빌려조잉 - 삼성 우수상, 그리고 팀원 이탈 속에서 배운 것들

목차
프로젝트 개요
빌려조잉은 물건을 서로 빌리고 빌려주는 C2C 공유 플랫폼입니다. 캠핑 텐트(30만원), 빔프로젝터(50만원)처럼 1~2번 쓰고 방치되는 물건을 이웃 간에 대여하면, 빌려주는 사람은 수익을, 빌리는 사람은 저렴한 비용을, 사회는 자원 낭비 감소를 얻습니다.
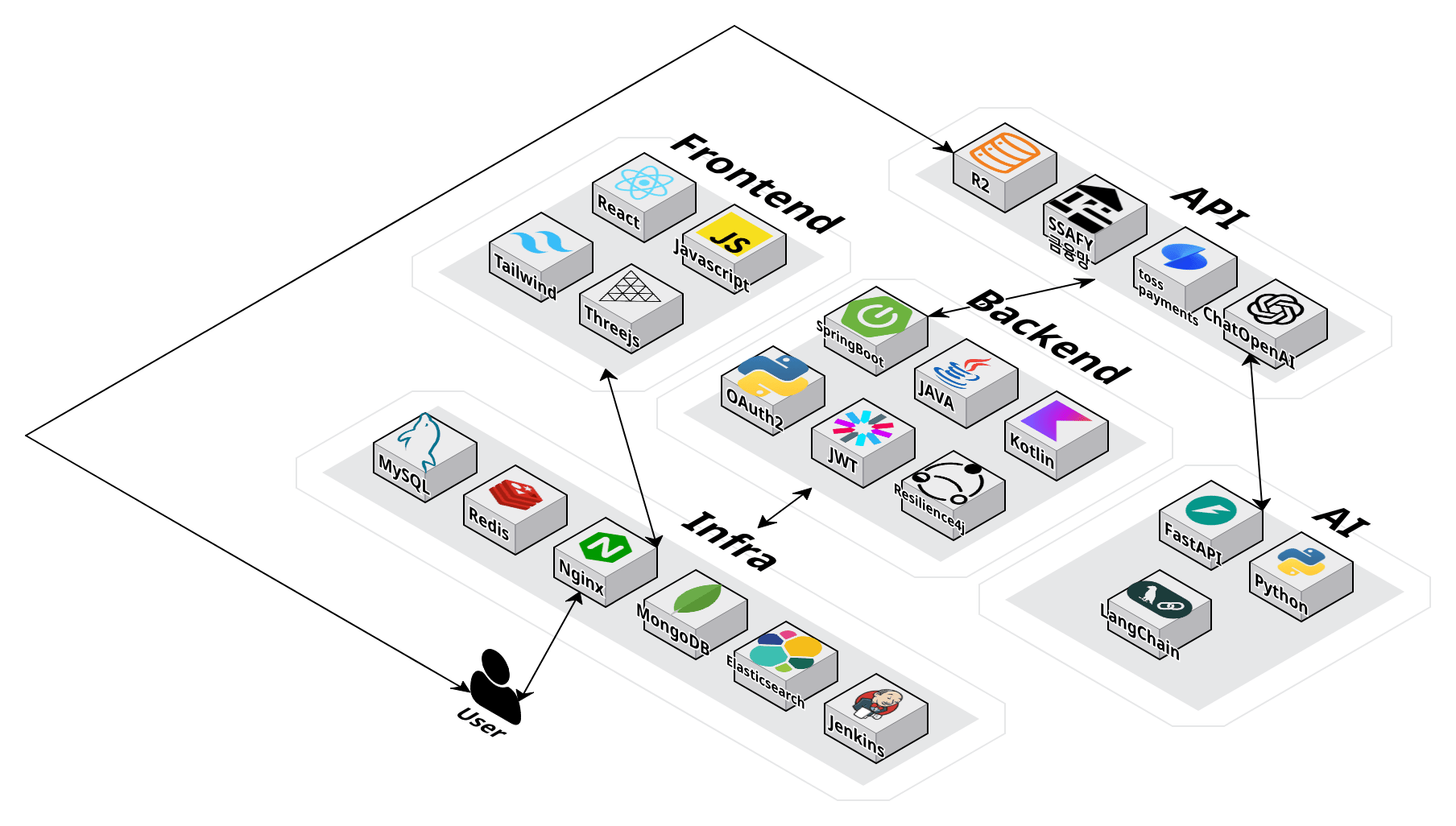
| 기간 | 2025.10.10 – 2025.11.20 (6주) |
| 팀 구성 | 6명 (프론트엔드 2명, 백엔드 4명) |
| 수상 | 삼성전자 주식회사 프로젝트 우수상 |
| 기술 스택 | Java, Kotlin, Spring Boot, WebSocket(STOMP), Redis Pub/Sub, MongoDB, MySQL |
| 인프라 | AWS EC2 t3.medium 1대 (2 vCPU / 4GB), Docker Compose |
내 역할
6명 팀(프론트엔드 2명, 백엔드 4명)의 리드를 맡았고, 백엔드(35%) + 프론트엔드(10%)를 담당했습니다. 회원 시스템(Spring Security + JWT)과 실시간 채팅 시스템 전체를 설계·구현했고, 마감 직전에는 프론트엔드 API 연동까지 직접 했습니다. 제가 직접 맡은 건 회원 인증과 실시간 채팅이고, 결제 에스크로는 담당자 이탈로 이어받았습니다. 상품·게시글 등 나머지 도메인은 다른 백엔드 팀원들이 맡았습니다.
