Kafka 기반 이벤트 드리븐 파일 처리 파이프라인

목차
한 줄 요약
파일 업로드 후 동기 처리로 응답이 5-30초 걸리던 구조를 Kafka 기반 비동기 파이프라인으로 바꿔 200ms 이내 응답 + DLQ 패턴으로 실패 복구까지 잡았습니다.
정상 상태
오락가락 서비스는 사용자가 녹음한 음성(평균 30-50MB WebM)을 분석해서 음악을 추천하는 플랫폼입니다.
업로드된 음성 파일은 WAV 변환(FFmpeg)과 AI 분석(Python FastAPI, GPU 8GB)이라는 두 단계를 거쳐야 합니다.
- Spring Boot 서버: EC2 (4 vCPU, 16GB RAM) Docker 컨테이너, Tomcat 기본 스레드 풀 200개
- AI 분석 서버: Python FastAPI, GPU 8GB, 별도 서버
- 업로드 API(
POST /api/uploads)에서 변환과 분석을 동기로 처리
문제 상황
WAV 변환에 5-10초(30MB WebM 기준), AI 분석에 20-30초가 걸렸습니다.
사용자가 녹음 버튼을 누르고 최대 40초를 빈 화면 앞에서 기다려야 했습니다.
동시 업로드 4건이 겹치면 Tomcat 스레드 4개가 각각 30-40초간 점유됩니다.
이 동안 FFmpeg가 CPU를 점유하면서 다른 API의 응답시간까지 증가했습니다.
이걸 비동기로 분리해야 한다는 건 명확했습니다. 동기 호출에서 요청 스레드가 I/O 완료를 기다리는 동안 해당 스레드는 다른 요청을 처리할 수 없고, 처리 시간이 수십 초 단위이므로 Little’s Law에 의해 동시 점유 스레드 수가 급증하는 구조입니다.
문제는 “어떤 방식으로” 분리할 것인가였습니다.
선택지를 좁혀간 과정
자체 큐(BlockingQueue)를 먼저 떠올렸다
같은 JVM 안에서 돌아가는 모노레포 구조였으니, 가장 먼저 BlockingQueue가 떠올랐습니다.
구현은 간단하고 외부 의존성도 없습니다.
하지만 세 가지가 걸렸습니다.
첫째, 서버가 재시작되면 큐에 있던 작업이 전부 날아갑니다.
음성 분석은 30초 이상 걸리는 작업인데, 배포할 때마다 처리 중인 건이 유실되면 사용자가 다시 녹음해야 합니다.
7주 프로젝트에서 배포가 하루에도 몇 번씩 일어나는데 이건 감수할 수 없었습니다.
둘째, AI 분석 서버가 Python FastAPI로 분리되어 있었습니다.
Spring Boot에서 Python 서버로 비동기 통신이 필요한데, JVM 내부의 BlockingQueue로는 언어가 다른 서비스와 통신할 수 없습니다.
셋째, 실패한 작업을 추적할 방법이 없습니다.
어떤 파일이 어디서 실패했는지도 모른 채 사라집니다.
RabbitMQ를 검토했다
Spring 생태계에서 비동기 메시징이라고 하면 RabbitMQ가 먼저 나옵니다.
Spring AMQP 문서를 읽어보면서 검토했습니다.
RabbitMQ의 장점은 라우팅이 유연하다는 점입니다.
Exchange 타입(direct, topic, fanout)으로 메시지를 다양한 패턴으로 분배할 수 있습니다.
지연시간도 ms 단위로 낮습니다.
그런데 우리 상황에서 두 가지가 맞지 않았습니다.
하나는, RabbitMQ는 소비자가 메시지를 ack하면 큐에서 삭제됩니다.
Kafka처럼 retention 기간 동안 메시지를 보관하는 개념이 없습니다.
장애가 발생했을 때 “이 파일이 어떤 이벤트를 거쳤는지” 원본 메시지를 다시 확인할 수 없습니다.
