Trie 기반 자동완성: 사전순 → 인기순, 한글 자모 검색
목차
이전 글
캐싱 전략에서 Caffeine L1 로컬 캐시를 도입하여 자동완성 응답시간을 368ms → 4.67ms(78.8x)로 개선하고, 캐시 히트율 99.9%를 달성했습니다.
이전 글 요약
Caffeine 캐시 덕분에 자동완성은 대부분 0.1ms에 반환됩니다. 하지만 반환 순서가 사전순이라는 근본적인 문제가 남아있었습니다.
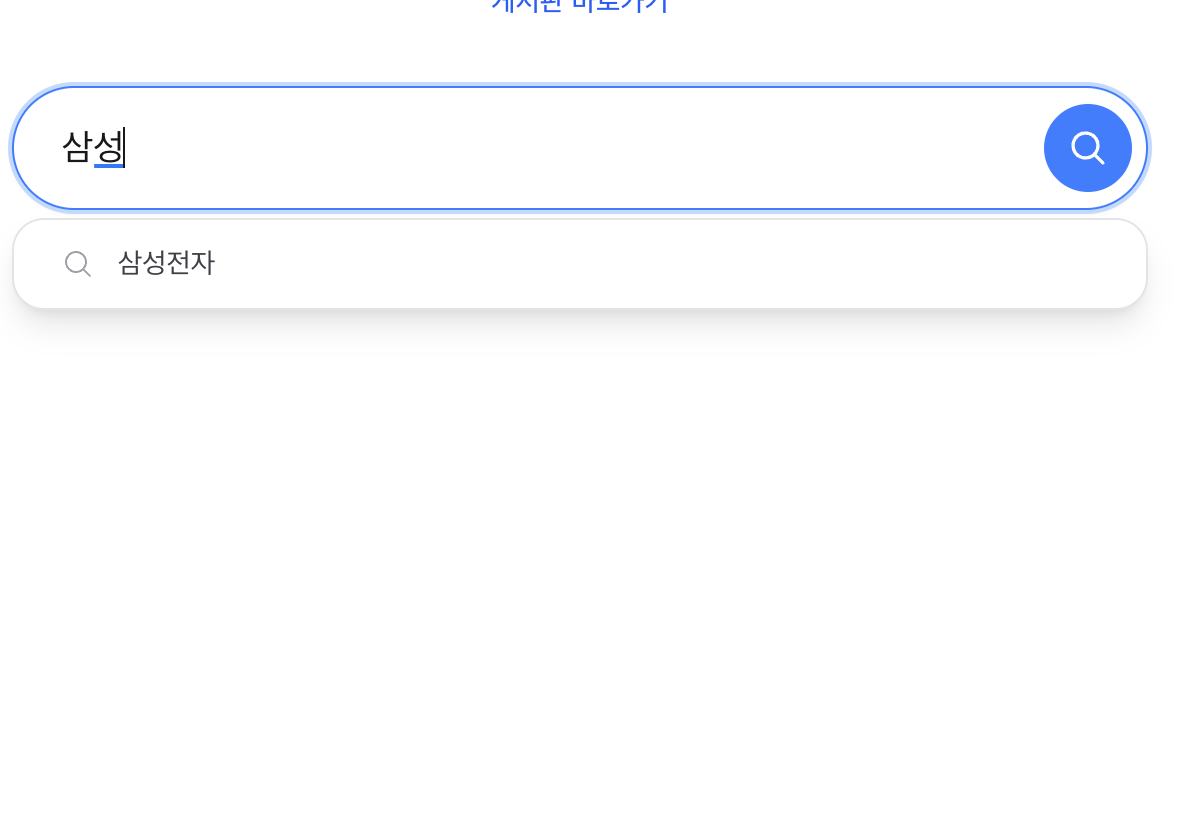
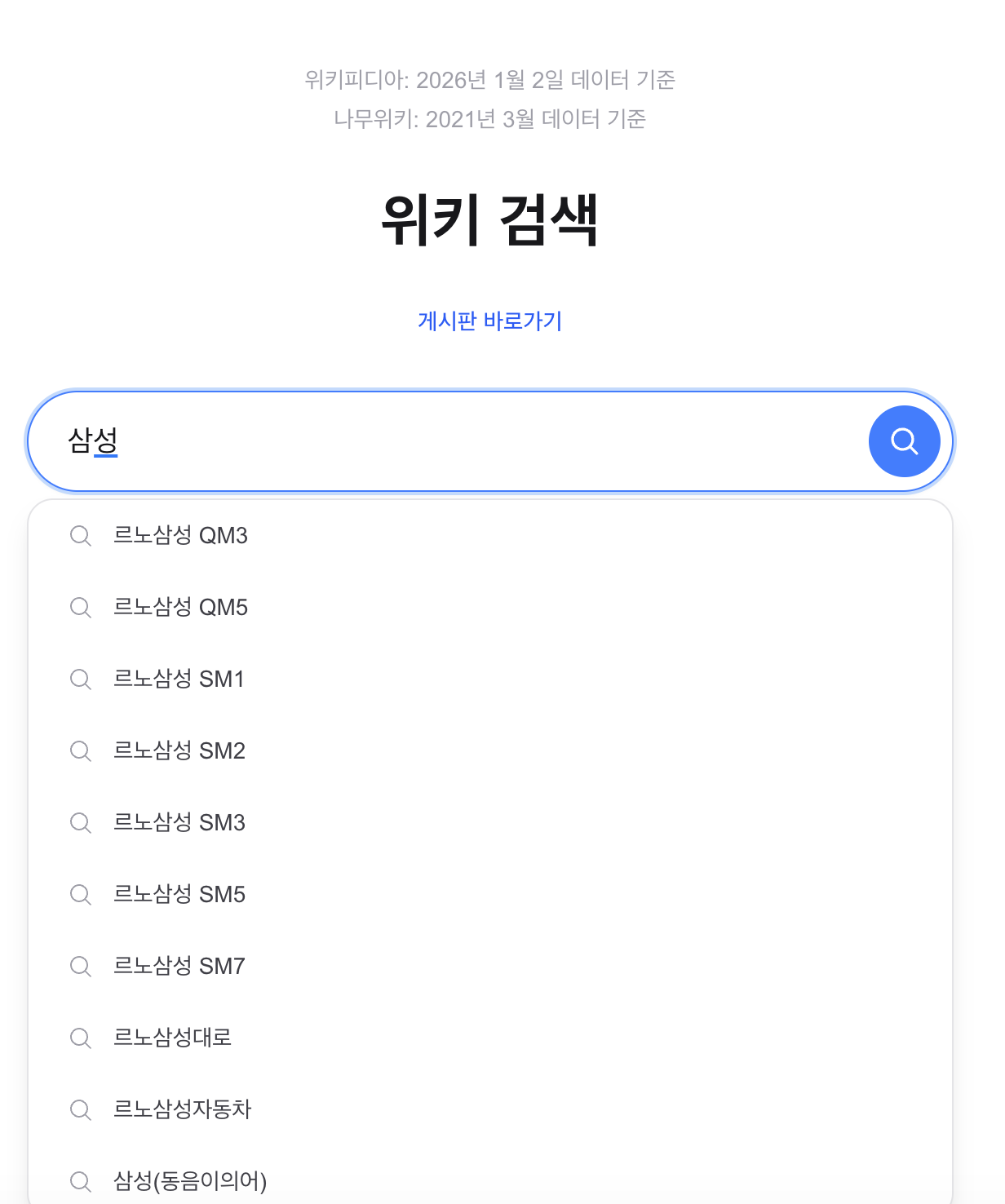
1. 문제: “삼성”을 입력하면 “르노삼성 QM3”이 먼저 나온다
Lucene PrefixQuery는 term dictionary를 사전순(lexicographic order)으로 순회합니다. “삼성”으로 시작하는 제목 중 “ㄹ(르노삼성)“이 “ㅅ(삼성전자)“보다 유니코드 순서가 앞이므로, 사용자가 원하는 “삼성전자”가 아닌 “르노삼성 QM3”이 먼저 표시됩니다.
PrefixQuery에 score를 부여하려면 전체 매칭 결과를 가져온 뒤 별도 정렬이 필요하여, prefix 검색의 O(m) 이점이 사라집니다.
추가로 한글 중간 입력(“삼ㅅ”)에서 자동완성이 끊기는 문제도 있었습니다. 한글은 자모 단위로 입력되는데, PrefixQuery는 완성된 음절만 매칭합니다.
