Nori 형태소 분석기 Stop Filter 문제: "안녕" 0건과 "안녕하세" 노이즈 해결
Lucene Nori 분석기에서 "안녕" 검색이 0건이 되는 IC 필터링 문제와, "안녕하세" 검색 시 "하세" 관련 문서만 나오는 형태소 분석 한계를 분석합니다. IC 제거 + title_ngram dis_max + PrefixQuery 폴백 3단계 해결을 적용하고, 자동완성 title_raw fallback까지 포함합니다.
검색 결과가 없습니다
제목, 태그, 카테고리로 검색
Lucene Nori 분석기에서 "안녕" 검색이 0건이 되는 IC 필터링 문제와, "안녕하세" 검색 시 "하세" 관련 문서만 나오는 형태소 분석 한계를 분석합니다. IC 제거 + title_ngram dis_max + PrefixQuery 폴백 3단계 해결을 적용하고, 자동완성 title_raw fallback까지 포함합니다.

나무위키+한국어 위키백과+영어 위키백과+뉴스+웹텍스트+C4 한국어 코퍼스 1,215만 건 검색 엔진 프로젝트를 2개월간 26편의 기술 블로그로 기록하고 총정리합니다. MySQL LIKE 5,000ms 타임아웃에서 시작하여 임베디드 Lucene + Nori 한국어 형태소 분석으로 전환하고, Caffeine+Redis 2계층 캐시(82% 히트율), MySQL Replication R/W 분리, Nginx 스케일아웃(에러율 13.25%→0%), Debezium+Kafka CDC, Redis 3노드 Consistent Hashing까지 분산 아키텍처를 완성합니다. 검색 품질은 동의어 확장, 오타 교정, UnifiedHighlighter snippet, LTR(NDCG +4.8%p), 카테고리 28개 자동 분류, Aho-Corasick 금칙어 필터링으로 고도화하고, RAG(Gemini SSE 스트리밍)로 AI 검색 요약을 제공합니다. 자동완성 시스템 설계(CQRS + MapReduce + CDC)의 이론과 실제 구현의 매핑, 26편 전체 시리즈 링크, 핵심 수치 총정리를 포함합니다.
Lucene BM25 검색 결과 Top-5 문서를 LLM 컨텍스트에 주입하는 RAG(Retrieval-Augmented Generation) 파이프라인을 구축합니다. Spring AI 2.0 + Gemini 2.0 Flash로 SSE 스트리밍 답변을 생성하고, 인라인 출처 배지를 파싱하여 게시글 링크로 연결합니다. 할루시네이션 방지(문서 기반 답변 제한 + 인용 강제), AI 요약 트리거 조건(네비게이션 의도 스킵), Redis Token Bucket rate limiting(10 RPM 전역), 동일 쿼리 캐싱(TTL 30분, LLM 비용 40-60% 절감), Grafana 7패널 대시보드(RPM, 응답시간, 토큰, 피드백, 비용 추정)까지 포함합니다. BM25가 이 프로젝트에서 Dense Retrieval보다 적합한 근거와, Hybrid Retrieval 전환 로드맵도 정리합니다.
커뮤니티 검색 서비스의 운영 안전장치를 구축합니다. 16,090개 금칙어를 Aho-Corasick O(N+Z) 알고리즘으로 탐지하여 자동완성 결과에서 유해 검색어를 필터링하고, 블라인드 게시글을 Lucene Occur.MUST_NOT으로 검색에서 제외합니다. 영어 금칙어의 Scunthorpe 문제(단어 경계 매칭), Negative Caching(빈 결과 30초 TTL)으로 cache penetration 방지, title_raw StringField로 자동완성 Lucene fallback 품질을 개선합니다.
BM25 수동 가중치(title:3, content:1)의 한계를 Learning to Rank(LTR)로 극복합니다. 카테고리 28개 자동 분류(키워드 기반, 정확도 83%) → SortedSetDocValuesFacetCounts 네이티브 Facet 전환 → 태그 216만 건 인덱싱을 1회 재색인으로 통합 반영합니다. LLM-as-a-Judge(Gemini)로 학습 데이터 900쌍을 생성하고(1차 실패 98% → 5초 딜레이+지수 백오프로 해결), XGBoost LambdaMART 14개 피처로 학습하여 NDCG@10을 0.6910 → 0.7387(+4.8%p) 개선합니다. XGBoost4J ARM64 네이티브 추론, Rescorer Top-200 재랭킹, RefreshListener 기반 FacetState 캐싱, MultiCollectorManager 단일 패스 수집까지 구현하지만, 2코어 ARM Free Tier에서 LTR ON 시 CPU 포화(72배 악화)를 k6로 실측하여 LTR_ENABLED=false로 비활성화합니다.
Lucene 기반 검색 엔진의 Recall과 Precision을 동시에 개선합니다. 동의어 확장(DB 기반 쿼리 타임)으로 "AI" 검색 시 "인공지능" 문서를 포함시키고, DirectSpellChecker로 "프로그래링" → "프로그래밍" 오타 교정을 구현합니다. UnifiedHighlighter + snippetSource 500자 StoredField로 검색어 주변 맥락 snippet을 제공하고, 무중단 전체 재색인 인프라(Directory Swap + SearcherManager 재생성)를 구축하여 12,156,589건(42GB)을 ~2시간 만에 재색인합니다. 인덱스 타임 동의어가 IDF를 왜곡하는 원리, Nori 사용자 사전 158,539개 적용, BM25 변형(BM25+/L/F) 불필요 판단 근거까지 정리합니다.