물론 durable queue와 persistent message로 브로커 재시작 시 메시지를 보존할 수는 있지만, 이미 소비된 메시지를 되감아서 재처리하는 건 불가능합니다.
다른 하나는, 같은 uploadId의 이벤트가 순서대로 처리되어야 한다는 점입니다.
RabbitMQ는 단일 큐 내에서는 FIFO를 보장하고, consistent hash exchange로 같은 uploadId를 같은 큐로 라우팅하면 순서 보장이 가능하긴 합니다.
하지만 Kafka는 파티션 키만 지정하면 같은 키의 메시지가 같은 파티션으로 들어가는 게 기본 동작이라, exchange 설정 없이 더 자연스럽게 순서가 보장됩니다.
SQS도 봤다
AWS를 쓰고 있으니 SQS도 후보였습니다.
관리형이라 운영 부담이 없다는 게 매력이었습니다.
SQS Standard는 순서 보장이 안 됩니다.
FIFO 큐는 기본 초당 300건(배치 시 3,000건)이고, High Throughput 모드를 켜면 초당 3,000건(배치 시 30,000건)까지 올릴 수 있습니다.
현재 트래픽에서는 충분한 수치였지만, 기술적으로 두 가지가 걸렸습니다.
첫째, SQS도 메시지 소비 후 삭제되는 구조라 장애 시 원본 메시지를 되감아 재처리하는 게 불가능합니다.
둘째, 이 프로젝트는 Spring Boot(Java) + Python FastAPI 두 언어로 구성돼 있는데, SQS + Lambda 조합은 Python 쪽에 Lambda를 별도로 둬야 하고, Kafka는 양쪽 서비스가 동일한 토픽을 구독하는 구조라 더 자연스러웠습니다.
다만 솔직하게 말하면, 현재 트래픽 규모에서 SQS FIFO로도 충분히 구현 가능했습니다. SSAFY 빅데이터 추천 트랙 프로젝트였기 때문에 Kafka 기반 파이프라인 경험을 쌓고 싶었던 것도 선택에 영향을 줬습니다. 이건 뒤에서 솔직하게 정리하겠습니다.
Kafka를 선택한 이유
위 검토를 거치면서 Kafka가 남았습니다.
결정적인 이유는 네 가지였습니다.
1. 다중 언어 서비스 간 통신
Spring Boot(Java)와 Python FastAPI가 Kafka 토픽을 통해 JSON 메시지를 주고받는 구조가 깔끔했습니다.
각 서비스가 독립적으로 배포/확장되고, 한쪽이 죽어도 메시지는 Kafka에 남아 있습니다.
2. 파티션 키로 파일 단위 순서 보장
uploadId를 파티션 키로 쓰면, 같은 파일의 모든 이벤트가 같은 파티션으로 들어갑니다.
WAV 변환이 끝나기 전에 AI 분석이 실행되는 문제를 구조적으로 방지할 수 있습니다.
3. 다중 컨슈머 그룹

같은 이벤트를 여러 컨슈머 그룹이 독립적으로 소비할 수 있습니다.
음성 처리, 로그 수집, 향후 추천 데이터 파이프라인 등을 같은 토픽에서 각자 가져갈 수 있습니다.
4. 재처리와 장애 분석
처리 실패 시 오프셋을 커밋하지 않으면 자동 재시도됩니다.
최대 재시도를 넘기면 DLQ로 이동합니다.
retention 기간(7일로 설정) 내에는 오프셋 리셋으로 언제든 재처리가 가능합니다.
배포 시에도 마지막 커밋된 오프셋부터 재개되니 메시지 유실이 없습니다.
5. 빅데이터 파이프라인 확장성
이 프로젝트는 SSAFY 빅데이터 추천 트랙 과제였습니다.
Kafka는 빅데이터 생태계의 핵심이라, Kafka Connect로 S3에 데이터 레이크를 구축하거나 Spark/Flink로 배치 분석을 붙이는 구조가 자연스럽습니다.
