Snowflake ID 도입기
목차
파일 업로드 API 만들면서 ID를 어떻게 할지 고민했습니다.
결론부터 말하면 내부 PK는 Auto Increment, 외부 노출용은 Snowflake ID로 분리했습니다.
왜 ID를 두 개로 분리하나
API 응답에 "uploadId": 1, "uploadId": 2 이렇게 순차적인 ID가 내려가면 문제입니다.
공격자가 ID를 1씩 증가시키면서 DELETE /api/v1/uploads/3, DELETE /api/v1/uploads/4 이런 식으로 다른 유저 파일 삭제를 시도할 수 있습니다.
물론 권한 체크가 있으니 실제로 삭제는 안 되겠지만, 전체 파일 수나 생성 속도 같은 비즈니스 정보가 노출됩니다.
그래서 내부 PK는 Auto Increment로 두고, API에 노출되는 건 UUID나 Snowflake 같은 불투명한 ID를 씁니다.
왜 업로드에만 적용했나?
게시글이나 댓글도 마찬가지로 public ID가 필요하긴 합니다. 근데 업로드는 좀 다른 점이 있습니다:
-
Presigned URL 흐름: 클라이언트가 Presigned URL 요청하면 서버에서 메타데이터(파일명, 크기, 상태=PENDING 등)를 먼저 DB에 저장하고, 그 ID를 R2 경로에 포함시킵니다. 이때 Auto Increment PK를 그대로 쓰면
/uploads/1,/uploads/2같은 예측 가능한 ID가 외부에 노출됩니다. Snowflake로 public ID를 따로 만들면 내부 PK는 숨기면서 불투명한 ID만 클라이언트에 내려줄 수 있습니다. -
외부 스토리지 경로: R2 저장 경로에 public ID가 들어갑니다.
profiles/{publicId}/image.jpg이런 식입니다. 경로만 봐도 어떤 업로드인지 매핑되니까 디버깅할 때 편합니다.
게시글이나 댓글은 일반적인 CRUD 흐름이라 Auto Increment PK를 그대로 쓰고, 나중에 필요하면 public ID 컬럼을 추가하면 됩니다.
지금 당장 분리할 필요는 없어서 업로드에만 먼저 적용했습니다.
MSA 관점에서도 Snowflake는 장점이 있습니다.
업로드 서비스를 별도로 분리하게 되면 DB도 분리될 텐데, Auto Increment는 DB마다 따로 관리되니까 ID 충돌이 납니다.
Snowflake는 애플리케이션에서 생성하니까 DB가 분리돼도 문제없습니다.
근데 이건 나중 얘기라 일단 넘어가겠습니다.
@Entitypublic class Upload { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; // 내부용 (4~8바이트)
@Column(unique = true) private Long publicId; // 외부 노출용 (8바이트)}UUID를 PK로 쓰면 안 되는 이유
UUID를 바이너리(BINARY(16))로 저장해도 16바이트입니다. Auto Increment BIGINT는 8바이트, INT는 4바이트. 이 차이가 왜 중요하냐면:
1. 인덱스 페이지 효율
MySQL InnoDB 인덱스 페이지는 기본 16KB입니다.
PK가 4바이트면 한 페이지에 들어가는 레코드 수가 UUID(16바이트)보다 4배 많습니다.
PlanetScale 블로그에서 계산한 걸 보면, 같은 데이터량에서 UUID는 인덱스 페이지를 약 4배 더 만듭니다.
세컨더리 인덱스도 문제입니다. InnoDB는 세컨더리 인덱스에 PK를 포인터로 저장하니까 PK가 크면 모든 인덱스가 같이 뚱뚱해집니다.
2. 페이지 스플릿과 단편화
UUID v4는 완전 랜덤이라 INSERT할 때 B-Tree 아무 데나 끼어들어갑니다.
MySQL은 PK 기준으로 클러스터드 인덱스를 만드니까, 순차적인 INSERT도 여러 데이터 블록에 흩어져 저장됩니다.
Percona에 따르면:
InnoDB will fill the pages to about 94% before creating a new page. When the primary key is random, the amount of space utilized from each page can be as low as 50%.
순차 PK는 페이지를 94%까지 채우는데, 랜덤 UUID는 50%밖에 못 채웁니다.
페이지 스플릿이 계속 일어나면서 단편화되고, 범위 검색도 비효율적이 됩니다.
