Redis 샤딩: Consistent Hashing으로 워크로드 격리
목차
이전 글
CDC (Change Data Capture): 이벤트 기반 동기화에서 PostService의 dual-write 구조를 이벤트 기반으로 전환하고, Debezium + Kafka CDC로 모든 DB 변경을 캡처했습니다. 이 글은 단일 Redis 인스턴스의 구조적 문제를 실측하고, Consistent Hashing으로 워크로드를 격리하는 과정입니다.
이전 글 요약
| 지표 | CDC 결과 |
|---|---|
| PostService 의존성 | 6개 → 이벤트 발행만 (OCP 준수) |
| 검색 캐시 무효화 | 미구현 → 이벤트 기반 L1 즉시 무효화 |
| 테스트 | 117개 전체 통과 |
| CDC 파이프라인 | MySQL binlog → Debezium → Kafka → Consumer |
| 아키텍처 패턴 | @ApplicationModuleListener (fallback) + Kafka CDC (primary) |
인프라와 아키텍처 모두 안정적이다. 이제 단일 Redis 인스턴스의 워크로드 간섭 문제와 KEYS 블로킹 안티패턴을 해결할 차례다.
1. 현재 아키텍처: 단일 Redis 인스턴스

하나의 Redis 인스턴스에 성격이 완전히 다른 4가지 워크로드가 혼재한다:
| 용도 | 키 패턴 | 추정 키 수 | 특성 |
|---|---|---|---|
| 자동완성 KV | prefix:v{version}:{prefix} | 수만~수십만 | 배치 갱신, TTL 2시간 |
| 게시글/검색 캐시 (L2) | post:{id}, search:{keyword}:{page}:{size} | 핫 쿼리 수천 | TTL 기반 |
| 조회수 카운터 | post:views:{id} | 조회된 게시글 수 | 30초 flush 후 삭제 |
| 토큰 블랙리스트 | blacklist:{token} | 로그아웃 수 | TTL = JWT 잔여시간 |
2. 문제 인식: 3가지 실측 근거
문제 1: KEYS 블로킹 안티패턴, 30초마다 Redis 전체 멈춤
ViewCountService.flushToDB()에서 30초마다 실행되는 코드:
Set<String> keys = redisTemplate.keys(KEY_PREFIX + "*"); // KEYS post:views:*Redis 공식 문서: “Don’t use KEYS in your regular application code. Consider it only for debugging purposes.”
KEYS는 전체 keyspace를 O(N)으로 블로킹 스캔한다. Redis는 싱글스레드이므로, KEYS 실행 동안 모든 GET/SET/INCR이 큐에서 대기한다.
실측 결과 (OCI ARM 2vCPU/12G, Redis 7.4-alpine, 키 2,041개):
| 명령 | 시도 1 | 시도 2 | 시도 3 | Redis 내부 (SLOWLOG) |
|---|---|---|---|---|
KEYS post:views:* | 88ms | 46ms | 66ms | 34.6ms |
KEYS prefix:* | 48ms | 116ms | 46ms | — |
셸 측정(46~116ms)에는
docker exec오버헤드가 포함되어 있다. Redis 내부 실제 시간은 SLOWLOG 기준 34.6ms로,slowlog-log-slower-than 10000(10ms) 임계값을 3.4배 초과하여 SLOWLOG에 기록됐다. KEYS는 O(N)이므로 키가 10배(2만 개)면 ~350ms, 100배(20만 개)면 ~3.5초로 선형 악화한다.
프로덕션 사고 사례:
- sidekiq-cron:
KEYS cron_jobs:*가 40M 키 환경에서 5~6초 블로킹 → 서비스 다운 - Medusa(e-commerce): 330K 키에서
KEYS mc:tag:*로 Redis 전체 블로킹, 모든 클라이언트 대기 - Drupal Redis: 150만 키에서 캐시 flush 시 전체 사이트 프리징 → SCAN 패치로 전환
문제 2: 배치 쓰기 vs 실시간 읽기가 부르는 워크로드 간섭
buildPrefixTopK()가 매시간 수만 개 키를 동시에 SET하면서, 실시간 GET/INCR과 같은 싱글스레드에서 경합한다.
실측 근거 (SLOWLOG + commandstats):
SLOWLOG에 배치 빌드 중 개별 SET이 10.7ms로 기록됨:
SLOWLOG #2: SET prefix:v1774134000041:scien ["science"] EX 7200 → 10,722us (10.7ms)commandstats 기준 SET 평균은 10.04us(0.01ms)이므로, 이 10.7ms는 평균의 1,070배다. 일반 GET 명령도 SLOWLOG에 잡혔다:
SLOWLOG #1: GET prefix:v1774018800170:삼성 → 15,513us (15.5ms)GET 평균 8.30us 대비 1,868배 느린 케이스로, 배치 쓰기와 실시간 읽기가 같은 싱글스레드에서 경합하는 증거다.
redis-benchmark baseline (배치 없을 때):
| 명령 | 처리량 | P50 |
|---|---|---|
| SET | 88,339 req/s | 0.231ms |
| GET | 104,602 req/s | 0.231ms |
baseline에서 Redis 자체는 충분히 빠르다 (GET P50 0.231ms). 문제는 KEYS/배치 빌드 시점에 간헐적으로 수십 ms 스파이크가 발생하는 것이다.
현업 사례:
- GitLab: eviction 중 Redis 메인 스레드 CPU 대부분 소모, 응답률 25,000 → 5,000 ops/sec (80% 하락)
- Alibaba Cloud: 트래픽 증가로 메모리 5분 만에 100%, eviction 연쇄 → 모든 GET/SET 타임아웃
문제 3: 용도별 격리 부재와 blast radius
| 워크로드 | 특성 | 위험 |
|---|---|---|
| 자동완성 KV | 배치 대량 WRITE (수만 키) | 배치 중 다른 워크로드 지연 |
| 게시글/검색 캐시 (L2) | TTL 기반, eviction 허용 | eviction이 다른 키에 영향 |
| 조회수 카운터 | 고빈도 INCR, 30초 flush | KEYS 스캔이 INCR 블로킹 |
| 토큰 블랙리스트 | 보안 크리티컬, 유실 불가 | volatile-lru에서 TTL 있는 블랙리스트 키가 eviction 대상 가능 |
핵심 위험: maxmemory-policy volatile-lru 설정에서, 메모리가 128MB에 도달하면 TTL이 설정된 모든 키가 eviction 대상이 된다. 블랙리스트 키(blacklist:{token})도 TTL이 있으므로 eviction되면 로그아웃된 토큰이 다시 유효해진다. 곧 보안 사고다.
Redis 공식 문서의 직접 권고: “The volatile-lru, volatile-random policies are mainly useful when you want to use a single instance for both caching and persistent keys. However, it is usually a better idea to run two Redis instances to solve such a problem.”
eviction 시뮬레이션 결과 (maxmemory를 used_memory + 1MB로 임시 축소):
| 항목 | 결과 |
|---|---|
| evicted_keys | 2,077개 |
| 블랙리스트 키 (Before) | 1개 |
| 블랙리스트 키 (After) | 1개 (이번에는 생존) |
이번 테스트에서 블랙리스트 키는 LRU 순서상 최근 접근이라 eviction 후순위였다. 하지만 이건 타이밍에 의존하는 결과다. 로그아웃 후 시간이 지나 LRU에서 밀리면 eviction 대상이 된다.
핵심: 2,077개 키가 eviction되는 동안 어떤 키가 제거될지 예측할 수 없다. 이번에 블랙리스트가 살아남은 건 운이지 보장이 아니다.
3가지 문제의 공통 원인: 성격이 다른 워크로드가 하나의 싱글스레드 Redis를 공유하고 있다. Redis 창시자(Salvatore Sanfilippo)는 단일 인스턴스에서 SELECT로 DB를 나누는 것을 “the worst design mistake”라고 직접 언급했다.
3. 근본 원인 분석
Redis는 모든 명령을 단일 스레드에서 순차 실행한다. 이것이 INCR의 원자성을 보장하는 장점이지만, 동시에 하나의 느린 명령이 모든 것을 블로킹하는 단점이다.
| 문제 | 원인 | 해결 방향 |
|---|---|---|
| KEYS 블로킹 | O(N) 전체 keyspace 스캔, 중간에 양보(yield) 안 함 | KEYS → SCAN 전환 |
| 배치 간섭 | Pipeline 없이 개별 SET 수만 회 → 네트워크 왕복 수만 회 | 용도별 Redis 인스턴스 분리 |
| blast radius | volatile-lru가 TTL 키를 용도 구분 없이 eviction | 블랙리스트 전용 인스턴스 |
4. 대안 검토

Redis Cluster (공식 분산)
자동 샤딩(16384 슬롯) + 자동 failover는 프로덕션 표준이지만 최소 6노드($144/월)가 필요하다. 현 규모(~60MB)에서는 과잉이다.
Redis Sentinel (현 규모 최적)
자동 failover + 단일 Primary. 데이터가 단일 노드 메모리에 들어가고 HA만 필요한 경우의 최적 선택. ~$36/월.
핵심 trade-off: 현 규모에서 고가용성만 필요했다면 Redis Sentinel이나 단일 인스턴스 유지가 더 단순한 선택이었을 수 있습니다. 하지만 이 단계의 핵심 문제는 HA보다도, 서로 다른 워크로드를 같은 인스턴스에 섞어두었을 때 생기는 간섭과 보안상 영향 범위를 어떻게 줄일 것인가에 더 가까웠습니다.
앱 레벨 Consistent Hashing (선택: 워크로드 분리와 제어 가능성)
Redis Cluster는 범용 샤딩에는 적합하지만, 이 단계에서 중요했던 것은 단순한 데이터 분산보다 자동완성, 일반 캐시, 조회수, 블랙리스트처럼 성격이 다른 데이터를 어떻게 분리하고 어떤 노드에 둘지 더 세밀하게 제어하는 일이었습니다. 그래서 현재 제약 안에서는 애플리케이션 라우팅 계층을 두고, 키 재배치와 노드별 역할을 직접 통제하는 방식이 더 적합하다고 판단했습니다.
