소개
안녕하세요! 이 블로그를 운영하고 있는 개발자입니다.
개발하면서 배운 것들을 기록하고 공유하기 위해 이 블로그를 시작했습니다.
기술 스택
- 이 블로그는 Astro와 Tailwind CSS로 만들어졌습니다.
- GitHub Pages에서 호스팅됩니다.
연락처
- GitHub: github.com/dj258255
- Email: dj258255@naver.com

프로젝트

텔레그램에서 구독 Claude를 그대로 돌리는 봇
폰에서 Claude에게 일을 시키고 싶어서 만들었다. API 키로 따로 과금하는 대신 이미 쓰던 Claude Code 구독 인증(claude -p)을 그대로 호출한다. 메시지를 보내면 진행 상황을 실시간으로 흘려주고, 코딩 모드에서는 서버 안에서 파일을 만들고 명령을 실행한다. 음성으로 지시하면 텍스트로 바꿔 넘기고, rm -rf 같은 위험한 명령은 실행 직전에 막는다. 같은 서버에 이미 돌던 다른 서비스는 건드리지 못하도록 격리해 두었다.

화면 공유를 켜야 출석으로 치는 디스코드 스터디 봇
알고리즘 스터디 출석 체크를 봇에게 넘겼다. 음성채널에서 화면 공유를 켠 시간만 구간 합산으로 기록하고, 누적 60분이면 출석, 주 3회 미달이면 경고, 경고 3회면 자동으로 자리를 정리한다. 공지는 실시간으로 하되 판정은 정산 크론에서만 하기 때문에 봇이 재시작돼도 기록이 깨지지 않는다.

kernel-hobby — C/RISC-V 토이 커널
부팅에서 멀티코어(SMP)·TCP·copy-on-write까지, MIT 6.S081(xv6) 랩 전부를 C/RISC-V로 바닥부터 구현한 토이 커널 — OS의 골격을 손으로 다시 지었다.
dbtower-lakehouse — 버려지는 관측 데이터의 장기 분석 파이프라인
DBTower가 5기종에서 수집한 쿼리 스냅샷은 7일 뒤 삭제된다(메타 DB 포화 방지). '지난달보다 느려진 쿼리?'에 답하려고, 만료 직전 스냅샷을 컬럼나 저장소로 내려(ELT) 장기 이력을 만드는 데이터 파이프라인 — Airflow·dbt·DuckDB/DuckLake·MinIO.
EEDGate
LLM 워크플로우의 실패를 유형으로 자동 분석해 규칙을 스스로 만들어내는 자기 개선 평가 루프 — 검증 게이트·회귀 테스트를 하나의 TUI/CLI로.
DBTower — 이기종 DBMS 운영 관리 플랫폼
다섯 기종(MySQL·PostgreSQL·Oracle·SQL Server·MongoDB)을 하나의 인터페이스 뒤로 추상화한 DB 관제탑. SQL도 JDBC도 없는 MongoDB를 Operator 구현체 하나로 얹었고, 수집·비교·회귀 감지·웹·MCP 코어 경로는 수정 0줄이었음을 실측으로 증명했다.