리드로서 신경 쓴 건 두 가지였습니다. 하나는 새 기능을 시작할 때마다 “어떤 상태가 되면 완성인지”를 먼저 글로 적어 팀과 맞춰, 막판에 인수 기준이 어긋나 다시 짜는 일을 줄인 것. 다른 하나는 기술 결정을 혼자 통보하지 않고 후보의 부하 테스트·실측값을 함께 공유해 같은 기준 위에서 판단하게 한 것이었습니다. 이견이 생겨도 감정보다 근거로 풀자 팀원이 먼저 더 나은 방법을 제안하기도 했습니다. 이 프로젝트에서 가장 많이 성장한 부분은 제약 안에서의 트레이드오프 판단이었습니다. “더 좋은 기술”을 좇기보다 지금 우리 규모와 인프라에 맞는 구조를 고르는 일이었습니다.
시작 전에 정해둔 것들
기술 선택에 들어가기 전에, 우리가 감당해야 할 규모와 제약부터 수치로 못 박았습니다. 이 가정이 이후 거의 모든 결정의 기준이 됐습니다.
- 트래픽 가정: 동시 접속 50~100명, 채팅방당 메시지 1~3건/초, 피크 시 전체 초당 100~200건. 1:1 채팅이라 채팅방 참여자는 구매자/판매자 2명 고정.
- 인프라 제약: EC2 t3.medium 단일 서버(2 vCPU/4GB)에 Spring Boot·MySQL·MongoDB·Redis를 Docker Compose로 함께 운영. 새 인프라(Kafka 클러스터 등)를 띄울 여유가 거의 없음.
- 일정 제약: 6주. 검증되지 않은 기술을 새로 학습할 시간보다, 빠르게 동작시키고 측정으로 검증하는 편이 합리적.
설계 전에 그어둔 분기
요구사항을 정리한 뒤에는 기술 이름보다 구조의 분기점을 먼저 그었습니다. 이 세 갈래가 채팅 시스템 전체 방향을 결정했습니다.
- 메시지 브로커를 새 인프라로 도입할지(Kafka 등) vs 이미 쓰는 Redis로 해결할지
- 저장소를 단일 DB로 갈지 vs 데이터 성격별로 나눌지(Polyglot)
- 인증 토큰을 LocalStorage에 둘지 vs HttpOnly Cookie로 둘지
1. 메시징: 왜 Kafka 대신 Redis Pub/Sub을 택했나
상황. 채팅은 양방향 실시간 통신이 필요합니다. 폴링은 불필요한 요청이 너무 많고 SSE는 단방향이라 부적합해 WebSocket(STOMP)을 선택했습니다. 남은 문제는 “여러 서버로 확장했을 때 메시지를 어떻게 브로드캐스트할 것인가”였습니다.
대안 비교. 메시지 브로커 후보를 트래픽 규모 기준으로 비교했습니다.
| 후보 | 판단 |
|---|---|
| Kafka | Consumer Group 기반 재전송은 완벽하지만 클러스터 운영 부담이 큼. 현재 트래픽엔 오버 엔지니어링 |
| RabbitMQ | 1:1 채팅 규모엔 라우팅 기능이 과함 |
| Redis Stream | 용도가 이벤트 로그에 가까워 Pub/Sub 대비 이점 적음 |
| NATS | 새 인프라 도입 부담 |
| Redis Pub/Sub (채택) | 이미 캐시로 쓰는 인프라 재사용. 단일 인스턴스로 초당 수십만 건 처리 가능 |
결정 근거. 추정 피크가 초당 100~200건인데, Redis Pub/Sub은 단일 인스턴스에서 초당 수십만 건을 처리합니다. 현재 트래픽의 1,000배 이상 여유가 있었고, 이미 운영 중인 인프라를 재사용할 수 있었습니다. “더 강력한 도구”인 Kafka를 일부러 배제하고, 규모에 맞는 가장 단순한 선택을 했습니다.