3. 애플리케이션 레벨 자료형
UUID를 문자열(CHAR(36))로 저장하면 36바이트로 더 커집니다.
바이너리로 저장해도 애플리케이션에서 UUID 객체로 변환하고, JSON 직렬화할 때 문자열로 바꾸고… 자잘한 처리가 늘어납니다.
Auto Increment만 쓰면?
싱글 서버면 문제없습니다. 근데:
1. 분산 환경에서 충돌
서버 A가 1, 2, 3 만들고 서버 B도 1, 2, 3 만들면 충돌납니다.
DB 하나로 ID 생성을 중앙화하면 해결되지만, 그러면 DB가 병목이 됩니다.
2. DB 경합
잘 만든 DBMS라 충돌은 안 나도, Auto Increment 값 할당할 때 락이 걸립니다.
트래픽 많으면 경합으로 인한 자원 소모가 생깁니다.
ID 생성을 애플리케이션 레벨로 빼면 이 병목을 줄일 수 있습니다.
Snowflake ID
Twitter가 2010년에 발표한 분산 ID 생성 알고리즘입니다.
Twitter 엔지니어링 블로그에서 공개했고, Wikipedia에 따르면 Discord, Instagram, Mastodon 등에서도 변형해서 씁니다.
[1비트 부호] [41비트 타임스탬프] [10비트 머신ID] [12비트 시퀀스]왜 Snowflake인가:
- 8바이트: UUID v7(16바이트)의 절반. MySQL BIGINT에 딱 맞습니다.
- 시간순 정렬: 타임스탬프가 상위 비트라 대략 시간순입니다. B-Tree 입장에서 거의 순차 삽입이라 페이지 스플릿이 적습니다.
- DB 병목 제거: 애플리케이션에서 ID를 생성하니까 DB 락 경합이 없습니다.
- 비즈니스 정보 포함: 머신 ID 보고 어느 서버에서 생성됐는지 알 수 있습니다. 디버깅할 때 유용합니다.
Snowflake의 단점
시계 동기화 필수
다중 서버 환경에서 시계가 안 맞으면 ID 순서가 꼬이거나 중복이 날 수 있습니다.
NTP 동기화가 필수고, 시계가 뒤로 가면 예외를 던지도록 처리해야 합니다.
if (currentTimestamp < lastTimestamp) { throw new IllegalStateException("Clock moved backwards");}싱글 서버면 이 문제는 거의 없지만, 스케일아웃하면 신경 써야 할 부분입니다.
UUID v7은?
2024년에 RFC 9562로 표준화됐습니다.
Snowflake 영향을 받아서 타임스탬프 기반이라 시간순 정렬이 됩니다.
Buildkite에서 시간순 UUID로 전환하면서 다른 최적화와 함께 6주간 WAL 쓰기가 50% 줄었다고 합니다(UUID v7 단독 효과는 아니고 복합적 개선 결과).
UUID v7은 16바이트로 Snowflake(8바이트)의 두 배지만, RFC 9562로 표준화되어 있고 시계 동기화에 덜 민감합니다.
반면 Snowflake는 크기가 작아 MySQL처럼 PK 크기가 중요한 환경에서 유리하고, 별도 라이브러리 없이 직접 구현할 수 있습니다.
기존에 UUID 인프라가 있거나 PostgreSQL처럼 UUID 타입이 잘 지원되는 환경이면 UUID v7이 나을 수 있습니다.
Instagram, Discord는 어떻게 했나
Instagram (Engineering 블로그)
초당 25장 업로드에 90개 좋아요를 처리해야 했습니다.
Twitter Snowflake를 검토했는데 별도 ID 서비스 운영이 부담이라 PostgreSQL 안에서 비슷하게 구현했다고 합니다.
- 41비트: 타임스탬프
- 13비트: 샤드 ID (어느 샤드인지 ID만 보고 알 수 있음)
- 10비트: 시퀀스
Discord (공식 문서)
- 42비트: 타임스탬프 (epoch: 2015-01-01)
- 5비트: 워커 ID
- 5비트: 프로세스 ID
- 12비트: 시퀀스
JavaScript Number가 53비트까지만 정밀해서 API에서 ID를 문자열로 반환합니다.
