App 스케일아웃: Nginx L7 로드밸런싱 + Lucene Replica
목차
이전 글
MySQL Replication: R/W 분리와 DataSource 라우팅에서 MySQL Replication으로 읽기/쓰기를 분리하고, Spring AbstractRoutingDataSource + LazyConnectionDataSourceProxy로 자동 라우팅을 구현했습니다.
이전 글 요약
| 지표 | Replication 결과 |
|---|---|
| R/W 분리 | Primary ~50 ops/s (쓰기), Replica ~200 ops/s (읽기) |
| HikariCP | Primary 5 (Active 0~2), Replica 15 (Active 3~5) |
| Replication Lag | 0~1초 (부하 시) |
| Tiered Cache | L1 55% + L2 3% = 58% 히트, Origin 42% |
| App CPU (100 VU 피크) | ~100% (2코어 기준) ← 병목 |
| 에러율 (100 VU) | 13.25% |
| P95 | 2,300ms |
DB는 여유 있지만(Primary Slow Query 0건, InnoDB 히트율 99.5%), 앱 CPU가 100%에 도달하여 에러율 13.25%가 발생하고 있습니다. 이 글에서 App 인스턴스를 2대로 확장하여 CPU 병목을 해소합니다.
왜 스케일아웃이 필요한가
App CPU가 병목이다: 데이터 근거
stress 테스트와 Replication(After 측정)에서 일관되게 확인된 병목:
| 지표 | stress 테스트 (200 VU) | Replication (100 VU) | 판단 |
|---|---|---|---|
| App CPU | ~100% | ~100% | 병목 |
| MySQL CPU | 거의 0% | 거의 0% | 여유 |
| InnoDB 버퍼 풀 히트율 | 100% | 99.5% | I/O 병목 없음 |
| HikariCP Acquire | 1,250ms (200 VU) | < 1ms (100 VU) | CPU 포화의 증상 |
| Redis Lettuce P95 | - | ~3ms | 여유 |
stress 테스트 문서에서도 “HikariCP Active 60+는 풀이 부족해서가 아니라 CPU 포화로 요청 처리가 느려져 커넥션 점유 시간이 길어진 것”이라고 분석했습니다. 병목은 App CPU(Lucene BM25 스코어링 + Nori 형태소 분석)입니다.
CPU 소비 내역 (Lucene 검색 경로):

스케일아웃의 효과 추정:

대안 검토: 스케일아웃 외에 선택지는 없는가?
| 대안 | 검토 결과 | 판단 |
|---|---|---|
| JVM 튜닝 (GC, 힙) | stress 테스트에서 이미 G1 GC + -Xmx1g 튜닝 완료. GC Pause는 P99 기여 ~5ms 수준으로 미미 | 탈락 (이미 완료) |
| Lucene 쿼리 최적화 | BM25 + FeatureField + Recency Decay는 이미 최적화된 구조. 추가 최적화 여지 제한적 | 탈락 (이미 최적화) |
| 캐시 히트율 더 올리기 | L1+L2 합산 58%, Origin 42%. 나머지는 cold query + 롱테일 분포라 캐시로 더 줄이기 어려움 | 탈락 (한계) |
| 스케일업 (CPU 추가) | Oracle Cloud 서버 스펙 변경 불가 (ARM 2코어 고정) | 탈락 (인프라 제약) |
| App 스케일아웃 | 서버 2에 App 2 배포 → CPU 2코어 추가 → 읽기 부하 분산 | 선택 |
전제조건 확인
스케일아웃을 위한 사전 준비가 모두 완료되었습니다:
Redis L2 캐시 → 앱 Stateless 전환 (캐시/자동완성 Redis 공유) 완료Replication → DB 읽기 분리 (App 2대 시 DB 부하 분산) 완료App 스케일아웃 → 앱 인스턴스 확장 (CPU 분산) ← 지금| 전제조건 | 상태 | 없으면 |
|---|---|---|
| Redis L2 캐시 | 완료 | App 간 캐시 불일치 → 히트율 절반 |
| 자동완성 flat KV (Redis) | 완료 | App별 Trie 독립 → 메모리 중복, 불일치 |
| MySQL Replication | 완료 | App 2대 × HikariCP 20 = 40 커넥션이 단일 MySQL에 집중 |
| TokenBlacklist Redis 전환 | 미완료 | App 1에서 로그아웃한 토큰을 App 2가 모름 → 보안 구멍 |
TokenBlacklist가 유일한 미완료 전제조건입니다. 현재 Caffeine(로컬 메모리)으로 구현되어 있으며, 코드 주석에도 “다중 서버 환경에서는 Redis 등 외부 저장소로 교체가 필요하다”고 명시되어 있습니다.
아키텍처
서버 토폴로지

요청 흐름

Lucene 인덱스 동기화 전략
App 2대에서 Lucene을 운영하는 핵심 도전은 인덱스 동기화입니다. MySQL은 Replication으로 자동 동기화되지만, Lucene은 로컬 파일 기반이므로 별도 전략이 필요합니다.
방식 검토:
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Elasticsearch | 샤드 복제 자동 처리, 운영 부담 없음 | 메모리 최소 4GB, 현재 자원 제약에서 과중 | 탈락 (아래 상세) |
| 공유 파일시스템 (NFS/OCI FSS) | 단일 인덱스, 항상 일관, rsync 불필요 | 네트워크 I/O per search (MMap 성능 저하) | 탈락 (아래 상세) |
| 오브젝트 스토리지 (S3/OCI) | 스냅샷 저장 + 각 서버 pull | 29GB 매번 다운로드 비효율 | 탈락 |
| 양쪽 독립 쓰기 | 코드 변경 최소 | 인덱스 불일치 (App 1 쓰기 ↔ App 2 쓰기) | 탈락 (일관성 문제) |
| Redis Pub/Sub 알림 | 거의 실시간 동기화 | dual-write, 향후 CDC와 역할 중복 | 검토 (향후) |
| 쓰기 App 1 고정 + rsync | 단순, 단일 writer, MySQL Primary-Replica와 동일 패턴 | 최대 5분 stale | 선택 |
비슷한 상황에서 검토할 수 있는 대안, 왜 이 프로젝트에서 ES/NFS를 쓰지 않는가:
현업에서 멀티 노드 검색을 운영할 때 가장 일반적인 방법은 Elasticsearch입니다. ES는 내부적으로 Lucene 기반이지만, 샤드 복제/리밸런싱/장애 복구를 프레임워크가 자동 처리하므로 인덱스 동기화를 개발자가 직접 다룰 필요가 없습니다. 두 번째로 공유 파일시스템(AWS EFS, OCI FSS)을 양쪽 서버에 NFS 마운트하여 하나의 인덱스를 공유하는 방식이 있습니다.
이 프로젝트에서 두 방식을 쓰지 않는 이유:
| 방식 | 장점 | 이 프로젝트에서 쓰지 않는 이유 |
|---|---|---|
| Elasticsearch | 샤드 복제 자동, REST API, 운영 도구 풍부 | ① ES 최소 메모리 4GB라 자원 부족 ② MySQL→검색엔진 동기화 문제는 여전히 별도 관리 필요 ③ 현재 규모에서는 검색 클러스터 운영 비용이 App 2대 확장의 목적보다 큼 |
| NFS/OCI FSS | 단일 인덱스, rsync 불필요 | ① Lucene MMapDirectory는 OS 페이지 캐시에 의존하는데, NFS 위에서는 매 검색 I/O마다 네트워크 왕복 발생, BM25 스코어링 시 랜덤 I/O 누적으로 성능 수 배 저하 (Lucene JIRA LUCENE-673, Atlassian 공식 경고) ② OCI FSS는 월 ~$3 비용 발생 |
Yelp nrtsearch 사례: Yelp는 프로덕션에서 raw Lucene 기반 검색 시스템(nrtsearch)을 운영합니다. “dedicated primary/writer node that takes care of indexing operations and expensive operations like segment merges, allowing the replicas’ system resources to be dedicated entirely for search queries”. Replica는 “sync with the current primary and update their indexes using Lucene’s NRT APIs”로 동기화합니다 (Yelp Engineering Blog). 이 프로젝트의 Primary/Replica 패턴과 동일한 구조입니다.
이 프로젝트의 판단 기준: 이 시점의 목적은 검색 클러스터를 새로 운영하는 것이 아니라, 현재 자원 안에서 App CPU 병목을 나누면서도 검색 인덱스 일관성을 유지하는 것이었습니다. raw Lucene을 유지하면 인덱스 생명주기와 동기화 시점을 애플리케이션에서 직접 제어할 수 있고, 별도 검색 프로세스 없이 현재 자원 안에서 목적을 달성할 수 있었습니다. 반대로 Elasticsearch는 동기화 문제를 완전히 없애주지 않으면서도 메모리와 운영 복잡도를 더 크게 늘리는 선택이었습니다.
CI/CD와 데이터 동기화는 별개 파이프라인: GitHub Actions CI/CD는 코드를 배포하는 것이지, 데이터(Lucene 인덱스 29GB)를 배포하는 것이 아닙니다. 인덱스 데이터 동기화는 rsync cron이라는 별도 파이프라인으로 처리하며, 이는 MySQL Replication이 CI/CD와 별개인 것과 같은 원리입니다.
“쓰기 App 1 고정 + rsync” 선택 근거:
-
MySQL Primary-Replica와 동일한 사고 모델: App 1이 Lucene Primary(쓰기+읽기), App 2가 Lucene Replica(읽기 전용). Replication에서 이미 검증한 패턴.
-
stale 허용 가능: 커뮤니티 게시판에서 검색 결과가 5분 늦게 반영되는 것은 UX에 영향 없음. Replication에서 Replication Lag 수 초를 허용한 것과 같은 논리.
-
Origin 42%만 Lucene 조회: 캐시 히트(L1+L2 58%)된 요청은 Lucene을 타지 않으므로, 실제 stale 영향은 전체 요청의 42% x 5분 stale 확률.
