Inbound Thread를 빨리 반환하면 더 많은 요청을 받을 수 있다

목차
배경: Spring WebSocket STOMP의 구조
일반적인 WebSocket 라이브러리(Netty, Ktor 등)는 EventLoop 방식으로 동작해서 Thread Pool 설정이 필요 없습니다. 하지만 Spring WebSocket STOMP는 Inbound/Outbound Channel에 각각 Thread Pool을 사용하는 구조입니다.
Spring WebSocket STOMP 구조
- Inbound Thread Pool: 클라이언트 → 서버 메시지 처리
- Outbound Thread Pool: 서버 → 클라이언트 메시지 전송
이 글은 Spring WebSocket STOMP를 사용할 때 Thread Pool을 효율적으로 활용하는 방법을 다룹니다.
0. 정상 상태
서버 환경: EC2 t3.medium (2 vCPU, 4GB RAM), Spring Boot 3.x + WebSocket STOMP.
Inbound Thread Pool: Spring WebSocket STOMP의 clientInboundChannel 기본 corePoolSize는 Runtime.getRuntime().availableProcessors() * 2 = 4개 (t3.medium 2 vCPU 기준). 이 4개의 스레드가 모든 클라이언트의 메시지 전송을 처리한다.
동시 접속: 테스트 환경 기준 20명, 채팅방 50개. 피크 시 초당 10-20건의 메시지 전송.
성능 기대치: 채팅 메시지 전송은 사용자가 즉시 전달되었다고 느껴야 한다. Inbound Thread가 블로킹되면 다른 사용자의 메시지 처리가 밀리면서 체감 지연이 발생한다.
1. 문제: Thread가 I/O 대기 중에 멈춘다
Spring WebSocket STOMP Handler는 기본적으로 동기 방식입니다.
메시지 한 건을 처리할 때 Inbound Thread가 뭘 하는지 뜯어봤습니다.
메시지 1건당 Inbound Thread가 거치는 블로킹 I/O
- MongoDB 영속화: 네트워크 왕복 후 쓰기 완료까지 대기
- Redis Pub/Sub 발행: 네트워크 왕복
- 안읽음 카운터 증가: 네트워크 왕복
정작 CPU가 일하는 시간은 파싱·DTO 변환 정도로 극히 짧고, 나머지는 전부 I/O 응답을 기다리며 스레드를 붙잡고 있는 시간입니다.
문제의 핵심은 평균 속도가 아니라 결합(coupling)입니다. 동기 구조에서 Inbound Pool의 처리 능력은
스레드 수 ÷ 메시지당 I/O 시간에 묶입니다. 평소에는 I/O가 밀리초 단위라 티가 안 나지만, MongoDB가 디스크 flush·락 경합·일시 지연으로 한 번 튀는 순간(tail latency) 스레드 4개가 전부 그 지연에 같이 잡히고, 다른 모든 사용자의 메시지 수신이 함께 멈춥니다.
Blocking I/O의 본질
MongoDB 저장 과정을 자세히 보면:
MongoDB 저장 한 번의 내부
- 네트워크 패킷 전송 ← CPU 사용 (마이크로초 단위)
- MongoDB 서버 처리·응답 대기 ← CPU 안 씀 (소요 시간의 대부분)
- 네트워크 응답 수신 ← CPU 사용 (마이크로초 단위)
소요 시간의 대부분은 CPU가 노는 ‘대기’다
운영체제 관점에서 보면:
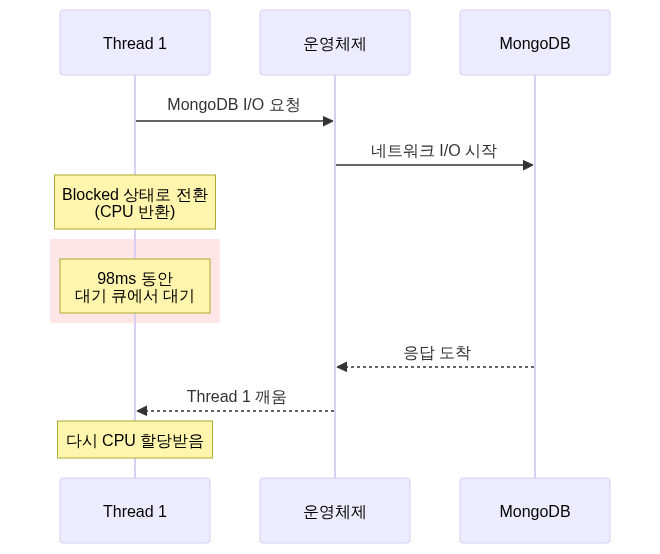
Thread 1은 대기하는 동안 아무 일도 안 하지만 Thread Pool의 자리를 차지합니다. 다른 메시지는 Thread 1이 돌아올 때까지 기다려야 합니다.
비동기 처리 방법 검토
Blocking I/O 문제를 해결하기 위한 방법을 검토했습니다.
1. Spring @Async

