[트러블슈팅] Kafka 파티션 불균형으로 처리 지연

목차
한 줄 요약
userId 기반 파티셔닝 때문에 헤비 유저의 이벤트가 한 파티션에 몰리면서 Lag 편차가 10배까지 벌어졌습니다.
uploadId 기반으로 바꿔서 Lag 편차 1.2배, 처리 완료 시간 p99를 5분에서 1분으로 줄였습니다.
증상
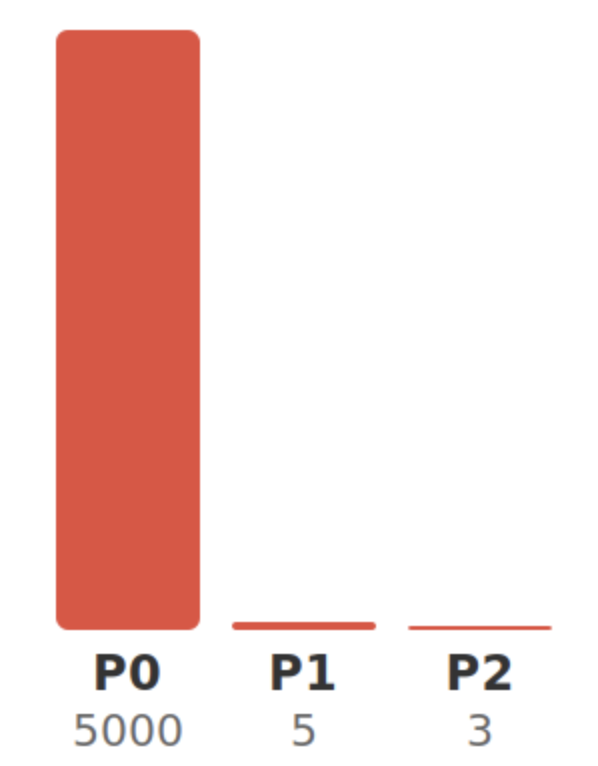
Kafka Exporter로 Consumer Lag을 파티션별로 확인하니, 특정 파티션에만 메시지가 몰려 있었습니다.
파티션 0의 Lag이 5000인데 파티션 1은 5, 파티션 2는 3이었습니다.
파티션 0에 붙은 Consumer만 바쁘게 돌고, 나머지 Consumer는 유휴 상태였습니다.
결과적으로 파티션 0에 걸린 사용자의 음성 분석이 5분 넘게 대기하는 반면, 다른 파티션에 걸린 사용자는 바로 처리됐습니다.
환경
- Apache Kafka 3.x (Docker 컨테이너)
- Spring Kafka
- 단일 서버 구성
원인: 파티션 키가 userId
기존에 userId를 파티션 키로 쓰고 있었습니다.
“같은 사용자의 이벤트는 순서대로 처리되어야 한다”는 생각이었습니다.
문제는 활동적인 사용자 한 명이 하루에 100건의 녹음을 올리면, 그 100건이 전부 같은 파티션에 들어간다는 것입니다.
비활동 사용자는 하루 3-5건이니, 파티션 간 부하 차이가 수십 배까지 벌어집니다.
대안 검토
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Round-robin (키 없음) | 완벽한 균등 분산 | 같은 파일의 이벤트가 다른 파티션으로 가서 순서 보장 불가 | 탈락 |
| userId 유지 + 파티션 수 증가 | 기존 코드 변경 없음 | 헤비 유저 문제는 파티션 수와 무관. 한 유저의 100건이 여전히 한 파티션에 집중 | 탈락 |
| uploadId 기반 파티셔닝 | UUID 해시라 균등 분산 + 같은 파일 내 순서 보장 | 같은 사용자의 서로 다른 업로드 간 순서는 미보장 (하지만 필요 없음) | 선택 |
| Custom Partitioner | 특정 로직 구현 가능 | uploadId 해시만으로 충분한데 커스텀은 과잉 | 탈락 |
해결: uploadId 기반 파티셔닝
생각해보니 “같은 사용자의 모든 업로드”가 순서를 보장할 필요는 없었습니다.
순서가 필요한 건 “같은 파일의 처리 단계” 뿐입니다.
UPLOADED → CONVERTING → COMPLETED가 순서대로 실행되면 되지, 사용자의 첫 번째 녹음과 두 번째 녹음 사이에 순서가 필요한 건 아닙니다.
uploadId를 파티션 키로 바꿨습니다.
업로드마다 UUID가 다르니 해시 분포가 고르게 퍼집니다.
같은 파일의 이벤트만 같은 파티션에 들어가면서 순서도 보장됩니다.
Consumer Group 구성
각 토픽별로 독립적인 Consumer Group을 구성했습니다.

