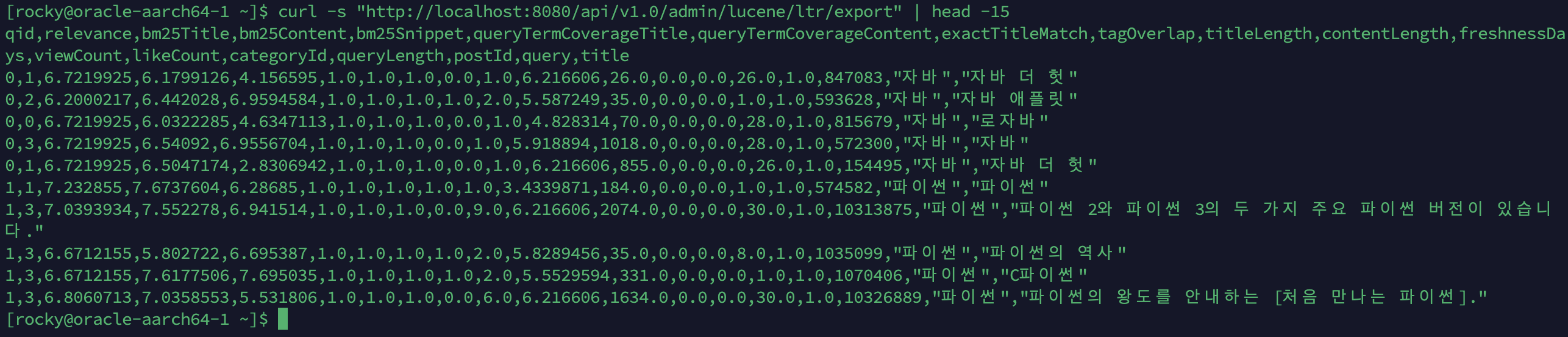
3-2. 피처 추출기 (14개 피처)
현업 기준: cold start 시 10~20개 피처로 시작 (LinkedIn 200+, Etsy 50~100). BM25 score가 거의 항상 최중요 피처. 처음 20개 피처가 전체 성능의 80%.
| # | 피처 | 유형 | 설명 |
|---|---|---|---|
| 1 | bm25Title | query-dependent | title 필드 BM25 스코어 |
| 2 | bm25Content | query-dependent | content 필드 BM25 스코어 |
| 3 | queryTermCoverageTitle | query-dependent | query term 중 title에 등장하는 비율 |
| 4 | queryTermCoverageContent | query-dependent | query term 중 content에 등장하는 비율 |
| 5 | exactTitleMatch | query-dependent | query가 title에 정확히 포함 (0/1) |
| 6 | titleLength | query-independent | title 길이 (토큰 수) |
| 7 | contentLength | query-independent | content 길이 (문자 수, log 변환) |
| 8 | freshnessDays | query-independent | 생성일로부터 경과일 |
| 9 | viewCount | query-independent | 조회수 (log1p 변환) |
| 10 | likeCount | query-independent | 좋아요 수 (log1p 변환) |
| 11 | tagOverlap | query-dependent | query term과 태그의 중복 수 |
| 12 | categoryId | query-independent | 카테고리 ID (ordinal) |
| 13 | queryLength | query-level | 쿼리 단어 수 |
| 14 | bm25Snippet | query-dependent | snippetSource 필드 BM25 스코어 |
3-3. Rescorer 기반 재랭킹
Two-Phase Ranking은 Google, Bing, 네이버 등 대부분의 검색엔진이 사용하는 패턴입니다:
1단계 (BM25): 12,156,589건 → Top-200 추출 (ms 단위)2단계 (LTR): Top-200 → 14개 피처 추출 → XGBoost4J 스코어링 → Top-K 반환public class LTRRescorer extends Rescorer { private final Booster booster; // XGBoost4J 모델
@Override public TopDocs rescore(IndexSearcher searcher, TopDocs firstPass, int topN) { for (int i = 0; i < hits.length; i++) { float[] features = featureExtractor.extractFeatures(query, doc, searcher); // XGBoost4J inplace_predict — thread-safe, DMatrix 생성 불필요 float[][] input = new float[][] { features }; float[][] output = booster.inplacePredict(input, 0, 0); newScores[i] = output[0][0]; } // 새 스코어로 정렬 → rerankedTopDocs }}Rescore window N=200은 Elasticsearch 공식 문서 기본값. ltr.enabled 설정으로 ON/OFF 제어.
3-4. 클릭 로그 인프라: implicit feedback 수집
LLM-as-a-Judge는 cold start 부트스트랩용입니다. 프로덕션에서는 사용자 클릭 데이터가 더 정확합니다.