보완: Redis Pub/Sub의 약점 메우기. Pub/Sub은 fire-and-forget이라 수신자가 없으면 메시지가 사라집니다. 그래서 모든 메시지를 MongoDB에 영속화하고, WebSocket 재연결 시 마지막 수신 시각 이후 메시지를 REST로 조회하는 폴백을 뒀습니다(추가 인프라 0, 재연결 지연 50~100ms로 체감 불가). 멀티 서버 환경의 메시지 순서는 클라이언트 클럭 차이를 배제하기 위해 서버 타임스탬프 기준으로 정렬했습니다.
상세 분석: Kafka는 우리에게 과했다 · WebSocket 메시지 유실 방지 · 메시지 순서 보장
2. Polyglot Persistence: 측정으로 결정했다
상황. “DB 3개는 관리가 힘들지 않냐”는 질문을 자주 받았습니다. 단일 DB로 갈 수 있다면 그게 더 단순합니다. 그래서 단일 DB가 정말 안 되는지부터 직접 측정했습니다.
측정. EC2 t3.medium에서 채팅 메시지 1,000건을 순차 Insert해 평균 소요시간을 측정했습니다.
| 저장소 | 메시지 Insert 평균 | 비고 |
|---|---|---|
| MySQL 8.0 (InnoDB, 인덱스 3개) | ~15ms | Row-level Lock으로 동시 전송 시 직렬화 병목 |
| MongoDB 6.0 (WiredTiger) | ~5ms | MySQL 대비 약 3배 빠름, JOIN 불가 |
단, 이 측정은 단일 서버·순차 1,000건 기준이라 동시성까지 반영한 정밀 벤치는 아니었습니다. 다만 차이가 반복 측정에서 안정적이라, 단순 삽입이 잦은 메시지 패턴엔 이 정도 근거로 충분하다고 판단했습니다.
결정: 데이터 성격에 맞춰 분리. 단일 DB로는 “메시지 쓰기 성능”과 “관계 조회”를 동시에 만족시킬 수 없었습니다. 그래서 각 데이터의 성격에 저장소를 맞췄습니다.
| 저장소 | 담당 | 이유 |
|---|---|---|
| MySQL | 채팅방·사용자·상품 관계 | 트랜잭션·조인 필요 |
| MongoDB | 채팅 메시지 | 쓰기 성능, 스키마 유연성 |
| Redis | Pub/Sub, 안읽은 메시지 수 캐싱 | 초저지연 조회 |
MySQL JSON 컬럼으로 절충하는 방법도 검토했지만, 파싱 오버헤드·인덱싱 한계 때문에 메시지 저장소로는 부적합하다고 판단했습니다.
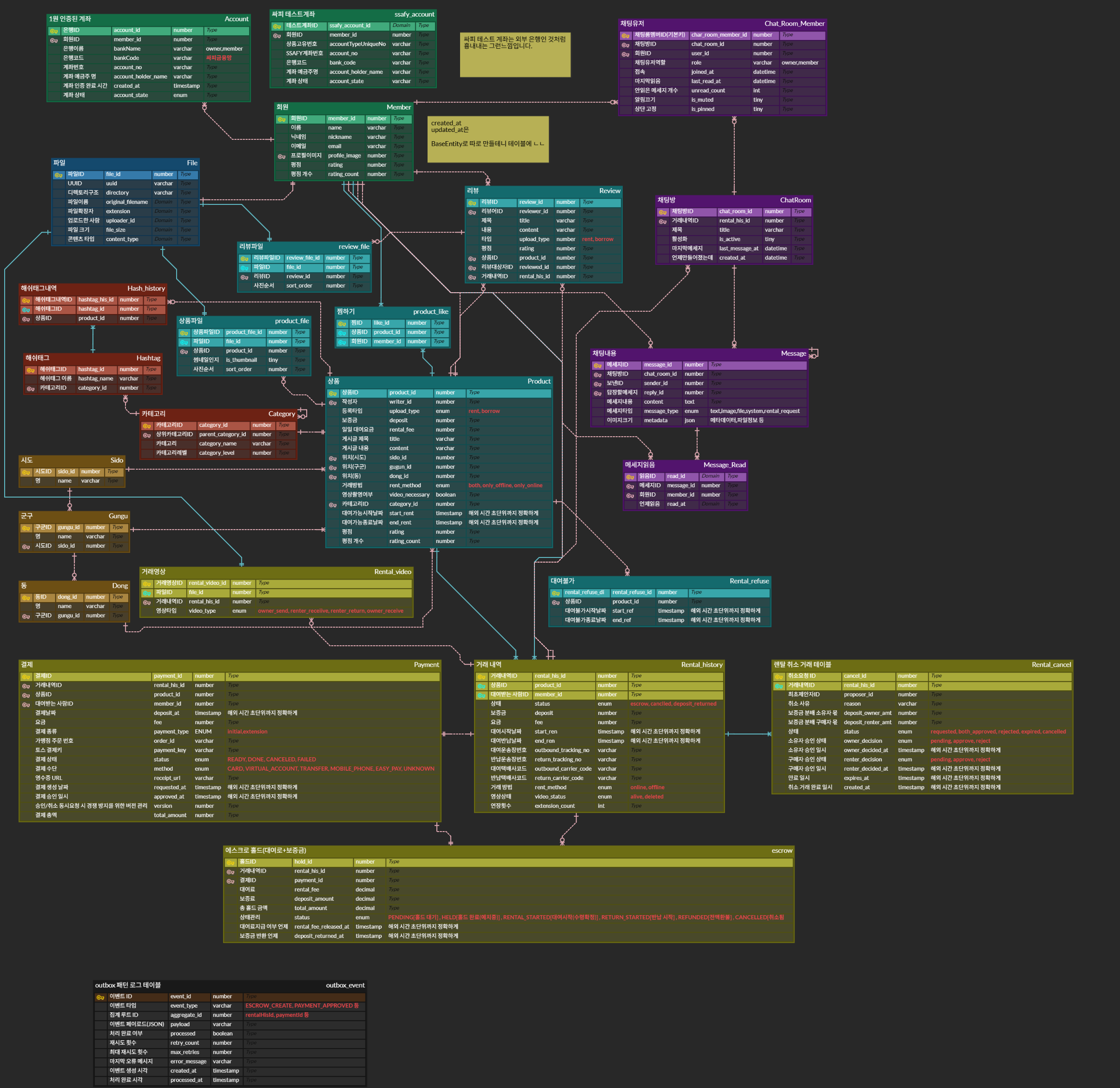
