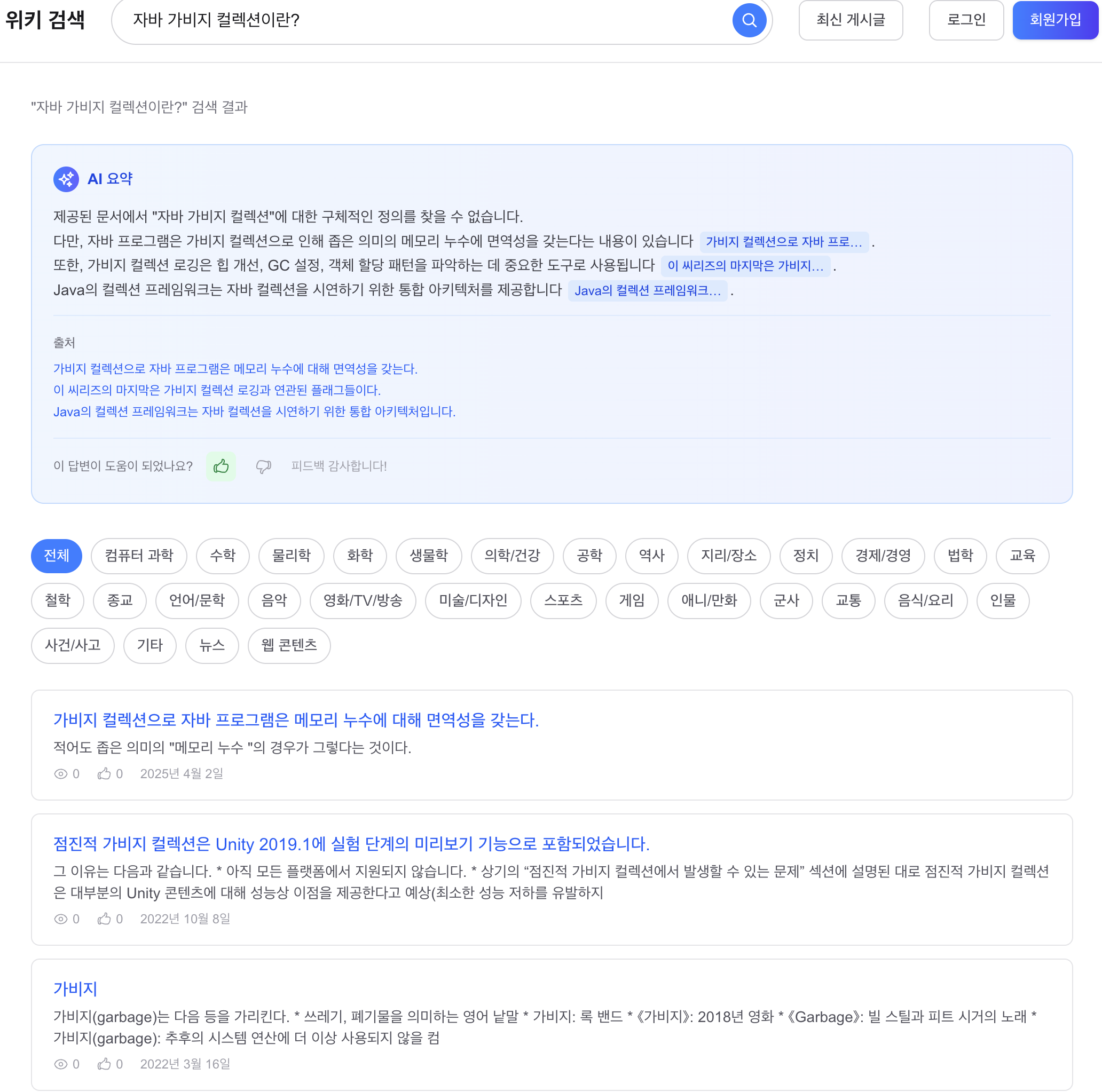
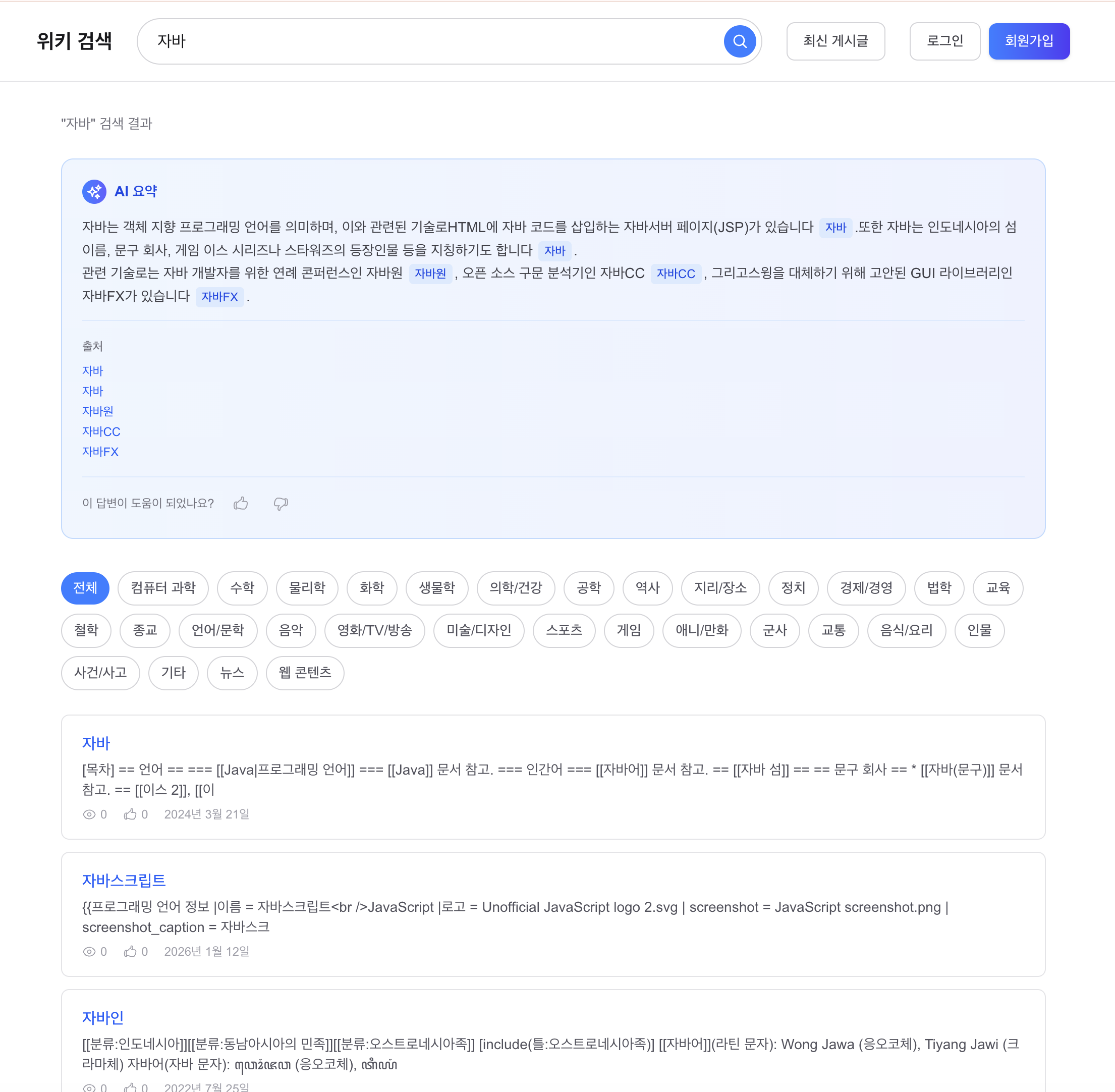
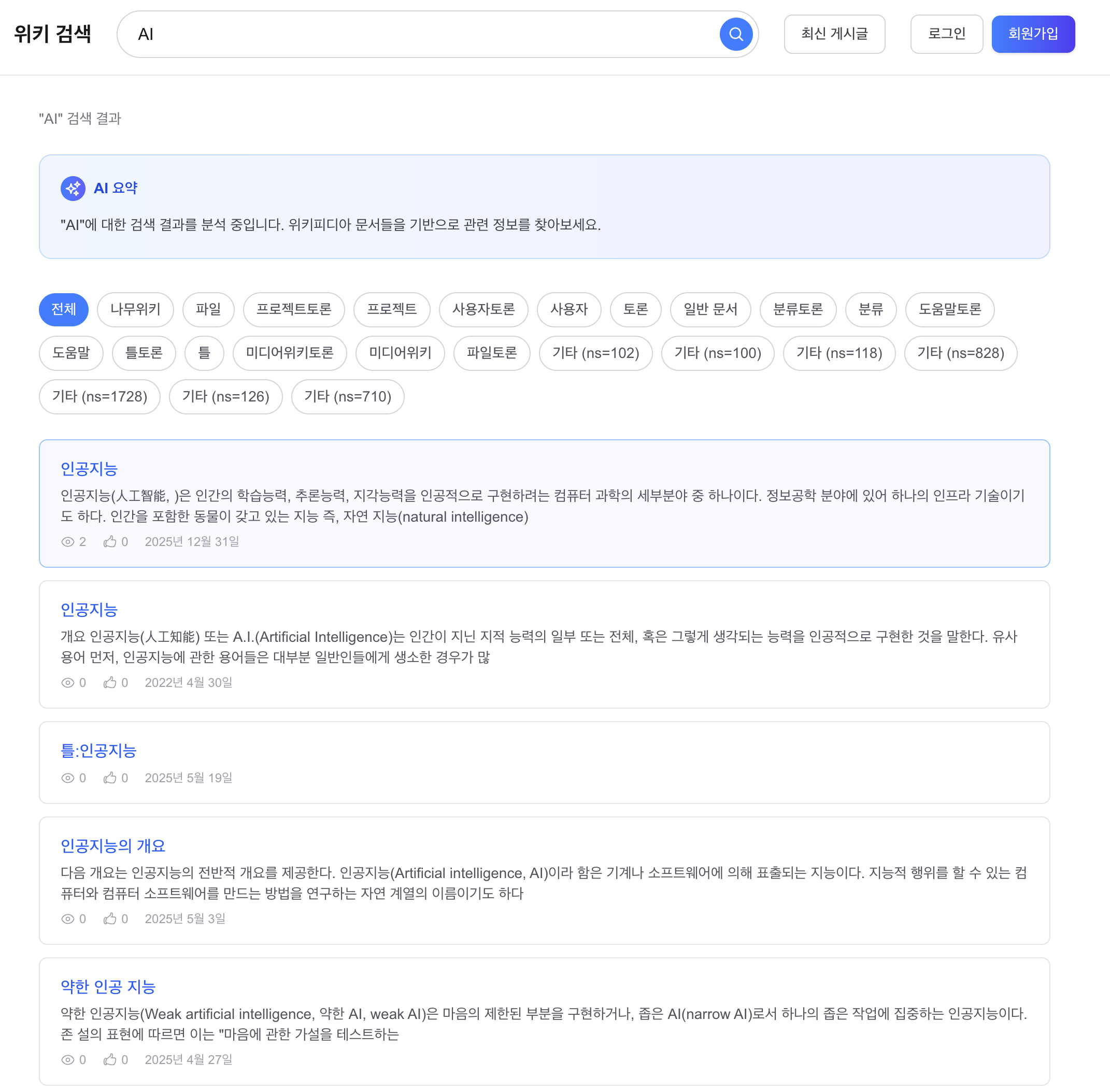
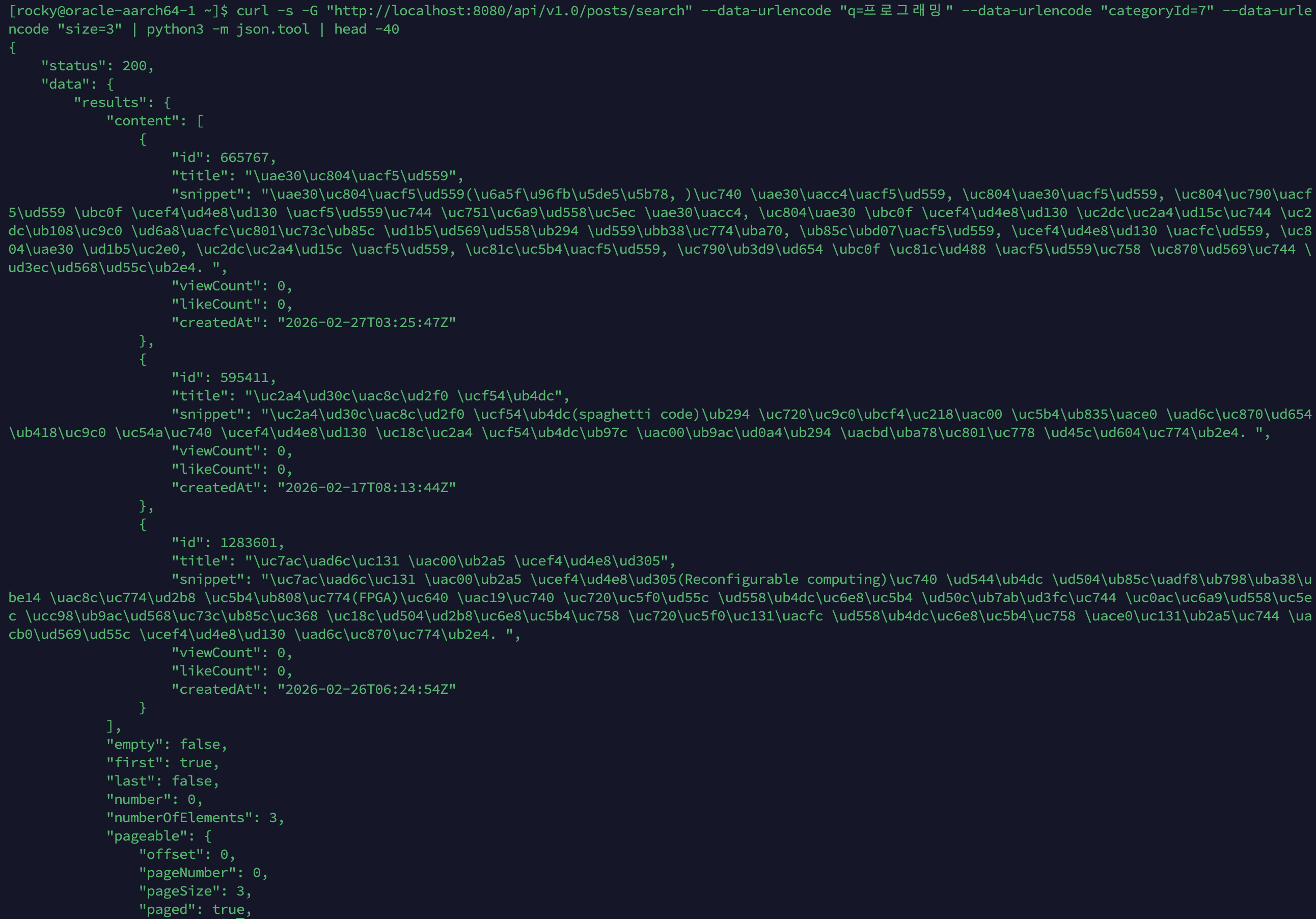