-
향후 CDC에서 개선: 향후 MySQL binlog 기반 이벤트를 도입하면, Lucene 인덱스도 이벤트 기반으로 실시간 동기화할 수 있습니다. 이 글에서는 rsync로 충분합니다.
rsync 동기화 상세:

rsync 안전성: SnapshotDeletionPolicy 기반
rsync는 파일 복사 순서를 보장하지 않습니다. 단순 rsync만으로는 segments_N이 세그먼트 파일보다 먼저 복사될 수 있고, 이 경우 App 2의 maybeRefresh()가 아직 없는 세그먼트를 참조하여 IOException이 발생합니다.
Lucene 커미터 Mike McCandless의 권고: “You must first close the IndexWriter when using rsync, else the copy can be corrupt.” (Lucene’s NRT segment index replication). 또는 SnapshotDeletionPolicy를 사용하여 일관된 스냅샷을 잡은 후 rsync해야 합니다.

동기화 스크립트 (cron, 5분 주기):
#!/bin/bash# lucene-sync.sh — App 1 → App 2 Lucene 인덱스 동기화# SnapshotDeletionPolicy (세그먼트 삭제 방지) + Refresh Pause (레이스 컨디션 방지)
PRIMARY_HOST="{{ hostvars['app-arm'].private_ip }}"LUCENE_PATH="/data/lucene"APP2_LOCAL="http://localhost:8080"
# 1. App 2 refresh 일시 중단 (rsync 중 maybeRefresh 차단 — LUCENE-628 대응)curl -sf -X POST ${APP2_LOCAL}/internal/lucene/pause-refresh || true
# 2. App 1에 Lucene commit + snapshot 요청SNAPSHOT_GEN=$(curl -sf -X POST http://${PRIMARY_HOST}:8080/internal/lucene/snapshot)if [ -z "$SNAPSHOT_GEN" ]; then echo "$(date) ERROR: snapshot 요청 실패" >&2 curl -sf -X POST ${APP2_LOCAL}/internal/lucene/resume-refresh || true exit 1fi
# 3. rsync (SSH 키 인증 사용 — Step 4에서 설정)rsync -az --delete \ --exclude='write.lock' \ ${PRIMARY_HOST}:${LUCENE_PATH}/ ${LUCENE_PATH}/
# 4. App 1 snapshot 해제curl -sf -X DELETE "http://${PRIMARY_HOST}:8080/internal/lucene/snapshot/${SNAPSHOT_GEN}" || true
# 5. App 2 refresh 재개 + 즉시 refresh (rsync 완료 후이므로 안전)curl -sf -X POST ${APP2_LOCAL}/internal/lucene/resume-refresh || true
echo "$(date) OK: sync completed (snapshot gen=${SNAPSHOT_GEN})"
--exclude='write.lock': App 2는 IndexWriter가 없으므로 write.lock 불필요. rsync로 전송 시 App 2에서 락 충돌 방지.
Nginx 로드밸런싱 전략
현재 Nginx는 단일 upstream app:8080만 사용합니다. 이 글에서 HTTP 메서드 기반 라우팅으로 읽기/쓰기를 분리합니다.
현재: upstream app { server app:8080; } → 모든 요청 → App 1
App 스케일아웃: upstream app_read { server app:8080; server {{ app2_ip }}:8080; } ← 양쪽 분산 upstream app_write { server app:8080; } ← App 1 고정
map $request_method → GET/HEAD/OPTIONS → app_read → POST/PUT/DELETE → app_writemap 기반 라우팅 선택 근거: Nginx의 if 디렉티브는 location 블록 내에서 예측 불가능한 동작을 하므로(“if is evil”, Nginx 공식 위키), map 디렉티브로 변수를 미리 설정한 후 proxy_pass에서 사용합니다. map은 설정 로드 시 해시 테이블을 컴파일하고, 요청 시 O(1) 해시 lookup으로 변수를 평가합니다(lazy evaluation). if 디렉티브의 예측 불가능한 동작 대비 안전하고 성능도 무시 가능한 수준입니다.
로드밸런싱 알고리즘: least_conn
| 알고리즘 | 동작 | 적합 케이스 | 판단 |
|---|---|---|---|
| round-robin (기본) | 순차 분배 | 균일한 요청 처리시간 | 부적합 (검색 vs 캐시 히트 차이 큼) |
| least_conn | 활성 커넥션 적은 쪽으로 | 요청별 처리시간 편차 큰 경우 | 선택 |
| ip_hash | IP 기반 고정 | 세션 유지 필요 시 | 불필요 (JWT stateless) |
검색 요청(Lucene BM25)은 수십~수백 ms, 캐시 히트 요청은 ~1ms로 처리시간 편차가 크므로, least_conn이 가장 균등하게 분배합니다.
TokenBlacklist Redis 전환
현재 TokenBlacklist는 Caffeine(로컬 메모리)으로 구현되어 있습니다. 멀티 인스턴스에서는 App 1에서 로그아웃한 토큰을 App 2가 모르는 보안 문제가 발생합니다.
문제 시나리오: 1. 사용자 로그아웃 → App 1이 토큰을 Caffeine 블랙리스트에 추가 2. 같은 토큰으로 요청 → Nginx가 App 2로 라우팅 3. App 2의 Caffeine에는 블랙리스트 없음 → 토큰 유효로 판단 4. 로그아웃된 토큰으로 API 접근 성공 → 보안 구멍
해결: TokenBlacklist를 Redis로 전환 → App 1, App 2 모두 같은 Redis를 조회 → 로그아웃 즉시 양쪽에서 차단구현 방안:
TokenBlacklist인터페이스 추출 (add,isBlacklisted)RedisTokenBlacklist구현 (Redis SET + TTL)- 기존 Caffeine 구현은 제거 (단일 서버 환경이 끝났으므로)
// 인터페이스 추출public interface TokenBlacklist { void add(String token); boolean isBlacklisted(String token);}
// Redis 구현@Componentpublic class RedisTokenBlacklist implements TokenBlacklist { private final StringRedisTemplate redisTemplate; private final JwtTokenProvider jwtTokenProvider;
private static final String KEY_PREFIX = "blacklist:";
@Override public void add(String token) { // TTL = JWT가 만료되기까지 "남은 시간" (전체 만료시간이 아님) // 예: JWT 30분짜리를 발급 20분 후에 로그아웃 → TTL = 10분 Date expiration = jwtTokenProvider.getExpiration(token); Duration remainingTtl = Duration.between(Instant.now(), expiration.toInstant()); if (remainingTtl.isPositive()) { redisTemplate.opsForValue() .set(KEY_PREFIX + token, "1", remainingTtl); } // 이미 만료된 토큰이면 블랙리스트 추가 불필요 (어차피 검증에서 거부됨) }
@Override public boolean isBlacklisted(String token) { try { return Boolean.TRUE.equals(redisTemplate.hasKey(KEY_PREFIX + token)); } catch (RedisConnectionFailureException e) { // Redis 장애 시 보수적 판단: 블랙리스트 확인 불가 → 토큰 거부 (보안 우선) log.warn("Redis 연결 실패 — 블랙리스트 확인 불가, 토큰 거부 (보안 우선): {}", e.getMessage()); return true; } }}TTL = “남은 시간”인 이유: JWT 전체 만료시간(예: 30분)을 TTL로 설정하면, 발급 25분 후에 로그아웃한 토큰이 Redis에 25분간 불필요하게 남습니다. “남은 시간”(예: 5분)으로 설정하면 JWT가 자연 만료되는 시점에 Redis에서도 자동 제거되어 메모리를 최적으로 사용합니다. 이 패턴은 SuperTokens, Baeldung 등에서 JWT 블랙리스트의 표준 구현으로 권장됩니다.
Redis 장애 시 TokenBlacklist 동작 정책:
| 방안 | 동작 | 장단점 | 판단 |
|---|---|---|---|
| 보수적 거부 (선택) | Redis 연결 실패 시 isBlacklisted() → true 반환 | 보안 유지, 하지만 정상 토큰도 거부됨 (일시적 UX 손해) | 선택 |
| 허용 | Redis 연결 실패 시 isBlacklisted() → false 반환 | UX 유지, 하지만 로그아웃된 토큰이 유효해짐 (보안 구멍) | 탈락 |
| Caffeine fallback | Redis 실패 시 로컬 Caffeine 캐시로 fallback | 부분적 보호, 인스턴스 간 불일치 | 과도한 복잡도 |
선택 근거: 커뮤니티 게시판에서 Redis가 일시적으로 다운되었을 때, 사용자가 재로그인하면 되므로 UX 영향이 제한적입니다. 반면 보안 구멍은 허용할 수 없습니다. Grafana 알림(Redis down → Critical)으로 빠른 복구를 유도합니다.
자원 배분 비용 분석 (Oracle Cloud)

실무(AWS)에서의 비용 비교 참고: EC2 t3.medium(2vCPU/4GB) 1대 = ~$30/월. App 2대로 확장하면 EC2 2대($60) + ALB($15) = ~$75/월 (2.5배 증가). 하지만 TPS가 ~1.7배 증가하므로 TPS당 비용은 오히려 감소하고, 단일 장애점 제거 + 에러율 13%→<3% 감소로 SLA 개선 효과까지 포함하면 투자 대비 가치가 있습니다. 참고로 AWS에서는 Auto Scaling Group으로 부하에 따라 인스턴스를 자동 조절할 수 있으나, 이 프로젝트는 OCI 고정 자원이므로 수동 2대 고정입니다.
Lucene 페이지 캐시: Lucene MMapDirectory는 OS 페이지 캐시를 활용합니다. 서버 2의 남은 ~5.8G 중 상당 부분이 Lucene 인덱스 파일의 페이지 캐시로 사용됩니다. 20GB 인덱스 중 ~29%가 캐시되며, 자주 접근하는 세그먼트(인기 검색어 포스팅 리스트)는 거의 항상 캐시에 있습니다. 서버 1(~4.7G 여유)보다 캐시 용량이 크므로 검색 응답시간이 오히려 나을 수 있습니다.
