콘텐츠 필터링: Aho-Corasick 금칙어 탐지와 운영 안전장치
목차
이전 글
LTR 재랭킹 + 카테고리 자동 분류에서 XGBoost LambdaMART로 NDCG@10을 +4.8%p 개선하고, 카테고리 28개 자동 분류 + Lucene 네이티브 Facet + 태그 216만 건 인덱싱을 완료했습니다.
| 지표 | 결과 |
|---|---|
| NDCG@10 | 0.6910 → 0.7387 (+4.8%p, 5-Fold CV) |
| 카테고리 분류 | 28개 주제별, 정확도 ~83% |
| Facet | SortedSetDocValuesFacetCounts 네이티브 전환 |
| LTR 프로덕션 | CPU 포화로 비활성화 (LTR_ENABLED=false) |
검색 기능(품질, 랭킹, 인프라)이 고도화되었지만, 커뮤니티 서비스 운영에 필수적인 콘텐츠 안전장치가 없습니다.
1. 정상 상태: 현재 콘텐츠 관리 현황
현재 wikiEngine은 위키피디아 데이터 기반이므로, 콘텐츠 품질이 높고 유해 콘텐츠가 거의 없습니다. 하지만 사용자 게시글 작성이 가능해지면 다음 문제가 발생합니다:
유해 콘텐츠 유형: 1. 금칙어 포함 게시글 (욕설, 혐오 표현) 2. 스팸 게시글 (광고, 도배) 3. 저품질 콘텐츠 (의미 없는 내용, 낚시 제목) 4. 개인정보 노출 (전화번호, 주소 등)현재 이에 대한 필터링/모니터링/신고 시스템이 전혀 없다.
2. 문제 상황: 왜 지금 콘텐츠 필터링이 필요한가
구조적 문제
- 게시글 작성 API가 이미 열려 있다.
POST /api/v1.0/posts로 누구나(인증된 사용자) 게시글을 작성할 수 있다 - k6 부하 테스트에서 게시글을 대량 생성한다. 제목과 본문에 아무 문자열이나 들어간다
- 자동완성이 검색 로그 기반이다. 유해 검색어가 자동완성에 그대로 노출될 수 있다
curl -X POST /api/v1.0/posts -d '{"title":"금칙어 포함 제목","content":"..."}'를 보내면 아무 검증 없이 DB에 저장되고 Lucene 인덱스에 포함됩니다.
커뮤니티 서비스의 표준 안전장치
| 문제 | 영향 | 사례 |
|---|---|---|
| 금칙어 미차단 | 커뮤니티 분위기 악화, 사용자 이탈 | 대부분의 커뮤니티 서비스에서 기본 제공 |
| 스팸 미차단 | 검색 결과 오염, 사용자 경험 저하 | Stack Overflow, Reddit 등 모두 스팸 필터 운영 |
| 신고 시스템 부재 | 유해 콘텐츠 자정 기능 없음 | 카카오, 네이버 모두 신고/블라인드 시스템 운영 |
| 자동완성 오염 | 유해 검색어가 자동완성에 노출 | 구글/네이버 자동완성 필터링 |
3. 문제 분석: Aho-Corasick 선택 근거
금칙어 탐지 알고리즘 비교:
| 방식 | 시간 복잡도 | 구현 | 판단 |
|---|---|---|---|
String.contains() 루프 | O(N×M) (N=텍스트, M=금칙어 수) | 단순 | 금칙어 1,000개면 느려짐 |
| Aho-Corasick | O(N+Z) (Z=매칭 수, M에 무관) | robert-bor/aho-corasick 라이브러리 사용 | 선택 |
| 정규식 합성 | O(N) | 금칙어 변경 시 재컴파일 | 대안 |
Aho-Corasick은 Trie 자료구조에 failure link를 추가하여, 텍스트를 한 번만 순회하면서 모든 패턴을 동시에 매칭합니다. 금칙어가 16,090개여도 텍스트 길이에만 비례하는 시간이 소요됩니다.
