N+1 문제 분석과 해결
목차
정상 상태
EduMeet은 청각장애인 대상 온라인 교육 플랫폼입니다. 게시판 기능에서 Board(게시글), BoardImage(첨부파일), Reply(댓글) 3개 테이블을 사용합니다.
테이블 구조:
board: id(PK, BIGINT), title(VARCHAR 200), content(TEXT), writer(VARCHAR 100), reg_date, mod_dateboard_image: uuid(PK, VARCHAR 255), filename(VARCHAR 255), ord(INT), board_id(FK → board.id)reply: id(PK, BIGINT), reply_text(VARCHAR 255), replayer(VARCHAR 255), board_id(FK → board.id), reg_date, mod_date
Board:BoardImage = 1:N (@OneToMany, FetchType.LAZY), Board:Reply = 1:N 관계입니다.
DB는 MySQL 8.0을 선택했습니다. 이유는 팀원 전원이 MySQL 경험이 있었고, 게시판 CRUD 중심의 Read-heavy 워크로드에서 MySQL의 InnoDB 버퍼풀이 효율적이라고 판단했기 때문입니다. 복잡한 JSON 쿼리나 Full-text 검색 요구사항이 없었기에 PostgreSQL의 추가 기능이 필요하지 않았고, 정형화된 테이블 관계(1:N)가 명확해서 MongoDB 같은 NoSQL도 배제했습니다.
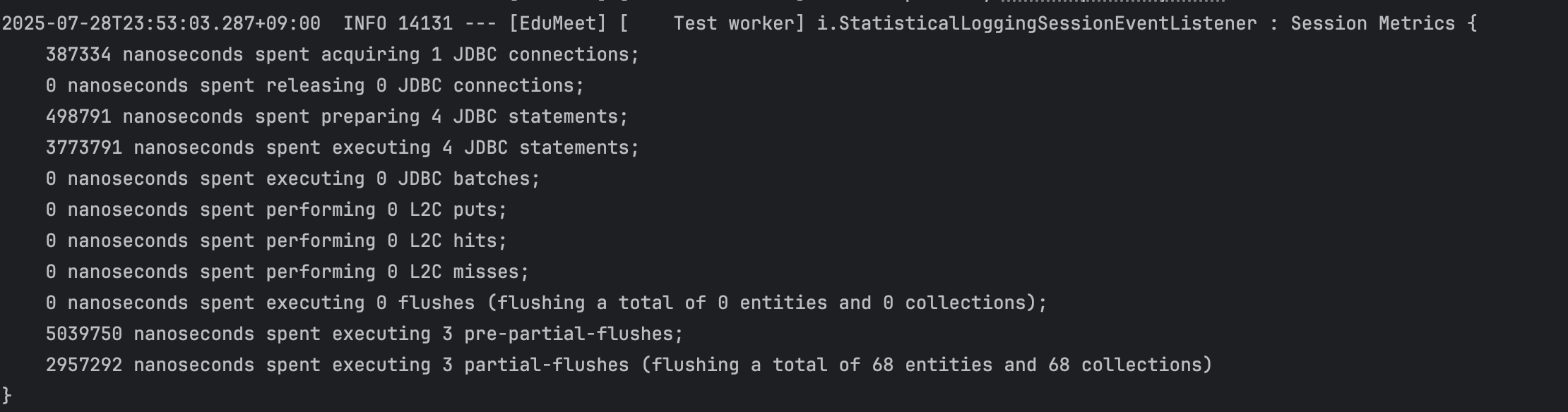
게시글 목록 조회 시 페이징된 Board 데이터를 가져오는 1개의 쿼리가 실행되고, 필요한 시점에 하위 엔티티를 조회하는 것이 정상 동작입니다.
문제 상황
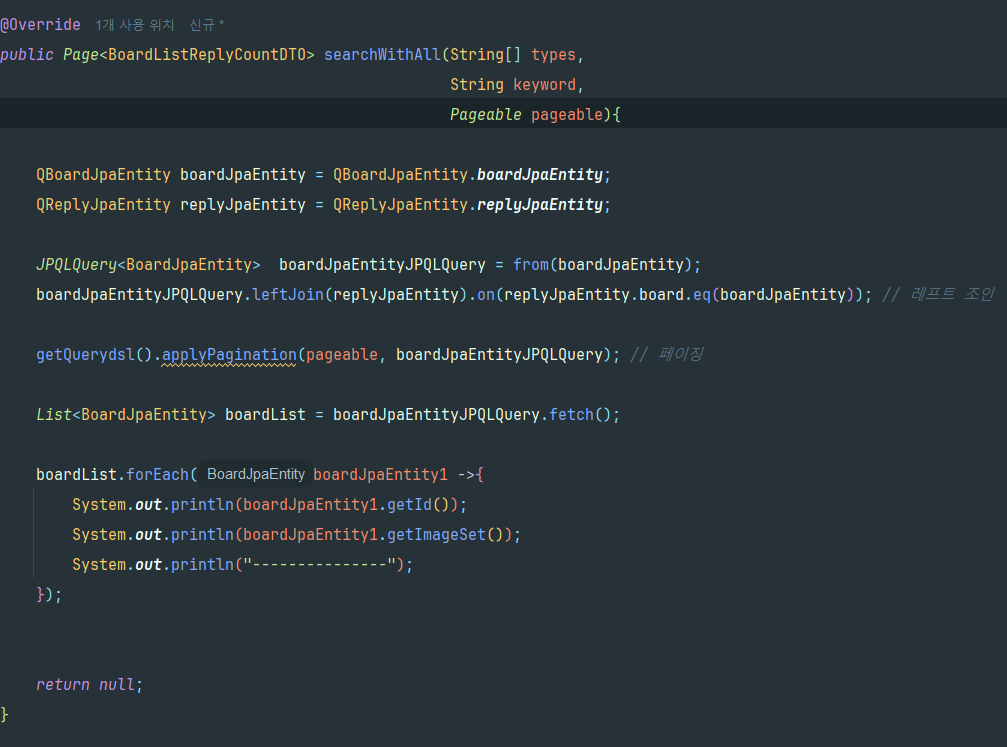
더미 데이터 100건을 넣고 Board와 Reply를 left join하는 단위 테스트를 작성했습니다.
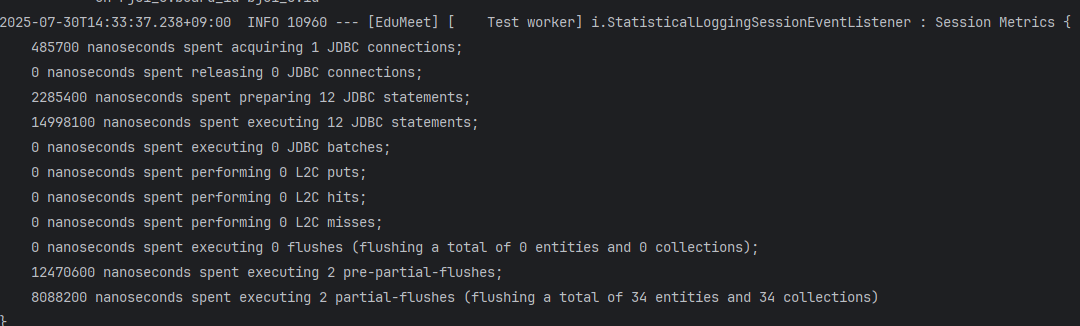
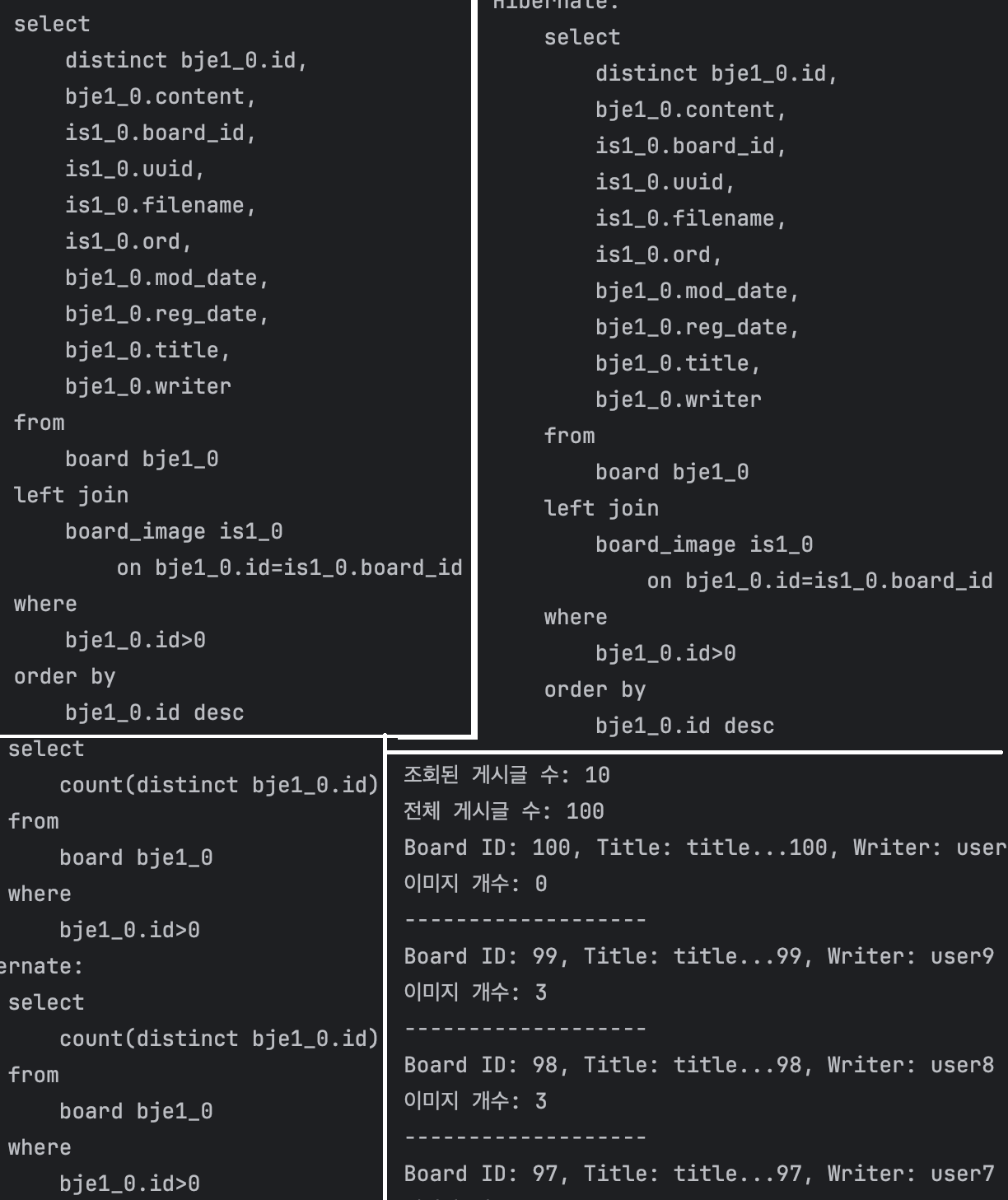
페이지 사이즈를 10으로 설정하고 테스트를 실행했는데, Hibernate 통계 기능으로 확인한 결과 JDBC statement가 12개 실행되고 있었습니다. 1(목록 조회) + 10(각 게시글의 board_image 개별 조회) + 1(페이징 COUNT 쿼리) = 12개.
