자동완성 B-Tree 인덱스 걸기
목차
이전 글 요약
이전 글에서 LIKE '%keyword%' 검색이 Full Table Scan으로 시스템을 마비시키는 문제를 발견하고, 긴급 완화 조치(content LIKE 제거, 5초 타임아웃, HikariCP Fail-Fast)로 시스템 마비를 방지했습니다.
검색은 여전히 타임아웃으로 실패하지만, 자동완성(LIKE 'prefix%')은 후방 와일드카드이므로 B-Tree 인덱스를 활용할 수 있을 것이라 예상했습니다.
1. 자동완성의 기대 동작
자동완성은 사용자가 검색창에 글자를 입력할 때마다, 해당 prefix로 시작하는 제목을 조회수 순으로 10건 반환하는 기능입니다.
LIKE 'prefix%'는 후방 와일드카드입니다. B-Tree 인덱스는 값의 앞부분부터 정렬되어 있으므로, LIKE 'prefix%'는 인덱스의 정렬 순서를 활용하여 range scan이 가능한 패턴입니다. 검색(LIKE '%keyword%')과 달리 인덱스만 추가하면 빠르게 동작할 것이라 예상했습니다.
단, 이전 글에서는 Baseline 측정을 위해 의도적으로 인덱스를 추가하지 않은 상태였습니다. 인덱스 없는 상태의 성능을 기록해야 Before/After 비교가 가능하기 때문입니다.
2. 문제 발생: 자동완성도 타임아웃
자동완성 API를 호출하자, 검색과 동일하게 5초 타임아웃이 발생했습니다.

검색도 안 되고, 자동완성도 안 되면 1,215만 건의 데이터를 찾을 수 있는 방법이 아예 없는 상태입니다. 자동완성 역시 Full Table Scan이 발생하면 검색과 마찬가지로 커넥션을 장시간 점유하여 시스템 마비를 유발할 수 있습니다.
의문: LIKE 'prefix%'는 B-Tree 인덱스를 탈 수 있는 후방 와일드카드인데, 왜 타임아웃이 나는가?
3. 원인 분석: 인덱스가 없으면 prefix도 Full Table Scan
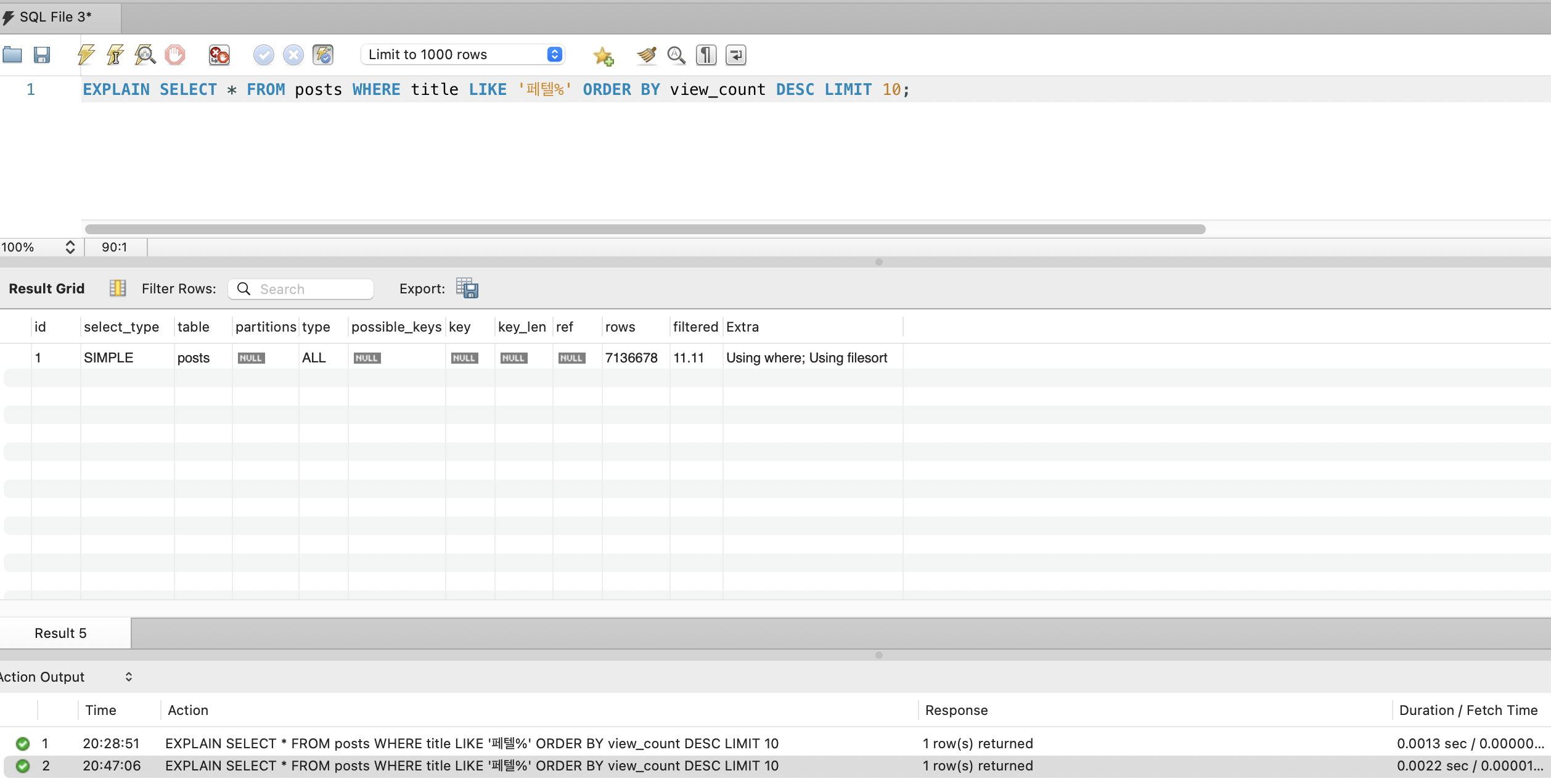
EXPLAIN 확인
| 항목 | 값 | 의미 |
|---|---|---|
| type | ALL | Full Table Scan |
| possible_keys | NULL | 사용 가능한 인덱스 없음 |