4. 구현
4-1. 금칙어 필터링
두 가지 시점에 적용: 1. 쓰기 시점: 게시글 작성/수정 시 금칙어 포함 여부 검사 2. 검색 시점: 자동완성 결과에서 금칙어 포함 제안 필터링@Servicepublic class ContentFilterService {
/** * Aho-Corasick automaton 2개를 Caffeine 캐시(TTL 10분)로 보관. * - koreanTrie: 부분 일치 — "금칙" → "금칙어" 차단 (합성어 커버) * - englishTrie: 단어 경계 매칭 — "ass" → "assassination" 허용 (Scunthorpe 방지) * * 라이브러리: org.ahocorasick:ahocorasick:0.6.3 (robert-bor) */ private record BannedAutomata(Trie koreanTrie, Trie englishTrie) {}
/** * Aho-Corasick으로 텍스트 내 금칙어를 O(N+Z) 시간에 탐지한다. * N = 텍스트 길이, Z = 매칭 수. 금칙어 수(M)에 무관하게 선형 시간. * * 현재 금칙어 한국어 3,094개 + 영어 12,996개 = 16,090개. */ private boolean isBanned(String text, BannedAutomata automata) { String lower = text.toLowerCase(); if (!automata.koreanTrie().parseText(lower).isEmpty()) return true; return !automata.englishTrie().parseText(lower).isEmpty(); }
public List<String> filterSuggestions(List<String> suggestions) { BannedAutomata automata = getAutomata(); return suggestions.stream() .filter(s -> !isBanned(s, automata)) .toList(); }}영어 Trie의 단어 경계 매칭(Scunthorpe 문제): “ass”를 금칙어로 등록하면 “assassination”, “class”, “Scunthorpe” 같은 정상 단어까지 차단됩니다. 영어 금칙어는 단어 경계(\b)로 매칭하여 이 문제를 방지합니다. 한국어는 교착어 특성상 부분 일치가 더 적합하다 (“금칙” → “금칙어”, “금칙어목록” 등을 모두 잡아야 함).
금칙어 사전
CREATE TABLE banned_words ( id BIGINT AUTO_INCREMENT PRIMARY KEY, word VARCHAR(100) NOT NULL UNIQUE, category ENUM('PROFANITY', 'HATE_SPEECH', 'SPAM', 'ADULT', 'PERSONAL_INFO') NOT NULL, severity ENUM('LOW', 'MEDIUM', 'HIGH') NOT NULL DEFAULT 'MEDIUM', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, INDEX idx_category (category));- 초기 데이터: 3,094개 한국어 금칙어(LDNOOBWV2/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words_V2
data/ko.txt) - 금칙어 변경 시 Caffeine 캐시 갱신 (TTL 10분) → Aho-Corasick automaton 재빌드
4-2. 블라인드 게시글: Lucene 인덱스 연동
// 블라인드된 게시글은 검색에서 제외// 방법 1: Lucene 인덱스에서 삭제 (CDC 이벤트로 자동)// 방법 2: 검색 시 필터 추가 (Occur.MUST_NOT)
// 방법 2 선택 — 복원 가능하도록Query blindFilter = new TermQuery(new Term("status", "BLIND"));builder.add(blindFilter, BooleanClause.Occur.MUST_NOT);신고 처리 흐름: 1. 사용자가 게시글 신고 (POST /api/v1.0/posts/{id}/report) 2. 신고 누적 N건 이상 → 자동 블라인드 (검색 결과에서 제외) 3. 관리자 리뷰 → 승인(삭제) 또는 반려(복원)재색인 불필요: 기존 인덱스에 blinded 필드 없음 → MUST_NOT 매칭 없음 → 전체 통과 (정상). 블라인드 처리 시 CDC 이벤트 → 해당 문서만 재인덱싱 → 검색 제외 반영.
4-3. 자동완성 안전장치
자동완성 구현에서 구현한 검색 로그 기반 자동완성에 금칙어 필터를 적용합니다.
현재 자동완성 흐름: 사용자 입력 → Redis flat KV 조회 → Top-10 반환
필터 추가: 사용자 입력 → Redis flat KV 조회 → 금칙어 필터링 → Top-10 반환금칙어 필터는 Redis 조회 후 앱 레벨에서 수행합니다. Redis에 금칙어를 저장하지 않고, Caffeine 캐시에 올린 금칙어 Set으로 필터링합니다. 이유: Redis KV 재빌드 주기(1시간)와 금칙어 업데이트가 독립적이어야 하므로.
