EduMeet - 첫 팀 프로젝트를 마무리하며

목차
프로젝트 소개
EduMeet은 실시간 음성-자막 변환으로 청각장애인의 학습을 지원하는 온라인 교육 플랫폼입니다. 한국수어통역사협회 자료에 따르면 수화 통역사 대비 청각장애인 비율이 1:300이라고 합니다. 온라인 강의에서 청각장애인은 자막 없이는 학습이 사실상 불가능한데, AI 음성인식으로 실시간 자막을 제공하면 이 문제를 크게 개선할 수 있다고 판단했습니다.
기간: 2025.07.07 - 2025.08.15 (6주)
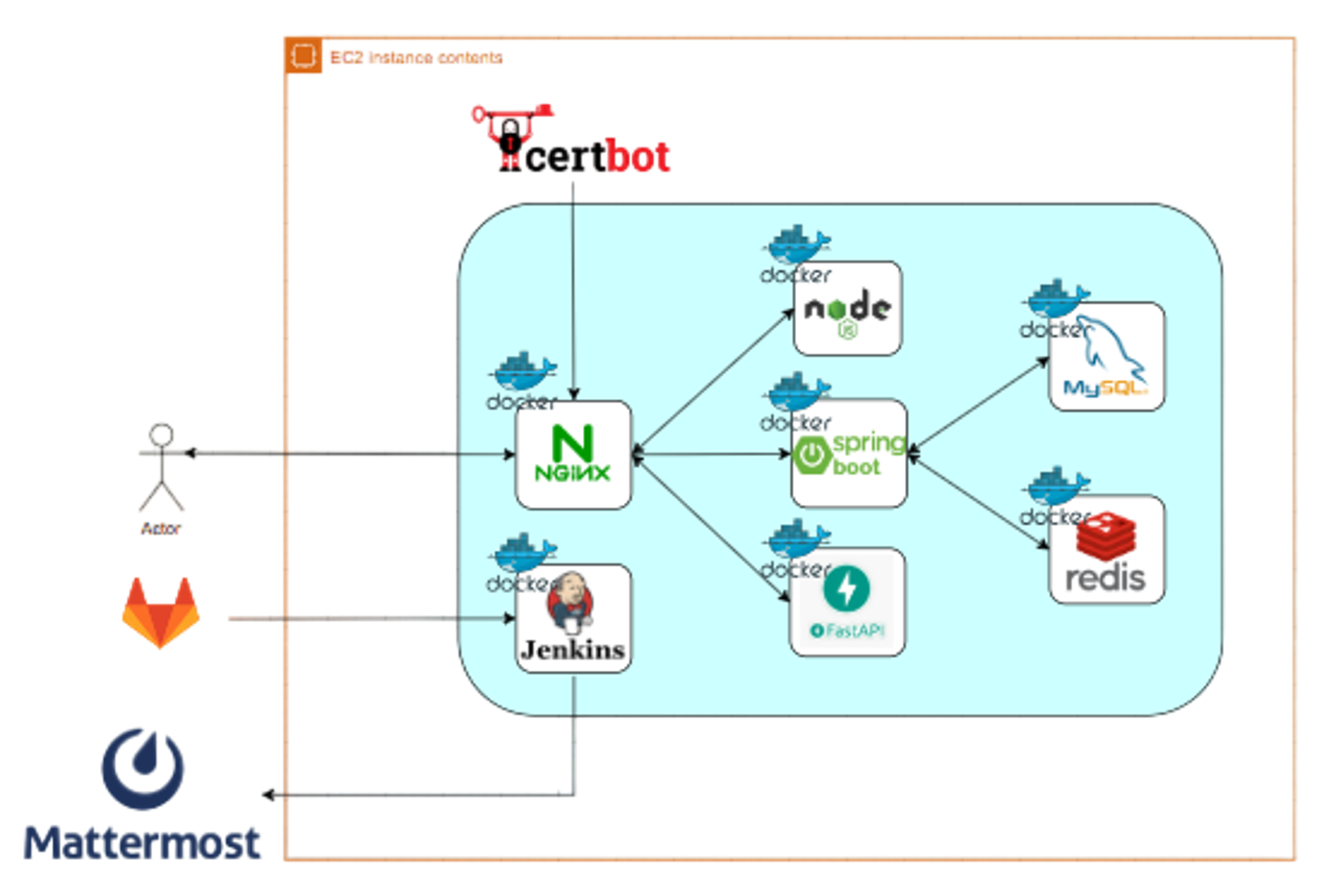
팀 구성: 6명 (프론트엔드 3명, 백엔드 3명)
기술 스택: Java, Spring Boot, JPA, QueryDSL, MySQL, AWS S3, Docker
내 역할
백엔드 개발을 담당했습니다. 구체적으로는 게시판 CRUD API 설계/구현, S3 이미지 업로드 파이프라인, 127개 단위테스트 작성, 레이어드 아키텍처 설계를 맡았습니다.