| key | NULL | 실제 사용한 인덱스 없음 |
| rows | 27,440,000 | 전체 행 스캔 |
| Extra | Using where; Using filesort | WHERE 필터 + 정렬 모두 디스크 처리 |
LIKE 'prefix%'가 B-Tree 인덱스를 활용할 수 있다는 것과, 실제로 활용한다는 것은 다릅니다.
title 컬럼에 인덱스 자체가 없으면 활용할 인덱스가 없으므로, 후방 와일드카드여도 Full Table Scan이 발생합니다.
4. 인덱스 설계: 대안 검토
자동완성 쿼리가 하는 일은 세 가지입니다:
- WHERE: title이 prefix로 시작하는 행을 찾습니다
- ORDER BY: view_count 내림차순으로 정렬합니다
- LIMIT: 상위 10건만 반환합니다
이 세 가지를 모두 만족하는 인덱스를 설계해야 합니다.
검토한 대안
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
단일 인덱스 (title) | range scan 가능 | view_count 정보가 인덱스에 없음 | - |
복합 인덱스 (title, view_count DESC) | range scan + ICP로 view_count 접근 | SELECT *이므로 테이블 lookup 필요 | O |
| 커버링 인덱스 (전체 컬럼 포함) | 테이블 lookup 제거 | content가 LONGTEXT라 인덱스에 포함 불가 | 불가능 |
| Trie 자료구조 | O(L) 탐색으로 매우 빠름 | 1,215만 제목을 메모리에 올려야 함 (ARM 서버 메모리 한계) | 시기상조 |
단일 인덱스 (title) 대신 복합 인덱스를 선택한 이유:
단일 인덱스 (title)만으로도 range scan이 가능하여 Full Table Scan → range scan 전환이라는 핵심 개선은 동일합니다. ORDER BY view_count DESC에 대한 filesort는 복합 인덱스 (title, view_count DESC)에서도 발생합니다. 선행 컬럼에 range 조건(LIKE ‘prefix%‘)이 걸리면 후행 컬럼의 정렬 순서를 활용할 수 없기 때문입니다 (equality 조건에서만 가능).
