채팅방 목록 조회에 1.3초가 걸렸다

목차
MongoDB + Redis Pub/Sub 아키텍처를 설계했습니다. 이제 채팅방 목록 조회 API를 만들 차례였습니다.
0. 정상 상태
서버 환경: AWS EC2 t3.medium (2 vCPU, 4GB RAM) 1대에 Spring Boot, MySQL 8.0, MongoDB 6.0, Redis 7.x를 Docker Compose로 운영. 모든 DB가 같은 서버에 위치하므로 네트워크 RTT는 사실상 0ms이고, 병목은 순수 쿼리 처리 시간이다.
데이터 규모:
- 사용자: 100명
- 총 채팅방: 500개 (사용자당 평균 10개)
- 채팅방당 평균 메시지: 150개
- MongoDB 총 메시지: 75,000개
정상 동작하는 API들: 게시글 CRUD, 로그인 등은 50ms 이내로 응답. 채팅방 목록 조회만 유독 느렸다.
1. 문제 상황
채팅방 목록에는 생각보다 많은 정보가 필요했습니다.
채팅방 목록에 보여줄 정보:
- 채팅방 기본 정보 - MySQL (ChatRoom)
- 상품 정보 (제목, 썸네일) - MySQL (Product, ProductFile)
- 상대방 정보 (닉네임, 프로필) - MySQL (Member, profileImage)
- 마지막 메시지 내용/시간 - MySQL (lastMessage, lastMessageAt)
- 채팅방 설정 (고정, 알림끄기) - MySQL (ChatRoomMember)
- 안읽은 메시지 개수 - MongoDB (count 쿼리)
DTO 필드만 해도 이 정도였다:
가장 직관적인 방법으로 구현했습니다.

테스트 환경을 설정하고 측정했습니다.
측정 조건: EC2 t3.medium, Spring Boot 내장 Tomcat 기본 설정, 단일 요청 기준 (동시 접속 없음). MySQL/MongoDB/Redis 모두 같은 서버.
채팅방 10개를 조회하면:
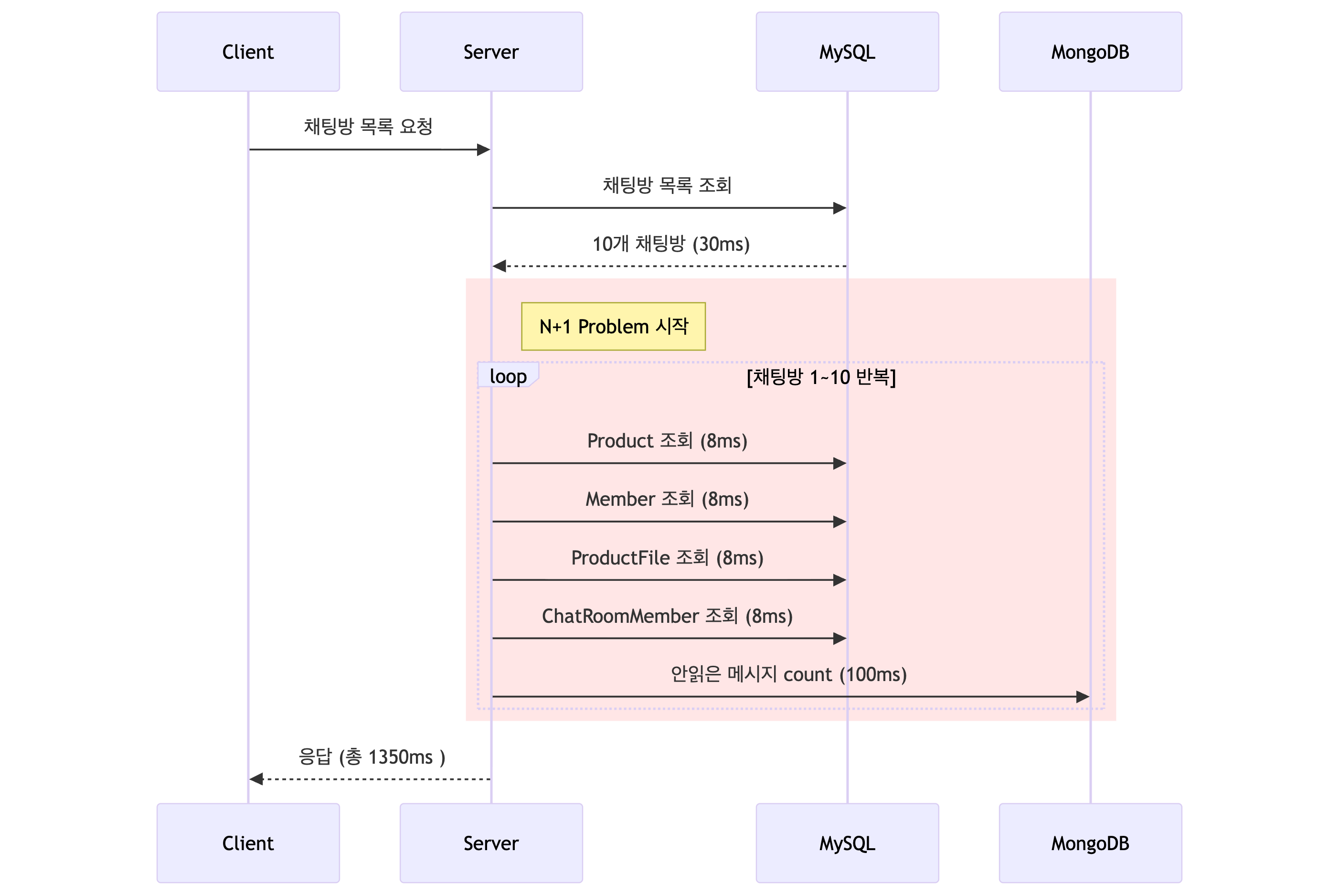
1.35초가 걸렸습니다. 채팅방이 많아질수록 선형으로 느려졌습니다.