-- click_logs 테이블 (Flyway V5)CREATE TABLE click_logs ( id BIGINT AUTO_INCREMENT PRIMARY KEY, query VARCHAR(500) NOT NULL, post_id BIGINT NOT NULL, click_position INT, dwell_time_ms BIGINT, session_id VARCHAR(36), user_id BIGINT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);- 검색 결과 클릭 시
navigator.sendBeacon()→ Kafka “search.clicks” topic produce + DB 저장 - 게시글 상세
visibilitychange+pagehide→ dwell time 전송 sessionStorage로 탭 단위 세션 ID 관리
클릭 → relevance 변환 규칙 (향후 재학습 시):
| Dwell time | Grade | 의미 | 근거 |
|---|---|---|---|
| > 120초 | 3 (Highly Relevant) | SAT click | Kim et al. WSDM 2014 |
| 30~120초 | 2 (Relevant) | Medium | |
| 10~30초 | 1 (Marginally) | Short click | |
| < 10초 | 0 (Irrelevant) | Misclick | Microsoft Research |
| 미클릭 + position 1~3 | 0 | 봤는데 안 클릭 | Joachims Skip-Above |
5. 검증: Before/After
랭킹 품질 (NDCG@10)
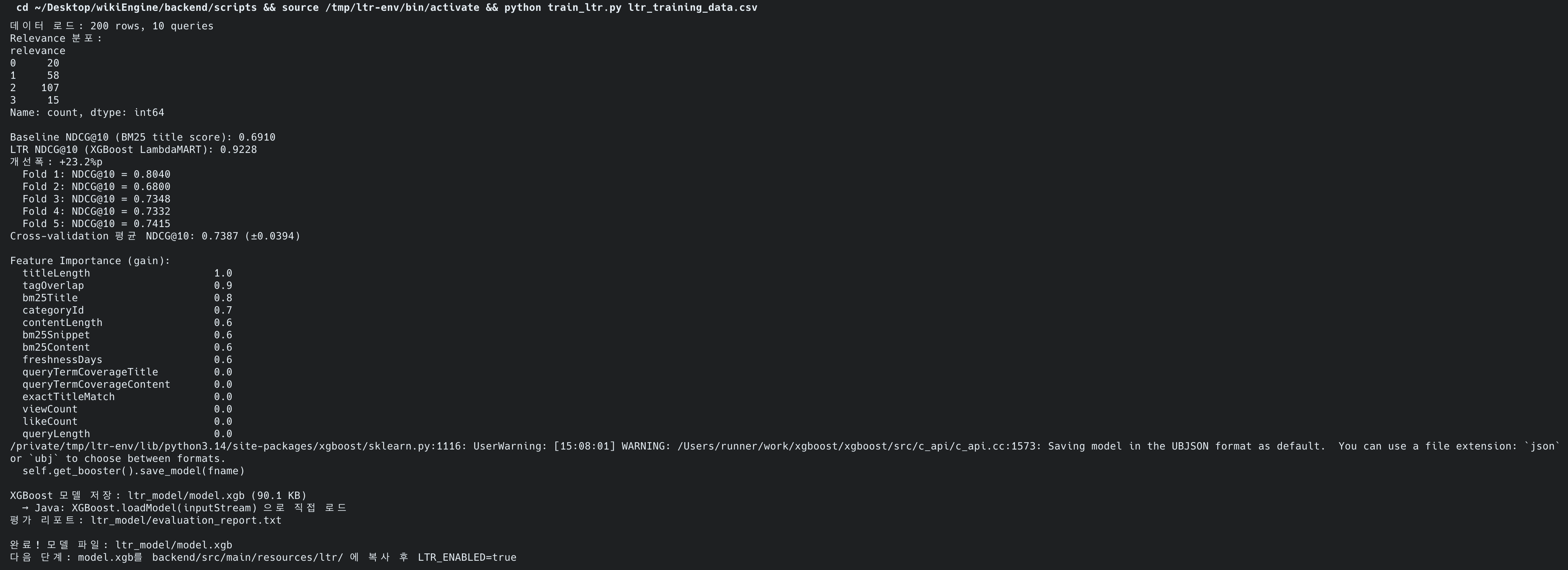
| 지표 | 수치 | 비고 |
|---|---|---|
| BM25 Baseline NDCG@10 | 0.6910 | bm25Title 스코어 기준 |
| LTR NDCG@10 (train set) | 0.9228 | 과적합 반영, 참고용 |
| LTR NDCG@10 (5-Fold CV) | 0.7387 (+-0.04) | BM25 대비 +4.8%p |
train set 0.9228은 과적합이 반영된 수치. CV 기준 +4.8%p가 정직한 개선폭. 10쿼리 200쌍 소규모 데이터에서 +4.8%p는 유의미한 개선 (Sanderson & Zobel: 100쿼리 기준 +5% 이상이면 통계적 감지 가능).
Feature Importance (gain):
| 순위 | 피처 | Gain | 분석 |
|---|---|---|---|
| 1 | titleLength | 1.0 | 짧은 제목 = 동음이의어 분기 문서 판별 |
| 2 | tagOverlap | 0.9 | 쿼리 term과 태그 중복, 태그 인덱싱의 효과 |
| 3 | bm25Title | 0.8 | BM25 title 스코어, 거의 모든 LTR에서 상위 |
| 4 | categoryId | 0.7 | 카테고리, 자동 분류의 효과 |
| 9~14 | viewCount, likeCount 등 | 0.0 | 미사용, 현재 더미 데이터로 변별력 없음 |
viewCount/likeCount가 0.0인 이유: 현재 조회수/좋아요가 거의 없어 변별력이 없음. 실 트래픽이 쌓이면 이 피처들의 importance가 올라갈 것으로 예상.