실제로 Kafka에서 Pinecone 벡터 DB까지 연결하는 파이프라인을 구현했습니다.

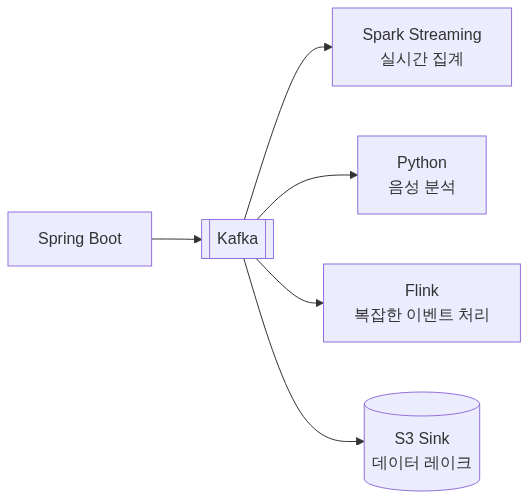
전체 아키텍처
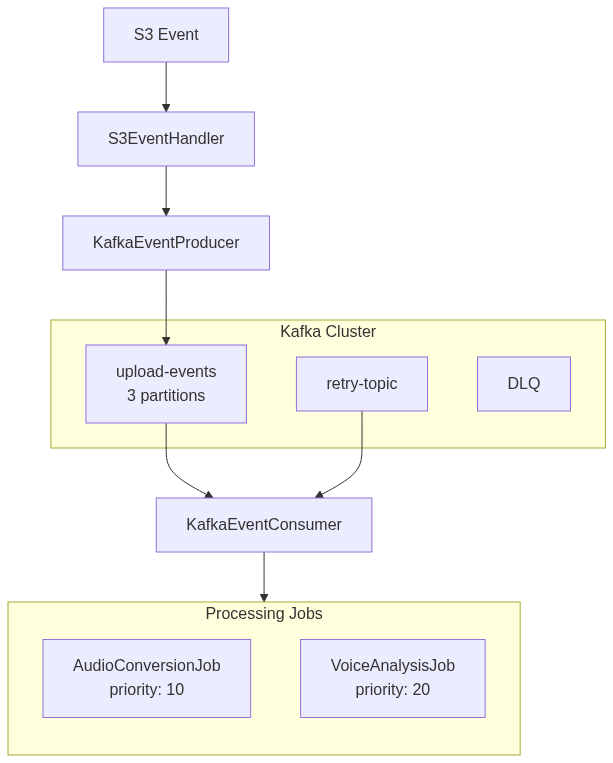
DLQ 패턴
재시도 전략: 지수 백오프

일시적 장애(네트워크 타임아웃, 일시적 서비스 불능)는 재시도로 해결되는 경우가 많습니다.
하지만 즉시 재시도하면 장애 중인 서비스에 부하만 가중시키니, 1초 → 2초 → 4초로 간격을 늘리는 지수 백오프를 적용했습니다.
최대 3회까지 시도합니다.
DLQ에 들어간 메시지는 자동 재처리하지 않는다
DLQ까지 간 메시지는 단순 재시도로 해결되지 않는 문제입니다.
잘못된 파일 포맷, AI 모델 에러 등 사람이 원인을 봐야 하는 경우입니다.
그래서 DLQ 메시지가 쌓이면 Mattermost로 알림을 보내고, 개발자가 원인을 분석한 뒤 수동으로 재처리하거나 보상 처리합니다.
GPU OOM 방어: 큐 + 세마포어 + 요청 크기 제한
AI 서버의 GPU는 DB보다 예민한 공유 자원입니다.
동시 요청이 GPU 메모리를 초과하면 OOM으로 Pod가 죽습니다.
이걸 3단계로 방어했습니다.
1순위 - Kafka 큐: GPU 서버가 직접 요청을 받지 않습니다.