N+1 Query 문제
핵심 문제는 N+1 Query였습니다. 채팅방 N개에 대해 여러 종류의 추가 쿼리가 발생했습니다.
채팅방 10개 조회 시 발생하는 쿼리:
- ChatRoom 목록 조회 (1번)
- Product 조회: N번 (Lazy Loading)
- Member 조회: N번 (Lazy Loading)
- ProductFile 조회: N번 (썸네일)
- ChatRoomMember 조회: N번 (설정)
- MongoDB count 조회: N번 (안읽은 개수)
총 쿼리 수: 1 + 5N
가장 느린 건 MongoDB count 쿼리였습니다. 쿼리 1번당 평균 100ms가 걸렸습니다.
MongoDB count 쿼리 과정:
- 네트워크 RTT (서버 -> MongoDB)
- 인덱스 탐색 (B-Tree 순회)
- 조건에 맞는 메시지 개수 계산
- 결과 반환
-> 디스크 I/O가 병목
문제는 쿼리를 너무 많이 날리는 것이었습니다. MongoDB 자체가 느린 것은 아니었습니다.
해결: Fetch Join + 배치 조회 + Redis 캐싱
최적화 후:
- ChatRoom + Product + Member: 1번 (Fetch Join)
- ChatRoomMember 설정: 1번 (배치 조회)
- ProductFile 썸네일: 1번 (배치 조회)
- 안읽은 개수: 1번 (Redis MGET)
총 쿼리 수: 4번
MySQL N+1은 Fetch Join과 배치 조회로 해결했습니다. MongoDB N+1은 Redis 캐싱으로 해결했습니다.
시도 1: MySQL 반정규화 (실패)
처음엔 MySQL에 unreadCount 컬럼을 추가하면 되지 않을까 싶었습니다.

세 가지 문제가 있었습니다.
데이터 정합성 문제
메시지 전송 시:
- MongoDB에 메시지 저장
- MySQL unreadCount 증가
MongoDB 저장 성공, MySQL 업데이트 실패?
-> 메시지는 있는데 안읽은 개수는 안 늘어남
분산 트랜잭션 필요
MongoDB와 MySQL 간 트랜잭션을 어떻게 보장하나?
2PC (Two-Phase Commit)?
- 구현 복잡
- 성능 오버헤드
- 장애 지점 증가
동시성 문제
사용자 A와 B가 동시에 메시지 전송:
Thread 1: unreadCount = 5 읽음
Thread 2: unreadCount = 5 읽음
Thread 1: unreadCount = 6으로 업데이트
Thread 2: unreadCount = 6으로 업데이트
-> 실제론 7이어야 하는데 6
분산 락이 필요하고, 복잡도가 급격히 올라갔습니다.
캐싱 전략 검토
N+1 문제를 해결하기 위한 캐싱 방법을 검토했습니다.
1. 애플리케이션 메모리 캐시 (HashMap)

서버 JVM 힙에 캐시를 두면 빠르지만, 재시작하면 사라지고 서버를 여러 대로 확장하면 동기화가 되지 않습니다.
2. MySQL 반정규화
위에서 다뤘듯이 분산 트랜잭션과 동시성 문제가 발생합니다.
3. MongoDB Aggregation Pipeline

채팅방별로 안읽은 메시지를 한 번에 집계할 수 있지만, 집계 연산 자체가 무겁고 매번 계산하므로 캐싱 효과가 없습니다.