비용 환산 (AWS 기준)
| 구성 | 월 비용 (AWS) | 비고 |
|---|---|---|
| 현재 (단일 Redis) | ElastiCache t4g.micro ~$12/월 | 128MB, 단일 노드 |
| Redis Sentinel (권장) | ~$36/월 | 1 Primary + 2 Replica |
| 3노드 샤딩 (선택) | ~$36/월 + 앱 라우팅 관리 | 동일 비용에 운영 부담 추가 |
| Redis Cluster | ~$144/월 | 3P + 3R, 과잉 |
5. Consistent Hashing 알고리즘

hash(key) % N의 문제
단순 모듈로 해시는 노드 수가 변경되면 거의 모든 키가 재배치된다:
| 시나리오 | hash(key) % N | Consistent Hashing |
|---|---|---|
| 3 → 4노드 | ~75% 키 이동 | ~25% 키 이동 (1/N) |
| 4 → 3노드 (장애) | ~75% 키 이동 | ~25% 키 이동 (1/N) |
가상 노드 (Virtual Nodes)
물리 노드 3개만으로는 해시 링 위 분포가 불균등하다. 각 물리 노드를 여러 가상 노드로 매핑하여 균등 분산:
| 가상 노드 수 | 키 분산 편차 | 노드 추가 시 이동 키 |
|---|---|---|
| 1 (가상 노드 없음) | ~50% 편차 | 최대 50% |
| 50 | ~10% 편차 | ~1/N |
| 150 (선택) | ~5% 편차 | ~1/N |
| 500 | ~2% 편차 | ~1/N |
가상 노드 150개는 균등 분산과 메모리(TreeMap 엔트리 수) 사이의 적절한 균형점이다.
6. 구현
아키텍처: 하이브리드 (Consistent Hashing + 용도별 격리)

데이터 라우팅 전략

| 데이터 | 라우팅 방식 | 이유 |
|---|---|---|
자동완성 KV (prefix:*) | Consistent Hashing | 키 수 최다, 분산 효과 극대화 |
게시글/검색 캐시 (post:{id}, search:*) | Consistent Hashing | 키 기반 분산 자연스러움 |
조회수 (post:views:{id}) | Consistent Hashing | 키 기반 분산, flush 시 각 노드에서 SCAN |
버전 포인터 (prefix:current_version) | 고정 노드 (Ring 첫 번째) | 전역 메타데이터, 1개만 존재 |
토큰 블랙리스트 (blacklist:*) | 전용 인스턴스 (격리) | 보안 크리티컬, 샤딩 불가 |
토큰 블랙리스트 샤딩 문제: JWT 토큰을 Consistent Hashing으로 분산하면, 노드 장애 시 해당 샤드의 블랙리스트를 조회할 수 없다. 보수적 정책(장애 시 모든 토큰 거부)과 결합하면 1/3 확률로 전체 인증 차단이 발생한다. 따라서 블랙리스트는 샤딩하지 않는 것이 안전하다.
ConsistentHashRouter 구현
@Componentpublic class ConsistentHashRouter {
private final ConcurrentSkipListMap<Long, StringRedisTemplate> ring = new ConcurrentSkipListMap<>(); private final List<StringRedisTemplate> nodes; private static final int VIRTUAL_NODES = 150;
public ConsistentHashRouter(List<StringRedisTemplate> shardRedisTemplates) { this.nodes = shardRedisTemplates; for (int i = 0; i < nodes.size(); i++) { for (int v = 0; v < VIRTUAL_NODES; v++) { long hash = hash("node-" + i + "-vnode-" + v); ring.put(hash, nodes.get(i)); } } }
/** 키에 해당하는 Redis 노드 결정 (ConcurrentSkipListMap은 thread-safe) */ public StringRedisTemplate getNode(String key) { long hash = hash(key); Map.Entry<Long, StringRedisTemplate> entry = ring.ceilingEntry(hash); if (entry == null) { entry = ring.firstEntry(); // 링 순환 } return entry.getValue(); }
/** 모든 노드 반환 (SCAN 등 전체 조회 시) */ public List<StringRedisTemplate> getAllNodes() { return Collections.unmodifiableList(nodes); }
private long hash(String key) { return Hashing.murmur3_128() .hashString(key, StandardCharsets.UTF_8) .asLong() & 0x7FFFFFFFFFFFFFFFL; }}RedisShardConfig: 다중 LettuceConnectionFactory 구성
@Configurationpublic class RedisShardConfig {
@Bean @Primary StringRedisTemplate stringRedisTemplate(RedisConnectionFactory connectionFactory) { // 기존 단일 인스턴스 유지 — 토큰 블랙리스트 등 비샤딩 용도 return new StringRedisTemplate(connectionFactory); }
@Bean List<StringRedisTemplate> shardRedisTemplates( @Value("${redis.shards[0].host}") String host1, @Value("${redis.shards[0].port}") int port1, @Value("${redis.shards[1].host}") String host2, @Value("${redis.shards[1].port}") int port2, @Value("${redis.shards[2].host}") String host3, @Value("${redis.shards[2].port}") int port3, @Value("${redis.password:}") String password) {
return List.of( createTemplate(host1, port1, password), createTemplate(host2, port2, password), createTemplate(host3, port3, password) ); }
private StringRedisTemplate createTemplate(String host, int port, String password) { RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(host, port); if (!password.isBlank()) { config.setPassword(password); } LettuceConnectionFactory factory = new LettuceConnectionFactory(config); factory.afterPropertiesSet(); return new StringRedisTemplate(factory); }}기존 코드 변경 영향
| 파일 | Before | After |
|---|---|---|
RedisAutocompleteService | StringRedisTemplate redis (단일) | ConsistentHashRouter router |
TieredCacheService | StringRedisTemplate redis (단일) | ConsistentHashRouter router |
ViewCountService | StringRedisTemplate redisTemplate (단일) | ConsistentHashRouter router |
RedisTokenBlacklist | StringRedisTemplate redisTemplate (단일) | 변경 없음 (기존 단일 Redis 유지) |
변경 패턴은 모두 동일하다:
// Before (단일 Redis)redis.opsForValue().get(key);
// After (Consistent Hashing)router.getNode(key).opsForValue().get(key);7. KEYS → SCAN 전환
// BeforeSet<String> keys = redisTemplate.keys(KEY_PREFIX + "*"); // KEYS — O(N) 블로킹
// AfterScanOptions options = ScanOptions.scanOptions().match(KEY_PREFIX + "*").count(1000).build();try (Cursor<String> cursor = redisTemplate.scan(options)) { // SCAN — 커서 기반, 비블로킹 while (cursor.hasNext()) { ... }}| Before (KEYS) | After (SCAN) | |
|---|---|---|
| SLOWLOG (10ms 임계값) | KEYS post:views:* 34.6ms 기록 | 기록 없음 (10ms 미만) |
| 전체 테스트 | 117개 통과 | 117개 통과 |
SLOWLOG RESET 후 90초 대기(flushToDB 3회 실행) → SLOWLOG GET 10 결과 비어 있음. KEYS 블로킹 안티패턴이 완전히 제거됨.
8. 3노드 분리 + ConsistentHashRouter 배포
배포 결과: 3개 Redis 샤드 컨테이너 healthy + App 정상 기동 확인
wiki-app-prod Up 3 minuteswiki-redis-shard3-prod Up 14 minutes (healthy)wiki-redis-shard2-prod Up 14 minutes (healthy)wiki-redis-shard1-prod Up 14 minutes (healthy)분산 균등성 테스트
| 시점 | shard-1 | shard-2 | shard-3 | 기존 redis |
|---|---|---|---|---|
| 배포 직후 (배치 빌드 전) | 0 | 0 | 0 | 1,050 |
| 배치 빌드 후 (1회차) | 369 | 304 | 347 | 1,022 |
| 배치 빌드 후 (2회차) | 751 | 607 | 682 | 1,022 |
샤드 합계: 2,040개 (751 + 607 + 682). 편차: 최소 607 / 최대 751 = 19.2%로, 3노드 × 150 가상 노드에서 Consistent Hashing이 정상 동작함을 확인했다.
자동완성 정상 동작:
curl /posts/autocomplete?prefix=science → ["science"]curl /posts/autocomplete?prefix=삼성 → ["삼성전자"]After redis-benchmark
| 명령 | Before (단일) | After (shard-1) | 차이 |
|---|---|---|---|
| GET | 104,602 req/s, P50 0.231ms | 104,166 req/s, P50 0.231ms | 동등 |
| SET | 88,339 req/s, P50 0.231ms | 71,428 req/s, P50 0.239ms | -19% (컨테이너 리소스 분산) |
샤딩으로 인한 성능 저하 없음. GET P50 동일(0.231ms). SET 처리량 감소는 서버에 Redis 컨테이너 4개가 동시 실행되면서 CPU/메모리를 분산하기 때문이며, 개별 샤드의 실사용 SET 부하는 1/3이므로 문제없음.
9. 노드 장애 시 fallback
docker stop wiki-redis-shard2-prod→ curl /posts/autocomplete?prefix=science→ 정상 응답: Lucene PrefixQuery fallback으로 10건 반환→ shard-2에 있던 키는 캐시 미스 → Lucene이 대신 응답→ docker start wiki-redis-shard2-prod → 복구 확인10. 핫스팟 문제와 Shard Manager
핫스팟 문제
샤딩은 데이터 분산에는 효과적이지만 부하 분산에는 부족하다:
- 1글자 prefix(“위”, “대”, “한”)는 3글자 prefix보다 수십 배 많이 조회
- 이벤트/시즌에 따라 특정 prefix가 폭발적으로 인기 상승
- → 해당 키가 있는 샤드가 핫스팟이 되어 성능 병목
동적 복제 (Dynamic Replication)
Meta 사의 Shard Manager에서 영감을 받은 해결책:
| # | 책임 | 설명 |
|---|---|---|
| 1 | 데이터 분산 | Consistent Hashing으로 샤드 간 데이터 분산 |
| 2 | 동적 복제 관리 | 각 샤드의 부하를 관찰하여 읽기 전용 복제본 동적 추가/제거 |
| 3 | 최소 노드 보장 | 고가용성을 위해 모든 샤드에 최소한의 건강한 노드 유지 |
핵심 포인트: Consistent Hashing으로 데이터 분산 문제를 해결하고, 동적 복제로 부하 분산 문제를 해결한다. 두 문제는 별개이며, 샤딩만으로는 핫스팟을 막을 수 없다.