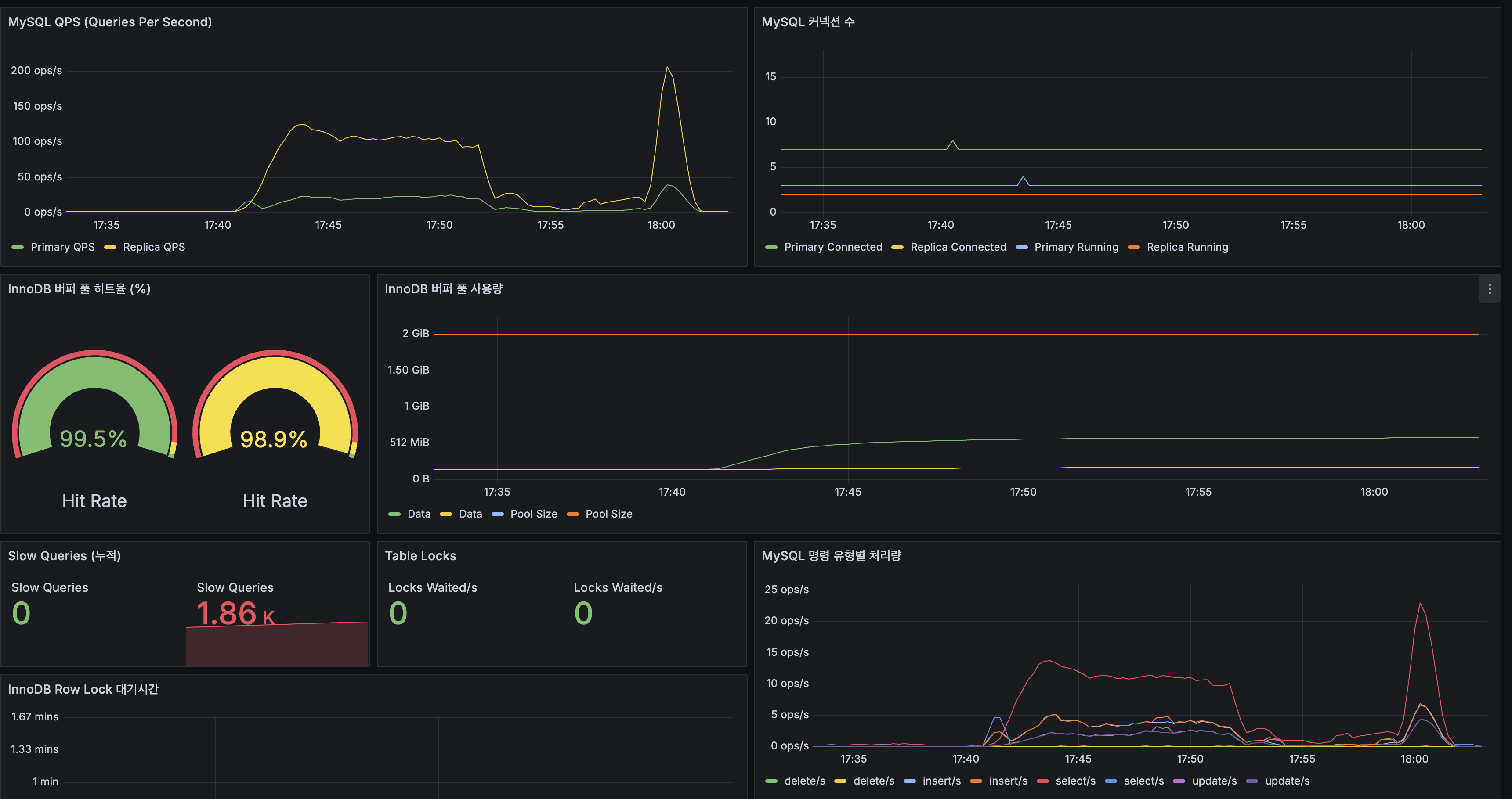
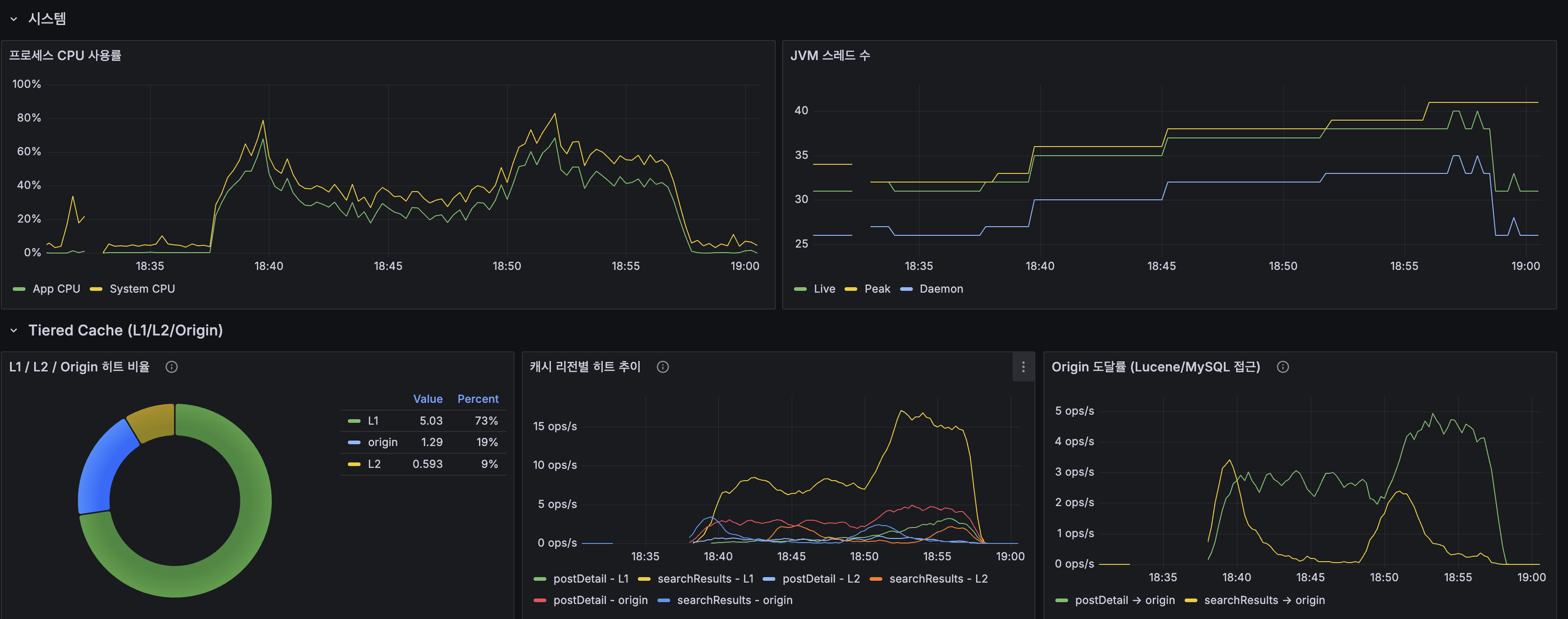
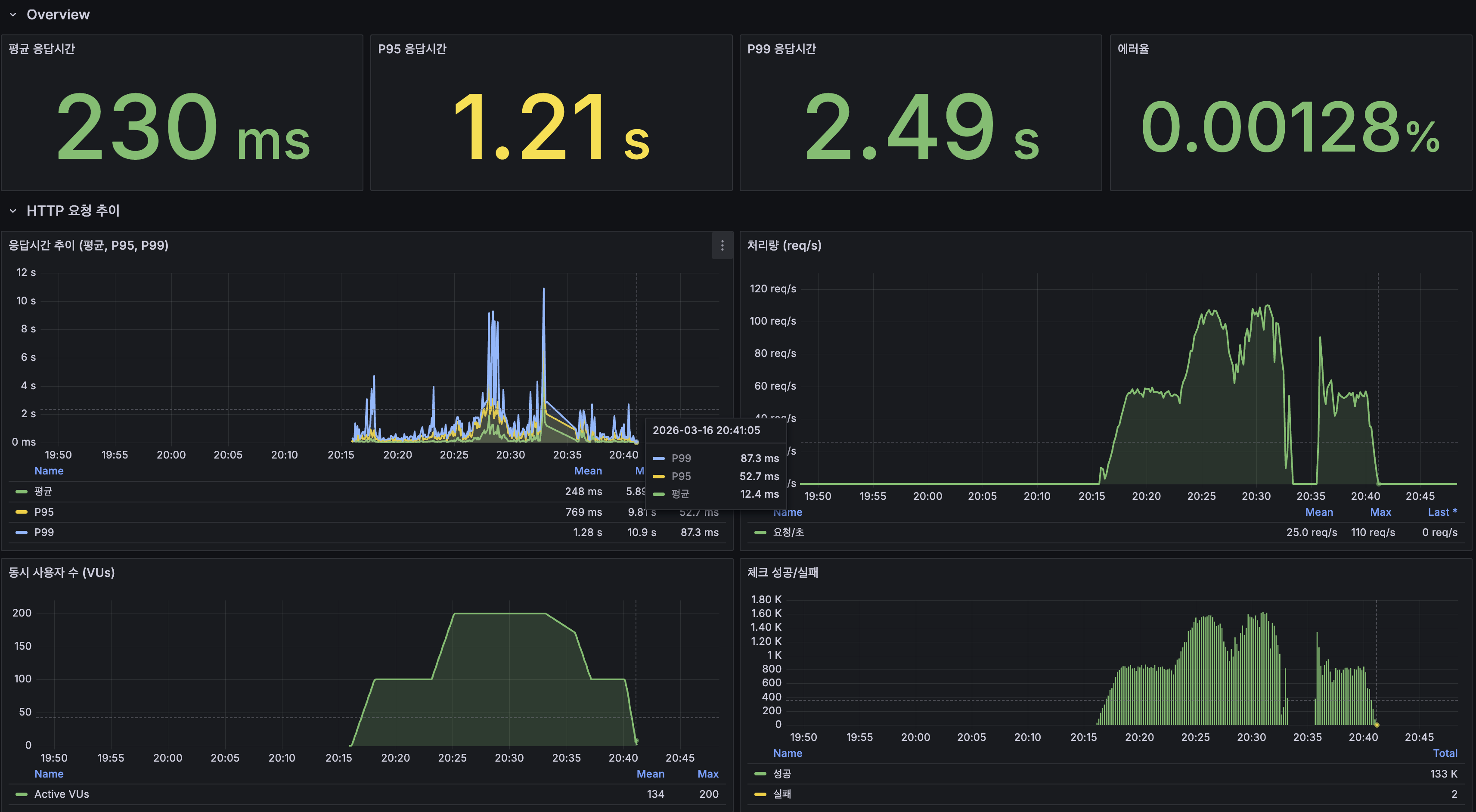
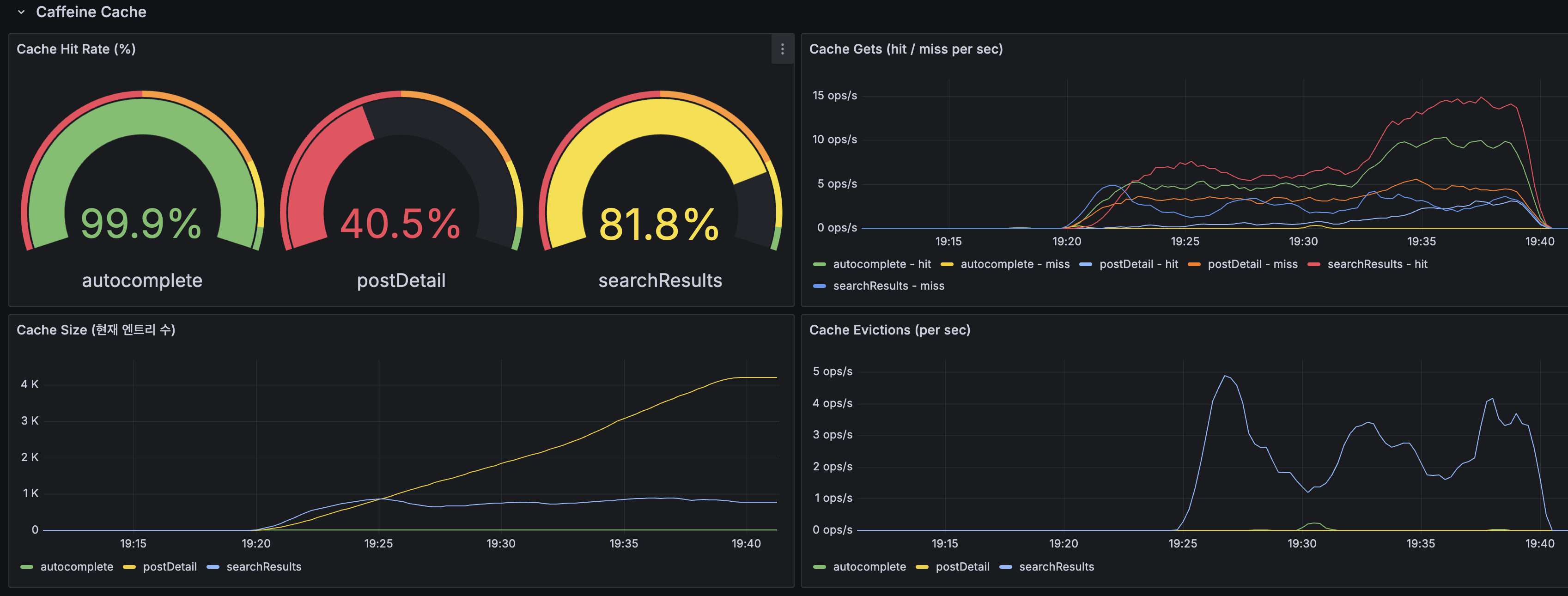