실행된 쿼리 로그를 확인해보니, 목록을 가져오는 쿼리 1건 외에 각 게시글마다 board_image를 조회하는 쿼리가 개별 실행되고 있었습니다.
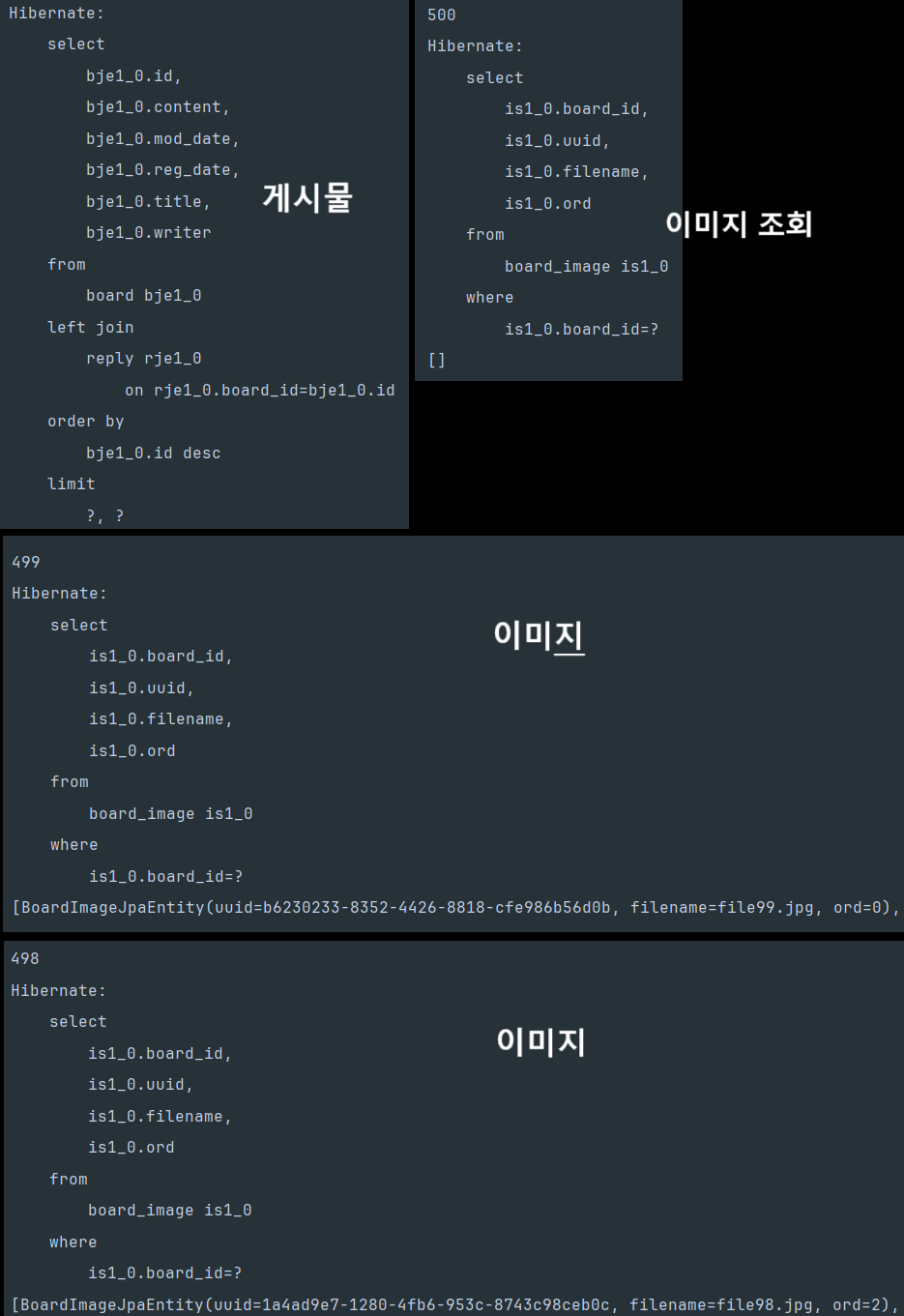
100건에서 38ms 자체는 치명적인 수치는 아닙니다. 하지만 N+1은 데이터 규모에 비례해서 쿼리 수가 증가하는 구조적 문제입니다. 페이지 사이즈가 10이면 항상 12개 쿼리(10 + 목록 + COUNT)가 실행되고, 만약 페이지 사이즈를 50으로 올리면 52개가 실행됩니다. 데이터가 늘어나는 게 아니라 페이지 사이즈에 비례해서 쿼리가 늘어나는 것이 핵심 문제이고, 운영 환경에서 연관 엔티티가 늘어나면(예: Board에 Tag, Category 등이 추가되면) 쿼리 수가 기하급수적으로 증가합니다.
원인 분석
이 현상은 N+1 문제입니다.
목록을 가져오는 쿼리 1건(+1)과, 각 게시글마다 연관 엔티티를 조회하는 쿼리 N건이 발생하는 것입니다.
실행 순서를 정리하면:
- 게시판에 대한 페이징 처리가 실행되면서
LIMIT으로 10건 조회 System.out.println()으로 게시판 ID 출력- 게시판 객체의
imageSet에 접근 → Hibernate가board_image프록시 객체를 초기화하면서SELECT * FROM board_image WHERE board_id = ?쿼리 실행 - 2~3을 10번 반복 → 총 10개의 추가 쿼리 발생
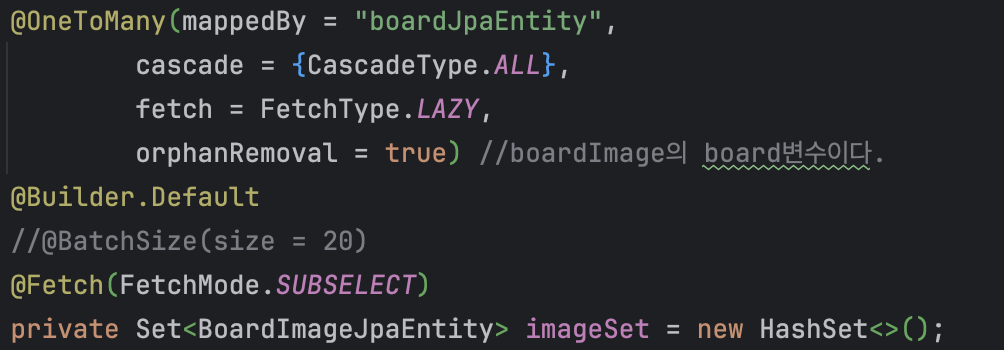
@OneToMany(fetch = FetchType.LAZY) 설정에서 하위 엔티티는 프록시 객체로 대체됩니다. 이 프록시는 실제 필드에 접근하는 시점에 Hibernate가 SELECT 쿼리를 실행해서 초기화합니다. 루프 안에서 접근하면 매 반복마다 쿼리가 나가는 구조입니다.