별도 Thread Pool을 만들어서 작업을 위임합니다. Inbound Thread는 즉시 반환되지만, I/O 대기 중인 Thread가 @Async Thread Pool로 이동했을 뿐 전체 시스템에서 블로킹되는 Thread 수는 동일합니다. Thread Pool 크기를 N으로 설정하면 동시에 N개까지만 처리 가능하고, 초과 요청은 큐에서 대기한다. Thread 수만 늘어나고 근본적인 해결이 안 됩니다. Coroutine과의 차이: Coroutine은 I/O 대기 중 Thread를 반환하고, I/O 완료 시 다시 Thread를 할당받는 구조라 같은 Thread 수로 더 많은 동시 요청을 처리할 수 있다.
2. Project Reactor (Reactive Programming)

완전한 Non-blocking을 구현할 수 있지만, 기존 JPA, JDBC 코드를 전부 Reactive로 바꿔야 합니다. 6주 프로젝트에서 전체 스택을 바꾸기엔 리스크가 컸습니다.
3. Virtual Threads (Java 21)

JVM이 관리하는 경량 스레드로 수백만 개 생성 가능합니다. 가장 깔끔한 해결책이지만, 당시 프로젝트가 Java 17 기반이었습니다. Java 21 업그레이드는 Spring Boot 버전 변경과 의존성 충돌 위험이 따랐습니다.
4. Kotlin Coroutine (선택)

우리 프로젝트가 이미 Kotlin 기반이었기 때문에 suspend만 붙이면 기존 코드와 자연스럽게 통합됩니다. JPA, JDBC를 그대로 쓸 수 있고, Reactor보다 학습 곡선이 완만합니다. 다만 JPA Lazy Loading과 충돌할 수 있다는 점은 인지하고 있었습니다(이 문제는 별도 글에서 다룹니다).
Coroutine 적용
Coroutine을 사용하면 Thread를 즉시 반환할 수 있습니다.

Thread 점유 시간 비교
Before (Blocking)
- Inbound Thread 점유: I/O가 끝날 때까지 이어짐(MongoDB 지연이 튀면 그대로 같이 묶임)
After (Coroutine)
- Inbound Thread 점유: 코루틴 디스패치까지만(즉시 반환)
- I/O 작업은 Dispatchers.IO 스레드 풀에서 별도 처리
Java CompletableFuture로도 동일하게 가능하다
사실 Java CompletableFuture로도 같은 효과를 낼 수 있습니다.
Java 버전