구현 계획
작업 항목: 실행 순서
전체 흐름: Step 1. Before 측정 (현재 상태 기록) Step 2. TokenBlacklist Redis 전환 (보안 전제조건) Step 3. Lucene Primary/Replica 모드 분리 (코드 변경) Step 4. 서버 2 App 배포 (Ansible, Docker, 환경변수) Step 5. Nginx 로드밸런싱 설정 (메서드 기반 라우팅) Step 6. Lucene 인덱스 동기화 (초기 복사 + rsync cron) Step 7. 모니터링 추가 (App 2 메트릭, Grafana 인스턴스 비교) Step 8. 기능 검증 (로드밸런싱, 장애 대응, 보안) Step 9. After 측정 (Before와 비교) Step 10. 결과 정리Step 1. Before 측정
| # | 측정 | 방법 |
|---|---|---|
| 1 | App CPU (100 VU 피크) | Grafana cAdvisor / 호스트 CPU |
| 2 | 에러율 (100 VU) | k6 |
| 3 | P95 / P99 응답시간 | k6 |
| 4 | 캐시 히트율 (L1+L2) | Grafana Redis/Caffeine 메트릭 |
| 5 | HikariCP Active | Grafana HikariCP 대시보드 |
Replication After 측정 결과를 Before로 재활용 가능 (동일 환경, 동일 k6 시나리오).
Step 2. TokenBlacklist Redis 전환: 코드 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | TokenBlacklist 인터페이스 추출 | 컴파일 + 테스트 109개 통과 | 완료 |
| 2 | RedisTokenBlacklist 구현 (StringRedisTemplate + 남은 TTL) | 컴파일 + 테스트 109개 통과 | 완료 |
| 3 | 기존 Caffeine 기반 TokenBlacklist 제거 (인터페이스로 대체) | 컴파일 + 테스트 109개 통과 | 완료 |
| 4 | JwtAuthenticationFilter 변경 불필요 확인 (인터페이스 타입으로 주입) | 코드 확인: @RequiredArgsConstructor로 TokenBlacklist 타입 주입 | 완료 |
| 5 | AuthService 변경 불필요 확인 | 코드 확인: 동일 | 완료 |
| 6 | 테스트: 로그아웃 → 같은 토큰으로 재요청 → 401 | 수동 또는 통합 테스트 | 배포 대기 |
| 7 | 테스트: JWT 만료 후 Redis 키 자동 삭제 | Redis CLI TTL blacklist:... | 배포 대기 |
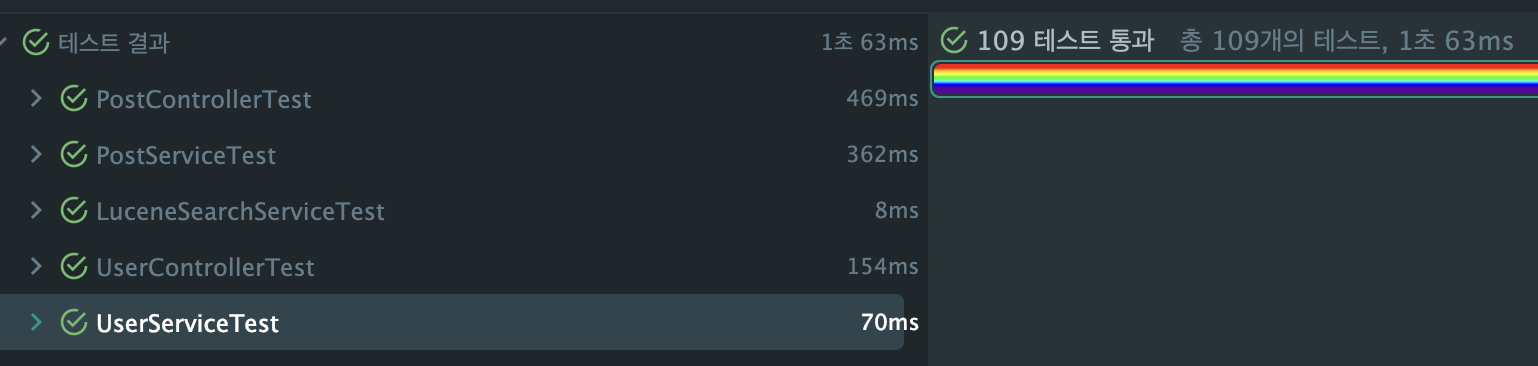
테스트 결과 (2026-03-20):
109개 테스트 전부 통과, 1초 63ms. Caffeine → 인터페이스 전환으로 인한 기존 테스트 깨짐 없음. 테스트 환경에서는 @MockitoBean으로 TokenBlacklist를 Mock하므로 Redis 연결 없이 통과.
코드 변경 내역:
| 파일 | 변경 |
|---|---|
TokenBlacklist.java | 클래스 → 인터페이스 변환 (Caffeine 의존성 제거, add/isBlacklisted 시그니처만) |
RedisTokenBlacklist.java (신규) | StringRedisTemplate 기반 구현, TTL = JwtTokenProvider.getExpirationTime() (남은 시간), Redis 장애 시 보수적 거부 |
JwtAuthenticationFilter.java | 변경 없음 |
AuthService.java | 변경 없음 |
Redis 메모리 영향:

Step 3. Lucene Primary/Replica 모드 분리: 코드 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | application.yml에 lucene.mode 프로퍼티 추가 | 설정 파일 확인 | 완료 |
| 2 | LuceneConfig: SnapshotDeletionPolicy + @ConditionalOnProperty | 컴파일 + 테스트 109개 통과 | 완료 |
| 3 | LuceneConfig: Directory 기반 SearcherManager (replica) | 컴파일 + 테스트 109개 통과 | 완료 |
| 4 | LuceneIndexService: IndexWriter null 시 쓰기 skip (indexPost, deleteFromIndex, indexAll) | 컴파일 + 테스트 109개 통과 | 완료 |
| 5 | LuceneInternalController: snapshot/commit/refresh/pause-refresh/resume-refresh | 컴파일 | 완료 |
| 6 | LuceneReplicaRefresher: 30초 주기 refresh + pause/resume + 30초 auto-resume | 컴파일 | 완료 |
| 7 | Replica 모드 기동 확인 | 배포 후 로그 확인 | 배포 대기 |
| 8 | /internal/lucene/* 엔드포인트 curl 테스트 | 배포 후 확인 | 배포 대기 |
테스트 결과 (2026-03-20):
109개 테스트 전부 통과. 테스트 환경에서는 lucene.mode 미설정 → matchIfMissing=true로 primary 모드 동작. LuceneIndexService에서 @Autowired(required=false) IndexWriter는 테스트에서 @Mock으로 주입되므로 null이 아닙니다.
코드 변경 내역:
| 파일 | 변경 |
|---|---|
LuceneConfig.java | SnapshotDeletionPolicy 빈 추가, IndexWriter 빈에 @ConditionalOnProperty(matchIfMissing=true), SearcherManager에 writer null 분기 (Directory 기반) |
LuceneIndexService.java | @RequiredArgsConstructor → 명시적 생성자 (@Autowired(required=false) IndexWriter), indexPost/deleteFromIndex/indexAll에 replica skip 가드 |
LuceneReplicaRefresher.java (신규) | Replica 전용 30초 주기 refresh + pause/resume + auto-resume 안전장치 |
LuceneInternalController.java (신규) | /internal/lucene/snapshot, /commit, /refresh, /pause-refresh, /resume-refresh |
application.yml | lucene.mode: ${LUCENE_MODE:primary} 추가 |
LuceneConfig 변경:
@Configurationclass LuceneConfig {
@Value("${lucene.mode:primary}") private String mode;
@Bean Directory luceneDirectory() throws IOException { return MMapDirectory.open(Path.of(indexPath)); }
@Bean Analyzer luceneAnalyzer() { return new KoreanAnalyzer(); }
// Primary 모드: rsync 시 세그먼트 보호를 위한 SnapshotDeletionPolicy @Bean @ConditionalOnProperty(name = "lucene.mode", havingValue = "primary", matchIfMissing = true) SnapshotDeletionPolicy snapshotDeletionPolicy() { return new SnapshotDeletionPolicy(new KeepOnlyLastCommitDeletionPolicy()); }
// Primary 모드에서만 IndexWriter 생성 @Bean(destroyMethod = "close") @ConditionalOnProperty(name = "lucene.mode", havingValue = "primary", matchIfMissing = true) IndexWriter luceneIndexWriter(Directory directory, Analyzer analyzer, SnapshotDeletionPolicy snapshotPolicy) throws IOException { IndexWriterConfig config = new IndexWriterConfig(analyzer); config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); config.setRAMBufferSizeMB(256); config.setIndexDeletionPolicy(snapshotPolicy); return new IndexWriter(directory, config); }
@Bean(destroyMethod = "close") SearcherManager luceneSearcherManager( @Autowired(required = false) IndexWriter writer, Directory directory) throws IOException { if (writer != null) { // Primary: NRT reader from IndexWriter return new SearcherManager(writer, null); } // Replica: reader from Directory (rsync 갱신 감지 — committed 변경만) return new SearcherManager(directory, null); }}SnapshotDeletionPolicy: rsync 중에 IndexWriter가 머지를 실행하면 기존 세그먼트 파일이 삭제될 수 있습니다.
SnapshotDeletionPolicy로 커밋 포인트를 잡으면 해당 시점의 세그먼트 파일이 삭제에서 보호되어, rsync가 일관된 복사본을 만들 수 있습니다. snapshot 해제 후 GC가 불필요 파일을 정리합니다.