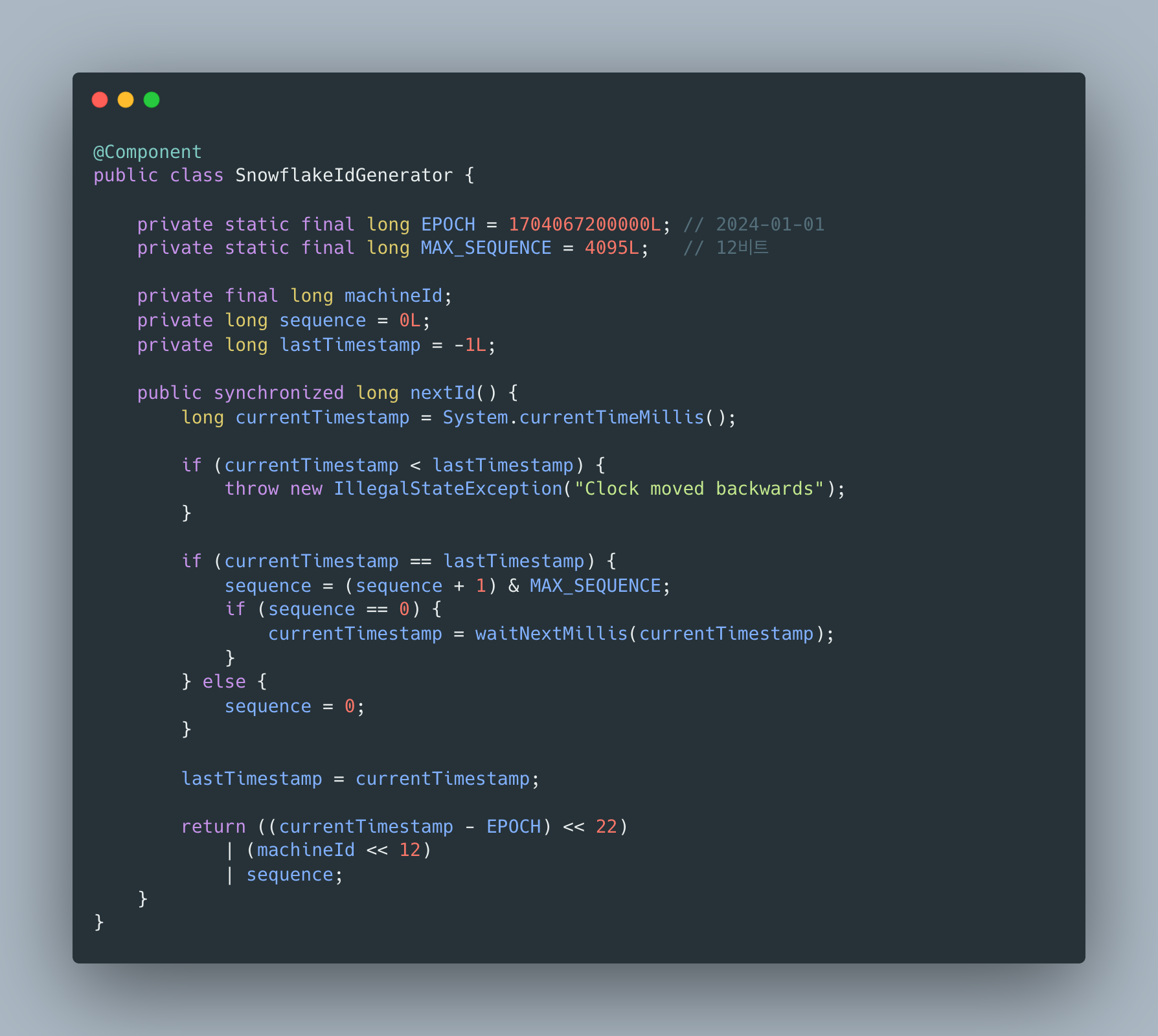
이 프로젝트 구현
synchronized: 같은 밀리초에 여러 스레드가 호출해도 시퀀스로 구분- 시계 역행 체크: NTP 동기화 문제 대비
- 머신 ID: MAC 주소 해시로 자동 생성
정리
싱글 서버 내부 시스템이면 Auto Increment로 충분하고, 외부 노출이 필요한 MySQL 환경이면 Snowflake(8바이트), 기존 UUID 인프라가 있거나 PostgreSQL이면 UUID v7도 괜찮습니다.
이 프로젝트는 모바일 앱 전용 API라 UUID 호환이 필요 없었습니다.
내부 PK는 Auto Increment로 JPA 최적화하고, 외부 노출용만 Snowflake로 분리했습니다.