Before: “자바” BM25 기본 랭킹
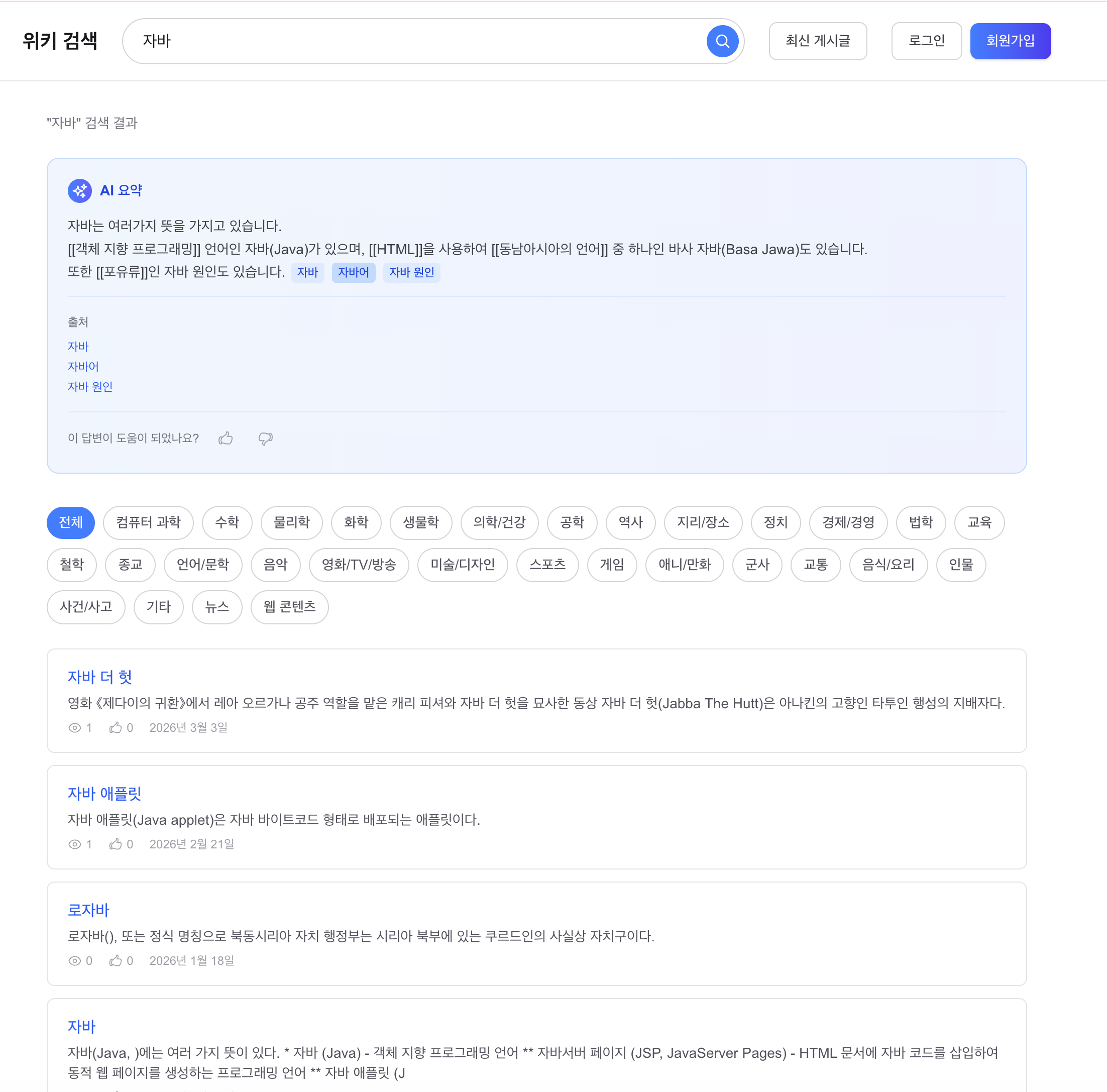

BM25 + FeatureField 수동 부스팅: 1.자바 더 헛(스타워즈) → 2.자바 애플릿 → 3.로자바 → 4.자바(프로그래밍 언어). 사용자 의도인 프로그래밍 언어가 4위로 밀려남.
After: “자바” LTR 재랭킹
LTR 재랭킹: 1.자바(프로그래밍 언어) → 2.자바스크립트 → 3.자바인. “자바 더 헛(스타워즈)“이 1위에서 밀려나고 프로그래밍 관련 문서가 상위로 이동. titleLength + tagOverlap + bm25Title 피처 interaction의 결과.