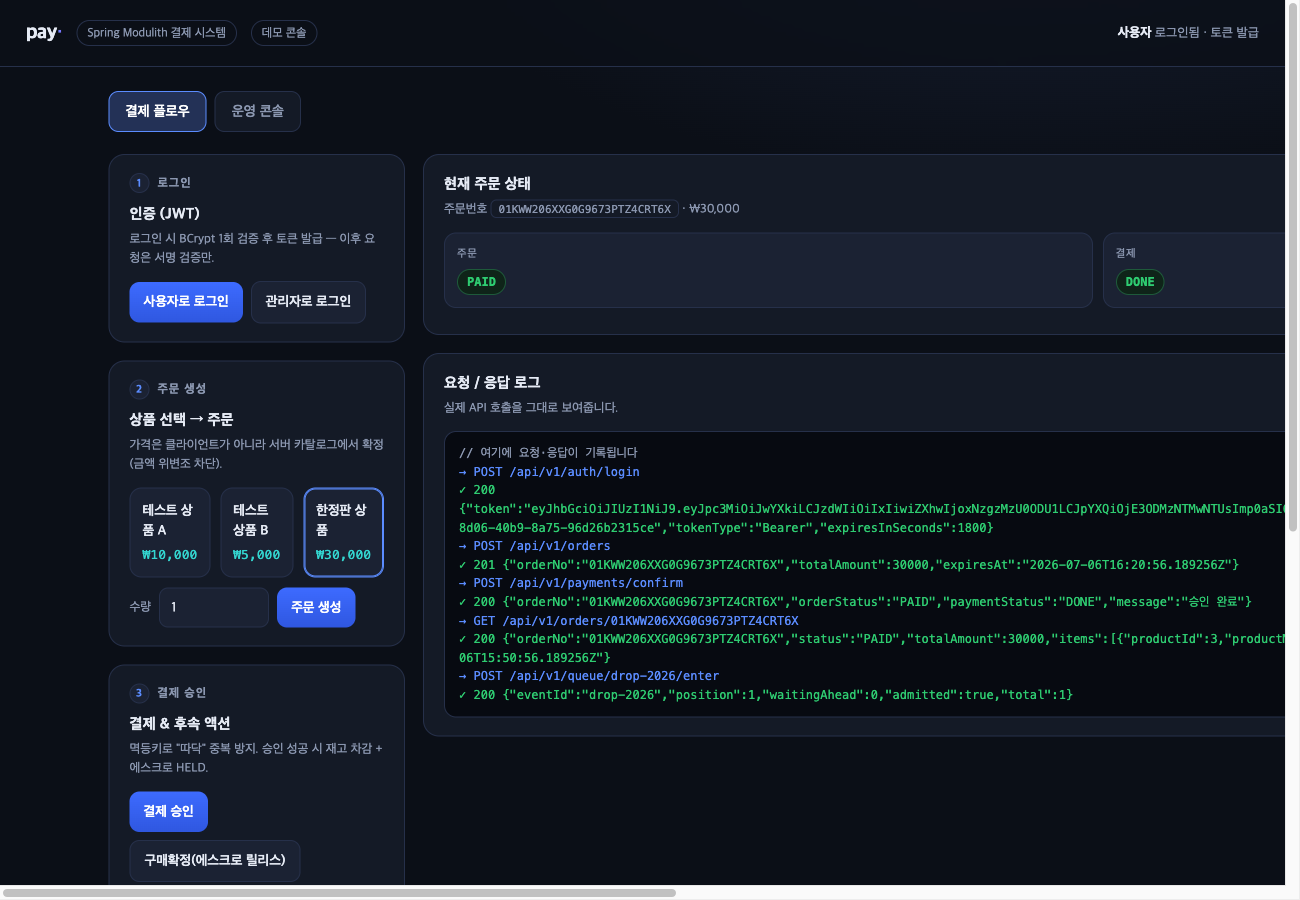
pay — Spring Modulith 결제 시스템
결제는 실패가 비싼 도메인 — 타임아웃·중복·미확정·정산 불일치가 실제로 아프게 드러난다. PG가 대신 안 해주는 그 빈 공간(실패 설계·정합성·분산 트랜잭션)을 밑바닥부터 직접 만들어보며 배운 학습 프로젝트. 복식부기 원장·정산/대사·체크아웃 사가(PG 콜을 트랜잭션 밖으로)·멀티PG·구독·선불 월렛·회원·분쟁/차지백까지, 실 MySQL 라이브 검증과 자가 감사로 다졌다.
위키엔진
1,425만 건 위키를 자체 검색엔진(Lucene)으로 색인하고, L1 캐시로 반복 부하를 80%+ 걷어낸 뒤 Stateless·읽기/쓰기 분리로 스케일아웃한 통합 검색 플랫폼.

IT Oasis
이 블로그 자체 — Astro 5.x로 만든 다국어(KO/EN) 기술 블로그로, View Transitions·다크모드·카테고리/태그 검색까지 직접 구현했다.

db-hobby — C로 만든 미니 RDBMS
진짜 psql이 그대로 접속하는 자작 RDBMS — 페이지 한 장에서 MVCC·WAL·비용 기반 옵티마이저·Raft 합의까지, PostgreSQL·MySQL 내부를 C로 바닥부터 재현하고 694개 테스트로 검증했다.