이 문제는 FetchType.EAGER로 바꾼다고 해결되지 않습니다.
Eager 전략이더라도 JPQL 실행 시 연관 엔티티를 개별 쿼리로 로딩하는 것은 동일합니다. JPQL은 엔티티의 fetch 전략을 무시하고 SQL을 그대로 실행하기 때문입니다.
N+1 문제의 해결 방법은 4가지가 있습니다.
해결 방법 4가지
1. FetchJoin
JPQL의 JOIN FETCH 키워드를 사용하여 연관 엔티티를 한 번의 쿼리로 함께 조회하는 방법입니다.
JOIN FETCH: Inner Join 쿼리 실행LEFT JOIN FETCH: Left Outer Join 쿼리 실행
Inner Join이 Left Join보다 검색 범위가 좁아 성능이 우수하므로, 하위 엔티티가 반드시 존재하는 경우에는 Inner Join을 사용하는 것이 좋습니다.
장점: 한 번의 쿼리로 연관 엔티티를 모두 조회, DB 왕복 횟수 최소화, LazyInitializationException 방지
단점: 페이징 처리 시 메모리에서 처리, 1:N 조인으로 데이터 중복 발생, 여러 @OneToMany 컬렉션을 동시에 Fetch Join할 수 없음
주의사항:
- 별칭 사용 주의: Left Join Fetch에서 별칭을 사용하면 DB와의 데이터 일관성을 해칠 수 있습니다.

- 카테시안 곱 중복 발생:
@OneToMany컬렉션을 Fetch Join할 때 발생합니다.
Hibernate 6부터는 자동으로 중복을 필터링하지만, 명시적으로DISTINCT를 선언하는 편이 의도가 명확합니다.
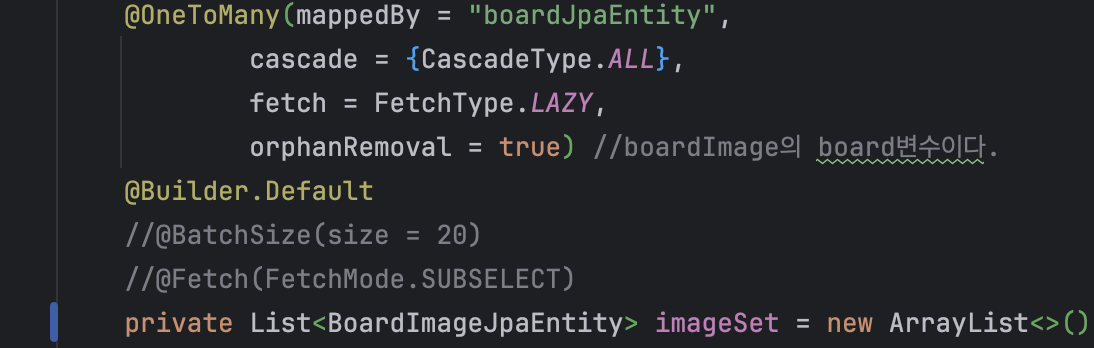
- 컬렉션 2개 이상 동시 Fetch Join 금지:
@XToMany컬렉션 필드는 하나만 Fetch Join 가능합니다.
두 개 이상이면MultipleBagFetchException이 발생합니다.
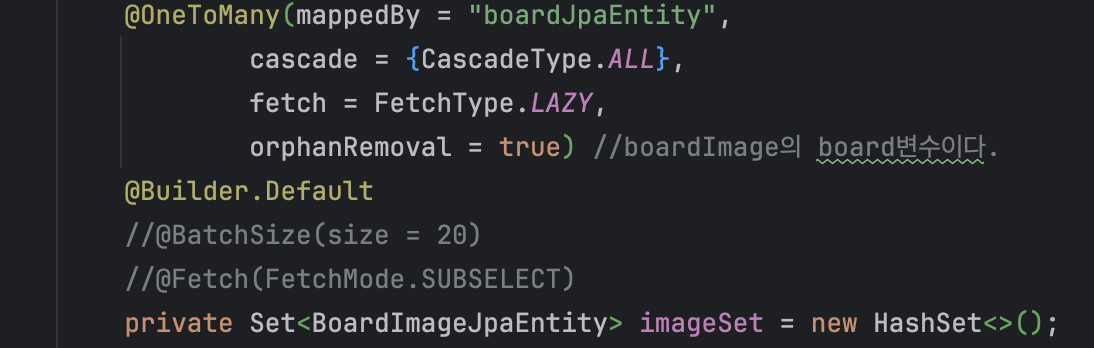
List 대신 Set을 사용하면 회피할 수 있습니다.
변경 전 (에러 발생)
변경 후 (에러 해결)
- 페이징 금지:
@XToMany컬렉션을 Fetch Join한 상태에서 페이징하면, Hibernate가 모든 데이터를 메모리에 로드 후 애플리케이션 레벨에서 페이징을 수행합니다.
결론: 현재 게시판은 페이징이 필수이므로, FetchJoin 단독 사용은 부적합합니다.
2. EntityGraph
@EntityGraph는 JPA가 제공하는 어노테이션으로, Fetch Join을 선언적으로 사용하는 방법입니다.
내부적으로 Left Join 기반으로 동작합니다.
장점: 쿼리 메서드만으로 구현 가능, 동적 fetch 전략 변경 가능, Named Graph로 재사용 가능
단점: 항상 Left Join으로 동작, Fetch Join과 동일한 제약사항 (페이징 불가, 카테시안 곱 문제)
3. @Fetch(FetchMode.SUBSELECT)
첫 번째 쿼리로 부모 엔티티를 조회한 후, 두 번째 쿼리에서 서브쿼리를 사용하여 연관된 모든 자식 엔티티를 한 번에 조회하는 방식입니다.
장점: 서브쿼리로 한 번에 연관 데이터 로딩 (총 2개 쿼리), 중복 데이터 없음
단점: 첫 번째 쿼리 결과 전체를 기반으로 두 번째 쿼리가 실행, 대용량 데이터에서 비효율적
4. @BatchSize
여러 개의 프록시 객체를 조회할 때, WHERE 절이 같은 여러 SELECT 쿼리들을 하나의 IN 쿼리로 합쳐주는 옵션입니다.
장점: 페이징과 완벽 호환, N+1 문제를 N/size로 완화, 메모리 효율적, 중복 데이터 없음
단점: 완전한 해결은 아님 (여전히 추가 쿼리 실행), 최적의 batch size 튜닝 필요
실측 비교
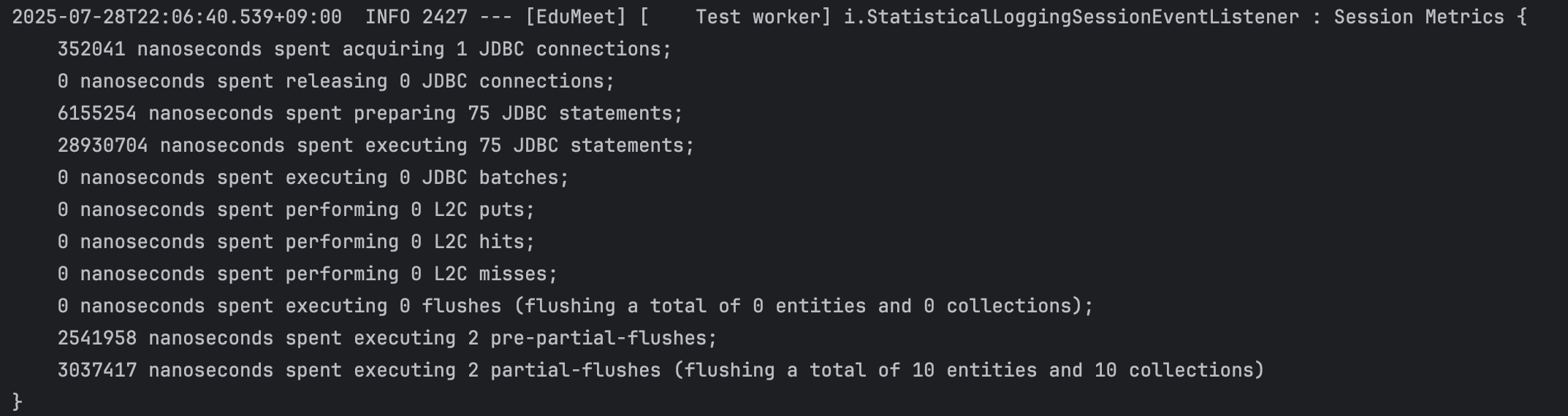
각 전략의 실제 성능을 비교하기 위해 Hibernate 통계 기능을 활성화했습니다.