2. 해결 전략: 검색 로그 + 인메모리 Trie + 자모 분해
세 가지를 조합하여 해결했습니다:
- 검색 로그 수집: 사용자가 실제로 검색하는 쿼리를 기록하여 인기도 데이터 확보
- 인메모리 Trie: 검색 로그의 인기 검색어를 Trie에 적재하여 검색 빈도순 반환
- 한글 자모 분해: 음절 → 초성/중성/종성 분해로 중간 입력 + 초성 검색 지원
3. 검색 로그 수집: 시간 버킷 집계
왜 검색 로그가 필요한가
인기순 정렬을 하려면 “어떤 검색어가 얼마나 자주 검색되는지” 데이터가 필요합니다. 위키 덤프 데이터는 viewCount가 전부 0이므로, 검색 로그가 유일한 인기도 신호입니다.
왜 MySQL 테이블인가 (S3가 아닌 이유)
Google/Naver 규모(일일 수십억 QPS)에서는 검색 로그를 S3에 파일로 저장하고 Spark로 배치 처리합니다. DB에 수십억 건을 INSERT하면 DB가 감당할 수 없기 때문입니다.
wikiEngine은 단일 서버(ARM 2코어, 12GB RAM)이므로 S3/Kafka 인프라가 불필요합니다. MySQL 테이블에 직접 저장합니다.
시간 버킷 설계
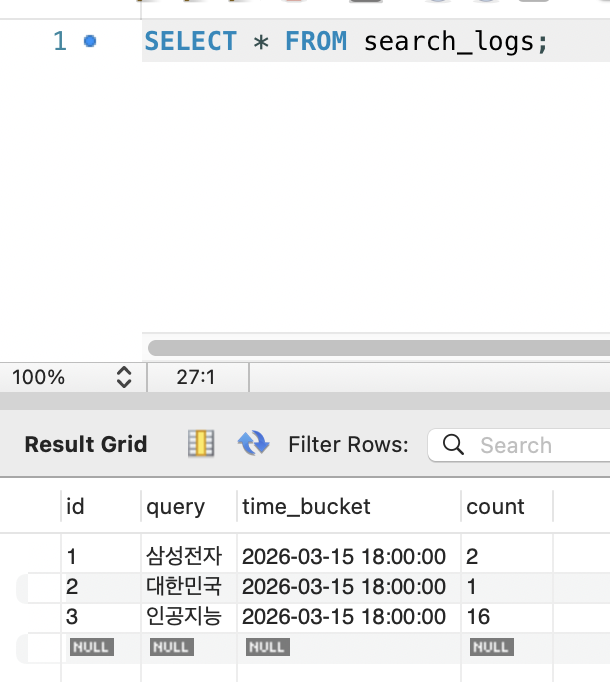
누적 카운트(query, total_count)가 아닌 시간 버킷(query, time_bucket, count) 구조를 사용합니다.
