FULLTEXT ngram 인덱스
목차
이전 글 요약
자동완성(LIKE 'prefix%')에 B-Tree 복합 인덱스를 추가하여 타임아웃을 해소했습니다.
(EXPLAIN rows 27,440,000 -> 1, >5,000ms -> 8ms)
하지만 검색(LIKE '%keyword%')은 선행 와일드카드이므로 B-Tree 인덱스를 사용할 수 없습니다.
여전히 Full Table Scan -> 5초 타임아웃 -> 검색 기능 사용 불가 상태입니다.
1. 검색의 기대 동작
사용자가 검색어를 입력하면, 제목 또는 본문에 해당 키워드가 포함된 게시글을 반환하는 기능입니다.
처음에는 제목과 본문을 모두 검색하되, 최신순(ORDER BY created_at DESC)으로 정렬했습니다:
하지만 content(LONGTEXT) 스캔이 커넥션 풀을 고갈시켜 시스템을 마비시켰고, 긴급 조치로 content 검색을 제거한 상태입니다.
현재는 title만 검색하고 있으며, FULLTEXT 인덱스를 title + content 모두에 적용하여 본문 검색을 복원하고, 정렬도 관련도순으로 전환합니다.
2. 문제 상태: 검색 100% 타임아웃
인덱스 적용 후에도 검색 쿼리는 변함없이 타임아웃이 발생합니다.

EXPLAIN 확인

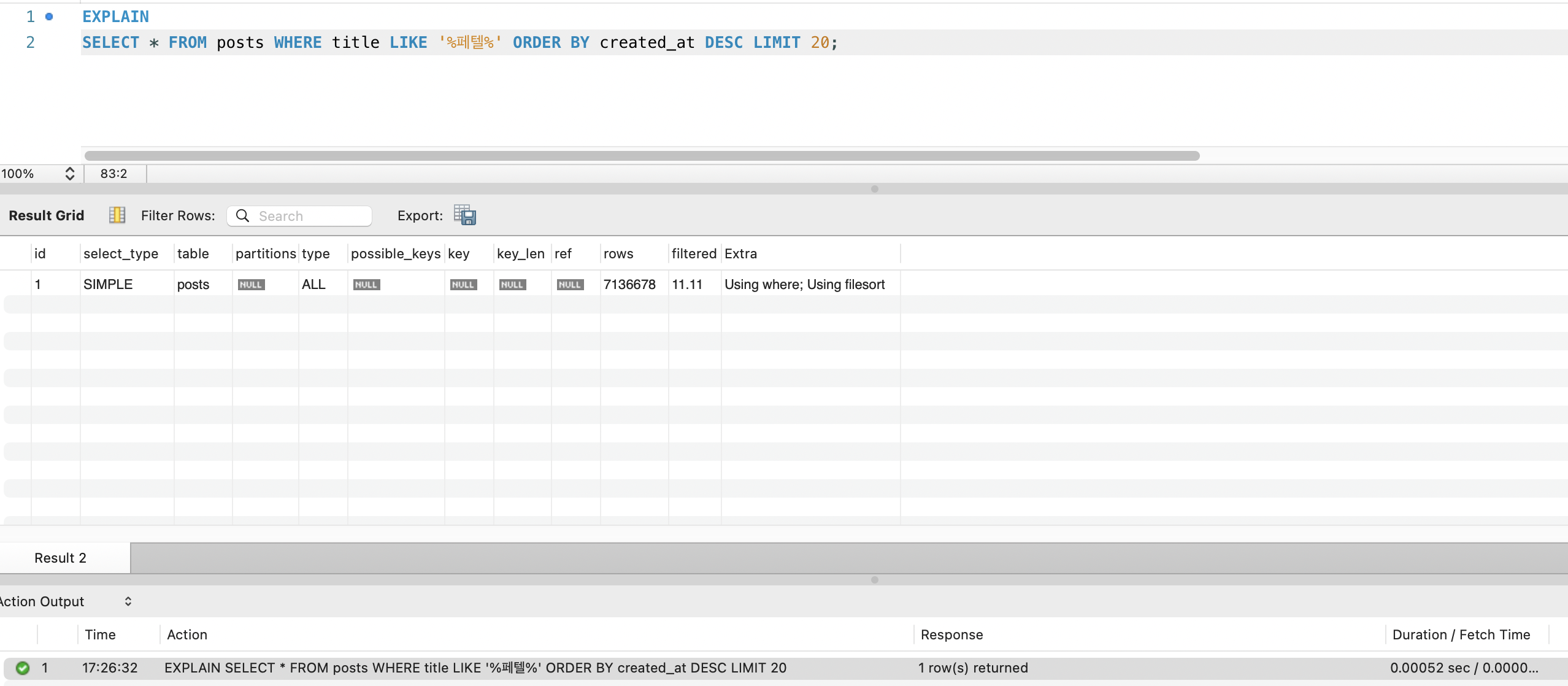
| 항목 | 값 | 의미 |
|---|---|---|
| type | ALL | Full Table Scan |
| possible_keys | NULL | 사용 가능한 인덱스 없음 |
| key | NULL | 실제 사용한 인덱스 없음 |
| rows | 27,440,000 | 전체 행 스캔 (InnoDB 옵티마이저 추정치) |
| Extra | Using where; Using filesort | WHERE 필터 + 정렬 모두 디스크 처리 |
참고: EXPLAIN의 rows=27,440,000은 InnoDB 옵티마이저의 추정치입니다.
실제COUNT(*)로 측정한 행 수는 14,768,700건이며, InnoDB는 통계 샘플링 방식의 한계로 실제와 2~5배 차이가 날 수 있습니다.
이후 실측값을 기준으로 분석합니다.
자동완성은 동작하지만, 검색은 여전히 사용 불가.
1,477만 건의 데이터에서 키워드로 문서를 찾을 수 없는 상태입니다.
3. 대안 검토: 왜 FULLTEXT ngram인가
B-Tree 인덱스의 한계
LIKE '%keyword%'는 선행 와일드카드입니다.
B-Tree 인덱스는 값의 앞부분부터 정렬되어 있으므로, 키워드가 문자열 어디에 위치하는지 알 수 없어 인덱스를 사용할 수 없습니다.

LIKE '페텔%'-> “페” 위치부터 range scan 가능LIKE '%페텔%'-> “페텔”이 문자열 어디에 있는지 알 수 없음 -> 전체 스캔
이것은 B-Tree 자료구조의 본질적 한계입니다. B-Tree가 해결하는 것은 “이 값으로 시작하는 행을 찾아라”이고, 지금 필요한 것은 “이 값이 어딘가에 포함된 행을 찾아라”입니다.
자료구조 자체가 다른 문제를 풀고 있으므로, B-Tree 위에서 아무리 튜닝해도 해결할 수 없습니다.
그렇다면 “특정 키워드가 포함된 문서를 빠르게 찾는” 자료구조는 무엇일까?
이 질문에서 출발해 정보 검색(Information Retrieval) 관점에서 어떤 자료구조가 이 문제에 맞는지 다시 검토했습니다.
역색인: IR 교재에서 찾은 해답
Introduction to Information Retrieval 3장(토큰과 텀)과 [정보검색의 이론과 실제] 2장(역색인)을 참고해, 텍스트 검색의 핵심 자료구조가 역색인(inverted index)이라는 점을 확인했습니다.
역색인은 사전(Dictionary) 과 포스팅 목록(Posting List) 으로 구성됩니다. 사전은 문서 모음에 포함된 모든 텀의 목록이고, 각 텀은 해당 텀이 출현한 문서를 가리키는 포스팅 목록으로 연결됩니다.

LIKE '%keyword%'가 느린 이유는 역색인이 없기 때문입니다.
역색인 없이는 키워드가 어떤 문서에 포함되어 있는지 알 수 없어 모든 행을 읽어야 합니다.
역색인이 있으면 키워드를 사전에서 찾고, 포스팅 목록에서 문서 ID를 바로 반환할 수 있습니다.

이것이 KMP, Trie, Bloom Filter 같은 문자열 알고리즘과의 근본적 차이입니다.
KMP는 행 1개 안에서 비교 속도를 O(n*m) -> O(n+m)으로 줄이는 것이고, 역색인은 읽어야 할 행 수 자체를 줄이는 것입니다.
병목은 문자열 비교가 아니라 1,477만 행을 디스크에서 읽는 I/O이므로, 역색인이 필요합니다.
역색인 구현 방식 비교
역색인이 필요하다는 것을 확인한 후, MySQL 8.0 Full-Text Search 공식 문서에서 MySQL이 내장 역색인(FULLTEXT 인덱스)을 지원한다는 것을 확인했습니다.
외부 검색엔진과 함께 구현 방식을 비교했습니다.
| 방식 | 역색인 구현 | 장점 | 단점 | 판단 |
|---|---|---|---|---|
| MySQL FULLTEXT ngram | MySQL 내장, ngram 토큰화 | 추가 인프라 불필요, 즉시 적용 가능 | 형태소 분석 미지원, false positive | O |
| Elasticsearch | Lucene 기반 역색인 | 형태소 분석, BM25 스코어링, 분산 처리 | 클러스터 운영, 데이터 동기화, 인프라 비용 | 시기상조 |
| PostgreSQL GIN + trigram | GIN 인덱스 기반 역색인 | trigram으로 부분 문자열 검색 | MySQL에서 미지원, DB 마이그레이션 필요 | X |
Elasticsearch를 지금 도입하지 않는 이유
Elasticsearch도 내부적으로 Lucene의 역색인을 사용합니다.
궁극적 해결책이지만, 현 시점에서 도입하면:
- 운영 복잡성: 클러스터 운영, 모니터링, 장애 대응
- 데이터 동기화: MySQL <-> Elasticsearch 간 일관성 보장 (Debezium/CDC 추가 인프라)
- 인프라 비용: 최소 힙 16GB+, ARM 서버 메모리 한계
- 현재 요구사항 대비 과잉: title + content 키워드 검색이면 MySQL 내장 FULLTEXT로 충분
추가 인프라 없이 MySQL 내장 FULLTEXT ngram으로 먼저 검색을 동작시키고, 검색 품질 한계가 드러나는 시점에 Lucene으로 전환합니다.
4. 해결: FULLTEXT ngram 인덱스
ngram parser란
MySQL 공식 문서: ngram Full-Text Parser에 따르면, ngram parser는 텍스트를 n글자 단위로 쪼개서 토큰을 만들고, 각 토큰이 어떤 문서에 포함되어 있는지를 역색인으로 저장합니다.
ngram_token_size=2 일 때:

검색 시 MATCH(title, content) AGAINST('페텔' IN BOOLEAN MODE)을 실행하면, MySQL은 역색인에서 “페텔” 토큰을 찾아 해당 문서 ID들을 즉시 반환합니다.
1,477만 행을 스캔할 필요가 없습니다.
ngram_token_size=2를 선택한 이유
ngram_token_size는 토큰의 글자 수를 결정하며, 이 값보다 짧은 단어는 인덱싱되지 않습니다.
MySQL 공식 문서와 MySQL 공식 한국어 블로그는 CJK(중국어/일본어/한국어)에서 2(bigram)를 권장합니다.
| token_size | 검색 가능 최소 단위 | 한국어 적합성 |
|---|---|---|
| 1 | 1글자 (물, 산) | 한글 완성형이 ~11,172자뿐이라 거의 모든 문서에 매칭 -> 노이즈 극심 |
| 2 | 2글자 (사랑, 학교) | 한국어 최빈 2음절 단어 정확 매칭, MySQL CJK 공식 권장 |
| 3 | 3글자 (프로그, 데이터) | 1~2음절 단어(사랑, 학교, 물) 검색 불가 -> 치명적 |
전체 데이터는 영어 위키피디아(~1,420만 건)가 한국어 나무위키(~57만 건)보다 압도적으로 많지만, ngram_token_size=2는 영어에도 유효합니다.
영어 단어는 2글자 이상이 대부분이고, ngram parser는 공백을 하드코딩된 스탑워드로 처리하여 단어 단위 토큰화가 자연스럽게 이루어집니다.
CJK와 영어 모두에서 2가 최적입니다.
BOOLEAN MODE를 선택한 이유
MySQL FULLTEXT는 두 가지 검색 모드를 제공합니다.
MySQL 공식 문서: Boolean Full-Text Searches와 MySQL 공식 한국어 블로그를 참고하여 선택했습니다.
ngram parser에서 두 모드의 핵심 차이는 검색어를 토큰으로 변환하는 방식입니다:
| 모드 | ngram 변환 방식 | 예시 ('페텔기' 검색) | 문제점 |
|---|---|---|---|
| NATURAL LANGUAGE MODE | ngram 합집합 (OR) | 페텔 OR 텔기 | ”페텔” 또는 “텔기”만 포함해도 매칭 → false positive 증가. 50% threshold로 흔한 토큰 무시 |
| BOOLEAN MODE | ngram 구문 검색 (순서 매칭) | "페텔 텔기" | ”페텔” 다음에 “텔기”가 순서대로 있어야 매칭 → false positive 감소 |
BOOLEAN MODE를 선택한 이유는 두 가지입니다:
- 구문 검색 변환: ngram 토큰이 순서대로 매칭되어야 하므로, NATURAL LANGUAGE MODE의 합집합 방식보다 false positive가 적습니다. 예를 들어
'대한민국'을 검색하면 BOOLEAN MODE는"대한 한민 민국"(순서 매칭)으로 변환되어, “대한”만 포함된 문서는 제외됩니다. - 50% threshold 없음: NATURAL LANGUAGE MODE는 전체 행의 50% 이상에 매칭되는 토큰을 무시합니다. 57만 건에서 흔한 한국어 2-gram 토큰(예: “한국”, “대한”)이 이 임계값을 넘을 수 있어 검색 결과가 누락됩니다.
인덱스 생성 전 테이블 측정
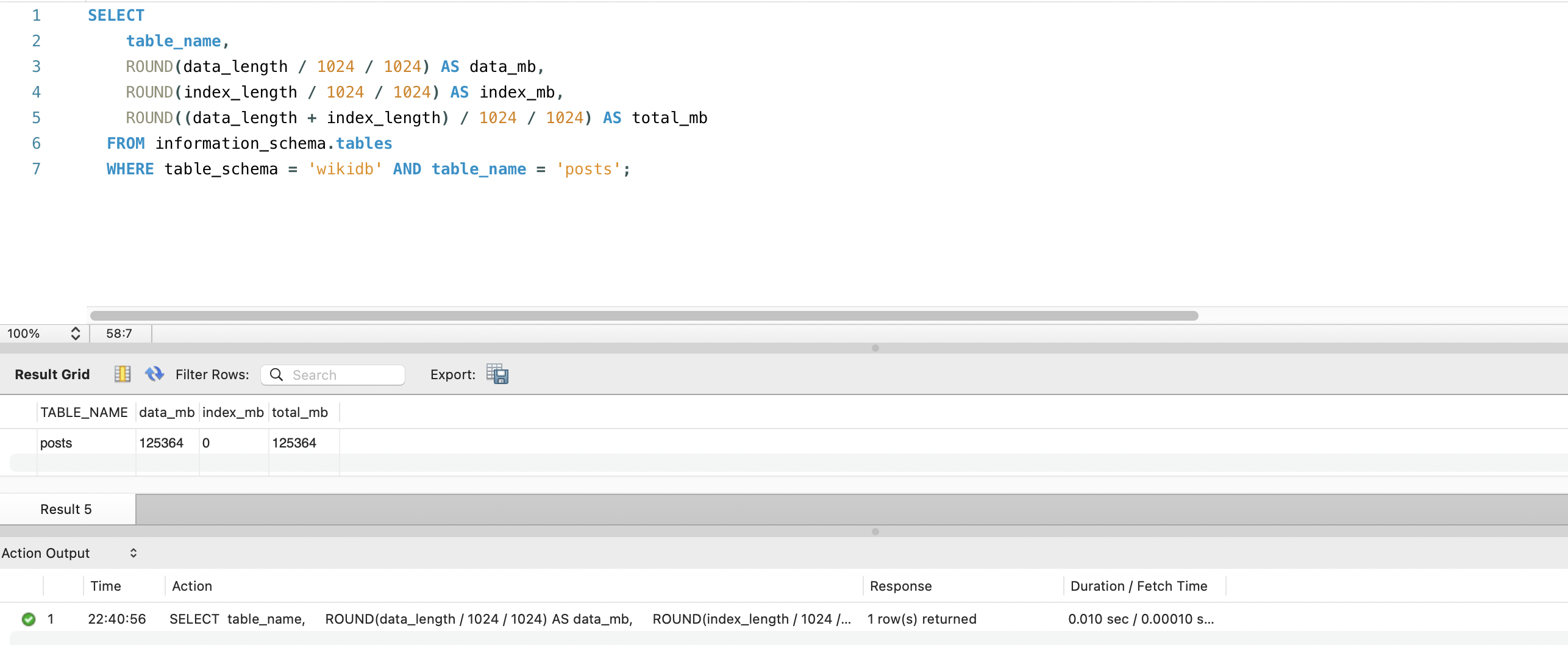
FULLTEXT 인덱스를 생성하기 전에, 현재 테이블의 디스크 크기와 content 컬럼의 통계를 먼저 측정했습니다.
테이블 디스크 크기, 데이터 122GB, 인덱스 0MB:
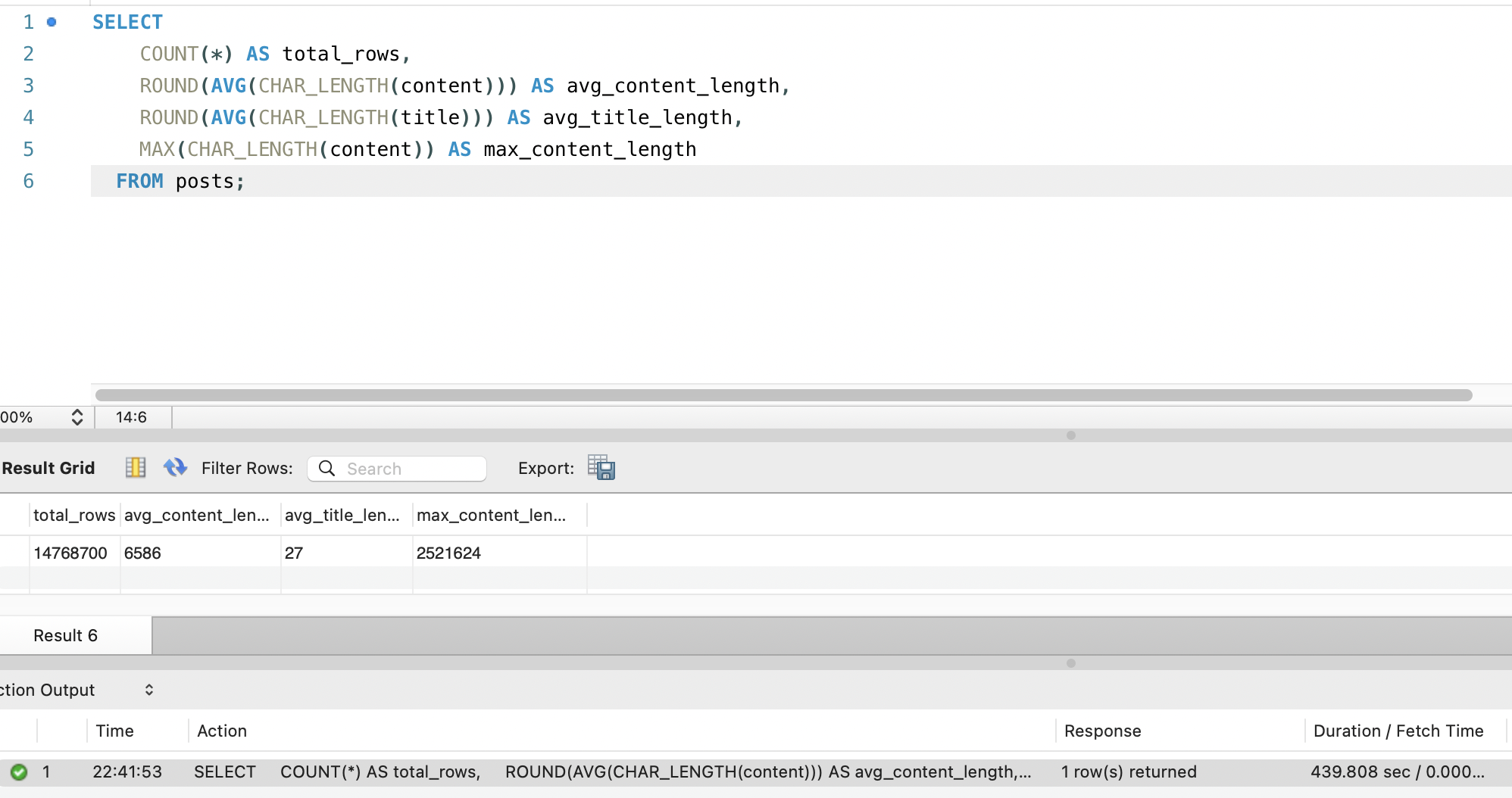
content 컬럼 통계, 14,768,700행, 평균 6,586자, 최대 2,521,624자 (쿼리 소요 439초):
인덱스 생성 전 테이블 현황:
| 항목 | 값 |
|---|---|
| 총 행 수 | 14,768,700 (약 1,477만 건) |
| 데이터 크기 | 122 GB (125,364 MB) |
| 기존 인덱스 크기 | 0 MB |
| 평균 title 길이 | 27자 |
| 평균 content 길이 | 6,586자 |
| 최대 content 길이 | 2,521,624자 (약 252만 자) |
ngram 토큰 수 추정:
| 대상 | 문서당 평균 토큰 수 | 총 토큰 수 |
|---|---|---|
| title만 | 26개 | ~3.8억 개 |
| content만 | 6,585개 | ~973억 개 |
| title + content | ~6,611개 | ~976억 개 |
content 포함 시 토큰 수가 title만 대비 약 250배 증가합니다.
인덱스 크기와 생성 시간이 크게 늘어날 것으로 예상됩니다.
FULLTEXT 인덱스 생성
MySQL 서버 설정에 ngram_token_size=2를 추가한 후, 제목과 본문을 하나의 복합 FULLTEXT 인덱스로 생성합니다.
command: > --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --ngram-token-size=2CREATE FULLTEXT INDEX ft_title_content ON posts(title, content) WITH PARSER ngram;posts 테이블 인덱스 생성 시도: 디스크 초과
1,477만 건 posts 테이블에 FULLTEXT ngram 인덱스를 생성했으나, 85분 경과 시점에 디스크가 가득 찼습니다.
MySQL 공식 문서 (Online DDL Space Requirements)에 따르면, FULLTEXT 인덱스 생성 시 MySQL은 임시 정렬 파일(temporary sort files) 을 생성합니다. 이 파일은 토큰을 정렬하여 역색인에 병합하기 위한 것으로, 테이블 데이터 + 기존 인덱스 크기만큼 의 추가 디스크를 사용합니다. 병합이 완료되면 자동으로 삭제됩니다.

