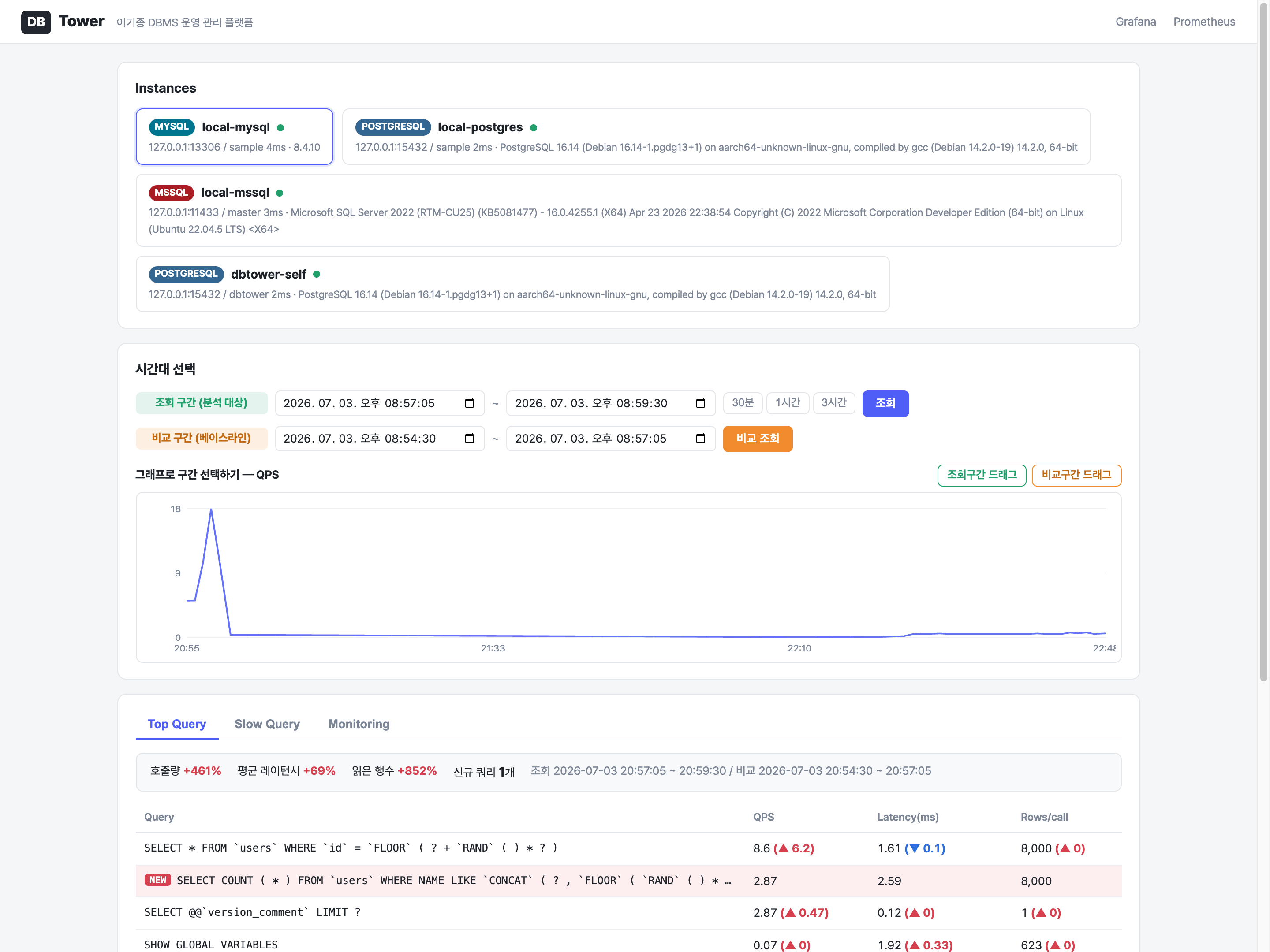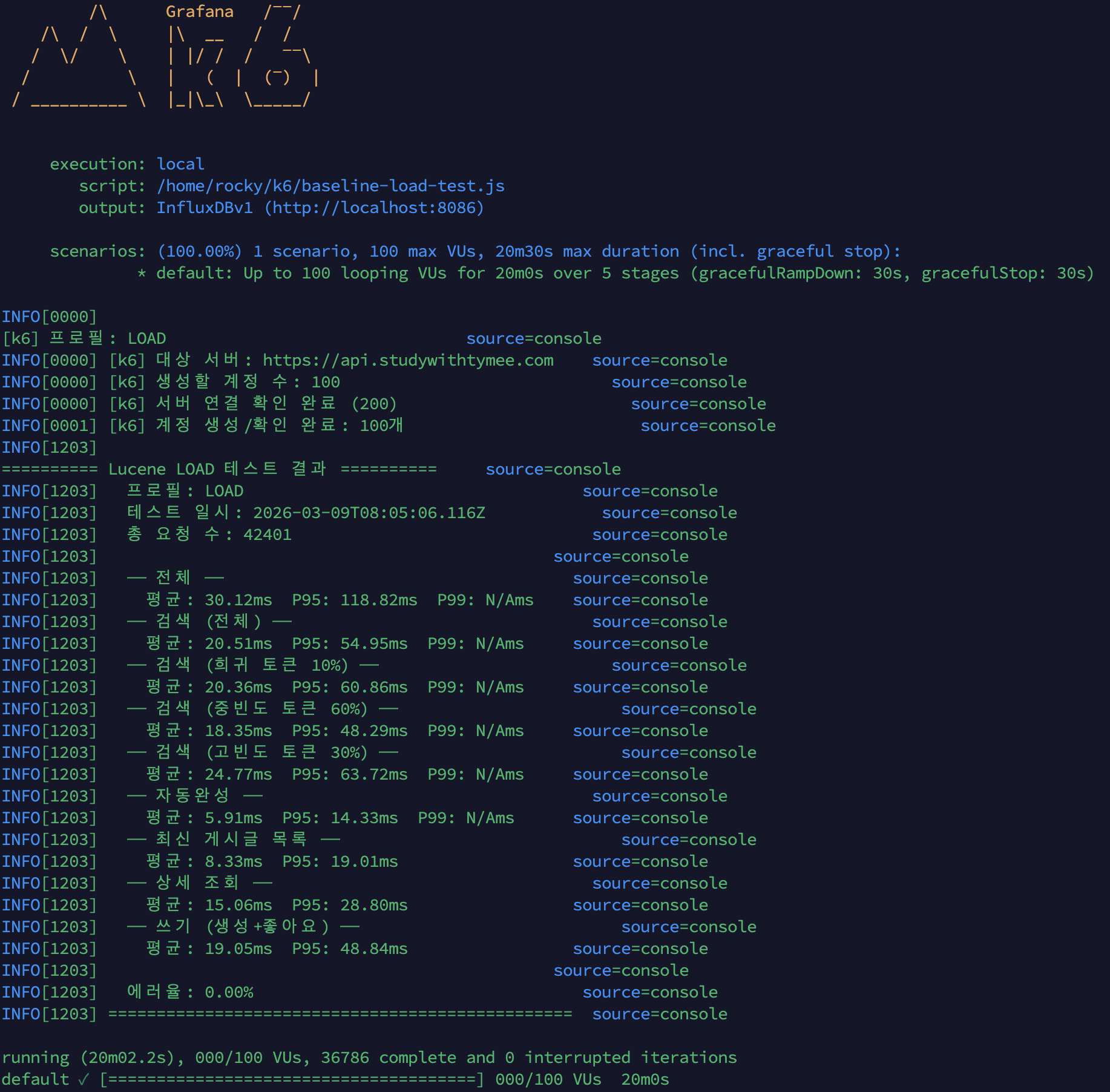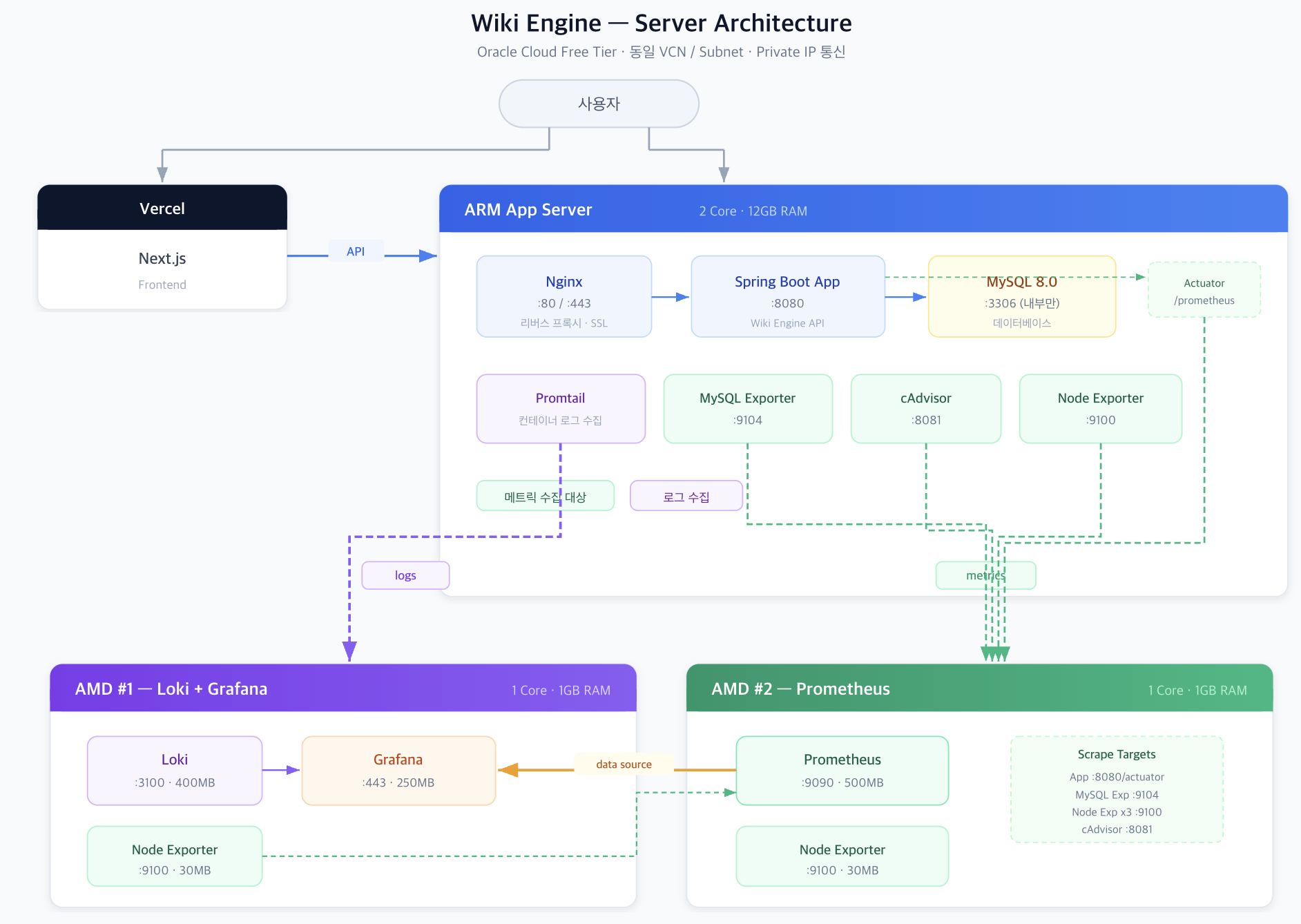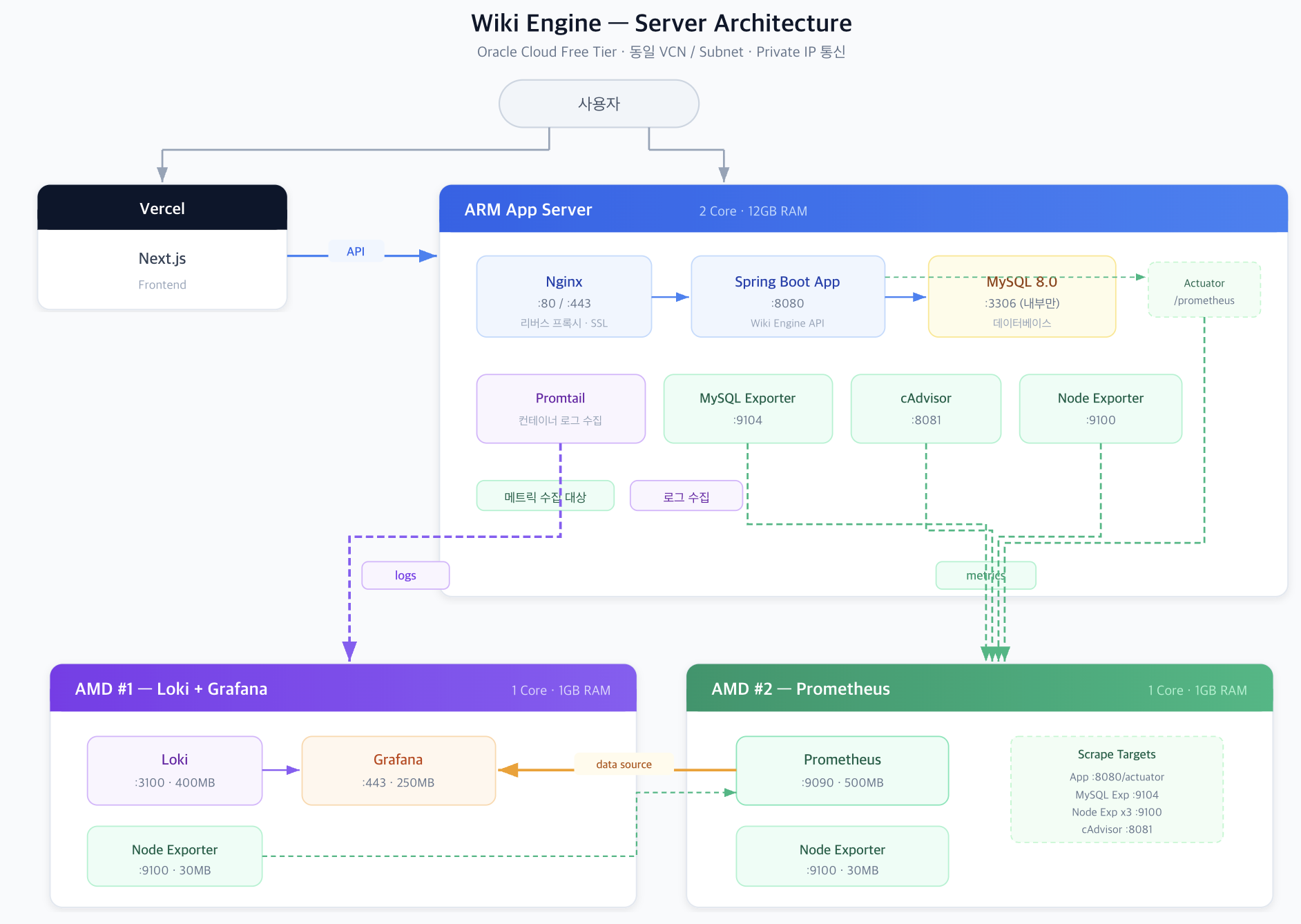