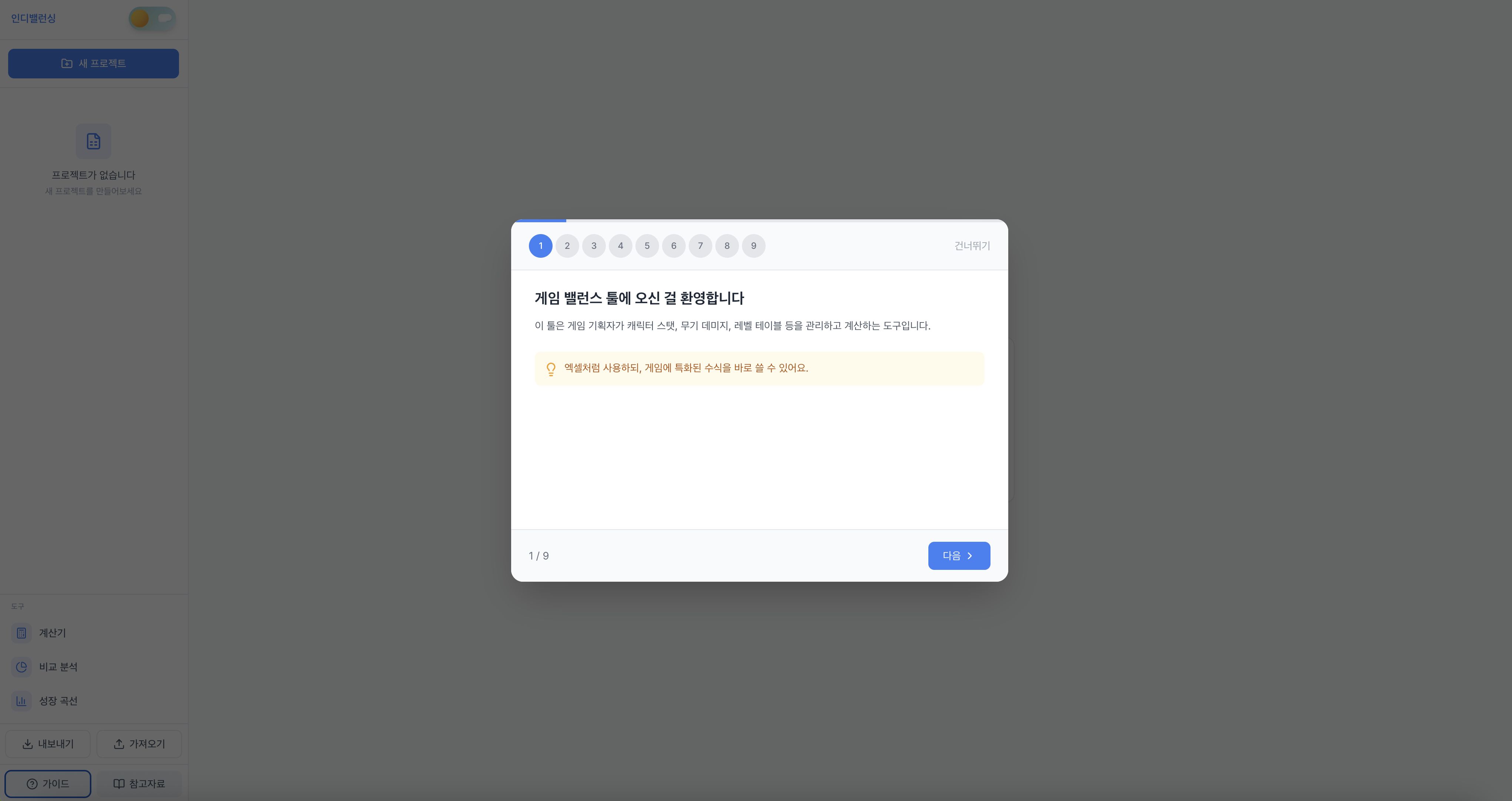
발루노
게임 기획자를 위한 오픈소스 밸런싱 플랫폼 — JSONB 1만 건에서도 시트 조회 p95를 500ms 이하로 유지하고, 멱등 저장·블루/그린 무중단 배포까지 갖췄다.


빌려조잉
삼성전자 우수상을 받은 C2C 대여 플랫폼 — 실시간 채팅 병목을 코루틴 전환으로 150ms에서 1ms 미만까지 줄인 6인 팀 프로젝트.

오락가락
내 목소리를 분석해 부를 노래를 추천하는 플랫폼 — 5~30초 걸리던 동기 음성 처리를 Kafka 비동기 파이프라인으로 200ms 응답 + DLQ 실패 복구까지 재설계한 팀 프로젝트.