첫 팀 프로젝트라서 “기능 구현”에만 집중할 줄 알았는데, 실제로는 기능 구현보다 방어 로직과 테스트 코드에 훨씬 더 많은 시간을 쏟았습니다.
주요 구현
N+1 문제 해결: 쿼리 12개 → 4개, 응답 66.9% 개선
Board-BoardImage-Reply 3개 테이블(1:N 관계)에서 게시판 목록 조회 시, 페이지 사이즈 10건마다 board_image를 개별 SELECT하는 N+1 문제를 발견했습니다. Hibernate SQL 로그와 통계 기능으로 쿼리 12개(목록 1 + N+1 10 + COUNT 1) 실행을 확인했습니다.
FetchJoin(메모리 페이징 문제), EntityGraph(성능 악화 +35%), SUBSELECT(Spring Data JPA 세션 비호환), BatchSize 4가지를 실측 비교한 결과, @BatchSize(20)이 페이징과 호환되면서 가장 높은 성능(38.33ms → 12.66ms, 66.9% 개선)을 보여 선택했습니다.
상세 분석: N+1 문제 분석과 해결
127개 단위테스트 & H2 전환
MySQL로 테스트를 돌리면 9.57초가 걸렸습니다. 디스크 I/O와 TCP 네트워크 왕복이 원인이었고, 개발 중 테스트를 하루 평균 20~30회 실행하면 4.34초 × 25회 ≈ 하루 약 1.5~2분, 6주간 3명 기준 약 3~4시간의 누적 대기가 발생합니다. H2 인메모리 DB로 전환하니 5.23초로 45% 빨라졌습니다.
단위테스트는 H2(빠른 피드백), 통합테스트는 MySQL(SQL 호환성 검증)로 이원화했습니다. H2-MySQL 간 SQL 호환성 차이(GROUP_CONCAT, ENUM 등)는 통합 테스트에서 잡는 전략입니다.
상세 분석: 단위테스트 DB 마이그레이션
S3 이미지 업로드 최적화: 용량 91.8% 감소
원본 이미지(약 5MB, 4032×3024)를 썸네일(약 410KB, 800×600)로 리사이징하여 91.8% 용량 감소를 달성했습니다. Stream/MultipartFile/AWS Multipart 3가지 업로드 방식을 비교하고, 서버 리사이징이 필수인 요구사항에 맞춰 MultipartFile을 선택했습니다.
DB PK는 InnoDB Clustered Index와의 호환성을 위해 Auto Increment, 외부 노출 파일명은 예측 불가능한 UUID로 역할을 분리했습니다.
상세 분석: S3 업로드 최적화
기억에 남는 트러블슈팅
JPA 엔티티 매핑 → N+1 해결까지 이어진 흐름
세 가지 문제가 순서대로 연결됐습니다:
-
OneToMany 중간테이블 자동 생성:
@OneToMany에mappedBy를 빠뜨려서 ERD에 없는board_image_set중간테이블이 생겼습니다.mappedBy = "board"로 해결하면서, JPA 매핑 후 반드시 DDL을 ERD와 대조 검증하는 팀 규칙을 정했습니다. → 상세 -
Lazy Loading No Session: 중간테이블을 제거하고 나니, 테스트에서 BoardImage에 접근할 때
LazyInitializationException이 발생했습니다. 영속성 컨텍스트의 생명주기를 이해하고@EntityGraph로 근본 해결했습니다. → 상세 -
N+1 문제 발견: @EntityGraph를 적용하면서 Lazy 로딩의 동작 원리를 파악했기에, 게시판 목록 조회에서 N+1이 발생하는 근본 원인(프록시 초기화 → 루프 내 추가 쿼리)을 빠르게 짚을 수 있었습니다. → 상세
QueryDSL 파일 이동 오류: 아키텍처 원칙 vs 프레임워크 규칙
레이어드 아키텍처에서 구현체를 Infrastructure 레이어로 이동했더니 “No property searchAll found for type Board” 에러가 발생했습니다. Spring Data JPA의 Custom Repository 네이밍 규칙과 레이어 분리 원칙이 충돌한 건데, AI가 제안한 2가지 방법 대신 extends 분리 + 독립 빈 주입이라는 아키텍처 관점의 해법을 선택했습니다.
상세 분석: 파일 이동 오류
느낀 점
기능보다 방어 로직이 중요하다
게시판 CRUD 기능 구현은 3일 만에 끝났습니다. 그런데 테스트 코드를 작성하면서 비정상 상황을 하나씩 따져보니, 방어 로직 구현에 5일이 더 걸렸습니다. 기능이 동작한다와 서비스가 안전하다는 다르다는 걸 처음으로 체감했습니다.