서버 디스크 여유(253GB)로는 감당할 수 없어 KILL 명령으로 인덱스 생성을 중단했습니다.
나무위키 데이터만 분리하여 실험
posts 테이블에는 인덱스를 생성할 수 없으므로, 범위를 좁혀야 합니다.
데이터의 카테고리별 분포를 확인했습니다:
| category_id | 데이터 | 행 수 |
|---|---|---|
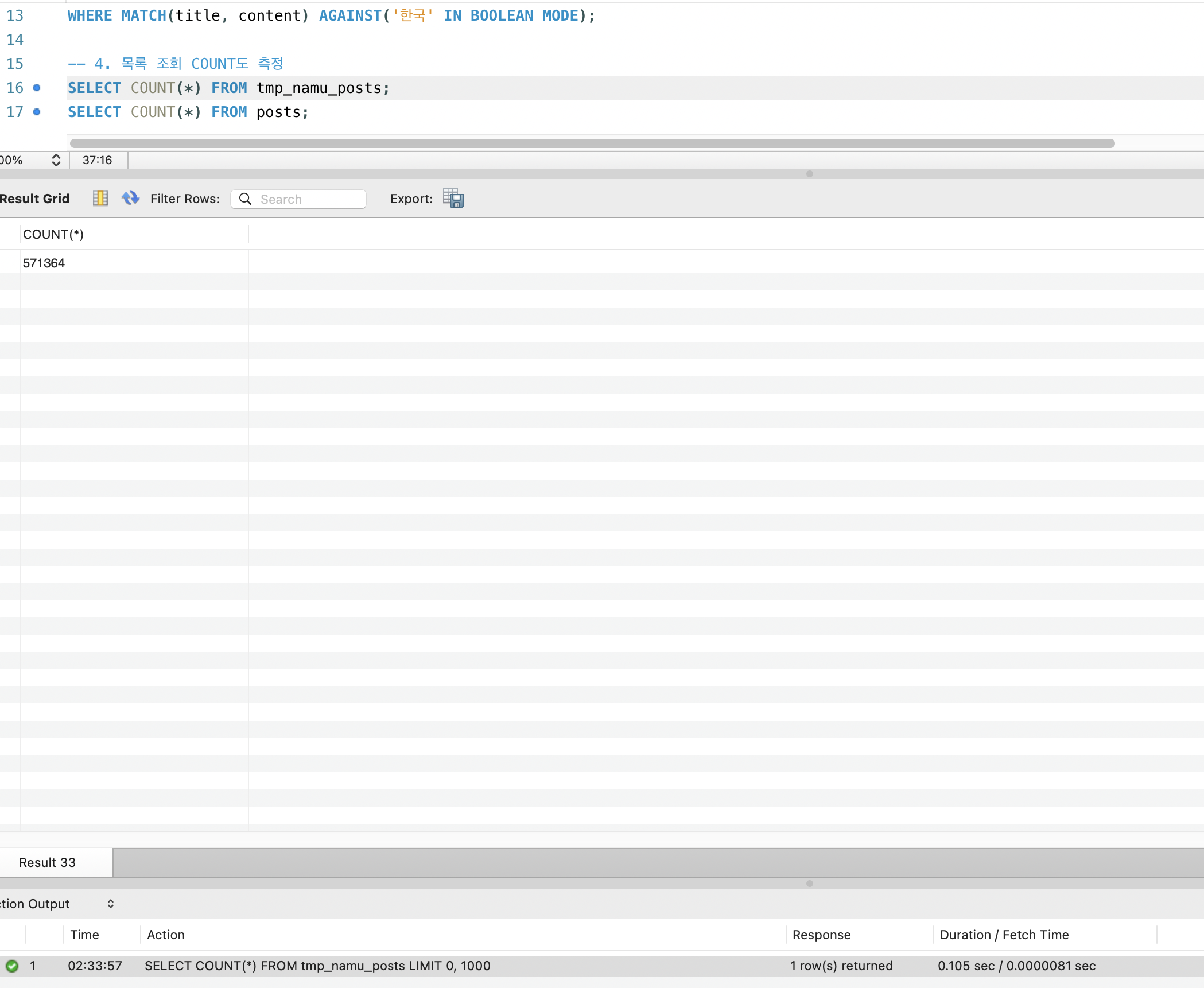
| 1 | 나무위키 (한국어) | 571,364 |
| 2 | 영/한 위키피디아 | ~14,197,336 |
전체 1,477만 건 중 나무위키(category_id=1)는 약 57만 건으로, 전체의 3.9%입니다. 이 범위라면 FULLTEXT 인덱스 크기가 수십 MB 수준으로 예상되어, 디스크 문제 없이 실험할 수 있습니다.
나무위키를 먼저 선택한 이유는 두 가지입니다:
- 한국어 ngram 검증:
ngram_token_size=2가 한국어 검색에 실제로 동작하는지 확인해야 함 - 사용자 검색 패턴: 서비스 특성상 한국어 검색이 주 사용 패턴
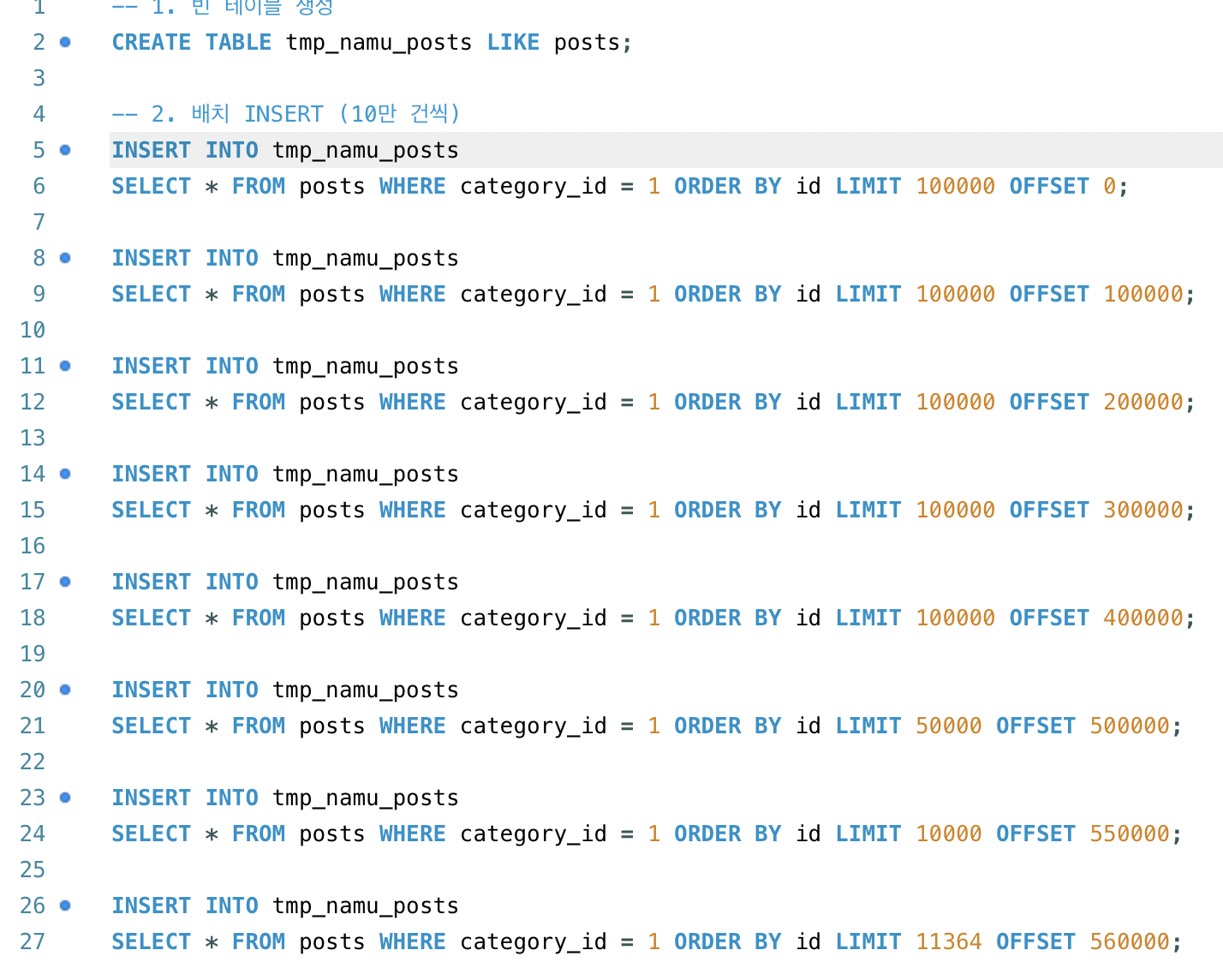
-- 한국어 데이터 전용 테이블 생성CREATE TABLE tmp_namu_posts LIKE posts;
-- 배치 INSERT (5만 건씩, InnoDB 락 테이블 크기 제한으로 분할)INSERT INTO tmp_namu_posts SELECT * FROM posts WHERE category_id = 1 ORDER BY id LIMIT 50000 OFFSET 0;INSERT INTO tmp_namu_posts SELECT * FROM posts WHERE category_id = 1 ORDER BY id LIMIT 50000 OFFSET 50000;-- ... (571,364건 완료)
-- FULLTEXT ngram 인덱스 생성 (57만 건 대상)CREATE FULLTEXT INDEX ft_title_content ON tmp_namu_posts(title, content) WITH PARSER ngram;배치 INSERT를 사용한 이유:
CREATE TABLE AS SELECT로 한 번에 복사하면 57만 건 x LONGTEXT를 하나의 트랜잭션으로 처리하게 됩니다. InnoDB는 트랜잭션 중 변경된 모든 행에 대해 락을 유지하는데, content(LONGTEXT)가 포함된 57만 행의 락이innodb_buffer_pool_size를 초과하여 Error 1206 (lock table size exceeded) 가 발생했습니다. 5만 건씩 분할하여 각 INSERT를 독립 트랜잭션으로 처리하면 락이 누적되지 않습니다.
| 항목 | posts 테이블 (posts) | 한국어만 (tmp_namu_posts) |
|---|---|---|
| 행 수 | 14,768,700 | 571,364 |
| 데이터 크기 | 122 GB | 12 GB |
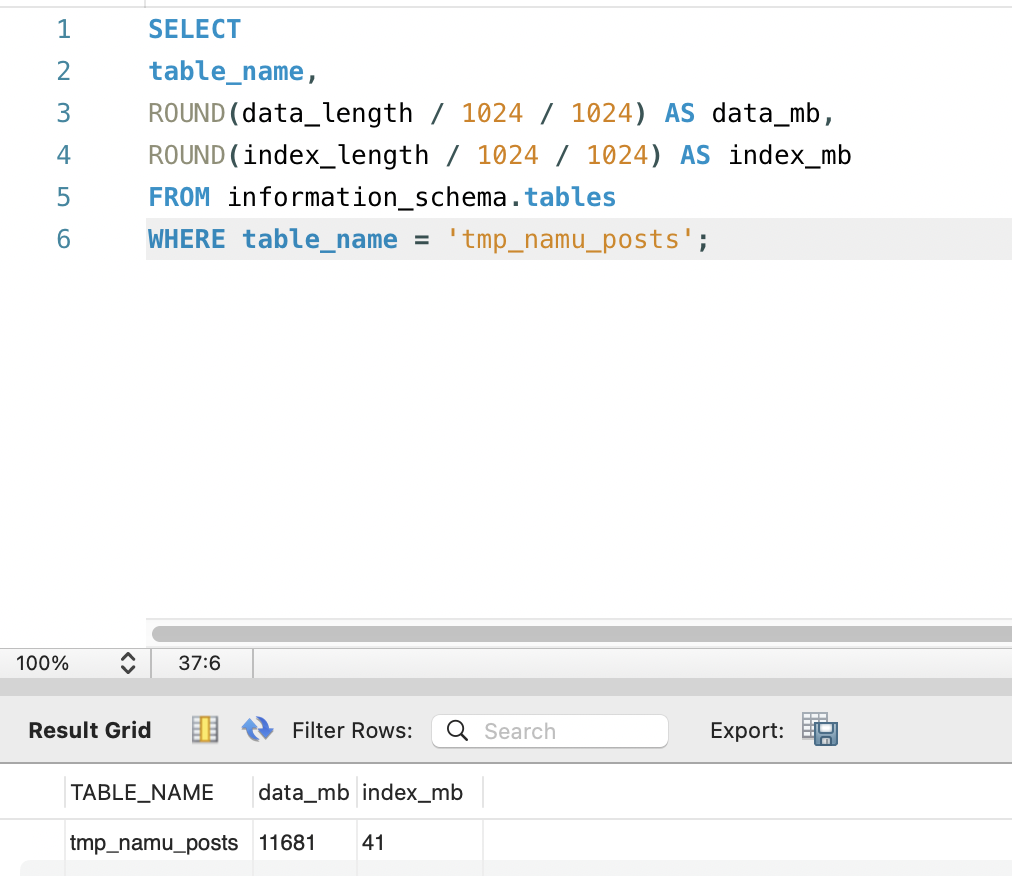
| FULLTEXT 인덱스 크기 | 300 GB+ (디스크 초과) | 6.7 GB |
| 인덱스 생성 | 중단 (85분 경과) | 성공 |
참고:
information_schema.tables.index_length는 B-Tree 인덱스만 포함하며, InnoDB FULLTEXT 인덱스는 별도의 FTS 보조 테이블(fts_*)에 저장됩니다.
실제 FULLTEXT 인덱스 크기는 MySQL 데이터 디렉토리에서 FTS 파일 크기를 합산해야 정확합니다.
검색 쿼리 변경
Spring Data JPA의 JPQL(Java Persistence Query Language)은 JPA 스펙에 정의된 SQL-like 문법만 지원합니다.
MATCH...AGAINST는 MySQL 고유 구문(vendor-specific syntax)이므로 JPQL에서 파싱할 수 없어, nativeQuery = true로 MySQL에 직접 SQL을 전달해야 합니다.
정렬도 기존 created_at DESC(최신순)에서 MATCH...AGAINST 반환값(관련도 스코어) 기반으로 전환합니다.
FULLTEXT 검색에서 MATCH...AGAINST는 0 이상의 부동소수점 값을 반환하며, 이 값이 높을수록 검색어와의 관련도가 높습니다.
검색 대상 테이블을 tmp_namu_posts로 변경하여, 한국어 데이터에 대해서만 FULLTEXT 검색을 수행합니다.
@Query(value = """ SELECT * FROM tmp_namu_posts WHERE MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) ORDER BY MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) DESC, created_at DESC LIMIT :#{#pageable.pageSize} OFFSET :#{#pageable.offset} """, countQuery = """ SELECT COUNT(*) FROM tmp_namu_posts WHERE MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) """, nativeQuery = true)Page<Post> searchByKeyword(@Param("keyword") String keyword, Pageable pageable);5. Before vs After
동일 데이터(tmp_namu_posts, 57만 건)에 동일 검색어(“페텔”)로 비교했습니다.
Before는 인덱스 없이LIKE검색, After는 FULLTEXT ngram 인덱스 적용 후MATCH AGAINST검색입니다.
EXPLAIN 비교
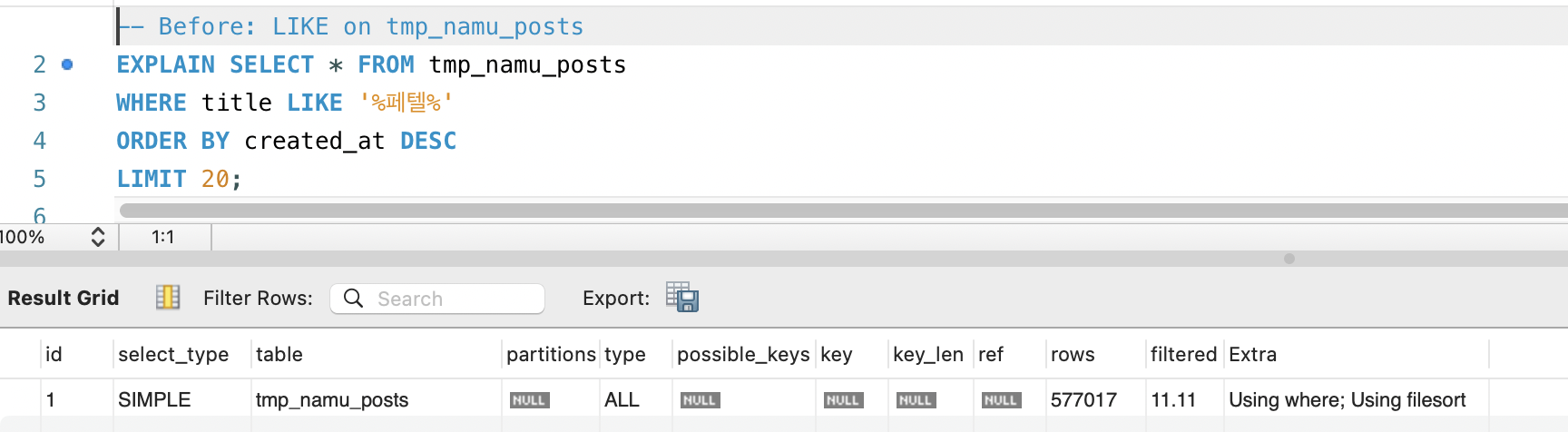
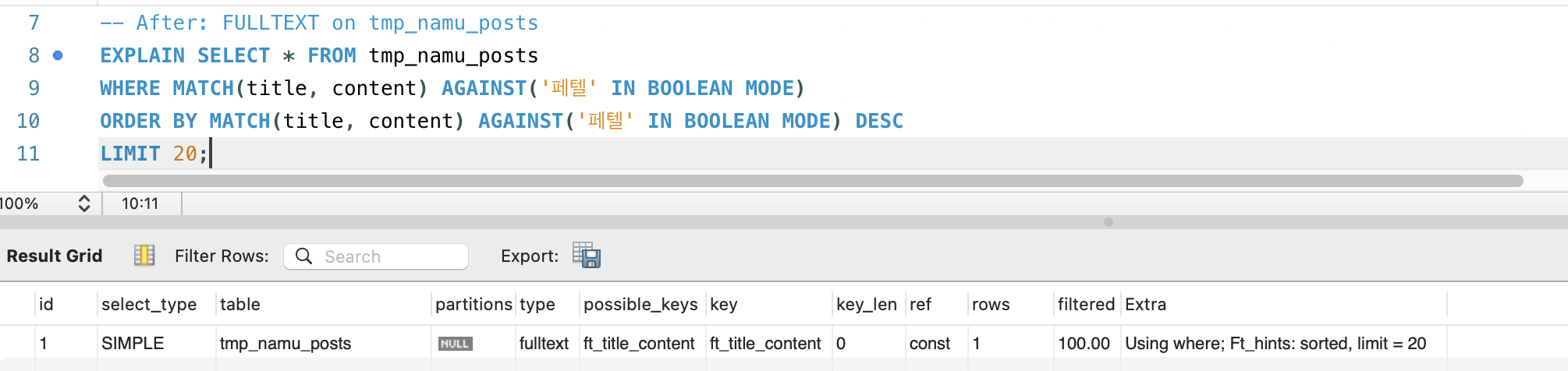
| 구분 | type | key | rows | Extra |
|---|---|---|---|---|
Before: LIKE '%페텔%' | ALL | NULL | 577,017 | Using where; Using filesort |
After: MATCH AGAINST | fulltext | ft_title_content | 1 | Using where; Ft_hints: sorted, limit = 20 |
- type: ALL(전체 행 스캔) → fulltext(역색인 탐색). 스캔 방식 자체가 바뀌었습니다.
- rows: 577,017 → 1. 옵티마이저가 역색인에서 바로 결과를 가져오므로 추정 스캔 행이 1입니다.
- Extra:
Using filesort(디스크 정렬) →Ft_hints: sorted, limit = 20. FULLTEXT 엔진이 관련도순 정렬과 LIMIT을 내부적으로 처리하여 별도 정렬이 불필요합니다.
응답시간 측정
테스트 환경: ARM 2코어 / 12GB RAM. Spring Boot 2GB(JVM 힙 1GB) + MySQL 4GB(InnoDB BP 2GB). 데이터: tmp_namu_posts (57만 건, 12GB).
Before LIKE '%페텔%': 12.766초, 6건 반환 (title만 검색):
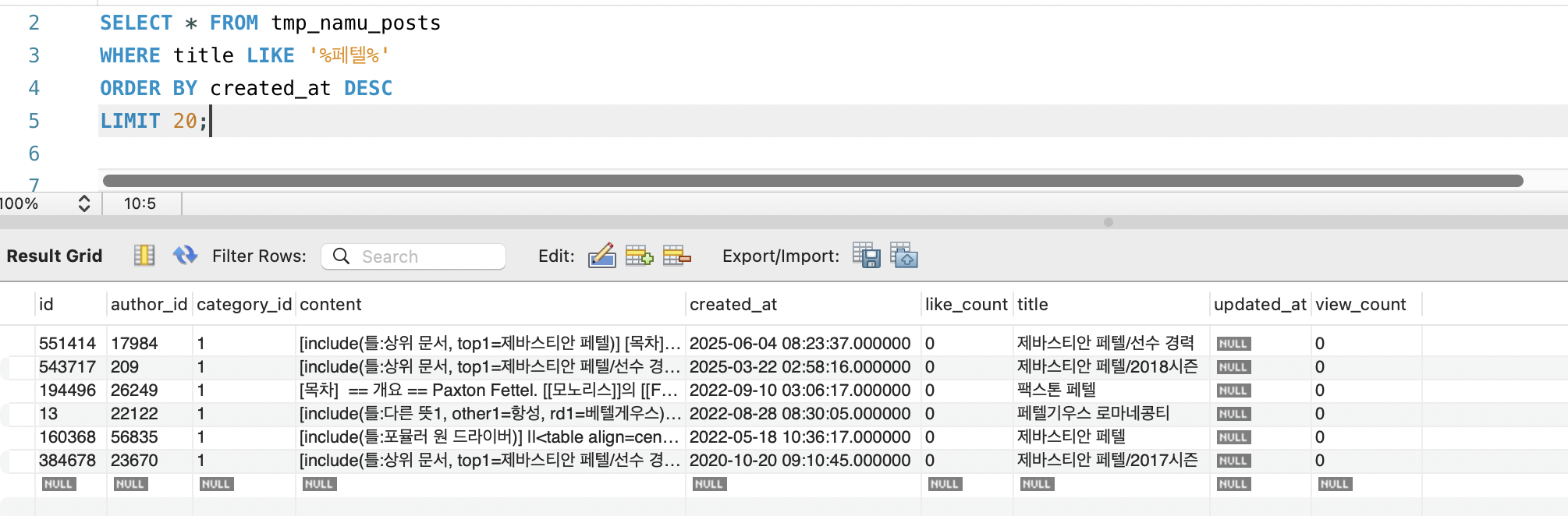