기존 N+1 상태

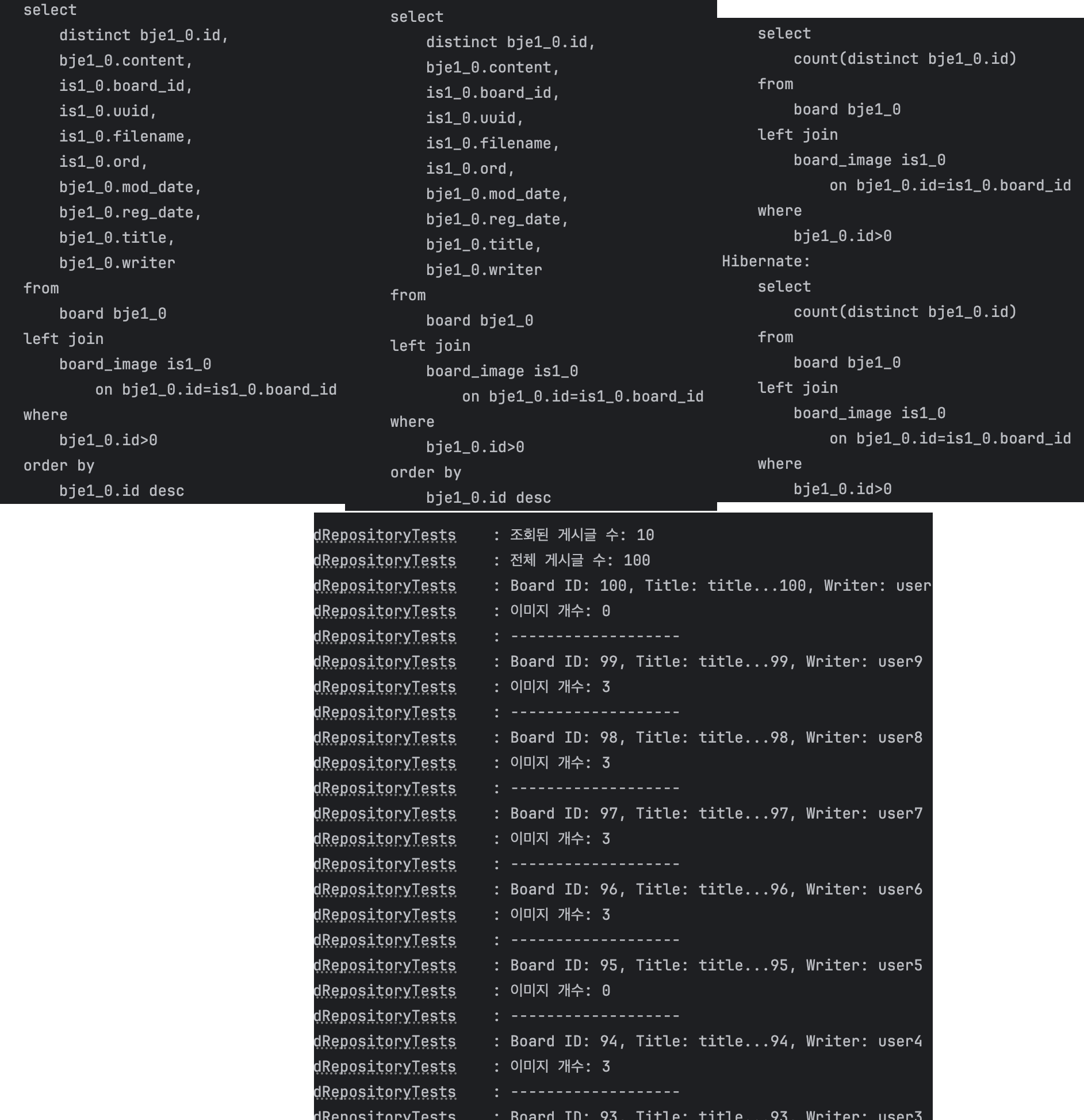
FetchJoin 적용
테스트 결과:
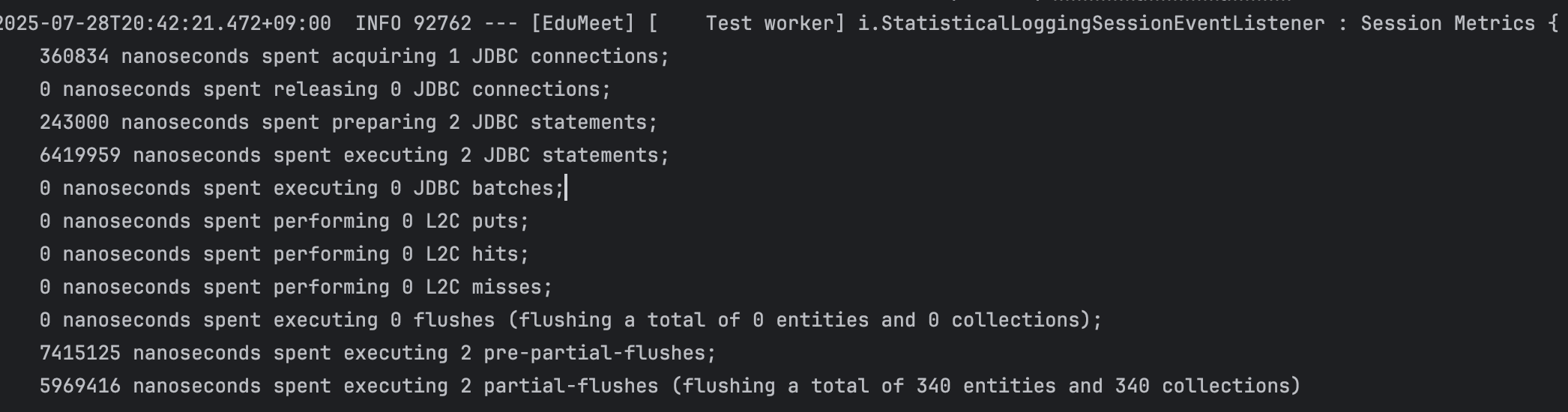
N+1은 해결되었지만 메모리 페이징 경고가 발생했습니다.

HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
EntityGraph 적용

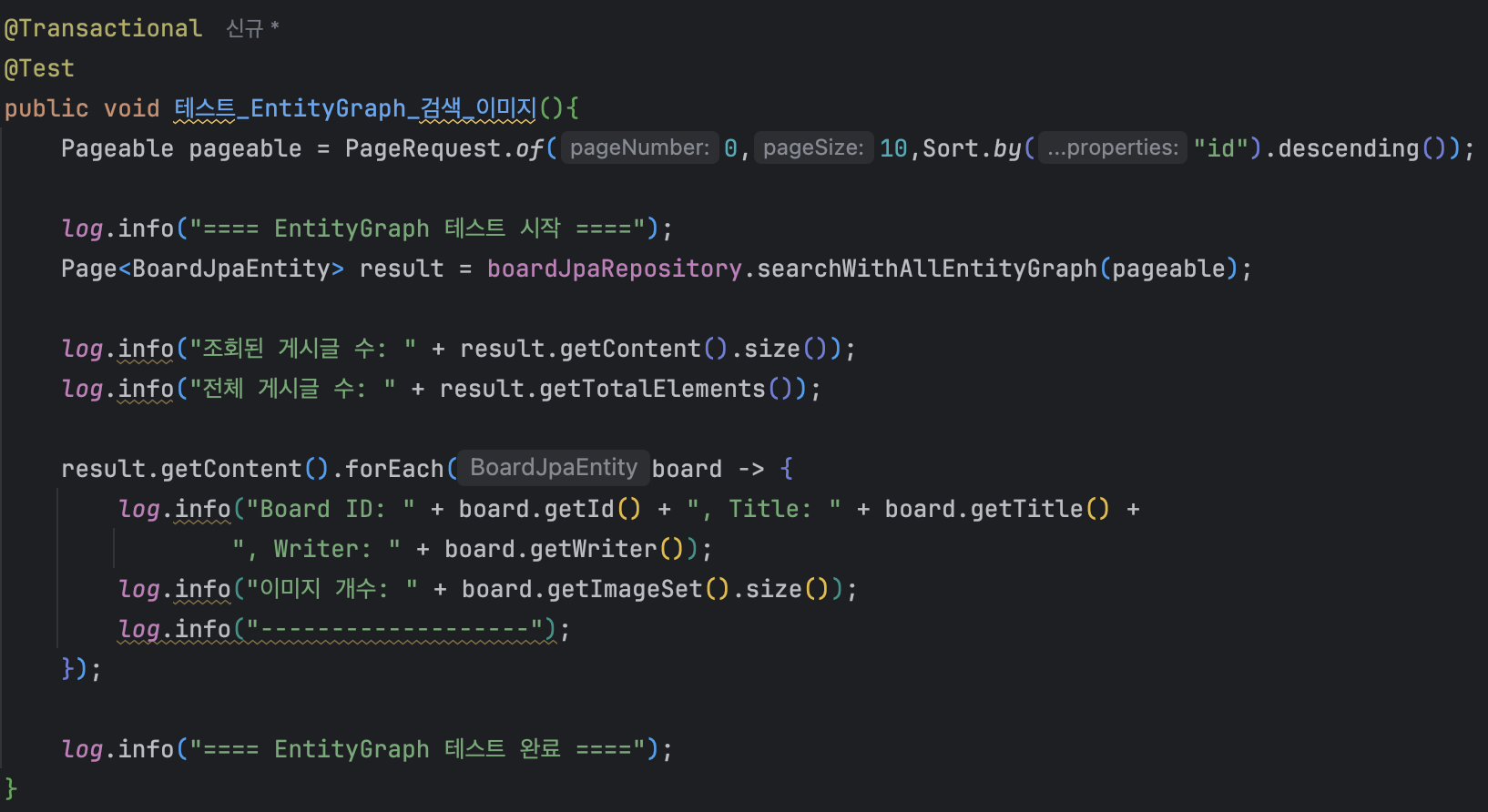
FetchJoin과 동일하게 메모리 페이징 경고가 발생했습니다.