11. 부하 테스트: k6 100 VU, 20분
k6 smoke 테스트 (5 VU, 2분)
| 시나리오 | 평균 | P95 |
|---|---|---|
| 전체 | 105ms | 490ms |
| 자동완성 | 35ms | 61ms |
| 최신 게시글 | 37ms | 62ms |
| 상세 조회 | 25ms | 44ms |
| 에러율 | 0.00% |
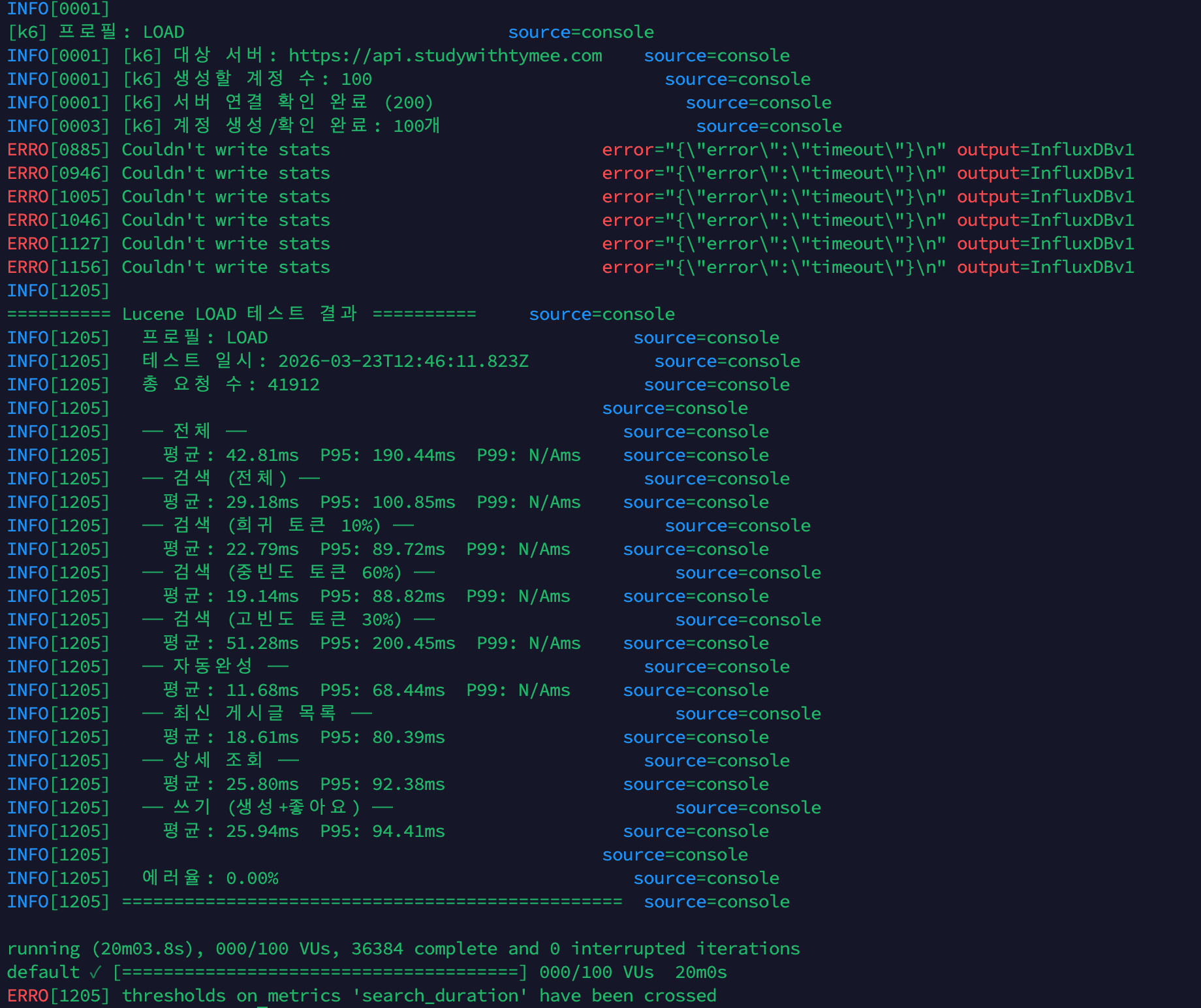
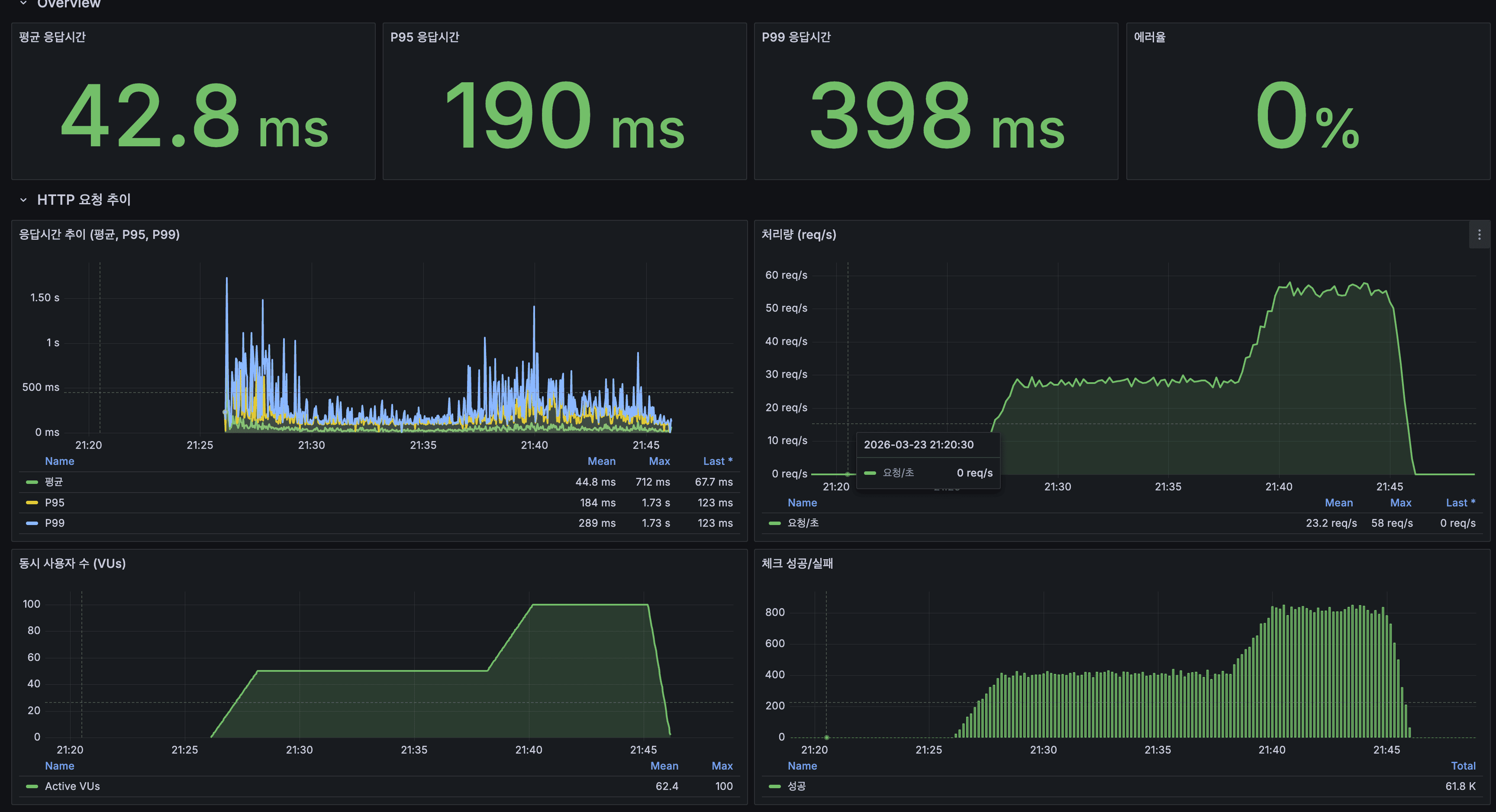
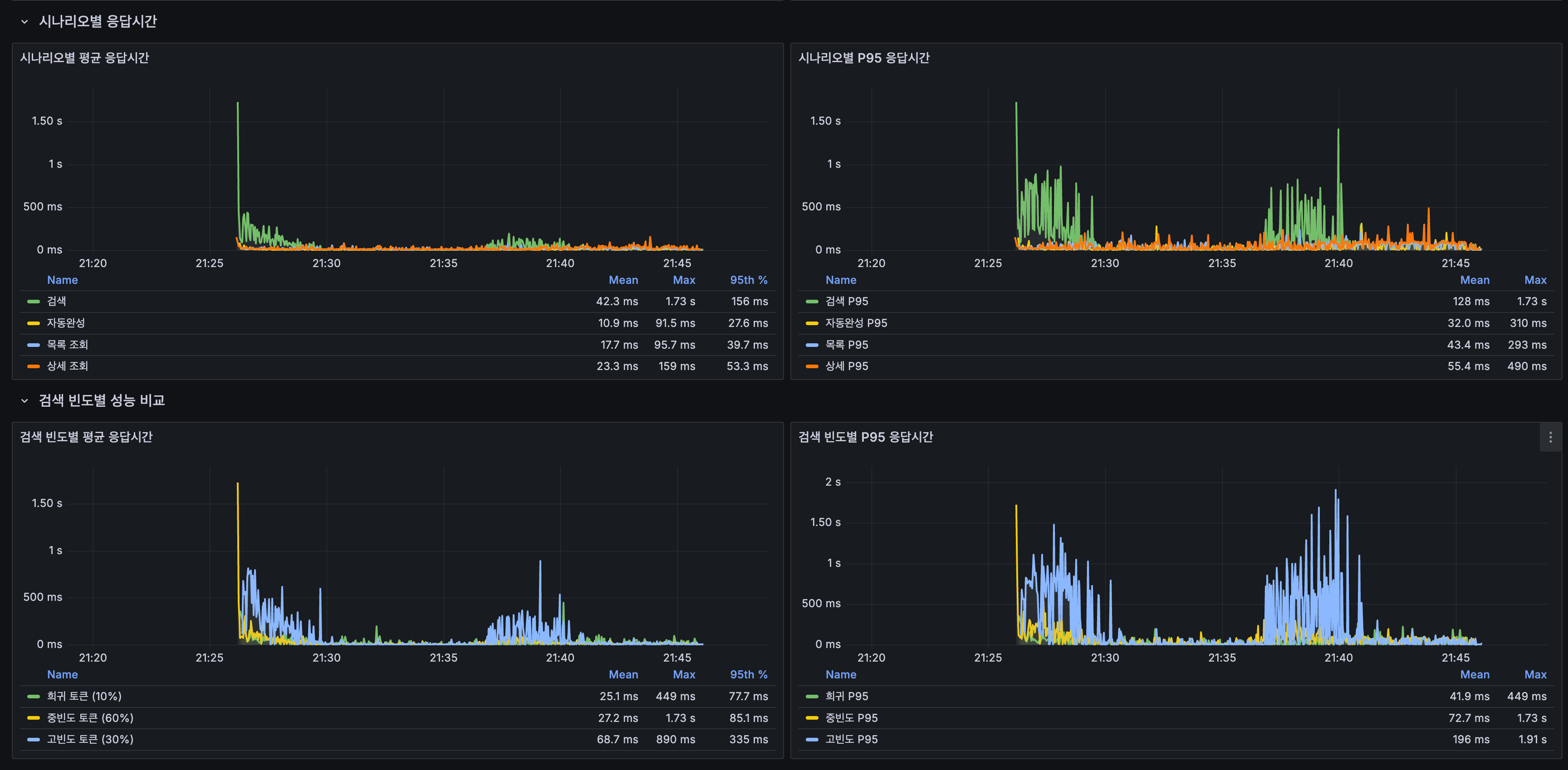
k6 LOAD 테스트: 서버 분산 배치 (100 VU, 20분, 최종)
shard-2, shard-3을 서버 1 → 서버 2로 이동 + Kafka/Debezium 메모리 축소 후 재측정.