After MATCH(title, content) AGAINST('페텔' IN BOOLEAN MODE): 0.006초, 20건 반환 (title + content 검색):


| 항목 | Before (LIKE) | After (FULLTEXT) | 비고 |
|---|---|---|---|
| 응답시간 | 12,766ms | 6ms | 약 2,100배 개선 |
| 검색 결과 수 | 6건 (title만) | 20건 (title + content) | 본문 검색 복원 |
| 스캔 방식 | Full Table Scan | 역색인 탐색 | EXPLAIN type: ALL → fulltext |
| 정렬 방식 | filesort (디스크) | FULLTEXT 엔진 내부 정렬 | 별도 정렬 비용 제거 |
| 테이블 크기 | 측정 안 함 | 12 GB (57만 건) | tmp_namu_posts 데이터 |
| FULLTEXT 인덱스 크기 | 없음 | 6.7 GB | 데이터 대비 약 56% |
결과 수 차이: 6건 vs 20건
Before(6건)와 After(20건)의 결과 수 차이는 검색 범위가 다르기 때문입니다.
- Before:
LIKE '%페텔%'는 title만 검색합니다.
이전에 content(LONGTEXT) 스캔이 커넥션 풀을 고갈시켜 시스템을 마비시켰고, 긴급 조치로 content 검색을 제거한 상태였습니다.
57만 건 중 제목에 “페텔”이 포함된 문서는 6건뿐입니다. - After:
MATCH(title, content)는 title + content 모두 검색합니다.
FULLTEXT 인덱스 덕분에 content를 스캔하지 않고 역색인에서 토큰을 찾으므로, 본문 검색을 복원해도 성능 문제가 없습니다.
제목에는 없지만 본문에서 “페텔기우스”를 언급하는 문서(예: 별자리, 천문학 관련 문서)가 추가로 매칭됩니다.
즉, FULLTEXT 인덱스는 속도 개선뿐 아니라 검색 품질(recall) 개선도 함께 달성했습니다.
기존에는 성능 문제로 포기했던 본문 검색이 복원되면서, 같은 검색어로 더 많은 관련 문서를 찾을 수 있게 되었습니다.
6. 알려진 한계점
ngram FULLTEXT는 LIKE '%keyword%' 대비 극적인 성능 개선을 제공하지만, 다음과 같은 한계가 있습니다.
6-1. False Positive (오탐)
2-gram 토큰화는 단어 경계 정보를 보존하지 않습니다.

6-2. 형태소 분석 미지원
ngram은 글자 단위로 잘라낼 뿐 형태소 분석을 수행하지 않습니다.

6-3. 고빈도 토큰 성능 저하 (MySQL Bug #85880)
“한국”, “대한” 같은 흔한 2-gram 토큰이 수만 건 이상 매칭되면, MySQL 내부적으로 역색인의 포스팅 리스트를 직렬 탐색하여 성능이 급격히 저하됩니다.
이 문제는 InnoDB FULLTEXT 내부 구현(fts0que.cc)에서 토큰 매칭 결과를 vector(배열) 순차 탐색으로 교집합을 구하기 때문에 발생합니다.
알고리즘 수준의 비효율이므로 파라미터 튜닝으로는 해결할 수 없습니다.
Bug #85880은 2017년 보고 이후 2026년 현재까지 Open(미해결) 상태이며, 보고자가 제출한 패치도 Oracle이 merge하지 않았습니다.
MySQL 자체 튜닝 가능성을 검토한 결과:
| 방법 | 효과 | 판단 |
|---|---|---|
innodb_ft_result_cache_limit 증가 | X. 메모리 상한만 조절, 탐색 알고리즘 그대로 | 효과 없음 |
ngram_token_size 3으로 증가 | 고빈도 2-gram 문제 감소 | ”한국”, “사과”, “경제” 등 2글자 검색 불가 → 한국어에서 치명적 |
| 커스텀 스톱워드 (“대한” 등 제거) | 해당 토큰 타임아웃 해소 | 해당 단어 포함 검색 자체 불가능 → 위키 검색에서 허용 불가 |
| WHERE 조건 추가로 범위 축소 | X. MySQL은 FULLTEXT를 먼저 전체 스캔 후 WHERE 적용 | FULLTEXT 단계 병목 그대로 |
Lucene의 Nori 형태소 분석기는 “대한민국”을 형태소 단위로 분석하므로, ngram의 고빈도 2-gram 토큰 문제가 원천적으로 발생하지 않습니다.
쿼리 모드 변경으로 해결 가능한가?
MySQL FULLTEXT는 세 가지 쿼리 모드를 제공합니다. 각 모드가 고빈도 토큰 타임아웃에 효과가 있는지 검토했습니다.
| 모드 | 고빈도 토큰 해결? | 동작 방식 | 문제점 |
|---|---|---|---|
| NATURAL LANGUAGE MODE | 부분적 | 전체 행의 50% 이상에 등장하는 토큰을 자동 무시 (IDF 기반) | “한국”이 50%+ 문서에 있으면 검색 결과 0건 반환. 검색 품질 하락 |
| BOOLEAN MODE (현재 사용) | X | 50% 규칙 없음. 매칭되는 모든 문서의 포스팅 리스트를 스캔 | 고빈도 토큰의 포스팅 리스트가 길어 탐색 시간이 선형 증가 |
| QUERY EXPANSION | X | 1차 검색 결과에서 연관어 추출 → 2차 검색 재실행 | 검색을 2번 수행하므로 고빈도 토큰에서 2배 더 느림 |
NATURAL LANGUAGE MODE의 50% 규칙은 정보검색 이론의 IDF(Inverse Document Frequency)에 기반합니다. 모든 문서에 등장하는 단어는 검색어로서 변별력이 없다는 개념인데, ngram 2-gram에서는 “한국”, “대한” 같은 의미 있는 검색어까지 필터링해버리는 부작용이 있습니다.
실용적 완화책
근본 해결은 불가능하지만, 현재 ngram 환경에서 타임아웃 빈도를 줄이는 실용적 완화책은 있습니다:
1) Boolean Mode 복합 검색어 강제
-- 단독 검색 → 타임아웃WHERE MATCH(title, content) AGAINST ('한국' IN BOOLEAN MODE)
-- 복합 검색어 → 교집합으로 결과 축소, 빠름WHERE MATCH(title, content) AGAINST ('+한국 +역사' IN BOOLEAN MODE)두 토큰의 포스팅 리스트 교집합만 반환하므로 결과 수가 줄어들어 속도가 개선됩니다. 프론트엔드에서 최소 2단어 이상 입력을 유도하면 실용적이지만, 단일 키워드 검색을 지원할 수 없다는 제약이 있습니다.
2) 커스텀 불용어(stopword) 등록
CREATE TABLE my_stopwords (value VARCHAR(30)) ENGINE=InnoDB;INSERT INTO my_stopwords VALUES ('한국'), ('대한'), ('사람');SET GLOBAL innodb_ft_server_stopword_table = 'wikidb/my_stopwords';-- 이후 FULLTEXT 인덱스 재생성 필요타임아웃을 유발하는 고빈도 토큰을 인덱싱에서 제외합니다. 하지만 해당 키워드로는 검색 자체가 불가능해지므로, 위키 검색엔진에서는 허용할 수 없습니다.
3) LIMIT을 통한 조기 종료 기대
MySQL FULLTEXT는 Ft_hints: sorted, limit = N으로 내부적으로 상위 N건만 반환하는 최적화를 수행하지만, 고빈도 토큰의 포스팅 리스트 전체를 먼저 탐색한 후 정렬하므로 LIMIT이 탐색 자체를 줄이지는 않습니다.
결론: ngram 환경에서 고빈도 토큰 타임아웃은 구조적으로 해결 불가능합니다. 복합 검색어 강제, 불용어 등록 등은 모두 검색 기능을 제한하는 트레이드오프를 수반합니다. 근본 원인은 ngram이 글자를 기계적으로 2개씩 잘라 의미와 무관한 토큰을 대량 생성하는 데 있으며, 이는 형태소 분석 기반 토큰화로만 해결할 수 있습니다.
InnoDB FULLTEXT 내부 아키텍처: 왜 고빈도 ngram은 구조적으로 해결 불가능한가
위에서 “vector 순차 탐색”이 병목이라고 언급했습니다. 이 절에서는 InnoDB FULLTEXT 엔진이 내부적으로 어떤 자료구조와 알고리즘을 사용하며, 왜 고빈도 토큰에서 성능이 폭발하는지를 소스 코드(fts0que.cc) 수준에서 분석합니다.
1) 저장 구조: 6개 보조 테이블(Auxiliary Tables)
FULLTEXT 인덱스를 생성하면 MySQL은 6개의 보조 테이블을 자동 생성합니다.

토큰의 첫 글자 정렬 가중치(character set sort weight) 기준으로 6개 테이블에 분배됩니다. 이는 병렬 인덱싱을 위한 설계이며, innodb_ft_sort_pll_degree(기본 2스레드)로 조정 가능합니다.
각 보조 테이블에는 역색인이 저장됩니다. 각 항목은 (토큰, posting list) 형태이며, posting list에는 DOC_ID + 바이트 오프셋 위치(position) 가 포함됩니다.

또한 InnoDB는 빈번한 소규모 INSERT 시 보조 테이블의 동시 접근 경합을 줄이기 위해 FTS 캐시를 유지합니다. 최근 삽입된 행의 토큰을 메모리에 임시 저장한 후, 캐시가 차면 보조 테이블로 일괄 flush합니다. 검색 시에는 보조 테이블(디스크)과 캐시(메모리) 결과를 병합합니다.
2) 쿼리 처리 파이프라인: fts0que.cc
fts0que.cc는 InnoDB FULLTEXT 검색의 핵심 쿼리 처리 엔진입니다. MATCH(title, content) AGAINST('대한민국' IN BOOLEAN MODE) 실행 시 내부 처리 흐름:

3) 교집합 단계 (3단계): RB-tree, 여기는 OK
fts_query_intersect()는 RB-tree(Red-Black Tree)를 사용합니다.