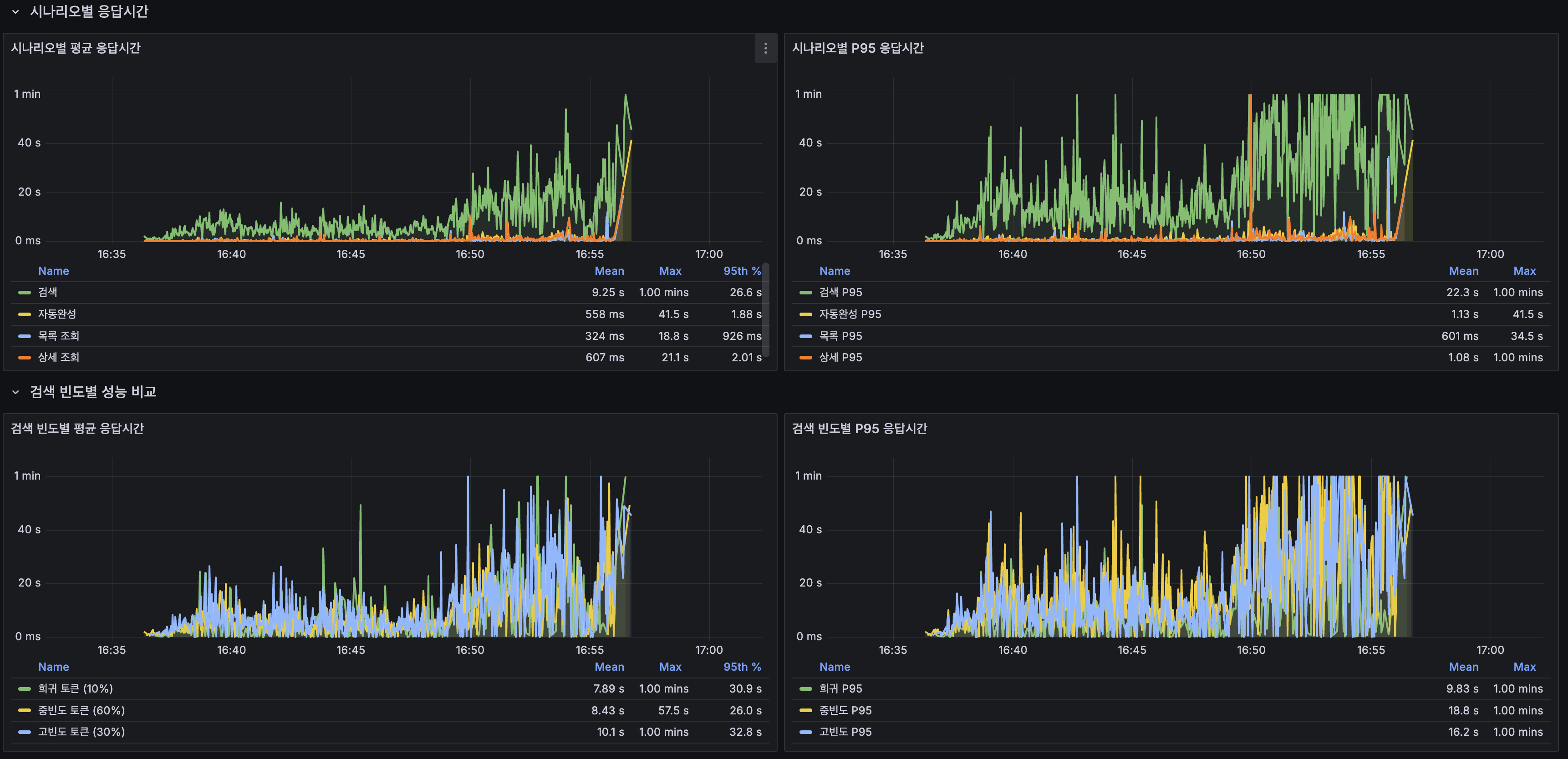
6. 부하 테스트: LTR의 현실
LTR ON: k6 100 VU, 20분
| 시나리오 | Baseline (LTR OFF) | LTR ON | 변화 |
|---|---|---|---|
| 전체 | 42.81ms / P95 190ms | 3,088ms / P95 16.7s | 72배 악화 |
| 검색 | 29.18ms / P95 100ms | 8,826ms / P95 37.2s | 302배 악화 |
| 자동완성 | 11.68ms / P95 68ms | 497ms / P95 2.2s | LTR 무관인데도 42배 악화 |
| 에러율 | 0.00% | 0.81% | timeout + 500 |
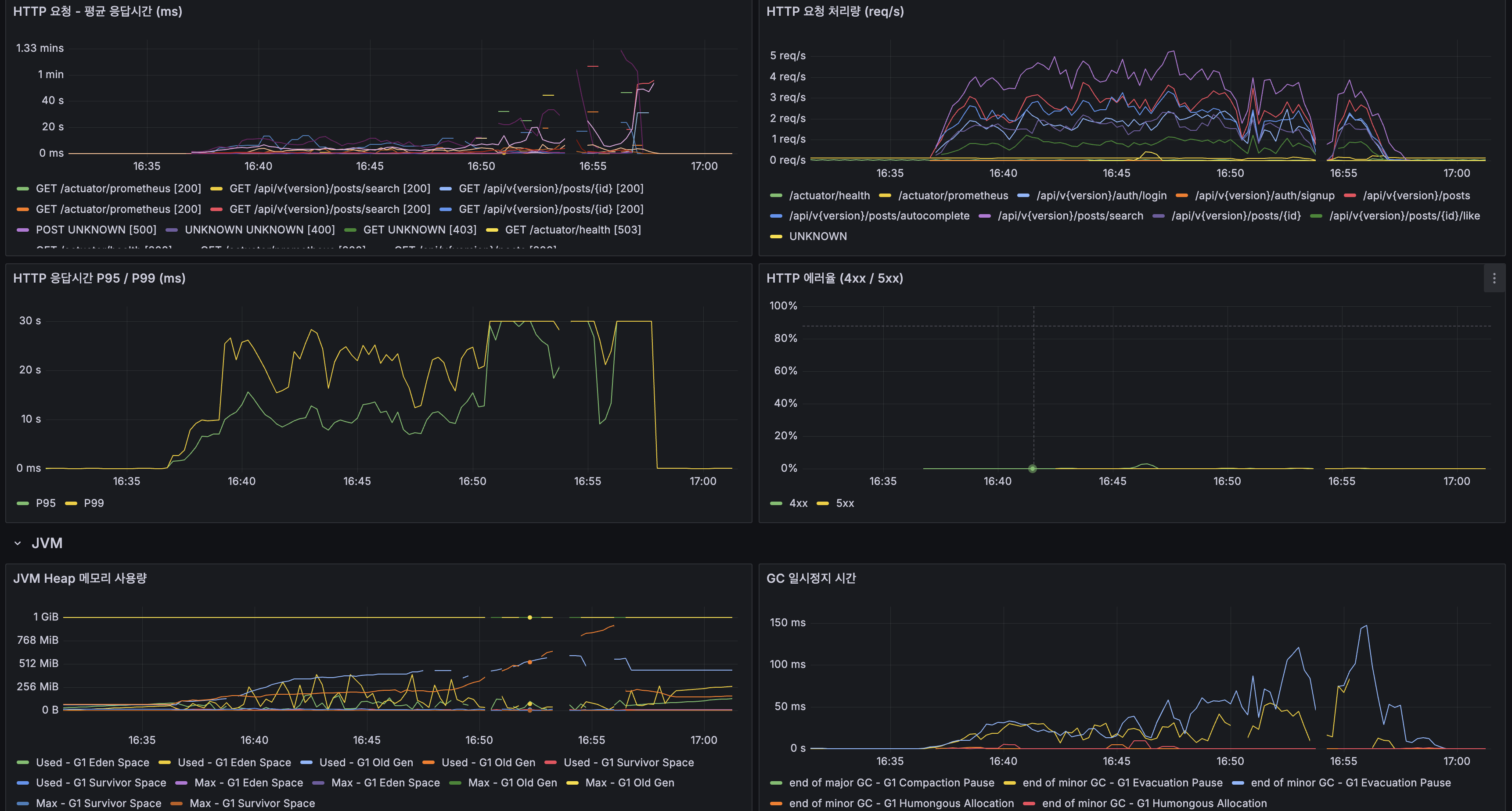
App CPU 피크 160% (2코어 중 80%+80%). JVM 스레드 수 50 → 150으로 급증. 모든 Tomcat 스레드가 LTR 피처 추출에 점유. Load Average 1분 피크 60 (2코어에서 30배 초과).
근본 원인: Rescore window 200에서 문서당 14개 피처 추출이 CPU-intensive. BM25 3필드 x 200문서 = 600회 Scorer 생성 + Nori 토큰화 200문서 x 3회 = 600회+ 형태소 분석. 100 VU 동시 요청 시 2코어 ARM에서 CPU 완전 포화 → queueing avalanche → LTR 무관 API(자동완성)까지 동반 악화.
LTR OFF: k6 100 VU, 20분
| 시나리오 | Baseline | LTR OFF (최종) | 변화 |
|---|---|---|---|
| 전체 | 42.81ms / P95 190ms | 263ms / P95 1.17s | +515% |
| 검색 | 29.18ms / P95 100ms | 548ms / P95 2.61s | Facet+태그+사전 비용 |
| 자동완성 | 11.68ms / P95 68ms | 43ms / P95 99ms | Baseline 수준 회복 |
| 에러율 | 0.00% | 0.00% | 안정 |
LTR OFF 시 에러율 0%, 자동완성 43ms로 Baseline 수준 회복. 검색 548ms는 이 글에서 추가된 Facet 집계 + 태그 인덱싱 + Nori 사용자 사전 158K의 비용. 인덱스 크기 36GB → 42GB 증가도 영향.
결론
- LTR 파이프라인은 기능 검증 완료: 학습 데이터 생성(LLM-as-a-Judge) → 모델 학습(XGBoost LambdaMART) → 재랭킹(Rescorer) → NDCG +4.8%p 개선 → 부하 테스트
- 2코어 ARM Free Tier에서 프로덕션 LTR은 CPU 부족:
LTR_ENABLED=false로 비활성화, 인프라 확장 시 재활성화 예정 - 규모가 더 커지면: 피처 사전 계산(pre-computation), 피처 캐싱, 전용 다코어 서버 또는 GPU에서 LTR 처리를 분리하는 편이 더 적합합니다. Elasticsearch LTR 플러그인도 dedicated scoring node 구성을 권장합니다.
다음 글
콘텐츠 필터링: 운영 안전장치에서 Aho-Corasick 기반 금칙어 필터링, 블라인드 게시글 검색 제외, Negative Caching, 자동완성 안전장치를 구현합니다.
출처
- SIGIR 2024 — LLMs can Accurately Predict Searcher Preferences (Thomas et al.)
- OpenSource Connections — LTR Linear Models
- Booking.com — 150 Successful ML Models (KDD 2019)
- Airbnb — ML-Powered Search Ranking (KDD 2018)
- Joachims et al. — Accurately Interpreting Clickthrough Data (SIGIR 2005)
- Kim et al. — Modeling Dwell Time (WSDM 2014)
- XGBoost Learning to Rank Tutorial
- Sanderson & Zobel — How many queries?
- LUCENE-7905 — SortedSetDocValues OrdinalMap build cost
Previous
In Query Expansion + Query Understanding we built synonym expansion, DirectSpellChecker typo correction, UnifiedHighlighter snippet improvements, and the full reindex infrastructure for 12,156,589 docs.
| Metric | Result |
|---|---|
| Synonym expansion | ”AI” → “인공지능” #1 (recall improved) |
| Typo correction | ”프로그래링” → “프로그래밍” suggestion succeeded |
| Snippet | UnifiedHighlighter + 500-char snippetSource |
| Reindex infra | Directory Swap + SearcherManager recreation (zero downtime) |
Search queries are correctly interpreted and expanded, but the ranking model still relies on manual rules. Also, the switch to native Lucene Facets that was deferred in Category Search Filtering is completed in this post.