Kotlin Coroutine 버전

둘 다 동일한 효과입니다. Inbound Thread를 빨리 반환하고, I/O 작업은 별도 스레드 풀에서 처리합니다.
왜 Coroutine을 선택했나
Java CompletableFuture로도 가능한데 Coroutine을 선택한 이유:
- 채팅 파트는 내가 맡은 영역 - 기술 선택의 자유가 있었습니다
- 프로젝트가 이미 Kotlin 기반 - 별도 설정 없이 바로 적용 가능했습니다
- 코드 가독성 -
launch { }블록이 CompletableFuture 체이닝보다 직관적
주의: 진짜 Non-blocking은 아니다
현재 구현
- Inbound Thread: 즉시 반환
- Dispatchers.IO Thread: I/O가 끝날 때까지 blocking. 대기가 사라지지 않고 자리만 옮긴 것
진짜 Non-blocking이 되려면
- Reactive MongoDB Driver 필요
- suspend 함수 + awaitSingle() 조합
현재 구현은 Inbound Thread Pool의 처리량을 높이는 것이 목적입니다. 전체 시스템이 Non-blocking이 된 건 아닙니다.
실제 구현
ChatMessageService

WebSocket Controller

결과
이 전환은 수치로 잰 개선이 아니라 구조가 바뀐 것이라, 비교도 구조로 정리하는 게 정확합니다.
| 관점 | Before (동기) | After (Coroutine) |
|---|---|---|
| Inbound Thread 점유 | I/O 완료까지 대기 | 디스패치 후 즉시 반환 |
| 처리량 상한 | 스레드 수 ÷ 메시지당 I/O 시간에 종속 | I/O 지연과 분리 (CPU 바운드만 남음) |
| MongoDB 지연 스파이크 | 전체 메시지 수신 정체로 전파 | Dispatchers.IO 안에 격리 |
| 실제 병목 지점 | Inbound Thread Pool | MongoDB/Redis I/O 대역폭 |
I/O 작업(MongoDB 저장, Redis 발행)의 총 소요 시간 자체는 그대로다. 하지만 이 작업을 Coroutine이 별도 I/O 스레드에서 비동기로 처리하므로, Inbound Thread는 즉시 반환되어 다음 메시지를 받을 수 있다. 병목이 “Thread Pool 크기”에서 “I/O 대역폭”으로 이동한 것이 핵심.
솔직한 한계도 남겨둡니다. 당시 테스트 규모(20명 동시 접속, 초당 10~20건)에서는 동기 구조로도 충분히 버틸 수 있었습니다. 이 전환의 가치는 그 시점의 처리량 숫자가 아니라, I/O 지연 스파이크가 메시지 수신 경로 전체를 멈추지 못하게 만든 구조에 있습니다.
Background: Spring WebSocket STOMP Architecture
Typical WebSocket libraries (Netty, Ktor, etc.) use an EventLoop model that doesn’t require Thread Pool configuration. However, Spring WebSocket STOMP uses separate Thread Pools for Inbound/Outbound Channels.
Spring WebSocket STOMP Structure
- Inbound Thread Pool: Handles client → server messages
- Outbound Thread Pool: Handles server → client messages
This post covers how to efficiently utilize Thread Pools when using Spring WebSocket STOMP.
0. Normal State
Server environment: EC2 t3.medium (2 vCPU, 4GB RAM), Spring Boot 3.x + WebSocket STOMP.
Inbound Thread Pool: Spring WebSocket STOMP’s clientInboundChannel default corePoolSize is Runtime.getRuntime().availableProcessors() * 2 = 4 threads (t3.medium, 2 vCPU). These 4 threads handle all client messages.
Concurrent users: 20 in test, 50 chatrooms. Peak: 10-20 msgs/sec.
Performance expectation: Chat messages should feel instant. When Inbound Threads block, other users’ messages queue up, causing perceived delay.
1. Problem: Threads Stall During I/O Waits
Spring WebSocket STOMP Handlers operate synchronously by default.
Breaking down what an Inbound Thread does per message:
Blocking I/O per message on the Inbound Thread
- MongoDB persistence — network round-trip + write completion wait
- Redis Pub/Sub publish — network round-trip
- Unread counter increment — network round-trip
Actual CPU work (parsing, DTO mapping) is tiny; the rest is holding the thread while waiting for I/O responses.
The real issue is coupling, not average speed. In a synchronous design, the Inbound Pool’s capacity is bound to
thread count ÷ per-message I/O time. Normally I/O takes mere milliseconds — but the moment MongoDB spikes (disk flush, lock contention, transient slowdowns — tail latency), all four threads get stuck on that spike, and every user’s message intake stalls together.
The Nature of Blocking I/O
Looking at the MongoDB save process in detail:
Inside a single MongoDB save
- Network packet send - CPU active (microseconds)
- MongoDB server processing/response wait - CPU idle (the vast majority of the time)
- Network response receive - CPU active (microseconds)
Most of the elapsed time is the CPU idling in ‘wait’.
From the OS perspective:
Thread 1 does nothing while waiting but still occupies a slot in the Thread Pool. Other messages must wait until Thread 1 returns.