4-4. 자동완성 Lucene fallback 품질 개선
문제: Lucene fallback에서 PrefixQuery가 Nori-analyzed title 필드를 사용. 형태소 분석된 토큰으로 prefix 매칭하면 의도와 무관한 결과가 반환된다.
원인: 자동완성은 형태소 분석 없이 원본 prefix로 매칭해야 하는데, 검색용 Nori-analyzed 필드를 공유하고 있었음.
해결: title_raw StringField (untokenized, lowercased) 추가 + PrefixQuery 대상 변경. 한국어 “금칙” → “금칙어”, 영어 “prog” → “programming”.
아키텍처 정리:
- Redis (메인): 검색 로그 기반 인기 검색어 제안(CQRS 읽기 경로, O(1))
- Lucene (fallback): Redis 미스 시 문서 제목 기반 보조 제안
- 단일 단어 (“자바”) →
title_rawPrefixQuery (untokenized)- 띄어쓰기 포함 (“자바 가비지”) → BM25
title검색 (Nori 분석)- 자동완성 ≠ 형태소 분석 (현업 표준: 네이버/구글/ES 모두 별도 untokenized 필드 사용)
4-5. Negative Caching: 빈 결과 짧은 TTL
문제: 앱 기동 직후 인덱스 로딩 전에 검색 → 0건 캐시 → 5~10분간 0건 유지.
해결: TieredCacheService에서 빈 결과는 30초 TTL, 정상 결과는 기존 10분 유지.
30초 TTL 선정 근거: 앱 기동 시 Lucene SearcherManager 초기화(인덱스 로딩)가 수 초~수십 초 소요됩니다. 