관문(gwanmun) — 레거시 전문 ↔ 현대 REST 연계 게이트웨이
20년 된 계정계는 고정길이 전문(電文)+TCP로, 모바일은 JSON+REST로 말한다. 둘 다 못 고치니 중간에 통역기를 세운다 — 전문↔JSON 매핑·TCP↔HTTP 변환(연계)에 인증·라우팅·유량제어(API 게이트웨이)를 한 흐름으로 얹은 미들웨어.

최신 스토리
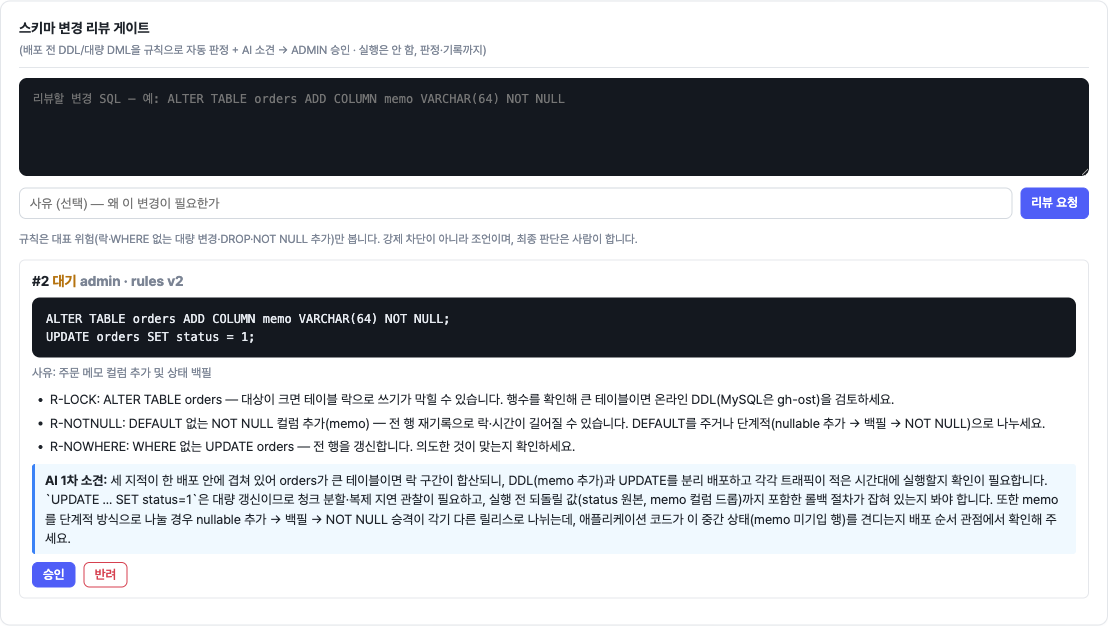
사람 손이 붙어 있던 다섯 곳을 끊다: 설정 드리프트·변경 리뷰·인덱스 판정·인시던트 리포트·월간 점검
이기종 DBMS 운영 관리 플랫폼 DBTower 9편. 현업 DBA의 병목이 어디에 남는지를 렌즈로, 사람 손이 선형으로 붙던 다섯 지점을 기능으로 끊었습니다. (1) 설정 드리프트 이력: 파라미터 diff의 공간축("A와 B가 다른가")에 시간축("언제부터 무엇이 바뀌었나")을 붙였습니다. 거울 테이블과 변경 로그로 무변경 주기엔 스냅샷 한 줄만 쌓이게 했고, work_mem 4096→8192 실변경을 감지해 카드를 쐈습니다. 검증 중 MongoDB parameters()가 $clusterTime 같은 응답 gossip 필드를 흘려 매번 오탐이 나던 기존 버그도 잡았습니다. (2) 스키마 변경 리뷰 게이트: 배포 전 DDL을 규칙으로 판정(락 위험·DEFAULT 없는 NOT NULL·DROP·WHERE 없는 대량 변경)하고 실제 행수로 락 위험을 확정한 뒤 AI 1차 소견을 붙여 ADMIN 승인·자동 감사까지. 실행은 하지 않고 gh-ost 경로만 안내합니다. (3) 인덱스 사용 통계 주기 영속: "이 인덱스 지워도 되나"는 재시작 누적 카운터의 순간값으론 못 답합니다. 5기종 스캔 통계를 6시간 주기로 영속하고(Oracle은 미지원 정직), lakehouse가 first-vs-last 델타·리셋 클램프로 분기 창 판정 마트를 짓습니다. (4) 인시던트 리포트: 장애 구간을 주면 시점 비교·설정 변경·플랜 플립·대기·가용성을 한 장으로 재구성하고 AI가 재료 내 사실만으로 요약합니다. (5) 월간 점검 리포트: 헬스·백업·Advisor·용량·낭비·설정 변경을 매월 자동 발행합니다. 다섯 개 전부 읽고 판정·기록까지가 몫이고 대상 DB는 바꾸지 않습니다. 신규 모듈 하나(review)는 이벤트로 alert에 카드를 위임하고, 공개 파사드 둘(score·finops)로 Modulith 경계를 순환 없이 유지했습니다. 테스트 514건, VERIFICATION 110개 절.