그러나 복합 인덱스는 Index Condition Pushdown(ICP) 시 view_count 값을 인덱스 레벨에서 읽을 수 있어, 향후 SELECT title, view_count 같은 커버링 쿼리로 변경할 경우 테이블 lookup을 줄일 수 있는 확장성이 있습니다.
커버링 인덱스를 제외한 이유:
커버링 인덱스는 쿼리에 필요한 모든 컬럼을 인덱스에 포함시켜 테이블 lookup을 제거하는 기법입니다. 하지만 현재 쿼리가 SELECT *이고, content 컬럼이 LONGTEXT이므로 인덱스에 포함할 수 없습니다. 또한 LIMIT 10이므로 테이블 lookup이 최대 10회 발생하는데, 이 정도는 무시할 수 있는 비용입니다.
Trie를 제외한 이유:
Trie는 prefix 탐색에 최적화된 자료구조이지만, 1,215만 개의 제목을 메모리에 올려야 합니다. 현재 ARM 서버는 메모리 제한이 있고, B-Tree 인덱스로 LIKE 'prefix%' LIMIT 10을 실행하면 ms 단위 응답이 가능하므로, 현 규모에서는 DB 인덱스로 충분합니다.
선택: 복합 인덱스 (title, view_count DESC)
CREATE INDEX idx_title_viewcount ON posts(title, view_count DESC);MySQL 공식 문서의 Multiple-Column Indexes에 따르면, B-Tree 복합 인덱스는 leftmost prefix rule을 따릅니다. 선행 컬럼(title)으로 range scan 후, 후행 컬럼(view_count DESC)의 정렬 순서를 그대로 활용할 수 있습니다.
idx_title_viewcount
| title | view_count |
|---|---|
| ”페텔 세바스찬” | 52,340 |
| ”페텔 세바스찬” | 12,100 |
| ”페텔리움” | 8,200 |
| ”페텔리움” | 3,100 |
| ”포뮬러” | … |
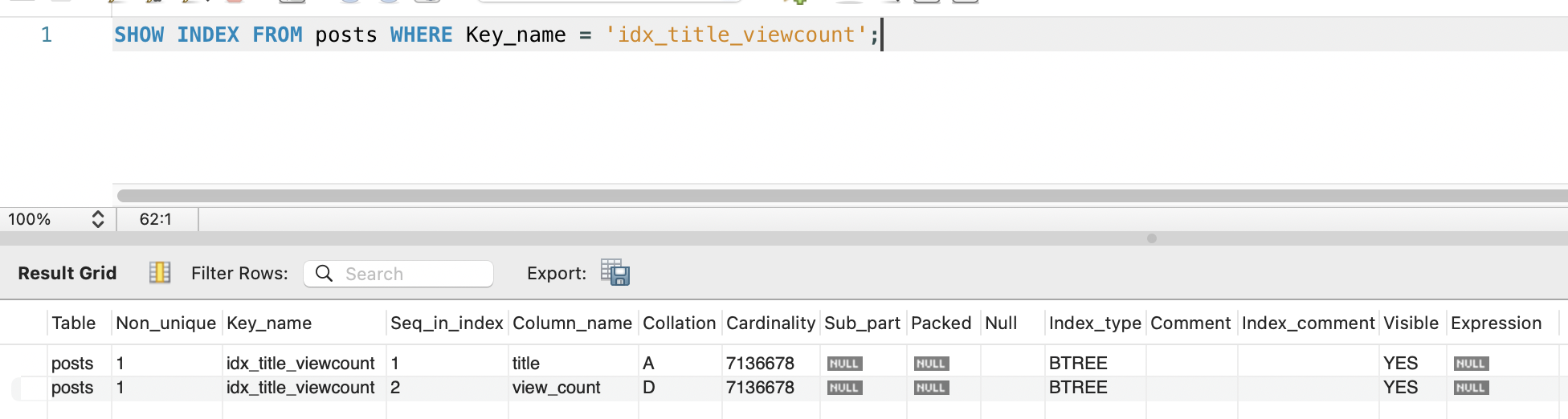
title이 선행 컬럼이므로LIKE '페텔%'에서 range scan이 가능합니다- 선행 컬럼에 range 조건이 걸리면 후행 컬럼의 정렬 순서는 활용되지 않습니다. 각 title 값 내에서는 view_count DESC로 정렬되어 있지만, 서로 다른 title 간의 view_count는 전역 정렬이 아니므로 filesort가 필요합니다