FetchJoin과 EntityGraph의 핵심 차이: COUNT 쿼리
FetchJoin의 COUNT 쿼리는 left join board_image를 포함하지만, EntityGraph의 COUNT 쿼리는 board 테이블만 조회합니다.
EntityGraph가 COUNT 쿼리에서 불필요한 JOIN을 하지 않아 더 효율적입니다.


SUBSELECT 적용
기대와 달리 쿼리가 대량으로 실행됐습니다.
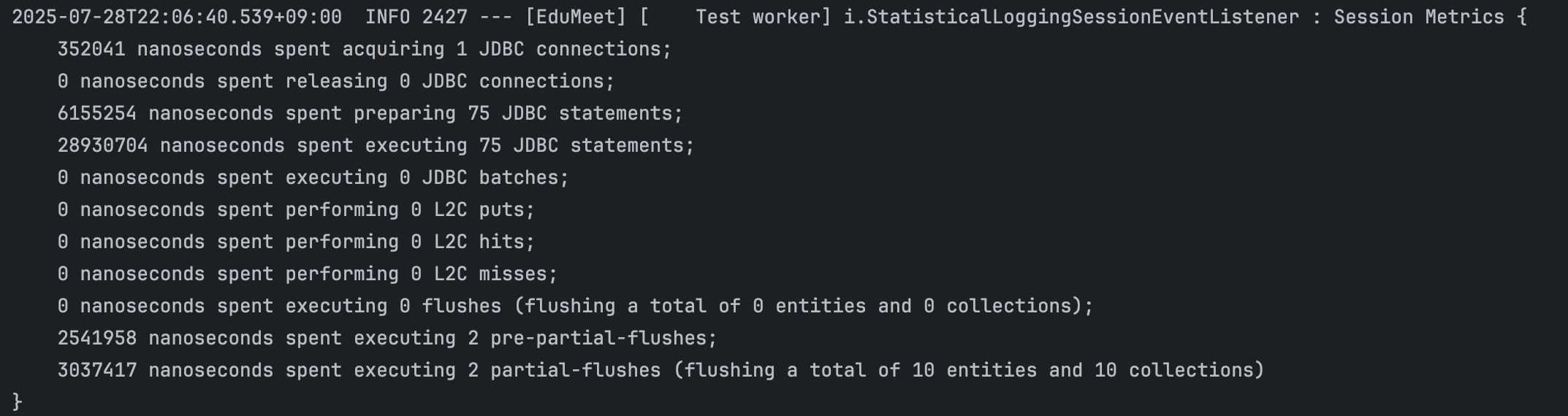
총 75개의 JDBC statements가 실행됐습니다.

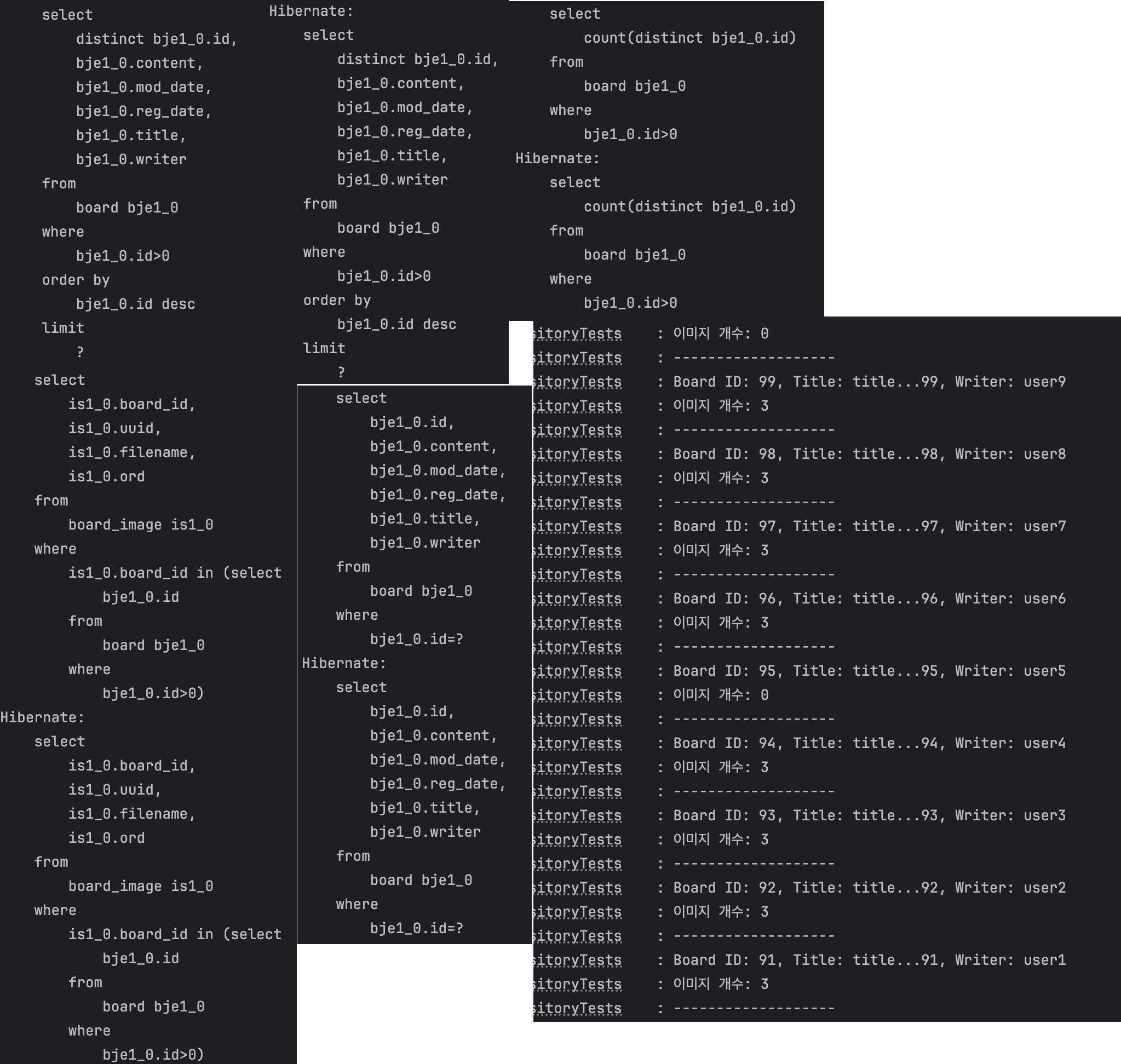
실패 원인: Hibernate의 SUBSELECT 최적화는 동일 Persistence Context 내에서 실행된 원본 쿼리를 기반으로 서브쿼리를 생성합니다. 그런데 Spring Data JPA의 Page 인터페이스는 COUNT 쿼리와 데이터 쿼리를 분리해서 실행하면서, SUBSELECT가 참조할 원본 쿼리 컨텍스트가 달라져 최적화 조건을 위반했습니다.