4. Redis 캐싱 (선택)
메모리 기반이라 1ms 미만으로 빠르고, 이미 Redis Pub/Sub을 사용 중이라 추가 인프라가 필요 없습니다. INCR/DECR로 원자적 증감이 가능해서 분산 락도 불필요합니다. 캐시와 DB 간 불일치(Eventual Consistency)가 발생할 수 있지만, 안읽은 메시지 개수가 1-2초 늦게 업데이트되어도 사용자가 거의 못 느낍니다. 일관성보다 성능이 더 중요한 데이터였습니다.
캐시 일관성 전략
캐시 일관성 전략에는 여러 가지가 있습니다.
Write-through
쓰기 시 캐시와 DB 동시 업데이트
Write-behind
쓰기 시 캐시만 업데이트, 나중에 DB 반영
Cache-aside
읽기 시 캐시 확인 -> 없으면 DB 조회 -> 캐시에 저장
우리는 Write-through + Cache-aside 혼합을 선택했습니다.
- 메시지 전송 시: Redis INCR (Write-through처럼 즉시 반영)
- 읽음 처리 시: Redis DEL (캐시 무효화)
- 조회 시: Redis 확인 -> 없으면 MongoDB에서 계산 후 캐싱 (Cache-aside)
Write-behind는 메시지 유실 위험이 있어서 제외했습니다. 채팅에서 “안읽은 개수”가 실제보다 적게 보이는 건 치명적입니다.
왜 Redis인가
MongoDB 조회: 100ms (디스크 I/O)Redis 조회: 1ms 미만 (메모리)
-> 100배 빠름추가 인프라 없이 바로 적용 가능했습니다. Redis는 이미 Pub/Sub과 세션 관리에 사용 중이었으므로 새 인스턴스 추가 비용이 0이다.
비용 관점
6주 프로젝트에서 EC2 t3.medium 1대로 운영 중이므로 AWS 과금 기준의 비용 비교는 해당 없다. 대신 고정 자원(4GB RAM) 내 배분 트레이드오프로 평가한다:
Redis 추가 메모리: ~50MB (안읽은 개수 캐시 + Pub/Sub + 세션)Redis 없이 MongoDB만 사용: 매 목록 조회마다 countDocuments × N회 → CPU 100ms × NRedis 도입 후: 캐시 히트 시 1ms, 미스 시만 MongoDB → CPU 부하 95% 감소
4GB RAM 중 50MB는 1.2% — 투자 대비 효과가 압도적실무(AWS) 환경으로 환산하면: ElastiCache cache.t3.micro(월 ~$15) 추가로 MongoDB Atlas M10(월 ~$57)의 읽기 부하를 95% 줄일 수 있으므로, MongoDB를 M0(무료) 또는 Serverless로 다운스케일할 여지가 생긴다. Redis 도입은 비용을 늘리기보다 DB 다운스케일 가능성을 여는 선택이다.
“DB 인스턴스 스펙을 올리면 되지 않나?”라는 대안도 검토했다. MongoDB Atlas M20(월 ~$140)으로 올리면 countDocuments가 빨라지겠지만, N+1 구조 자체가 해결되지 않으므로 근본적 개선이 안 된다. 캐싱이 구조적으로 더 나은 선택이다.
왜 Redis 캐싱이 효과적인가
채팅방 목록은 같은 사용자가 반복 조회하는 데이터입니다. 사용자 A가 09:00에 목록을 보고 09:01에 다시 보면, 같은 안읽은 개수를 또 계산할 이유가 없습니다. 이런 시간 지역성이 높은 데이터는 캐싱 효과가 극대화됩니다.
Redis는 LRU(Least Recently Used)로 캐시를 관리합니다. 활성 사용자의 데이터는 자주 조회되어 캐시에 유지되고, 비활성 사용자의 데이터는 자동으로 제거됩니다.