코드 리뷰의 가치
GitLab MR 기반 코드 리뷰를 도입했습니다. “왜 이렇게 구현했나요?”라는 질문에 답하려면 공식 문서를 확인하고 근거를 정리해야 했습니다. 번거롭지만, 이 과정 덕분에 모든 코드에 “왜 이렇게 했는가”의 근거를 준비하는 습관이 생겼습니다.
완성의 경험
2주차에 기능 목록이 일정 대비 많다는 걸 깨닫고, 핵심 기능부터 완성하자고 제안했습니다. 게시판 CRUD → 이미지 업로드 → WebRTC 순서로 우선순위를 정하고, 매일 작은 단위로 완성해나갔습니다. 6주 안에 기획부터 배포까지 마무리한 첫 경험이었습니다.
About the Project
EduMeet is an online education platform that supports hearing-impaired learners through real-time speech-to-subtitle conversion. According to the Korea Association of Sign Language Interpreters, the ratio of sign language interpreters to hearing-impaired individuals is 1:300. Online lectures are virtually inaccessible without subtitles, and we believed AI speech recognition could significantly address this issue.
Duration: Jul 7 – Aug 15, 2025 (6 weeks)
Team: 6 members (3 Frontend, 3 Backend)
Tech Stack: Java, Spring Boot, JPA, QueryDSL, MySQL, AWS S3, Docker
My Role
I was responsible for backend development. Specifically, I owned board CRUD API design/implementation, S3 image upload pipeline, 127 unit tests, and layered architecture design.
Being my first team project, I expected to focus solely on feature implementation, but in reality I spent far more time on defensive logic and test code than the features themselves.
Key Implementations
N+1 Problem Fix — 12 Queries → 4, 66.9% Response Improvement
In the Board-BoardImage-Reply 3-table structure (1:N relationships), I discovered an N+1 problem where individual SELECTs for board_image fired per post during list queries. Hibernate statistics confirmed 12 JDBC statements per page (list 1 + N+1 10 + COUNT 1).
After benchmarking FetchJoin (memory pagination issue), EntityGraph (+35% degradation), SUBSELECT (Spring Data JPA session incompatibility), and BatchSize, @BatchSize(20) was selected for best pagination compatibility and performance (38.33ms → 12.66ms, 66.9% improvement).
Detailed analysis: N+1 Problem Analysis and Solution
127 Unit Tests & H2 Migration
MySQL-based tests took 9.57 seconds due to disk I/O and TCP round trips. Running tests 20-30 times daily, cumulative wait time became non-trivial. Switching to H2 in-memory reduced it to 5.23 seconds — 45% faster.
Unit tests use H2 (fast feedback), integration tests use MySQL (SQL compatibility verification). H2-MySQL differences (GROUP_CONCAT, ENUM, etc.) are caught in integration tests.
Detailed analysis: Unit Test DB Migration
S3 Image Upload Optimization — 91.8% Size Reduction
Resized original images (~5MB, 4032×3024) to thumbnails (~410KB, 800×600) for 91.8% size reduction. Compared Stream/MultipartFile/AWS Multipart upload methods and chose MultipartFile for server-side resizing requirements.
DB PKs use Auto Increment (InnoDB Clustered Index compatibility), external file names use UUID (unpredictable).
Detailed analysis: S3 Upload Optimization
Memorable Troubleshooting
JPA Entity Mapping → N+1 Resolution Flow
Three issues connected sequentially:
-
OneToMany join table: Missing
mappedBycaused JPA to auto-create aboard_image_setjoin table. Fixed withmappedBy = "board", established team rule to verify DDL against ERD. → Details -
Lazy Loading No Session: After fixing the join table,
LazyInitializationExceptionoccurred when accessing BoardImage in tests. Understood Persistence Context lifecycle and applied@EntityGraphas fundamental fix. → Details -
N+1 discovery: Understanding Lazy loading mechanics from the EntityGraph work enabled quick identification of the N+1 root cause (proxy initialization → additional queries per loop iteration). → Details
QueryDSL File Move — Architecture Principles vs Framework Rules
Moving implementation to Infrastructure layer triggered “No property searchAll found for type Board.” Spring Data JPA’s Custom Repository naming rules conflicted with layer separation. Chose extends separation + independent bean injection over AI’s 2 suggestions, based on architectural reasoning.
Detailed analysis: File Move Error
Takeaways
Defensive Logic Matters More Than Features
The board CRUD feature took just 3 days to implement. But writing test code and handling each abnormal scenario one by one took another 5 days. This was the first time I truly felt that “the feature works” and “the service is safe” are two different things.
The Value of Code Reviews
We adopted GitLab MR-based code reviews. To answer “Why did you implement it this way?”, I had to check official documentation and prepare justifications. It’s tedious, but this process built a habit of always having a rationale for every code decision.
The Experience of Completion
In week 2, I realized our feature list was too ambitious for the timeline, so I proposed completing core features first. We prioritized: Board CRUD → Image Upload → WebRTC, completing small units daily. This was my first experience of finishing everything from planning to deployment within 6 weeks.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.