1. Steady State — Current Ranking Model
The ranking implemented in Search Quality Evaluation is based on manual weights. Whether these weights actually align with the order users want has not been validated by data.
2. Problems
Problem 1: limits of manual weighting
Problem 2: Facet — limits of DB GROUP BY approximation
In Category Search Filtering I implemented an approximate Facet via DB GROUP BY, but it was an approximation over only the top-1,000 results. Switching to native SortedSetDocValuesFacetCounts is needed for exact Facets over the entire matching set. That requires SortedSetDocValuesFacetField + a full reindex.
Problem 3: namespace-based categories make Facets meaningless
The categories assigned during the wiki import skew 97% to “general doc,” so showing a Facet is meaningless. Reclassifying into 28 topical categories must come first.
3. Alternative Review
LTR model choice
| Model | Pro | Con | Verdict |
|---|---|---|---|
| LambdaMART (XGBoost) | optimizes NDCG, industry standard for search ranking | Python training → Java inference conversion needed | chosen |
| Linear Model | simple, interpretable, native to Java | cannot learn non-linear relationships | rejected (same as manual boosting) |
| Neural (BERT) | understands context | inference latency hundreds of ms, needs GPU | rejected (240ms SLA) |
| Elasticsearch LTR | integrated into ES ecosystem | needs a separate cluster (≥6GB RAM) | rejected (impossible on Free Tier) |
Why Linear Model was rejected: per OpenSource Connections — “Elasticsearch boosts are nothing but coefficients in a linear regression”. Training a Linear Model on the same 3 features (viewCount, likeCount, recency) gives almost identical results to the existing manual weights. A tree model (LambdaMART) can learn feature interactions (e.g., short titleLength + high tagOverlap), capturing non-linear relationships.
Java inference runtime choice
| Option | Outcome | Reason |
|---|---|---|
| xgboost-predictor-java | rejected | incompatible with XGBoost 2.x model format (UBJSON), deprecated |
| ONNX Runtime | rejected | onnxmltools does not support XGBRanker → ONNX conversion (Issue #382) |
| XGBoost4J | chosen | loads Python save_model() directly via Java XGBoost.loadModel() with no conversion. ARM64 Linux native lib bundled in the JAR. inplace_predict() is thread-safe |
OCI Free Tier is ARM Ampere A1. The XGBoost4J JAR (ml.dmlc:xgboost4j_2.12:2.1.4) bundles lib/linux/aarch64/libxgboost4j.so, so it works without any extra compilation.
Training data: LLM-as-a-Judge
User traffic is essentially zero, so click logs do not accumulate. We use an LLM to substitute for relevance judgments.
Industry basis: SIGIR 2024 (Thomas et al.) — GPT-4’s relevance judgments agree with crowdsource annotators at Cohen’s Kappa 0.6-0.7, equal to or better than inter-annotator agreement (0.4-0.6).
4. Implementation
Part 1: Auto-classifying 28 categories
Reclassified the existing namespace-based categories (“general doc” 97%) into 28 topical categories (computer science, math, physics, history, music, games, sports, etc.).
Method: keyword-based batch classification (CategoryClassificationService). For each category, define a list of representative keywords; assign the post to the category with the most keyword matches in title + tags.
Accuracy validation (90 manual samples):
| Category | Correct | Borderline | Wrong | Accuracy |
|---|---|---|---|---|
| Computer Science | 10 | 0 | 0 | 100% |
| History | 10 | 0 | 0 | 100% |
| Music | 10 | 0 | 0 | 100% |
| Game | 10 | 0 | 0 | 100% |
| Sports | 10 | 0 | 0 | 100% |
| Physics | 8 | 2 | 0 | 80% |
| Math | 6 | 4 | 0 | 60% |
| Education | 6 | 3 | 1 | 60% |
| People | 5 | 5 | 0 | 50% |
| Average | ~83% |
Limits of keyword classification: “수능시험” (college entrance exam) matches the “math” keyword and is classified as math; anime character names match the “people” keyword. Without priority/exclusivity logic between keywords, accuracy degrades on edge cases. 83% is enough for Facet exploration; can be improved with MoreLikeThis-based reclassification later.
Part 2: Native Facet switch + tag indexing
This is where the native Lucene Facet deferred in Category Search Filtering lands. All changes are integrated into a single reindex.
Changes included in the reindex:
| Change | Detail |
|---|---|
| Facet field | SortedSetDocValuesFacetField("category", categoryName) |
| Tag indexing | TextField("tags", tagNames, Store.YES) — 2.16M unique tags |
| Nori user dict | 158,539 entries (30 manual + 158,509 from open-korean-text) |
| snippetSource sanitization | raw markup → clean plain text |
| Batch tag preloading | prevents N+1 (1 JOIN query per batch) |
Performance optimizations:
SortedSetDocValuesReaderStatecached via RefreshListener: pre-built when the reader refreshes viaSearcherManager.addListener(). The search path does only a volatile read, no lock. Lucene Javadoc: “create it once and re-use for a given IndexReader”. LUCENE-7905 reports OrdinalMap build cost of ~106s for 26.6M terms — must not build it on every search.- Single-pass collection of TopDocs + FacetsCollector via
MultiCollectorManager: consolidate twosearcher.search()calls into one for the same query, saving I/O.