우리 시스템 기준으로 추산하면:
전체 채팅방: 10,000개활성 채팅방(Working Set): 2,000개 (20%)Redis 메모리 필요량: 2,000개 x 100 bytes = 200 KB실제 Redis 할당: 1 GB-> Working Set이 충분히 메모리에 들어감-> 캐시 히트율 95% 이상 달성캐시 키 설계
Redis Key: “unread:{chatRoomId}:{memberId}”
Value: “5” (안읽은 개수)
TTL: 7일
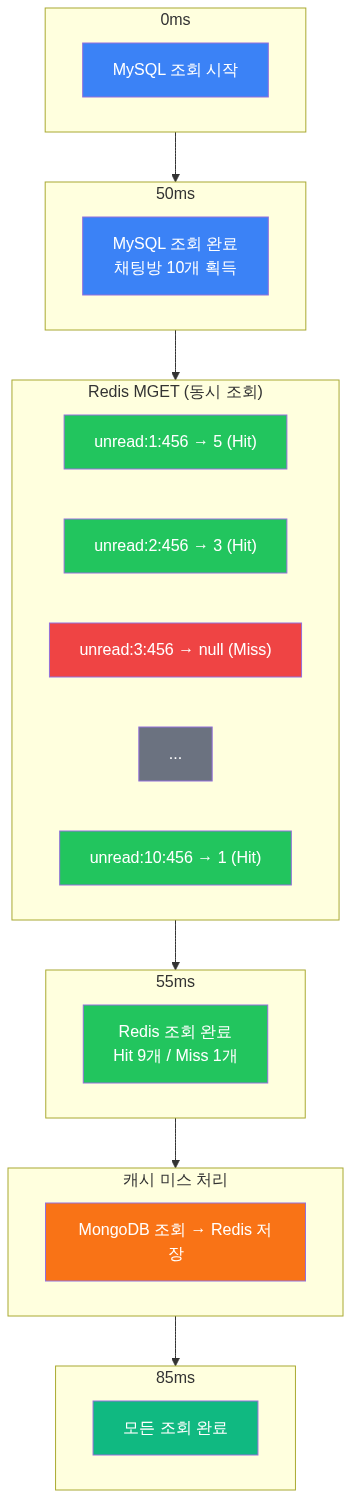
Redis MGET: 조회 10번을 1번으로
Redis에서 여러 값을 조회할 때 가장 중요한 건 명령 실행 횟수를 줄이는 것입니다.
잘못된 방식

올바른 방식

성능 비교
개별 조회 (GET 10번):- 명령 파싱 x 10- 결과 반환 x 10-> 총 10ms
MGET (1번):- 명령 파싱 x 1- 결과 배치 반환 x 1-> 총 1ms
-> 10배 빠름Redis는 명령 실행이 싱글 스레드입니다 (Redis 6+에서 I/O는 멀티스레드지만, 명령 처리 자체는 단일 스레드). 명령을 10번 보내면 파싱 오버헤드가 10번 누적됩니다. MGET은 이를 1번으로 줄여줍니다.
Cache Warming 전략
Redis 캐싱에서 가장 중요한 건 캐시 히트율입니다.
캐시 히트율 = 캐시에서 찾은 횟수 / 전체 조회 횟수
캐시 미스가 발생하면 MongoDB를 조회해야 해서 느려집니다.
캐시를 미리 채우는 시점
- 메시지 전송 시: 상대방 안읽은 개수 증가
-> INCR unread:{chatRoomId}:{receiverId} - 읽음 처리 시: Redis 초기화
-> DEL unread:{chatRoomId}:{memberId} - 캐시 미스 시: MongoDB에서 계산 후 Redis에 저장
-> SET unread:{chatRoomId}:{memberId} {count} EX 604800
실제 동작
실제 구현
UnreadCountService

채팅방 목록 조회 개선

결과
측정 조건: EC2 t3.medium (2 vCPU, 4GB), MySQL/MongoDB/Redis 동일 서버, 단일 요청 기준. 사용자 100명, 채팅방 500개, MongoDB 메시지 75,000개 환경.
최적화 후 쿼리 시간 분해:
- ChatRoom + Product + Member (Fetch Join): 50ms, MySQL 1회로 3개 테이블 JOIN
- ChatRoomMember 배치 조회: 15ms,
WHERE chat_room_id IN (...)1회 - ProductFile 배치 조회: 15ms,
WHERE product_id IN (...)1회 - Redis MGET (10개 키 일괄 조회): 5ms, 캐시 히트율 95%이고 미스 시 MongoDB countDocuments 후 캐시 저장
| 지표 | Before | After | 개선 |
|---|---|---|---|
| 총 쿼리 수 | 51번 (1 + 5N, N=10) | 4번 | 쿼리 92% 감소 |
| 총 소요 시간 | 1,350ms | 85ms | 16배 개선 |
| 캐시 히트율 | 없음 (매번 MongoDB) | 95% | MongoDB 부하 95% 감소 |
| 캐시 미스 시 | — | +100ms (MongoDB fallback) | 여전히 Before보다 빠름 |
캐시 미스가 발생하면 MongoDB countDocuments()를 Coroutine async로 병렬 조회한다. 10개 채팅방에서 캐시 미스가 5개여도 병렬 실행으로 ~100ms에 완료되므로, 최악의 경우(전체 캐시 미스)에도 185ms로 Before(1,350ms) 대비 7배 빠르다.