RB-tree는 O(log n) 탐색이므로 이 단계 자체는 치명적이지 않습니다.
4) 구절 검증 단계 (4단계): ib_vector_t 순차 탐색, 여기가 병목
ngram 검색에서 “대한민국”은 3개 토큰의 구절(phrase) 검색입니다. 교집합으로 후보를 줄인 후, 각 후보 문서에서 토큰이 연속 위치에 존재하는지 검증해야 합니다.
fts0que.cc의 핵심 자료구조:
// InnoDB 내부 자료구조struct fts_match_t { doc_id_t doc_id; // 문서 ID ulint start; // 구절 매칭 시작 오프셋 ib_vector_t *positions; // 단어 위치 오프셋 배열 ← vector(동적 배열)};ib_vector_t는 InnoDB 내부 동적 배열로, C++의 std::vector와 유사합니다. 접근은 ib_vector_get(positions, i)로 인덱스 기반 순차 접근합니다.
fts_query_match_phrase()의 알고리즘 (소스 코드 기반 의사코드):
// 각 후보 문서에 대해 구절 검증 실행for (i = phrase->match->start; i < ib_vector_size(positions); i++) { // positions = 해당 문서에서 첫 번째 토큰("대한")의 모든 출현 위치 pos = ib_vector_get(positions, i); // O(1) 접근이지만 모든 위치를 순회
// 이 위치부터 나머지 토큰("한민", "민국")이 연속하는지 확인 // → fts_query_match_phrase_terms() // → 문서 텍스트를 읽어서 토큰 단위로 순차 비교 matched = fts_query_match_phrase_terms(phrase, pos);
if (matched) break; // 매칭 성공}문제의 본질:

5) 고빈도 토큰에서 폭발하는 이유
단일 토큰 검색(“대한”)의 경우, 교집합 없이 196,593건 전부가 후보가 됩니다.

희귀 토큰 “페텔” 검색 결과는 20건, 0.023초:
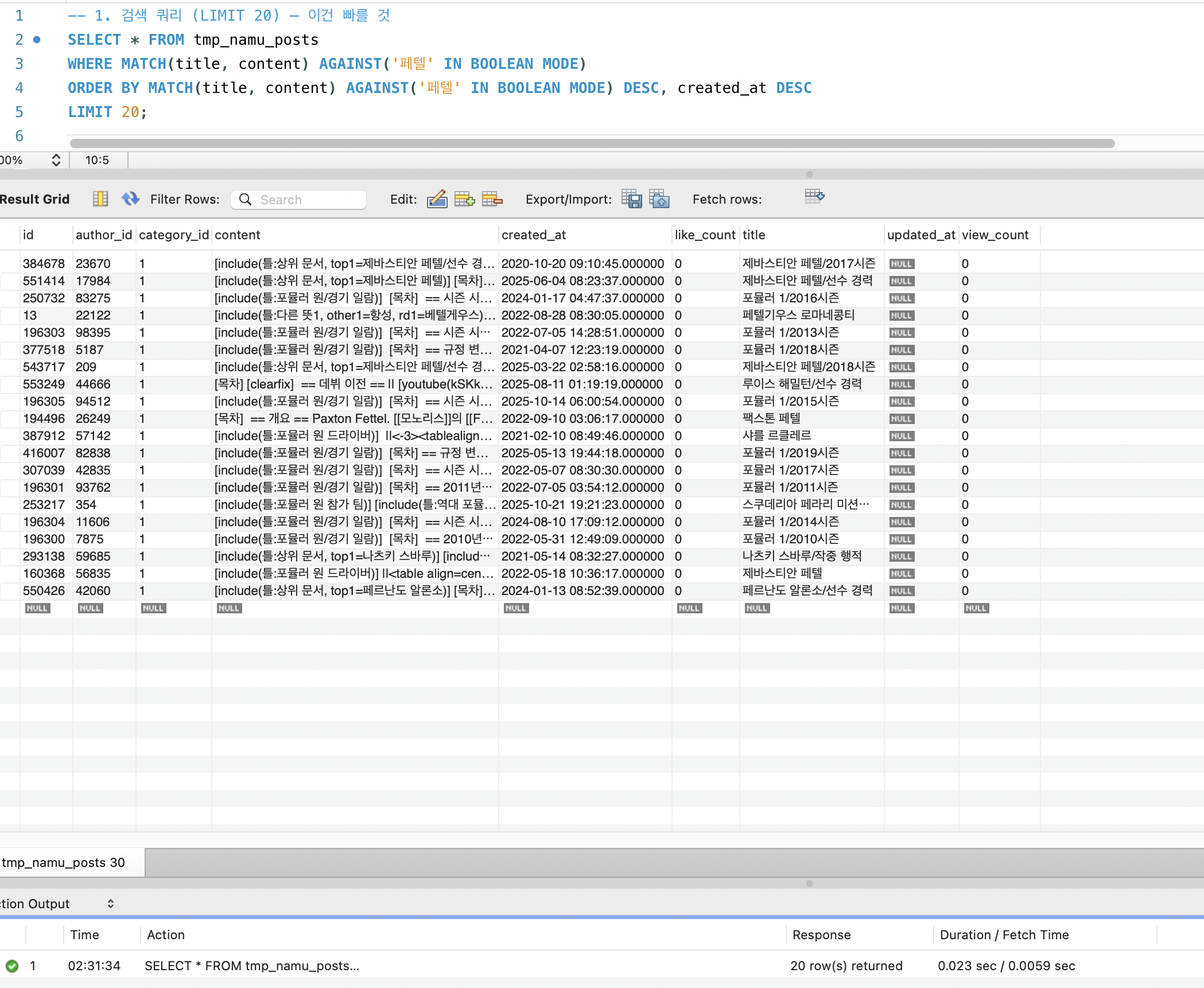
“페텔” 매칭 문서 수는 406건:
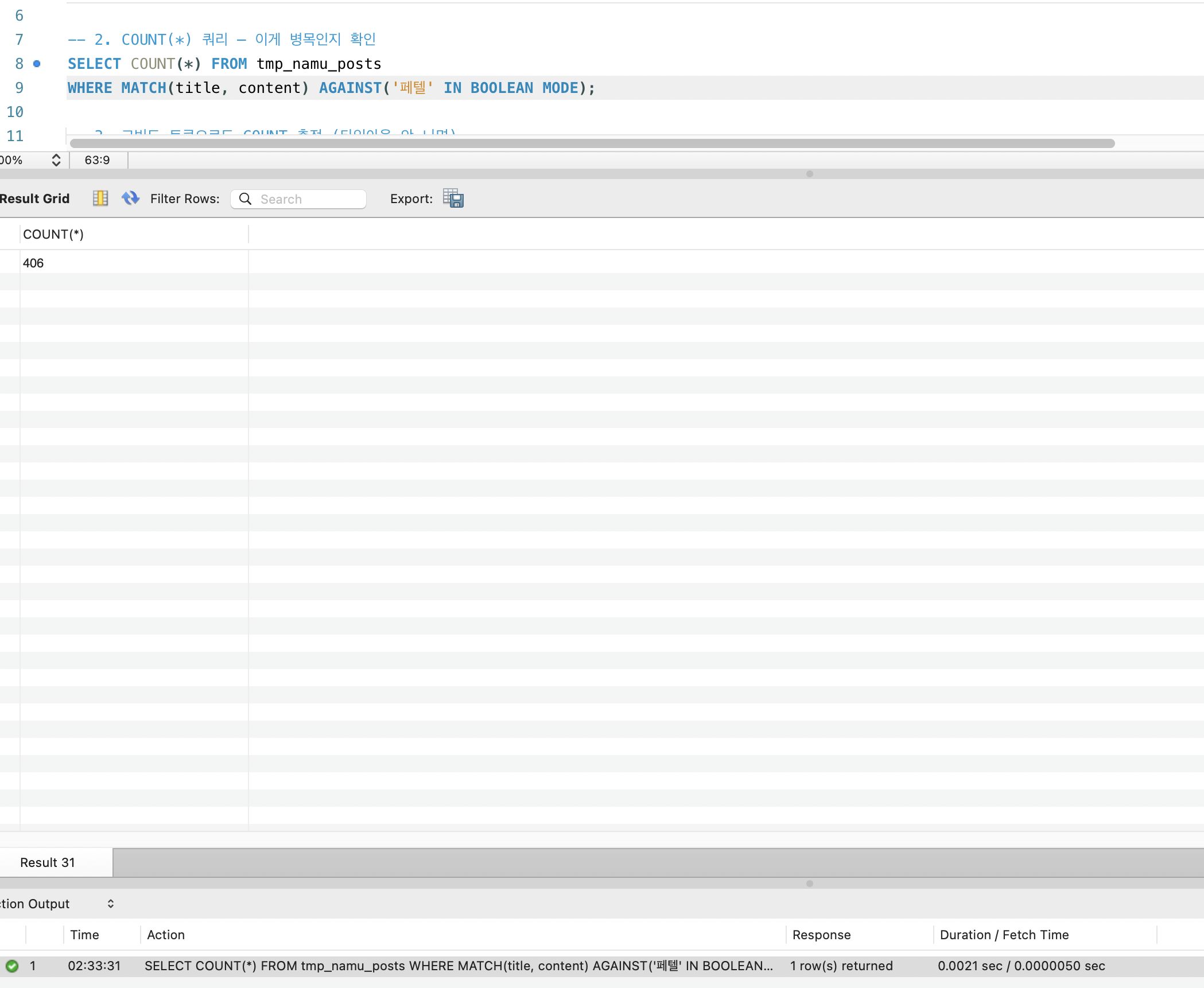
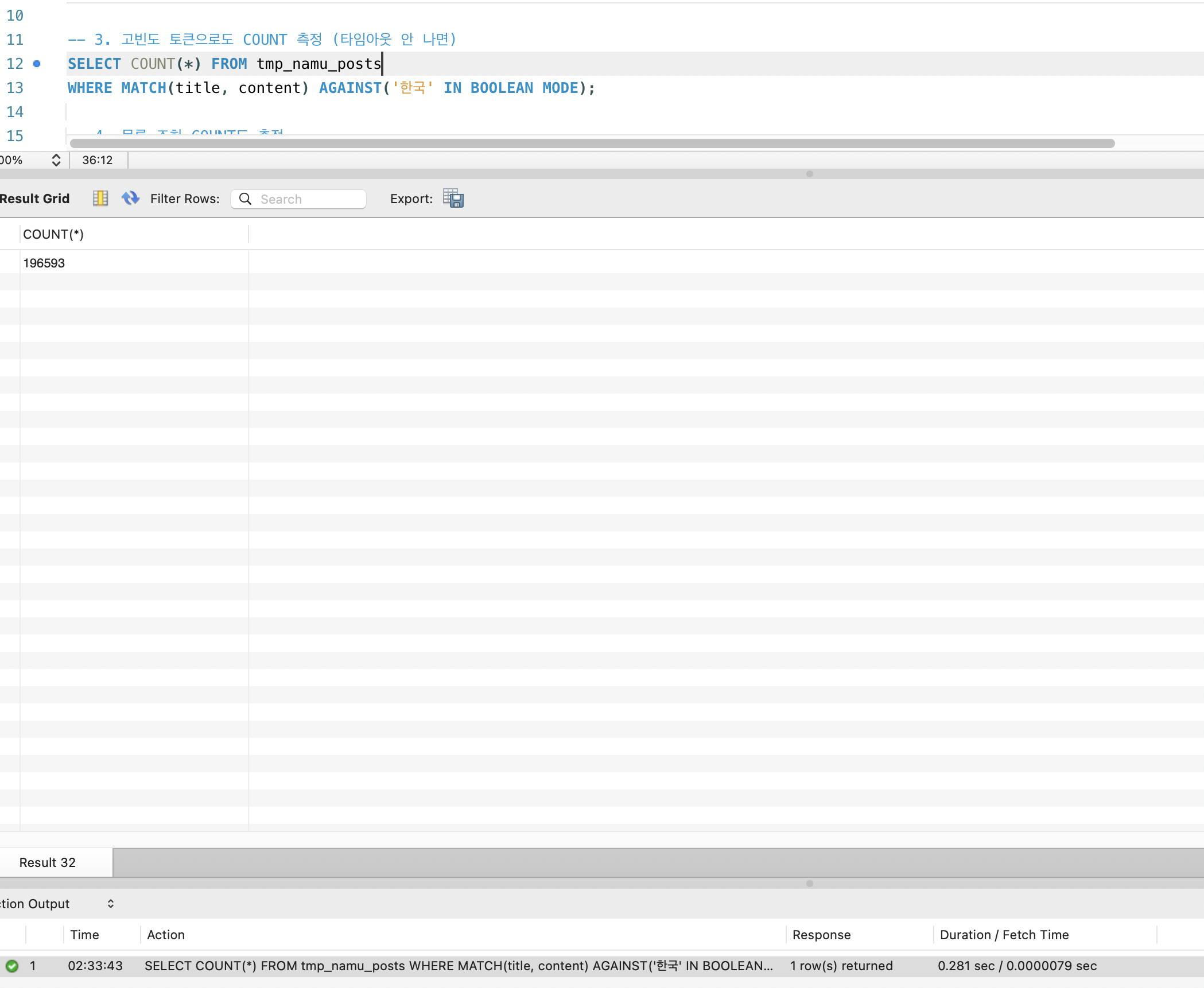
고빈도 토큰 “한국” 매칭 문서 수는 196,593건:
| 검색어 | 매칭 문서 수 | 처리 방식 | 소요시간 |
|---|---|---|---|
| ”페텔” | 406 | 406건 순차 처리 | 23ms |
| ”한국” | 196,593 | 19.6만 건 순차 처리 | 281ms |
| ”대한” | 19.6만+ | 19.6만+ 건 순차 + 구절 검증 | 5초+ 타임아웃 |
시간이 매칭 문서 수에 선형 비례한다. 매칭 문서가 500배 늘면 시간도 ~500배 느려집니다.
6) Bug #85880 리포터가 제안한 해결책: Oracle이 거부
Bug #85880 리포터는 한국어 검색에서 “중국가을”(토큰: “중국” 22만 건, “국가” 5.9만 건, “가을” 4.5만 건)이 7.55초 걸리는 문제를 재현하고, 두 가지 패치를 제안했습니다:
| 해결책 | 방식 | 결과 | Oracle 대응 |
|---|---|---|---|
| HashMap으로 교체 | ib_vector_t(순차 탐색 O(n)) → HashMap(조회 O(1))으로 교집합 가속 | 구절 검증 병목은 남음 | merge하지 않음 |
| Multi-gram 인덱싱 | ngram_token_size를 고정 2가 아닌 2~4 범위로 확장. “대한민국” 자체를 하나의 토큰으로 인덱싱 | 0.01ms로 해결 | merge하지 않음 |
Multi-gram 패치는 7.55초 → 0.01ms로 75만 배 개선되었지만, Oracle은 9년간(2017→2026) 이 패치를 merge하지 않았습니다. InnoDB FTS는 Oracle 내부에서만 수정 가능한 코드이므로, 외부 기여 패치가 있어도 Oracle이 채택하지 않으면 적용할 수 없습니다.
7) 전체 파이프라인 요약