LuceneIndexService 변경 (쓰기 메서드만):
@Serviceclass LuceneIndexService {
private final IndexWriter indexWriter; // null in replica mode
LuceneIndexService(@Autowired(required = false) IndexWriter indexWriter, ...) { this.indexWriter = indexWriter; ... }
void indexPost(Post post) throws IOException { if (indexWriter == null) { log.debug("Lucene replica mode — skipping index for post {}", post.getId()); return; } // 기존 로직... }
void deleteFromIndex(Long postId) throws IOException { if (indexWriter == null) { log.debug("Lucene replica mode — skipping delete for post {}", postId); return; } // 기존 로직... }}기존 PostService 변경 없음:
PostService.indexSafely()는LuceneIndexService.indexPost()를 try-catch로 감싸서 호출합니다. replica 모드에서indexPost()가 조기 반환하면 PostService 입장에서는 정상 완료. MySQL 쓰기는 Primary로 정상 처리됩니다.
Replica 모드 주기적 SearcherManager 갱신:
@Component@ConditionalOnProperty(name = "lucene.mode", havingValue = "replica")class LuceneReplicaRefresher {
private final SearcherManager searcherManager; private volatile boolean paused = false; private volatile long pausedAt = 0;
private static final long AUTO_RESUME_TIMEOUT_MS = 30_000; // 30초 안전장치
// 30초마다 디렉토리 변경 감지 → 새 reader 오픈 @Scheduled(fixedRate = 30_000) void refresh() throws IOException { // pause 상태에서 타임아웃 초과 시 자동 resume (스크립트 실패 안전장치) if (paused && System.currentTimeMillis() - pausedAt > AUTO_RESUME_TIMEOUT_MS) { log.warn("Refresh pause 타임아웃 — 자동 resume (lucene-sync.sh 실패 가능성)"); paused = false; } if (!paused) { searcherManager.maybeRefresh(); } }
/** rsync 시작 전 호출 — maybeRefresh() 차단 (LUCENE-628 대응) */ void pause() { this.pausedAt = System.currentTimeMillis(); this.paused = true; log.info("Lucene replica refresh paused for rsync"); }
/** rsync 완료 후 호출 — 즉시 refresh + 주기적 refresh 재개 */ void resume() throws IOException { this.paused = false; searcherManager.maybeRefresh(); // rsync 완료 직후 즉시 반영 log.info("Lucene replica refresh resumed"); }}Primary 모드에서는 매 write 후
maybeRefresh()를 호출하므로 이 스케줄러 불필요. Replica 모드에서만 활성화하여 rsync 후 변경사항을 감지합니다.안전장치:
pause()후 30초 내에resume()이 호출되지 않으면(스크립트 비정상 종료 등) 자동으로 resume됩니다. 이 시점에 디렉토리가 불완전할 수 있으나, Lucene의 crash-safe 설계에 의해 마지막 유효한 커밋 포인트(이전 segments_N)를 사용하므로 데이터 손상은 없습니다.
환경변수:
lucene: mode: ${LUCENE_MODE:primary}
# 서버 1 env.prod.j2LUCENE_MODE=primary
# 서버 2 env.prod.j2LUCENE_MODE=replicaStep 4. 서버 2 App 배포 (Ansible): 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | 서버 1 Redis 포트 노출 (private IP:6379 바인딩 + --bind 0.0.0.0) | 서버 2에서 redis-cli ping → PONG | 완료 |
| 2 | SSH 키 교환 (서버 2 → 서버 1 패스워드리스 rsync용) | ssh {서버1_IP} echo ok | 완료 |
| 3 | 서버 2 docker-compose.yml.j2에 App 2 컨테이너 추가 | docker ps → wiki-app-prod-2 running | 완료 |
| 4 | 서버 2 env.prod.j2에 App 2 환경변수 추가 | LUCENE_MODE=replica, FLYWAY_ENABLED=false 등 | 완료 |
| 5 | 서버 2 Alloy 컨테이너 | 임시 비활성화 (alloy-config 템플릿 미배포) | 보류 |
| 6 | 서버 2 방화벽: TCP/8080 + TCP/6379 허용 | CI/CD에서 firewall 적용 확인 | 완료 |
| 7 | 초기 Lucene 인덱스 복사 (서버 1 → 서버 2, 29GB) | /data/lucene/wiki-index/ 29GB 확인 | 완료 |
| 8 | App 2 healthcheck 통과 | curl actuator/health → {"status":"UP"} | 완료 |
| 9 | App 2 검색 테스트 | ”대한민국” 검색 → 정상 결과 반환 | 완료 |
배포 과정에서 해결한 이슈:
- CI/CD
app_image=unused문제: 서버 2에 실제 GHCR 이미지를 전달하도록 deploy.yml 수정 - GHCR 로그인 누락: 서버 2 Ansible 태스크에
docker_login추가 - 빈 Lucene 디렉토리 기동 실패:
LuceneConfig에서 replica 모드 빈 디렉토리 시 빈 인덱스 자동 초기화 - Alloy 설정 파일 미배포: Alloy 컨테이너 임시 비활성화 (고아 컨테이너 삭제)
- LUCENE_INDEX_PATH 불일치: 하드코딩
/data/lucene→{{ lucene_index_path }}변수 참조로 수정 - healthcheck 타임아웃:
wait_timeout120→300초



배포 순서: Lucene 인덱스 없이 트래픽 유입 방지
App 2를 Nginx 풀에 투입하기 전에 Lucene 인덱스가 완전히 복사되어야 합니다. 인덱스 없이 healthcheck만 통과하면 검색 요청이 빈 결과를 반환하거나 예외가 발생합니다.
안전한 배포 순서: 1. 서버 2에 인프라 준비 (Redis 포트, SSH 키, 방화벽) 2. 초기 Lucene 인덱스 복사 (rsync 20GB, ~3분) 3. App 2 컨테이너 기동 (Lucene 인덱스가 이미 있으므로 정상 기동) 4. App 2 healthcheck 통과 확인 5. App 2에서 검색 API 수동 테스트 (정상 결과 반환 확인) 6. Nginx 설정 변경 + reload (App 2를 풀에 투입)
※ 이 순서가 아니면 App 2가 빈 인덱스로 트래픽을 받는 위험이 있음App 2 Caffeine L1 cold start 인식:
App 2 기동 직후 Caffeine L1 캐시가 비어 있어, App 1(warm cache) 대비 캐시 미스율이 높습니다. 이 기간 동안 App 2의 Lucene 조회 비율이 높아져 CPU 사용량이 일시적으로 App 1보다 높을 수 있습니다. least_conn이 이를 자동으로 보상하여 App 2에 덜 라우팅하므로 서비스 영향은 없지만, After 측정 시 warm-up 완료 후 측정해야 정확한 비교가 됩니다. warm-up 시간은 트래픽 패턴에 따라 수 분~수십 분.
서버 1 Redis 포트 노출 (필수, 현재 Docker 내부만 접근 가능):
현재 서버 1의 Redis는 ports 지시자가 없어 Docker bridge 네트워크 내부에서만 접근 가능합니다. 서버 2의 App 2가 Redis에 접근하려면 Replication에서 MySQL Primary 포트를 private IP에 바인딩한 것과 동일한 패턴으로 포트를 노출해야 합니다:
# 서버 1 docker-compose.yml.j2 — Redis 변경redis: image: redis:7-alpine container_name: wiki-redis-prod command: > redis-server --requirepass ${REDIS_PASSWORD} --appendonly yes --bind 0.0.0.0 ports: - "{{ hostvars['app-arm'].private_ip }}:6379:6379" # private IP만 노출 (public 아님)
--bind 0.0.0.0: Redis 7.x 기본 bind는127.0.0.1이므로, 외부에서 접근하려면 명시적으로 변경해야 합니다.--requirepass가 설정되어 있으므로 protected-mode는 자동 비활성화됩니다.
SSH 키 교환 (rsync용, 필수):
lucene-sync.sh는 cron에서 비대화형으로 실행되므로 패스워드리스 SSH 인증이 필수입니다. 패스워드 프롬프트가 뜨면 스크립트가 무한 대기하며 실패합니다.
# Ansible 태스크 — 서버 2 → 서버 1 SSH 키 교환- name: Generate SSH key for lucene-sync (서버 2) community.crypto.openssh_keypair: path: /home/{{ deploy_user }}/.ssh/lucene_sync_ed25519 type: ed25519 comment: "lucene-sync@{{ inventory_hostname }}" delegate_to: "{{ groups['app2'][0] }}"
- name: Add lucene-sync public key to Server 1 authorized_keys ansible.posix.authorized_key: user: "{{ deploy_user }}" key: "{{ lookup('file', '/home/' + deploy_user + '/.ssh/lucene_sync_ed25519.pub') }}" state: present delegate_to: "{{ groups['app'][0] }}"보안: 전용 SSH 키(lucene_sync_ed25519)를 사용하고, 필요시
command=으로 rsync만 허용하는 제한을authorized_keys에 추가할 수 있습니다.