Kafka에서 pull하는 구조라, GPU가 바쁘면 요청이 자연스럽게 대기열에 쌓입니다.
2순위 - Semaphore(permits=2): 동시에 AI 서버로 보내는 요청을 2개로 제한합니다.
ThreadPool max=4와 별개로, 4개 스레드가 동시에 실행되더라도 AI 서버에는 2개만 동시 요청합니다.
나머지는 Semaphore 대기입니다.
3순위 - 요청 크기 제한(100MB): 요청마다 GPU 메모리 사용량이 다르니, 큰 파일은 업로드 단계에서 거부합니다.

세마포어만으로는 부족합니다.
요청마다 메모리 사용량이 다르고, 백엔드 서버가 여러 대면 각 서버가 동시에 요청을 보냅니다.
큐가 앞단에서 버퍼 역할을 해야 GPU 서버가 안전합니다.
비용 분석
| 방식 | 인프라 비용 | 운영 복잡도 | 비고 |
|---|---|---|---|
| SQS FIFO | ~$1-5/월 (요청 기반 과금) | 낮음 (관리형) | 현재 트래픽에서 가장 저렴 |
| Kafka (자체 호스팅, KRaft) | EC2 비용에 포함 (단일 브로커) | 중간 (브로커 모니터링, 파티션 관리) | 별도 EC2 비용은 없지만 메모리/디스크 점유 |
| MSK (관리형 Kafka) | ~$150+/월 (kafka.m5.large 최소) | 낮음 | 프로젝트 규모 대비 과잉 |
이 프로젝트에서는 EC2 내 Docker 컨테이너로 KRaft 모드 단일 브로커를 운영했습니다.
별도 EC2를 추가하지 않았으므로 Kafka 자체의 추가 인프라 비용은 0이지만, 브로커가 점유하는 메모리(JVM 힙 + 페이지 캐시)와 로그 디스크는 기존 서버 자원에서 소모됩니다. Kafka 공식 문서 기준 KRaft 모드 브로커는 최소 4-5GB RAM을 권장하지만, 이 프로젝트에서는 토픽 수와 파티션 수가 적어 JVM 힙을 1GB로 제한하고 운영했습니다.
SQS FIFO를 선택했다면 월 $5 미만으로 동일한 기능을 구현할 수 있었습니다.
Kafka는 비용 효율보다 다중 컨슈머 그룹, 재처리 가능성, 빅데이터 파이프라인 확장성을 위해 선택했습니다.
솔직한 평가
Kafka를 선택한 건 맞는 판단이었다고 생각하지만, 비용도 분명했습니다.
오버엔지니어링 여부: 현재 트래픽만 보면 SQS FIFO로도 충분히 가능했습니다.
기술적 근거(재처리, 다중 컨슈머 그룹, 파티션 키 순서 보장)는 있지만, SQS FIFO + MessageGroupId로도 순서 보장이 가능하고 DLQ도 네이티브 지원합니다.
Kafka를 선택한 가장 큰 이유 중 하나는 “빅데이터 추천 트랙 프로젝트에서 Kafka 기반 파이프라인 경험을 쌓고 싶었기 때문”입니다.
운영 복잡도: Zookeeper 없는 KRaft 모드로 단순화했지만, 브로커 모니터링과 파티션 관리는 여전히 신경 써야 했습니다.
실제 활용도: Spark나 Flink로의 확장은 구현하지 않았습니다.
Kafka → Pinecone 파이프라인까지는 구현했지만, “할 수 있는 구조”와 “실제로 한 것”은 다릅니다.
이건 인정합니다.
성과
| 지표 | 개선 전 | 개선 후 |
|---|---|---|
| 업로드 응답 시간 | 5-30초 | 200ms |
| 복구 방식 | 수동 확인 | 30분 주기 배치 스캔 + 최대 3회 자동 재시도 |
| 실패 처리 | 영구 Stuck | DLQ 이동 후 Mattermost 알림 |
| 장애 영향 범위 | 전체 API 지연 | 해당 처리만 격리 |
프론트엔드 연동
비동기 전환 후 프론트엔드가 처리 완료를 인지하는 방법도 바뀌었습니다.