| 시나리오 | 평균 | P95 |
|---|---|---|
| 전체 | 42.81ms | 190.44ms |
| 검색 (전체) | 29.18ms | 100.85ms |
| 검색 (희귀 10%) | 22.79ms | 89.72ms |
| 검색 (중빈도 60%) | 19.14ms | 88.82ms |
| 검색 (고빈도 30%) | 51.28ms | 200.45ms |
| 자동완성 | 11.68ms | 68.44ms |
| 최신 게시글 | 18.61ms | 80.39ms |
| 상세 조회 | 25.80ms | 92.38ms |
| 쓰기 (생성+좋아요) | 25.94ms | 94.41ms |
| 에러율 | 0.00% | |
| 총 요청 수 | 41,912 |
비교: 단일 Redis → 서버 집중 → 서버 분산
| 지표 | CDC 이후 (단일 Redis) | 샤딩 (서버 1 집중) | 샤딩 (서버 분산) |
|---|---|---|---|
| 평균 | 35.6ms | 47.6ms (+34%) | 42.8ms (+20%) |
| P95 | 138ms | 197ms | 190ms |
| P99 | 294ms | 473ms | 398ms |
| 자동완성 | 10.4ms | 14.8ms | 11.7ms |
| 검색 | 25.7ms | 35.3ms | 29.2ms |
| 에러율 | 0% | 0% | 0% |
| 처리량 피크 | ~58 req/s | ~57 req/s | ~58 req/s |
서버 분산 효과: shard-2, shard-3을 서버 2로 옮기면서 CPU/메모리 경합 완화. 자동완성 14.8ms → 11.7ms로 CDC 이후 수준(10.4ms)에 근접 회복. 잔여 +7ms(35.6→42.8)는 분산 시스템의 본질적 비용, 곧 해시 라우팅, 다중 커넥션 풀, 서버 간 네트워크 왕복 때문이다.
“샤딩하면 빨라져야 하는 거 아닌가?”
아니다. 샤딩/멀티 인스턴스의 목적은 용량 확장, 워크로드 격리, 장애 격리이지 레이턴시 감소가 아니다. 같은 서버에서 인스턴스를 분리하면 커넥션 풀 관리, CPU 경합으로 오히려 오버헤드가 추가된다.
Redis Cluster 공식 스펙에서는 “N개 마스터 노드가 있으면 단일 인스턴스 대비 N배 성능을 기대할 수 있고, 레이턴시도 단일 노드와 동일”이라고 명시한다. 하지만 이는 별도 서버에 분산 배치한 경우다.
현업 사례:
- GitLab: Redis를 워크로드별로 분리하면서 커넥션 오버헤드 증가를 수용. 목적은 “Sidekiq 폴링이 캐시 읽기를 간섭하는 noisy-neighbor 제거”
- Shopify: 단일 Redis 공유로 전체 다운(“Redismageddon”) → Pod별 완전 격리 전환
+7ms의 trade-off 평가:
- 42.8ms는 Jakob Nielsen의 “즉각적” 임계값(100ms) 미만이라 사용자가 인지할 수 없다
- P95 190ms는 업계 표준(웹 API P95 < 200ms) 이내
- 에러율 0%, 처리량 동등(58 req/s)
- 얻은 것: KEYS 블로킹 제거, volatile-lru 보안 격리, 워크로드 분리, 노드 장애 시 1/3 부분 영향
12. Grafana 대시보드
Redis Shards (서버 분산 배치)
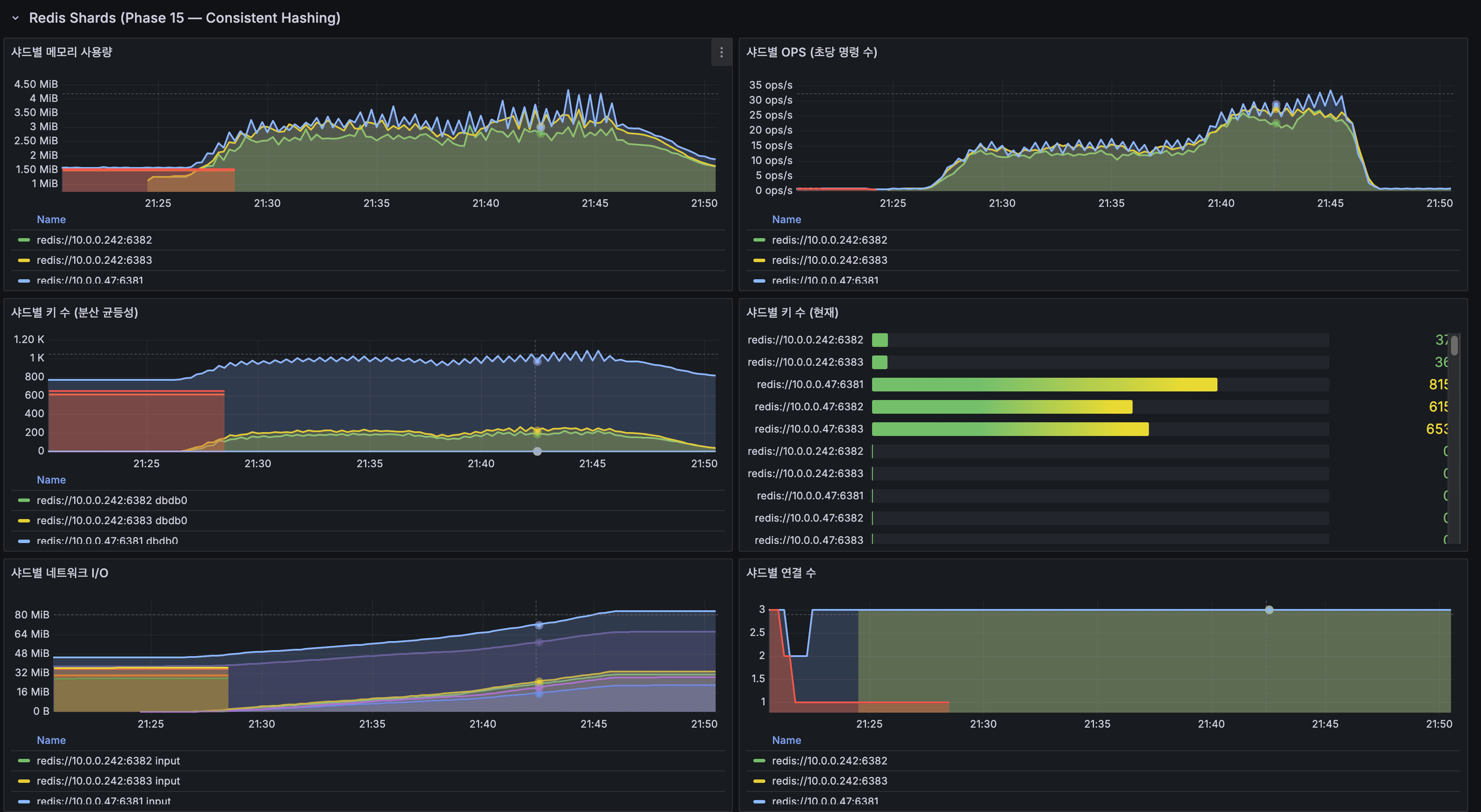
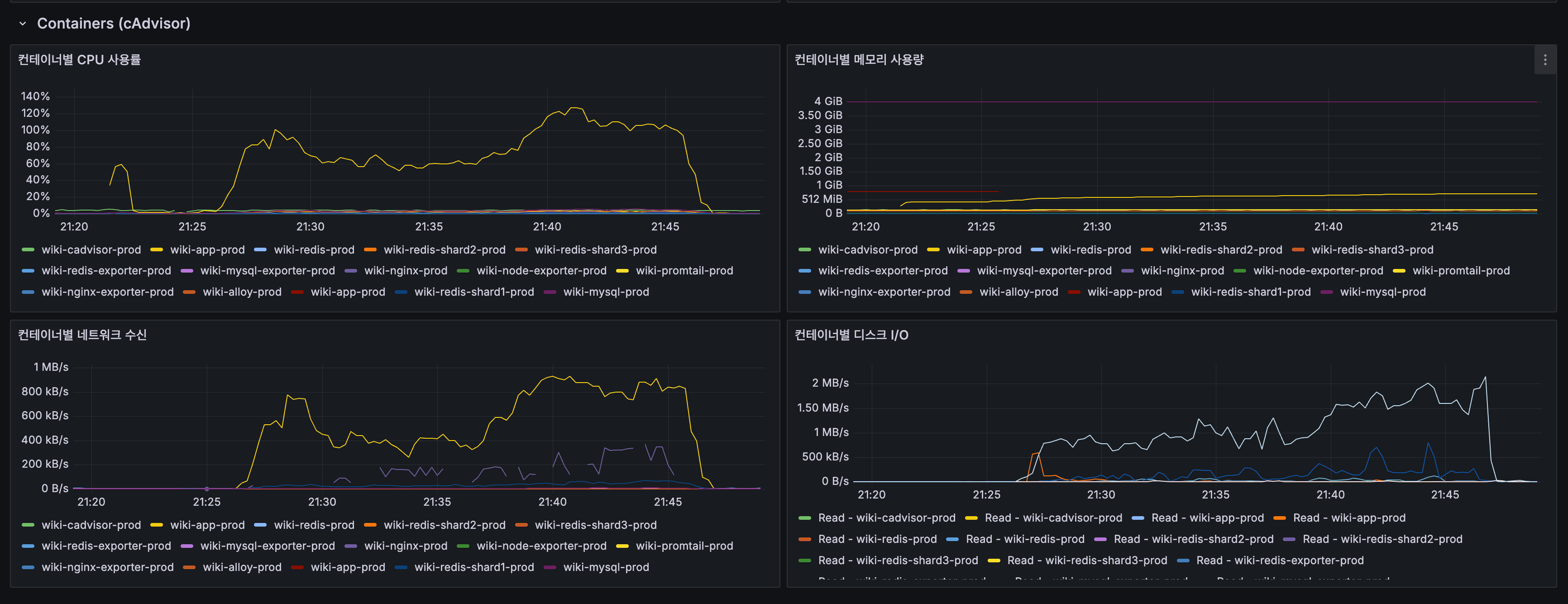
- shard-1 (서버 1): 키 815개
- shard-2 (서버 2): 키 37개 → 다음 배치 빌드 시 정상 분배
- shard-3 (서버 2): 키 36개 → 다음 배치 빌드 시 정상 분배
기존 Redis (블랙리스트 전용)
- 메모리: 0.597%, L2 히트율: 66.6%, Eviction: 0
Spring Boot
- HTTP 평균: 양쪽 인스턴스 ~50ms 이하
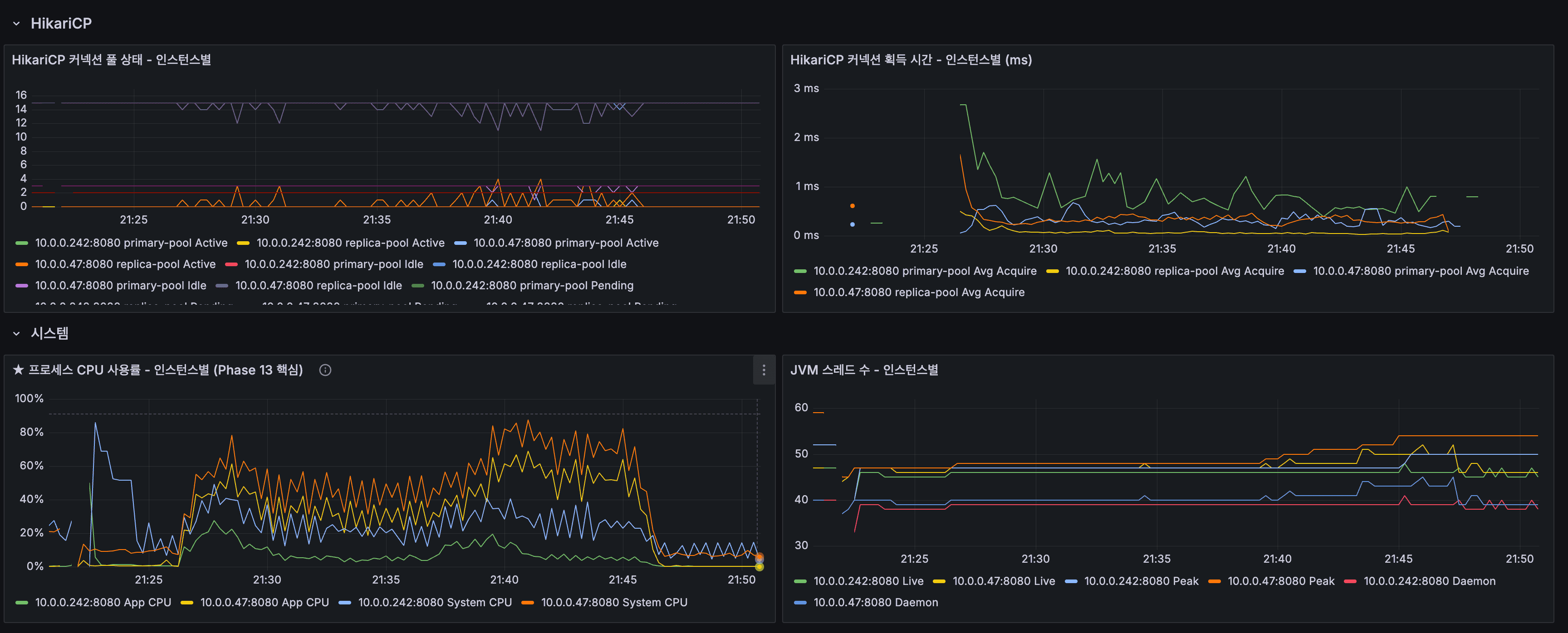
- App CPU: 서버 1 피크 ~80%, 서버 2 피크 ~40% (분산 효과)
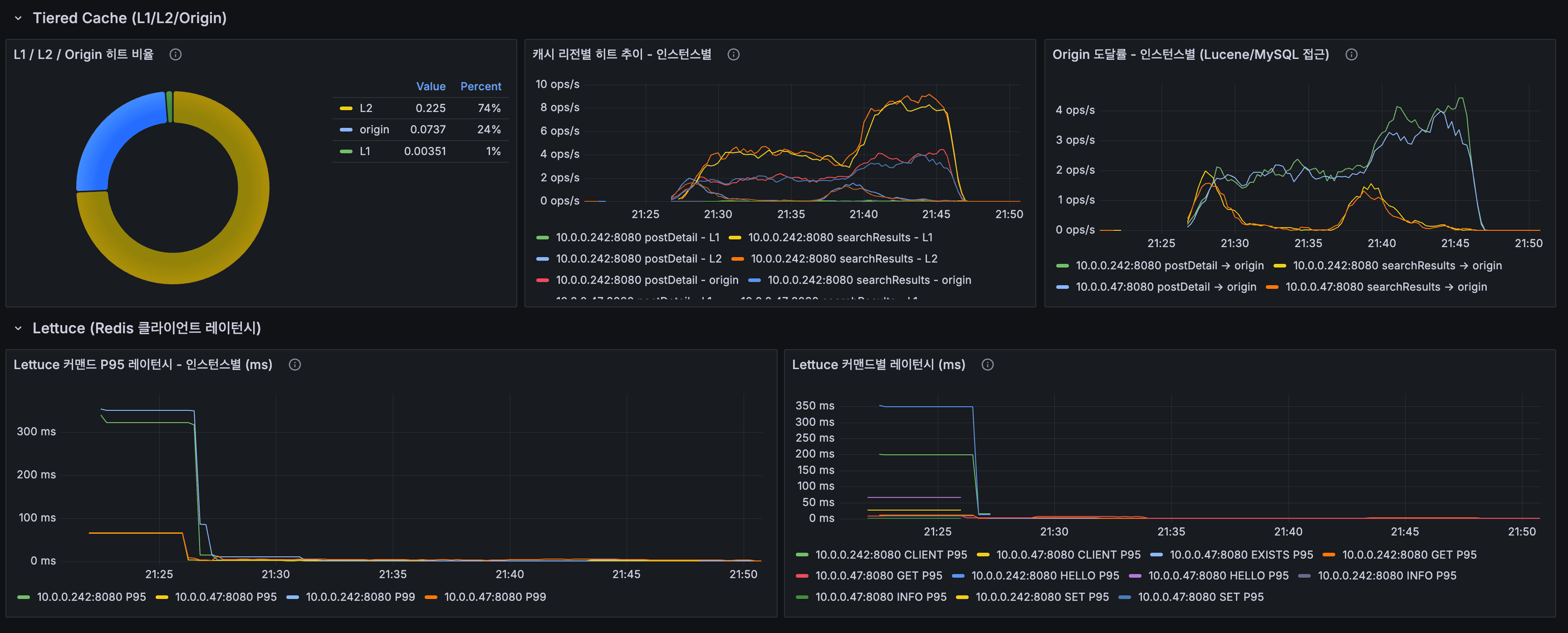
Tiered Cache + Lettuce
- L2 히트율: 74%, Origin: 24%, L1: 1%
- Lettuce P95: 안정 구간 ~5ms 이하
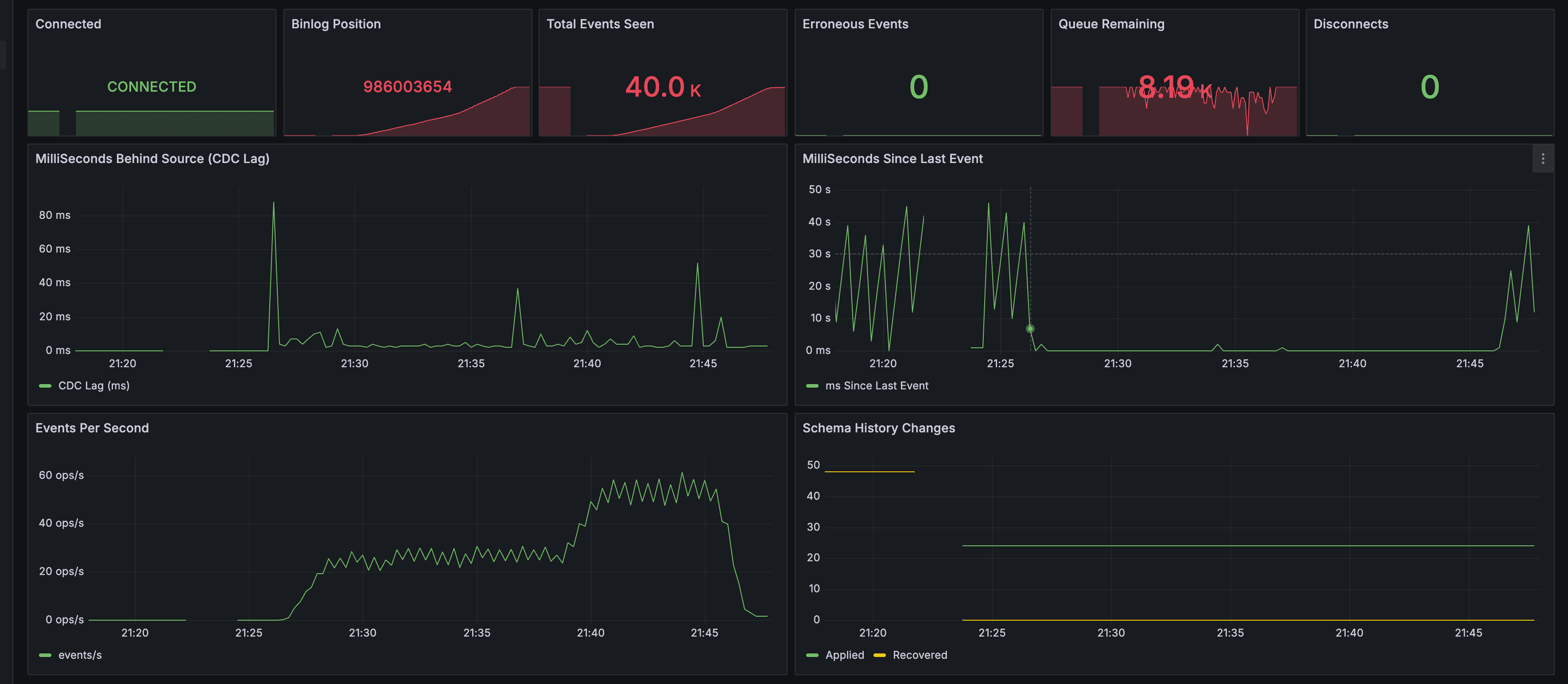
Debezium CDC
- Connected: CONNECTED, Erroneous Events: 0
- CDC Lag: ~80ms 이하로, Kafka/Debezium 메모리 축소 후에도 정상
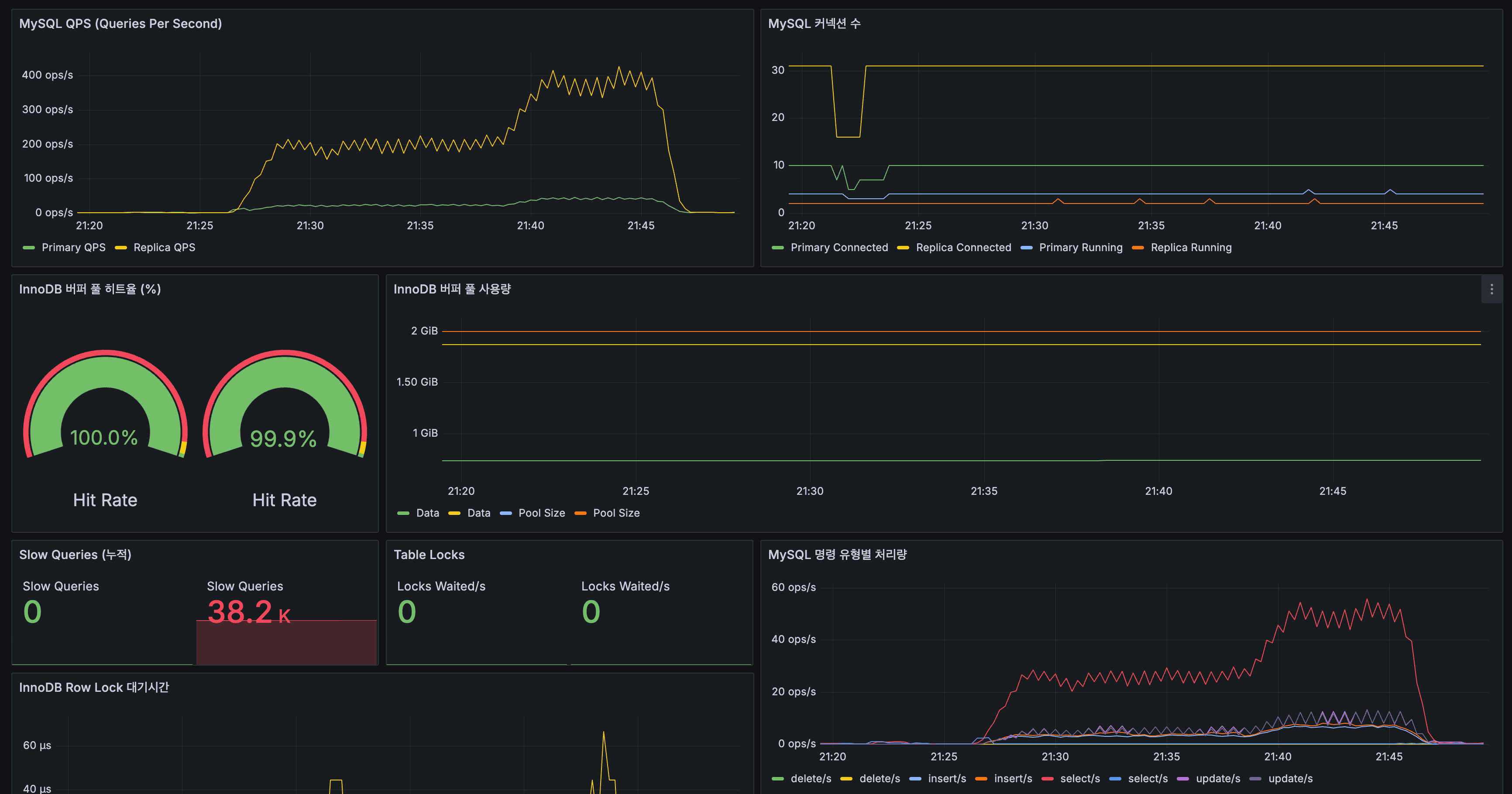
MySQL
- Primary QPS: 피크 ~400 ops/s
- InnoDB 히트율: Primary 100%, Replica 99.9%
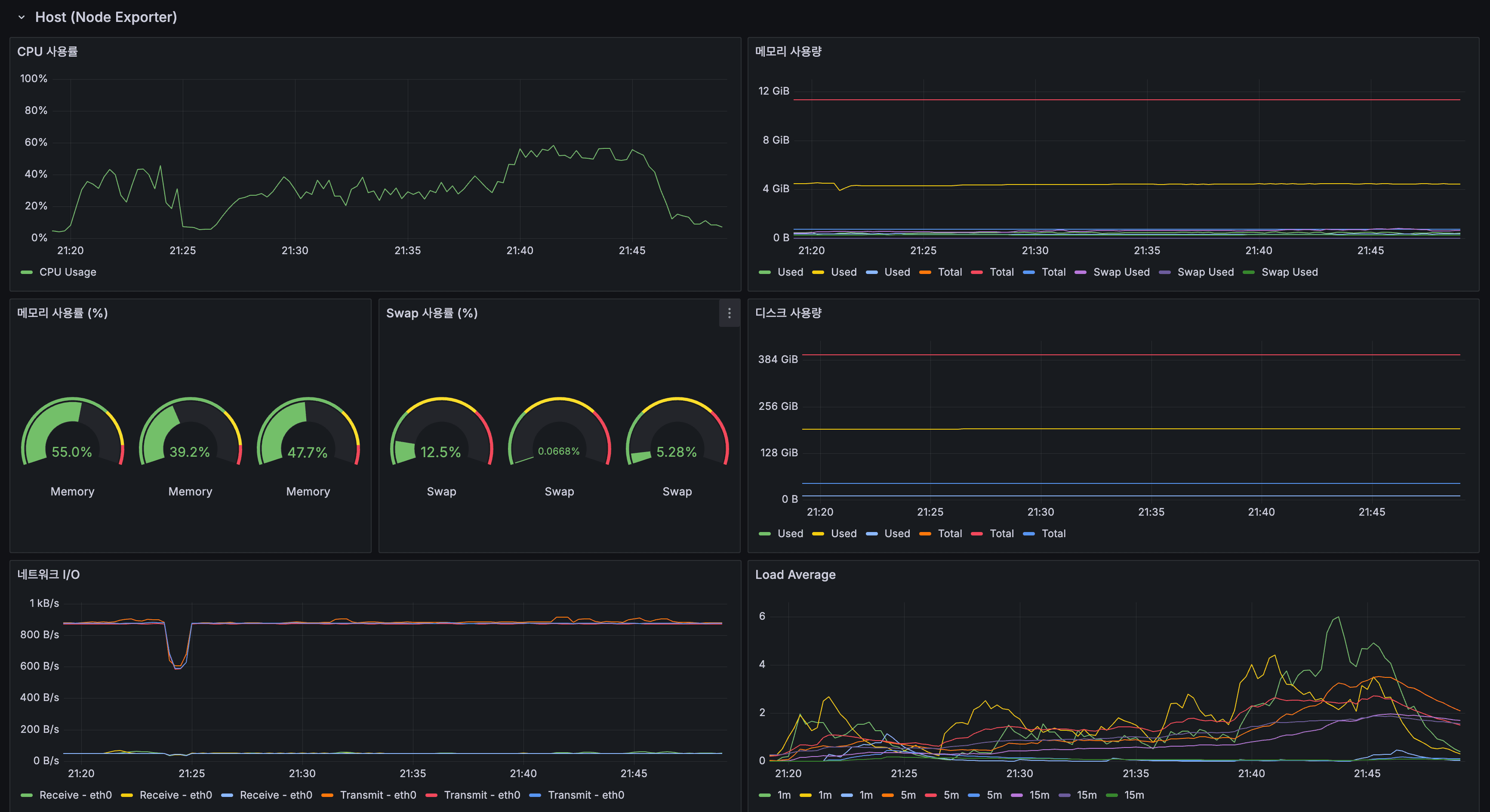
Host
- 서버 1 메모리: 55.0% (shard 2개 제거 효과)
- 서버 2 메모리: 39.2% (shard 2개 추가 + Kafka/Debezium 축소)
13. 성능 종합 비교
| 지표 | Before (단일 Redis) | After (SCAN + 3노드 분리) |
|---|---|---|
| flush 중 KEYS 블로킹 | 34.6ms (SLOWLOG) | 0ms (SCAN 비블로킹) |
| 배치 중 GET 최악 | 15.5ms (SLOWLOG) | 워크로드 분리로 해소 |