후기
사실 이게 맞나 싶었습니다.
안읽은 메시지 개수를 Redis에 캐싱하고, INCR/DEL로 관리하는 게 “정석”인지 확신이 없었습니다. 혹시 더 좋은 방법이 있는데 모르는 건 아닐까?
대규모 서비스에서의 Redis 캐싱 사례
찾아보니 대형 서비스들도 비슷한 패턴을 쓰고 있었습니다.
Twitter는 타임라인 서비스에 Redis를 사용합니다. 초당 3,900만 건(39MM QPS)의 요청을 처리하고, 10,000개 이상의 Redis 인스턴스로 105TB의 데이터를 관리합니다. 각 사용자의 타임라인에 최근 800개의 트윗 ID를 Redis에 저장해서 빠른 조회를 제공합니다.
Pinterest도 수십억 개의 관계 데이터를 Redis에 캐싱합니다. 사용자 ID 공간을 8192개의 가상 샤드로 나누고, 여러 Redis 인스턴스에 분산 저장합니다. “이 사용자가 이 보드를 팔로우하는가?” 같은 빈번한 조회를 Redis로 처리합니다.
출처: Using Redis at Pinterest for Billions of Relationships - VMware Tanzu
국내 기업들의 Redis 캐싱 사례
국내 대형 서비스들도 비슷한 패턴을 사용하고 있었습니다.
카카오페이는 로컬 캐시와 Redis를 목적에 따라 구분해서 사용합니다. 자주 변하지 않는 조회성 데이터(상품, 통신사, 혜택 등)는 로컬 캐시에, 세션이나 자주 변경되는 동적 데이터는 Redis에 저장합니다. Redis Pub/Sub으로 데이터 변경 이벤트를 발행하고, 각 서버가 구독해서 로컬 캐시를 무효화하는 방식으로 최종 일관성(Eventual Consistency)을 달성합니다.
토스는 Redis를 인메모리 캐시로 사용하면서 캐시 쇄도(Cache Stampede), 캐시 관통(Cache Penetration), 핫키 만료 등의 문제를 해결하기 위해 다양한 전략을 적용합니다. 특히 핫키 만료 시 Redis의 싱글 스레드 특성을 활용한 레드락(Redlock) 알고리즘으로 분산 락을 구현합니다.
올리브영은 로컬 캐시(Caffeine)와 Redis를 결합한 다중 레이어 캐시를 적용했습니다. Redis만 사용했을 때 네트워크 송신량이 높아지자, 로컬 캐시를 1차로 두고 Redis를 2차로 두는 구조로 변경했습니다. 결과적으로 TPS는 478% 증가하고, Redis 네트워크 송신량은 99.1% 감소했습니다.
안읽은 개수처럼 자주 조회되고, 정확도보다 속도가 중요한 데이터는 Redis 캐싱이 사실상 표준이었습니다.
6주 프로젝트의 한계
다만 현업과 다른 점도 있었습니다.
6주 프로젝트에서 못 한 것
- 캐시 정합성 모니터링 (Redis와 MongoDB 값이 어긋나면?)
- 캐시 장애 시 폴백 전략 (Redis 죽으면?)
- 부하 테스트 기반 TTL 튜닝
- 캐시 워밍 배치 작업
특히 캐시 정합성 검증 로직을 못 만든 게 아쉬웠습니다. 현재 구현은 “캐시가 항상 맞다”고 가정하는데, 실무에서는 “캐시가 틀릴 수 있다”고 가정하고 검증 로직을 넣습니다.
// 만들고 싶었던 검증 배치@Scheduled(cron = "0 0 4 * * *") // 매일 새벽 4시fun validateUnreadCountCache() { // 1. 활성 채팅방 목록 조회 val activeChatRooms = chatRoomRepository.findActiveRooms()
// 2. Redis 값과 MongoDB 값 비교 activeChatRooms.forEach { room -> val redisCount = redis.get("unread:${room.id}:${room.memberId}") val mongoCount = chatMessageRepository.countUnread(room.id, room.memberId)
if (redisCount != mongoCount) { // 3. 불일치 시 MongoDB 기준으로 재동기화 redis.set("unread:${room.id}:${room.memberId}", mongoCount) log.warn("캐시 불일치 발견: room=${room.id}, redis=$redisCount, mongo=$mongoCount") } }}이 로직이 있으면 INCR/DEL 과정에서 네트워크 장애로 캐시가 어긋나도 다음 날 새벽에 자동으로 보정됩니다. 시간이 더 있었다면 불일치율 메트릭까지 수집해서 모니터링 대시보드를 만들고 싶었습니다.