LIMIT 10이 걸려있고, range scan으로 줄어든 결과에 대한 filesort이므로 비용은 미미합니다
만약 컬럼 순서가 반대라면 (view_count DESC, title):
WHERE title LIKE 'prefix%'→ title이 후행 컬럼이라 인덱스 사용 불가- Full Table Scan 발생
Flyway 마이그레이션
-- V3__add_indexes.sqlCREATE INDEX idx_title_viewcount ON posts(title, view_count DESC);5. Before vs After
EXPLAIN 비교
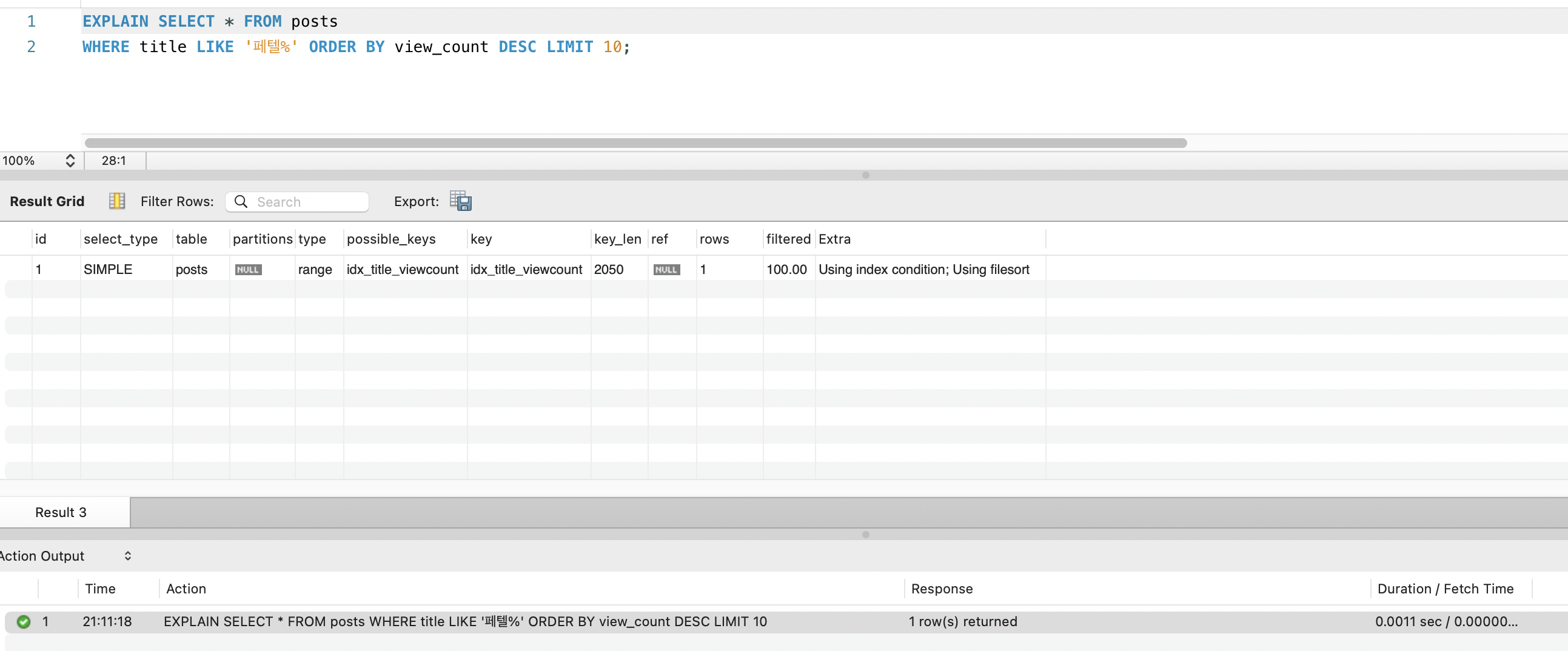
| 구분 | type | key | rows | Extra |
|---|---|---|---|---|
| Before | ALL | NULL | 27,440,000 | Using where; Using filesort |
| After | range | idx_title_viewcount | 1 | Using index condition; Using filesort |
- type:
ALL(전체 스캔) →range(범위 스캔) - key:
NULL→idx_title_viewcount(인덱스 사용) - rows: 27,440,000 → 1 (prefix에 매칭되는 행만 스캔)
- Extra:
Using filesort가 여전히 남아있습니다. 선행 컬럼에 range 조건(LIKE)이 걸리면 후행 컬럼(view_count DESC)의 정렬을 활용할 수 없기 때문입니다. 단,LIMIT 10과 함께 range scan으로 줄어든 결과에 대한 filesort이므로 비용은 미미합니다
응답시간 측정
테스트 환경: ARM 2코어 / 12GB RAM. Spring Boot 2GB(JVM 힙 1GB) + MySQL 4GB(InnoDB BP 2GB). 데이터: 1,215만 건.
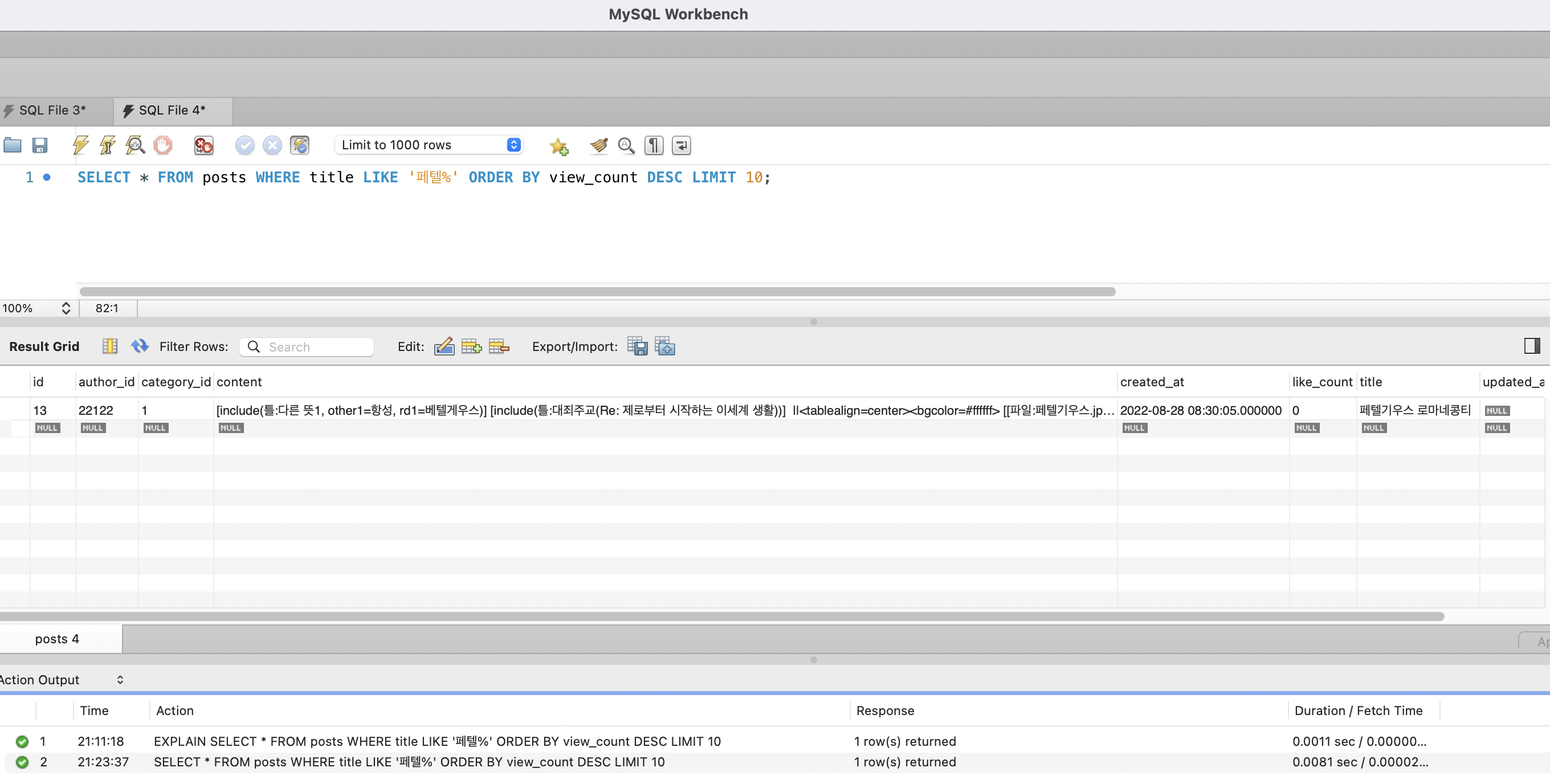
| 쿼리 | Before | After | 개선율 |
|---|---|---|---|
자동완성 (LIKE 'prefix%') | >5,000ms (타임아웃) | 8ms | 99.8%+ |
6. 현재 위치와 남은 문제
해결된 것:
- 자동완성
LIKE 'prefix%'→ B-Tree 복합 인덱스로 range scan 전환, 타임아웃 해소