CREATE TABLE search_logs ( id BIGINT AUTO_INCREMENT PRIMARY KEY, query VARCHAR(200) NOT NULL, time_bucket DATETIME NOT NULL, count BIGINT NOT NULL DEFAULT 1, UNIQUE INDEX uk_search_logs_query_bucket (query, time_bucket));누적 카운트는 “10000회가 6개월 전인지 오늘인지” 구분할 수 없어 시간 감쇠 점수 계산이 불가능합니다. 시간 버킷이면 WHERE time_bucket >= NOW() - INTERVAL 7 DAY로 윈도우별 집계가 가능합니다.
SearchLogCollector: volatile swap flush
매 요청마다 DB INSERT하면 쓰기 부하가 문제됩니다. ConcurrentHashMap에 인메모리 집계 후 5분마다 batch upsert합니다.
@Scheduled(fixedDelay = 300_000)@Transactionalpublic void flush() { ConcurrentHashMap<String, LongAdder> snapshot = buffer; buffer = new ConcurrentHashMap<>(); // volatile swap
LocalDateTime timeBucket = LocalDateTime.now().truncatedTo(ChronoUnit.HOURS); for (var entry : snapshot.entrySet()) { searchLogRepository.upsert(entry.getKey(), timeBucket, entry.getValue().sum()); }}snapshot + clear() 패턴이 아닌 volatile 참조 교체를 사용합니다. clear() 패턴은 snapshot 생성과 clear 사이에 record()가 호출되면 데이터가 영원히 유실됩니다. 참조 교체 방식은 교체 이후의 record()가 새 버퍼에 기록되고, 구 버퍼는 flush 전용이 되어 유실이 없습니다.
fixedRate가 아닌 fixedDelay를 사용합니다. fixedRate는 이전 flush가 끝나지 않아도 다음 스케줄이 대기열에 들어가서, 동시 ON DUPLICATE KEY UPDATE → 데드락 가능. fixedDelay는 이전 실행 종료 후 5분 뒤에 시작하므로 겹침이 원천 차단됩니다.
4. 인메모리 Trie: Copy-on-Write + 검색 로그 기반 초기화
Copy-on-Write (volatile reference swap)
Trie 갱신은 매일 새벽 3시 배치로 수행합니다. 새 Trie를 별도로 빌드한 뒤 volatile 참조를 교체하면 읽기 스레드는 락 없이 안전하게 탐색할 수 있습니다.
private volatile TrieNode root = new TrieNode();
void swapRoots(TrieNode newRoot, TrieNode newJamoRoot) { this.root = newRoot; // volatile write this.jamoRoot = newJamoRoot;}Cold Start 문제와 해결
처음에 MySQL ORDER BY (view_count + like_count) DESC로 인기 제목을 가져오려 했으나:
- 위키 덤프 데이터라 viewCount가 전부 0 → 어떤 기준으로 뽑든 “인기” 제목이 아님
- 인덱스 없는 표현식 정렬 → 14.25M건 Full Scan → connection leak → 앱 기동 실패
@PostConstruct→ 기동 블로킹 → health check 타임아웃 → 배포 실패
해결: 검색 로그 기반으로 전환
@EventListener(ApplicationReadyEvent.class)void initialize() { List<Object[]> topQueries = searchLogRepository.findTopQueriesSince( LocalDateTime.now().minusDays(7), TRIE_MAX_ENTRIES); // 로그가 없으면 빈 Trie → 100% Lucene fallback (기존과 동일) // 로그가 쌓이면 인기 검색어만 Trie에 로드 → 인기순 자동완성}@PostConstruct→@EventListener(ApplicationReadyEvent): 앱 기동을 블로킹하지 않음- 검색 로그가 없으면 빈 Trie → Lucene PrefixQuery fallback → 기존과 동일하게 동작
- 검색 로그가 쌓이면 자동으로 Trie가 풍부해짐

Before vs After
| Before (Lucene PrefixQuery) | After (Trie + 검색 로그) | |
|---|---|---|
| “삼성” 입력 | 르노삼성 QM3, 르노삼성 QM5, … | 삼성전자, 삼성sdi, 삼성물산 |
| 정렬 기준 | 사전순 (lexicographic) | 검색 빈도순 (인기도) |
| 데이터 소스 | Lucene term dictionary | search_logs 시간 버킷 집계 |
5. 한글 자모 분해: “삼ㅅ” → “삼성전자”
문제
한글은 자모 단위로 입력됩니다. “삼성”을 입력하는 과정에서 “삼ㅅ” 상태가 존재하는데, 원본 Trie는 완성된 음절(“삼성”)만 처리하므로 “삼ㅅ”에서 매칭이 끊깁니다.