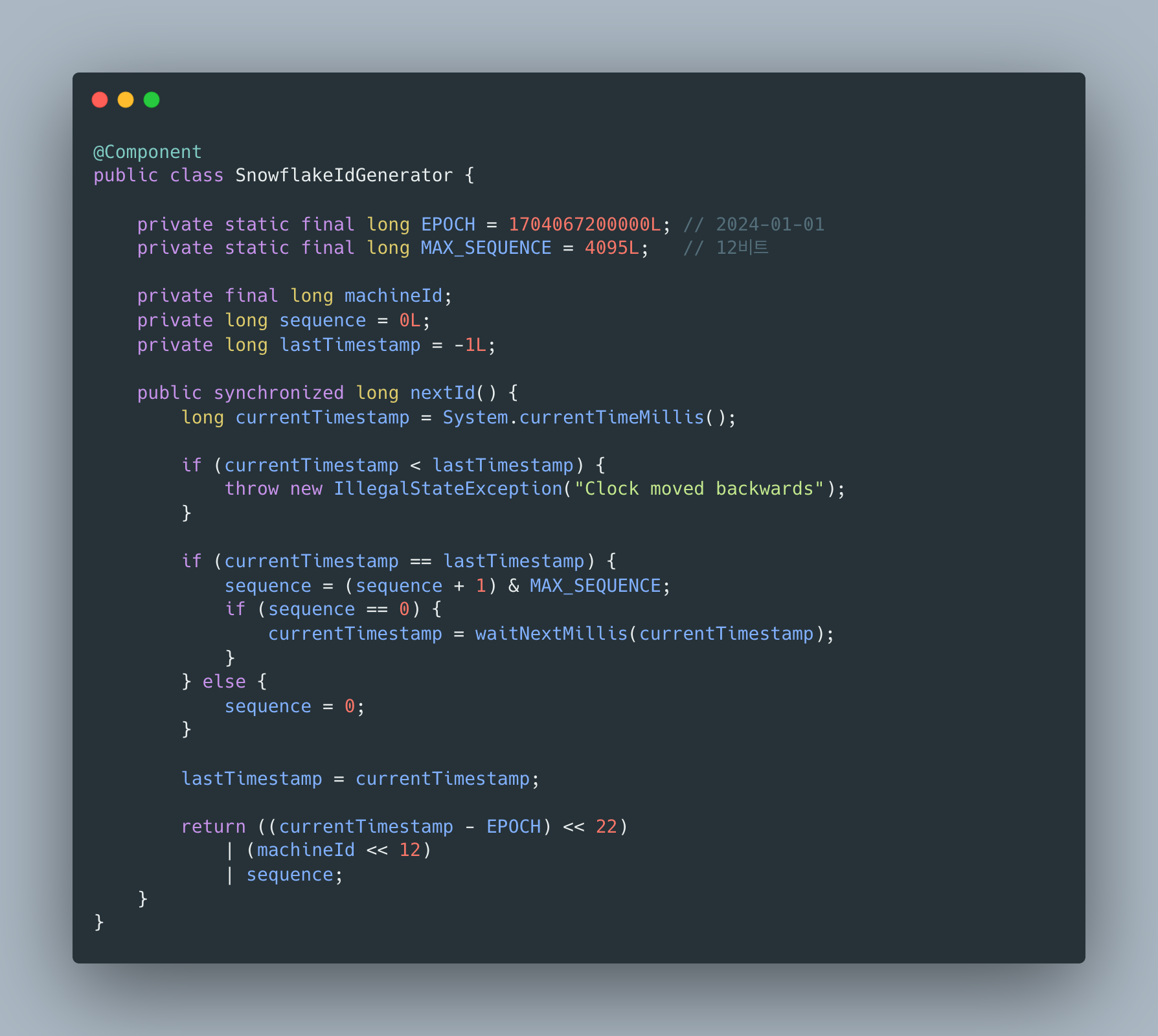
백업이 진짜가 되기까지: 로그 백업 5기종과 시점 복구, 그리고 정석까지의 네 걸음
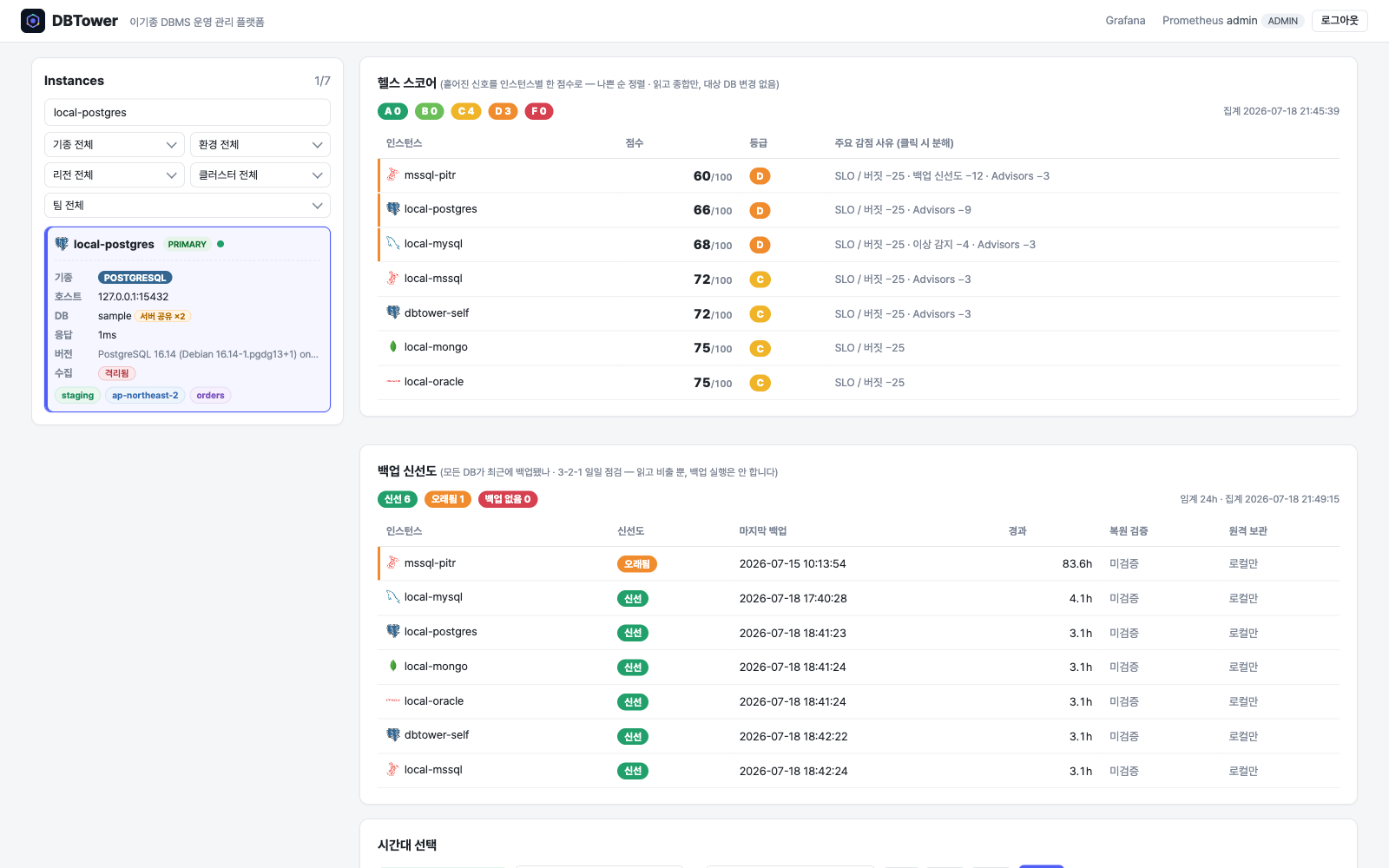
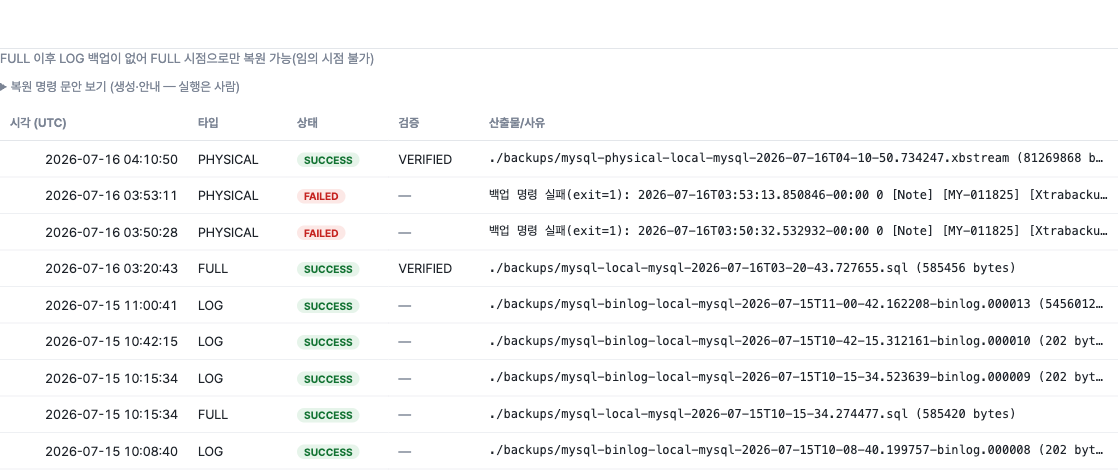