현업에서의 캐시 동기화
현업에서는 캐시 무효화를 자동화하기 위해 CDC(Change Data Capture) 패턴을 많이 사용합니다.
Debezium + Kafka 조합이 대표적입니다. DB의 트랜잭션 로그를 감시하다가 데이터가 변경되면 Kafka로 이벤트를 발행하고, 이를 구독해서 캐시를 무효화합니다. 우리 프로젝트처럼 애플리케이션 코드에서 수동으로 캐시를 관리하면 놓치는 케이스가 생길 수 있는데, CDC는 DB 레벨에서 모든 변경을 캡처하므로 누락이 없습니다.
출처: Automating Cache Invalidation With Change Data Capture - Debezium Blog
NATS도 대안이 될 수 있습니다. Kafka가 높은 처리량과 메시지 영속성에 최적화되어 있다면, NATS는 저지연과 경량화에 최적화되어 있습니다. 마이크로서비스 간 실시간 통신이나 캐시 무효화 이벤트 전달처럼 단순한 pub/sub 용도에는 NATS가 더 가볍고 빠릅니다. Tesla, PayPal, Walmart 같은 기업들이 NATS를 사용 중입니다.
출처: NATS and Kafka Compared - Synadia
출처: About NATS - NATS.io
현업에서 추가로 고려할 것:- CDC로 캐시 자동 동기화 (Debezium + Kafka 또는 NATS)- Redis Cluster 구성- 캐시 히트율 메트릭 수집- Circuit Breaker 패턴배운 점
그래도 “왜 Redis를 썼는지”, “왜 INCR이 atomic한지”, “캐시 일관성 전략이 뭔지” 정도는 설명할 수 있게 됐습니다. 대규모 서비스들도 같은 패턴을 쓴다는 걸 확인하니 방향은 맞았다고 생각합니다. 6주 프로젝트치고는 충분히 깊이 있게 고민했습니다.
We had designed the MongoDB + Redis Pub/Sub architecture. Now it was time to build the chatroom list query API.
0. Normal State
Server environment: Single AWS EC2 t3.medium (2 vCPU, 4GB RAM) running Spring Boot, MySQL 8.0, MongoDB 6.0, and Redis 7.x via Docker Compose. All DBs on the same server, so network RTT is effectively 0ms — bottleneck is pure query processing time.
Data scale: 100 users, 500 chatrooms (avg 10 per user), 150 messages per chatroom, 75,000 total MongoDB messages.
Normally functioning APIs: Post CRUD, login, etc. all respond within 50ms. Only the chatroom list query was slow.
1. The Problem
The chatroom list required more information than expected.
Information needed for the chatroom list:
- Chatroom basic info - MySQL (ChatRoom)
- Product info (title, thumbnail) - MySQL (Product, ProductFile)
- Counterpart info (nickname, profile) - MySQL (Member, profileImage)
- Last message content/time - MySQL (lastMessage, lastMessageAt)
- Chatroom settings (pinned, muted) - MySQL (ChatRoomMember)
- Unread message count - MongoDB (count query)
The DTO fields alone were substantial:
We implemented it in the most straightforward way.
We set up a test environment and measured performance.
Test environment:
- Users: 100
- Total chatrooms: 500 (average 10 per user)
- Average messages per chatroom: 150
- Total MongoDB messages: 75,000
Querying 10 chatrooms:
It took 1.35 seconds. It slowed linearly as the number of chatrooms increased.
N+1 Query Problem
The core issue was N+1 queries. Multiple additional queries were fired for each of the N chatrooms.
Queries generated when loading 10 chatrooms:
- ChatRoom list query (1 time)
- Product query: N times (Lazy Loading)
- Member query: N times (Lazy Loading)
- ProductFile query: N times (thumbnails)
- ChatRoomMember query: N times (settings)
- MongoDB count query: N times (unread count)
Total queries: 1 + 5N
The slowest was the MongoDB count query, averaging 100ms per call.
MongoDB count query process:
- Network RTT (Server -> MongoDB)
- Index traversal (B-Tree)
- Count matching messages
- Return result
-> Disk I/O is the bottleneck
MongoDB wasn’t slow — we were making too many queries.
Solution: Fetch Join + Batch Queries + Redis Caching
After optimization:
- ChatRoom + Product + Member: 1 query (Fetch Join)
- ChatRoomMember settings: 1 query (batch)
- ProductFile thumbnails: 1 query (batch)
- Unread counts: 1 call (Redis MGET)
Total queries: 4
MySQL N+1 was solved with Fetch Join and batch queries. MongoDB N+1 was solved with Redis caching.