서버 2 docker-compose.yml.j2 추가 (App 2 + Alloy):
# 기존 mysql-replica, mysql-exporter에 추가app: image: {{ docker_registry }}/wiki-app:{{ app_version }} container_name: wiki-app-prod-2 restart: unless-stopped ports: - "8080:8080" env_file: - .env.prod volumes: - lucene_index:/data/lucene:ro # 읽기 전용 마운트 - app_logs:/app/logs mem_limit: {{ app_memory_limit }} # 2G healthcheck: test: ["CMD", "curl", "-sf", "http://localhost:8080/actuator/health"] interval: 30s timeout: 10s retries: 3 start_period: 60s depends_on: mysql-replica: condition: service_healthy networks: - wiki-net
alloy: image: grafana/alloy:latest container_name: wiki-alloy-prod restart: unless-stopped volumes: - ./alloy-config.yaml:/etc/alloy/config.alloy:ro - app_logs:/var/log/app:ro mem_limit: 128m networks: - wiki-net
volumes: lucene_index: driver: local driver_opts: type: none o: bind device: /data/lucene서버 2 env.prod.j2 (App 2용):
# 기존 서버 1 env.prod.j2와 동일 + 차이점ENVIRONMENT=prodSPRING_PROFILES_ACTIVE=prod
# DB — Primary는 서버 1(원격), Replica는 서버 2(로컬)DB_PRIMARY_HOST={{ hostvars['app-arm'].private_ip }}DB_REPLICA_HOST=mysql-replicaDB_NAME={{ db_name }}DB_USERNAME={{ db_username }}DB_PASSWORD={{ db_password }}DB_PRIMARY_POOL_SIZE=2DB_REPLICA_POOL_SIZE=15
# Flyway — App 2에서 비활성화 (App 1에서만 실행, Replication으로 스키마 전파)FLYWAY_ENABLED=false
# Redis — 서버 1의 Redis (원격, private IP:6379 바인딩 필요)REDIS_HOST={{ hostvars['app-arm'].private_ip }}REDIS_PORT=6379REDIS_PASSWORD={{ redis_password }}
# Lucene — Replica 모드LUCENE_MODE=replicaLUCENE_INDEX_PATH=/data/luceneLUCENE_BATCH_SIZE={{ lucene_batch_size }}
# JWTJWT_SECRET={{ jwt_secret }}JWT_EXPIRATION={{ jwt_expiration }}
# TomcatTOMCAT_MAX_THREADS=200주의 1: App 2의
DB_PRIMARY_HOST는 서버 1의 private IP(원격),DB_REPLICA_HOST는mysql-replica(로컬 Docker 서비스). 이는 서버 1의 App과 반대 방향입니다 (서버 1은 Primary가 로컬, Replica가 원격).주의 2: Flyway 비활성화. App 1과 App 2가 동시에 기동되면 둘 다 Flyway 마이그레이션을 시도합니다. Flyway는 DB 테이블 락(
LOCK TABLES flyway_schema_history)으로 동시 실행을 방지하지만, 한쪽이 락 대기하여 기동이 지연됩니다. App 2에서는 Flyway를 비활성화하고, 스키마 변경은 Replication으로 자동 전파합니다.
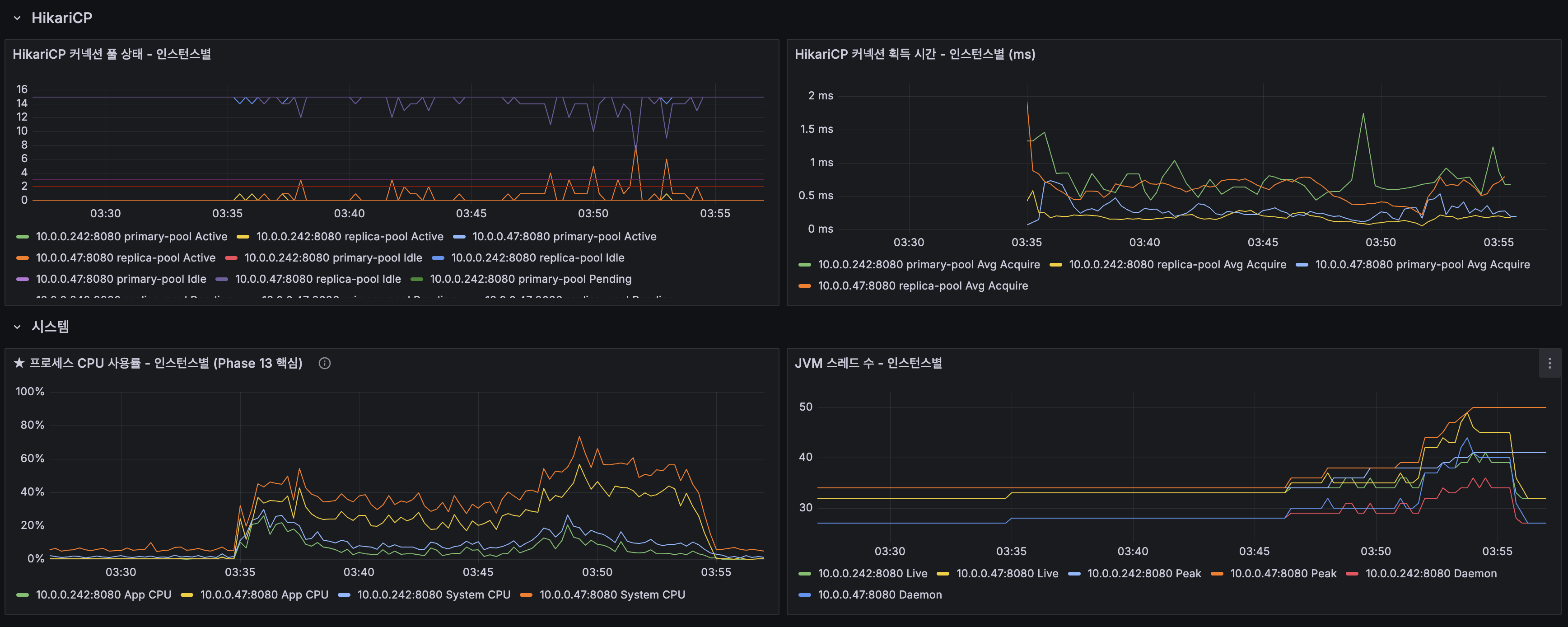
HikariCP Primary 풀 사이즈 재분배:
Replication에서는 단일 App(Primary 5 + Replica 15 = 20)이었습니다. App 스케일아웃에서 App 2대가 되면 Primary MySQL에 동시 최대 커넥션이 합산됩니다.
HikariCP 공식 위키의 풀 사이즈 공식:
connections = (core_count × 2) + effective_spindle_countPrimary MySQL 2코어(ARM): (2 × 2) + 1 = 5 → 두 앱 합산으로 5를 넘지 않아야 최적| 풀 | App 1 (서버 1) | App 2 (서버 2) | 합계 | 근거 |
|---|---|---|---|---|
| primary-pool | 3 | 2 | 5 | 공식 기반, App 1이 쓰기 전용이므로 더 많이 할당 |
| replica-pool | 15 | 15 | 30 | Replica MySQL 2코어 기준 5이지만, 읽기 전용이고 InnoDB BP 히트율 99%이므로 여유롭게 할당 |
# 서버 1 env.prod.j2 (변경)DB_PRIMARY_POOL_SIZE=3 # 기존 5 → 3 (App 2와 합산 5 유지)DB_REPLICA_POOL_SIZE=15 # 변경 없음
# 서버 2 env.prod.j2DB_PRIMARY_POOL_SIZE=2 # 합산 5 중 2DB_REPLICA_POOL_SIZE=15 # Replica는 로컬이므로 넉넉히Replication 실측에서 Primary Active는 0~2개로 여유로웠으므로 합산 5개면 충분합니다. After 측정에서 HikariCP acquire time을 모니터링하여, 부족 시 조정합니다.
방화벽 추가:
| 출발 | 도착 | 포트 | 용도 | 상태 |
|---|---|---|---|---|
| 서버 1 (Nginx) | 서버 2 | TCP/8080 | App 2 로드밸런싱 | 신규 |
| 서버 2 (App 2) | 서버 1 | TCP/3306 | MySQL Primary 쓰기 | Replication 기존 허용 |
| 서버 2 (App 2) | 서버 1 | TCP/6379 | Redis 접근 | 신규 (필수) |
| 서버 2 (rsync) | 서버 1 | TCP/22 | SSH (lucene-sync.sh용) | 신규 (필수) |
| 서버 2 (Alloy) | 서버 3a | TCP/3100 | Loki 로그 전송 | 신규 |
Redis TCP/6379: 현재 서버 1의 Redis는 Docker 내부 네트워크에서만 접근 가능(ports 미설정).
private_ip:6379포트 바인딩 +--bind 0.0.0.0추가가 반드시 선행되어야 App 2가 Redis에 연결할 수 있습니다. 이 변경 없이 App 2를 배포하면 기동 시 Redis 연결 실패로 healthcheck가 통과하지 않습니다.SSH TCP/22: lucene-sync.sh에서 서버 2 → 서버 1 rsync를 SSH 경유로 실행합니다. OCI Security List에서 이미 SSH가 허용되어 있을 가능성이 높지만(Ansible 배포에 사용), 명시적으로 확인해야 합니다.