왜 MySQL인가: 이 프로젝트는 Read-heavy 워크로드(타이머 기록 조회, 랭킹 조회)가 주이고, 복잡한 JOIN보다 단순 CRUD가 대부분입니다. 팀 내 MySQL 운영 경험이 있고, Oracle Cloud Free Tier에서 제공하는 ARM 인스턴스에 MySQL을 직접 설치해서 비용 없이 운영 가능합니다. PostgreSQL은 UUID 네이티브 타입 지원과 JSONB 등 장점이 있지만, 이 프로젝트에서는 필요하지 않았습니다. Snowflake ID가 Long(8바이트)이라 MySQL BIGINT에 딱 맞는 것도 선택 이유 중 하나입니다.
참고 자료
- Twitter Engineering - Announcing Snowflake
- Instagram Engineering - Sharding & IDs at Instagram
- PlanetScale - The Problem with Using a UUID Primary Key in MySQL
- Percona - UUIDs are Popular, but Bad for Performance
- Buildkite - Goodbye to sequential integers, hello UUIDv7!
- RFC 9562 - UUID Version 7
- Discord - Snowflake IDs
While building a file upload API, I had to decide how to handle IDs. Long story short, I used Auto Increment for the internal PK and Snowflake ID for the externally exposed ID.
Why Separate IDs?
If API responses return sequential IDs like "uploadId": 1, "uploadId": 2, that is a problem. An attacker could increment the ID by 1 and try requests like DELETE /api/v1/uploads/3, DELETE /api/v1/uploads/4 to attempt deleting other users’ files. Of course, authorization checks would prevent actual deletion, but business information like total file count or creation rate would be exposed.
So the internal PK stays as Auto Increment, and the ID exposed through the API uses an opaque identifier like UUID or Snowflake.
Why only uploads?
Posts and comments also need public IDs, but uploads are a bit different:
-
Presigned URL flow: When the client requests a Presigned URL, the server first saves metadata (filename, size, status=PENDING, etc.) to the DB and includes that ID in the R2 path. Using Auto Increment PK directly would expose predictable IDs like
/uploads/1,/uploads/2. By generating a separate public ID with Snowflake, the internal PK stays hidden while only the opaque ID is sent to the client. -
External storage path: The public ID is included in the R2 storage path, like
profiles/{publicId}/image.jpg. Being able to map uploads just by looking at the path is convenient for debugging.
Posts and comments follow a standard CRUD flow, so they use Auto Increment PK as-is. A public ID column can always be added later if needed. Since there was no immediate need to separate them, I only applied it to uploads first.
From an MSA perspective, Snowflake also has advantages. If the upload service gets separated out, the DB would be split too, and Auto Increment is managed per DB, causing ID collisions. Snowflake generates IDs at the application level, so DB separation is not a problem. But that is a concern for later, so I will skip it for now.
@Entitypublic class Upload { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; // Internal (4-8 bytes)
@Column(unique = true) private Long publicId; // External-facing (8 bytes)}Why You Should Not Use UUID as PK
Even when storing UUID as binary (BINARY(16)), it is 16 bytes. Auto Increment BIGINT is 8 bytes, INT is 4 bytes. Here is why this difference matters:
1. Index Page Efficiency
MySQL InnoDB index pages are 16KB by default. With a 4-byte PK, a page can hold 4 times more records than with a UUID (16 bytes). According to PlanetScale’s blog, for the same amount of data, UUID creates roughly 4 times more index pages.
Secondary indexes are also affected. InnoDB stores the PK as a pointer in secondary indexes, so a larger PK makes all indexes bloated.
2. Page Splits and Fragmentation
UUID v4 is completely random, so INSERTs land anywhere in the B-Tree. Since MySQL builds a clustered index based on the PK, even sequential INSERTs get scattered across multiple data blocks.
According to Percona:
InnoDB will fill the pages to about 94% before creating a new page. When the primary key is random, the amount of space utilized from each page can be as low as 50%.
Sequential PKs fill pages up to 94%, while random UUIDs only achieve 50%. Continuous page splits cause fragmentation, and range queries become inefficient.
3. Application-Level Data Types
Storing UUID as a string (CHAR(36)) takes 36 bytes, making it even larger. Even with binary storage, you need to convert to UUID objects in the application and to strings during JSON serialization — the small overhead adds up.
What About Using Only Auto Increment?