| 블랙리스트 eviction 위험 | 있음 (volatile-lru 대상) | 없음 (전용 인스턴스) |
| Redis 가용 메모리 | 128MB | 384MB (3 × 128MB) |
| 배치 쓰기 영향 범위 | 전체 워크로드 | 자동완성 노드만 |
| k6 100 VU 에러율 | 0% | 0% |
| k6 100 VU 평균 | 35.6ms | 42.8ms (+7ms, 분산 비용) |
| k6 100 VU P95 | 138ms | 190ms |
핵심 개선: 레이턴시 감소보다 워크로드 격리(배치↔실시간 분리), 안티패턴 제거(KEYS→SCAN), 보안 격리(블랙리스트 전용 인스턴스)에 있습니다. Consistent Hashing은 분리된 노드의 라우팅 계층으로서, 현재 구조에서 키 이동을 최소화하면서 용도별 분리를 유지할 수 있게 만든 선택이었습니다.
Previous Post
In CDC (Change Data Capture) — Event-Driven Synchronization, PostService’s dual-write architecture was converted to event-driven synchronization, and Debezium + Kafka CDC was used to capture all DB changes. This post covers identifying structural problems in a single Redis instance through actual measurements and isolating workloads with Consistent Hashing.
Previous Post Summary
| Metric | CDC Result |
|---|---|
| PostService Dependencies | 6 → Event publishing only (OCP compliant) |
| Search Cache Invalidation | Not implemented → Event-driven L1 immediate invalidation |
| Tests | 117 all passing |
| CDC Pipeline | MySQL binlog → Debezium → Kafka → Consumer |
| Architecture Pattern | @ApplicationModuleListener (fallback) + Kafka CDC (primary) |
Both infrastructure and architecture are stable. Now it’s time to resolve the workload interference and KEYS blocking anti-pattern in the single Redis instance.