출처: MySQL Bug #85880, fts0que.cc File Reference, InnoDB Full-Text Indexes, Pythian: MySQL InnoDB’s Full Text Search Overview
6-4. 인덱스 크기와 생성 비용
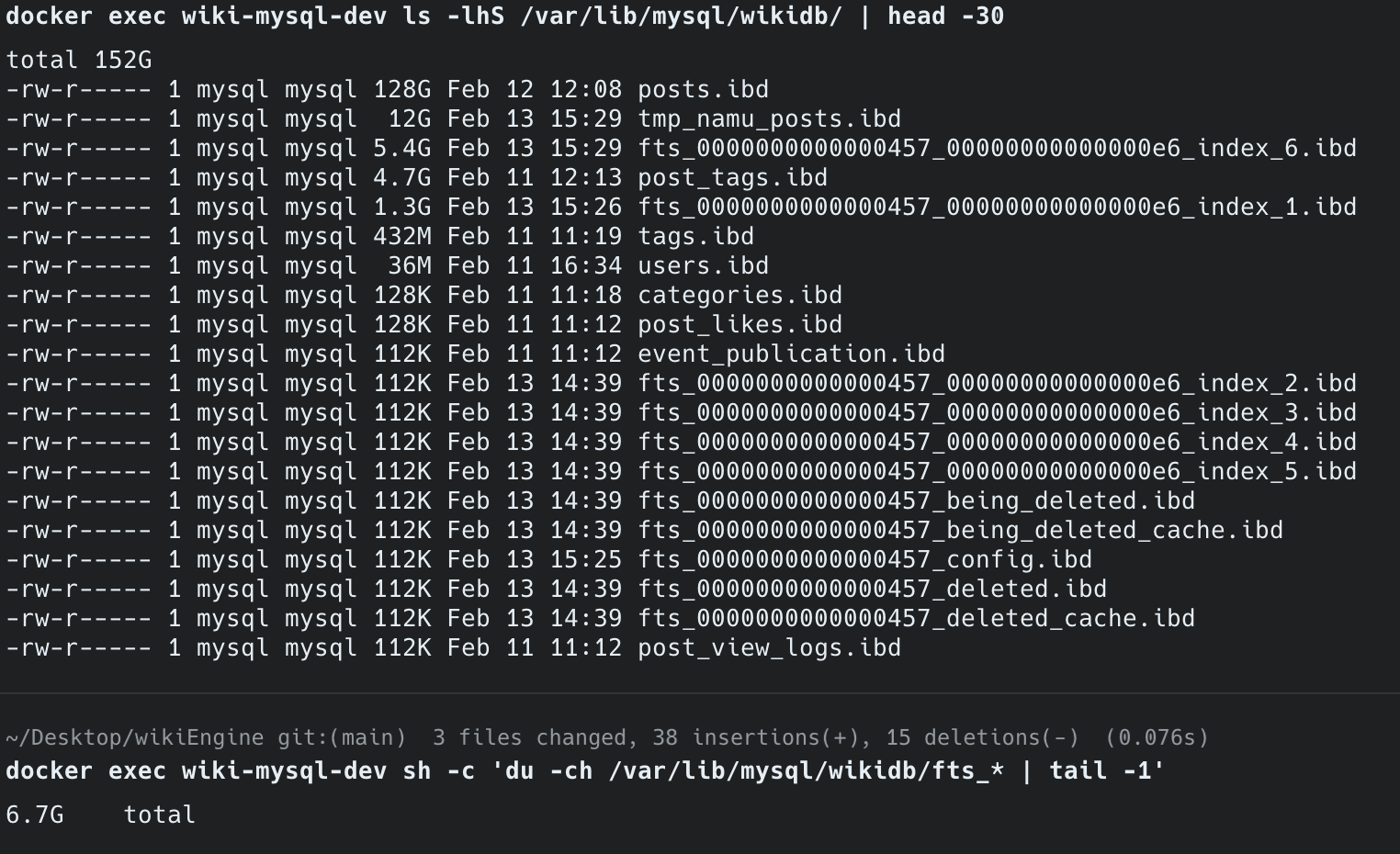
title + content 복합 FULLTEXT 인덱스는 content(LONGTEXT)의 모든 2-gram 토큰을 역색인에 포함하므로 인덱스 크기가 상당합니다.
한국어 57만 건(데이터 12GB)에 대해서도 FULLTEXT 인덱스가 6.7GB(데이터 대비 56%)를 차지합니다.
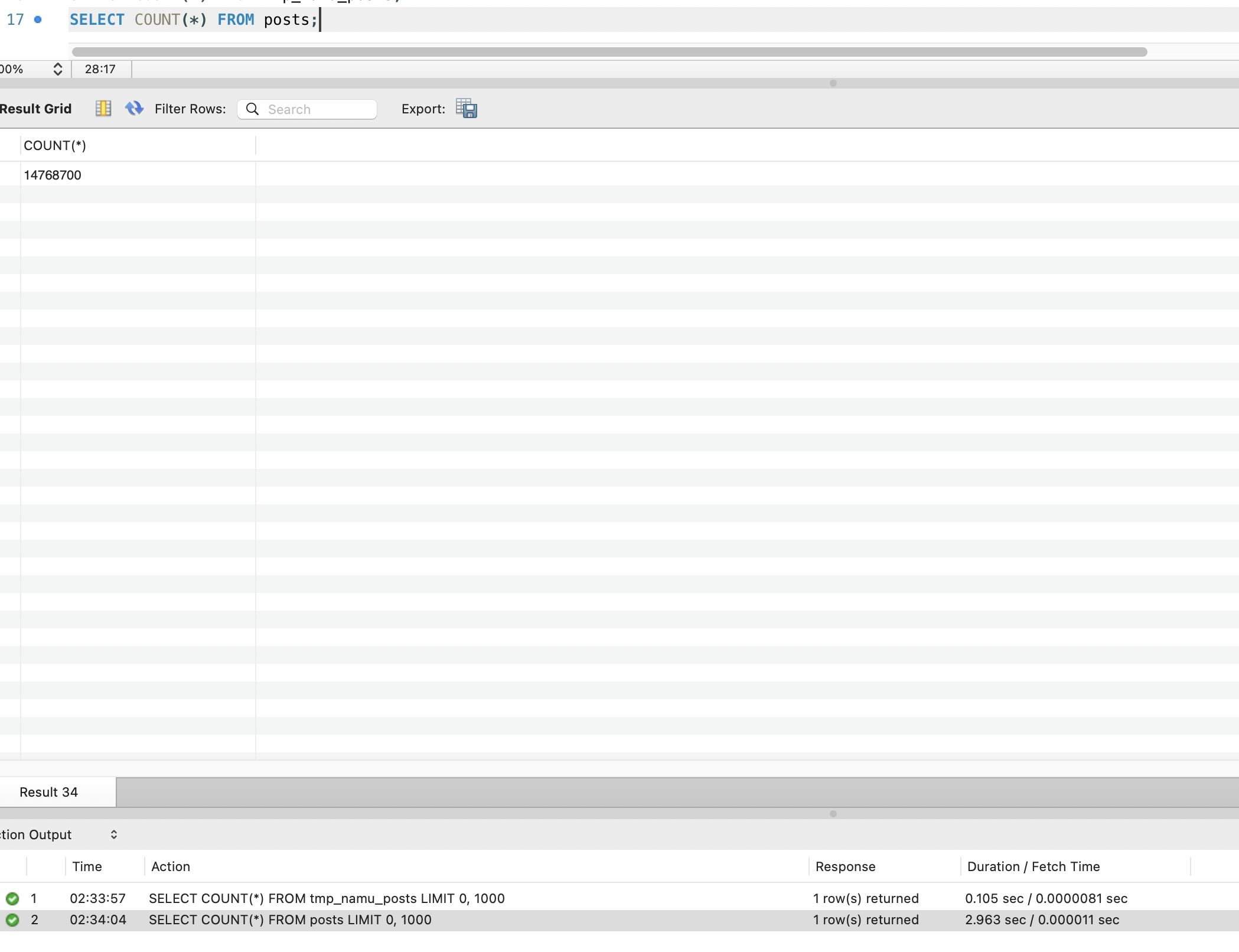
Posts 테이블(1,477만 건, 122GB)에 인덱스를 생성했을 때는 300GB를 초과하여 서버 디스크(여유 253GB)로 감당이 불가능했습니다.
전체 데이터 검색을 위해서는 Lucene 전환이 필수적입니다.
결론: ngram FULLTEXT는 “검색이 아예 안 되는 상태”를 “제목 + 본문 검색이 동작하는 상태”로 전환하는 데 효과적입니다. 검색 품질(정확도, 형태소 분석)은 Lucene + Nori 형태소 분석기로 해결합니다.
6-5. Row-Oriented 저장 구조가 FULLTEXT 인덱스 비용을 증폭시키는 이유
300GB+ 디스크 초과는 단순히 “데이터가 많아서”가 아니라, MySQL의 Row-Oriented 저장 구조에서 비롯되는 구조적 문제입니다.
MySQL(InnoDB)은 Row-Oriented 스토리지입니다. 하나의 행을 구성하는 모든 컬럼(id, title, content, created_at, …)이 디스크의 같은 페이지에 연속으로 저장됩니다.

FULLTEXT 인덱스를 생성할 때, MySQL은 모든 행의 title과 content를 읽어서 ngram 토큰을 추출해야 합니다. 그런데 Row-Oriented 구조에서는 content 컬럼만 읽을 수 없습니다. 디스크에서 행 전체를 읽은 후 content 값을 추출해야 합니다. 즉, title(평균 27자)과 content(평균 6,586자)의 ngram 토큰을 만들기 위해 행의 모든 컬럼(122GB)을 디스크에서 읽어야 합니다.
여기에 더해, MySQL 공식 문서(Online DDL Space Requirements)에 따르면 FULLTEXT 인덱스 생성 시 임시 정렬 파일이 필요합니다. 토큰을 사전순으로 정렬하여 역색인에 병합하기 위한 것으로, 이 파일 크기는 테이블 데이터 크기에 비례합니다.
반면, BigQuery 같은 Column-Oriented 스토리지는 컬럼별로 독립 저장합니다. 만약 Column-Oriented였다면, content 컬럼 파일만 읽으면 되므로 불필요한 I/O가 발생하지 않습니다.

