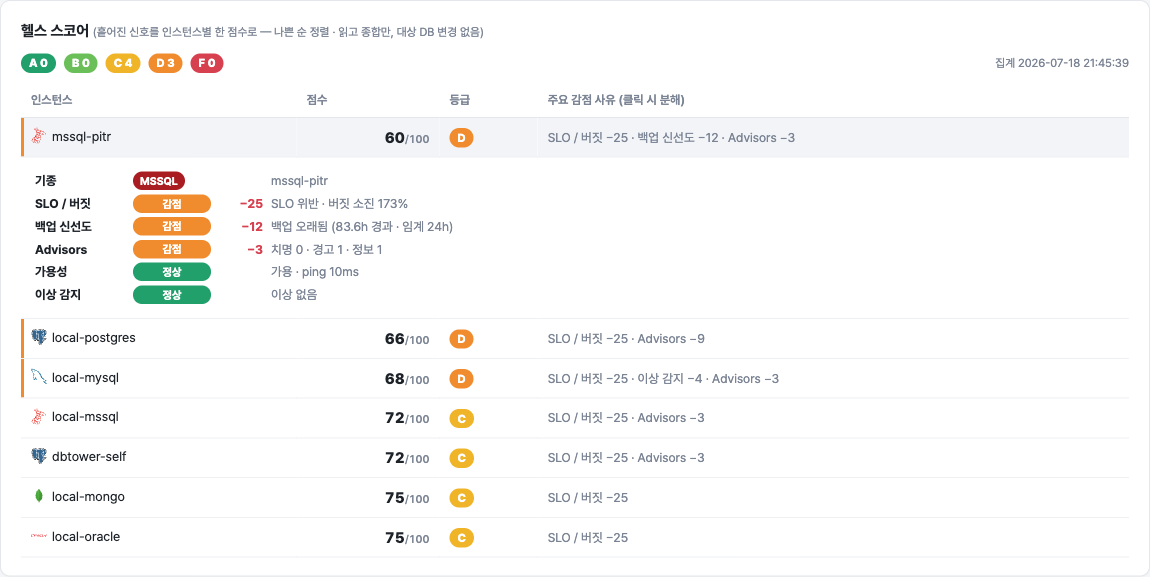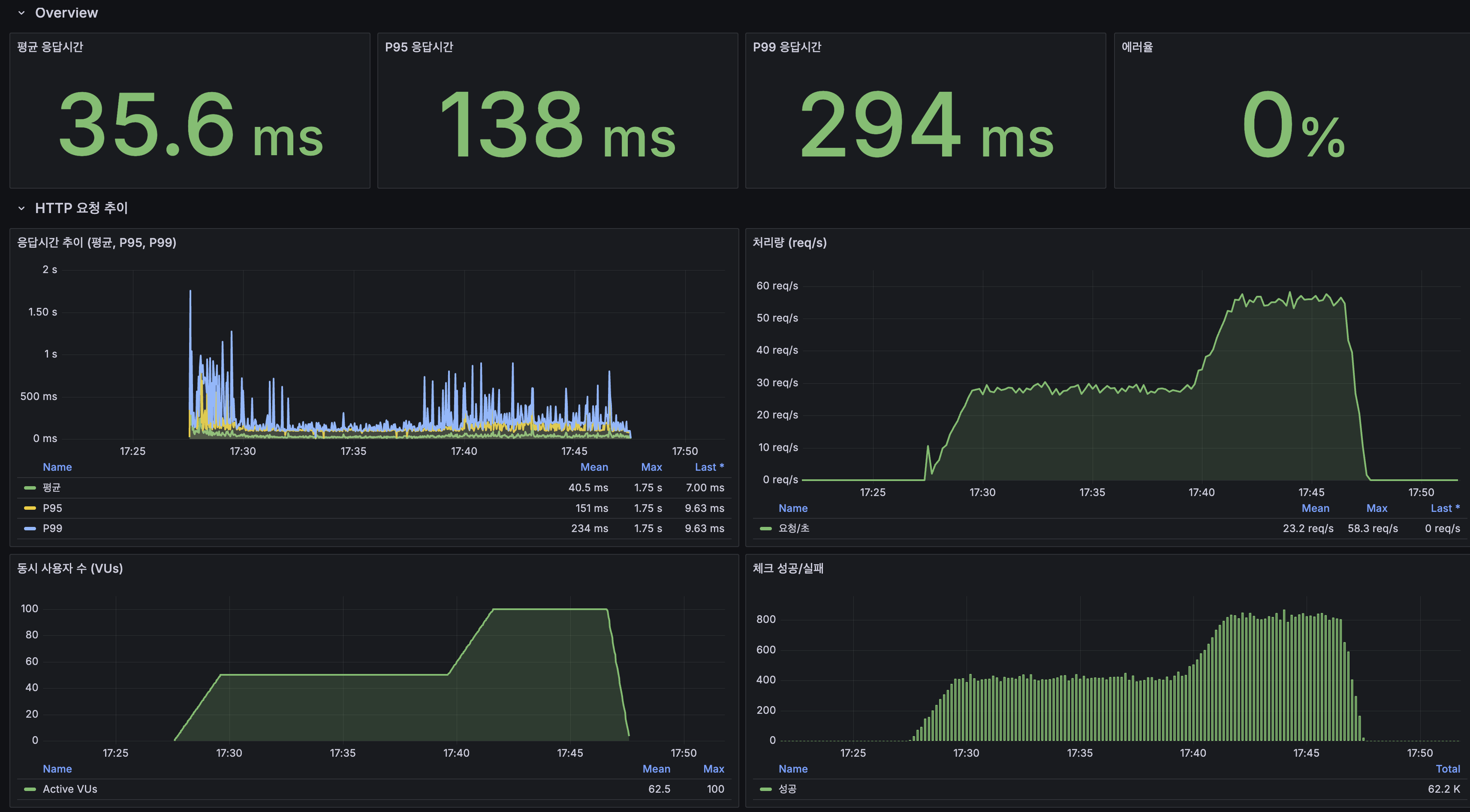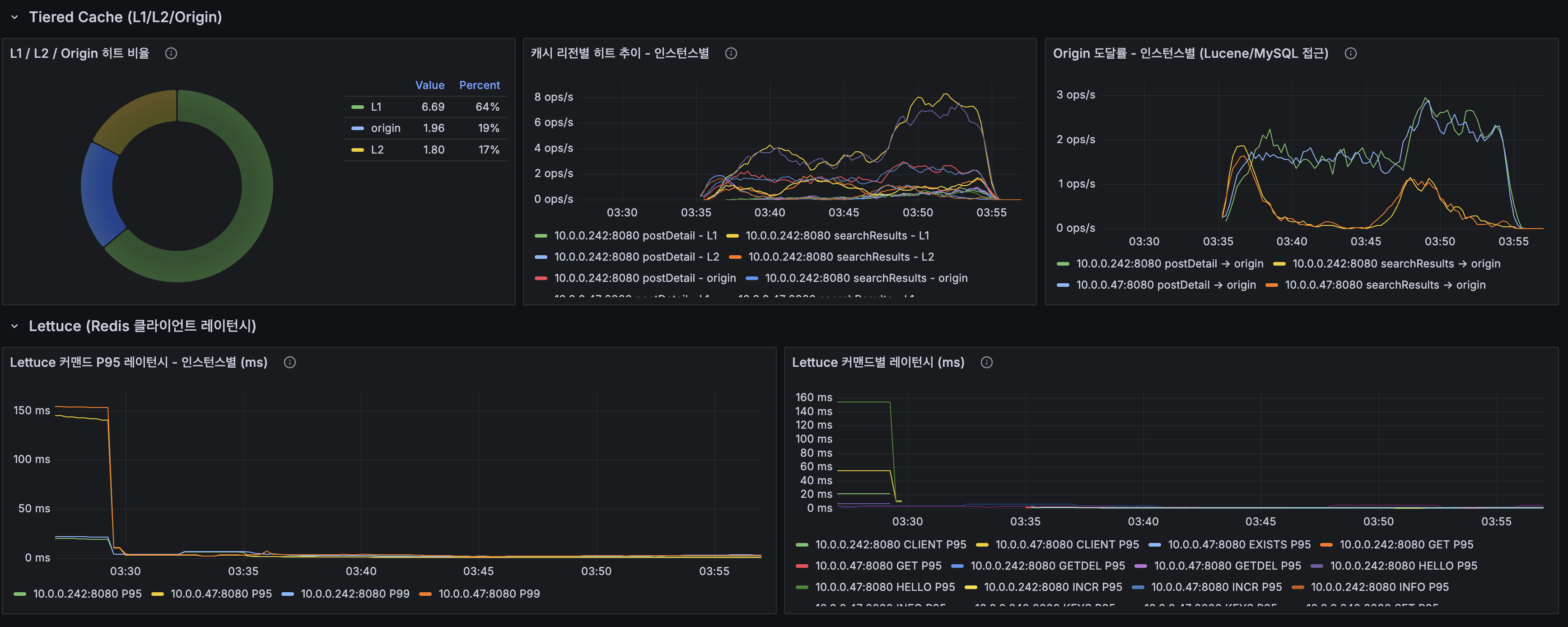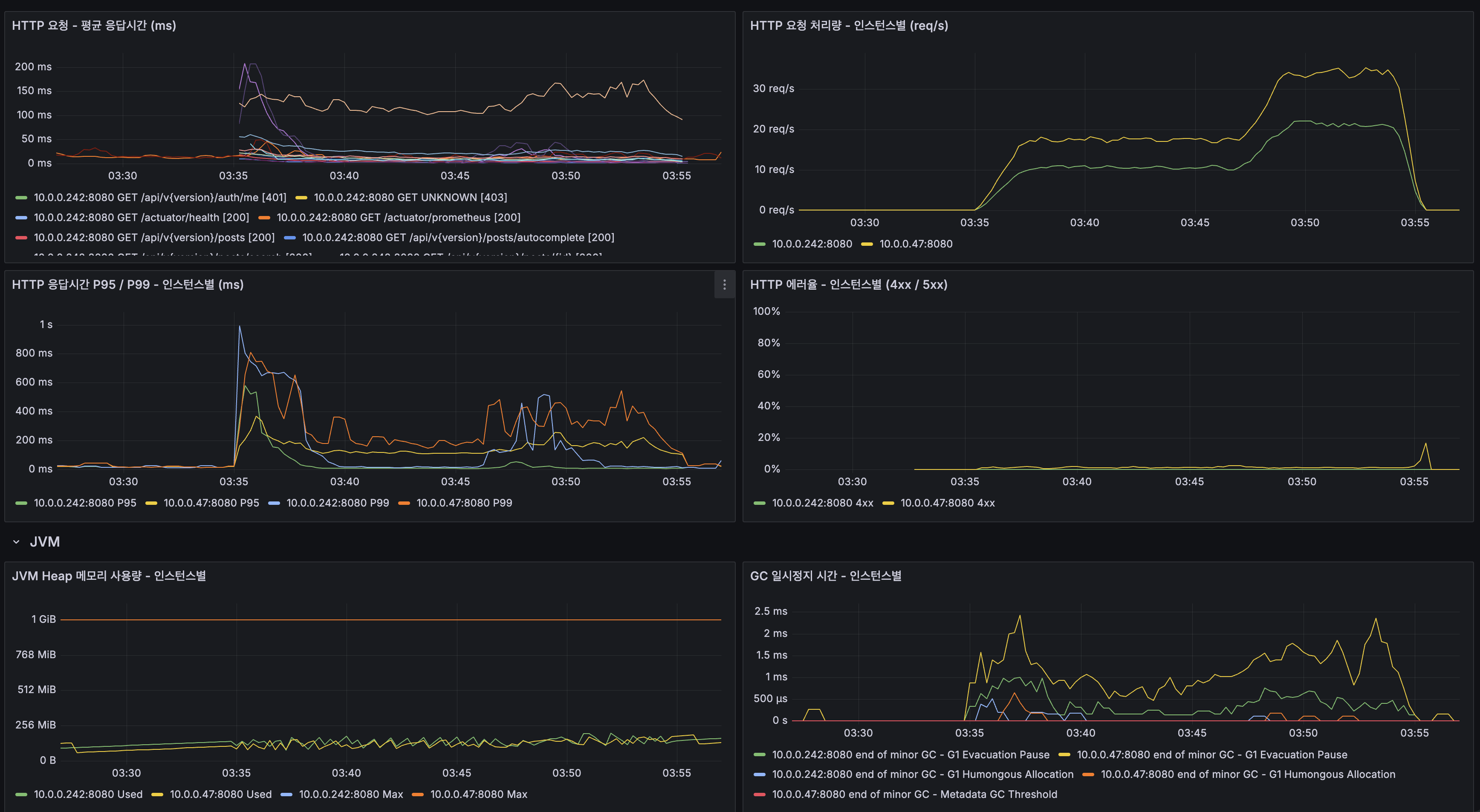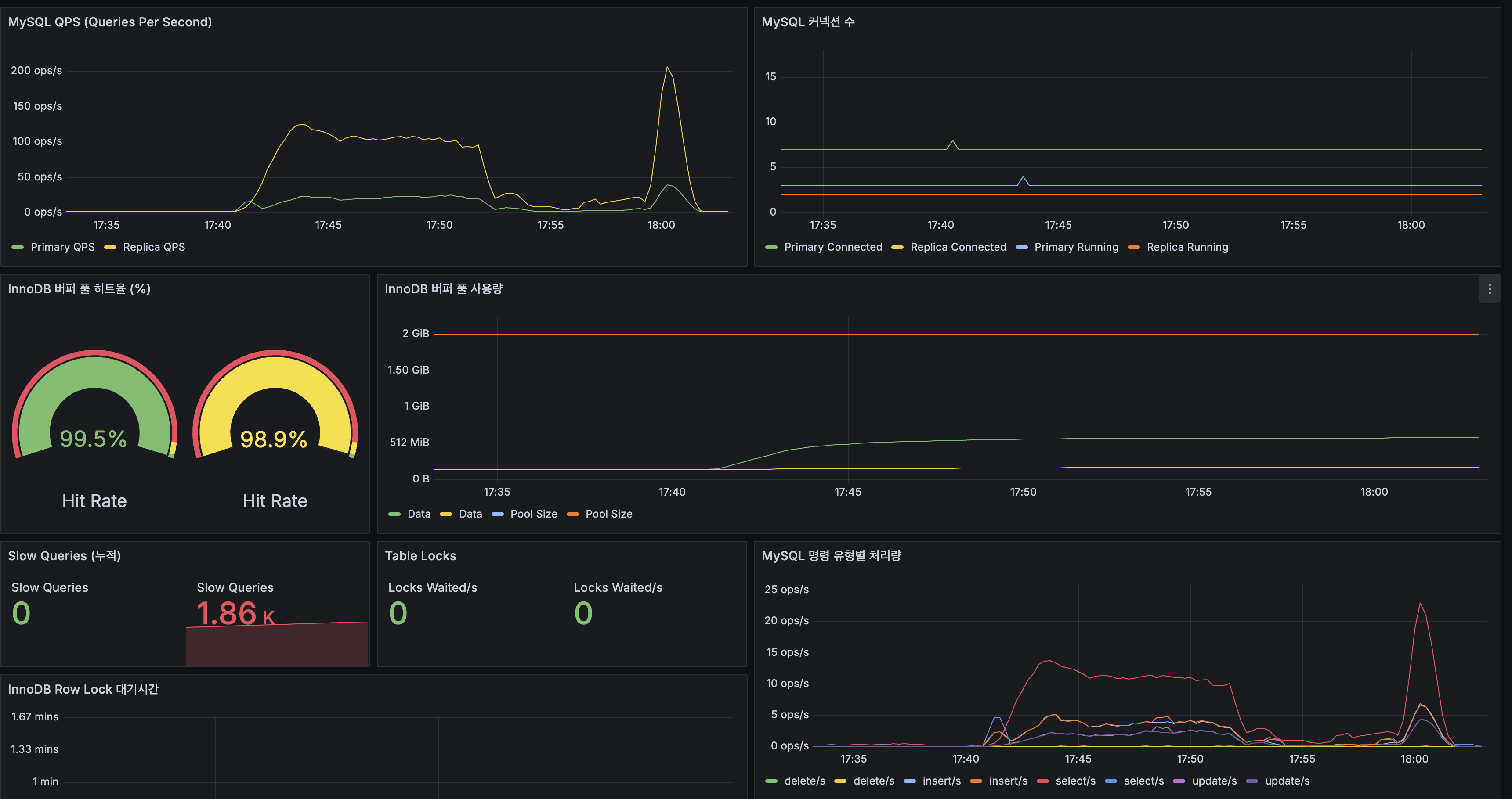