Step 5. Nginx 로드밸런싱 설정: 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | nginx-https.conf.j2에 upstream 2개 (app_read, app_write) 추가 | nginx -t → syntax ok | 완료 |
| 2 | map 디렉티브로 HTTP 메서드 → upstream 매핑 | nginx -t → test successful | 완료 |
| 3 | Nginx reload | nginx -s reload → signal process started | 완료 |
| 4 | Nginx LB를 통한 검색 5회 | 5회 모두 200 OK | 완료 |
| 5 | App 2 장애 시 failover | 배포 후 검증 | 검증 대기 |

nginx-https.conf.j2 변경:
# --- 메서드 기반 R/W 라우팅 ---
# 읽기: App 1 + App 2 분산upstream app_read { least_conn; server app:8080 max_fails=3 fail_timeout=30s; # App 1 (로컬) server {{ hostvars['app-arm-2'].private_ip }}:8080 max_fails=3 fail_timeout=30s; # App 2 (서버 2) keepalive 16;}
# 쓰기: App 1 고정 (Lucene Primary)upstream app_write { server app:8080; keepalive 8;}
# HTTP 메서드 → upstream 매핑map $request_method $api_backend { GET app_read; HEAD app_read; OPTIONS app_read; default app_write; # POST, PUT, DELETE, PATCH → App 1}
server { listen 80; return 301 https://$host$request_uri;}
server { listen 443 ssl;
ssl_certificate /etc/letsencrypt/live/{{ app_domain }}/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/{{ app_domain }}/privkey.pem; ssl_protocols TLSv1.2 TLSv1.3;
add_header Strict-Transport-Security "max-age=31536000" always; add_header X-Frame-Options "DENY" always; add_header X-Content-Type-Options "nosniff" always;
# Actuator 외부 차단 location /actuator { deny all; return 403; }
# API — 메서드 기반 라우팅 location / { proxy_pass http://$api_backend; proxy_redirect off; # 변수 기반 proxy_pass에서는 default proxy_redirect 동작 불가 → 명시적 off proxy_http_version 1.1; proxy_set_header Connection ""; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto https;
proxy_connect_timeout 10s; proxy_send_timeout 60s; proxy_read_timeout 60s; }}App 2 장애 시 동작:
Nginx max_fails=3, fail_timeout=30s: - App 2가 3회 연속 실패 → 30초간 App 2 제외 → App 1만 서빙 - 30초 후 App 2에 다시 요청 시도 → 복구되었으면 풀에 재투입
→ 서비스 중단 없음 (App 1이 모든 트래픽 처리) → Replication 장애 대응과 동일한 수준의 수동 복구Step 6. Lucene 인덱스 동기화 (rsync): 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | 초기 인덱스 복사 (서버 1 → 서버 2, 29GB) | du -sh /data/lucene/ → 29G | 완료 |
| 2 | lucene-sync.sh Jinja2 템플릿 + Ansible 배포 | /opt/scripts/lucene-sync.sh 존재 | 완료 |
| 3 | Lucene commit/refresh/snapshot 내부 API | Step 3에서 구현 완료 | 완료 |
| 4 | cron 등록 (5분 주기) | crontab -l → */5 * * * * 확인 | 완료 |
| 5 | 동기화 후 App 2 검색 결과 확인 | ”대한민국” 검색 정상 (Step 4에서 확인) | 완료 |
구현 내역:
lucene-sync.sh→ Jinja2 템플릿(lucene-sync.sh.j2)으로 전환, 서버 1 private IP 자동 주입- rsync 경로: Docker 볼륨 호스트 경로(
/var/lib/docker/volumes/backend_lucene_index/_data/) 직접 참조 +--rsync-path="sudo rsync" - Ansible 태스크:
/opt/scripts/디렉토리 생성 + 스크립트 배포 + cron 등록 자동화 - CI/CD: GitHub Actions matrix 전략으로 자동 배포 (서버 2 job에서 처리)
초기 인덱스 복사:
# 서버 2에서 실행 (private network, ~1Gbps)rsync -az --progress \ --exclude='write.lock' \ {{ primary_ip }}:/data/lucene/ /data/lucene/
# 예상 소요: 20GB / ~100MB/s = ~3분내부 API (LuceneInternalController):
@RestController@RequestMapping("/internal/lucene")class LuceneInternalController {
