Kafka는 우리에게 과했다

목차
메시지 순서 문제를 해결하려고 메시지 브로커를 검토했습니다. 처음에는 “실시간 메시징이니까 Kafka 써야 하는 거 아니야?”라는 생각이 있었습니다. 하지만 실제로 각 기술을 비교해보니 우리 상황에 맞는 답은 달랐습니다.
Kafka: 설정이 너무 복잡했다
Kafka가 제일 먼저 후보에 올랐습니다. 메시지를 디스크에 저장하고, 파티션 단위로 순서를 보장하고, 초당 수십만 건 처리도 가능합니다.
설정을 시작했습니다.
KRaft 모드 설정, 클러스터 ID 생성, 메타데이터 디렉토리 포맷, 브로커별 고유 ID 설정, 리플리케이션 팩터 설정, 파티션 개수 설계…
6주 프로젝트에서 Kafka 설정에 2주를 쓸 수는 없었다.
Kafka가 필요한 경우는 명확합니다:
- 여러 서비스가 같은 메시지를 소비할 때 (번역, 필터링, 분석 등)
- 메시지 재처리가 필요할 때 (“어제 메시지 전부 다시 분석해줘”)
- Exactly-Once 처리가 필요할 때 (결제, 포인트 적립)
우리 요구사항은 달랐습니다:
- 채팅 메시지 전달만 하면 됨
- 재처리 필요 없음
- 중복 전달되어도 클라이언트가 중복 제거하면 됨
우리 트래픽에 Kafka는 오버 엔지니어링이었습니다. 트래픽 추정: 동시 접속 50-100명 × 채팅방당 1-2건/초 = 피크 시 초당 100~200건 수준. Redis Pub/Sub은 단일 인스턴스에서 초당 수십만 건 처리가 가능하므로(Redis 공식 벤치마크 기준) 현재 트래픽의 1,000배 이상 여유가 있다.
RabbitMQ: 1:1 채팅에는 과했다
RabbitMQ는 메시지를 디스크에 저장하고, ACK 시스템으로 전달을 보장합니다. Exchange 패턴으로 라우팅도 유연합니다.
문제는 RabbitMQ가 “메시지 큐”에 최적화되어 있다는 점입니다. 한 메시지를 한 소비자가 처리하는 구조에 강합니다.
1:1 채팅은 한 메시지를 2명(송신자, 수신자)에게 전달해야 합니다. 서버를 여러 대로 확장하면 각 서버마다 별도 큐를 생성해야 해서 관리가 복잡해집니다.
이미 Redis를 쓰고 있었습니다. 캐싱, 세션 관리에 Redis를 쓰는데, 새로운 미들웨어를 추가하는 건 운영 부담이었습니다.
Redis Stream: 용도가 달랐다
Redis 5.0부터 추가된 Redis Stream을 검토했습니다. 메시지가 저장되고, 순서가 보장되며, Consumer Group도 지원합니다.
XADD chat:stream * message "안녕하세요"→ ID: "1609459200000-0" (밀리초 타임스탬프-시퀀스)Redis는 명령 실행이 싱글 스레드이기 때문에(Redis 6+에서 I/O는 멀티스레드지만 명령 처리는 단일 스레드) ID가 순서대로 부여됩니다.
Consumer Group 코드:

Consumer Group, Pending List, ACK 처리… 코드가 복잡해졌습니다.
팀 회의에서 질문이 나왔습니다.
“실시간 전달에 순서 보장이 꼭 필요한가?”
생각해보니 아니었습니다.
- 네트워크는 원래 불안정합니다: 서버에서 순서대로 보내도 클라이언트 네트워크 상황에 따라 도착 순서가 바뀔 수 있습니다.
- 클라이언트가 정렬하면 됩니다: 카카오톡, 슬랙, 디스코드 모두 DB에서 조회할 때
ORDER BY timestamp로 정렬합니다.
Redis Stream의 순서 보장은 실시간 전달에서만 의미 있는데, 어차피 네트워크 때문에 보장이 안 됩니다.
Consumer Group은 “작업 분배”에 최적화되어 있습니다. 우리가 필요한 건 “메시지 브로드캐스트”였습니다.
NATS: 새 인프라 도입이 부담이었다
NATS는 경량 메시징 시스템입니다. 설정이 단순하고, 지연 시간이 낮습니다.
NATS Core
- Fire-and-forget (메시지 저장 안 함)
- At-most-once 전달
NATS JetStream
- 메시지 저장
- At-least-once / Exactly-once 전달
NATS Core는 Redis Pub/Sub과 비슷하게 메시지를 저장하지 않습니다. JetStream을 쓰면 저장되지만 설정 복잡도가 올라갑니다.
이미 Redis가 있었습니다. Pub/Sub, 캐싱, 세션 관리를 Redis로 하고 있는데, NATS를 추가하면 인프라가 늘어납니다. EC2 서버 1대로 Spring Boot, MySQL, MongoDB, Redis를 전부 돌리는 환경에서 새 미들웨어 도입은 부담이었습니다.
WebSocket 프로토콜: 왜 STOMP를 선택했나?
메시지 브로커와 별개로, 클라이언트-서버 간 WebSocket 프로토콜도 선택해야 했습니다.
| 옵션 | 장점 | 단점 |
|---|---|---|
| Raw WebSocket | 가벼움, 자유도 높음 | 프로토콜 직접 설계 필요 |
| STOMP | Spring 지원, 표준 프로토콜 | 약간의 오버헤드 |
| Socket.io | 자동 재연결, 룸 관리 | Java 서버 지원 약함 |
Raw WebSocket
Raw WebSocket으로도 구현할 수 있습니다. 직접 메시지 타입을 정의하면 됩니다.