구현: 원본 Trie + 자모 Trie 이중 구조
한글 음절(U+AC00~U+D7AF)을 초성/중성/종성으로 분해합니다:
"삼성전자" → 원본 Trie: 삼 → 성 → 전 → 자 → 자모 Trie: ㅅ → ㅏ → ㅁ → ㅅ → ㅓ → ㅇ → ㅈ → ㅓ → ㄴ → ㅈ → ㅏ → 초성: ㅅ → ㅅ → ㅈ → ㅈ검색 시 입력에 자모(ㄱ~ㅎ, ㅏ~ㅣ)가 포함되면 전체를 자모 분해한 후 자모 Trie에서 검색합니다:
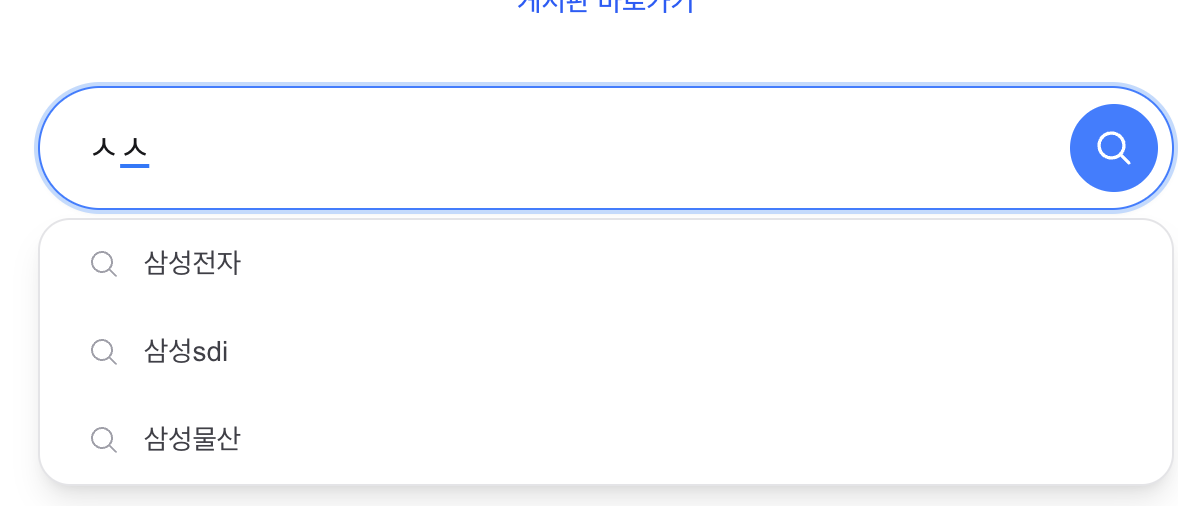
"삼ㅅ" → containsJamo=true → decompose("삼ㅅ")="ㅅㅏㅁㅅ" → 자모 Trie 검색"ㅅㅅ" → containsJamo=true → 그대로 → 자모 Trie 초성 매칭"삼성" → containsJamo=false → 원본 Trie 검색구현 중 발견된 버그