1. Current Architecture — Single Redis Instance
A single Redis instance hosts four fundamentally different workloads:
| Purpose | Key Pattern | Estimated Key Count | Characteristics |
|---|---|---|---|
| Autocomplete KV | prefix:v{version}:{prefix} | Tens to hundreds of thousands | Batch refresh, TTL 2 hours |
| Post/Search Cache (L2) | post:{id}, search:{keyword}:{page}:{size} | Thousands of hot queries | TTL-based |
| View Counter | post:views:{id} | Number of viewed posts | Deleted after 30s flush |
| Token Blacklist | blacklist:{token} | Number of logouts | TTL = JWT remaining time |
2. Problem Identification — 3 Measured Evidence Points
Problem 1: KEYS Blocking Anti-Pattern — Redis Freezes Every 30 Seconds
Code executed every 30 seconds in ViewCountService.flushToDB():
Set<String> keys = redisTemplate.keys(KEY_PREFIX + "*"); // KEYS post:views:*Redis official documentation: “Don’t use KEYS in your regular application code. Consider it only for debugging purposes.”
KEYS performs an O(N) blocking scan of the entire keyspace. Since Redis is single-threaded, all GET/SET/INCR operations queue up while KEYS is running.
Measured Results (OCI ARM 2vCPU/12G, Redis 7.4-alpine, 2,041 keys):
| Command | Trial 1 | Trial 2 | Trial 3 | Redis Internal (SLOWLOG) |
|---|---|---|---|---|
KEYS post:views:* | 88ms | 46ms | 66ms | 34.6ms |
KEYS prefix:* | 48ms | 116ms | 46ms | — |
Shell measurements (46~116ms) include
docker execoverhead. The actual Redis internal time is 34.6ms per SLOWLOG — 3.4x above theslowlog-log-slower-than 10000(10ms) threshold, triggering a SLOWLOG entry. Since KEYS is O(N), 10x keys (20K) means ~350ms, 100x keys (200K) means ~3.5s — linear degradation.
Production Incident Cases:
- sidekiq-cron:
KEYS cron_jobs:*caused 5-6 second blocking → service down in a 40M key environment - Medusa (e-commerce):
KEYS mc:tag:*with 330K keys caused total Redis blocking, all clients waiting - Drupal Redis: Cache flush with 1.5M keys caused entire site freezing → migrated to SCAN patch
Problem 2: Batch Writes vs. Realtime Reads — Workload Interference
When buildPrefixTopK() SETs tens of thousands of keys hourly, it competes with realtime GET/INCR on the same single thread.
Measured Evidence (SLOWLOG + commandstats):
SLOWLOG recorded an individual SET during batch build at 10.7ms:
SLOWLOG #2: SET prefix:v1774134000041:scien ["science"] EX 7200 → 10,722us (10.7ms)The commandstats average for SET is 10.04us (0.01ms), making this 10.7ms 1,070x the average. A normal GET command was also caught in SLOWLOG:
SLOWLOG #1: GET prefix:v1774018800170:삼성 → 15,513us (15.5ms)This is 1,868x slower than the GET average of 8.30us — evidence that batch writes and realtime reads are contending on the same single thread.
redis-benchmark baseline (without batch):
| Command | Throughput | P50 |
|---|---|---|
| SET | 88,339 req/s | 0.231ms |
| GET | 104,602 req/s | 0.231ms |
At baseline, Redis itself is fast enough (GET P50 0.231ms). The problem is intermittent spikes of tens of milliseconds during KEYS/batch build.
Industry Cases:
- GitLab: During eviction, Redis main thread consumed most CPU, response rate dropped 25,000 → 5,000 ops/sec (80% decrease)
- Alibaba Cloud: Memory hit 100% in 5 minutes due to traffic surge, cascading eviction → all GET/SET timeouts
Problem 3: Lack of Per-Purpose Isolation — Blast Radius
| Workload | Characteristics | Risk |
|---|---|---|
| Autocomplete KV | Batch bulk WRITE (tens of thousands of keys) | Other workloads delayed during batch |
| Post/Search Cache (L2) | TTL-based, eviction allowed | Eviction affects other keys |
| View Counter | High-frequency INCR, 30s flush | KEYS scan blocks INCR |
| Token Blacklist | Security-critical, loss unacceptable | Blacklist keys with TTL are eviction candidates under volatile-lru |
Core Risk: With maxmemory-policy volatile-lru, when memory reaches 128MB, all keys with TTL become eviction candidates. Blacklist keys (blacklist:{token}) also have TTL, so if evicted, a logged-out token becomes valid again — a security incident.
Direct recommendation from Redis official documentation: “The volatile-lru, volatile-random policies are mainly useful when you want to use a single instance for both caching and persistent keys. However, it is usually a better idea to run two Redis instances to solve such a problem.”
Eviction Simulation Results (maxmemory temporarily reduced to used_memory + 1MB):
| Item | Result |
|---|---|
| evicted_keys | 2,077 |
| Blacklist Keys (Before) | 1 |
| Blacklist Keys (After) | 1 (survived this time) |
The blacklist key survived because it was recently accessed and ranked low in LRU eviction order. But this result depends on timing — after some time since logout, it would move up in LRU order and become an eviction candidate.
Key point: While 2,077 keys were evicted, there is no way to predict which keys will be removed. The blacklist surviving this time was luck, not a guarantee.
Common Root Cause of All 3 Problems: Workloads with fundamentally different characteristics share a single single-threaded Redis. Redis creator Salvatore Sanfilippo directly called separating DBs with SELECT on a single instance “the worst design mistake”.
3. Root Cause Analysis
Redis executes all commands sequentially on a single thread. This is the strength that guarantees INCR atomicity, but also the weakness where one slow command blocks everything.
| Problem | Cause | Solution Direction |
|---|---|---|
| KEYS blocking | O(N) full keyspace scan, no yielding mid-operation | KEYS → SCAN migration |
| Batch interference | Individual SETs tens of thousands of times without Pipeline → tens of thousands of network round trips | Per-purpose Redis instance separation |
| Blast radius | volatile-lru evicts TTL keys regardless of purpose | Dedicated blacklist instance |
4. Alternative Evaluation
Redis Cluster (Official Distribution)
Auto-sharding (16384 slots) + auto-failover — the production standard, but requires a minimum of 6 nodes ($144/month). Overkill for current scale (~60MB).
Redis Sentinel (Optimal for Current Scale)
Auto-failover + single Primary. The optimal choice when data fits in a single node’s memory and only HA is needed. ~$36/month.
Honest Admission: The most rational production choice at current scale is Redis Sentinel or keeping the current single instance. App-level Consistent Hashing is rarely used in production.
App-Level Consistent Hashing (Selected — Learning Purpose)
Redis Cluster handles CRC16-based 16384 slot distribution internally, so the hash ring, virtual nodes, and minimum key migration when adding nodes cannot be directly observed. The goal is to implement O(log N) routing with ConcurrentSkipListMap and measure distribution variance by virtual node count.
Cost Comparison (AWS Basis)
| Configuration | Monthly Cost (AWS) | Notes |
|---|---|---|
| Current (Single Redis) | ElastiCache t4g.micro ~$12/month | 128MB, single node |
| Redis Sentinel (Recommended) | ~$36/month | 1 Primary + 2 Replica |
| 3-Node Sharding (Selected) | ~$36/month + app routing management | Same cost with added operational burden |
| Redis Cluster | ~$144/month | 3P + 3R, overkill |
5. Consistent Hashing Algorithm
The Problem with hash(key) % N
Simple modulo hashing redistributes almost all keys when the node count changes:
| Scenario | hash(key) % N | Consistent Hashing |
|---|---|---|
| 3 → 4 nodes | ~75% key migration | ~25% key migration (1/N) |
| 4 → 3 nodes (failure) | ~75% key migration | ~25% key migration (1/N) |
Virtual Nodes
With only 3 physical nodes, the distribution on the hash ring is uneven. Each physical node is mapped to multiple virtual nodes for even distribution:
| Virtual Nodes | Key Distribution Variance | Keys Moved on Node Addition |
|---|---|---|
| 1 (no virtual nodes) | ~50% variance | Up to 50% |
| 50 | ~10% variance | ~1/N |
| 150 (selected) | ~5% variance | ~1/N |
| 500 | ~2% variance | ~1/N |
150 virtual nodes is the right balance between even distribution and memory (TreeMap entry count).
6. Implementation
Architecture — Hybrid (Consistent Hashing + Per-Purpose Isolation)
Data Routing Strategy
| Data | Routing Method | Reason |
|---|---|---|
Autocomplete KV (prefix:*) | Consistent Hashing | Highest key count, maximizes distribution benefit |
Post/Search Cache (post:{id}, search:*) | Consistent Hashing | Key-based distribution is natural |
View Count (post:views:{id}) | Consistent Hashing | Key-based distribution, SCAN on each node during flush |
Version Pointer (prefix:current_version) | Fixed Node (first in Ring) | Global metadata, only 1 exists |
Token Blacklist (blacklist:*) | Dedicated Instance (isolated) | Security-critical, cannot be sharded |
Token Blacklist Sharding Problem: If JWT tokens are distributed via Consistent Hashing, a node failure means the blacklist for that shard cannot be queried. Combined with a conservative policy (reject all tokens on failure), there’s a 1/3 chance of blocking all authentication. Therefore, the blacklist is safest without sharding.