이보다 짧은 30초로 설정하면, 인덱스 로딩 완료 후 캐시가 만료되어 다음 요청에서 정상 결과를 자동 갱신합니다. RFC 2308(DNS Negative Caching)은 60~300초를 권장하지만, 이는 DNS 전파 지연이 전제된 수치이며 앱 레벨 캐시에서는 더 짧은 TTL이 적절하다. AWS CloudFront도 negative TTL 기본값이 5초로 짧게 설정되어 있습니다. 빈 결과를 아예 캐시하지 않으면 cache penetration(동일 쿼리가 매번 origin까지 관통)이 발생하므로, 짧은 TTL로 캐시하되 빠르게 만료시키는 것이 ByteByteGo의 Cache Miss Attack 패턴에서도 권장하는 방식이다.
5. 검증: Before/After
금칙어 자동완성 필터링
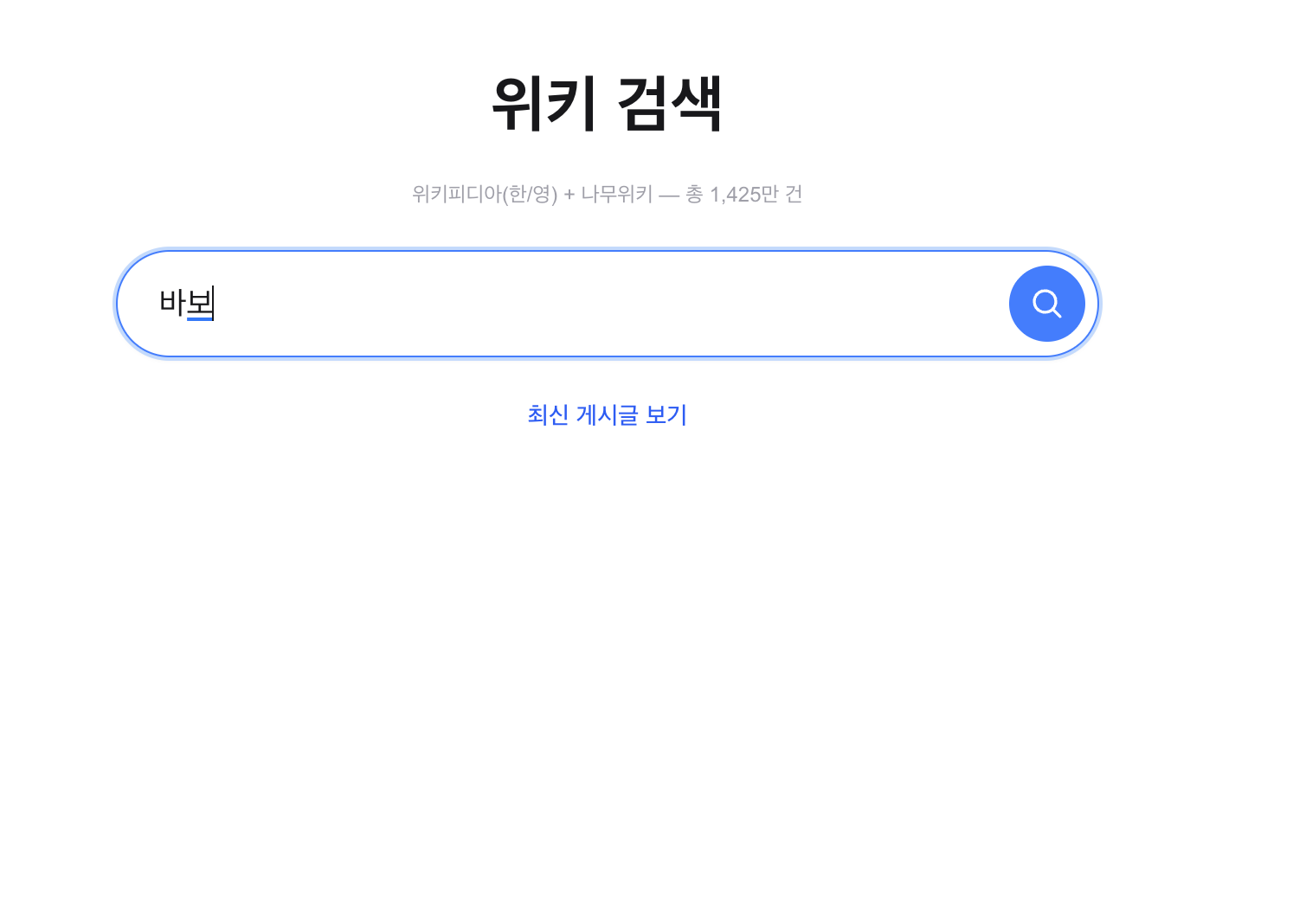
“바보” 입력 시 자동완성 제안 없음:
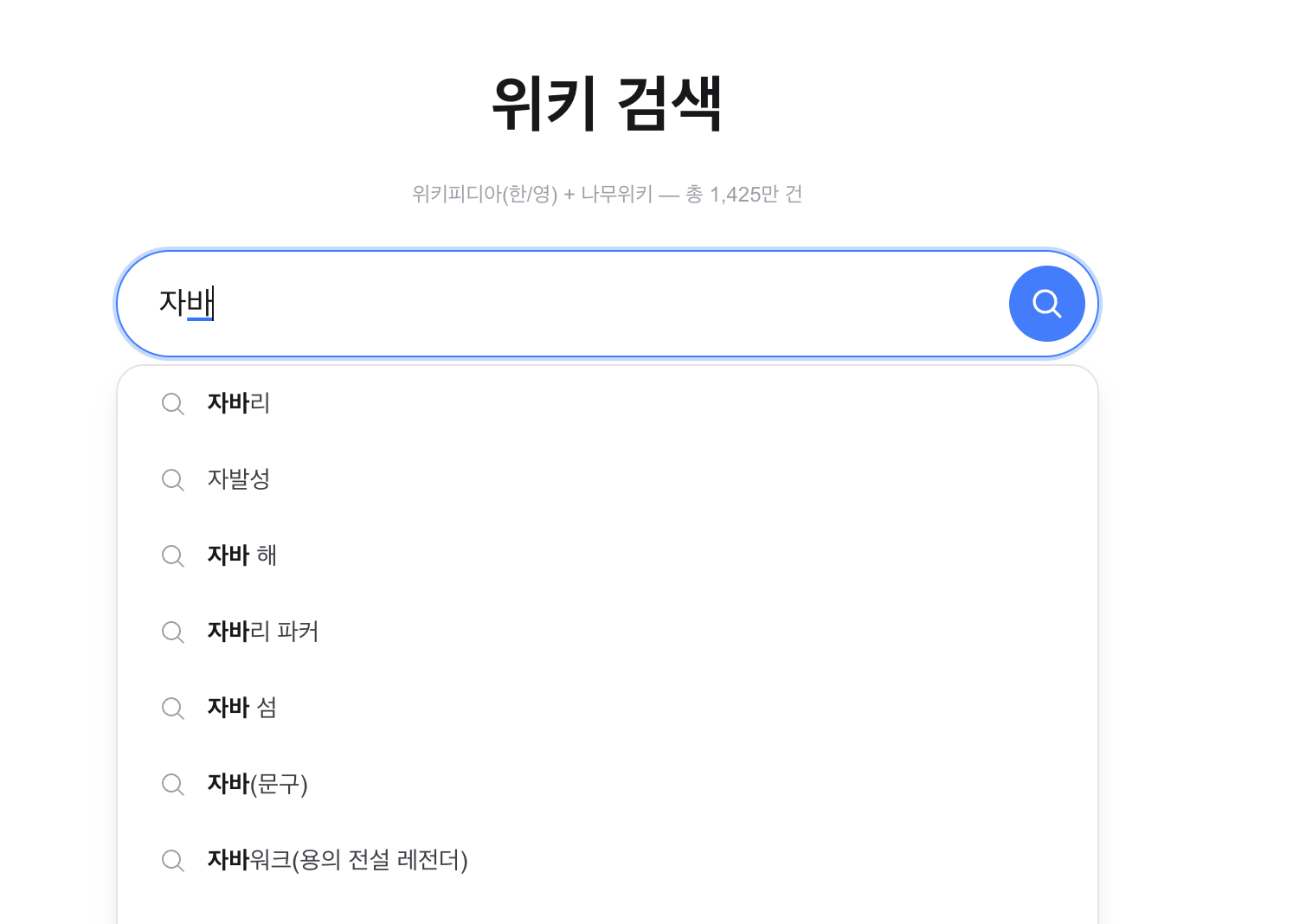
“자바” 입력 시 정상 자동완성:
“바보”는
banned_words_ko.txt(3,094개)에 포함된 금칙어. Aho-CorasickTrie.parseText()로 O(N+Z) 탐지 →ContentFilterService.filterSuggestions()에서 제거.
블라인드 게시글 검색 제외
Before: id=619166 게시글이 검색 결과에 포함

After: id=619166 게시글이 검색 결과에서 제외됨
POST /admin/lucene/reindex?ids=619166으로 Lucene 인덱스에blinded=true반영 후,Occur.MUST_NOT TermQuery("blinded","true")에 의해 검색 결과에서 자동 제외. 블라인드 해제 시blinded=false로 재인덱싱하면 검색에 복원됩니다.
다음 글
AI 검색 요약: RAG에서 Lucene BM25 검색 결과를 LLM 컨텍스트에 주입하여 AI 요약 답변을 생성하고, SSE 스트리밍, 출처 인용, 할루시네이션 방지, 비용 모니터링까지 구현합니다.
출처
- robert-bor/aho-corasick — Java Aho-Corasick 라이브러리
- LDNOOBWV2 — List of Dirty, Naughty, Obscene, and Otherwise Bad Words V2
- RFC 2308 — Negative Caching of DNS Queries
- ByteByteGo — Cache Miss Attack
Previous
In LTR Re-ranking + Auto-Categorization we improved NDCG@10 by +4.8%p with XGBoost LambdaMART, finished 28-topic auto-categorization + native Lucene Facet + indexing 2.16M tags.
| Metric | Result |
|---|---|
| NDCG@10 | 0.6910 → 0.7387 (+4.8%p, 5-Fold CV) |
| Categorization | 28 topics, ~83% accuracy |
| Facet | switched to native SortedSetDocValuesFacetCounts |
| LTR in production | disabled (LTR_ENABLED=false) due to CPU saturation |
Search functionality (quality, ranking, infra) is now solid, but the content-safety mechanisms that any community service needs are still missing.