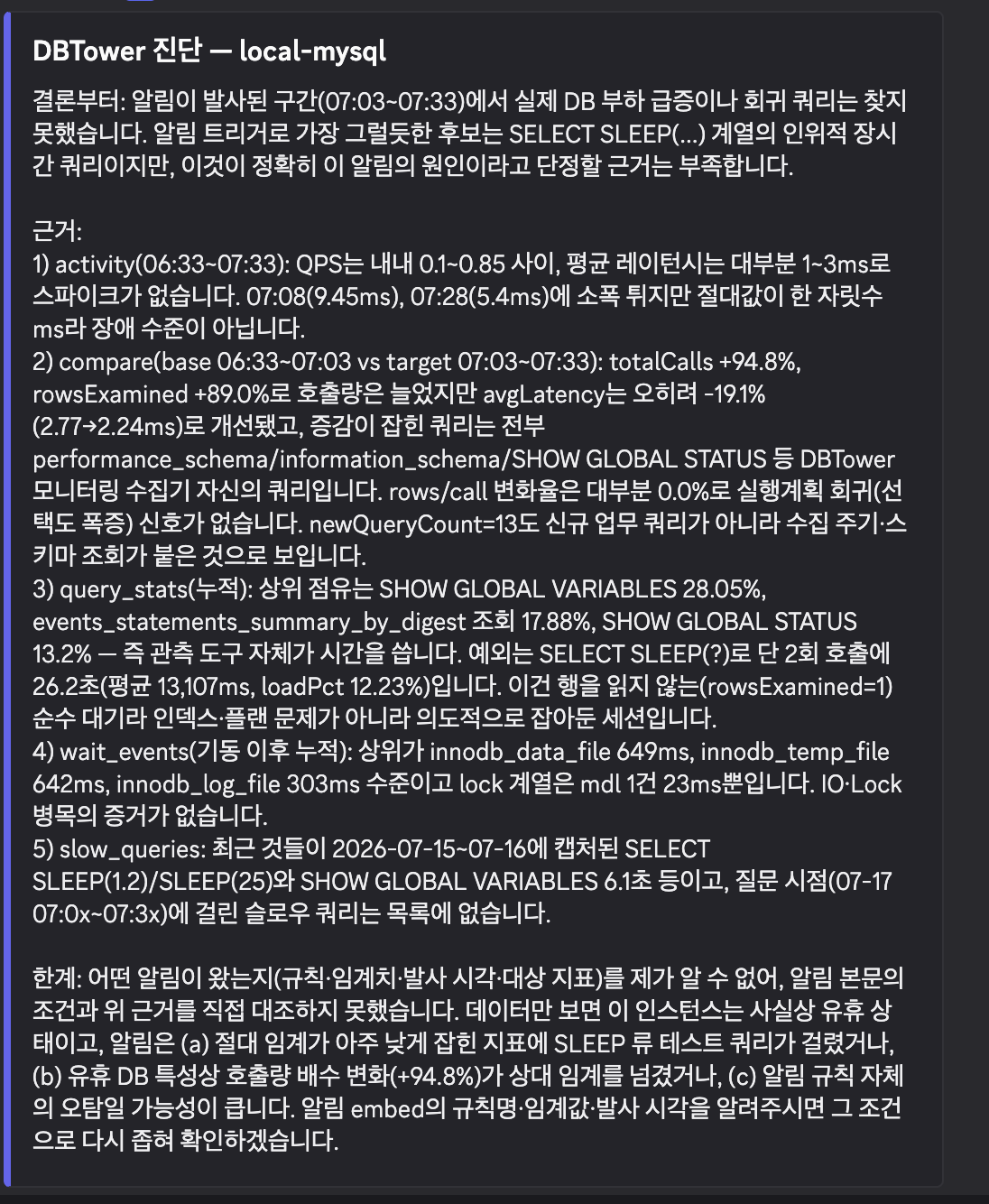
관제탑과 대화하고 두 저장소를 잇다. 이모지로 진단을 부르고, 창고가 계산한 평소로 오탐을 지운다
이기종 DBMS 운영 관리 플랫폼 DBTower. 앞부분은 알림에서 진단까지의 왕복을 완성합니다. 회귀·이상·운영 경보가 밋밋한 텍스트에서 구조화된 Discord embed 카드가 됩니다(심각도 색·담당 팀·AI 1차 분석·질문이 미리 채워진 진단 딥링크). 알림에 돋보기 이모지를 달면 봇이 그 인스턴스를 AI로 진단해 답글을 붙이죠. 여기엔 함정이 둘 있었습니다. 왼쪽 돋보기(U+1F50D)와 오른쪽 돋보기(U+1F50E)가 서로 다른 유니코드라는 점, 그리고 웹훅이 쓴 메시지의 embed를 봇이 읽으려면 특권 인텐트가 필요하다는 점입니다. 후자는 발사 시점에 message_id를 인스턴스에 매핑해 권한 0개로 풀었습니다. 대상이 하필 죽어 있어 진단 도구가 전부 빈손이었을 때, AI 답글은 수치를 지어내는 대신 "근본원인을 확정하지 못했습니다"라고 답했습니다. 이번 실측에서 가장 인상적인 대목이었습니다. MCP 정적 토큰은 OAuth 2.1 브라우저 로그인으로 바꿨고(302 대신 401 함정, redirect_uri userinfo 우회), Vault 동적 자격증명으로 유출 창을 TTL 2분으로 줄였습니다. 뒷부분은 lakehouse(장기 분석계)와의 루프를 양방향으로 닫습니다. 받아오는 쪽에서는, lakehouse가 수개월 이력으로 계산한 요일×시간대 베이스라인을 V24 테이블로 받아 14일 창에 충분통계량 복원(Σx=n·m, Σx²=(n−1)s²+n·m²)으로 가중 병합했습니다. 실측 스파이크(psql 3,000회)의 판정이 장기 테이블 내용에 따라 뒤집혀 z=7.42로 발화했고, 관측 수가 101(장기 100+단기 1)로 찍히며 병합이 실제로 작동한 자국이 남았습니다. 