이것이 MySQL FULLTEXT의 본질적 한계입니다:
| 관점 | Row-Oriented (MySQL) | Column-Oriented (BigQuery 등) |
|---|---|---|
| 토큰 추출 시 I/O | 행 전체(122GB) 읽기 | 필요한 컬럼만 읽기 |
| 임시 정렬 파일 | 데이터 크기(122GB)에 비례 | 컬럼 크기에 비례 (훨씬 작음) |
| OLTP 쿼리 (INSERT/UPDATE) | 효율적 (한 행을 한 번에 쓰기) | 비효율적 (여러 파일에 분산 쓰기) |
MySQL은 OLTP(트랜잭션 처리)에 최적화된 Row-Oriented DB입니다. 단건 INSERT/UPDATE/DELETE가 빠른 대신, “특정 컬럼만 대량으로 읽는” 분석 워크로드에는 구조적으로 불리합니다. FULLTEXT 인덱스 생성은 사실상 “content 컬럼 1,477만 개를 전부 읽어서 토큰화하는” 분석 워크로드이므로, Row-Oriented 구조에서 비용이 극대화된 것입니다.
이 관점에서 Lucene 전환의 의미가 더 명확해집니다. Lucene은 역색인 전용 스토리지로, 토큰화된 데이터를 자체적으로 세그먼트(segment) 파일에 저장합니다. MySQL의 Row-Oriented 페이지를 경유하지 않으므로, 인덱스 생성 시 불필요한 I/O가 발생하지 않습니다.
결론: ngram FULLTEXT는 “검색이 아예 안 되는 상태”를 “제목 + 본문 검색이 동작하는 상태”로 전환하는 데 효과적입니다. 다만, Row-Oriented 저장 구조의 한계로 인해 대규모 데이터에서는 인덱스 생성 비용이 극대화됩니다. 검색 품질(정확도, 형태소 분석)과 인덱스 확장성은 Lucene + Nori 형태소 분석기로 해결합니다.
7. 현재 위치와 남은 문제
해결된 것:
- 자동완성
LIKE 'prefix%'-> B-Tree 인덱스 - 검색
LIKE '%keyword%'-> FULLTEXT ngram 인덱스 (한국어 57만 건 대상)
확인된 한계:
- 인덱스 크기: posts 테이블(1,477만 건) 대상 FULLTEXT ngram 인덱스가 300GB+로, 현재 서버 디스크로 감당 불가. 한국어 데이터만 분리하여 우회 중
- 검색 범위: 현재 한국어(나무위키) 데이터만 검색 가능, 영어 위키 데이터는 검색 대상에서 제외
- 검색 품질: False Positive, 형태소 분석 미지원
- 고빈도 토큰 타임아웃: “페텔”처럼 희귀한 토큰은 6ms 만에 406건을 반환하지만, “대한”처럼 수만 건 이상의 문서에 등장하는 고빈도 토큰은 포스팅 리스트 탐색에 5초 이상 소요되어 타임아웃이 발생한다. MySQL Bug #85880에 해당하는 문제로, 내부 알고리즘(vector 순차 탐색) 수준의 비효율이라 파라미터 튜닝으로는 해결 불가능하다
부하 테스트 시점:
계획했던 k6 부하 테스트 Baseline은 “검색이 최소한 동작하는 상태에서 실행한다”는 전제였다. 현재 희귀 토큰은 동작하지만 고빈도 토큰은 여전히 타임아웃이므로, 실제 사용자 검색 패턴을 반영한 부하 테스트가 불가능하다. k6 Baseline 부하 테스트는 Lucene 전환 후, 모든 검색어가 안정적으로 동작하는 상태에서 실행한다.
Previous Post Summary
Added a B-Tree composite index to autocomplete (LIKE 'prefix%') to resolve the timeout.
(EXPLAIN rows 27,440,000 -> 1, >5,000ms -> 8ms)
However, search (LIKE '%keyword%') uses a leading wildcard, so it cannot use B-Tree indexes.
Still in Full Table Scan -> 5-second timeout -> search functionality unusable state.
1. Expected Search Behavior
When a user enters a search term, the system returns posts containing that keyword in the title or body.
Initially, both title and body were searched, sorted by newest first (ORDER BY created_at DESC):
However, content (LONGTEXT) scanning exhausted the connection pool and brought the system down, so content search was removed as an emergency measure.
Currently only title is searched. We apply FULLTEXT index to both title + content to restore body search and switch sorting to relevance-based.
2. Problem State — 100% Search Timeout
Even after applying indexes, search queries consistently time out.
EXPLAIN Analysis
| Item | Value | Meaning |
|---|---|---|
| type | ALL | Full Table Scan |
| possible_keys | NULL | No available indexes |
| key | NULL | No index used |
| rows | 27,440,000 | Full row scan (InnoDB optimizer estimate) |
| Extra | Using where; Using filesort | WHERE filter + sort both processed on disk |
Note: EXPLAIN’s rows=27,440,000 is an InnoDB optimizer estimate. The actual row count measured with
COUNT(*)is 14,768,700. InnoDB’s statistical sampling can differ from actual by 2-5x. Subsequent analysis uses actual measurements.
Autocomplete works, but search remains unusable. Cannot find documents by keyword across 14.77 million records.
3. Alternative Evaluation — Why FULLTEXT ngram
B-Tree Index Limitations
LIKE '%keyword%' uses a leading wildcard. B-Tree indexes are sorted from the beginning of values, so they cannot determine where a keyword is located within a string and thus cannot use the index.
LIKE '페텔%'-> Can range scan from the “페” positionLIKE '%페텔%'-> Cannot determine where “페텔” is in the string -> full scan
This is a fundamental limitation of the B-Tree data structure. B-Tree solves “find rows starting with this value,” but what we need is “find rows containing this value somewhere.” Since the data structure is solving a different problem, no amount of tuning on B-Tree can solve this.
Then what data structure can “quickly find documents containing a specific keyword”? This question led us to study the field of Information Retrieval (IR).
Inverted Index — The Answer from IR Textbooks
From Introduction to Information Retrieval Chapter 3 (Tokens and Terms) and [Theory and Practice of Information Retrieval] Chapter 2 (Inverted Index), we learned that the core data structure for text search is the inverted index.
An inverted index consists of a Dictionary and Posting Lists. The dictionary is a list of all terms in the document collection, and each term links to a posting list pointing to documents where that term appears.
The reason LIKE '%keyword%' is slow is the absence of an inverted index. Without one, there is no way to know which documents contain the keyword, so every row must be read. With an inverted index, you look up the keyword in the dictionary and immediately return document IDs from the posting list.
This is the fundamental difference from string algorithms like KMP, Trie, or Bloom Filter. KMP reduces comparison speed within a single row from O(n*m) to O(n+m), while inverted indexes reduce the number of rows that need to be read. The bottleneck is not string comparison but disk I/O reading 14.77 million rows, so an inverted index is needed.
Inverted Index Implementation Comparison
After confirming the need for an inverted index, the MySQL 8.0 Full-Text Search documentation confirmed MySQL supports built-in inverted indexes (FULLTEXT indexes). We compared implementation approaches with external search engines.
| Approach | Inverted Index Implementation | Pros | Cons | Decision |
|---|---|---|---|---|
| MySQL FULLTEXT ngram | MySQL built-in, ngram tokenization | No additional infrastructure, immediately applicable | No morphological analysis, false positives | O |
| Elasticsearch | Lucene-based inverted index | Morphological analysis, BM25 scoring, distributed processing | Cluster operations, data sync, infrastructure cost | Premature |
| PostgreSQL GIN + trigram | GIN index-based inverted index | Substring search via trigram | Not supported in MySQL, requires DB migration | X |
Why Not Adopt Elasticsearch Now
Elasticsearch also uses Lucene’s inverted index internally. It is the ultimate solution, but adopting it now means:
- Operational complexity: Cluster operations, monitoring, incident response
- Data synchronization: Ensuring consistency between MySQL <-> Elasticsearch (additional Debezium/CDC infrastructure)
- Infrastructure cost: Minimum heap 16GB+, ARM server memory limits
- Overkill for current requirements: Title + content keyword search is sufficient with MySQL built-in FULLTEXT
We first make search work with MySQL built-in FULLTEXT ngram without additional infrastructure, then transition to Lucene when search quality limitations become apparent.
4. Solution — FULLTEXT ngram Index
What is ngram Parser
According to MySQL documentation: ngram Full-Text Parser, the ngram parser splits text into n-character tokens and stores which documents contain each token in an inverted index.
When ngram_token_size=2:
When executing MATCH(title, content) AGAINST('페텔' IN BOOLEAN MODE), MySQL finds the “페텔” token in the inverted index and immediately returns matching document IDs. No need to scan 14.77 million rows.
Why ngram_token_size=2
ngram_token_size determines the number of characters per token, and words shorter than this value are not indexed. MySQL documentation and the MySQL official Korean blog recommend 2 (bigram) for CJK (Chinese/Japanese/Korean).
| token_size | Minimum Searchable Unit | Korean Suitability |
|---|---|---|
| 1 | 1 character (물, 산) | Korean has only ~11,172 complete syllables, matching almost every document -> extreme noise |
| 2 | 2 characters (사랑, 학교) | Exact match for most frequent Korean 2-syllable words, MySQL CJK official recommendation |
| 3 | 3 characters (프로그, 데이터) | Cannot search 1-2 syllable words (사랑, 학교, 물) -> critical |
Overall data has far more English Wikipedia (~14.2M) than Korean Namuwiki (~570K), but ngram_token_size=2 is also effective for English. Most English words are 2+ characters, and the ngram parser treats spaces as hardcoded stopwords, naturally achieving word-level tokenization. 2 is optimal for both CJK and English.
Why BOOLEAN MODE
MySQL FULLTEXT provides two search modes. We chose based on MySQL documentation: Boolean Full-Text Searches and the MySQL official Korean blog.
The key difference between modes in ngram parser is how the search term is converted to tokens:
| Mode | ngram Conversion | Example (searching '페텔기') | Issues |
|---|---|---|---|
| NATURAL LANGUAGE MODE | ngram union (OR) | 페텔 OR 텔기 | Matches if only “페텔” or “텔기” present -> more false positives. 50% threshold ignores common tokens |
| BOOLEAN MODE | ngram phrase search (order matching) | "페텔 텔기" | ”페텔” followed by “텔기” in order required -> fewer false positives |
Two reasons for choosing BOOLEAN MODE:
- Phrase search conversion: ngram tokens must match in order, resulting in fewer false positives than NATURAL LANGUAGE MODE’s union approach. For example, searching
'대한민국'converts to"대한 한민 민국"(order matching) in BOOLEAN MODE, excluding documents containing only “대한.” - No 50% threshold: NATURAL LANGUAGE MODE ignores tokens matching 50%+ of all rows. Among 570K records, common Korean 2-gram tokens (e.g., “한국”, “대한”) could exceed this threshold, causing missing search results.
Pre-Index Table Measurements
Before creating the FULLTEXT index, we measured the current table’s disk size and content column statistics.
Table disk size — Data 122GB, Index 0MB:
Content column statistics — 14,768,700 rows, average 6,586 chars, max 2,521,624 chars (query took 439s):
Pre-index table summary:
| Item | Value |
|---|---|
| Total rows | 14,768,700 (~14.77M) |
| Data size | 122 GB (125,364 MB) |
| Existing index size | 0 MB |
| Average title length | 27 chars |
| Average content length | 6,586 chars |
| Maximum content length | 2,521,624 chars (~2.52M chars) |
ngram token count estimate:
| Target | Avg tokens per document | Total tokens |
|---|---|---|
| title only | 26 | ~380M |
| content only | 6,585 | ~97.3B |
| title + content | ~6,611 | ~97.6B |
Including content increases token count by ~250x compared to title only. Index size and creation time are expected to increase significantly.
FULLTEXT Index Creation
After adding ngram_token_size=2 to MySQL server settings, we create a composite FULLTEXT index on title and content.
command: > --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --ngram-token-size=2CREATE FULLTEXT INDEX ft_title_content ON posts(title, content) WITH PARSER ngram;Posts Table Index Attempt — Disk Exceeded
Creating a FULLTEXT ngram index on the 14.77M row posts table failed when disk ran out after 85 minutes.
According to MySQL documentation (Online DDL Space Requirements), MySQL creates temporary sort files during FULLTEXT index creation. These files sort tokens for merging into the inverted index, using additional disk space equal to table data + existing index size. They are automatically deleted after merging completes.
Server disk headroom (253GB) was insufficient, so index creation was killed with the KILL command.
Separating Namuwiki Data for Experimentation
Since index creation is impossible on the posts table, we need to narrow the scope. We checked the data distribution by category:
| category_id | Data | Rows |
|---|---|---|
| 1 | Namuwiki (Korean) | 571,364 |
| 2 | EN/KR Wikipedia | ~14,197,336 |
Namuwiki (category_id=1) is about 570K of the total 14.77M records, or 3.9% of total. At this scale, the FULLTEXT index size is expected to be in the tens of MB range, enabling experimentation without disk issues.
Two reasons for choosing Namuwiki first:
- Korean ngram verification: Need to confirm
ngram_token_size=2actually works for Korean search - User search patterns: Korean search is the primary usage pattern given the service characteristics
-- Create Korean-only tableCREATE TABLE tmp_namu_posts LIKE posts;
-- Batch INSERT (50K per batch, split due to InnoDB lock table size limit)INSERT INTO tmp_namu_posts SELECT * FROM posts WHERE category_id = 1 ORDER BY id LIMIT 50000 OFFSET 0;INSERT INTO tmp_namu_posts SELECT * FROM posts WHERE category_id = 1 ORDER BY id LIMIT 50000 OFFSET 50000;-- ... (571,364 rows completed)
-- Create FULLTEXT ngram index (570K target)CREATE FULLTEXT INDEX ft_title_content ON tmp_namu_posts(title, content) WITH PARSER ngram;Why batch INSERT: Using
CREATE TABLE AS SELECTprocesses 570K x LONGTEXT rows in a single transaction. InnoDB maintains locks on all modified rows during a transaction, and locks for 570K rows with content (LONGTEXT) exceededinnodb_buffer_pool_size, causing Error 1206 (lock table size exceeded). Splitting into 50K batches makes each INSERT an independent transaction, preventing lock accumulation.
| Item | posts table | Korean only (tmp_namu_posts) |
|---|---|---|
| Rows | 14,768,700 | 571,364 |
| Data size | 122 GB | 12 GB |
| FULLTEXT index size | 300 GB+ (disk exceeded) | 6.7 GB |
| Index creation | Aborted (85 min elapsed) | Succeeded |
Note:
information_schema.tables.index_lengthincludes only B-Tree indexes. InnoDB FULLTEXT indexes are stored in separate FTS auxiliary tables (fts_*). Accurate FULLTEXT index size requires summing FTS file sizes in the MySQL data directory.
Search Query Change
Spring Data JPA’s JPQL (Java Persistence Query Language) only supports SQL-like syntax defined in the JPA spec. MATCH...AGAINST is MySQL vendor-specific syntax that JPQL cannot parse, requiring nativeQuery = true to pass SQL directly to MySQL.
Sorting also changes from created_at DESC (newest first) to MATCH...AGAINST return value (relevance score). In FULLTEXT search, MATCH...AGAINST returns a non-negative floating-point value where higher values indicate greater relevance.
The search target table is changed to tmp_namu_posts to perform FULLTEXT search only on Korean data.
@Query(value = """ SELECT * FROM tmp_namu_posts WHERE MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) ORDER BY MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) DESC, created_at DESC LIMIT :#{#pageable.pageSize} OFFSET :#{#pageable.offset} """, countQuery = """ SELECT COUNT(*) FROM tmp_namu_posts WHERE MATCH(title, content) AGAINST(:keyword IN BOOLEAN MODE) """, nativeQuery = true)Page<Post> searchByKeyword(@Param("keyword") String keyword, Pageable pageable);5. Before vs After
Compared on identical data (tmp_namu_posts, 570K rows) with the same search term (“페텔”). Before is
LIKEsearch without index, After isMATCH AGAINSTsearch with FULLTEXT ngram index applied.
EXPLAIN Comparison
| Case | type | key | rows | Extra |
|---|---|---|---|---|
Before — LIKE '%페텔%' | ALL | NULL | 577,017 | Using where; Using filesort |
After — MATCH AGAINST | fulltext | ft_title_content | 1 | Using where; Ft_hints: sorted, limit = 20 |
- type: ALL (full row scan) to fulltext (inverted index lookup). The scan method itself changed.
- rows: 577,017 to 1. The optimizer retrieves results directly from the inverted index, so estimated scan rows is 1.
- Extra:
Using filesort(disk sort) toFt_hints: sorted, limit = 20. The FULLTEXT engine handles relevance sorting and LIMIT internally, eliminating separate sorting.
Response Time
Test environment: ARM 2 cores / 12GB RAM — Spring Boot 2GB (JVM heap 1GB) + MySQL 4GB (InnoDB BP 2GB). Data: tmp_namu_posts (570K rows, 12GB).
Before — LIKE '%페텔%': 12.766s, 6 results (title only):
After — MATCH(title, content) AGAINST('페텔' IN BOOLEAN MODE): 0.006s, 20 results (title + content):