1. Steady State — Current Content Management
WikiEngine is on top of Wikipedia data, so content quality is high and there is barely any harmful content. But the moment user-authored posts come into play, you get:
Harmful-content categories: 1. Posts containing banned words (profanity, hate speech) 2. Spam (ads, flooding) 3. Low-quality content (meaningless, clickbait) 4. Personal-info exposure (phone numbers, addresses, etc.)Right now there is no filtering / monitoring / reporting system at all.
2. The Problem — Why Content Filtering, Now
Structural issues
- The post-creation API is already open —
POST /api/v1.0/postslets any authenticated user create a post. - k6 load tests create posts in bulk — title/body get arbitrary strings.
- Autocomplete is built on search logs — harmful queries can leak straight into autocomplete.
curl -X POST /api/v1.0/posts -d '{"title":"banned-word title","content":"..."}' is currently stored in the DB and indexed into Lucene with zero validation.
Standard safety mechanisms in community services
| Issue | Impact | Industry baseline |
|---|---|---|
| No banned-word block | Toxic environment, user churn | Default in most community services |
| No spam block | Polluted search results, degraded UX | Stack Overflow, Reddit, etc. all run spam filters |
| No reporting | No self-cleaning mechanism | Kakao, Naver all run report/blind systems |
| Polluted autocomplete | Harmful queries leak into autocomplete | Google/Naver filter autocomplete |
3. Analysis — Why Aho-Corasick
Banned-word detection options:
| Approach | Time complexity | Implementation | Verdict |
|---|---|---|---|
String.contains() loop | O(N×M) (N=text, M=word count) | trivial | slow with 1,000+ words |
| Aho-Corasick | O(N+Z) (Z=match count, independent of M) | use robert-bor/aho-corasick | chosen |
| Compiled regex union | O(N) | recompile on word changes | alternative |
Aho-Corasick adds failure links to a Trie, scans the text once, and matches all patterns simultaneously. Even with 16,090 banned words, time only scales with text length.
4. Implementation
4-1. Banned-word filtering
Two enforcement points: 1. Write-time: check posts on create/update for banned words 2. Search-time: filter banned words from autocomplete suggestions@Servicepublic class ContentFilterService {
/** * Two Aho-Corasick automata kept in a Caffeine cache (10-min TTL). * - koreanTrie: substring match — "금칙" matches "금칙어" (covers compounds) * - englishTrie: word-boundary match — "ass" does NOT match "assassination" (Scunthorpe-safe) * * Library: org.ahocorasick:ahocorasick:0.6.3 (robert-bor) */ private record BannedAutomata(Trie koreanTrie, Trie englishTrie) {}
/** * Detect banned words in O(N+Z) using Aho-Corasick. * N = text length, Z = matches. Linear regardless of M (word count). * * Currently 3,094 KO + 12,996 EN = 16,090 banned words. */ private boolean isBanned(String text, BannedAutomata automata) { String lower = text.toLowerCase(); if (!automata.koreanTrie().parseText(lower).isEmpty()) return true; return !automata.englishTrie().parseText(lower).isEmpty(); }
public List<String> filterSuggestions(List<String> suggestions) { BannedAutomata automata = getAutomata(); return suggestions.stream() .filter(s -> !isBanned(s, automata)) .toList(); }}English Trie uses word-boundary matching — the Scunthorpe problem: registering “ass” as a banned word would also block legitimate words like “assassination”, “class”, “Scunthorpe”. For English we match on word boundary (\b) to avoid that. Korean is agglutinative, so substring match fits better — “금칙” needs to also catch “금칙어”, “금칙어목록”, etc.
Banned-word dictionary
CREATE TABLE banned_words ( id BIGINT AUTO_INCREMENT PRIMARY KEY, word VARCHAR(100) NOT NULL UNIQUE, category ENUM('PROFANITY', 'HATE_SPEECH', 'SPAM', 'ADULT', 'PERSONAL_INFO') NOT NULL, severity ENUM('LOW', 'MEDIUM', 'HIGH') NOT NULL DEFAULT 'MEDIUM', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, INDEX idx_category (category));- Initial data: 3,094 Korean banned words — LDNOOBWV2/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words_V2
data/ko.txt - On any change to the dictionary → invalidate the Caffeine cache (10-min TTL) → rebuild the Aho-Corasick automaton.