3. 읽기 경로 최적화: 채팅방 목록 1,350ms → 85ms (16배)
상황. 게시글 CRUD·로그인은 50ms 이내였는데, 채팅방 목록 조회만 유독 1.3초가 걸렸습니다.
원인. 채팅방 10개를 조회하는 데 51번의 쿼리가 발생했습니다. MySQL N+1에 더해 채팅방별 개별 Redis GET, 채팅방별 개별 MongoDB countDocuments가 겹친 결과였습니다.
사실 이 N+1은 초기 설계에서 제가 만든 문제였습니다. 빨리 만드는 데 집중하다 조회 경로를 안일하게 짠 결과라, 자랑이라기보다 제 설계를 바로잡은 과정에 가깝습니다.
해결(Action). 세 층위에서 동시에 줄였습니다.
- MySQL N+1 → Fetch Join으로 쿼리 3개
- 안읽은 수 개별 GET → Redis MGET으로 10개 키 일괄 조회
- 캐시 미스만 Coroutine
async로 MongoDB 병렬 조회(순차 500ms → 병렬 100ms)
결과(Result). 51쿼리 → 4쿼리, 1,350ms → 85ms(캐시 히트율 95% 기준, 약 16배). 최악의 경우(전체 캐시 미스)에도 185ms로 Before 대비 7배 빨랐습니다. 같은 맥락에서, 메시지마다 MySQL로 권한을 확인하던 경로도 Redis 권한 캐싱으로 옮겨 DB 부하를 줄였습니다.
상세 분석: 채팅방 목록 조회에 1.3초가 걸렸다 · 메시지마다 DB 조회하던 권한 체크 · Inbound Thread 최적화
4. 서버 확장 준비: SimpleBroker의 한계를 넘다
상황. Spring WebSocket 기본 SimpleBroker는 메모리 내 세션으로 동작해, 서버를 2대로 늘리면 A서버에 붙은 사용자와 B서버에 붙은 사용자가 서로 메시지를 받지 못합니다.
대안 비교. Sticky Session 유지 / RabbitMQ STOMP Broker / Redis 세션 관리를 비교했고, 이미 쓰는 인프라를 재사용하면서 어느 서버로 라우팅되든 동일하게 동작하는 Redis 기반 세션 관리(memberId 기준 전송)를 선택했습니다.
부수 개선. 확장 과정에서 두 가지를 함께 정리했습니다.
- 시간 타입: 서버·클라이언트 타임존 차이로 어긋나던
LocalDateTime을Instant로 마이그레이션 - 페이지네이션: Offset 페이징은 뒤로 갈수록 느려졌습니다(100번째 페이지 450ms). 커서 기반 페이지네이션으로 전환해 페이지 위치와 무관하게 12ms 고정.