| Item | Before (LIKE) | After (FULLTEXT) | Note |
|---|---|---|---|
| Response time | 12,766ms | 6ms | ~2,100x improvement |
| Result count | 6 (title only) | 20 (title + content) | Body search restored |
| Scan method | Full Table Scan | Inverted index lookup | EXPLAIN type: ALL -> fulltext |
| Sort method | filesort (disk) | FULLTEXT engine internal sort | Separate sort cost eliminated |
| Table size | — | 12 GB (570K rows) | tmp_namu_posts data |
| FULLTEXT index size | None | 6.7 GB | ~56% of data |
Result Count Difference — 6 vs 20
The difference between Before (6) and After (20) results is due to different search scopes.
- Before:
LIKE '%페텔%'searches title only. Previously, content (LONGTEXT) scanning exhausted the connection pool and brought the system down, so content search was removed as an emergency measure. Only 6 documents out of 570K have “페텔” in the title. - After:
MATCH(title, content)searches both title and content. Thanks to the FULLTEXT index, tokens are found in the inverted index without scanning content, so restoring body search causes no performance issues. Documents mentioning “페텔기우스” in the body (e.g., constellation, astronomy articles) are additionally matched.
In other words, the FULLTEXT index achieved not only speed improvement but also search quality (recall) improvement. With body search restored — previously abandoned due to performance issues — more relevant documents can be found with the same search term.
6. Known Limitations
ngram FULLTEXT provides dramatic performance improvement over LIKE '%keyword%', but has the following limitations.
6-1. False Positives
2-gram tokenization does not preserve word boundary information.
6-2. No Morphological Analysis
ngram simply splits by character count without performing morphological analysis.
6-3. High-Frequency Token Performance Degradation (MySQL Bug #85880)
When common 2-gram tokens like “한국” or “대한” match tens of thousands of documents, MySQL internally traverses the inverted index posting lists sequentially, causing dramatic performance degradation.
This occurs because InnoDB FULLTEXT’s internal implementation (fts0que.cc) computes intersections of token match results using vector (array) sequential traversal. This is an algorithm-level inefficiency that cannot be resolved by parameter tuning. Bug #85880 was reported in 2017 and remains Open (unresolved) as of 2026, with patches submitted by the reporter not merged by Oracle.
MySQL self-tuning options reviewed:
| Method | Effect | Decision |
|---|---|---|
Increase innodb_ft_result_cache_limit | X — Only adjusts memory ceiling, search algorithm unchanged | No effect |
Increase ngram_token_size to 3 | Reduces high-frequency 2-gram issue | Cannot search 2-char words like “한국”, “사과”, “경제” -> critical for Korean |
| Custom stopwords (remove “대한”, etc.) | Resolves timeout for that token | Makes search for that word completely impossible -> unacceptable for wiki search |
| Add WHERE conditions to narrow scope | X — MySQL fully scans FULLTEXT first then applies WHERE | FULLTEXT stage bottleneck remains |
Lucene’s Nori morphological analyzer analyzes “대한민국” at the morpheme level, so ngram’s high-frequency 2-gram token problem does not occur at all.
Can Changing Query Mode Solve This?
MySQL FULLTEXT provides three query modes. We examined whether each mode is effective against high-frequency token timeout.
| Mode | Solves high-freq? | Behavior | Problem |
|---|---|---|---|
| NATURAL LANGUAGE MODE | Partial | Automatically ignores tokens appearing in 50%+ of all rows (IDF-based) | If “한국” is in 50%+ documents, returns 0 results. Search quality degradation |
| BOOLEAN MODE (current) | X | No 50% rule. Scans posting lists of all matching documents | Posting lists of high-frequency tokens are long, so traversal time increases linearly |
| QUERY EXPANSION | X | Extracts related words from 1st search results → re-executes 2nd search | Performs search twice, so 2x slower for high-frequency tokens |
NATURAL LANGUAGE MODE’s 50% rule is based on IDF (Inverse Document Frequency) from information retrieval theory. The concept is that words appearing in all documents have no discriminative value as search terms, but with ngram 2-gram, it has the side effect of filtering out meaningful search terms like “한국” and “대한.”
Practical Mitigations
While a fundamental fix is impossible, there are practical mitigations to reduce timeout frequency in the current ngram environment:
1) Force Boolean Mode Compound Queries
-- Single term search → timeoutWHERE MATCH(title, content) AGAINST ('한국' IN BOOLEAN MODE)
-- Compound query → result reduced by intersection, fastWHERE MATCH(title, content) AGAINST ('+한국 +역사' IN BOOLEAN MODE)Only the intersection of two tokens’ posting lists is returned, reducing result count and improving speed. Encouraging minimum 2-word input on the frontend is practical, but cannot support single-keyword search.
2) Custom Stopword Registration
CREATE TABLE my_stopwords (value VARCHAR(30)) ENGINE=InnoDB;INSERT INTO my_stopwords VALUES ('한국'), ('대한'), ('사람');SET GLOBAL innodb_ft_server_stopword_table = 'wikidb/my_stopwords';-- FULLTEXT index rebuild required afterwardExcludes high-frequency tokens causing timeouts from indexing. However, search for those keywords becomes completely impossible, which is unacceptable for a wiki search engine.
3) Early Termination via LIMIT
MySQL FULLTEXT performs optimization to internally return only the top N results with Ft_hints: sorted, limit = N, but since it traverses the entire posting list first for high-frequency tokens before sorting, LIMIT does not reduce the traversal itself.
Conclusion: High-frequency token timeout in ngram environments is structurally unsolvable. Forcing compound queries, registering stopwords, etc. all involve trade-offs that limit search functionality. The root cause is that ngram mechanically splits text into 2-character chunks, generating massive numbers of semantically meaningless tokens, which can only be solved by morphological analysis-based tokenization.
InnoDB FULLTEXT Internal Architecture — Why High-Frequency ngram is Structurally Unsolvable
Above, we mentioned “vector sequential traversal” as the bottleneck. This section analyzes what data structures and algorithms the InnoDB FULLTEXT engine uses internally, and why performance explodes with high-frequency tokens, at the source code (fts0que.cc) level.
1) Storage Structure — 6 Auxiliary Tables
When a FULLTEXT index is created, MySQL automatically generates 6 auxiliary tables.
Tokens are distributed across 6 tables based on first character sort weight (character set sort weight). This is designed for parallel indexing and adjustable via innodb_ft_sort_pll_degree (default 2 threads).
Each auxiliary table stores the inverted index. Each entry has the form (token, posting list), where the posting list contains DOC_ID + byte offset position.
Additionally, InnoDB maintains an FTS cache to reduce contention on auxiliary tables during frequent small INSERTs. Tokens from recently inserted rows are temporarily stored in memory, then batch-flushed to auxiliary tables when the cache fills. During search, results from auxiliary tables (disk) and cache (memory) are merged.
2) Query Processing Pipeline — fts0que.cc
fts0que.cc is the core query processing engine for InnoDB FULLTEXT search. Internal processing flow when executing MATCH(title, content) AGAINST('대한민국' IN BOOLEAN MODE):
3) Intersection Stage (Stage 3) — RB-tree, This is OK
fts_query_intersect() uses an RB-tree (Red-Black Tree).
RB-tree provides O(log n) lookup, so this stage itself is not critical.
4) Phrase Verification Stage (Stage 4) — ib_vector_t Sequential Traversal, This is the Bottleneck
In ngram search, “대한민국” is a phrase search of 3 tokens. After reducing candidates via intersection, each candidate document must be verified for tokens existing at consecutive positions.
Core data structure in fts0que.cc:
// InnoDB internal data structurestruct fts_match_t { doc_id_t doc_id; // document ID ulint start; // phrase match start offset ib_vector_t *positions; // word position offset array ← vector (dynamic array)};ib_vector_t is an InnoDB internal dynamic array, similar to C++‘s std::vector. Access is index-based sequential via ib_vector_get(positions, i).
fts_query_match_phrase() algorithm (pseudocode based on source code):
// Execute phrase verification for each candidate documentfor (i = phrase->match->start; i < ib_vector_size(positions); i++) { // positions = all occurrence positions of first token ("대한") in this document pos = ib_vector_get(positions, i); // O(1) access but iterates all positions
// Check if remaining tokens ("한민", "민국") are consecutive from this position // → fts_query_match_phrase_terms() // → reads document text and compares token by token sequentially matched = fts_query_match_phrase_terms(phrase, pos);
if (matched) break; // match success}The Core Problem:
5) Why It Explodes with High-Frequency Tokens
For single-token search (“대한”), all 196,593 documents become candidates without intersection.
Rare token “페텔” search results — 20 results, 0.023s:
“페텔” matching document count — 406:
High-frequency token “한국” matching document count — 196,593:
| Search term | Matching docs | Processing method | Time |
|---|---|---|---|
| ”페텔” | 406 | 406 docs sequential | 23ms |
| ”한국” | 196,593 | 196K docs sequential | 281ms |
| ”대한” | 196K+ | 196K+ docs sequential + phrase verification | 5s+ timeout |
Time scales linearly with matching document count. 500x more matching documents means ~500x slower.
6) Bug #85880 Reporter’s Proposed Solutions — Rejected by Oracle
Bug #85880 reporter reproduced the issue where Korean search “중국가을” (tokens: “중국” 220K docs, “국가” 59K docs, “가을” 45K docs) took 7.55 seconds, and proposed two patches:
| Solution | Approach | Result | Oracle Response |
|---|---|---|---|
| Replace with HashMap | ib_vector_t(sequential O(n)) → HashMap(lookup O(1)) to accelerate intersection | Phrase verification bottleneck remains | Not merged |
| Multi-gram indexing | Extend ngram_token_size from fixed 2 to range 2~4. Index “대한민국” itself as a single token | Resolved in 0.01ms | Not merged |
The Multi-gram patch improved 7.55s → 0.01ms (750,000x improvement), but Oracle has not merged this patch for 9 years (2017→2026). InnoDB FTS code can only be modified internally by Oracle, so even with external contribution patches, they cannot be applied unless Oracle adopts them.
7) Complete Pipeline Summary
Sources: MySQL Bug #85880, fts0que.cc File Reference, InnoDB Full-Text Indexes, Pythian: MySQL InnoDB’s Full Text Search Overview
6-4. Index Size and Creation Cost
The title + content composite FULLTEXT index includes all 2-gram tokens from content (LONGTEXT) in the inverted index, making the index size substantial.
Even for Korean-only 570K records (12GB data), the FULLTEXT index occupies 6.7GB (56% of data).
When creating the index on the posts table (14.77M rows, 122GB), it exceeded 300GB, beyond the server disk capacity (253GB free). Transitioning to Lucene is essential for full data search.
Conclusion: ngram FULLTEXT is effective for transitioning from “search completely broken” to “title + body search working.” Search quality (precision, morphological analysis) will be addressed with Lucene + Nori morphological analyzer.
6-5. Why Row-Oriented Storage Amplifies FULLTEXT Index Cost
The 300GB+ disk overflow is not simply “too much data” — it’s a structural problem stemming from MySQL’s Row-Oriented storage architecture.
MySQL (InnoDB) is Row-Oriented storage. All columns composing a single row (id, title, content, created_at, …) are stored consecutively on the same disk page.
When creating a FULLTEXT index, MySQL must read all rows’ title and content to extract ngram tokens. However, in Row-Oriented storage, it cannot read only the content column. It must read the entire row from disk, then extract the content value. In other words, to create ngram tokens from title (avg 27 chars) and content (avg 6,586 chars), all columns of every row (122GB) must be read from disk.
On top of this, according to MySQL documentation (Online DDL Space Requirements), temporary sort files are needed during FULLTEXT index creation. These sort tokens alphabetically for merging into the inverted index, and their size is proportional to the table data size.
In contrast, Column-Oriented storage like BigQuery stores each column independently. If it were Column-Oriented, only the content column file would need to be read, eliminating unnecessary I/O.
This is the fundamental limitation of MySQL FULLTEXT:
| Aspect | Row-Oriented (MySQL) | Column-Oriented (BigQuery, etc.) |
|---|---|---|
| I/O for token extraction | Read entire rows (122GB) | Read only needed columns |
| Temporary sort files | Proportional to data size (122GB) | Proportional to column size (much smaller) |
| OLTP queries (INSERT/UPDATE) | Efficient (write one row at once) | Inefficient (distributed writes across files) |
MySQL is a Row-Oriented DB optimized for OLTP (transaction processing). While single INSERT/UPDATE/DELETE operations are fast, it is structurally disadvantaged for analytical workloads that “read specific columns in bulk.” FULLTEXT index creation is essentially an analytical workload of “reading and tokenizing all 14.77M content columns,” so the cost is maximized in a Row-Oriented structure.
From this perspective, the significance of the Lucene transition becomes clearer. Lucene is dedicated inverted-index storage that stores tokenized data in its own segment files. Since it does not go through MySQL’s Row-Oriented pages, no unnecessary I/O occurs during index creation.
Conclusion: ngram FULLTEXT is effective for transitioning from “search completely broken” to “title + body search working.” However, due to Row-Oriented storage limitations, index creation cost is maximized for large-scale data. Search quality (precision, morphological analysis) and index scalability will be addressed with Lucene + Nori morphological analyzer.
7. Current Status and Remaining Issues
Resolved:
- Autocomplete
LIKE 'prefix%'-> B-Tree index - Search
LIKE '%keyword%'-> FULLTEXT ngram index (targeting 570K Korean documents)
Confirmed limitations:
- Index size: FULLTEXT ngram index for posts table (14.77M rows) exceeds 300GB+, beyond current server disk capacity. Workaround by separating Korean data only
- Search scope: Currently only Korean (Namuwiki) data is searchable; English Wikipedia data is excluded from search
- Search quality: False positives, no morphological analysis
- High-frequency token timeout: Rare tokens like “페텔” return 406 results in 6ms, but high-frequency tokens like “대한” appearing in tens of thousands of documents take 5+ seconds for posting list traversal, causing timeout. This corresponds to MySQL Bug #85880, an algorithm-level inefficiency (vector sequential traversal) that cannot be resolved through parameter tuning
Load Test Timing:
The k6 load test baseline was premised on “executing when search at least works.” Currently, rare tokens work but high-frequency tokens still timeout, making it impossible to run load tests reflecting actual user search patterns. The k6 baseline load test will be executed after Lucene transition, when all search terms operate stably.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.