Attempt 1: MySQL Denormalization (Failed)
Initially, we considered adding an unreadCount column to MySQL.
Three problems emerged.
Data Consistency Issue
When sending a message:
- Save message to MongoDB
- Increment MySQL unreadCount
What if MongoDB save succeeds but MySQL update fails?
-> Message exists but unread count doesn’t increase
Distributed Transaction Required
How to guarantee transactions between MongoDB and MySQL?
2PC (Two-Phase Commit)?
- Complex implementation
- Performance overhead
- More failure points
Concurrency Issue
Users A and B send messages simultaneously:
Thread 1: reads unreadCount = 5
Thread 2: reads unreadCount = 5
Thread 1: updates to 6
Thread 2: updates to 6
-> Should be 7, but it’s 6
Distributed locks would be needed, dramatically increasing complexity.
Caching Strategy Review
We evaluated caching approaches to solve the N+1 problem.
1. Application Memory Cache (HashMap)
Fast when cached in JVM heap, but lost on restart and impossible to synchronize across multiple servers.
2. MySQL Denormalization
As discussed above, causes distributed transaction and concurrency issues.
3. MongoDB Aggregation Pipeline
Can aggregate unread messages per chatroom in one query, but the aggregation itself is heavy and recalculated every time — no caching benefit.
4. Redis Caching (Chosen)
Sub-1ms reads (memory-based), no additional infrastructure needed (already using Redis Pub/Sub), and atomic increment/decrement via INCR/DECR eliminates the need for distributed locks. Eventual consistency between cache and DB is acceptable — users barely notice a 1-2 second delay in unread counts. Performance mattered more than strict consistency for this data.
Cache Consistency Strategy
There are several cache consistency strategies.
Write-through
Update cache and DB simultaneously on writes
Write-behind
Update only cache on writes, sync to DB later
Cache-aside
Check cache on read -> if miss, query DB -> store in cache
We chose a Write-through + Cache-aside hybrid.
- On message send: Redis INCR (immediate, like write-through)
- On read receipt: Redis DEL (cache invalidation)
- On query: Check Redis -> if miss, compute from MongoDB and cache (cache-aside)
Write-behind was excluded due to message loss risk. Showing fewer unread messages than actual is critical in chat.
Why Redis
MongoDB query: 100ms (disk I/O)Redis query: <1ms (memory)
-> 100x fasterImmediately applicable with no additional infrastructure.
Why Redis Caching Is Effective
Chatroom lists are data that the same user queries repeatedly. If user A views the list at 09:00 and again at 09:01, there’s no reason to recalculate the same unread counts. Data with high temporal locality maximizes caching effectiveness.
Redis manages cache with LRU (Least Recently Used). Active users’ data stays cached through frequent access, while inactive users’ data is automatically evicted.
Estimated for our system:
Total chatrooms: 10,000Active chatrooms (Working Set): 2,000 (20%)Redis memory needed: 2,000 x 100 bytes = 200 KBActual Redis allocation: 1 GB-> Working Set fits comfortably in memory-> Achieves 95%+ cache hit rateCache Key Design
Redis Key: “unread:{chatRoomId}:{memberId}”
Value: “5” (unread count)
TTL: 7 days
Redis MGET: 10 Queries to 1
When retrieving multiple values from Redis, reducing the number of commands is crucial.
Wrong Approach
Correct Approach
Performance Comparison
Individual queries (GET x10):- Command parsing x10- Result return x10-> Total 10ms
MGET (x1):- Command parsing x1- Batch result return x1-> Total 1ms
-> 10x fasterRedis operates on a single thread. Sending 10 commands accumulates parsing overhead 10 times. MGET reduces this to once.
Cache Warming Strategy
The most important metric in Redis caching is the cache hit rate.
Cache hit rate = cache hits / total queries
Cache misses require MongoDB queries, causing slowdowns.
When to Pre-populate the Cache
- On message send: Increment receiver’s unread count
-> INCR unread:{chatRoomId}:{receiverId} - On read receipt: Reset Redis
-> DEL unread:{chatRoomId}:{memberId} - On cache miss: Compute from MongoDB and store in Redis
-> SET unread:{chatRoomId}:{memberId} {count} EX 604800
Actual Behavior
Implementation
UnreadCountService
Chatroom List Query Improvement
Results
Test Environment
- Users: 100
- Total chatrooms: 500 (average 10 per user)
- Average messages per chatroom: 150
- Total MongoDB messages: 75,000
Optimized Query Times
- ChatRoom + Product + Member (Fetch Join): 50ms
- ChatRoomMember batch query: 15ms
- ProductFile batch query: 15ms
- Redis MGET (95% hit rate): 5ms
Total: 85ms
| Metric | Before | After |
|---|---|---|
| Chatrooms | 10 | 10 |
| Total queries | 51 | 4 |
| Total time | 1350ms | 85ms |
| Cache hit rate | - | 95% |
16x faster.