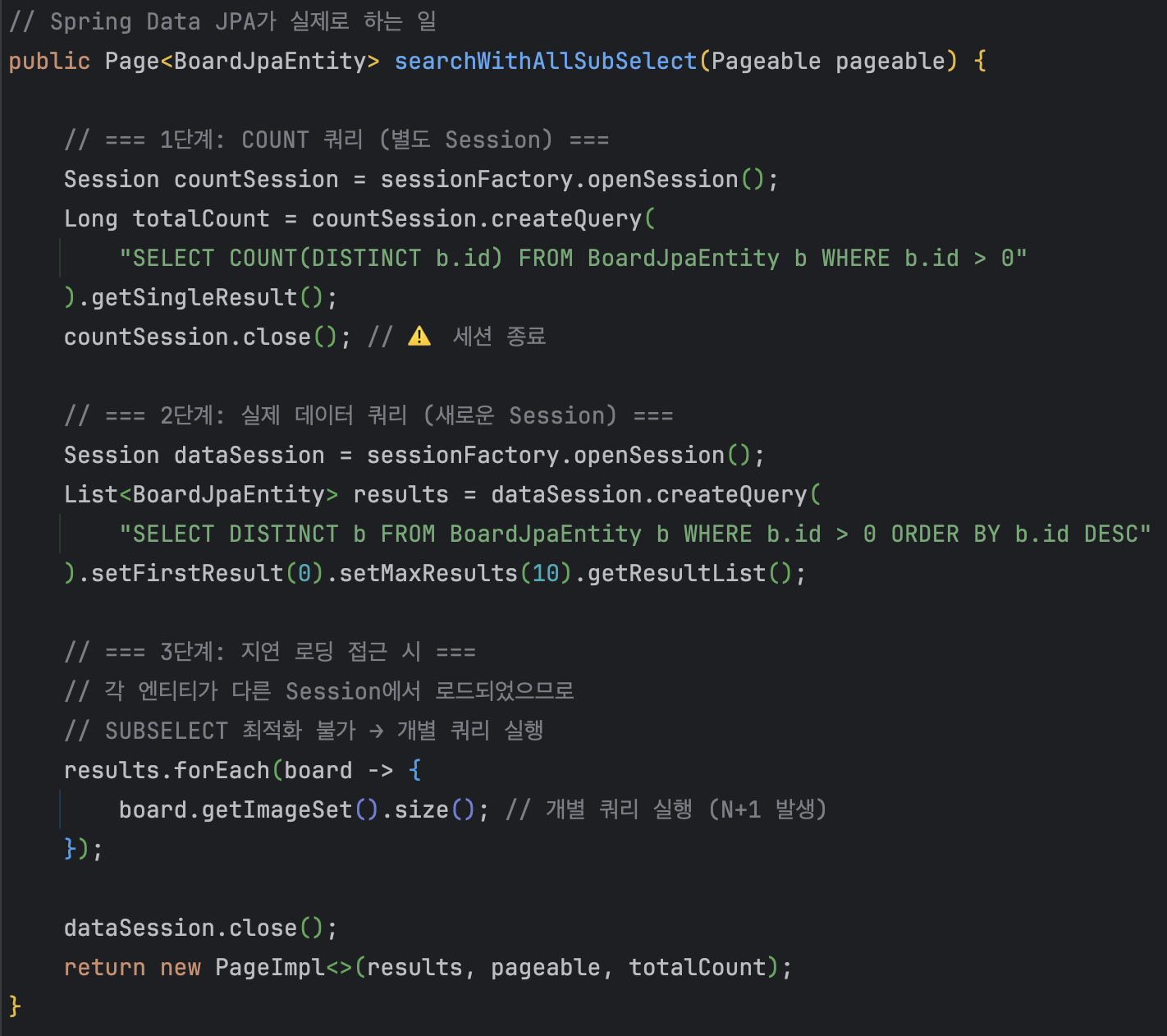
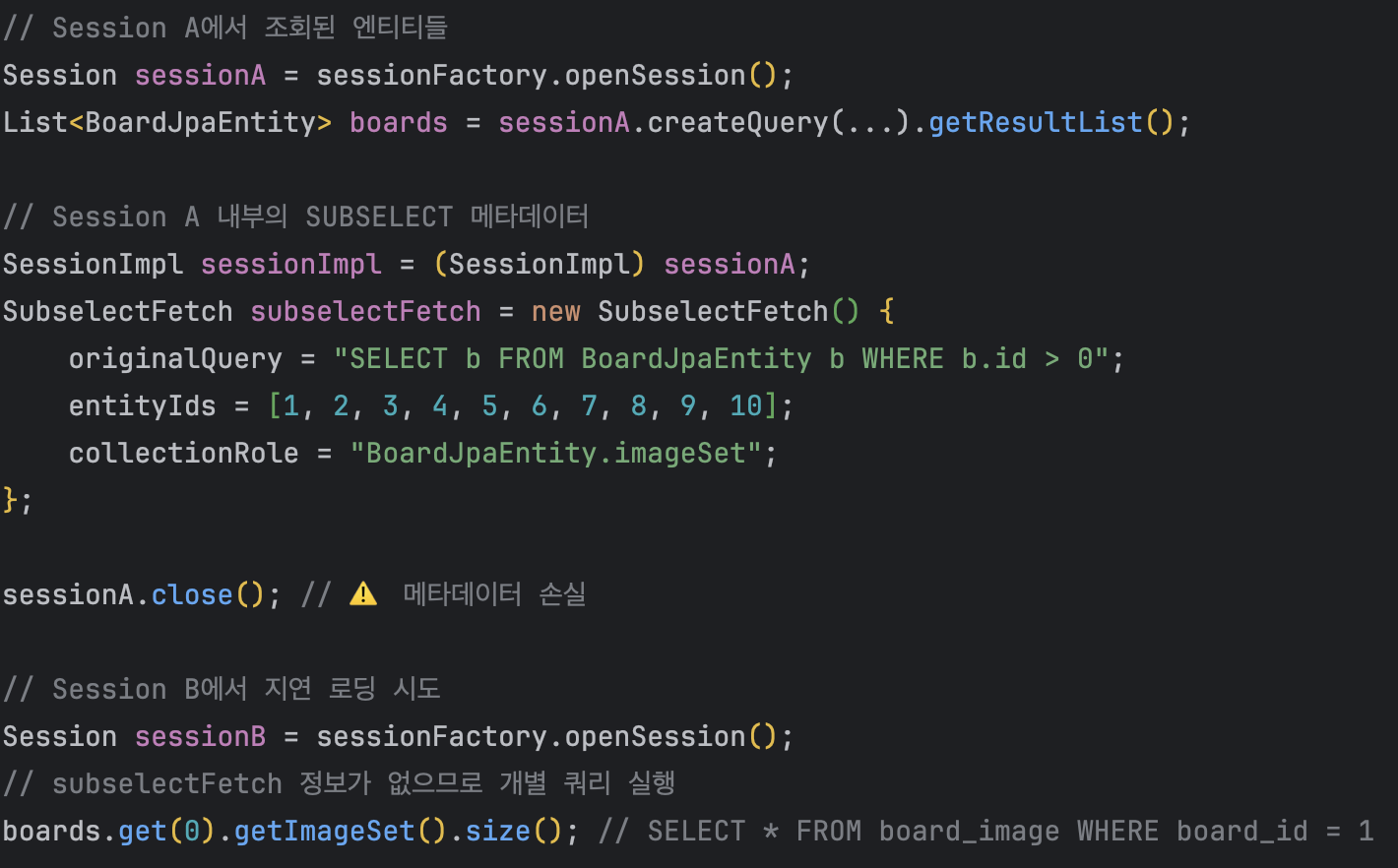
수동 Session 관리를 시도했으나, 전체 Parent ID 기준으로 SUBSELECT가 실행되는 문제가 발생했습니다.
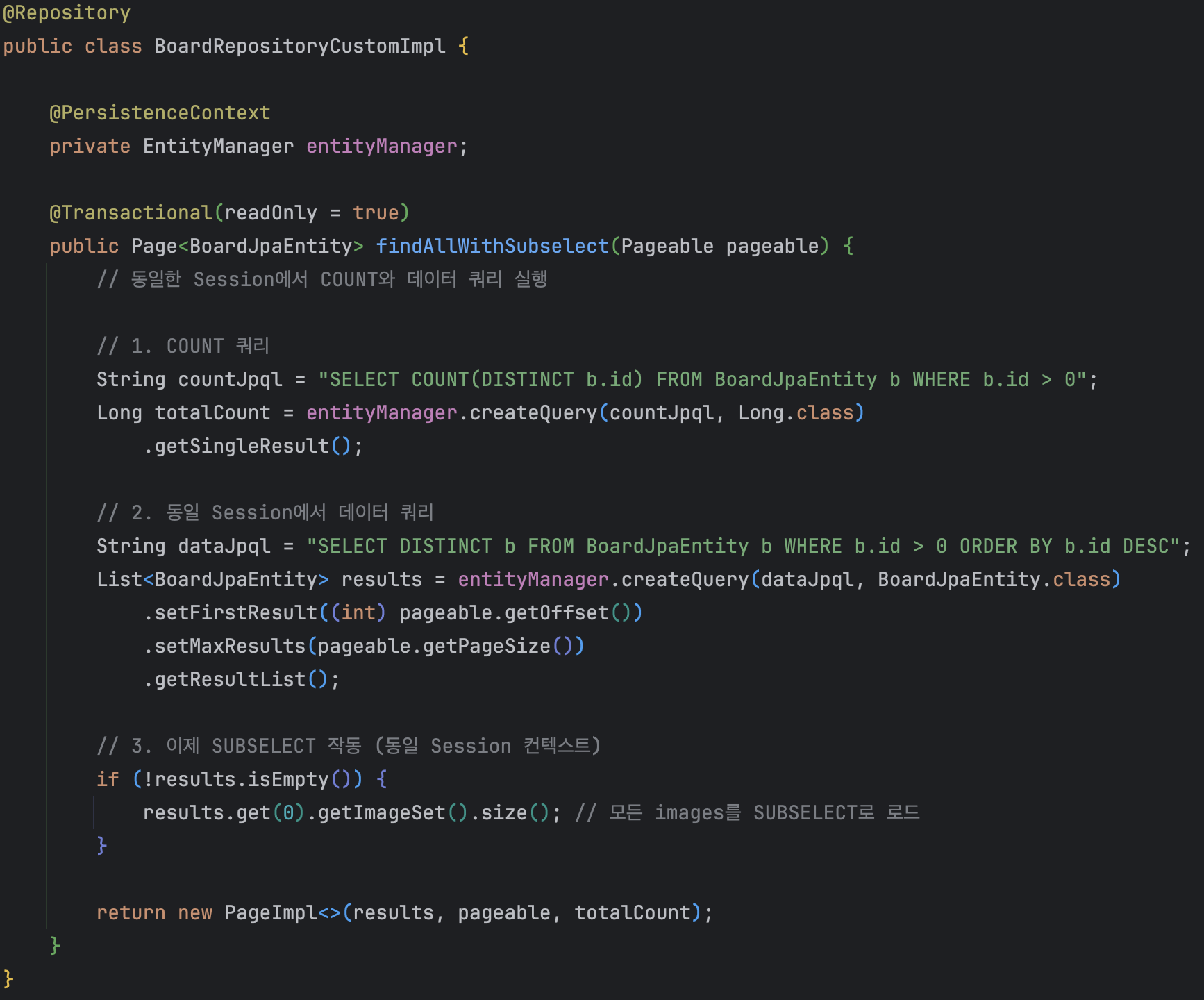

결론: SUBSELECT는 Spring Data JPA의 페이징 처리 방식과 근본적으로 호환되지 않습니다.