상세 분석: 서버 여러 대로 확장하려면
5. 인증과 보안
JWT 저장은 HttpOnly Cookie. LocalStorage + Authorization 헤더 방식은 XSS로 토큰이 탈취될 위험이 있습니다. npm 공급망 공격처럼 제어할 수 없는 의존성을 통한 XSS는 완전히 막을 수 없으므로, “만약의 경우”를 대비한 방어층으로 HttpOnly Cookie를 택했습니다(네이버·구글·GitHub 등도 동일). 로컬 개발에서 SameSite 쿠키 정책으로 쿠키가 전송되지 않는 문제는 Vite 프록시로 동일 출처를 만들어 해결했습니다.
Redis 긴급 보안 대응: CVE-2025-49844 “RediShell”. 보안 뉴스에서 CVSS 9.9의 Redis RCE 취약점을 접했는데, 우리가 쓰던 Redis 7.0.15가 정확히 취약 버전이었습니다. 13년간 잠복했던 Lua 스크립팅의 use-after-free 결함으로, 인증된 사용자가 조작된 Lua 스크립트로 원격 코드 실행이 가능한 문제였습니다. 즉시 7.2.11로 업그레이드하고, 인증 활성화 + Lua/EVAL 명령어 비활성화 + Docker 네트워크 격리까지 다층 방어(defense-in-depth)를 적용했습니다.
사실 우리 Redis는 Docker 내부망에 격리돼 외부에서 직접 닿기는 어려웠습니다. 그래서 실제 위협이 컸다기보다, 취약 버전을 알고도 방치하지 않는다는 원칙으로 인증·EVAL 비활성화·격리를 함께 적용했습니다.
그 외 구현: AI 자동 게시글 생성 (LangChain)
판매자가 “대여료를 얼마로 정해야 할지 모르겠다”는 문제가 있었습니다. 이를 자동화하기 위해 4단계 파이프라인을 구현했습니다. GPT-4o Vision으로 이미지에서 물건 상태를 파악하고, 네이버 쇼핑 API로 시세를 조사한 뒤, 이를 결합해 적정 대여료와 게시글 초안을 자동 생성합니다.
6. 기억에 남는 트러블슈팅: Coroutine + JPA가 401을 뱉었다
가장 기억에 남는 삽질입니다. suspend fun에서 withContext(Dispatchers.IO)를 쓰면 스레드가 전환되는데, Hibernate Session은 ThreadLocal에 바인딩돼 있어 새 스레드에서는 Session을 찾지 못합니다. 여기까진 논리적으로 이해되는데, 문제는 이 LazyInitializationException이 Spring Security를 거치며 401 Unauthorized로 둔갑했다는 점이었습니다.
반나절 동안 JWT·Security 설정만 의심하다가, 결국 스택트레이스를 끝까지 뜯어 원인을 찾았습니다. runBlocking으로 스레드 전환을 막고 Fetch Join으로 필요한 데이터를 미리 로딩하는 이중 안전장치를 적용했습니다. 에러 메시지(401)와 실제 원인(Lazy Loading)이 완전히 다를 수 있다는 것을, 그래서 추측보다 스택트레이스를 끝까지 읽어야 한다는 것을 체감한 경험입니다.
상세 분석: Coroutine에서 JPA가 401을 뱉었다
7. 팀원 이탈, 그리고 대응
3주차에 에스크로 결제 담당자가 취업으로 팀을 떠났습니다. DB 스키마는 있었지만 서비스 로직은 판매 플로우만 구현된 상태였고, 남은 팀원 중 아무도 이어받으려 하지 않았습니다.
제가 직접 맡았습니다. 토스페이먼츠 에스크로 문서를 3일간 분석하고, 빌리는 사람 관점의 역방향 로직을 구현해 양방향 거래 플로우를 완성했습니다. 마감 1주일 전에는 10개 화면 중 7개가 API 연동 없이 하드코딩된 상태라는 걸 발견했고, Swagger로 API 문서를 자동 생성한 뒤 연동이 안 된 화면은 직접 React 코드를 수정해 배포 전날까지 모든 화면 연동을 끝냈습니다.
실패와 교훈
1. 추측보다 측정. “MongoDB가 쓰기에 빠르다”, “Kafka가 더 안정적이다” 같은 통념이 우리 상황에서도 맞는지 직접 측정(Insert ~5ms vs ~15ms)과 트래픽 추정(초당 100~200건)으로 검증했습니다. 측정 없이 도구를 고르면 오버 엔지니어링이나 병목 둘 중 하나로 빠지기 쉽습니다.
2. 더 강력한 도구 ≠ 더 나은 선택. Kafka·RabbitMQ를 의도적으로 배제하고 Redis Pub/Sub을 택한 것이 이 프로젝트에서 가장 잘한 판단 중 하나였습니다. 규모에 맞지 않는 인프라는 운영 부담만 키웁니다.