문제는 직접 구현할 게 많다는 점입니다:
- 메시지 타입별 라우팅
- 구독/구독 해제 로직
- Heartbeat 관리
- 재연결 로직
- 브라우저 호환성 (WebSocket 미지원 시 Fallback)
Socket.io
Socket.io는 Node.js 생태계에서 강력합니다. 자동 재연결, 룸 관리, Fallback까지 다 됩니다.

문제는 우리가 Spring Boot를 쓴다는 점입니다. Java용 Socket.io 서버 구현체(netty-socketio)가 있지만, Spring 생태계와의 통합이 약하고 유지보수가 활발하지 않습니다.
STOMP 선택 이유
솔직히 STOMP가 필수는 아니었습니다. Raw WebSocket으로도 충분히 구현 가능합니다.
그래도 STOMP를 선택한 이유:
- Spring이 공식 지원한다:
@MessageMapping으로 REST Controller처럼 깔끔하게 작성 가능 - SockJS Fallback: WebSocket 미지원 브라우저에서 자동으로 HTTP Polling으로 전환
- 팀 학습 비용: REST와 비슷한 패턴이라 팀원들이 빠르게 적응

다만 STOMP의 SimpleBroker는 사용하지 않았습니다.
만약의 경우 서버 확장 시 메모리 기반 SimpleBroker는 다른 서버의 구독자를 모르기 때문입니다. 대신 Redis Pub/Sub으로 직접 브로드캐스트했습니다.
결론: Redis Pub/Sub + MongoDB
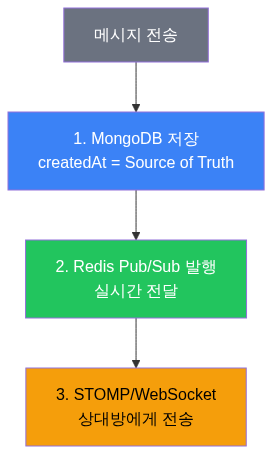
Redis Pub/Sub은 코드가 단순합니다 (Redis Stream의 1/3 수준). 순서는 MongoDB의 createdAt으로 보장하고, 추가 인프라도 필요 없습니다. Pub/Sub이 메시지를 저장하지 않는 건 MongoDB에 저장하니까 문제없고, 실시간 순서 보장이 안 되는 건 네트워크 특성상 어차피 보장할 수 없는 영역입니다.
트레이드오프: fire-and-forget의 위험
Redis Pub/Sub은 메시지를 저장하지 않으므로, 구독자가 없는 순간에 발행된 메시지는 영구 유실된다. 이건 명확한 단점이다. 이 문제는 별도 글(WebSocket 메시지 유실 방지)에서 MongoDB 기반 재연결 복구 메커니즘으로 해결했다. Redis Pub/Sub은 “실시간 전달 채널”이고, MongoDB가 “메시지의 Source of Truth”라는 역할 분리가 핵심이다.
결과
| 후보 | 탈락 이유 |
|---|---|
| Kafka | 설정 복잡, 인프라 과함 |
| RabbitMQ | 1:1 채팅에 부적합, 인프라 추가 |
| Redis Stream | Consumer Group이 작업 분배용 |
| NATS | 새 인프라 도입 부담 |
선택: Redis Pub/Sub + MongoDB
나중에 트래픽이 폭발하면 NATS나 카프카로 마이그레이션하면 됩니다. 이를 대비해 메시지 발행을 ChatMessagePublisher 인터페이스로 추상화해두었고, RedisPubSubPublisher가 이를 구현한다. Kafka 전환 시 KafkaPublisher 구현체만 추가하면 된다. 처음부터 완벽한 인프라를 갖추는 것보다, 현재 규모에 맞는 기술을 쓰고 필요할 때 교체하는 게 낫다고 판단했습니다.
We needed a message broker to solve message ordering issues. The initial thought was “It’s real-time messaging, so shouldn’t we use Kafka?” But after actually comparing each technology, the right answer for our situation was different.
Kafka: Configuration Was Too Complex
Kafka was the first candidate. It stores messages on disk, guarantees ordering per partition, and can handle hundreds of thousands of messages per second.
We started configuring it.
KRaft mode setup, cluster ID generation, metadata directory formatting, unique broker IDs, replication factor configuration, partition count design…
We couldn’t spend 2 weeks on Kafka setup in a 6-week project.
Kafka is clearly needed when:
- Multiple services consume the same message (translation, filtering, analytics, etc.)
- Message reprocessing is required (“Re-analyze all messages from yesterday”)
- Exactly-Once processing is needed (payments, point accrual)
Our requirements were different:
- Just deliver chat messages
- No reprocessing needed
- Client-side deduplication handles duplicates
Kafka was over-engineering for our traffic. Traffic estimation: 50-100 concurrent users × 1-2 msgs/sec/room = peak ~100-200 msgs/sec. Redis Pub/Sub handles hundreds of thousands per second on a single instance (Redis benchmarks), giving us 1,000x+ headroom.
RabbitMQ: Overkill for 1:1 Chat
RabbitMQ stores messages on disk, guarantees delivery with ACK, and offers flexible routing via Exchange patterns.
The problem is that RabbitMQ is optimized for “message queues” — one message processed by one consumer. For 1:1 chat, each message needs to reach 2 people (sender and receiver). Scaling to multiple servers requires separate queues per server, increasing management complexity.
We were already using Redis. Adding a new middleware on top of Redis (already used for caching and session management) was an operational burden.
Redis Stream: Different Purpose
Redis Stream (available since Redis 5.0) was evaluated. It stores messages, guarantees ordering, and supports Consumer Groups.
XADD chat:stream * message "Hello"→ ID: "1609459200000-0" (millisecond timestamp-sequence)Since Redis executes commands on a single thread (I/O is multi-threaded since Redis 6, but command processing remains single-threaded), IDs are assigned in order.