For a single server, it is fine. But:
1. Collisions in Distributed Environments
If Server A generates 1, 2, 3 and Server B also generates 1, 2, 3, they collide. Centralizing ID generation with a single DB solves it, but then the DB becomes a bottleneck.
2. DB Contention
Even with a well-built DBMS that avoids collisions, a lock is acquired when allocating Auto Increment values. Under heavy traffic, contention leads to resource overhead. Moving ID generation to the application level reduces this bottleneck.
Snowflake ID
A distributed ID generation algorithm announced by Twitter in 2010. It was published on the Twitter Engineering blog, and according to Wikipedia, Discord, Instagram, Mastodon, and others use variations of it.
[1-bit sign] [41-bit timestamp] [10-bit machine ID] [12-bit sequence]Why Snowflake:
- 8 bytes: Half the size of UUID v7 (16 bytes). Fits perfectly in a MySQL BIGINT.
- Time-ordered: The timestamp occupies the upper bits, so IDs are roughly time-sorted. From the B-Tree’s perspective, this is nearly sequential insertion, minimizing page splits.
- Eliminates DB bottleneck: IDs are generated at the application level, so there is no DB lock contention.
- Embeds business information: The machine ID reveals which server generated the ID, which is useful for debugging.
Downsides of Snowflake
Clock Synchronization Required
In a multi-server environment, if clocks are out of sync, ID ordering can break or duplicates can occur. NTP synchronization is essential, and the system should throw an exception if the clock moves backward.
if (currentTimestamp < lastTimestamp) { throw new IllegalStateException("Clock moved backwards");}On a single server this is rarely an issue, but it becomes a concern when scaling out.
What About UUID v7?
It was standardized as RFC 9562 in 2024. Influenced by Snowflake, it is timestamp-based and supports time-ordering. Buildkite reported a 50% reduction in WAL writes after switching to time-ordered UUIDs (combined with other optimizations over a 6-week period, not solely attributable to the UUID change).
UUID v7 is 16 bytes — twice the size of Snowflake (8 bytes) — but it is standardized under RFC 9562 and less sensitive to clock synchronization. Snowflake, on the other hand, is smaller, which is advantageous in MySQL where PK size matters, and it can be implemented directly without external libraries. If you already have UUID infrastructure or use PostgreSQL where UUID types are well supported, UUID v7 may be the better choice.
How Instagram and Discord Did It
Instagram (Engineering blog)
They needed to handle 25 photo uploads per second and 90 likes per second. They evaluated Twitter Snowflake but found running a separate ID service too burdensome, so they implemented something similar inside PostgreSQL.
- 41 bits: timestamp
- 13 bits: shard ID (you can tell which shard just by looking at the ID)
- 10 bits: sequence
Discord (Official docs)
- 42 bits: timestamp (epoch: 2015-01-01)
- 5 bits: worker ID
- 5 bits: process ID
- 12 bits: sequence
Since JavaScript Number only supports up to 53-bit precision, the API returns IDs as strings.
Implementation in This Project
synchronized: Even when multiple threads call within the same millisecond, the sequence keeps them distinct- Clock regression check: Safeguard against NTP synchronization issues
- Machine ID: Auto-generated from a hash of the MAC address
Summary
For a single-server internal system, Auto Increment is sufficient. If external exposure is needed in a MySQL environment, Snowflake (8 bytes) is a good choice. If you already have UUID infrastructure or use PostgreSQL, UUID v7 is also viable.
This project is a mobile-app-only API, so UUID compatibility was not needed. The internal PK uses Auto Increment for JPA optimization, and only the externally exposed ID is separated using Snowflake.
Why MySQL: This project has a read-heavy workload (timer record queries, ranking lookups) with mostly simple CRUD rather than complex JOINs. There is existing MySQL operational experience, and MySQL can be installed directly on Oracle Cloud Free Tier ARM instances at no cost. PostgreSQL offers advantages like native UUID types and JSONB, but these were not needed for this project. Snowflake ID being a Long (8 bytes) that fits perfectly into MySQL BIGINT was also a factor in the decision.
References
- Twitter Engineering - Announcing Snowflake
- Instagram Engineering - Sharding & IDs at Instagram
- PlanetScale - The Problem with Using a UUID Primary Key in MySQL
- Percona - UUIDs are Popular, but Bad for Performance
- Buildkite - Goodbye to sequential integers, hello UUIDv7!
- RFC 9562 - UUID Version 7
- Discord - Snowflake IDs

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.