BatchSize 적용
@BatchSize(size = 20) 적용 결과 4개 쿼리만 실행됐습니다:
-- 1번째: 목록 조회 쿼리SELECT b.id, b.content, b.mod_date, b.reg_date, b.title, b.writerFROM board b LEFT JOIN reply r ON r.board_id = b.idORDER BY b.id DESC LIMIT 10;
-- 2번째: BatchSize가 작동한 이미지 조회 쿼리SELECT is1_0.board_id, is1_0.uuid, is1_0.filename, is1_0.ordFROM board_image is1_0WHERE is1_0.board_id IN (100, 99, 98, 97, 96, 95, 94, 93, 92, 91);
-- 3번째: findAll 쿼리-- 4번째: COUNT 쿼리
전체 비교
측정 환경 및 방법
- 환경: macOS, JDK 17, Spring Boot 3.x, MySQL 8.0 (Docker), 더미 데이터 100건
- 방법: Hibernate 통계 기능(
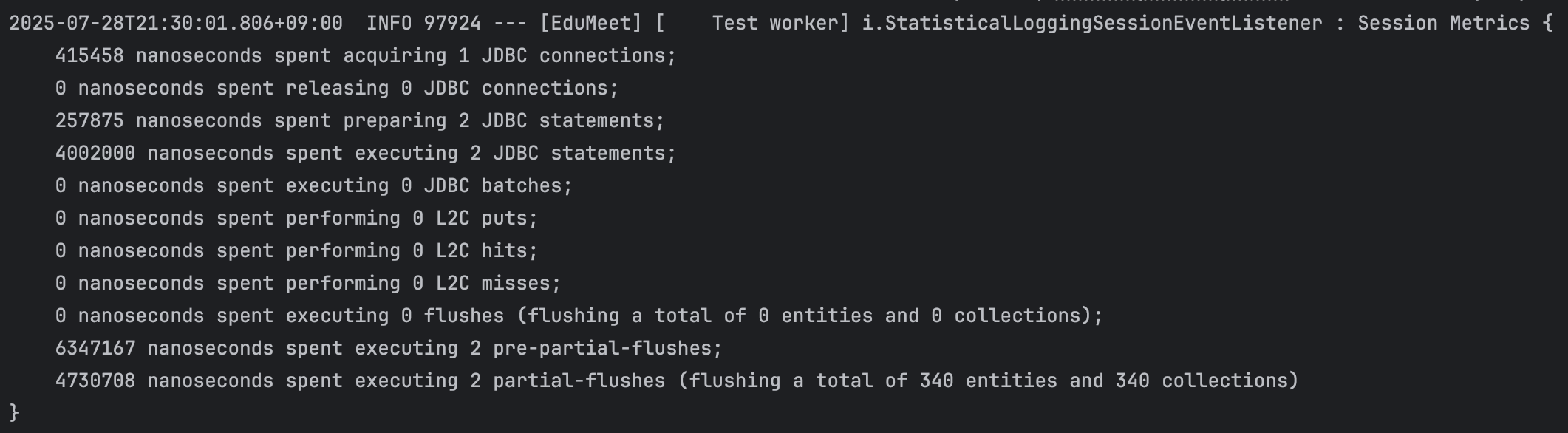
hibernate.generate_statistics=true)을 활성화하여, 각 전략당 동일 테스트를 5회 반복 실행한 뒤 중간 3회의 평균을 취했습니다. 첫 번째와 마지막 실행은 JVM warm-up과 GC 영향을 배제하기 위해 제외했습니다. - 측정 항목: JDBC Connection 획득, Statement Prepare, Execute, Pre-Flush, Flush 각 단계의 소요 시간
성능 비교 표 (단위: ms, 5회 중 중간 3회 평균)
| 전략 | Conn. | Prep. | Exec. | Pre-Flush | Flush | Total Time |
|---|---|---|---|---|---|---|
| N+1 (기본) | 0.49 | 2.29 | 14.99 | 12.47 | 8.09 | 38.33 ms |
@FetchJoin | 0.36 | 0.24 | 6.42 | 7.42 | 5.97 | 20.41 ms |
@EntityGraph | 0.42 | 0.26 | 40.02 | 6.35 | 4.73 | 51.78 ms |
@Fetch(SUBSELECT) | 0.35 | 6.16 | 28.93 | 2.54 | 3.04 | 40.99 ms |
@BatchSize(20) | 0.39 | 0.50 | 3.77 | 5.04 | 2.96 | 12.66 ms |
성능 개선율 (기준: N+1 = 38.33ms)
| 전략 | Total(ms) | 개선율 |
|---|---|---|
| N+1 | 38.33 | - |
@FetchJoin | 20.41 | 46.7% 개선 |
@EntityGraph | 51.78 | 성능 악화 (+35.1%) |
@Fetch(SUBSELECT) | 40.99 | 성능 저하 (+6.9%) |
@BatchSize(20) | 12.66 | 66.9% 개선 |
적용: @BatchSize 선택
이 프로젝트에서는 @BatchSize(size = 20)로 N+1 문제를 해결했습니다.
왜 BatchSize인가: 선택하지 않은 이유까지
| 전략 | 탈락 이유 |
|---|---|
| FetchJoin | @OneToMany 컬렉션을 Fetch Join하면 Hibernate가 모든 데이터를 메모리에 로드한 뒤 애플리케이션 레벨에서 페이징합니다. 게시판은 페이징이 필수이므로 사용 불가 |
| EntityGraph | FetchJoin과 동일하게 Left Join 기반이라 메모리 페이징 경고가 발생했고, 실측에서 오히려 성능이 악화(+35.1%)됐습니다 |
| SUBSELECT | Hibernate SUBSELECT는 동일 Persistence Context 내 원본 쿼리 기반으로 서브쿼리를 생성하는데, Spring Data JPA의 Page가 COUNT와 데이터 쿼리를 분리 실행하면서 이 전제가 깨졌습니다. 75개 JDBC statement가 실행되는 결과 |
BatchSize(20) 값의 근거
Hibernate 커뮤니티와 Vlad Mihalcea, Thorben Janssen 등 주요 레퍼런스에서 batch size는 10~50 범위를 권장합니다. 이 프로젝트에서 20을 선택한 이유:
- 페이지 사이즈가 10이므로, batch size = 20이면 한 페이지의 모든 연관 엔티티를 1~2개의 IN 쿼리로 처리 가능
- batch size를 50으로 올려봤지만, IN 절에 들어가는 ID 수가 늘어나도 쿼리 수는 이미 1~2개라 추가 이득 없음
- batch size를 10으로 낮추면 페이지 사이즈와 동일해서 항상 2개 쿼리가 실행. 20이면 1개로 줄어드는 경우가 더 많음
선택 이유:
- 페이징 호환: Spring Data JPA의 Page 인터페이스와 완벽하게 호환
- 성능: 66.9% 개선으로 4가지 중 가장 우수 (38.33ms → 12.66ms)
- 쿼리 수 예측 가능: N+1에서 N이 쿼리 수를 결정했지만, BatchSize에서는 ceil(N/size)로 계산 가능. 10건 조회 시 항상 2~4개 쿼리
- 적용 용이성: 어노테이션 하나로 적용 가능, 기존 코드 변경 없음
DB 부하 관점
쿼리 수 감소는 응답 시간만 줄이는 데 그치지 않습니다. DB 서버 관점에서도 직접적인 영향이 있습니다.
- N+1 상태에서 페이지 요청 1건당 JDBC statement 12개 → BatchSize 적용 후 4개. DB의 쿼리 파싱, 실행 계획 생성, 커넥션 점유 횟수가 약 67% 감소
- 동시 사용자가 10명이면 N+1에서는 120개 쿼리가 동시에 DB에 들어가지만, BatchSize에서는 40개로 줄어듭니다
- 이 차이는 운영 환경에서 RDS 인스턴스 스펙 선정에 직접 영향을 줍니다. 쿼리 부하가 낮으면 더 작은 인스턴스로 운영 가능하고, AWS RDS 비용에서 한 단계 다운스케일(예: db.t3.medium → db.t3.small)은 월 약 3~4만원 차이
상황별 최적 전략
게시글 목록 조회 (페이징 필요) → BatchSize 권장

단일 게시글 상세 조회 → EntityGraph 권장

특정 게시글 소량 조회 (페이징 불필요) → FetchJoin 권장

N+1은 왜 ORM 차원에서 해결하지 않는가
N+1은 “버그”가 아니라 트레이드오프입니다.