내보내는 쪽에서는, 대기 이벤트(V25)와 오브젝트 크기(V26)를 주기 영속하는 잡을 신설하고 plan_snapshot 보존에 48시간 하한을 병행했습니다. 자연어 서빙은 Metabot이 Cloud 전용이라 생긴 갭을 MCP 도구 두 개(장기 마트 SELECT·Metabase 카드 생성)로 메웠고, 카드 76이 실제로 생성되어 bar 차트가 143ms에 렌더됐습니다.

7일이면 버려지는 스냅샷을 장기 이력으로 살려낸 dbtower-lakehouse 실측 총정리
DBTower가 7일 뒤 버리는 쿼리 스냅샷을 컬럼형 저장소로 내려 장기 이력을 만드는 ELT 파이프라인의 전체 기록을 한 편에 정리합니다. 오케스트레이션은 Airflow, 적재는 MinIO의 Parquet입니다. 변환은 dbt가 맡고 질의는 DuckLake로 합니다. 문제 정의(7일 시야로는 '지난달 대비 느려진 쿼리'에 못 답함)에서 시작해, 원천·적재·조회 3자 일치로 검증한 멱등 추출(닫힌 창 07-05=149,259·07-06=79,894), 누적 카운터를 일간 델타로 접는 변환, 조용한 오답을 막는 4축 fail-closed 게이트, lake를 house로 올리는 DuckLake 타임트래블, 아카이브가 자신을 지우던 치명 결함의 차단, 1년치를 합성해 407.62초 재빌드를 4초로 줄인 규모 실측, Kafka를 넣지 않은 근거를 담았습니다. 여기에 남이 그대로 띄우는 셀프호스트 어플라이언스, 두 저장소가 손잡는 되쓰기, 그리고 이 창고만 할 수 있는 여섯 가지 판정(용량 D-day·플랜 회귀·백업 공백·미사용 인덱스·설정 변경 상관·가용성 SLO)까지, 파이프라인이 답을 만드는 공정에서 판정을 내리는 창고로 자란 과정을 이었습니다. 라이브에서 MSSQL 두 인스턴스가 63퍼센트대 가용성에 평균 ping 2에서 7초로 목표 미달, 나머지는 99.9퍼센트로 목표를 지킵니다. 모든 수치는 직접 측정했고 재현 기록이 저장소에 있습니다.