사람 손이 붙어 있던 다섯 곳을 끊다: 설정 드리프트·변경 리뷰·인덱스 판정·인시던트 리포트·월간 점검
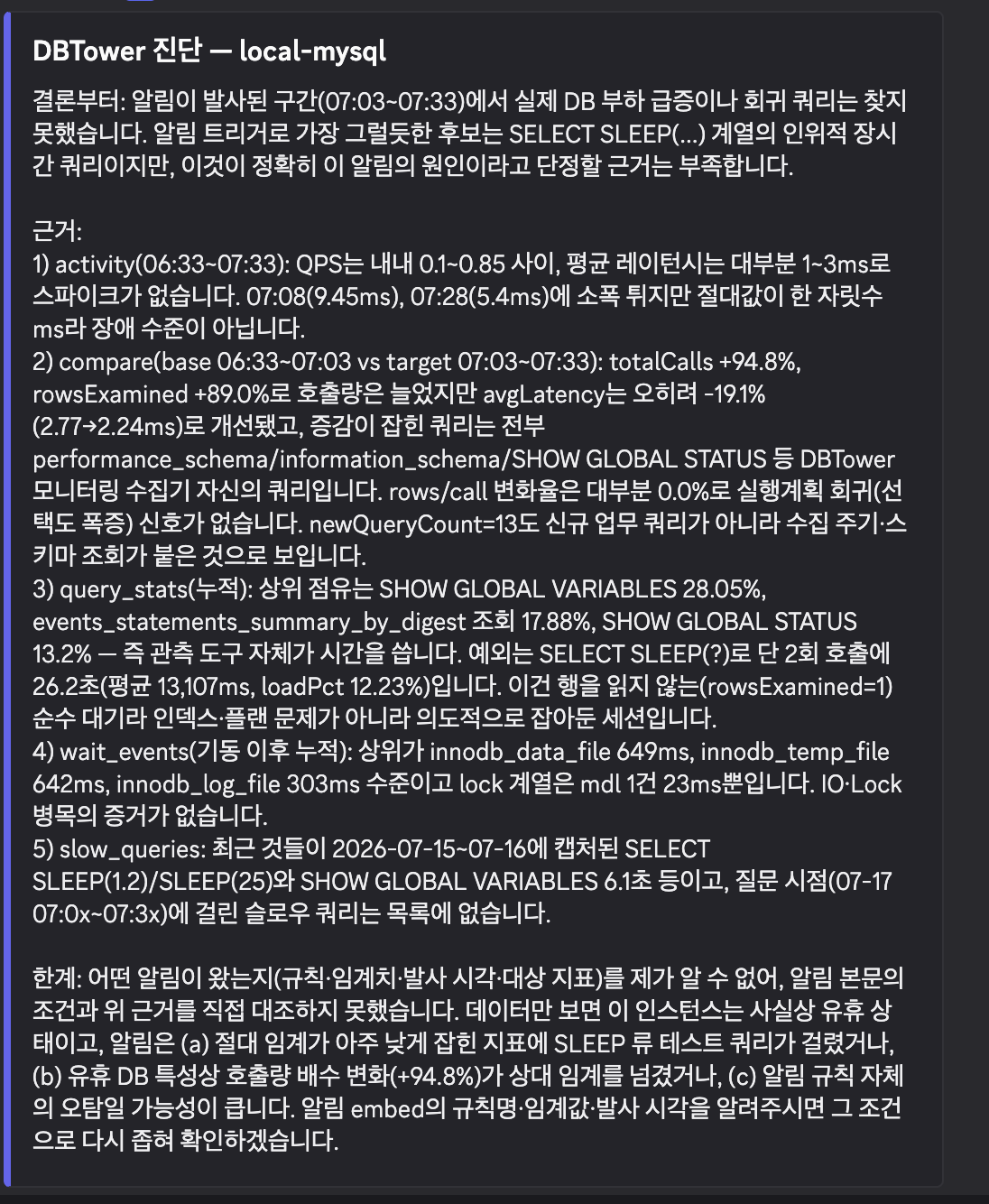
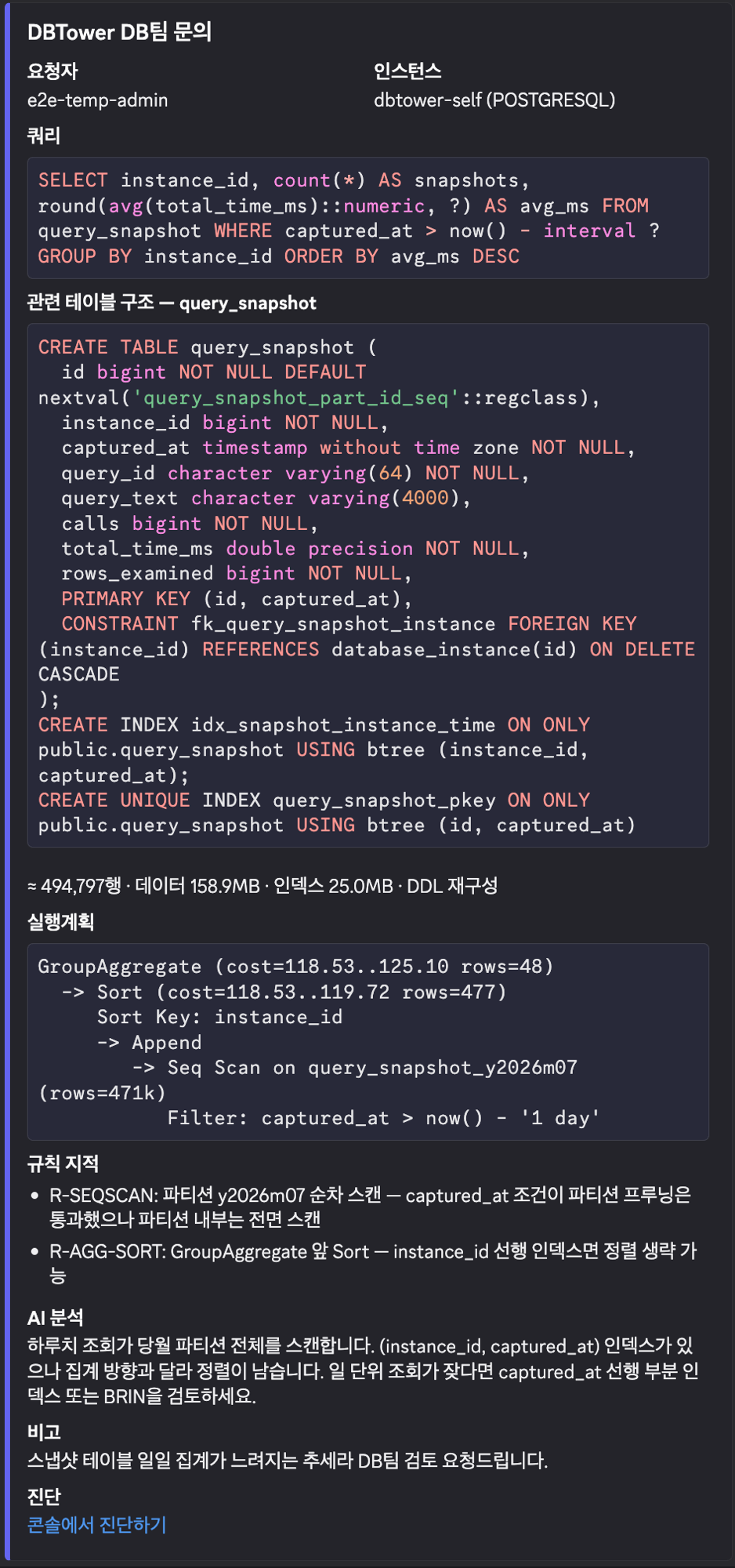
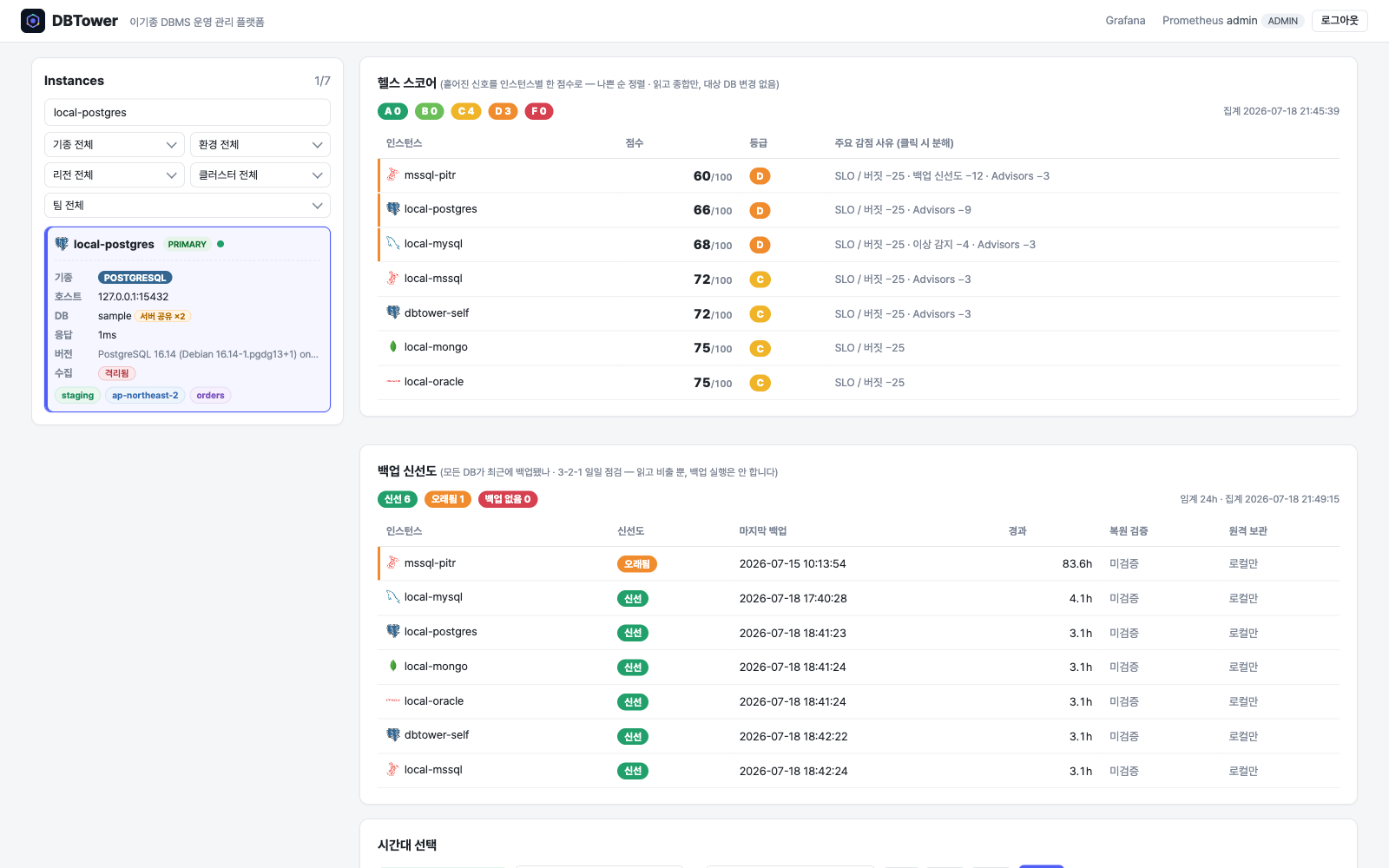