1,425만 건 Lucene 검색 엔진에 카테고리 필터링을 추가합니다. categoryId가 이미 LongField로 인덱싱되어 있지만 검색 쿼리(buildQuery)에서 사용하지 않고 있던 구조적 비대칭을 발견하고, Occur.FILTER 절로 해결합니다. DB Post-filter 방식이 pagination을 깨뜨리는 이유, FILTER가 MUST와 달리 스코어에 기여하지 않으면서 bitset 캐싱 대상이 되는 원리, DB GROUP BY 간이 Facet의 한계와 Lucene 네이티브 Facet 전환 계획까지 정리합니다.

MySQL FULLTEXT ngram의 구조적 한계(고빈도 토큰 타임아웃, 300GB+ 인덱스, false positive)를 분석하고, Lucene·Elasticsearch·벡터DB를 비용 관점에서 비교하여 임베디드 Lucene + Nori 형태소 분석기를 선택한 기술 결정 과정을 정리합니다.
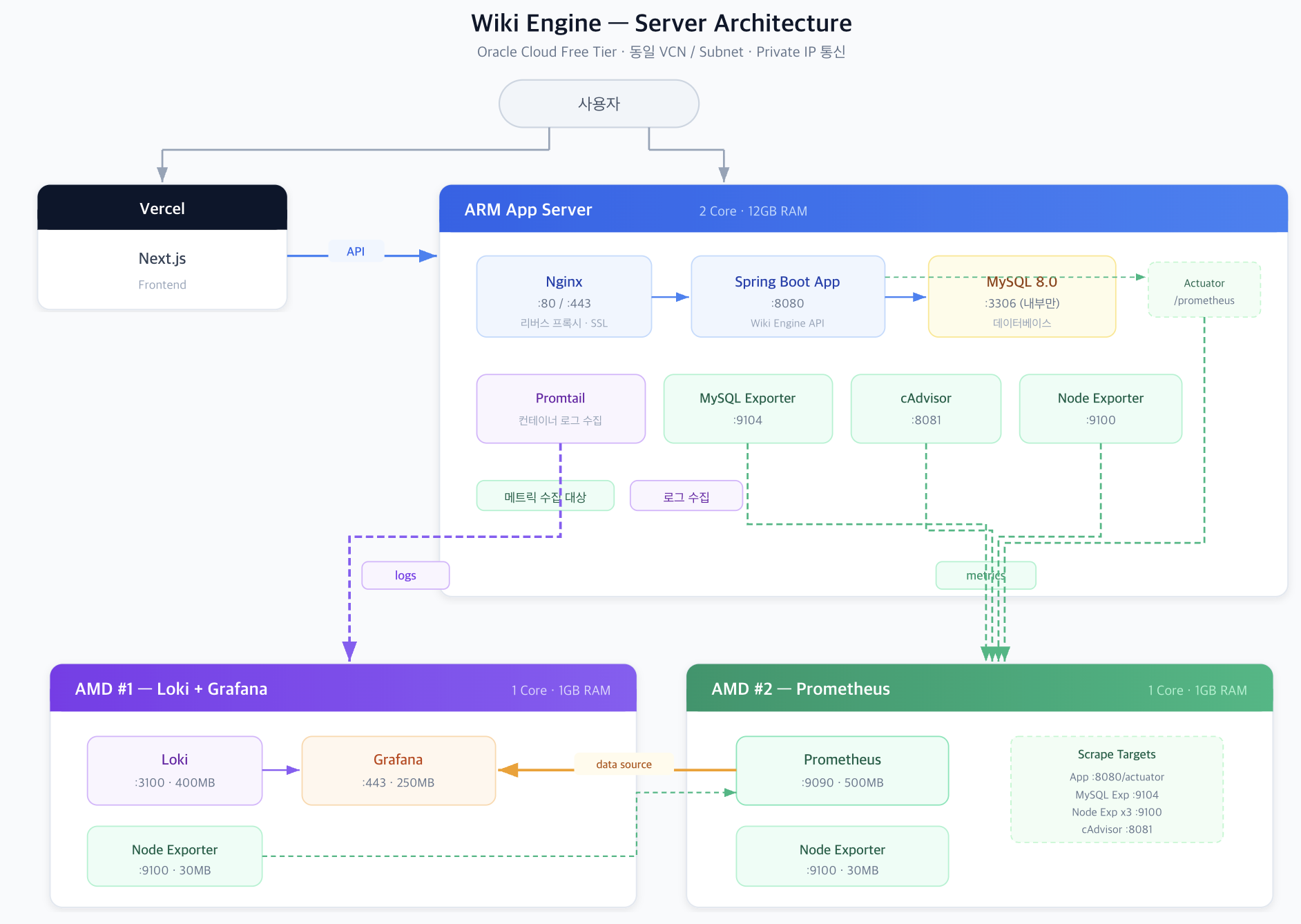
나무위키, 위키피디아 덤프 데이터를 MySQL에 적재하고, 커뮤니티 수준의 트래픽을 감당할 수 있는 검색엔진을 만드는 프로젝트의 개요와 서버 구성을 정리한다.