창고가 데이터를 내리는 데서 판정을 내리는 데까지, 여섯 가지 판정을 채우다
창고에 데이터를 내리기만 하고 판정을 안 하고 있었습니다. plan_snapshot과 fct_query_daily를 둘 다 갖고도 상관시키지 않아 신고마다 30분씩 플랜 이력을 뒤졌고, 백업 공백은 판정 컬럼이 없어 복구하다 발견했습니다. 셋 다 신규 수집 없이 이미 내린 데이터를 판정 컬럼까지 잇는 일이었습니다. 플랜 회귀는 일 단위 대표 플랜의 뒤집힘을 전후 N일 지연과 겹치되 관측이 덜 차면 PENDING, 창이 오염되면 AMBIGUOUS로 지어내지 않고, 백업 공백은 유니버스를 query 팩트에서 잡아 기록 없는 인스턴스도 행으로 드러내며 기준일을 벽시계가 아닌 창고 최신 dt로 잡습니다. 이 셋을 주간 보고 한 장으로 접었습니다. 그리고 판정에 "왜"가 빠졌음을 깨달아 설정 드리프트를 원인 후보로 붙이고, 상관을 플랜 뒤집힘 한 축에서 지연·볼륨까지 넓히고, change_review는 저빈도라 자리만 열어 두었습니다. 여러 마트가 달던 "기종 축이 없다"는 각주는 이미 읽던 database_instance의 name·type로 회수해 instance_id 1이 local-mysql (MYSQL)로 읽히게 했고, 마지막으로 DBTower가 35일 뒤 지우는 up 여부를 장기 가용성 SLO로 만들었습니다. 라이브에서 MSSQL 두 인스턴스가 63퍼센트대 가용성에 평균 ping 2에서 7초로 목표 미달, 나머지는 99.9퍼센트로 목표를 지킵니다. 이걸로 관리 대상 DB에 관해 창고가 답할 판정 여섯이 한 바퀴 찼습니다. 발화는 여전히 남에게 맡기고 판정 컬럼까지만 정직하게 계산합니다.
폰에서 Claude를 돌리려고 텔레그램 봇을 만들었다
이미 쓰던 Claude 구독을 폰에서도 쓰고 싶어서 만든 봇입니다. API 키로 따로 과금하는 대신 Claude Code 구독 인증(claude -p)을 그대로 호출하고, 메시지를 보내면 작업 과정을 실시간으로 흘려줍니다. 디스코드 봇을 이미 돌리고 있으면서도 이번엔 텔레그램을 고른 이유, 코딩 모드에서 확인 없이 파일을 고치는 대신 넣은 취소 장치, 같은 서버의 다른 서비스를 못 건드리게 막은 격리까지 정리했습니다.
화면 공유를 켜야 출석으로 친다: 디스코드 스터디 출석봇
알고리즘 스터디의 출석 체크를 봇에게 넘긴 기록입니다. 음성채널에 들어와 있는 시간이 아니라 화면 공유를 켠 시간만 구간 합산으로 세고, 누적 60분이면 출석, 주 3회 미달이면 경고, 경고 3회면 자동으로 자리를 정리합니다. 공지는 실시간이지만 판정은 정산 크론에서만 하도록 갈라 둔 덕에 봇이 재시작돼도 기록이 안 깨집니다. 후반부는 '시간대 제한을 풀고 24시간 돌리자'는 설정 한 줄짜리 변경인 줄 알았던 일이 함정 세 개(24:00이라는 크론에 없는 시각, 일요일 출석을 못 보는 주간 점검, DB에 남은 옛 세션 키로 죽는 재시작 복구)로 번진 이야기입니다.