이기종 DBMS 운영 관리 플랫폼 DBTower 6편. 백업 대장정입니다. 전반부는 로그 백업이 MSSQL만 되던 것을 MySQL binlog, PostgreSQL WAL, MongoDB oplog, Oracle 아카이브 로그까지 다섯 기종 전부로 넓히며 "기종이 못 하는 것"과 "하다가 깨진 것"을 구분하는 UNSUPPORTED 상태를 만들고, 최신 파일 하나만 수집하면 체인에 조용한 구멍이 난다는 것을 "마지막 이전 전부" 보충 수집으로 고치고, 생성한 복원 안내문을 실제로 실행해 SQL Server와 PostgreSQL에서 목표 시점의 상태를 정확히 재현한 기록입니다. 후반부는 그걸 현업의 정석 쪽으로 옮겨 가는 네 걸음입니다. Mongo oplog 증분($gte로 일부러 만든 겹침 한 건이 체인 무결의 증거, 산출물 28분의 1), pg_receivewal 스트리밍(복제 슬롯 덕에 수신자를 죽여도 재시작 사이 유실 0, 그리고 죽은 프로세스를 산 것처럼 보이게 하던 docker exec -i 함정), MySQL 물리 백업 XtraBackup(MYSQL_PWD를 안 읽고 /dev/stdin defaults를 조용히 무시하는 함정 두 겹, 검증은 파일 존재가 아니라 실제 prepare 실행), 그리고 AES-256-GCM 산출물 암호화(변조된 백업은 조용히 오염되는 대신 명확히 실패한다)까지입니다.