위키 검색엔진 개요
목차
나무위키, 위키피디아(한/영) 덤프 데이터를 MySQL에 적재하고, 실제 커뮤니티 수준의 트래픽을 감당할 수 있는 검색엔진을 만드는 프로젝트입니다.
그리고 더 나아가 다른 기능까지 만들 예정입니다.
단순히 “검색 기능을 만들었다”에서 그치지 않고, 가장 느린 상태에서 시작하여 병목이 드러날 때마다 다음 기술로 전환하는 과정 전체를 기록합니다.
각 단계에서 성능, 구현 복잡도, 운영 비용의 트레이드오프를 비교하고, 전환이 필요한 근거를 수치로 남깁니다.
데이터
| 소스 | 포맷 | 문서 수 | 카테고리 | 설명 |
|---|---|---|---|---|
| 나무위키 (2021.03) | JSON | 571,364건 | 키워드 분류 (28개) | 나무마크 본문, 한국어 커뮤니티 문서 |
| 한국어 위키백과 (2026.03) | XML | 739,791건 | 키워드 분류 (28개) | MediaWiki XML 덤프 (ns=0만) |
| 영어 위키백과 (2026.02) | XML | 7,139,510건 | 키워드 분류 (28개) | MediaWiki XML 덤프 (ns=0만) |
| 한국어 뉴스 | JSON | 159,639건 | 고정: 뉴스 | 뉴스 기사 텍스트 |
| 한국어 웹텍스트 | JSON | 1,284,822건 | 고정: 웹 콘텐츠 | 웹 크롤링 텍스트 |
| C4 한국어 클린 | JSON | 2,261,463건 | 고정: 웹 콘텐츠 | 한국어 웹 코퍼스 |
| 합계 | 12,156,589건 | 30개 카테고리 | 고유 태그 ~216만 개 |
위키 문서를 그대로 쓰지 않고 실제 커뮤니티 게시판처럼 변환하여 적재합니다:
- 위키
[[분류:XXX]]/[[Category:XXX]]→ 태그 (해시태그) + 카테고리 키워드 매칭 - 뉴스/웹 콘텐츠 → 소스별 고정 카테고리
- ns=0(일반 문서)만 import (틀, 분류, 모듈 등 제외)
- author_id → 10만 명의 더미 유저에게 랜덤 균등 배정
- created_at → 2020~2025 범위 내 랜덤 생성
- 리다이렉트 문서 제외
결과적으로 수천만 건의 게시글, 수십만 개의 태그, 카테고리별 게시판이 갖춰진 커뮤니티 데이터셋이 됩니다.
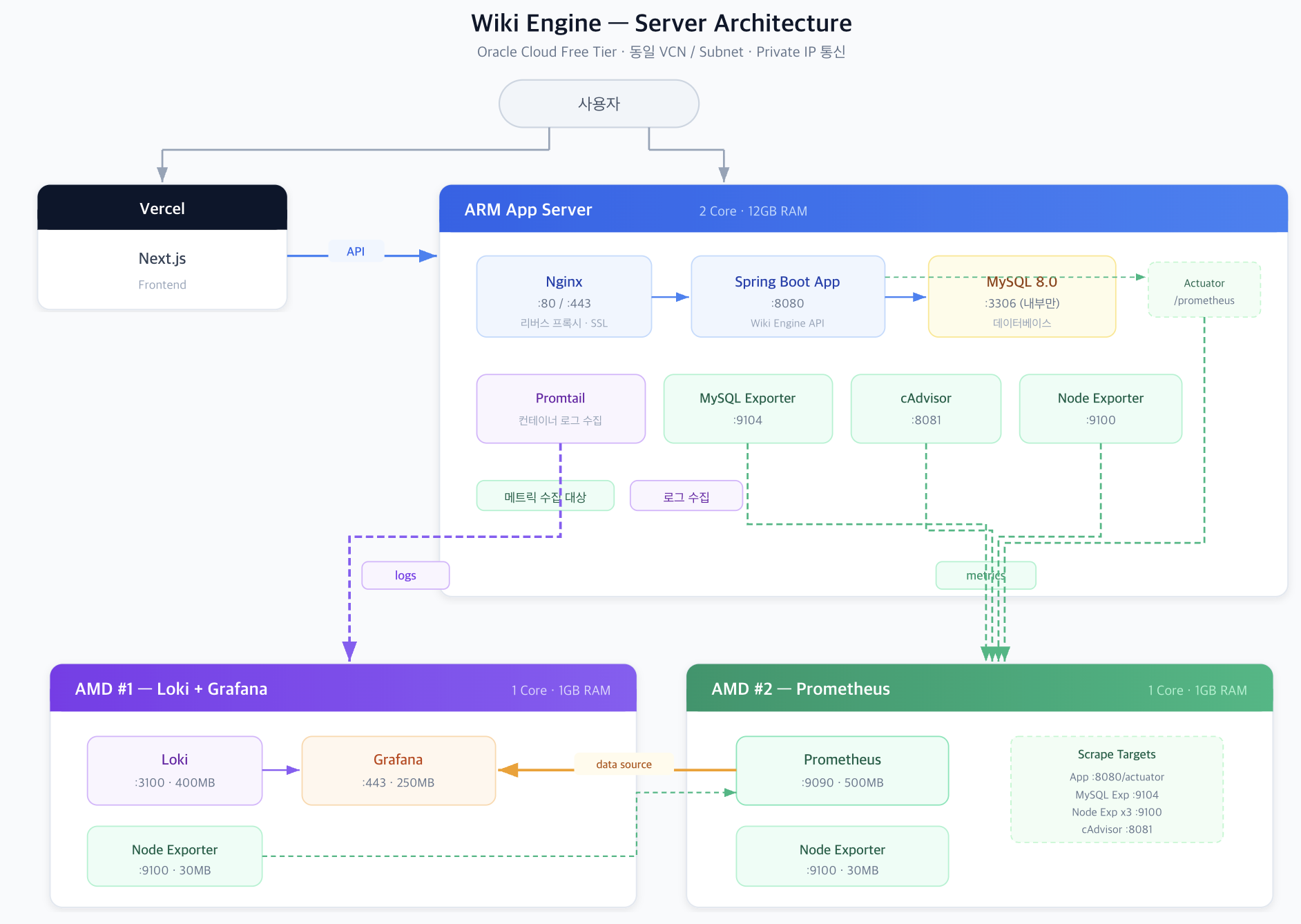
서버 구성
시작은 Oracle Cloud Free Tier 3대에서 시작합니다.