ConsistentHashRouter Implementation
@Componentpublic class ConsistentHashRouter {
private final ConcurrentSkipListMap<Long, StringRedisTemplate> ring = new ConcurrentSkipListMap<>(); private final List<StringRedisTemplate> nodes; private static final int VIRTUAL_NODES = 150;
public ConsistentHashRouter(List<StringRedisTemplate> shardRedisTemplates) { this.nodes = shardRedisTemplates; for (int i = 0; i < nodes.size(); i++) { for (int v = 0; v < VIRTUAL_NODES; v++) { long hash = hash("node-" + i + "-vnode-" + v); ring.put(hash, nodes.get(i)); } } }
/** 키에 해당하는 Redis 노드 결정 (ConcurrentSkipListMap은 thread-safe) */ public StringRedisTemplate getNode(String key) { long hash = hash(key); Map.Entry<Long, StringRedisTemplate> entry = ring.ceilingEntry(hash); if (entry == null) { entry = ring.firstEntry(); // 링 순환 } return entry.getValue(); }
/** 모든 노드 반환 (SCAN 등 전체 조회 시) */ public List<StringRedisTemplate> getAllNodes() { return Collections.unmodifiableList(nodes); }
private long hash(String key) { return Hashing.murmur3_128() .hashString(key, StandardCharsets.UTF_8) .asLong() & 0x7FFFFFFFFFFFFFFFL; }}RedisShardConfig — Multiple LettuceConnectionFactory Configuration
@Configurationpublic class RedisShardConfig {
@Bean @Primary StringRedisTemplate stringRedisTemplate(RedisConnectionFactory connectionFactory) { // 기존 단일 인스턴스 유지 — 토큰 블랙리스트 등 비샤딩 용도 return new StringRedisTemplate(connectionFactory); }
@Bean List<StringRedisTemplate> shardRedisTemplates( @Value("${redis.shards[0].host}") String host1, @Value("${redis.shards[0].port}") int port1, @Value("${redis.shards[1].host}") String host2, @Value("${redis.shards[1].port}") int port2, @Value("${redis.shards[2].host}") String host3, @Value("${redis.shards[2].port}") int port3, @Value("${redis.password:}") String password) {
return List.of( createTemplate(host1, port1, password), createTemplate(host2, port2, password), createTemplate(host3, port3, password) ); }
private StringRedisTemplate createTemplate(String host, int port, String password) { RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(host, port); if (!password.isBlank()) { config.setPassword(password); } LettuceConnectionFactory factory = new LettuceConnectionFactory(config); factory.afterPropertiesSet(); return new StringRedisTemplate(factory); }}Impact on Existing Code
| File | Before | After |
|---|---|---|
RedisAutocompleteService | StringRedisTemplate redis (single) | ConsistentHashRouter router |
TieredCacheService | StringRedisTemplate redis (single) | ConsistentHashRouter router |
ViewCountService | StringRedisTemplate redisTemplate (single) | ConsistentHashRouter router |
RedisTokenBlacklist | StringRedisTemplate redisTemplate (single) | No change (keeps existing single Redis) |
The change pattern is identical across all files:
// Before (single Redis)redis.opsForValue().get(key);
// After (Consistent Hashing)router.getNode(key).opsForValue().get(key);7. KEYS → SCAN Migration
// BeforeSet<String> keys = redisTemplate.keys(KEY_PREFIX + "*"); // KEYS — O(N) blocking
// AfterScanOptions options = ScanOptions.scanOptions().match(KEY_PREFIX + "*").count(1000).build();try (Cursor<String> cursor = redisTemplate.scan(options)) { // SCAN — cursor-based, non-blocking while (cursor.hasNext()) { ... }}| Before (KEYS) | After (SCAN) | |
|---|---|---|
| SLOWLOG (10ms threshold) | KEYS post:views:* 34.6ms recorded | No entries (under 10ms) |
| Full Tests | 117 passing | 117 passing |
After SLOWLOG RESET, waited 90 seconds (3 flushToDB executions) → SLOWLOG GET 10 result was empty. The KEYS blocking anti-pattern has been completely eliminated.
8. 3-Node Separation + ConsistentHashRouter Deployment
Deployment Result: 3 Redis shard containers healthy + App started successfully
wiki-app-prod Up 3 minuteswiki-redis-shard3-prod Up 14 minutes (healthy)wiki-redis-shard2-prod Up 14 minutes (healthy)wiki-redis-shard1-prod Up 14 minutes (healthy)Distribution Uniformity Test
| Timing | shard-1 | shard-2 | shard-3 | original redis |
|---|---|---|---|---|
| Right after deployment (before batch build) | 0 | 0 | 0 | 1,050 |
| After batch build (1st run) | 369 | 304 | 347 | 1,022 |
| After batch build (2nd run) | 751 | 607 | 682 | 1,022 |
Shard total: 2,040 keys (751 + 607 + 682). Variance: min 607 / max 751 = 19.2% — Consistent Hashing working correctly with 3 nodes x 150 virtual nodes.
Autocomplete working correctly:
curl /posts/autocomplete?prefix=science → ["science"]curl /posts/autocomplete?prefix=삼성 → ["삼성전자"]After redis-benchmark
| Command | Before (single) | After (shard-1) | Difference |
|---|---|---|---|
| GET | 104,602 req/s, P50 0.231ms | 104,166 req/s, P50 0.231ms | Equal |
| SET | 88,339 req/s, P50 0.231ms | 71,428 req/s, P50 0.239ms | -19% (container resource sharing) |
No performance degradation from sharding. GET P50 identical (0.231ms). The SET throughput decrease is due to 4 Redis containers running simultaneously on the same server, sharing CPU/memory. Since each shard handles 1/3 of actual SET load, this is not an issue.
9. Node Failure Fallback
docker stop wiki-redis-shard2-prod→ curl /posts/autocomplete?prefix=science→ Normal response: 10 results returned via Lucene PrefixQuery fallback→ Keys on shard-2 result in cache miss → Lucene responds instead→ docker start wiki-redis-shard2-prod → Recovery confirmed10. Hotspot Problem and Shard Manager
Hotspot Problem
Sharding is effective for data distribution but insufficient for load distribution:
- 1-character prefixes (“wi”, “de”, “ha”) are queried tens of times more than 3-character prefixes
- Certain prefixes see explosive popularity spikes due to events/seasons
- → The shard containing those keys becomes a hotspot, creating a performance bottleneck
Dynamic Replication
A solution inspired by Meta’s Shard Manager:
| # | Responsibility | Description |
|---|---|---|
| 1 | Data Distribution | Distribute data across shards via Consistent Hashing |
| 2 | Dynamic Replication Management | Monitor each shard’s load and dynamically add/remove read replicas |
| 3 | Minimum Node Guarantee | Maintain a minimum number of healthy nodes per shard for high availability |
Key Point: Consistent Hashing solves the data distribution problem, and dynamic replication solves the load distribution problem. These are separate problems, and sharding alone cannot prevent hotspots.
11. Load Test — k6 100 VU, 20 Minutes
k6 Smoke Test (5 VU, 2 Minutes)
| Scenario | Average | P95 |
|---|---|---|
| Overall | 105ms | 490ms |
| Autocomplete | 35ms | 61ms |
| Latest Posts | 37ms | 62ms |
| Detail View | 25ms | 44ms |
| Error Rate | 0.00% |
k6 LOAD Test — Server-Distributed Deployment (100 VU, 20 Minutes, Final)
shard-2 and shard-3 moved from Server 1 → Server 2 + Kafka/Debezium memory reduced, then re-measured.
| Scenario | Average | P95 |
|---|---|---|
| Overall | 42.81ms | 190.44ms |
| Search (All) | 29.18ms | 100.85ms |
| Search (Rare 10%) | 22.79ms | 89.72ms |
| Search (Medium 60%) | 19.14ms | 88.82ms |
| Search (High-frequency 30%) | 51.28ms | 200.45ms |
| Autocomplete | 11.68ms | 68.44ms |
| Latest Posts | 18.61ms | 80.39ms |
| Detail View | 25.80ms | 92.38ms |
| Write (Create + Like) | 25.94ms | 94.41ms |
| Error Rate | 0.00% | |
| Total Requests | 41,912 |
Comparison — Single Redis → Server-Concentrated → Server-Distributed
| Metric | After CDC (Single Redis) | Sharding (Server 1 Concentrated) | Sharding (Server-Distributed) |
|---|---|---|---|
| Average | 35.6ms | 47.6ms (+34%) | 42.8ms (+20%) |
| P95 | 138ms | 197ms | 190ms |
| P99 | 294ms | 473ms | 398ms |
| Autocomplete | 10.4ms | 14.8ms | 11.7ms |
| Search | 25.7ms | 35.3ms | 29.2ms |
| Error Rate | 0% | 0% | 0% |
| Peak Throughput | ~58 req/s | ~57 req/s | ~58 req/s |
Server distribution effect: Moving shard-2 and shard-3 to Server 2 reduced CPU/memory contention. Autocomplete improved from 14.8ms → 11.7ms, approaching the post-CDC level (10.4ms). The remaining +7ms (35.6→42.8) is the inherent cost of distributed systems — hash routing, multiple connection pools, and inter-server network round trips.
“Shouldn’t sharding make things faster?”
No. The purpose of sharding/multi-instance is capacity scaling, workload isolation, and fault isolation — not latency reduction. Splitting instances on the same server actually adds overhead from connection pool management and CPU contention.
The Redis Cluster official spec states: “With N master nodes you can expect N times the performance of a single instance, and latency equal to a single node.” However, this assumes deployment on separate servers.
Industry cases:
- GitLab: Accepted increased connection overhead when separating Redis by workload. The goal was “removing the noisy-neighbor problem where Sidekiq polling interferes with cache reads”
- Shopify: Shared single Redis caused total downtime (“Redismageddon”) → migrated to per-pod complete isolation
+7ms Trade-off Assessment:
- 42.8ms is below Jakob Nielsen’s “instantaneous” threshold (100ms) — imperceptible to users
- P95 190ms is within industry standards (web API P95 < 200ms)
- Error rate 0%, equivalent throughput (58 req/s)
- Gained: KEYS blocking elimination, volatile-lru security isolation, workload separation, 1/3 partial impact on node failure
12. Grafana Dashboard
Redis Shards (Server-Distributed Deployment)
- shard-1 (Server 1): 815 keys
- shard-2 (Server 2): 37 keys → Will be properly distributed on next batch build
- shard-3 (Server 2): 36 keys → Will be properly distributed on next batch build
Original Redis (Blacklist Dedicated)
- Memory: 0.597%, L2 Hit Rate: 66.6%, Eviction: 0
Spring Boot
- HTTP Average: Both instances under ~50ms
- App CPU: Server 1 peak ~80%, Server 2 peak ~40% (distribution effect)
Tiered Cache + Lettuce
- L2 Hit Rate: 74%, Origin: 24%, L1: 1%
- Lettuce P95: Stable range under ~5ms
Debezium CDC
- Connected: CONNECTED, Erroneous Events: 0
- CDC Lag: Under ~80ms — Normal even after Kafka/Debezium memory reduction
MySQL
- Primary QPS: Peak ~400 ops/s
- InnoDB Hit Rate: Primary 100%, Replica 99.9%
Host
- Server 1 Memory: 55.0% (effect of removing 2 shards)
- Server 2 Memory: 39.2% (added 2 shards + Kafka/Debezium reduced)
13. Overall Performance Comparison
| Metric | Before (Single Redis) | After (SCAN + 3-Node Separation) |
|---|---|---|
| KEYS blocking during flush | 34.6ms (SLOWLOG) | 0ms (SCAN non-blocking) |
| Worst GET during batch | 15.5ms (SLOWLOG) | Resolved by workload separation |
| Blacklist eviction risk | Present (volatile-lru target) | None (dedicated instance) |
| Redis available memory | 128MB | 384MB (3 x 128MB) |
| Batch write blast radius | All workloads | Autocomplete nodes only |
| k6 100 VU error rate | 0% | 0% |
| k6 100 VU average | 35.6ms | 42.8ms (+7ms, distribution cost) |
| k6 100 VU P95 | 138ms | 190ms |
Key Improvement: Not latency reduction, but workload isolation (batch vs. realtime separation), anti-pattern elimination (KEYS→SCAN), and security isolation (dedicated blacklist instance). Consistent Hashing serves as the routing layer for separated nodes and keeps key redistribution limited when nodes are added later.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.