4-2. Blinded posts — wired into the Lucene index
// Blinded posts are excluded from search.// Option 1: delete from the Lucene index (auto via CDC events)// Option 2: add a filter at search time (Occur.MUST_NOT)
// Picked option 2 — keeps it reversible.Query blindFilter = new TermQuery(new Term("status", "BLIND"));builder.add(blindFilter, BooleanClause.Occur.MUST_NOT);Report-handling flow: 1. User reports a post (POST /api/v1.0/posts/{id}/report) 2. After N reports → auto-blind (excluded from search) 3. Admin review → approve (delete) or reject (restore)No reindex needed: existing index has no blinded field → no MUST_NOT matches → everything passes (correct). When something is blinded, a CDC event → reindex just that doc → exclusion takes effect.
4-3. Autocomplete safety
We apply the banned-word filter to the search-log-based autocomplete from Autocomplete Implementation.
Current autocomplete flow: user input → Redis flat KV lookup → top-10 returned
After filter: user input → Redis flat KV lookup → banned-word filter → top-10 returnedThe banned-word filter runs in-app after the Redis lookup. We do not store banned words in Redis; we filter against a banned-word Set held in a Caffeine cache. Reason: the Redis KV rebuild cycle (1 hr) and the banned-word update cadence must stay independent.
4-4. Improving Lucene autocomplete fallback quality
Problem: in the Lucene fallback, PrefixQuery was hitting the Nori-analyzed title field. Doing prefix match on morphologically tokenized terms returned results that did not match user intent.
Cause: autocomplete must match on the raw prefix (no morphological analysis), but it was sharing the search-side Nori-analyzed field.
Fix: added title_raw StringField (untokenized, lowercased) and switched PrefixQuery to it. Korean “금칙” → “금칙어”, English “prog” → “programming”.
Architecture summary:
- Redis (main): popular-query suggestions from search logs — the CQRS read path, O(1)
- Lucene (fallback): on Redis miss, doc-title-based supplementary suggestions
- single token (“자바”) →
title_rawPrefixQuery (untokenized)- contains whitespace (“자바 가비지”) → BM25 search on
title(Nori-analyzed)- Autocomplete ≠ morphological analysis (industry standard: Naver/Google/ES all use a separate untokenized field)
4-5. Negative caching — short TTL for empty results
Problem: searching right after app boot — before the index is fully loaded — caches a 0-result response and keeps returning 0 results for 5-10 minutes.
Fix: in TieredCacheService, empty results get a 30-second TTL while normal results keep the existing 10-minute TTL.
Why 30s: Lucene SearcherManager initialization (loading the index) takes seconds to tens of seconds at boot. Setting TTL shorter than that means once index loading completes, the cache expires and the next request automatically refreshes with real results. RFC 2308 (DNS Negative Caching) recommends 60-300s, but that assumes DNS propagation delay; for app-level caches a shorter TTL is more appropriate. AWS CloudFront also defaults negative TTL to a short 5 seconds. Not caching empty results at all causes cache penetration (every same query goes through to origin), so caching with a short TTL but expiring fast is exactly the pattern recommended in ByteByteGo’s Cache Miss Attack pattern.
5. Verification — Before/After
Banned-word filtering in autocomplete
Typing “바보” — no suggestions:
Typing “자바” — normal autocomplete:
“바보” is in
banned_words_ko.txt(3,094 entries). Detected in O(N+Z) by Aho-CorasickTrie.parseText()and removed byContentFilterService.filterSuggestions().
Excluding blinded posts from search
Before — post id=619166 is in the result set:
After — post id=619166 is excluded:
POST /admin/lucene/reindex?ids=619166updates the Lucene index withblinded=true, after whichOccur.MUST_NOT TermQuery("blinded","true")automatically excludes it. To unblind, reindex withblinded=falseand it comes back.
Next
In AI Search Summary — RAG we feed Lucene BM25 search results into LLM context to generate AI summaries, and implement SSE streaming, source citations, hallucination prevention, and cost monitoring.
Sources

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.