Retrospective
Honestly, I wasn’t sure this was the right approach.
I wasn’t confident that caching unread message counts in Redis and managing them with INCR/DEL was the “standard” approach. Maybe there was a better method I didn’t know about?
Redis Caching in Large-scale Services
It turned out major services use similar patterns.
Twitter uses Redis for its timeline service, handling 39 million QPS with over 10,000 Redis instances managing 105TB of data. They store the 800 most recent tweet IDs per user timeline in Redis for fast retrieval.
Pinterest caches billions of relationship data in Redis, partitioning the user ID space into 8,192 virtual shards distributed across Redis instances. Frequent queries like “does this user follow this board?” are handled by Redis.
Source: Using Redis at Pinterest for Billions of Relationships - VMware Tanzu
Korean Companies’ Redis Caching
Major Korean services also use similar patterns.
KakaoPay separates local cache and Redis by purpose. Infrequently changing read-only data (products, carriers, benefits) goes to local cache, while sessions and frequently changing dynamic data goes to Redis. They achieve eventual consistency by publishing change events via Redis Pub/Sub and having each server subscribe to invalidate local caches.
Source: Local Caching in Distributed Systems - KakaoPay Tech Blog
Toss uses Redis as an in-memory cache and applies various strategies to handle cache stampede, cache penetration, and hot key expiration. They implement distributed locks using the Redlock algorithm, leveraging Redis’s single-threaded nature.
Olive Young applied multi-layer caching combining local cache (Caffeine) with Redis. When network throughput became high with Redis alone, they added local cache as the first layer and Redis as the second. This resulted in a 478% TPS increase and 99.1% reduction in Redis network throughput.
Source: High-Performance Cache Architecture Design - Olive Young Tech Blog
For frequently queried data where speed matters more than precision — like unread counts — Redis caching is effectively the industry standard.
Limitations of a 6-week Project
There were differences from production environments.
What we couldn’t do in 6 weeks:
- Cache consistency monitoring (what if Redis and MongoDB values diverge?)
- Fallback strategy on cache failure (what if Redis goes down?)
- Load test-based TTL tuning
- Cache warming batch jobs
The biggest regret was not building cache consistency validation logic. Our implementation assumes “the cache is always correct,” but production systems assume “the cache can be wrong” and include validation.
// The validation batch we wanted to build@Scheduled(cron = "0 0 4 * * *") // Daily at 4 AMfun validateUnreadCountCache() { // 1. Get active chatrooms val activeChatRooms = chatRoomRepository.findActiveRooms()
// 2. Compare Redis and MongoDB values activeChatRooms.forEach { room -> val redisCount = redis.get("unread:${room.id}:${room.memberId}") val mongoCount = chatMessageRepository.countUnread(room.id, room.memberId)
if (redisCount != mongoCount) { // 3. Re-sync based on MongoDB on mismatch redis.set("unread:${room.id}:${room.memberId}", mongoCount) log.warn("Cache inconsistency found: room=${room.id}, redis=$redisCount, mongo=$mongoCount") } }}With this logic, even if caches drift due to network failures during INCR/DEL, they’d auto-correct the next morning. Given more time, we would have collected mismatch rate metrics and built a monitoring dashboard.
Cache Synchronization in Production
Production systems often use the CDC (Change Data Capture) pattern to automate cache invalidation.
The Debezium + Kafka combination is a classic approach. It monitors DB transaction logs, publishes events to Kafka on data changes, and subscribers invalidate caches accordingly. Unlike our project’s manual cache management in application code, CDC captures all changes at the DB level with zero omissions.
Source: Automating Cache Invalidation With Change Data Capture - Debezium Blog
NATS is another alternative. While Kafka is optimized for high throughput and message durability, NATS is optimized for low latency and lightweight operation. For simple pub/sub use cases like inter-microservice communication or cache invalidation events, NATS is lighter and faster. Companies like Tesla, PayPal, and Walmart use NATS.
Source: NATS and Kafka Compared - Synadia
Source: About NATS - NATS.io
Additional production considerations:- Automated cache sync via CDC (Debezium + Kafka or NATS)- Redis Cluster setup- Cache hit rate metrics collection- Circuit Breaker patternLessons Learned
At the very least, I can now explain “why we chose Redis,” “why INCR is atomic,” and “what cache consistency strategies exist.” Confirming that large-scale services use the same patterns validated our direction. For a 6-week project, we dug deep enough.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.