최초 구현에서 “삼ㅅ” 입력 시 자모가 감지되어 자모 Trie로 갔지만, “삼ㅅ”을 분해하지 않고 그대로 검색하여 매칭 실패했습니다. 자모 Trie에는 “ㅅㅏㅁㅅ…” 경로로 저장되어 있으므로, 입력을 먼저 분해해야 합니다.
Before (버그): "삼ㅅ" → 자모Trie.search("삼ㅅ") → 매칭 실패After (수정): "삼ㅅ" → decompose("삼ㅅ")="ㅅㅏㅁㅅ" → 자모Trie.search("ㅅㅏㅁㅅ") → 삼성전자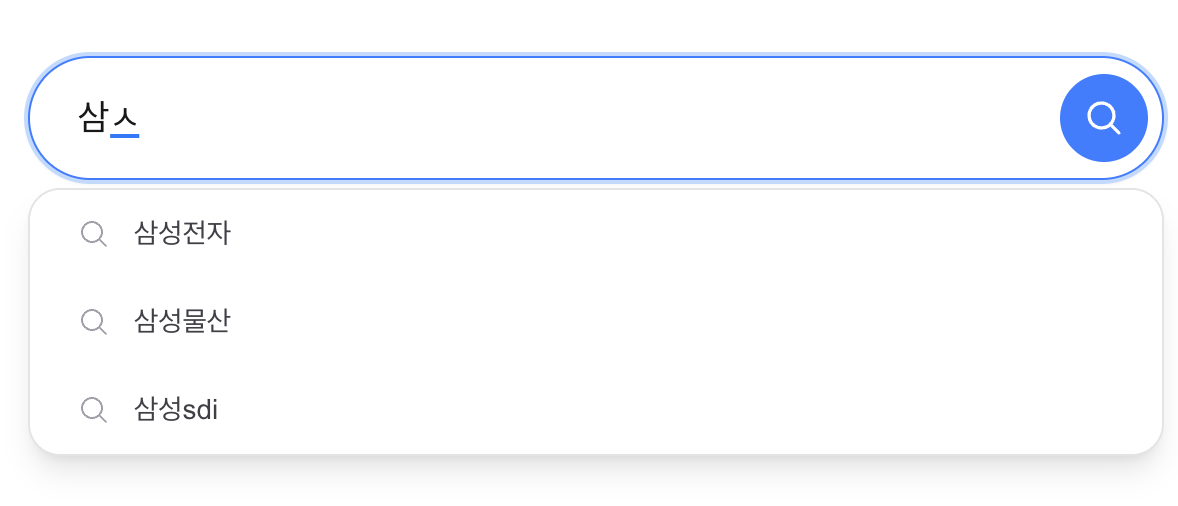
6. k6 부하 테스트로 검색 로그 축적
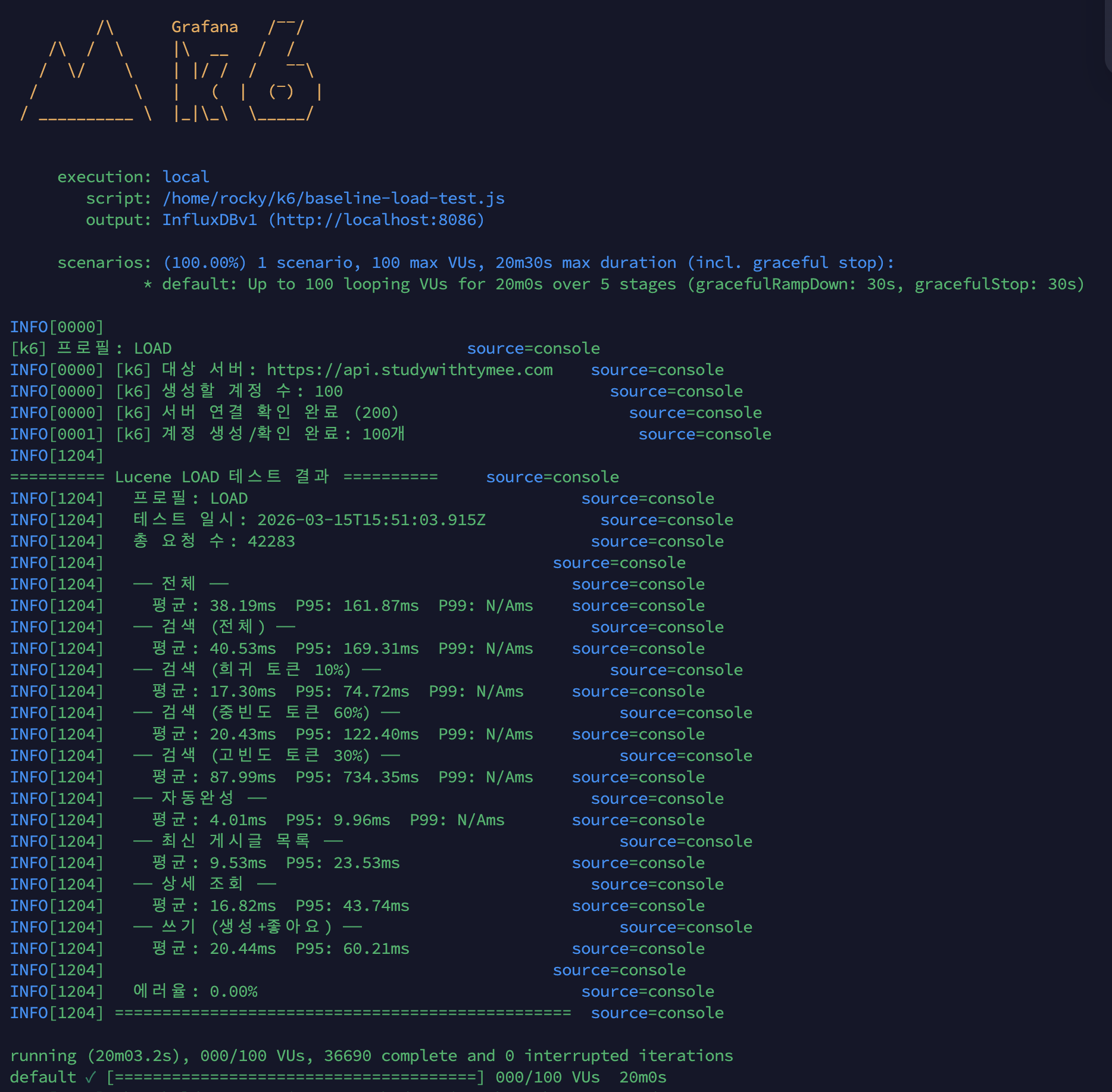
검색 로그를 빠르게 쌓기 위해 k6 smoke + load 테스트를 실행했습니다. k6 검색 시나리오(35% 비중)가 PostService.search()를 호출하면 searchLogCollector.record()가 자동 실행되어 로그가 축적됩니다.