Decision to drop tag Facet: Faceting over 2.16M unique tags is a high-cardinality anti-pattern (Elasticsearch’s own docs warn about this). Tags are kept only for search-quality (indexed as TextField and matched in search); only the 30 categories are kept as Facets.
Facet measurement:
Aggregated over the entire matching set via
SortedSetDocValuesFacetCounts. Searching “프로그래밍”: web content (21,884) > others (3,770) > computer science (3,047) > games (878) > music (720) … food/cooking (5). All 30 categories aggregated correctly.
Part 3: LTR — LambdaMART + XGBoost4J
3-1. Training data — LLM-as-a-Judge (Gemini)
Collect 45 search queries, extract BM25 top-20 for each → 900 (query, doc) pairs. Use the Gemini API for 4-point relevance judgments:
- 0: Irrelevant
- 1: Marginally relevant — only mentions the topic
- 2: Relevant — partial answer
- 3: Highly relevant — direct, complete answer
Non-determinism handling — average of 3 calls, rounded: even at temperature=0, LLMs are not fully deterministic (GPU batch composition varies, floating-point non-associativity). For graded relevance, averaging + rounding is the canonical approach (TREC LLMJudge participant RMIT-IR: 3 generations → average → round).
First run failed (2% success rate):
45 queries × 20 docs = 900 marked done, but CSV export pulled out only 18. Server logs showed 882 with
Failed to generate content.
Root cause: 2-second delay between rounds → 3 calls take ~6s → 30 requests/min, exceeding 15 RPM. Spring AI’s default retry classifies HTTP 429 as NonTransientAiException and does not retry. Also, data was memory-only (ArrayList) and the status API had no success/fail breakdown, so the 98% failure went unnoticed.
Fixes:
| Item | Before | After |
|---|---|---|
| Inter-round delay | 2s (30 RPM, over) | 5s (12 RPM, within 15 RPM) |
| On API failure | no retry | exponential backoff (10s → 20s, max 2 per round) |
| Data persistence | memory-only (loss risk) | CSV append + flush (write to disk on each judgment) |
| Re-execution | from scratch | resume — skip completed (qid, postId) |
| Status API | only dataSize | shows success and fail separately |
After the fixes: 10 queries × 20 docs = 200 pairs, 200/200 success on Gemini 3.1 Flash Lite (100%).
3-2. Feature extractor (14 features)
Industry baseline: cold start uses 10-20 features (LinkedIn 200+, Etsy 50-100). BM25 score is almost always the most important. The first 20 features cover ~80% of total performance.
| # | Feature | Type | Description |
|---|---|---|---|
| 1 | bm25Title | query-dependent | BM25 on title field |
| 2 | bm25Content | query-dependent | BM25 on content field |
| 3 | queryTermCoverageTitle | query-dependent | fraction of query terms appearing in title |
| 4 | queryTermCoverageContent | query-dependent | fraction of query terms appearing in content |
| 5 | exactTitleMatch | query-dependent | query exactly contained in title (0/1) |
| 6 | titleLength | query-independent | title length (token count) |
| 7 | contentLength | query-independent | content length (chars, log-transformed) |
| 8 | freshnessDays | query-independent | days since creation |
| 9 | viewCount | query-independent | view count (log1p) |
| 10 | likeCount | query-independent | like count (log1p) |
| 11 | tagOverlap | query-dependent | overlap between query terms and tags |
| 12 | categoryId | query-independent | category ID (ordinal) |
| 13 | queryLength | query-level | query word count |
| 14 | bm25Snippet | query-dependent | BM25 on snippetSource field |
3-3. Rescorer-based reranking
Two-Phase Ranking — the pattern most search engines use (Google, Bing, Naver):
Phase 1 (BM25): 12,156,589 docs → extract top-200 (ms range)Phase 2 (LTR): top-200 → extract 14 features → score with XGBoost4J → return top-Kpublic class LTRRescorer extends Rescorer { private final Booster booster; // XGBoost4J model
@Override public TopDocs rescore(IndexSearcher searcher, TopDocs firstPass, int topN) { for (int i = 0; i < hits.length; i++) { float[] features = featureExtractor.extractFeatures(query, doc, searcher); // XGBoost4J inplace_predict — thread-safe, no DMatrix needed float[][] input = new float[][] { features }; float[][] output = booster.inplacePredict(input, 0, 0); newScores[i] = output[0][0]; } // sort by new scores → rerankedTopDocs }}Rescore window N=200 is the Elasticsearch official default. Toggle on/off via the ltr.enabled setting.
3-4. Click log infrastructure — implicit feedback collection
LLM-as-a-Judge is a cold-start bootstrap. In production, user click data is more accurate.