여럿이 쓰는 관제탑: 팀 경계와 멀티노드, 그리고 호스트 차원
이기종 DBMS 운영 관리 플랫폼 DBTower의 멀티테넌시와 호스트 차원 기록입니다. 앞부분은 여러 팀이 한 콘솔을 쓰기 시작하는 국면을 다룹니다. 팀 사용자는 자기 팀 인스턴스와 전역만 보고, 남의 팀 인스턴스는 id로 직접 찔러도 403이 아니라 404를 받습니다(존재 자체를 숨김). 강제 지점은 단 한 곳(RegistryService)입니다. 세션을 메타 DB로 옮겨 재시작에도 로그인이 살아남게 했고, 그 과정에서 Boot 자동구성이 인메모리로 조용히 폴백하는 함정을 밟았습니다. 이렇게 준비한 노드를 실제로 늘렸더니, 분산 락 하나 때문에 두 번째 노드가 놀고 있었습니다. 샤드별 락으로 바꾸니 두 노드가 수집을 나눠 들고, 한 노드를 죽이면 남은 노드가 설정 변경 없이 전 샤드를 인수하며, 같은 쿠키로 로그인도 유지됩니다. 로그인 잠금 카운터도 메타 DB로 옮겨, 노드 A에서 두 번·B에서 한 번 틀리자 네 번째가 잠기는 것을 실측했습니다. 최대 볼륨 테이블은 월별로 파티셔닝해 보존 정리를 DELETE 1.9초에서 DROP 12.8ms로 줄이고 블로트를 아예 없앴으며, 커넥션은 온디맨드로 바꿔 격리 대상의 유휴 커넥션을 1개 영구에서 0으로 만들었습니다. 뒷부분은 호스트 차원입니다. 디스크 포화 예측은 잔량이 아니라 속도를 봅니다. 여유가 76.8%나 남았는데 치명 경보가 뜨는 화면을 실쓰기 부하로 직접 만들었습니다. 초당 17MB씩 줄고 있으면 20시간 뒤 장애이므로 이 경보가 맞습니다. 여기서도 node-exporter가 rootfs 마운트 없이 컨테이너 자기 자신만 보고 있던 함정과, mountpoint="/" 고정이 데이터 전용 마운트를 쓰는 실무와 어긋나는 설계 함정을 만났습니다. 마지막은 서버 공유 인지입니다. 등록 단위는 DB인데 물리 단위는 서버라, 같은 서버에 DB 두 개를 등록하면 세션·복제·데드락 경보가 두 번 울립니다. 이를 그룹당 1회로 줄이되 "누구에게 해당하는지"를 명시하고, 헬스 스코어(위험 귀속)는 일부러 dedup하지 않은 선 긋기를 기록했습니다.
아무도 못 쓰던 프로젝트를 셀프호스트 제품으로 끌어올리고, 화면 패리티까지 맞추다
이기종 DBMS 운영 관리 플랫폼 DBTower 프로덕션화·화면 패리티 편. 기능은 레퍼런스로 삼은 사례를 넘어섰는데, 정작 "남이 클론해서 실제로 쓸 수 있나"를 물으니 답이 아니었습니다. 블로커는 넷이었습니다. 라이선스가 없어 법적으로 아무도 못 썼습니다. 암호화 fail-closed가 하필 셀프호스트가 쓰는 docker 프로필만 비껴가, 대상 DB 비밀번호가 평문으로 저장됐습니다. 비밀번호 컬럼이 든 옛 H2 파일은 커밋된 채였고, AI 판단 규칙 파일은 이미지에서 빠져 빈 프롬프트로 돌고 있었습니다. Phase 0(배포 블로커) 넷을 없애고, 관제탑이 자기 자신을 지키기 시작하고(로그인 잠금·메타 백업·웹 HTTPS), 문의에 참조 테이블 스키마를 붙였습니다. 이어서 레퍼런스 발표의 화면 11장을 컬럼 단위로 전수 대조하며 표 컬럼 패리티를 맞췄고, 그 과정에서 함정 셋을 만났습니다. 단위 테스트 382건이 초록인데도 웹 콘솔 전체가 백화된 채 커밋돼 있었습니다. "카탈로그 재구성(근사)" 배지는 알고 보니 게으름의 라벨이었습니다. CPU 그래프를 붙이다 보니 활동 그래프가 9시간 미래의 빈 구간을 조회하고 있었습니다. 전부 라이브 실측과 함께 기록합니다.