B-Tree 인덱스는 값의 앞부분부터 정렬되어 있으므로, LIKE 'prefix%'(후방 와일드카드)에는 range scan이 가능하지만, LIKE '%keyword%'(선행 와일드카드)에는 어디서부터 찾아야 할지 알 수 없어 전체를 스캔해야 합니다.
검색 문제를 해결하려면 B-Tree와는 다른 접근이 필요합니다.
Previous Step Summary
In the previous post, we discovered that LIKE '%keyword%' search caused Full Table Scan that brought the system down, and applied emergency mitigations (removing content LIKE, 5-second timeout, HikariCP Fail-Fast) to prevent system paralysis.
Search still fails with timeout, but autocomplete (LIKE 'prefix%') uses a trailing wildcard, so we expected it could leverage a B-Tree index.
1. Expected Autocomplete Behavior
Autocomplete returns the top 10 titles starting with the given prefix, sorted by view count, each time the user types a character in the search box.
LIKE 'prefix%' is a trailing wildcard. Since B-Tree indexes are sorted from the beginning of values, LIKE 'prefix%' can leverage the index’s sort order for range scan. Unlike search (LIKE '%keyword%'), we expected it would work fast simply by adding an index.
However, in the previous post, we intentionally did not add indexes to measure the baseline. We needed to record index-free performance for Before/After comparison.
2. Problem — Autocomplete Also Times Out
When calling the autocomplete API, it hit the same 5-second timeout as search.
If neither search nor autocomplete works, there is no way to find anything among the 27.44 million records. Autocomplete with Full Table Scan can also monopolize connections and bring the system down, just like search.
Question: LIKE 'prefix%' is a trailing wildcard that can use a B-Tree index — why does it time out?
3. Root Cause — No Index Means Full Table Scan Even for Prefix
EXPLAIN Analysis
| Item | Value | Meaning |
|---|---|---|
| type | ALL | Full Table Scan |
| possible_keys | NULL | No available indexes |
| key | NULL | No index used |
| rows | 27,440,000 | Full row scan |
| Extra | Using where; Using filesort | WHERE filter + sort both on disk |
There is a difference between LIKE 'prefix%' being able to use a B-Tree index and actually using one. If no index exists on the title column, there is nothing to leverage, so even trailing wildcards result in Full Table Scan.
4. Index Design — Evaluating Alternatives
The autocomplete query does three things:
- WHERE: Find rows where title starts with the prefix
- ORDER BY: Sort by view_count descending
- LIMIT: Return only the top 10 rows
We need an index that satisfies all three.