Evaluating Async Processing Options
Four approaches were evaluated to solve the blocking I/O problem.
1. Spring @Async
Delegates work to a separate Thread Pool. However, threads are still blocked during I/O waits. It just increases the number of threads without fundamentally solving the problem.
2. Project Reactor (Reactive Programming)
Achieves true Non-blocking, but requires rewriting all JPA/JDBC code to Reactive. Too risky for a 6-week project.
3. Virtual Threads (Java 21)
Lightweight JVM-managed threads that can scale to millions. The cleanest solution, but our project was on Java 17. Upgrading to Java 21 risked Spring Boot version changes and dependency conflicts.
4. Kotlin Coroutine (Chosen)
Since our project was already Kotlin-based, adding suspend integrates naturally with existing code. JPA and JDBC can be used as-is, and the learning curve is gentler than Reactor. The potential conflict with JPA Lazy Loading was noted (covered in a separate post).
Applying Coroutines
With Coroutines, threads can be returned immediately.
Thread Occupancy Comparison
Before (Blocking)
- Inbound Thread occupancy: until I/O completes — a MongoDB latency spike drags the thread with it
After (Coroutine)
- Inbound Thread occupancy: only until coroutine dispatch — returned immediately
- I/O work handled separately in Dispatchers.IO thread pool
Java CompletableFuture Achieves the Same Effect
Java CompletableFuture can produce the same result.
Java Version
Kotlin Coroutine Version
Both achieve the same effect. The Inbound Thread is returned quickly, and I/O work is processed in a separate thread pool.
Why Coroutine Was Chosen
Reasons for choosing Coroutine over Java CompletableFuture:
- I owned the chat module - Freedom in technology choices
- Project was already Kotlin-based - No additional setup required
- Code readability -
launch { }blocks are more intuitive than CompletableFuture chaining
Caveat: This Is Not True Non-blocking
Current Implementation
- Inbound Thread: Returned immediately
- Dispatchers.IO Thread: Blocked until I/O completes — the waiting didn’t disappear, it moved
For True Non-blocking
- Reactive MongoDB Driver required
- suspend functions + awaitSingle() combination
The current implementation aims to increase Inbound Thread Pool throughput. The entire system has not become Non-blocking.
Actual Implementation
ChatMessageService
WebSocket Controller
Results
This change is a structural improvement rather than a measured one, so the comparison is best expressed structurally.
| Aspect | Before (Sync) | After (Coroutine) |
|---|---|---|
| Inbound Thread occupancy | Held until I/O completes | Returned right after dispatch |
| Throughput ceiling | Bound to thread count ÷ per-message I/O time | Decoupled from I/O latency (CPU-bound only) |
| MongoDB latency spike | Propagates into a stall of all message intake | Isolated inside Dispatchers.IO |
| Actual bottleneck | Inbound Thread Pool | MongoDB/Redis I/O bandwidth |
Total I/O time (MongoDB save, Redis publish) stays the same. But Coroutines handle it asynchronously on separate I/O threads, so Inbound Threads are immediately returned for the next message. The bottleneck shifted from “Thread Pool size” to “I/O bandwidth.”
An honest caveat: at our test scale (20 concurrent users, 10–20 msgs/sec), the synchronous design would have held up fine. The value of this change is not a throughput number at that point in time, but a structure where I/O latency spikes can no longer stall the entire message intake path.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.