| 서버 | 스펙 | 역할 |
|---|---|---|
| App Server | ARM (Ampere A1) 2코어 / 12GB RAM | Nginx + Spring Boot + MySQL |
| Monitoring #1 | AMD (E2.1.Micro) 1GB + Swap 1GB | Loki + Grafana + Nginx (HTTPS) |
| Monitoring #2 | AMD (E2.1.Micro) 1GB + Swap 1GB | Prometheus |
3대 모두 동일 VCN/서브넷에 위치하며, 서버 간 통신은 Private IP를 사용합니다.
App Server 리소스 할당 (12GB 내부 배분):
| 서비스 | 컨테이너 제한 | 내부 설정 | 비고 |
|---|---|---|---|
| Spring Boot | 2 GB | JVM 힙 1 GB (-Xmx1g) | API + Lucene 검색 |
| MySQL 8.0 | 4 GB | InnoDB Buffer Pool 2 GB | localhost only |
| Nginx | 256 MB | — | 리버스 프록시 + SSL |
| Promtail | 256 MB | — | 로그 → Loki |
| cAdvisor | 256 MB | — | 컨테이너 메트릭 |
| MySQL Exporter | 128 MB | — | MySQL 메트릭 |
| Node Exporter | 30 MB | — | 호스트 메트릭 |
| 합계 | ~7 GB | 나머지 ~5GB → OS 페이지 캐시 (Lucene MMap) |
프론트엔드는 Vercel에 배포합니다.
아키텍처
This is a project to load Namuwiki and Wikipedia (Korean/English) dump data into MySQL and build a search engine capable of handling community-level traffic, with plans to add more features.
Rather than simply “building a search feature,” this project records the entire process of starting from the slowest state and transitioning to the next technology whenever bottlenecks emerge.
At each stage, we compare trade-offs of performance, implementation complexity, and operational cost, documenting the rationale for transitions with metrics.
Data
| Source | Format | Documents | Description |
|---|---|---|---|
| Namuwiki | JSON | ~1M | Namuwiki markup content, Korean community documents |
| Korean Wikipedia | XML | ~2.16M | MediaWiki XML dump |
| English Wikipedia | XML | ~25.28M | MediaWiki XML dump (~7.13M excluding redirects) |
Wiki documents are not used as-is but transformed to resemble a real community bulletin board:
- Wiki namespaces (articles, discussions, users, templates) → Categories (board concept)
[[분류:XXX]]/[[Category:XXX]]→ Tags (hashtag concept)- author_id → Randomly distributed among 100K dummy users
- created_at → Randomly generated within 2020-2025 range
- Redirect documents excluded
The result is a community dataset with tens of millions of posts, hundreds of thousands of tags, and category-based boards.
Server Configuration
Starting with 3 Oracle Cloud Free Tier instances.
| Server | Specs | Role |
|---|---|---|
| App Server | ARM (Ampere A1) 2 cores / 12GB RAM | Nginx + Spring Boot + MySQL |
| Monitoring #1 | AMD (E2.1.Micro) 1GB + 1GB Swap | Loki + Grafana + Nginx (HTTPS) |
| Monitoring #2 | AMD (E2.1.Micro) 1GB + 1GB Swap | Prometheus |
App Server Resource Allocation (12GB breakdown):
| Service | Container Limit | Internal Config | Note |
|---|---|---|---|
| Spring Boot | 2 GB | JVM Heap 1 GB (-Xmx1g) | API + Lucene Search |
| MySQL 8.0 | 4 GB | InnoDB Buffer Pool 2 GB | localhost only |
| Nginx | 256 MB | — | Reverse Proxy + SSL |
| Promtail | 256 MB | — | Logs → Loki |
| cAdvisor | 256 MB | — | Container metrics |
| MySQL Exporter | 128 MB | — | MySQL metrics |
| Node Exporter | 30 MB | — | Host metrics |
| Total | ~7 GB | Remaining ~5GB → OS page cache (Lucene MMap) |
All 3 instances are in the same VCN/subnet, using Private IPs for inter-server communication.
Frontend is deployed on Vercel.
Architecture

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.