Lazy 로딩은 “필요한 시점에 필요한 데이터만 로드한다”는 설계 원칙을 따릅니다.
문제가 되는 것은 “목록 조회 후 연관 엔티티에 접근”하는 패턴이 빈번하기 때문입니다.
Hibernate는 FetchJoin, EntityGraph, BatchSize 등 상황에 맞는 최적화 도구를 제공하여 개발자가 선택할 수 있도록 하고 있습니다.
ORM이 모든 경우를 자동으로 최적화하면, 반대로 불필요한 데이터까지 로드하는 문제가 생깁니다.
사용자에게 선택권을 주는 것이 올바른 설계 판단입니다.
Reference
Normal Behavior
EduMeet is an online education platform for the hearing-impaired. The board feature uses 3 tables: Board (posts), BoardImage (attachments), and Reply (comments).
Table structure:
board: id(PK, BIGINT), title(VARCHAR 200), content(TEXT), writer(VARCHAR 100), reg_date, mod_dateboard_image: uuid(PK, VARCHAR 255), filename(VARCHAR 255), ord(INT), board_id(FK → board.id)reply: id(PK, BIGINT), reply_text(VARCHAR 255), replayer(VARCHAR 255), board_id(FK → board.id), reg_date, mod_date
Board:BoardImage = 1:N (@OneToMany, FetchType.LAZY), Board:Reply = 1:N.
MySQL 8.0 was chosen because all team members had MySQL experience, and InnoDB’s buffer pool is efficient for the Read-heavy CRUD workload. No complex JSON queries or full-text search requirements meant PostgreSQL’s extra features weren’t needed, and the well-defined 1:N relationships made NoSQL like MongoDB unnecessary.
When retrieving a post list, a single query should fetch paginated Board data, with child entities loaded on demand.
The Problem
After inserting 100 dummy records and writing a unit test with Board and Reply left join, Hibernate statistics showed 12 JDBC statements executing: 1 (list query) + 10 (individual board_image SELECTs per post) + 1 (pagination COUNT query) = 12.
The query log revealed that beyond the list query, individual queries for board_image were being executed for each post.
38ms for 100 records isn’t critical by itself. But N+1 is a structural problem where query count grows proportionally with page size. With page size 10, 12 queries always execute (10 + list + COUNT); with page size 50, it becomes 52. The core issue is queries scaling with page size, and in production with more related entities (Tags, Categories, etc.), query count grows exponentially.
Root Cause
This is the N+1 problem: 1 query to fetch the list (+1) and N queries to fetch related entities for each post.
With @OneToMany(fetch = FetchType.LAZY), child entities are replaced with proxy objects. Hibernate executes a SELECT query to initialize these proxies when actual fields are accessed. Inside a loop, this means additional queries on every iteration.
Switching to FetchType.EAGER doesn’t solve this — JPQL ignores entity fetch strategies and executes SQL directly, so related entities are still loaded with individual queries.
There are 4 solutions to the N+1 problem.
Four Solutions
1. FetchJoin
Uses JPQL’s JOIN FETCH keyword to retrieve related entities in a single query.
Pros: Single query for all related entities, minimized DB round trips
Cons: In-memory pagination, data duplication from 1:N joins, cannot simultaneously Fetch Join multiple @OneToMany collections
Critical: Pagination is forbidden with @XToMany collection Fetch Join — Hibernate loads all data into memory and paginates at the application level.
2. EntityGraph
JPA annotation for declarative Fetch Join. Operates on Left Join internally.
Pros: Simple implementation with query methods, dynamic fetch strategy changes
Cons: Always Left Join, same constraints as Fetch Join
3. @Fetch(FetchMode.SUBSELECT)
After the first query fetches parent entities, a second query uses a subquery to load all related child entities at once.
Pros: Single subquery for all related data (2 queries total), no duplicates
Cons: Second query runs based on entire first query result, inefficient with large datasets
4. @BatchSize
Combines multiple SELECT queries with identical WHERE clauses into a single IN query.
Pros: Perfect pagination compatibility, reduces N+1 to N/size, memory efficient, no duplicates
Cons: Not a complete solution (still executes additional queries), requires batch size tuning
Real Benchmarks
Hibernate statistics were enabled to compare actual performance of each strategy.
Measurement Environment and Method
- Environment: macOS, JDK 17, Spring Boot 3.x, MySQL 8.0 (Docker), 100 dummy records
- Method: Hibernate statistics (
hibernate.generate_statistics=true) enabled. Each strategy was run 5 times, with the middle 3 averaged. First and last runs excluded to eliminate JVM warm-up and GC effects. - Metrics: Time for each JDBC phase — Connection acquisition, Statement Prepare, Execute, Pre-Flush, Flush
Performance Comparison (unit: ms, average of middle 3 of 5 runs)
| Strategy | Conn. | Prep. | Exec. | Pre-Flush | Flush | Total Time |
|---|---|---|---|---|---|---|
| N+1 (default) | 0.49 | 2.29 | 14.99 | 12.47 | 8.09 | 38.33 ms |
@FetchJoin | 0.36 | 0.24 | 6.42 | 7.42 | 5.97 | 20.41 ms |
@EntityGraph | 0.42 | 0.26 | 40.02 | 6.35 | 4.73 | 51.78 ms |
@Fetch(SUBSELECT) | 0.35 | 6.16 | 28.93 | 2.54 | 3.04 | 40.99 ms |
@BatchSize(20) | 0.39 | 0.50 | 3.77 | 5.04 | 2.96 | 12.66 ms |
Improvement Rate (baseline: N+1 = 38.33ms)
| Strategy | Total(ms) | Improvement |
|---|---|---|
| N+1 | 38.33 | - |
@FetchJoin | 20.41 | 46.7% faster |
@EntityGraph | 51.78 | Degraded (+35.1%) |
@Fetch(SUBSELECT) | 40.99 | Degraded (+6.9%) |
@BatchSize(20) | 12.66 | 66.9% faster |
Key findings:
- SUBSELECT is fundamentally incompatible with Spring Data JPA’s pagination — Hibernate’s SUBSELECT optimization generates subqueries based on the original query within the same Persistence Context, but Spring Data JPA’s Page interface separates COUNT and data queries, breaking the context SUBSELECT relies on.
- FetchJoin vs EntityGraph: The core difference is in COUNT queries. EntityGraph’s COUNT query only scans the
boardtable, while FetchJoin’s includes unnecessary joins.
Applied: @BatchSize Selected
This project solved the N+1 problem with @BatchSize(size = 20).
Why BatchSize — Including Why Others Were Rejected
| Strategy | Rejection Reason |
|---|---|
| FetchJoin | Fetch Join on @OneToMany collections causes Hibernate to load all data into memory and paginate at application level. Board listing requires pagination, so this is unusable |
| EntityGraph | Same Left Join basis as FetchJoin, triggered memory pagination warning. Actual benchmark showed degradation (+35.1%) |
| SUBSELECT | Hibernate SUBSELECT generates subqueries based on the original query within the same Persistence Context. Spring Data JPA’s Page separates COUNT and data queries, breaking this precondition. 75 JDBC statements executed |
Why BatchSize(20) Specifically
Hibernate community references (Vlad Mihalcea, Thorben Janssen) recommend batch size 10-50. Reasons for 20:
- Page size is 10, so batch size 20 handles all related entities in 1-2 IN queries
- Tested with 50 — no additional benefit since query count was already 1-2
- With 10, it always executes 2 queries; with 20, it often reduces to 1
Reasons:
- Pagination compatible: Works perfectly with Spring Data JPA’s Page interface
- Performance: Best improvement at 66.9% (38.33ms → 12.66ms)
- Predictable query count: N+1’s N determined query count, but BatchSize uses ceil(N/size). 10 records = always 2-4 queries
- Ease of use: Applied with a single annotation, no existing code changes
DB Load Perspective
Reducing query count isn’t just about response time — it directly impacts DB server resources:
- N+1: 12 JDBC statements per page request → BatchSize: 4. ~67% reduction in query parsing, execution plan generation, and connection occupancy
- With 10 concurrent users, N+1 sends 120 queries simultaneously vs. 40 with BatchSize
- This difference directly affects RDS instance sizing in production. Lower query load means smaller instances, and downscaling one tier (e.g., db.t3.medium → db.t3.small) saves roughly $30-40/month on AWS RDS
Optimal Strategy by Scenario
- Post list with pagination → BatchSize recommended
- Single post detail view → EntityGraph recommended
- Small batch retrieval without pagination → FetchJoin recommended
Why Doesn’t ORM Solve N+1 Automatically?
N+1 is not a “bug” — it’s a trade-off.
Lazy loading follows the design principle of “load only the data you need, when you need it.” The problem arises because the pattern of “fetching a list then accessing related entities” is so common. Hibernate provides optimization tools for different situations (FetchJoin, EntityGraph, BatchSize), letting developers choose.
If ORM automatically optimized every case, it would conversely cause problems by loading unnecessary data. Giving users the choice is the correct design decision.
Reference

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.