| 테스트 | 요청 수 | 에러율 |
|---|---|---|
| smoke (2분, 5 VU) | 261 | 0% |
| load (20분, 100 VU) | 42,283 | 0% |
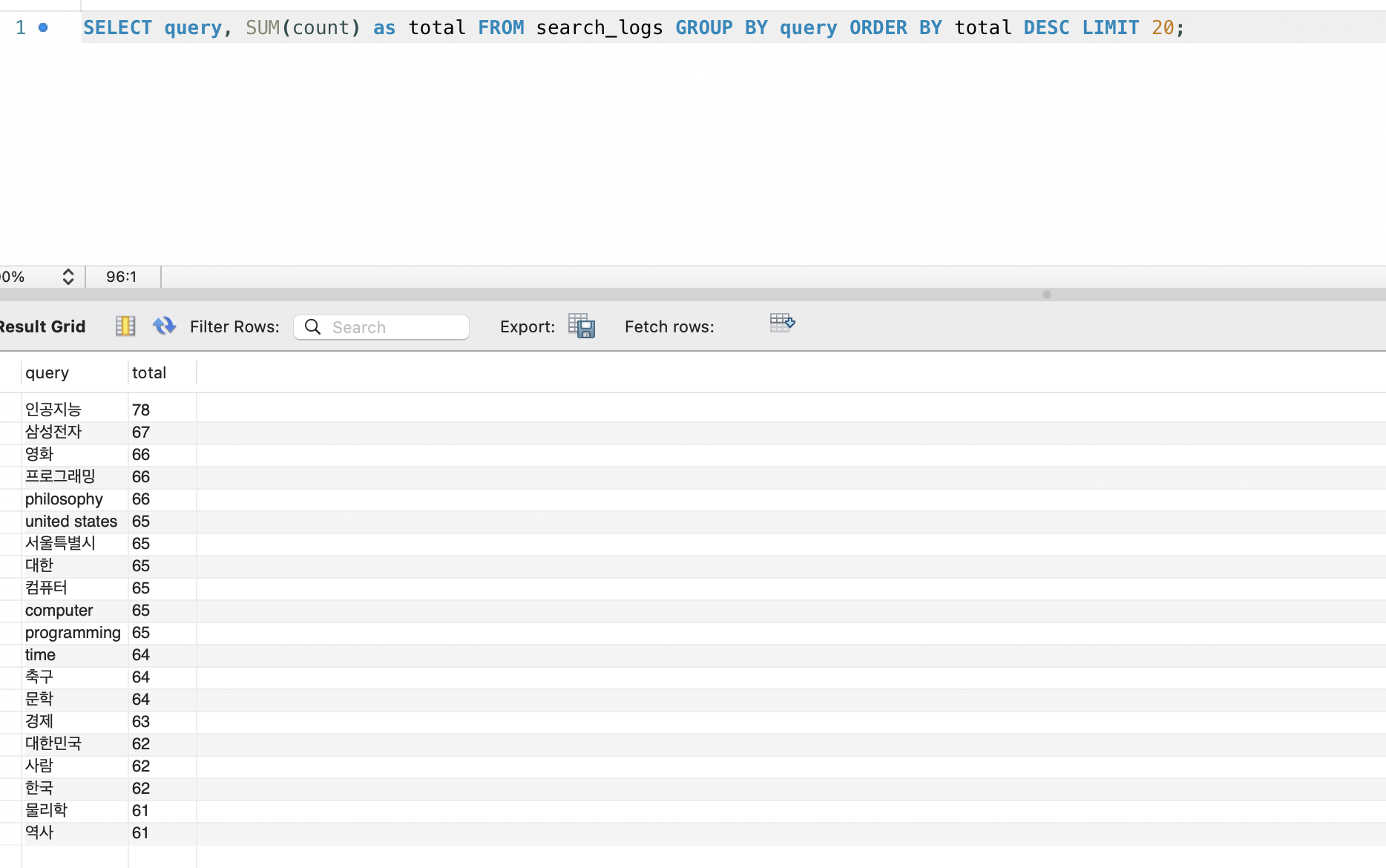
k6 후 검색 로그: 49개 고유 검색어, 인공지능 78회 1위.
7. 구현 과정에서 발견된 문제와 해결
| 문제 | 원인 | 해결 |
|---|---|---|
ORDER BY (view_count + like_count) 기동 실패 | 인덱스 없는 표현식 정렬 → 14.25M건 Full Scan → connection leak | 검색 로그 기반으로 전환 |
@PostConstruct 기동 블로킹 | Trie 로드 시 health check 타임아웃 | @EventListener(ApplicationReadyEvent) |
| viewCount=0 (위키 덤프) | Cold start, 인기도 데이터 없음 | search_logs 축적 → Trie rebuild |
snapshot + clear() 데이터 유실 | snapshot과 clear 사이에 record()가 끼어들면 유실 | volatile 참조 교체 (swap) |
fixedRate 데드락 가능 | 이전 flush 미완료 시 다음 flush 겹침 | fixedDelay로 변경 |
| ”삼ㅅ” 자모 검색 실패 | 자모 포함 입력을 분해하지 않고 검색 | 전체 분해 후 자모 Trie 검색 |
8. 스킵한 항목과 판단 근거
| 항목 | 스킵 이유 |
|---|---|
| 점수 공식 (70% 빈도 + 30% 시간 감쇠) | 검색 로그 41건이 하루 만에 쌓여서 시간 분포가 없음. raw count와 결과 동일 |
| Pre-computed Top-K (depth <= 3) | 41건에서 DFS가 0.1ms. 사전 계산의 이점보다 관리 복잡도가 더 큼 |
| AnalyzingSuggester 비교 | Redis L2 캐시에서 Redis flat KV로 전환 시 Trie를 퇴역. 퇴역할 자료구조를 비교할 실익 없음 |
대규모에서의 Trie 한계
Trie는 이 단계에서 검색 품질 문제를 해결하는 데는 유효했지만, 대규모 자동완성의 최종 형태로 보기는 어렵습니다.