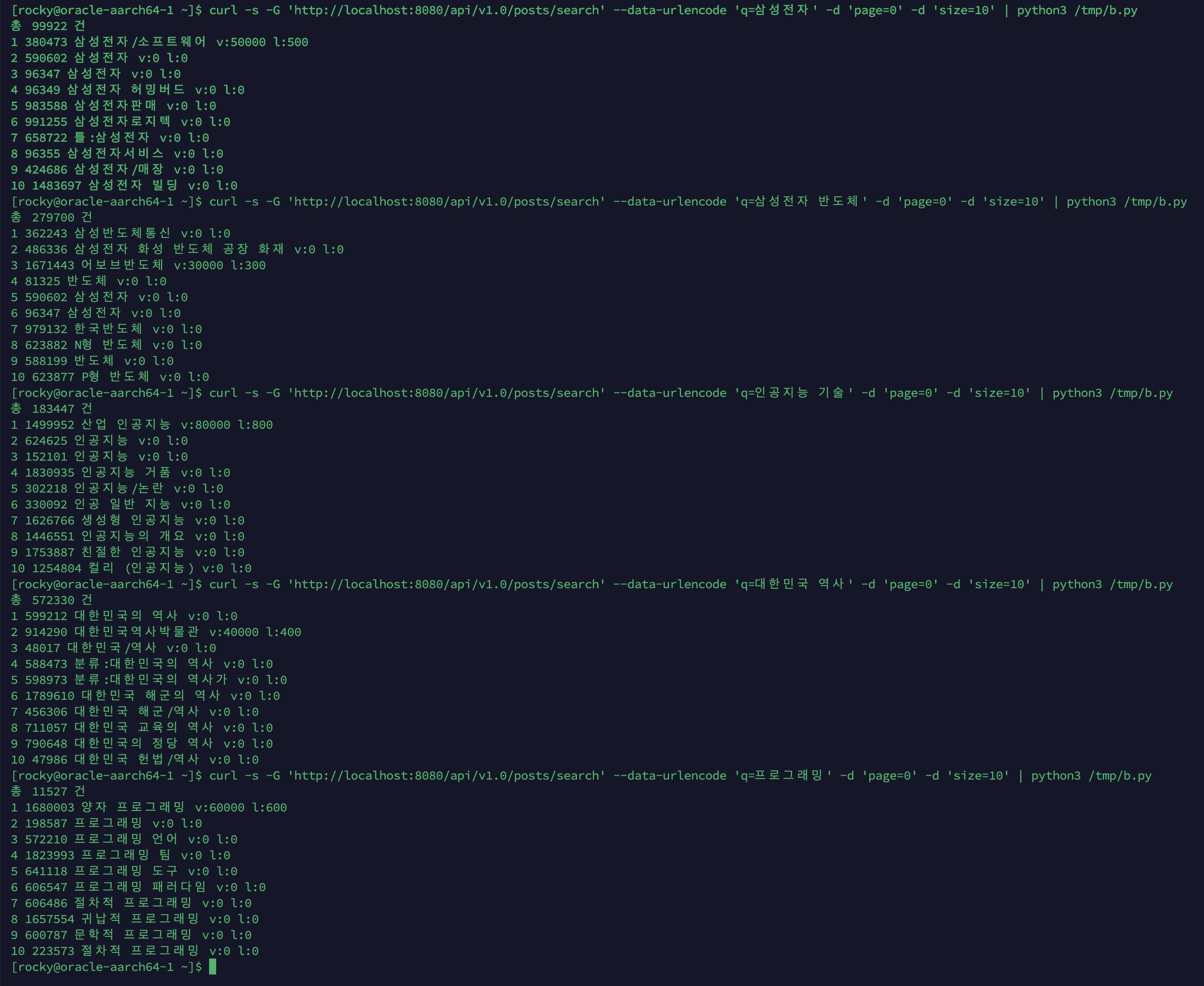
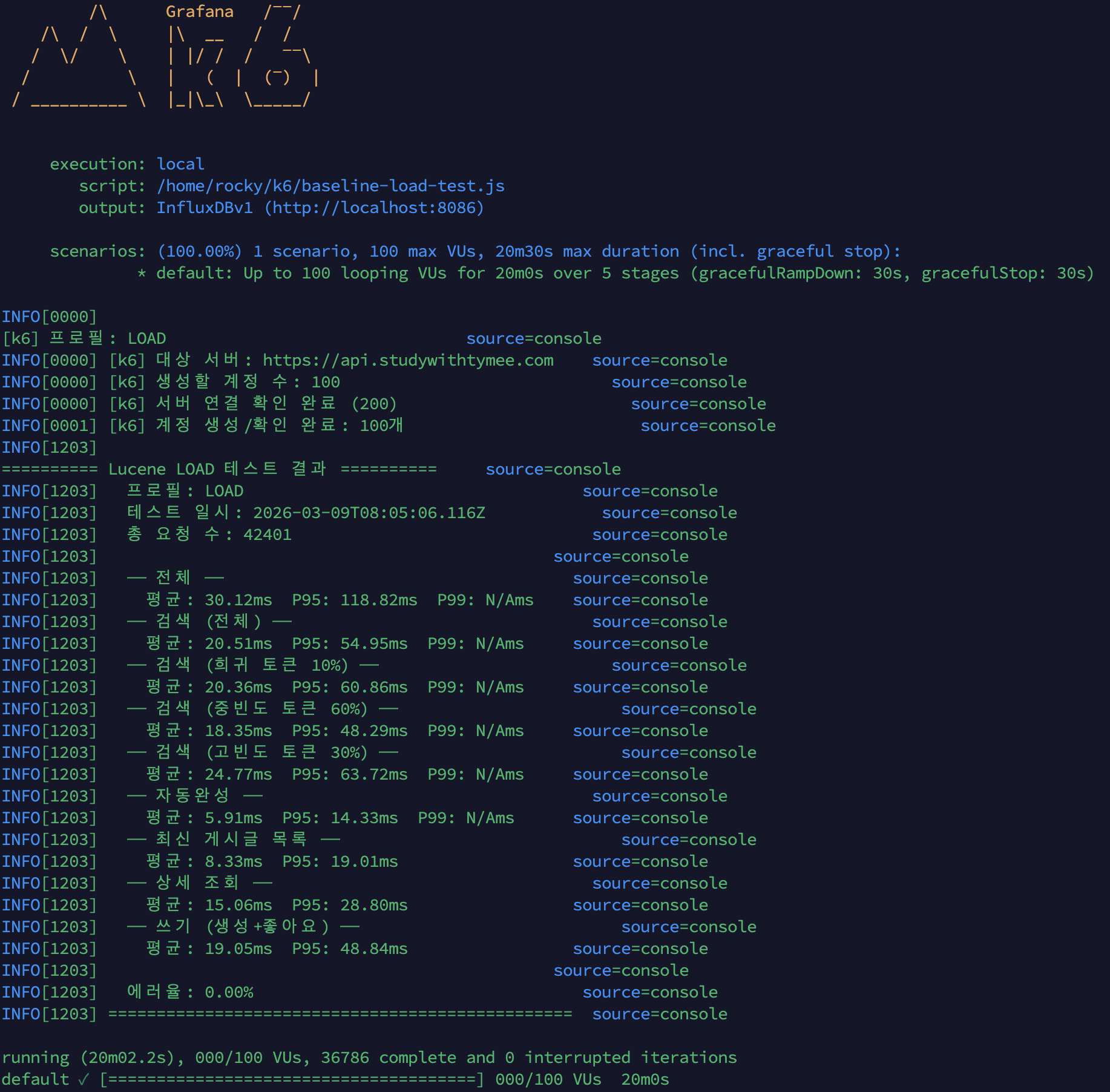
며칠치로는 규모를 증명 못 해서 1년치를 만들었고, 축을 돌려 다시 쟀습니다
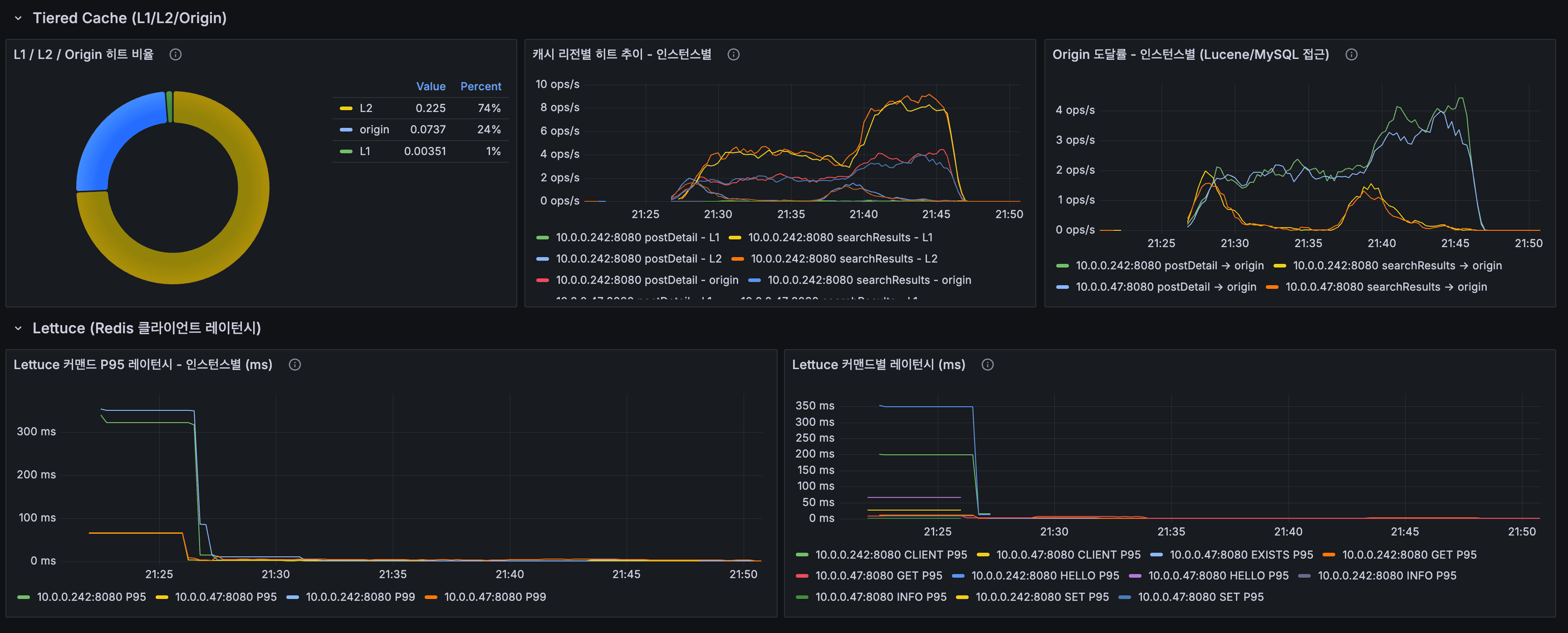