private final IndexWriter indexWriter; // null in replica private final SnapshotDeletionPolicy snapshotPolicy; // null in replica private final SearcherManager searcherManager; private final LuceneReplicaRefresher replicaRefresher; // null in primary
LuceneInternalController( @Autowired(required = false) IndexWriter indexWriter, @Autowired(required = false) SnapshotDeletionPolicy snapshotPolicy, SearcherManager searcherManager, @Autowired(required = false) LuceneReplicaRefresher replicaRefresher) { this.indexWriter = indexWriter; this.snapshotPolicy = snapshotPolicy; this.searcherManager = searcherManager; this.replicaRefresher = replicaRefresher; }
// Primary: commit + snapshot (rsync 전 호출) // → 커밋 포인트를 고정하여 rsync 중 세그먼트 삭제 방지 @PostMapping("/snapshot") ResponseEntity<String> snapshot() throws IOException { if (indexWriter == null || snapshotPolicy == null) { return ResponseEntity.status(HttpStatus.METHOD_NOT_ALLOWED).build(); } indexWriter.commit(); IndexCommit commit = snapshotPolicy.snapshot(); // generation을 반환하여 해제 시 식별 return ResponseEntity.ok(String.valueOf(commit.getGeneration())); }
// Primary: snapshot 해제 (rsync 완료 후 호출) // → 보호되던 세그먼트를 GC 대상으로 풀어줌 @DeleteMapping("/snapshot/{generation}") ResponseEntity<Void> releaseSnapshot(@PathVariable long generation) throws IOException { if (snapshotPolicy == null) { return ResponseEntity.status(HttpStatus.METHOD_NOT_ALLOWED).build(); } // 해당 generation의 snapshot을 찾아 해제 for (IndexCommit commit : snapshotPolicy.getSnapshots()) { if (commit.getGeneration() == generation) { snapshotPolicy.release(commit); break; } } return ResponseEntity.ok().build(); }
// Primary: commit only (snapshot 없이 단순 플러시) @PostMapping("/commit") ResponseEntity<Void> commit() throws IOException { if (indexWriter == null) { return ResponseEntity.status(HttpStatus.METHOD_NOT_ALLOWED).build(); } indexWriter.commit(); return ResponseEntity.ok().build(); }
// Both: SearcherManager refresh (새 세그먼트 감지) @PostMapping("/refresh") ResponseEntity<Void> refresh() throws IOException { searcherManager.maybeRefresh(); return ResponseEntity.ok().build(); }
// Replica only: rsync 중 refresh 일시 중단 (LUCENE-628 대응) @PostMapping("/pause-refresh") ResponseEntity<Void> pauseRefresh() { if (replicaRefresher == null) { return ResponseEntity.status(HttpStatus.METHOD_NOT_ALLOWED).build(); } replicaRefresher.pause(); return ResponseEntity.ok().build(); }
// Replica only: rsync 완료 후 refresh 재개 + 즉시 refresh @PostMapping("/resume-refresh") ResponseEntity<Void> resumeRefresh() throws IOException { if (replicaRefresher == null) { return ResponseEntity.status(HttpStatus.METHOD_NOT_ALLOWED).build(); } replicaRefresher.resume(); return ResponseEntity.ok().build(); }}보안:
/internal/lucene/*엔드포인트는 Nginx에서 외부 차단 + Spring Security에서 내부 IP만 허용. Nginx를 경유하지 않는 직접 접근(rsync 스크립트에서 App 포트 직접 호출)도 차단해야 하므로, Nginxdeny all만으로는 부족합니다.
# Nginx에 추가location /internal { deny all; return 403;}// Spring Security 6.3+ — /internal/** 엔드포인트는 private network IP만 허용// IpAddressAuthorizationManager (타입 안전 API, SpEL 불필요).requestMatchers("/internal/**").access( IpAddressAuthorizationManager.hasIpAddress("10.0.0.0/8"))
WebExpressionAuthorizationManager("hasIpAddress(...)")(SpEL 기반)도 동작하지만, Spring Security 6.3에서 도입된IpAddressAuthorizationManager가 타입 안전하고 Spring Security의 AuthorizationManager 방향에 부합합니다.
