
[트러블슈팅] Prometheus 알림 폭풍
서버 재시작할 때마다 알림이 50-100건씩 쏟아져서 정작 중요한 알림을 놓치고 있었다. for 절과 inhibit_rules로 노이즈를 90% 줄인 과정을 정리한다.
검색 결과가 없습니다
제목, 태그, 카테고리로 검색
서버 재시작할 때마다 알림이 50-100건씩 쏟아져서 정작 중요한 알림을 놓치고 있었다. for 절과 inhibit_rules로 노이즈를 90% 줄인 과정을 정리한다.

Exception 로그가 여러 줄로 분리되어 Grafana에서 스택트레이스 검색이 안 됐다. Log4j2 JSON 포맷 + Promtail JSON 파이프라인으로 해결한 과정을 정리한다.

userId 기반 파티셔닝 때문에 헤비 유저의 이벤트가 한 파티션에 몰리면서 Lag 편차가 10배까지 벌어졌다. uploadId 기반으로 바꿔서 해결한 과정을 정리한다.

동시 요청 제한 없이 AI 서버에 보내다가 하루 5-10회 GPU OOM이 터졌다. ThreadPool + Semaphore 이중 동시성 제어로 OOM 0회를 달성한 과정을 정리한다.

음성 기반 노래 추천 플랫폼 오락가락을 5주간 개발하며 Kafka 파이프라인, GPU OOM 방어, Prometheus+Grafana 모니터링을 구축한 이야기입니다.

파일 업로드 후 동기 처리로 5-30초 걸리던 구조를 Kafka 기반 비동기 파이프라인으로 바꿔 200ms 이내 응답 + DLQ 패턴으로 실패 복구까지 구현한 과정을 정리한다.
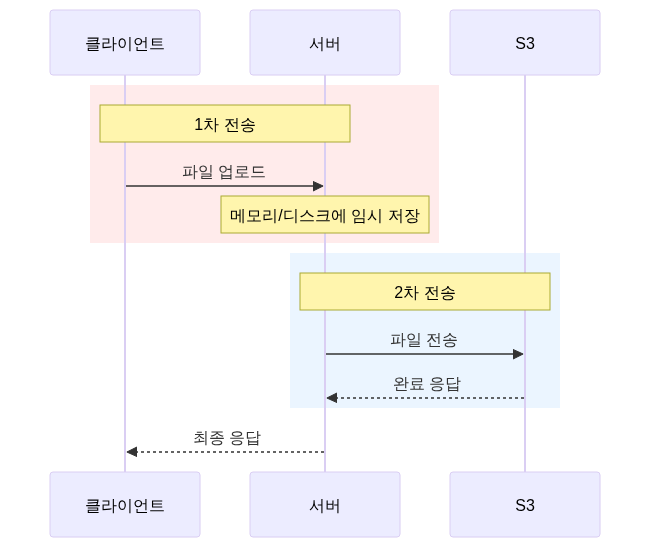
서버를 거치는 업로드 방식이 OOM과 이중 전송 문제를 일으킨다는 걸 파악하고, Presigned URL로 S3 직접 업로드 + EventBridge로 완료 감지하는 구조로 전환한 과정을 정리한다.

Webhook, API, Actuator가 각각 다른 인증 방식을 요구해서 3개의 SecurityFilterChain을 @Order로 분리하고, 경로별 독립적인 보안 정책을 적용한 과정을 정리한다.
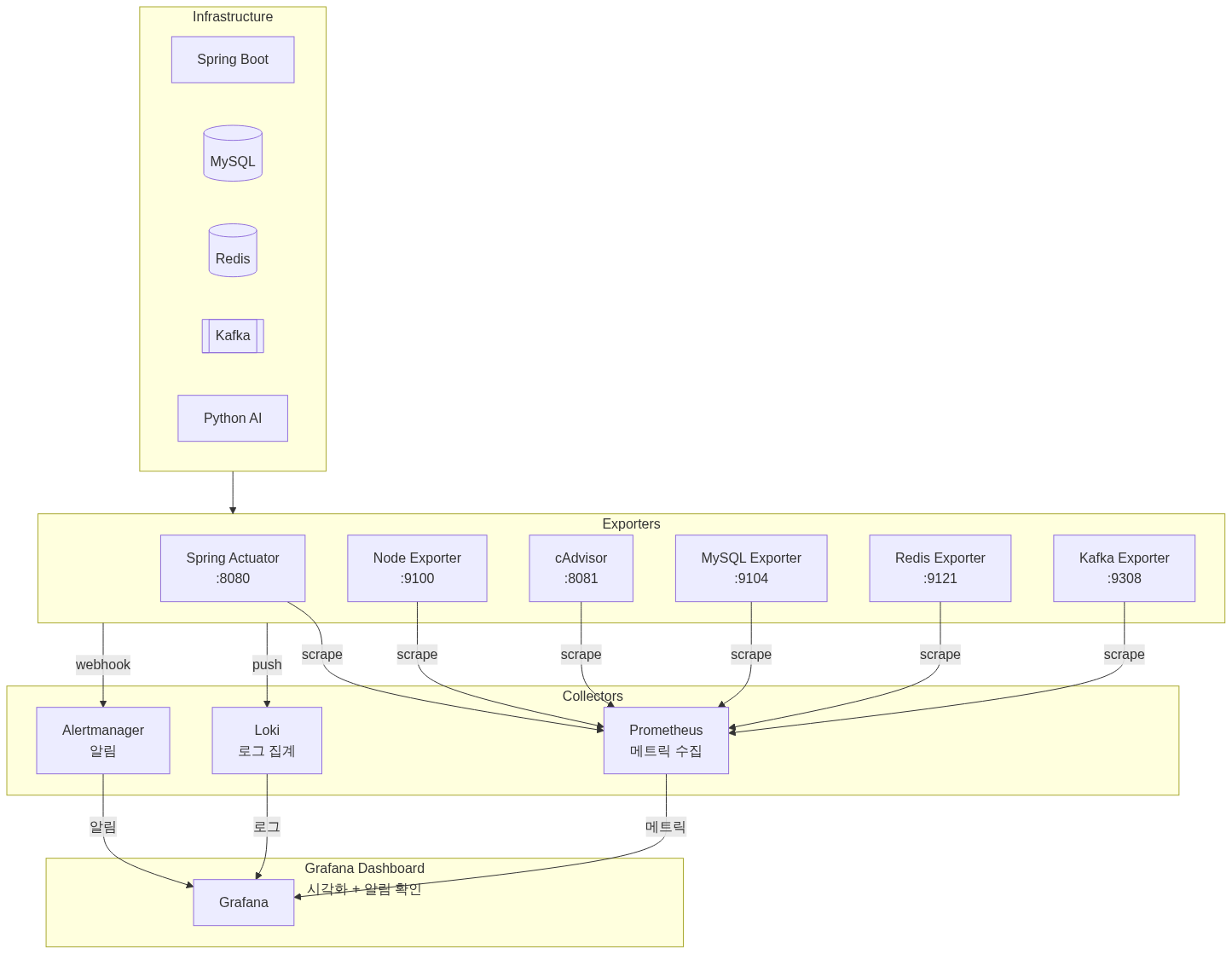
장애를 SSH로 확인하던 구조를 Prometheus(메트릭) + Loki(로그) + Grafana(시각화) + Alertmanager(알림)로 자동화해서 Critical 장애 감지를 ~85초 이내로 줄인 과정을 정리한다.