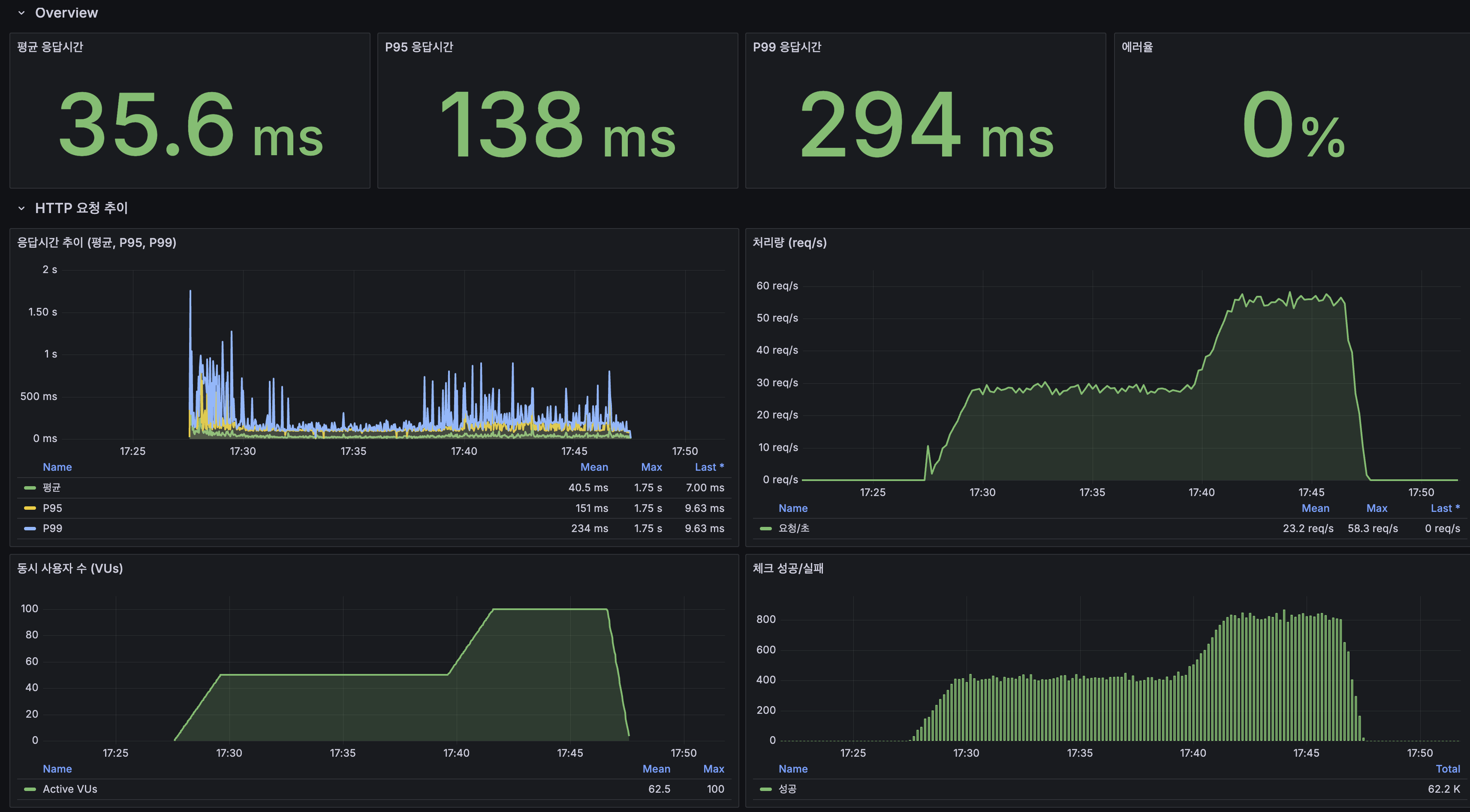
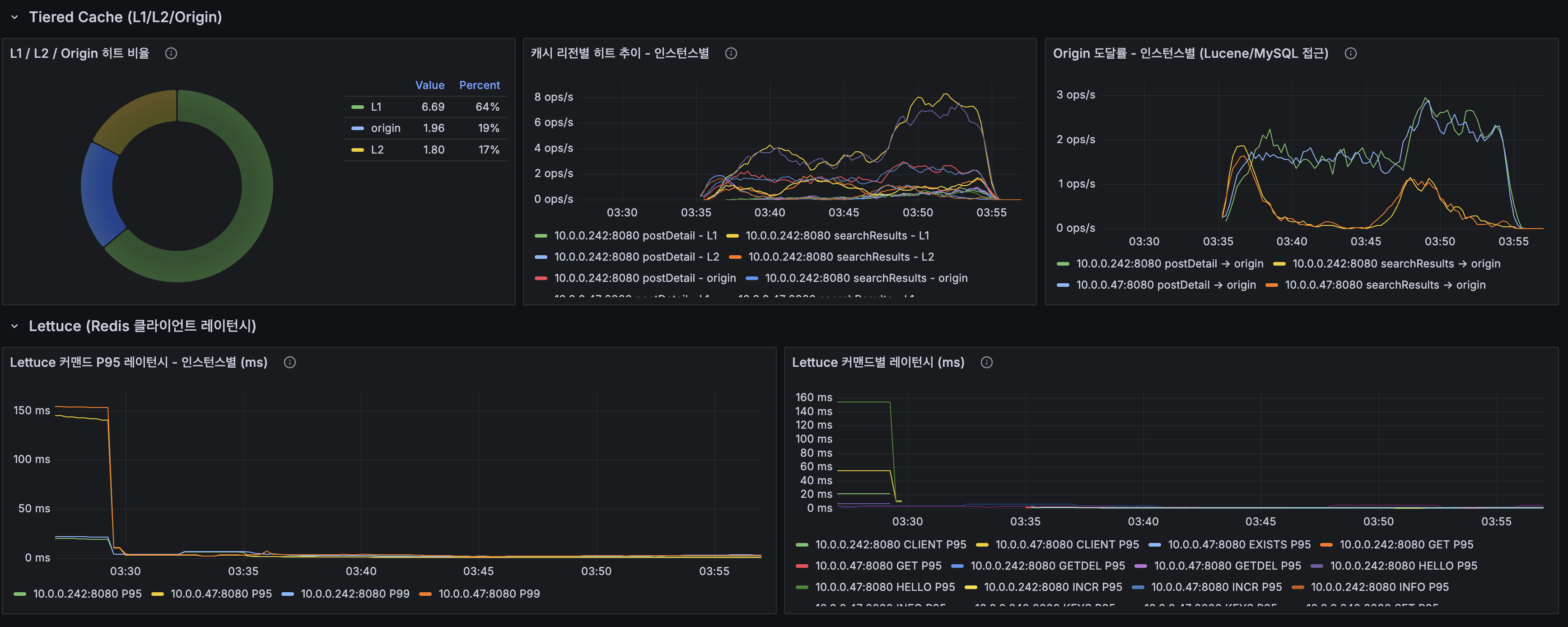
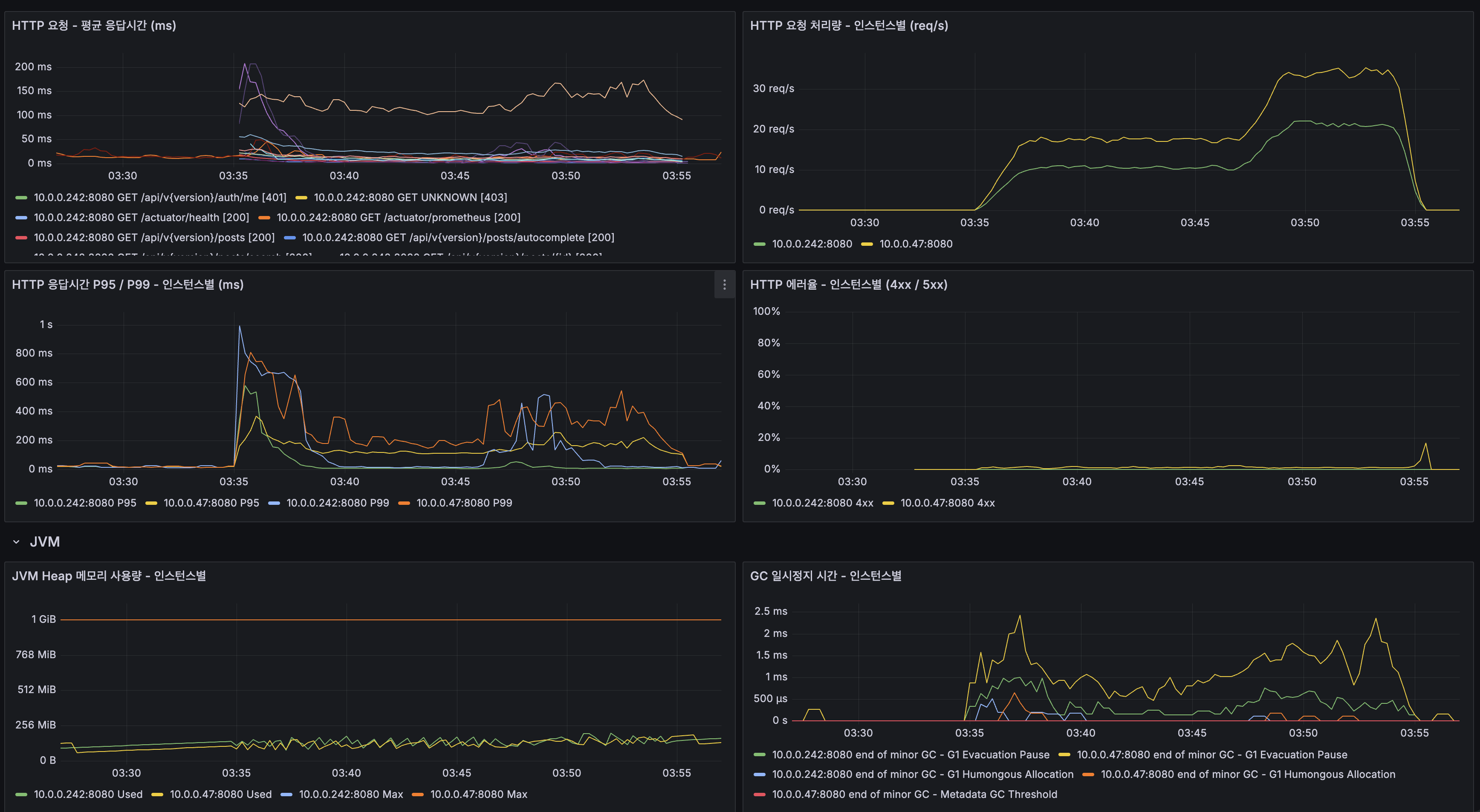