-- click_logs table (Flyway V5)CREATE TABLE click_logs ( id BIGINT AUTO_INCREMENT PRIMARY KEY, query VARCHAR(500) NOT NULL, post_id BIGINT NOT NULL, click_position INT, dwell_time_ms BIGINT, session_id VARCHAR(36), user_id BIGINT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);- On click in search results:
navigator.sendBeacon()→ produce to Kafka “search.clicks” topic + DB write - On post detail
visibilitychange+pagehide→ send dwell time sessionStorage-managed per-tab session ID
Click → relevance conversion (for future retraining):
| Dwell time | Grade | Meaning | Source |
|---|---|---|---|
| > 120s | 3 (Highly Relevant) | SAT click | Kim et al. WSDM 2014 |
| 30-120s | 2 (Relevant) | medium | |
| 10-30s | 1 (Marginally) | short click | |
| < 10s | 0 (Irrelevant) | misclick | Microsoft Research |
| no click + position 1-3 | 0 | seen but not clicked | Joachims Skip-Above |
5. Verification — Before/After
Ranking quality (NDCG@10)
| Metric | Value | Note |
|---|---|---|
| BM25 Baseline NDCG@10 | 0.6910 | bm25Title score |
| LTR NDCG@10 (train set) | 0.9228 | reflects overfit, reference only |
| LTR NDCG@10 (5-Fold CV) | 0.7387 (±0.04) | +4.8%p over BM25 |
The 0.9228 train-set figure reflects overfitting. +4.8%p on CV is the honest improvement. With a small dataset (10 queries, 200 pairs), +4.8%p is meaningful (Sanderson & Zobel: ≥+5% over 100 queries is statistically detectable).
Feature Importance (gain):
| Rank | Feature | Gain | Analysis |
|---|---|---|---|
| 1 | titleLength | 1.0 | short titles = disambiguation pages |
| 2 | tagOverlap | 0.9 | overlap of query terms and tags — payoff of tag indexing |
| 3 | bm25Title | 0.8 | BM25 title score — top in nearly all LTR setups |
| 4 | categoryId | 0.7 | category — payoff of auto-classification |
| 9-14 | viewCount, likeCount, etc. | 0.0 | unused — dummy data so no signal |
viewCount/likeCount are 0.0 because views/likes are essentially zero — no discriminative signal. Their importance should rise once real traffic accumulates.
Before: “자바” with BM25 default ranking
BM25 + FeatureField manual boost: 1. Java the Hutt (Star Wars) → 2. Java applet → 3. Rojava → 4. Java (programming language). The user-intended programming language is pushed to #4.
After: “자바” with LTR reranking
LTR rerank: 1. Java (programming language) → 2. JavaScript → 3. Java people. “Java the Hutt (Star Wars)” is dropped from #1 and programming-related docs move up. This is the result of titleLength + tagOverlap + bm25Title feature interactions.
6. Load Test — The Reality of LTR
LTR ON — k6 100 VU, 20 min
| Scenario | Baseline (LTR OFF) | LTR ON | Change |
|---|---|---|---|
| Overall | 42.81ms / P95 190ms | 3,088ms / P95 16.7s | 72× worse |
| Search | 29.18ms / P95 100ms | 8,826ms / P95 37.2s | 302× worse |
| Autocomplete | 11.68ms / P95 68ms | 497ms / P95 2.2s | 42× worse despite being unrelated to LTR |
| Error rate | 0.00% | 0.81% | timeout + 500 |
App CPU peak 160% (80% + 80% across 2 cores). JVM thread count spikes 50 → 150. All Tomcat threads occupied by LTR feature extraction. 1-min Load Average peaks at 60 (30× over capacity on 2 cores).
Root cause: extracting 14 features for each of 200 docs in the rescore window is CPU-intensive. BM25 across 3 fields × 200 docs = 600 Scorer creations + Nori tokenization 200 docs × 3 = 600+ morphological analyses. With 100 VU concurrency on 2-core ARM, CPU saturates → queueing avalanche → even unrelated APIs (autocomplete) degrade in tandem.
LTR OFF — k6 100 VU, 20 min
| Scenario | Baseline | LTR OFF (final) | Change |
|---|---|---|---|
| Overall | 42.81ms / P95 190ms | 263ms / P95 1.17s | +515% |
| Search | 29.18ms / P95 100ms | 548ms / P95 2.61s | cost of Facet+tags+dict |
| Autocomplete | 11.68ms / P95 68ms | 43ms / P95 99ms | back to baseline level |
| Error rate | 0.00% | 0.00% | stable |
With LTR off, error rate is 0% and autocomplete returns to the 43ms baseline level. The 548ms search figure is the cost of the additions in this post: Facet aggregation + tag indexing + 158K-entry Nori user dict. The index growth from 36GB → 42GB also contributes.
Conclusion
- LTR pipeline is functionally validated: training-data generation (LLM-as-a-Judge) → model training (XGBoost LambdaMART) → reranking (Rescorer) → NDCG +4.8%p improvement → load test
- Production LTR is CPU-bound on 2-core ARM Free Tier: disabled via
LTR_ENABLED=false; will re-enable when infrastructure scales up - At larger scale: pre-computed features, feature caching, and offloading LTR to a dedicated multi-core or GPU-backed scoring node fits better. The Elasticsearch LTR plugin also recommends a dedicated scoring node configuration.
Next
In Content Filtering — Operational Safety we implement Aho-Corasick banned-word filtering, exclusion of blinded posts from search, Negative Caching, and autocomplete safety mechanisms.
Sources
- SIGIR 2024 — LLMs can Accurately Predict Searcher Preferences (Thomas et al.)
- OpenSource Connections — LTR Linear Models
- Booking.com — 150 Successful ML Models (KDD 2019)
- Airbnb — ML-Powered Search Ranking (KDD 2018)
- Joachims et al. — Accurately Interpreting Clickthrough Data (SIGIR 2005)
- Kim et al. — Modeling Dwell Time (WSDM 2014)
- XGBoost Learning to Rank Tutorial
- Sanderson & Zobel — How many queries?
- LUCENE-7905 — SortedSetDocValues OrdinalMap build cost

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.