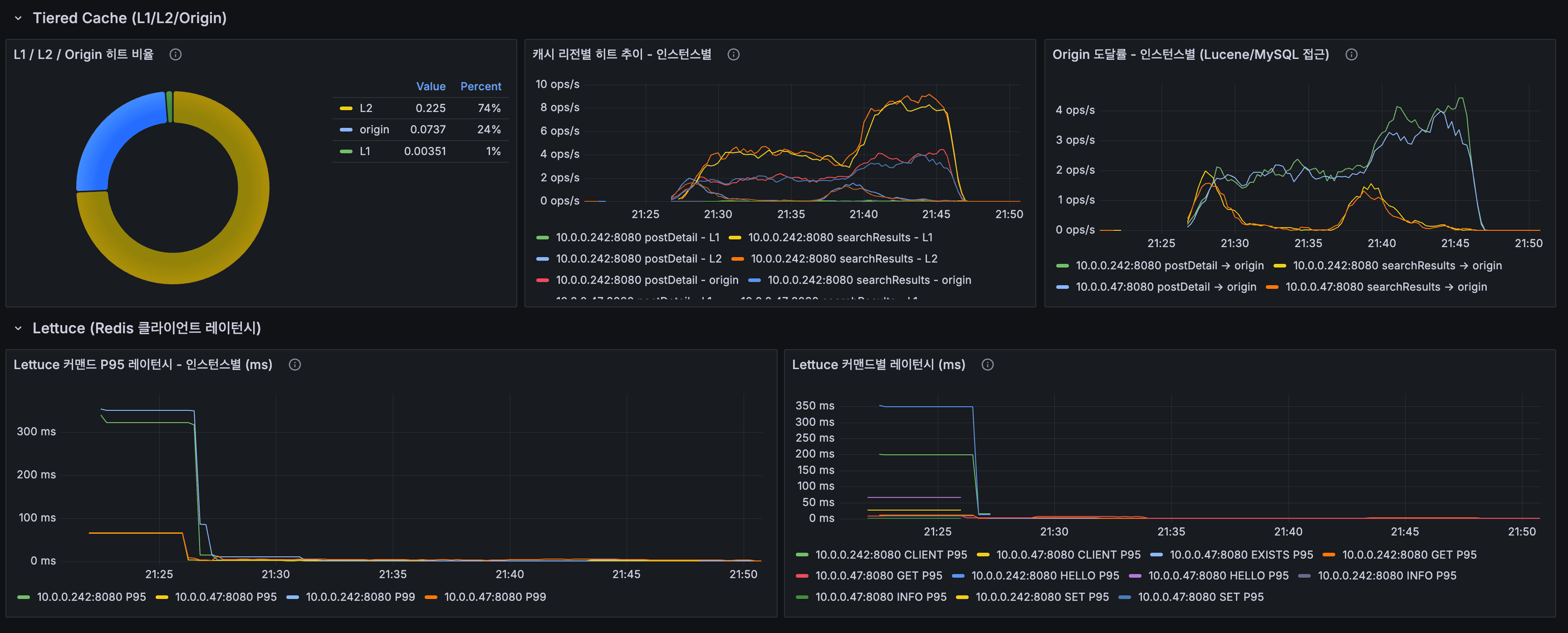
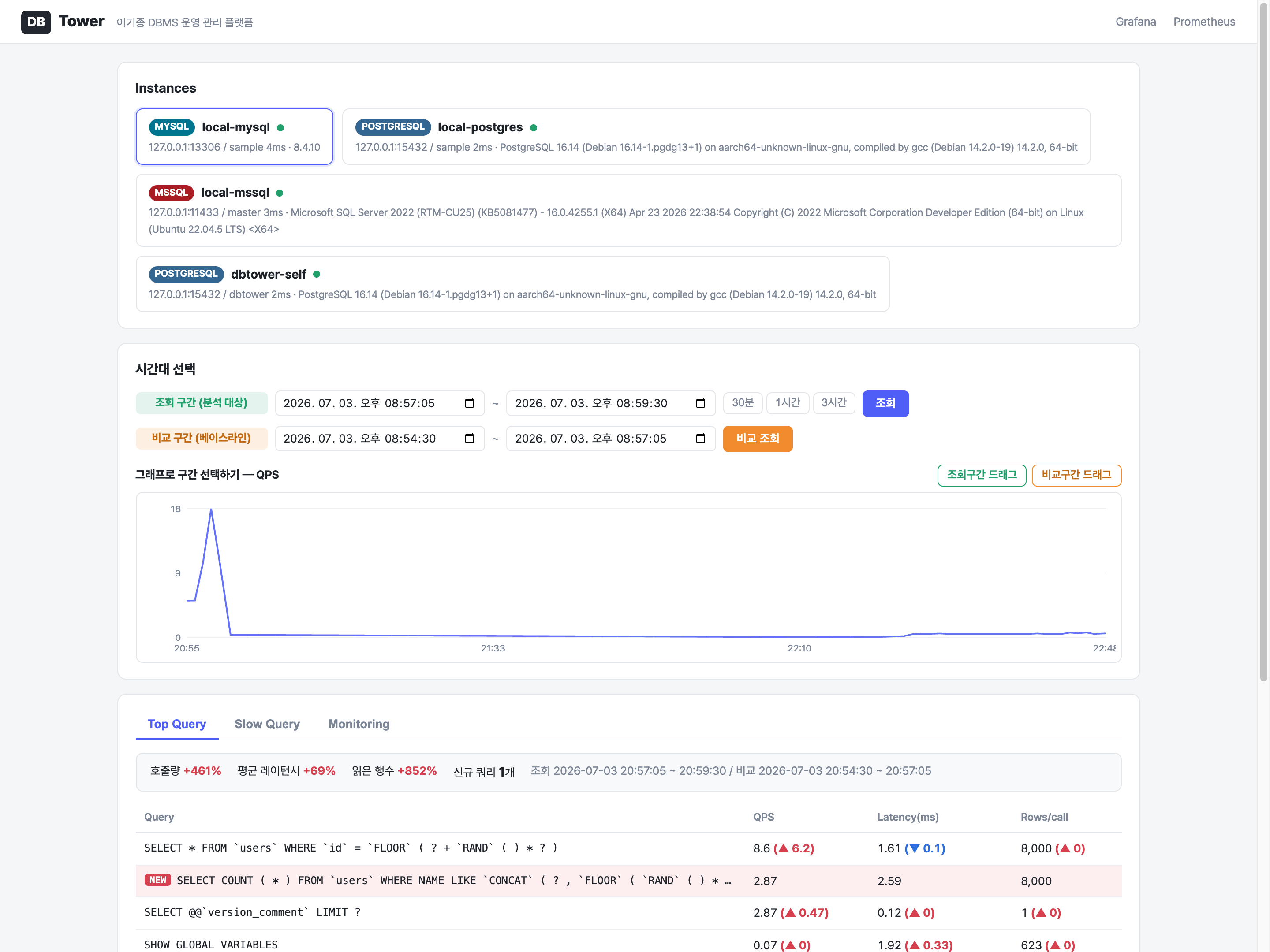
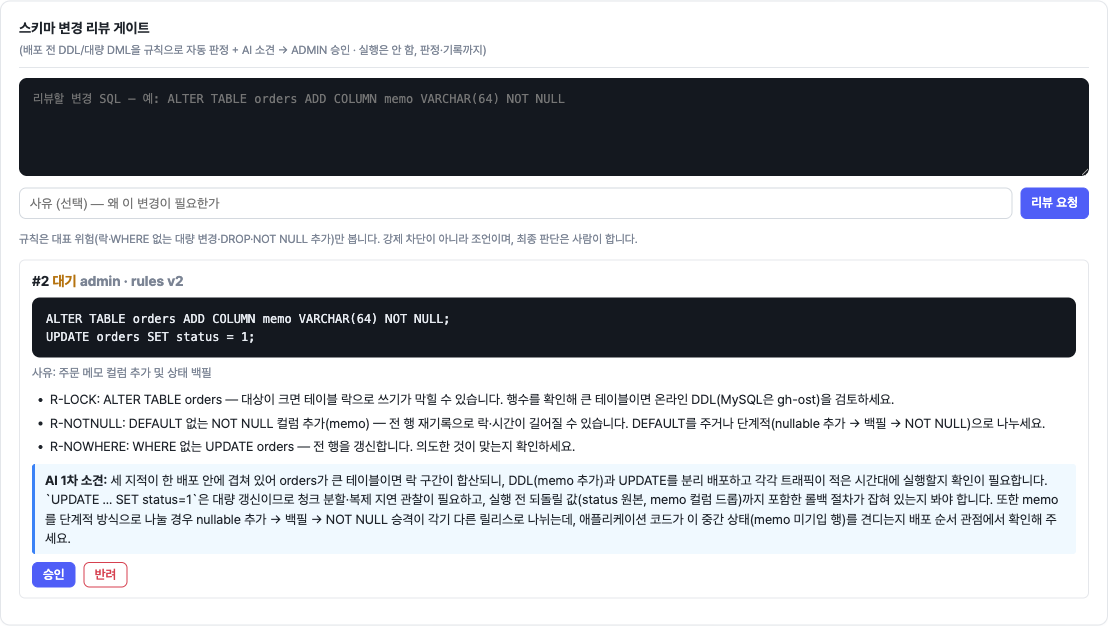
이기종 DBMS 운영 관리 플랫폼 DBTower 9편. 