지금까지 모든 실측은 닫힌 dt 세 개, 수십만 행에서 돌았습니다. 그 규모에선 전부 초 단위라 "규모에서도 버틴다"고 말하고 싶어지는데, 며칠치로는 증명이 안 됩니다. 마트(fct)는 매일 전체 이력을 다시 계산하는데 이력이 3일이라 안 아팠을 뿐입니다. 그래서 닫힌 dt를 날짜 시프트로 복제해 365dt×6인스턴스=2,190파일(54.5M행)을 격리 프리픽스에 만들어 어디가 먼저 무너지는지 쟀습니다. 병목은 fct 전체 재빌드 407.62초 하나였고, 나머지는 규모에서도 초 단위였습니다. 그 수치가 정당화하니 dt 단위 독립성을 살려 delete+insert로 증분화했고, 컴파일 타임 워터마크 리터럴로 파티션 프루닝을 걸어 407.62초를 4초로 줄였습니다. 그런데 규모의 축은 시간 하나가 아닙니다. 셀프호스터가 몇백 대를 관제하는 사람이라면 늘어나는 축은 dt가 아니라 인스턴스 수입니다. 로드맵에 "소파일이 먼저 무너지고 그다음 추출, 컴퓨트는 마지막"이라고 외삽해 뒀었는데 재보지 않은 문장이었습니다. 총량을 고정하고 축만 돌려 300대(52.2M행)로 다시 재보니, 증분 fct는 8.03초로 건재했고 급소는 소파일이 아니라 full-refresh였습니다. 제 외삽 두 개가 틀렸고, 그걸 수치가 바로잡았습니다. 최적화는 병목 수치가 정당화한 곳만 건드렸습니다.