- 메모리: 모든 단어/구 조합을 Trie에 저장하면 단일 머신에 올릴 수 없음
- 검색 성능: 1~2글자 prefix의 DFS 분기가 폭발적
- 네트워크 기반 불가: 분산 환경에서 글자마다 네트워크 홉 발생
최종 아키텍처는 prefix → [top-10 suggestions] flat 매핑을 Redis에서 O(1) GET으로 서빙하는 것입니다 (Redis L2 캐시에서 구현).
출처
자동완성 시스템 설계:
- Design Search Autocomplete System — AlgoMaster
- Ranking Signals in Autocomplete — System Overflow
- Prefixy: Scalable Prefix Search — Medium
한글 유니코드:
동시성 패턴:
Previous Post
In Caching Strategy, we introduced Caffeine L1 local cache and improved autocomplete response time from 368ms to 4.67ms (78.8x), achieving a 99.9% cache hit rate.
Previous Post Summary
Thanks to Caffeine cache, autocomplete responses are returned in roughly 0.1ms. However, the fundamental problem remained: results were returned in lexicographic order.
1. Problem — Typing “Samsung” Returns “Renault Samsung QM3” First
Lucene PrefixQuery traverses the term dictionary in lexicographic order. Among titles starting with the Korean characters for “Samsung,” the Unicode value of the prefix in “Renault Samsung” comes before “Samsung Electronics,” so “Renault Samsung QM3” appears first instead of the desired “Samsung Electronics.”
To assign scores to PrefixQuery, you would need to fetch all matching results and sort them separately, negating the O(m) advantage of prefix search.
Additionally, autocomplete broke during mid-input of Korean jamo (e.g., typing the incomplete syllable sequence for “Samsung”). Korean is typed character-by-character at the jamo level, but PrefixQuery only matches fully composed syllables.
2. Solution Strategy — Search Logs + In-Memory Trie + Jamo Decomposition
We combined three approaches to solve this:
- Search Log Collection: Record queries users actually search to obtain popularity data
- In-Memory Trie: Load popular search terms from logs into a Trie and return results by search frequency
- Korean Jamo Decomposition: Decompose syllables into initial/medial/final consonants to support mid-input and choseong (initial consonant) search
3. Search Log Collection — Time-Bucket Aggregation
Why Search Logs Are Needed
To sort by popularity, we need data on “how frequently each search term is queried.” Since the wiki dump data has viewCount of 0 across the board, search logs are the only popularity signal.
Why a MySQL Table (Not S3)
At Google/Naver scale (billions of daily QPS), search logs are saved as files in S3 and batch-processed with Spark. Inserting billions of records into a DB would overwhelm it.
wikiEngine runs on a single server (ARM 2-core, 12GB RAM), making S3/Kafka infrastructure unnecessary. We store logs directly in a MySQL table.
Time-Bucket Design
Instead of cumulative counts (query, total_count), we use a time-bucket structure (query, time_bucket, count).
CREATE TABLE search_logs ( id BIGINT AUTO_INCREMENT PRIMARY KEY, query VARCHAR(200) NOT NULL, time_bucket DATETIME NOT NULL, count BIGINT NOT NULL DEFAULT 1, UNIQUE INDEX uk_search_logs_query_bucket (query, time_bucket));Cumulative counts cannot distinguish “whether 10,000 searches happened six months ago or today,” making time-decay scoring impossible. With time buckets, window-based aggregation is possible using WHERE time_bucket >= NOW() - INTERVAL 7 DAY.
SearchLogCollector — Volatile Swap Flush
Issuing a DB INSERT per request creates write-load problems. We aggregate in-memory using ConcurrentHashMap and batch-upsert every 5 minutes.
@Scheduled(fixedDelay = 300_000)@Transactionalpublic void flush() { ConcurrentHashMap<String, LongAdder> snapshot = buffer; buffer = new ConcurrentHashMap<>(); // volatile swap
LocalDateTime timeBucket = LocalDateTime.now().truncatedTo(ChronoUnit.HOURS); for (var entry : snapshot.entrySet()) { searchLogRepository.upsert(entry.getKey(), timeBucket, entry.getValue().sum()); }}We use volatile reference swap instead of the snapshot + clear() pattern. With clear(), if record() is called between snapshot creation and clear, data is permanently lost. With reference swap, record() calls after the swap write to the new buffer, while the old buffer is used exclusively for flushing — no data loss.
We use fixedDelay instead of fixedRate. With fixedRate, the next schedule enters the queue even if the previous flush hasn’t finished, potentially causing concurrent ON DUPLICATE KEY UPDATE leading to deadlocks. fixedDelay starts 5 minutes after the previous execution ends, eliminating overlap entirely.
4. In-Memory Trie — Copy-on-Write + Search-Log-Based Initialization
Copy-on-Write (Volatile Reference Swap)
Trie updates run as a daily batch at 3 AM. A new Trie is built separately, then the volatile reference is swapped so read threads can traverse safely without locks.