업로드 API는 uploadId만 즉시 반환하고, 프론트엔드는 이 uploadId로 상태를 폴링(GET /api/uploads/{uploadId}/status)합니다.
응답에는 현재 상태(PENDING → CONVERTING → ANALYZING → COMPLETED/FAILED)가 포함되어 있어서, 프론트엔드가 진행 상황을 사용자에게 보여줄 수 있습니다.
WebSocket이나 SSE도 검토했지만, 폴링 주기 3초면 UX에 충분했고 구현 복잡도가 훨씬 낮아서 폴링을 택했습니다.
참고 자료
Summary
Migrated synchronous file processing (5-30s response) to a Kafka-based async pipeline achieving sub-200ms response with DLQ pattern for failure recovery.
Normal State
Orak is a platform that recommends music by analyzing users’ recorded voices (avg 30-50MB WebM). Uploaded files require two stages: WAV conversion (FFmpeg) and AI analysis (Python FastAPI, 8GB GPU).
- Spring Boot server: EC2 (4 vCPU, 16GB RAM) Docker container, Tomcat default 200 threads
- AI analysis server: Python FastAPI, 8GB GPU, separate instance
- Upload API (
POST /api/uploads) processed conversion and analysis synchronously
Problem
WAV conversion took 5-10 seconds (30MB WebM basis), AI analysis 20-30 seconds. Users stared at a blank screen for up to 40 seconds.
With 4 concurrent uploads, 4 Tomcat threads were occupied for 30-40 seconds each. FFmpeg consumed CPU during conversion, degrading other API response times. By Little’s Law, with processing times in the tens of seconds, concurrent thread occupation grows rapidly under even moderate load.
Async separation was clearly needed. The question was how.
Narrowing Down Options
BlockingQueue First
As a monorepo in a single JVM, BlockingQueue came to mind first. Simple implementation, no external dependencies.
Three issues: server restart loses all queued work (unacceptable with frequent deployments); the AI server is Python FastAPI requiring cross-language communication; no way to track failed tasks.
RabbitMQ
RabbitMQ offers flexible routing via Exchange types (direct, topic, fanout) with ms-level latency.
Two mismatches: messages are deleted after consumer ack with no retention-based replay for failure analysis. For ordering, RabbitMQ guarantees FIFO within a single queue and consistent hash exchange can route the same uploadId to the same queue — but Kafka’s partition key model achieves this as a default behavior without exchange configuration.
SQS
SQS Standard lacks ordering. FIFO queues handle 300/s base (3,000/s batched), or 3,000/s (30,000/s batched) with High Throughput mode. Current traffic would be fine, but two technical issues remained: same post-consumption deletion preventing replay, and the dual-language architecture (Java + Python) fitting more naturally with Kafka’s shared topic model than SQS + Lambda.
That said, SQS FIFO could have handled this workload. The Kafka choice was also influenced by wanting big data pipeline experience in this track project. This is addressed candidly below.
Why Kafka
1. Multi-Language Service Communication
Spring Boot (Java) and Python FastAPI exchanging JSON via Kafka topics was clean. Services deploy/scale independently, and messages persist in Kafka if one side goes down.
2. Partition Key for Per-File Ordering
Using uploadId as the partition key ensures all events for the same file go to the same partition, structurally preventing AI analysis from running before WAV conversion completes.
3. Multiple Consumer Groups
The same events can be independently consumed by multiple consumer groups: voice processing, log collection, future recommendation pipelines.
4. Reprocessing and Failure Analysis
Failed processing retries automatically by not committing offsets. Beyond max retries, messages move to DLQ. Offset reset enables reprocessing within the 7-day retention period. Deployments resume from the last committed offset with zero message loss.