3. 6주 프로젝트의 한계는 솔직히 인정. 수치는 대부분 단일 서버·추정 트래픽 기반이며, 대규모 부하 테스트(k6 등)나 실제 멀티 인스턴스 운영까지는 가지 못했습니다. 멀티 서버 캐시 동기화, 장애 주입 테스트는 다음 과제로 남았습니다.
4. 기다리기보다 직접 움직이기. 담당자가 빠진 기능과 연동이 안 되는 화면은 기다린다고 해결되지 않습니다. 먼저 손을 들면 프로젝트가 진행됩니다. 백엔드 개발자가 프론트 코드를 만질 수 있으면 병목을 직접 해소할 수 있다는 것도 배웠습니다. 물론 이건 마감 위기에서의 임시 대응이지, 평소에 역할 경계를 흐리자는 뜻은 아닙니다.
핵심 수치
| 항목 | Before | After | 방법 |
|---|---|---|---|
| 채팅방 목록 조회 | 1,350ms (51쿼리) | 85ms (4쿼리, 16배) | Fetch Join + Redis MGET + Coroutine 병렬 |
| 페이지네이션(100p) | 450ms | 12ms | Offset → 커서 기반 |
| 메시지 Insert | MySQL ~15ms | MongoDB ~5ms (3배) | Polyglot Persistence |
| 메시징 여유 | — | 추정 트래픽의 1,000배+ | Redis Pub/Sub |
| Redis 보안 | 7.0.15 (CVSS 9.9 취약) | 7.2.11 + 다층 방어 | RediShell 긴급 패치 |
| 결과 | — | 삼성전자 프로젝트 우수상 | 위기 속 서비스 완성 |
마무리
빌려조잉에서 얻은 가장 큰 배움은 두 가지였습니다. 기술적으로는 제약을 먼저 수치로 정의하고, 통념 대신 측정으로 트레이드오프를 판단하는 법. 그리고 팀 관점에서는 위기 대응 능력이 기술적 완성도만큼이나 프로젝트 성패를 가른다는 것. 팀원 이탈이라는 위기 속에서도 서비스를 완성한 경험이 심사에서 좋게 평가받아 삼성 우수상으로 이어졌다고 생각합니다.
About the Project
Joying is a C2C sharing platform where people lend and borrow items from each other. Items like camping tents (300K KRW) or beam projectors (500K KRW) that sit unused after one or two uses — if neighbors could rent these out, lenders earn income, borrowers save money, and society reduces waste.
| Duration | Oct 10 – Nov 20, 2025 (6 weeks) |
| Team | 6 members (2 Frontend, 4 Backend) |
| Award | Samsung Electronics Project Excellence Award |
| Tech Stack | Java, Kotlin, Spring Boot, WebSocket(STOMP), Redis Pub/Sub, MongoDB, MySQL |
| Infrastructure | AWS EC2 t3.medium ×1 (2 vCPU / 4GB), Docker Compose |
My Role
I led a team of 6 (2 frontend, 4 backend) and owned backend (35%) + frontend (10%). I designed and built the entire member system (Spring Security + JWT) and real-time chat system, and handled frontend API integration directly in the final stretch. The parts I personally owned were member auth and real-time chat; I took over escrow payments after that developer left, while other backend teammates owned domains like products and listings.
As the lead, I focused on two things. First, before each new feature I wrote down what state counts as “done” and aligned the team on it, which cut last-minute rework from mismatched acceptance criteria. Second, rather than dictating technical decisions, I shared load-test and measured numbers for each candidate so we judged on the same basis — and resolving disagreements with evidence rather than emotion often led teammates to propose even better approaches. Where I grew most was making trade-off decisions within constraints — choosing not “the more powerful tech” but “the structure that fits our current scale and infrastructure.”
Decided Before We Started
Before picking any technology, we pinned down the scale and constraints we had to handle in concrete numbers. These assumptions became the basis for nearly every decision that followed.
- Traffic assumptions: 50–100 concurrent users, 1–3 messages/sec per chat room, peak 100–200 messages/sec overall. 1:1 chat, so each room has exactly 2 participants (buyer/seller).
- Infrastructure constraint: A single EC2 t3.medium (2 vCPU/4GB) running Spring Boot, MySQL, MongoDB, and Redis together via Docker Compose. Almost no room to stand up new infrastructure (e.g., a Kafka cluster).
- Schedule constraint: 6 weeks. Getting things working fast and validating by measurement beat learning unproven new tech.
Design Forks Drawn Upfront
After defining requirements, I drew the structural forks before tool names. These three branches determined the entire direction of the chat system.
- Introduce a broker as new infrastructure (Kafka, etc.) vs solve it with the Redis we already use
- Single DB vs split by data characteristics (Polyglot)
- Store the auth token in LocalStorage vs HttpOnly Cookie
1. Messaging — Why Redis Pub/Sub Instead of Kafka
Situation. Chat needs bidirectional real-time communication. Polling generates too many requests and SSE is unidirectional, so I chose WebSocket (STOMP). The remaining question: how to broadcast messages once we scale to multiple servers.