private volatile TrieNode root = new TrieNode();
void swapRoots(TrieNode newRoot, TrieNode newJamoRoot) { this.root = newRoot; // volatile write this.jamoRoot = newJamoRoot;}Cold Start Problem and Solution
Initially, we tried fetching popular titles from MySQL with ORDER BY (view_count + like_count) DESC, but:
- Wiki dump data has viewCount of 0 across the board — no way to determine “popular” titles
- Expression-based sort without an index — Full Scan of 14.25M rows — connection leak — app startup failure
@PostConstruct— startup blocking — health check timeout — deployment failure
Solution: Switch to search-log-based initialization
@EventListener(ApplicationReadyEvent.class)void initialize() { List<Object[]> topQueries = searchLogRepository.findTopQueriesSince( LocalDateTime.now().minusDays(7), TRIE_MAX_ENTRIES); // No logs → empty Trie → 100% Lucene fallback (same as before) // Logs accumulate → only popular queries loaded into Trie → popularity-ranked autocomplete}@PostConstructchanged to@EventListener(ApplicationReadyEvent): does not block app startup- No search logs → empty Trie → Lucene PrefixQuery fallback → behaves identically to before
- As search logs accumulate, the Trie automatically becomes richer
Before vs After
| Before (Lucene PrefixQuery) | After (Trie + Search Logs) | |
|---|---|---|
| Typing “Samsung” | Renault Samsung QM3, Renault Samsung QM5, … | Samsung Electronics, Samsung SDI, Samsung C&T |
| Sort Criteria | Lexicographic order | Search frequency (popularity) |
| Data Source | Lucene term dictionary | search_logs time-bucket aggregation |
5. Korean Jamo Decomposition — Mid-Input to Full Match
Problem
Korean is typed at the jamo (consonant/vowel) level. While typing “Samsung” (in Korean), there is an intermediate state with an incomplete syllable. The original Trie only handles fully composed syllables, so matching breaks at the mid-input state.
Implementation — Dual Structure: Original Trie + Jamo Trie
Korean syllables (U+AC00~U+D7AF) are decomposed into initial/medial/final consonants:
"삼성전자" → Original Trie: 삼 → 성 → 전 → 자 → Jamo Trie: ㅅ → ㅏ → ㅁ → ㅅ → ㅓ → ㅇ → ㅈ → ㅓ → ㄴ → ㅈ → ㅏ → Choseong: ㅅ → ㅅ → ㅈ → ㅈDuring search, if the input contains jamo characters, the entire input is decomposed and searched in the Jamo Trie:
"삼ㅅ" → containsJamo=true → decompose("삼ㅅ")="ㅅㅏㅁㅅ" → Jamo Trie search"ㅅㅅ" → containsJamo=true → as-is → Jamo Trie choseong matching"삼성" → containsJamo=false → Original Trie searchBug Discovered During Implementation
In the initial implementation, when “삼ㅅ” (mid-input) was entered, jamo was detected and the Jamo Trie was selected, but the input was searched as-is without decomposition, causing a match failure. Since the Jamo Trie stores entries along the “ㅅㅏㅁㅅ…” path, the input must be decomposed first.
Before (bug): "삼ㅅ" → jamoTrie.search("삼ㅅ") → match failureAfter (fix): "삼ㅅ" → decompose("삼ㅅ")="ㅅㅏㅁㅅ" → jamoTrie.search("ㅅㅏㅁㅅ") → Samsung Electronics
6. k6 Load Testing to Accumulate Search Logs
We ran k6 smoke + load tests to quickly accumulate search logs. The k6 search scenario (35% weight) calls PostService.search(), which automatically triggers searchLogCollector.record() to accumulate logs.
| Test | Requests | Error Rate |
|---|---|---|
| smoke (2 min, 5 VU) | 261 | 0% |
| load (20 min, 100 VU) | 42,283 | 0% |
After k6: 49 unique search terms, “Artificial Intelligence” ranked #1 with 78 searches.
7. Issues Discovered During Implementation and Solutions
| Issue | Cause | Solution |
|---|---|---|
ORDER BY (view_count + like_count) startup failure | Expression-based sort without index — 14.25M row Full Scan — connection leak | Switched to search-log-based approach |
@PostConstruct blocking startup | Trie loading caused health check timeout | @EventListener(ApplicationReadyEvent) |
| viewCount=0 (wiki dump) | Cold start — no popularity data | search_logs accumulation followed by Trie rebuild |
snapshot + clear() data loss | record() called between snapshot and clear causes permanent loss | Volatile reference swap |
fixedRate potential deadlock | Next flush overlaps if previous flush hasn’t finished | Changed to fixedDelay |
| Mid-input jamo search failure | Input containing jamo was searched without decomposition | Full decomposition before Jamo Trie search |
8. Skipped Items and Rationale
| Item | Reason for Skipping |
|---|---|
| Score formula (70% frequency + 30% time decay) | 41 search logs accumulated in a single day with no time distribution. Results identical to raw count |
| Pre-computed Top-K (depth <= 3) | DFS takes 0.1ms with 41 entries. No benefit from pre-computation — over-engineering |
| AnalyzingSuggester comparison | Trie will be retired in Step 12 when switching to Redis flat KV. No practical value in comparing a data structure slated for retirement |
Trie Limitations at Scale
The Trie is effective for solving the search-quality problem at this stage, but it is not the final form of large-scale autocomplete.
- Memory: Storing all word/phrase combinations in a Trie cannot fit on a single machine
- Search Performance: DFS branching for 1-2 character prefixes explodes
- Network-Based Infeasible: In distributed environments, each character incurs a network hop
The final architecture serves prefix -> [top-10 suggestions] flat mappings via O(1) GET from Redis (Step 12).
References
Autocomplete System Design:
- Design Search Autocomplete System — AlgoMaster
- Ranking Signals in Autocomplete — System Overflow
- Prefixy: Scalable Prefix Search — Medium
Korean Unicode:
Concurrency Patterns:

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.