현업 DBA의 병목이 어디에 남는지를 렌즈로, 사람 손이 선형으로 붙던 다섯 지점을 기능으로 끊었습니다. (1) 설정 드리프트 이력: 파라미터 diff의 공간축("A와 B가 다른가")에 시간축("언제부터 무엇이 바뀌었나")을 붙였습니다. 거울 테이블과 변경 로그로 무변경 주기엔 스냅샷 한 줄만 쌓이게 했고, work_mem 4096→8192 실변경을 감지해 카드를 쐈습니다. 검증 중 MongoDB parameters()가 $clusterTime 같은 응답 gossip 필드를 흘려 매번 오탐이 나던 기존 버그도 잡았습니다. (2) 스키마 변경 리뷰 게이트: 배포 전 DDL을 규칙으로 판정(락 위험·DEFAULT 없는 NOT NULL·DROP·WHERE 없는 대량 변경)하고 실제 행수로 락 위험을 확정한 뒤 AI 1차 소견을 붙여 ADMIN 승인·자동 감사까지. 실행은 하지 않고 gh-ost 경로만 안내합니다. (3) 인덱스 사용 통계 주기 영속: "이 인덱스 지워도 되나"는 재시작 누적 카운터의 순간값으론 못 답합니다. 5기종 스캔 통계를 6시간 주기로 영속하고(Oracle은 미지원 정직), lakehouse가 first-vs-last 델타·리셋 클램프로 분기 창 판정 마트를 짓습니다. (4) 인시던트 리포트: 장애 구간을 주면 시점 비교·설정 변경·플랜 플립·대기·가용성을 한 장으로 재구성하고 AI가 재료 내 사실만으로 요약합니다. (5) 월간 점검 리포트: 헬스·백업·Advisor·용량·낭비·설정 변경을 매월 자동 발행합니다. 다섯 개 전부 읽고 판정·기록까지가 몫이고 대상 DB는 바꾸지 않습니다. 신규 모듈 하나(review)는 이벤트로 alert에 카드를 위임하고, 공개 파사드 둘(score·finops)로 Modulith 경계를 순환 없이 유지했습니다. 테스트 514건, VERIFICATION 110개 절.