Consumer Group Code:
Consumer Groups, Pending Lists, ACK handling… the code grew complex.
A question came up in a team meeting:
“Is ordering really necessary for real-time delivery?”
Thinking it through, the answer was no.
- Networks are inherently unreliable: Even if the server sends in order, client network conditions can reorder arrivals.
- The client can sort: KakaoTalk, Slack, and Discord all use
ORDER BY timestampwhen querying from the DB.
Redis Stream’s ordering guarantee only matters for real-time delivery, which the network can’t guarantee anyway.
Consumer Groups are optimized for “task distribution.” What we needed was “message broadcast.”
NATS: New Infrastructure Was a Burden
NATS is a lightweight messaging system with simple configuration and low latency.
NATS Core
- Fire-and-forget (no message storage)
- At-most-once delivery
NATS JetStream
- Message storage
- At-least-once / Exactly-once delivery
NATS Core doesn’t store messages, similar to Redis Pub/Sub. JetStream adds storage but increases configuration complexity.
We already had Redis. Adding NATS on top of an EC2 instance already running Spring Boot, MySQL, MongoDB, and Redis was too much.
WebSocket Protocol: Why STOMP?
Separate from the message broker, we needed to choose a WebSocket protocol for client-server communication.
| Option | Pros | Cons |
|---|---|---|
| Raw WebSocket | Lightweight, flexible | Must design protocol manually |
| STOMP | Spring support, standard protocol | Slight overhead |
| Socket.io | Auto-reconnect, room management | Weak Java server support |
Raw WebSocket
Raw WebSocket works fine — just define message types manually.
The problem is the amount of manual implementation:
- Message type routing
- Subscribe/unsubscribe logic
- Heartbeat management
- Reconnection logic
- Browser compatibility (WebSocket fallback)
Socket.io
Socket.io is powerful in the Node.js ecosystem with auto-reconnect, room management, and fallback support.
The problem is we use Spring Boot. The Java Socket.io server implementation (netty-socketio) has weak Spring integration and isn’t actively maintained.
Why STOMP Was Chosen
Honestly, STOMP wasn’t mandatory. Raw WebSocket could have worked.
Reasons for choosing STOMP:
- Official Spring support: Write cleanly with
@MessageMapping, similar to REST Controllers - SockJS Fallback: Automatic HTTP Polling fallback for browsers without WebSocket support
- Team learning cost: REST-like patterns meant quick team adaptation
However, we did not use STOMP’s SimpleBroker. For potential server scaling, the in-memory SimpleBroker wouldn’t know about subscribers on other servers. Instead, we broadcast directly via Redis Pub/Sub.
Conclusion: Redis Pub/Sub + MongoDB
Redis Pub/Sub code is simple (1/3 the complexity of Redis Stream). Ordering is guaranteed by MongoDB’s createdAt, and no additional infrastructure is needed. Pub/Sub not storing messages is fine since MongoDB handles persistence. Real-time ordering not being guaranteed is inherently a network limitation anyway.
Results
| Candidate | Reason for Elimination |
|---|---|
| Kafka | Complex setup, excessive infrastructure |
| RabbitMQ | Unsuitable for 1:1 chat, additional infrastructure |
| Redis Stream | Consumer Groups designed for task distribution |
| NATS | Burden of new infrastructure |
Chosen: Redis Pub/Sub + MongoDB
If traffic explodes later, we can migrate to NATS or Kafka. Message publishing was abstracted behind a ChatMessagePublisher interface, with RedisPubSubPublisher as the current implementation. Migrating to Kafka means adding a KafkaPublisher implementation. We decided it’s better to use technology that fits the current scale and replace it when needed, rather than building perfect infrastructure from the start.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.