토픽 구성
| 토픽 | 용도 | 파티션 키 |
|---|---|---|
| upload-events | 업로드 완료 이벤트 | uploadId |
| processing-status | 처리 상태 변경 | uploadId |
| processing-results | 처리 결과 | uploadId |
| voice-analysis-events | 음성 분석 요청 | uploadId |
| upload-events-retry | 재시도 대기 | uploadId |
| upload-events-dlq | 최종 실패 | uploadId |
모든 토픽에서 uploadId를 파티션 키로 통일했습니다.
결과
| 지표 | 개선 전 | 개선 후 |
|---|---|---|
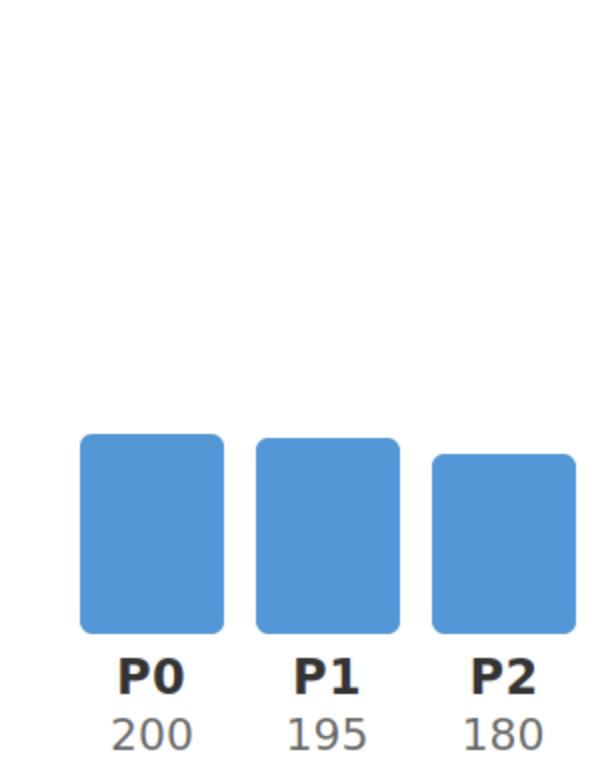
| 파티션별 처리량 편차 | 10배 | 1.2배 |
| 최대 Consumer Lag | 5000 | 200 |
| 처리 완료 시간 p99 | 5분 | 1분 |
| 유휴 Consumer 비율 | 66% | 0% |
Before
After
참고 자료
Summary
Resolved 10x partition lag variance caused by userId-based partitioning. Switching to uploadId-based partitioning reduced lag variance to 1.2x and p99 processing time from 5 minutes to 1 minute.
Symptoms
Kafka Exporter showed messages piling up on specific partitions. Partition 0 had a lag of 5000 while partitions 1 and 2 had 5 and 3 respectively. Only the Consumer on partition 0 was busy; the rest were idle.
Users whose events landed on partition 0 waited 5+ minutes for voice analysis, while others were processed immediately.
Environment
- Apache Kafka 3.x (Docker container)
- Spring Kafka
- Single-server setup
Cause: userId as Partition Key
userId was the partition key, based on the assumption that “same user’s events must be processed in order.”
The problem: one active user uploading 100 recordings per day sends all 100 to the same partition. Inactive users upload 3-5 per day, creating tens-of-times load difference between partitions.
Alternatives Considered
| Approach | Pros | Cons | Decision |
|---|---|---|---|
| Round-robin (no key) | Perfect even distribution | Same file’s events scatter across partitions, no ordering | Rejected |
| Keep userId + more partitions | No code changes | Heavy user problem is partition-count-independent. 100 events from one user still land on one partition | Rejected |
| uploadId-based partitioning | UUID hash distributes evenly + preserves per-file ordering | No cross-upload ordering for same user (but not needed) | Selected |
| Custom Partitioner | Flexible logic | uploadId hash is sufficient; custom is over-engineering | Rejected |
Solution: uploadId-based Partitioning
On reflection, ordering wasn’t needed across “all uploads from the same user.” Ordering was only needed for “processing stages of the same file.” UPLOADED → CONVERTING → COMPLETED must be sequential, but a user’s first and second recordings don’t need ordering.
Switching to uploadId as partition key distributes hashes evenly (each upload has a unique UUID). Events for the same file still land on the same partition, preserving ordering.
Consumer Group Configuration
Independent Consumer Groups per topic.
Topic Structure
| Topic | Purpose | Partition Key |
|---|---|---|
| upload-events | Upload completion events | uploadId |
| processing-status | Processing state changes | uploadId |
| processing-results | Processing results | uploadId |
| voice-analysis-events | Voice analysis requests | uploadId |
| upload-events-retry | Retry queue | uploadId |
| upload-events-dlq | Final failures | uploadId |
All topics unified on uploadId as partition key.
Results
| Metric | Before | After |
|---|---|---|
| Per-partition throughput variance | 10x | 1.2x |
| Max Consumer Lag | 5000 | 200 |
| Processing completion time p99 | 5min | 1min |
| Idle Consumer ratio | 66% | 0% |
Before
After
References

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.