Alternatives.
| Candidate | Verdict |
|---|---|
| Kafka | Perfect replay via Consumer Groups, but heavy cluster ops. Overkill for our traffic |
| RabbitMQ | Routing features excessive for 1:1 chat |
| Redis Stream | More of an event log; little benefit over Pub/Sub here |
| NATS | Cost of adopting new infrastructure |
| Redis Pub/Sub (chosen) | Reuses infra we already run for caching; hundreds of thousands of msgs/sec on a single instance |
Rationale. Estimated peak is 100–200 msgs/sec, while Redis Pub/Sub handles hundreds of thousands/sec on one instance — over 1,000x headroom — and reuses existing infrastructure. I deliberately ruled out the “more powerful” Kafka and made the simplest choice that fit our scale.
Covering the weakness. Pub/Sub is fire-and-forget, so messages vanish if no subscriber is present. I persisted every message to MongoDB and added a REST fallback that fetches messages after the last received timestamp on WebSocket reconnect (zero extra infra, 50–100ms reconnect delay — imperceptible). To avoid client clock skew across servers, messages are ordered by server timestamp.
Detailed analysis: Kafka Was Overkill · WebSocket Message Loss Prevention · Message Ordering
2. Polyglot Persistence — Measurement, Not Assumption
Situation. People often asked “isn’t managing 3 DBs painful?” A single DB would be simpler — so I measured whether single-DB really couldn’t work.
Measurement. On EC2 t3.medium, I inserted 1,000 chat messages sequentially and measured the average.
| Store | Avg message Insert | Note |
|---|---|---|
| MySQL 8.0 (InnoDB, 3 indexes) | ~15ms | Row-level locks serialize concurrent sends |
| MongoDB 6.0 (WiredTiger) | ~5ms | ~3x faster than MySQL, no JOINs |
That said, this measurement was single-server and sequential (1,000 inserts), not a precise concurrent benchmark. Still, the gap held up across repeated runs, so for a write-heavy, simple-insert message pattern I judged it sufficient.
Decision — split by data character. A single DB couldn’t satisfy both “message write throughput” and “relational queries” at once, so I matched each store to its data.
| Store | Responsibility | Why |
|---|---|---|
| MySQL | Chat rooms, users, product relations | Transactions & joins |
| MongoDB | Chat messages | Write performance, schema flexibility |
| Redis | Pub/Sub, unread counts cache | Ultra-low-latency reads |
I considered MySQL JSON columns as a compromise but ruled them out for messages due to parsing overhead and indexing limits.
Detailed analysis: MySQL, MongoDB, Redis — Why Three?
3. Read-Path Optimization — Chatroom List 1,350ms → 85ms (16x)
Situation. Post CRUD and login responded within 50ms, but only the chatroom list took 1.3s.
Cause. Loading 10 rooms triggered 51 queries — MySQL N+1 + a per-room Redis GET + a per-room MongoDB countDocuments.
Honestly, this N+1 was a problem I created in the initial design — I rushed to ship and laid out the read path carelessly. So this isn’t really a brag; it’s me fixing my own design.
Action. Reduced it across three layers simultaneously:
- MySQL N+1 → Fetch Join (3 queries)
- Per-room unread GETs → Redis MGET (10 keys at once)
- Cache misses only → parallel MongoDB reads via Coroutine
async(sequential 500ms → parallel 100ms)
Result. 51 queries → 4, 1,350ms → 85ms (at 95% cache hit, ~16x). Even worst case (full cache miss) was 185ms — 7x faster than before. In the same vein, the per-message MySQL permission check moved to a Redis permission cache to cut DB load.
Detailed analysis: Chatroom List Took 1.3 Seconds · Per-Message DB Permission Check · Inbound Thread Optimization
4. Preparing to Scale — Beyond SimpleBroker
Situation. Spring WebSocket’s default SimpleBroker holds sessions in memory, so scaling to 2 servers means users on server A and server B can’t receive each other’s messages.
Alternatives. I compared keeping Sticky Sessions / a RabbitMQ STOMP broker / Redis-based session management, and chose Redis-based session management (routing by memberId) — reusing existing infra and behaving identically regardless of which server handles the request.
Side improvements. Two cleanups came along with scaling:
- Time type: migrated
LocalDateTime(which drifted across server/client timezones) toInstant. - Pagination: Offset paging slowed down deeper in (450ms at page 100). Cursor-based pagination made it a constant 12ms regardless of position.