Alternatives Considered
| Approach | Pros | Cons | Decision |
|---|---|---|---|
Single index (title) | Enables range scan | No view_count info in index | - |
Composite index (title, view_count DESC) | Range scan + ICP access to view_count | Table lookup needed for SELECT * | O |
| Covering index (all columns) | Eliminates table lookup | content is LONGTEXT, cannot include in index | Impossible |
| Trie data structure | O(L) lookup, very fast | Must load 27.44M titles in memory (ARM server memory limit) | Premature |
Why composite index was chosen over single index (title):
A single index (title) alone would also enable range scan, achieving the same core improvement from Full Table Scan to range scan. The ORDER BY view_count DESC filesort occurs with both single and composite indexes — when the leading column has a range condition (LIKE ‘prefix%’), MySQL cannot leverage the trailing column’s sort order (only possible with equality conditions).
However, the composite index provides Index Condition Pushdown (ICP) access to view_count at the index level, which offers extensibility for future covering queries like SELECT title, view_count.
Why covering index was rejected:
A covering index includes all columns needed by the query to eliminate table lookups. However, the current query uses SELECT * and the content column is LONGTEXT, which cannot be included in an index. Also, with LIMIT 10, table lookups occur at most 10 times — a negligible cost.
Why Trie was rejected:
Trie is a data structure optimized for prefix search, but it requires loading 27.44 million titles into memory. The current ARM server has memory constraints, and with B-Tree index, LIKE 'prefix%' LIMIT 10 can respond in milliseconds. At this scale, a DB index is sufficient.
Choice: Composite Index (title, view_count DESC)
CREATE INDEX idx_title_viewcount ON posts(title, view_count DESC);According to MySQL’s official Multiple-Column Indexes documentation, B-Tree composite indexes follow the leftmost prefix rule. After range scan on the leading column (title), the sort order of the trailing column (view_count DESC) can be used directly.
idx_title_viewcount
| title | view_count |
|---|---|
| ”페텔 세바스찬” | 52,340 |
| ”페텔 세바스찬” | 12,100 |
| ”페텔리움” | 8,200 |
| ”페텔리움” | 3,100 |
| ”포뮬러” | … |
titleis the leading column, enabling range scan forLIKE '페텔%'- When the leading column has a range condition, the trailing column’s sort order is not leveraged — within each title value, rows are sorted by view_count DESC, but view_counts across different titles are not globally sorted, so filesort is needed
- With
LIMIT 10and the reduced result set from range scan, the filesort cost is negligible
If the column order were reversed (view_count DESC, title):
WHERE title LIKE 'prefix%'— title is the trailing column, so the index cannot be used- Full Table Scan occurs
Flyway Migration
-- V3__add_indexes.sqlCREATE INDEX idx_title_viewcount ON posts(title, view_count DESC);5. Before vs After
EXPLAIN Comparison
| Case | type | key | rows | Extra |
|---|---|---|---|---|
| Before | ALL | NULL | 27,440,000 | Using where; Using filesort |
| After | range | idx_title_viewcount | 1 | Using index condition; Using filesort |
- type:
ALL(full scan) torange(range scan) - key:
NULLtoidx_title_viewcount(index used) - rows: 27,440,000 to 1 (scans only prefix-matching rows)
- Extra:
Using filesortremains because range conditions on the leading column prevent leveraging the trailing column’s sort order. However, withLIMIT 10on the reduced result set from range scan, the filesort cost is negligible
Response Time
Test environment: ARM 2 cores / 12GB RAM — Spring Boot 2GB (JVM heap 1GB) + MySQL 4GB (InnoDB BP 2GB). Data: 27.44M rows.
| Query | Before | After | Improvement |
|---|---|---|---|
Autocomplete (LIKE 'prefix%') | >5,000ms (timeout) | 8ms | 99.8%+ |
6. Current Status and Remaining Issues
Resolved:
- Autocomplete
LIKE 'prefix%'— switched to range scan via B-Tree composite index, timeout resolved
B-Tree indexes are sorted from the beginning of values, so LIKE 'prefix%' (trailing wildcard) can use range scan, but LIKE '%keyword%' (leading wildcard) cannot determine where to start searching and must scan everything.
To solve the search problem, a fundamentally different approach from B-Tree is needed.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.