5. Big Data Pipeline Extensibility
This was a SSAFY big data recommendation track project. Kafka naturally connects to S3 data lakes via Kafka Connect, or to Spark/Flink batch analysis. A pipeline from Kafka to Pinecone vector DB was actually implemented.
Full Architecture
DLQ Pattern
Retry Strategy: Exponential Backoff
Transient failures often resolve with retry. But immediate retry adds load to a failing service. Exponential backoff (1s → 2s → 4s) was applied, with a maximum of 3 attempts.
DLQ Messages Are Not Auto-Reprocessed
Messages reaching DLQ represent problems that simple retry won’t fix: invalid file formats, AI model errors. When DLQ messages accumulate, Mattermost alerts are sent for developers to analyze and manually reprocess or compensate.
GPU OOM Defense: Queue + Semaphore + Request Size Limit
The AI server’s GPU is a sensitive shared resource. Concurrent requests exceeding GPU memory cause OOM Pod kills.
Three-layer defense:
Layer 1 - Kafka Queue: GPU server doesn’t receive direct requests. It pulls from Kafka, so requests naturally queue when GPU is busy.
Layer 2 - Semaphore (permits=2): Limits concurrent AI server requests to 2, independent of ThreadPool max=4.
Layer 3 - Request Size Limit (100MB): Large files are rejected at upload to prevent variable GPU memory consumption.
Semaphore alone isn’t enough. Per-request memory varies, and multiple backend servers can send simultaneously. The queue must buffer upstream to keep the GPU server safe.
Cost Analysis
| Approach | Infra Cost | Operational Complexity | Notes |
|---|---|---|---|
| SQS FIFO | ~$1-5/mo (per-request billing) | Low (managed) | Cheapest for current traffic |
| Kafka (self-hosted, KRaft) | Included in EC2 (single broker) | Medium (broker monitoring, partition mgmt) | No separate EC2, but ~1GB RAM + disk consumed |
| MSK (managed Kafka) | ~$150+/mo (kafka.m5.large min) | Low | Excessive for project scale |
This project ran a KRaft-mode single broker in a Docker container on existing EC2. No additional EC2 cost, but the broker consumed memory (JVM heap + page cache) and log disk from the existing server. Kafka’s official documentation recommends 4-5GB minimum for KRaft brokers, but with minimal topics and partitions, JVM heap was limited to 1GB in this project. SQS FIFO would have achieved similar functionality for under $5/month.
Honest Assessment
Kafka was the right choice, but with clear costs.
Over-engineering: Current traffic could have been handled by SQS FIFO, which natively supports MessageGroupId ordering and DLQ. Technical justifications (replay, multi-consumer groups, partition key ordering) exist, but SQS FIFO covers most of them. One of the biggest reasons for choosing Kafka was wanting to build Kafka pipeline experience in a big data track project.
Operational complexity: KRaft mode (no Zookeeper) simplified things, but broker monitoring and partition management still required attention.
Actual utilization: Spark/Flink extensions were not implemented. The Kafka → Pinecone pipeline was built, but “capable architecture” differs from “actually implemented.” This is acknowledged.
Results
| Metric | Before | After |
|---|---|---|
| Upload response time | 5-30s | 200ms |
| Recovery method | Manual check | 30-min batch scan + max 3 auto-retries |
| Failure handling | Permanent stuck | DLQ with Mattermost alert |
| Failure blast radius | All APIs delayed | Isolated to affected processing |
Frontend Integration
After the async migration, how the frontend learns about completion changed. The upload API returns only the uploadId immediately, and the frontend polls status (GET /api/uploads/{uploadId}/status). The response includes the current state (PENDING → CONVERTING → ANALYZING → COMPLETED/FAILED), allowing the frontend to show progress to the user.
WebSocket and SSE were considered, but 3-second polling intervals provided sufficient UX with much lower implementation complexity.
References

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.