Detailed analysis: Scaling to Multiple Servers
5. Authentication and Security
JWT storage — HttpOnly Cookie. LocalStorage + Authorization header risks token theft via XSS. Since XSS through uncontrollable dependencies (e.g., npm supply-chain attacks) can’t be fully prevented, I chose HttpOnly Cookie as a defense layer for the “just in case” (as Naver, Google, GitHub do). The local-dev issue where SameSite policy blocked the cookie was solved with a Vite proxy to create a same-origin context.
Redis emergency response — CVE-2025-49844 “RediShell”. I spotted a CVSS 9.9 Redis RCE in the security news, and our Redis 7.0.15 was exactly the vulnerable version. It’s a 13-year-old use-after-free in the Lua scripting engine that lets an authenticated user achieve remote code execution via a crafted Lua script. I immediately upgraded to 7.2.11 and applied defense-in-depth: auth enabled + Lua/EVAL disabled + Docker network isolation.
To be fair, our Redis was isolated on a Docker internal network, so it wasn’t directly reachable from outside. So this was less about a large real-world threat and more about a principle — not leaving a known-vulnerable version in place — which is why I layered auth, EVAL disabling, and isolation together.
Detailed analysis: Why Manage JWT in Cookies · “Redis Blew Up” — a 13-Year-Old Time Bomb
Other Implementation — AI Auto-Generated Listings (LangChain)
Sellers struggled to decide how much to charge for rentals. To automate this, I built a 4-stage pipeline: GPT-4o Vision assesses item condition from images, the Naver Shopping API checks market prices, and the two are combined to auto-generate an appropriate rental fee and a listing draft.
6. Most Memorable Debugging — Coroutine + JPA Threw a 401
My most memorable debugging session. Using withContext(Dispatchers.IO) in a suspend fun switches threads, but the Hibernate Session is bound to ThreadLocal — so the new thread can’t find it. That part makes sense; the twist was that this LazyInitializationException got disguised as a 401 Unauthorized through Spring Security.
I spent half a day suspecting JWT/Security config before reading the stack trace to the end and finding the real cause. I applied dual safeguards: runBlocking to prevent thread switching, and Fetch Join to eagerly load required data. It taught me that the error message (401) and the real cause (lazy loading) can be completely different — so read the stack trace to the end instead of guessing.
Detailed analysis: Coroutine Threw a JPA 401
7. Team Member Departures and How I Responded
In week 3, the escrow payment developer left for a job. The DB schema existed, but only the seller flow was implemented, and no one on the remaining team wanted to take it over.
I volunteered. I spent 3 days analyzing the TossPayments escrow docs, implemented the buyer-side reverse logic, and completed the bidirectional transaction flow. One week before the deadline, I found 7 of 10 screens still hardcoded with no API integration — so I auto-generated API docs with Swagger and directly modified the React code for the unconnected screens, finishing all integrations by the day before deployment.
Failures and Lessons
1. Measure, don’t assume. Instead of taking “MongoDB is faster for writes” or “Kafka is more reliable” at face value, I validated with direct measurement (Insert ~5ms vs ~15ms) and traffic estimates (100–200 msgs/sec). Choosing tools without measuring leads to either over-engineering or bottlenecks.
2. More powerful ≠ better. Deliberately ruling out Kafka/RabbitMQ for Redis Pub/Sub was one of the best calls of the project. Infra that doesn’t match your scale only adds operational burden.
3. Honestly acknowledging the limits of a 6-week project. Most numbers are single-server and based on estimated traffic; I didn’t reach large-scale load testing (e.g., k6) or real multi-instance operations. Multi-server cache consistency and fault-injection testing remain future work.
4. Act instead of waiting. A feature without an owner, screens without integration — waiting solves nothing. Raising your hand first moves the project forward. I also learned a backend dev who can touch frontend code can remove bottlenecks directly. Of course, this was an emergency response near the deadline, not an argument for routinely blurring role boundaries.
Key Numbers
| Item | Before | After | Method |
|---|---|---|---|
| Chatroom list | 1,350ms (51 queries) | 85ms (4 queries, 16x) | Fetch Join + Redis MGET + parallel Coroutine |
| Pagination (page 100) | 450ms | 12ms | Offset → cursor-based |
| Message Insert | MySQL ~15ms | MongoDB ~5ms (3x) | Polyglot Persistence |
| Messaging headroom | — | 1,000x+ estimated traffic | Redis Pub/Sub |
| Redis security | 7.0.15 (CVSS 9.9 vuln) | 7.2.11 + defense-in-depth | RediShell emergency patch |
| Outcome | — | Samsung Excellence Award | Shipped despite the crisis |
Closing
My two biggest takeaways from Joying: technically, define constraints in numbers first, then judge trade-offs by measurement instead of conventional wisdom; and from a team perspective, crisis-response ability determines a project’s outcome as much as technical quality. I believe shipping the service through the crisis of team departures is what earned the Samsung Excellence Award.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.