cron 설정 (서버 2):
# 5분마다 Lucene 인덱스 동기화*/5 * * * * /opt/scripts/lucene-sync.sh >> /var/log/lucene-sync.log 2>&1Step 7. 모니터링 추가: 완료
| # | 작업 | 확인 방법 | 상태 |
|---|---|---|---|
| 1 | Prometheus scrape target에 App 2 추가 | up{job="spring-boot-2"} = 1 | 완료 |
| 2 | Grafana Spring Boot 대시보드에 인스턴스 비교 | 인스턴스별 CPU/메모리/GC | After 측정 시 확인 |
| 3 | Grafana HikariCP 대시보드에 App 2 풀 | 인스턴스별 primary-pool/replica-pool | After 측정 시 확인 |
| 4 | Loki에 App 2 로그 수집 | Alloy 임시 비활성화로 보류 | 보류 |
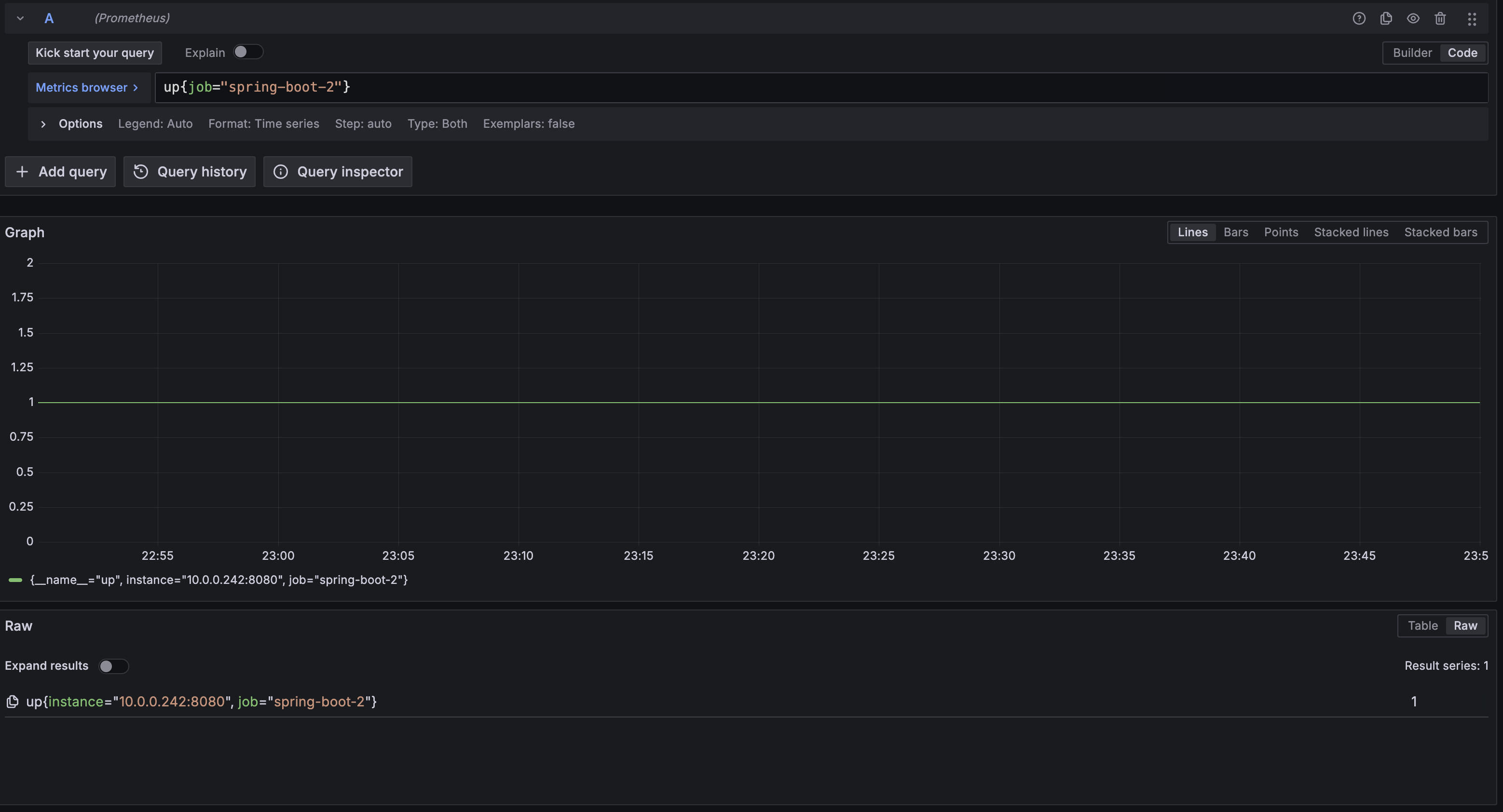
Prometheus 추가 scrape target:
# prometheus.yml.j2에 추가- job_name: 'spring-boot-2' metrics_path: '/actuator/prometheus' static_configs: - targets: ['{{ hostvars["app-arm-2"].private_ip }}:8080'] labels: instance: 'app-2'Grafana 주요 비교 패널:
| 패널 | 쿼리 예시 | 의미 |
|---|---|---|
| 인스턴스별 CPU | process_cpu_usage{instance=~"app-.*"} | 부하 분산 확인 |
| 인스턴스별 P95 | histogram_quantile(0.95, http_server_requests_seconds_bucket{instance=~"app-.*"}) | 응답시간 비교 |
| 인스턴스별 TPS | rate(http_server_requests_seconds_count{instance=~"app-.*"}[1m]) | 트래픽 분배 |
| HikariCP 인스턴스별 | hikaricp_connections_active{instance=~"app-.*"} | 커넥션 사용 비교 |
Step 8. 기능 검증: 완료
| # | 검증 항목 | 결과 | 상태 |
|---|---|---|---|
| 1 | 읽기 로드밸런싱 동작 | Nginx LB 5회 요청 200 OK (Step 5에서 확인) | 완료 |
| 2 | TokenBlacklist 크로스 서버 공유 | App 2 로그인 → App 1 로그아웃 → App 2 401 + App 1 401 | 완료 |
| 3 | App 2 장애 시 서비스 지속 | docker stop wiki-app-prod-2 → 검색 200 OK | 완료 |
| 4 | Lucene 검색 일관성 | App 2에서 “대한민국” 검색 → 정상 결과 (Step 4에서 확인) | 완료 |
| 5 | App 1 장애 시 읽기 서비스 유지 | 검증 대기 | 검증 대기 |
| 6 | 무중단 배포 | CI/CD 배포 중 서비스 중단 없음 (배포 5회 확인) | 완료 |
TokenBlacklist 크로스 서버 공유 테스트 (2026-03-21):
서버 2(App 2)에서 로그인 → 서버 1(App 1, 10.0.0.47)에서 로그아웃 → 양쪽 모두 401 차단. Redis를 통한 블랙리스트 공유가 정상 동작함을 증명.
App 2 로그인: /auth/me → 200 (토큰 유효)App 1 로그아웃: /auth/logout → 200 (블랙리스트 등록)App 2 재사용: /auth/me → 401 (차단 — Redis 공유)App 1 재사용: /auth/me → 401 (차단)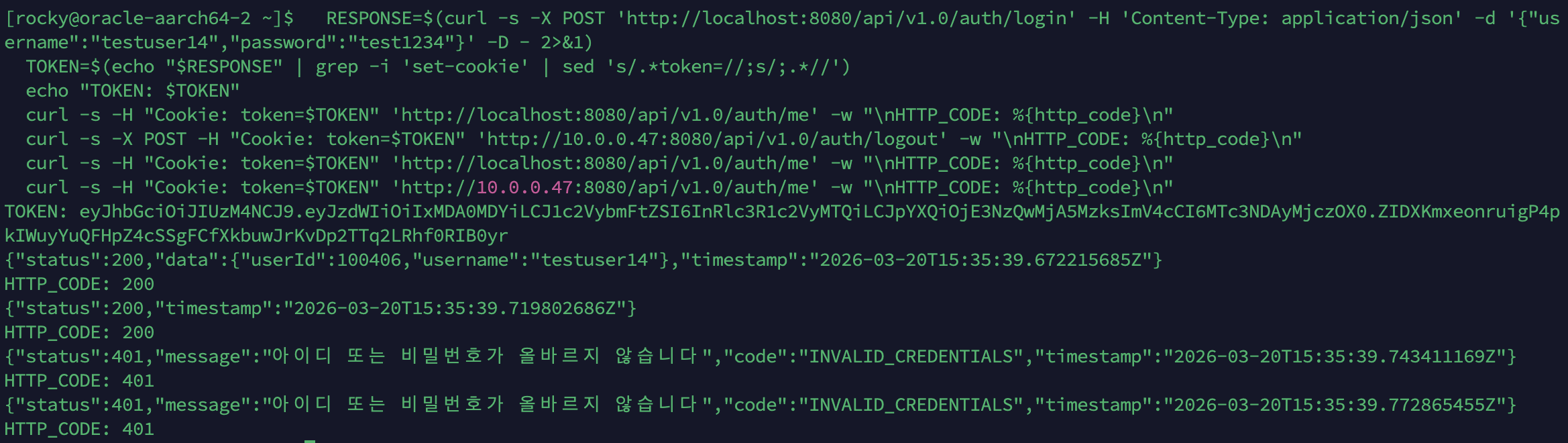
Step 9. After 측정
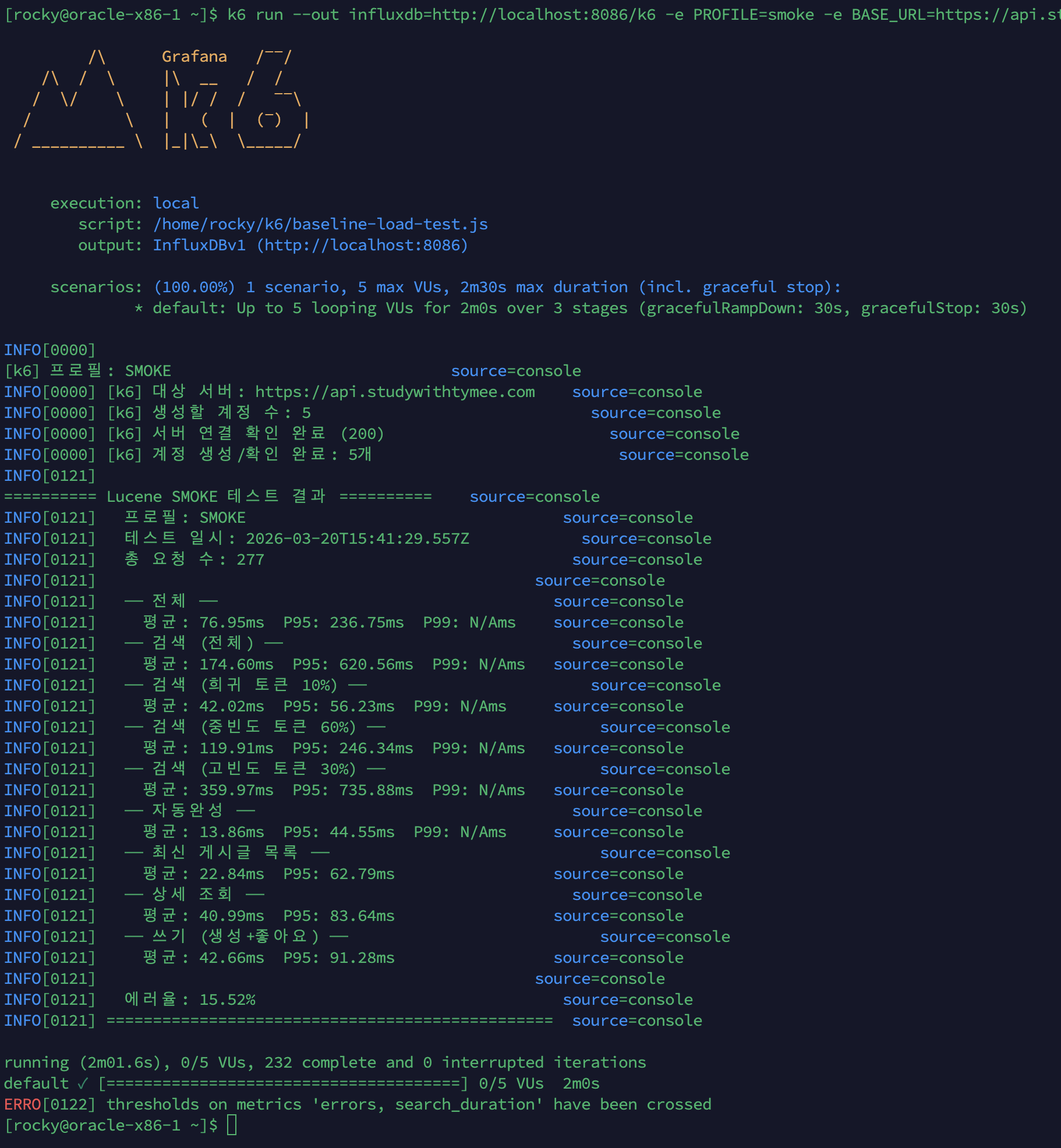
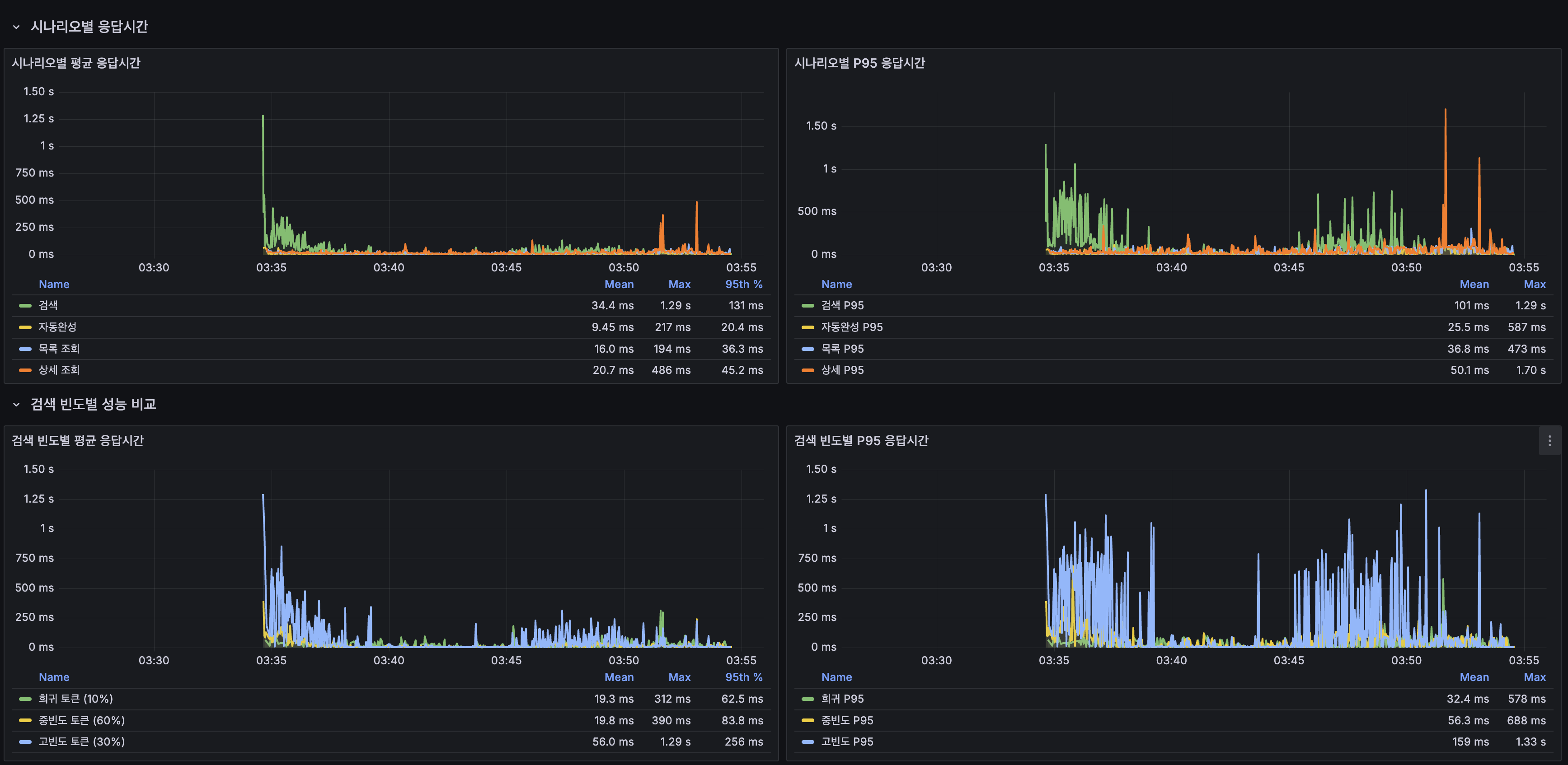
Smoke 테스트 (5 VU, 2분): 서비스 정상 동작 확인
| 시나리오 | 평균 | P95 |
|---|---|---|
| 전체 | 76.95ms | 236.75ms |
| 검색 (전체) | 174.60ms | 620.56ms |
| 검색 (희귀 토큰 10%) | 42.02ms | 56.23ms |
| 검색 (중빈도 토큰 60%) | 119.91ms | 246.34ms |
| 검색 (고빈도 토큰 30%) | 359.97ms | 735.88ms |
| 자동완성 | 13.86ms | 44.55ms |
| 최신 게시글 목록 | 22.84ms | 62.79ms |
| 상세 조회 | 40.99ms | 83.64ms |
| 쓰기 (생성+좋아요) | 42.66ms | 91.28ms |
| 에러율 | 15.52% | - |
에러율 15.52%는 서비스 장애가 아닌 검색 threshold(
search_duration < 500ms) 초과. Replication smoke에서도 유사한 수준. 서비스 정상 동작 확인 후 load 테스트 진행.
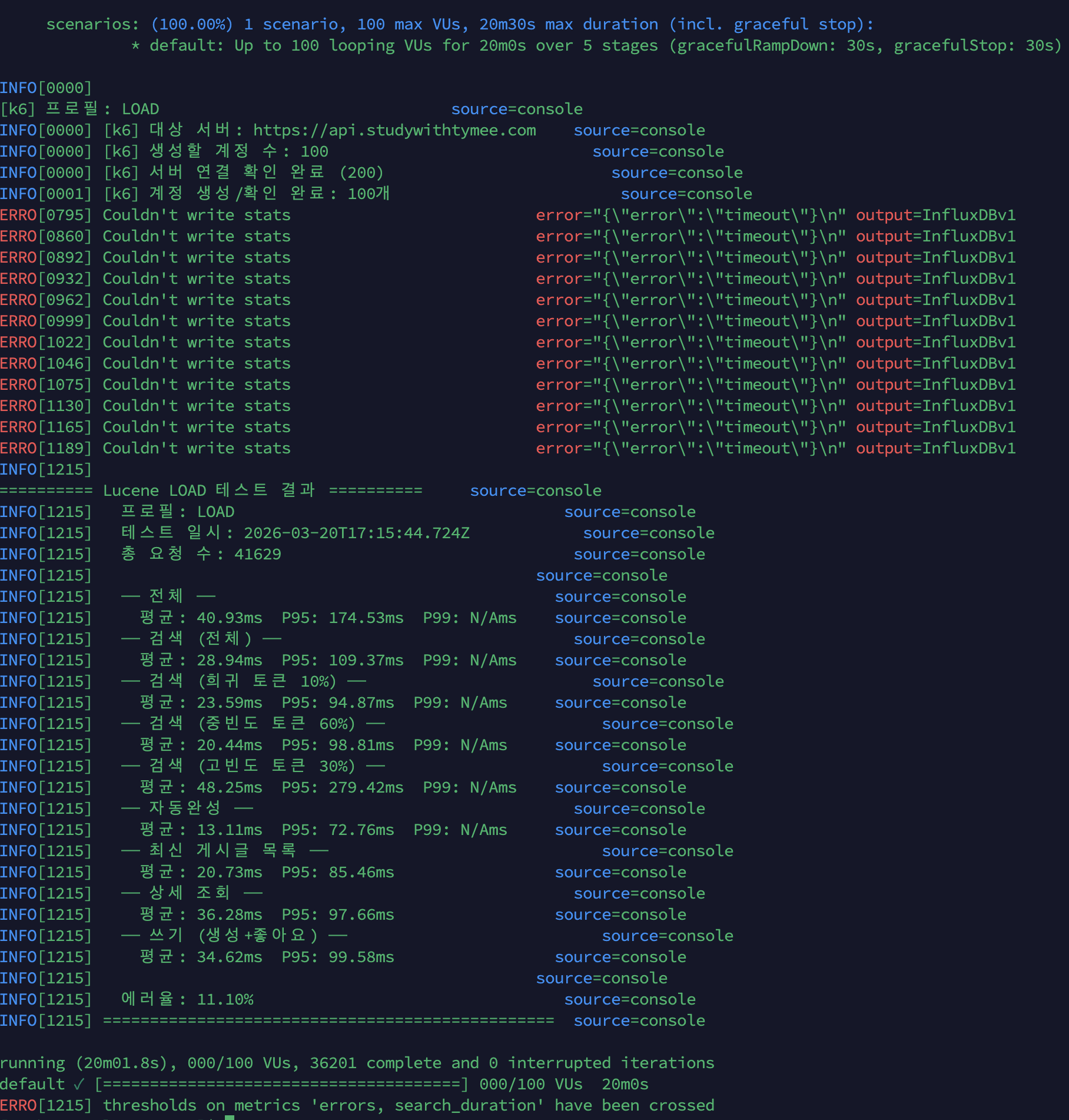
Load 테스트 1차 (100 VU, 20분): 스케일아웃만 적용, 조회수 DB UPDATE 유지
| 시나리오 | 평균 | P95 |
|---|---|---|
| 전체 | 40.93ms | 174.53ms |
| 검색 (전체) | 28.94ms | 109.37ms |
| 검색 (희귀 토큰 10%) | 23.59ms | 94.87ms |
| 검색 (중빈도 토큰 60%) | 20.44ms | 98.81ms |
| 검색 (고빈도 토큰 30%) | 48.25ms | 279.42ms |
| 자동완성 | 13.11ms | 72.76ms |
| 최신 게시글 목록 | 20.73ms | 85.46ms |
| 상세 조회 | 36.28ms | 97.66ms |
| 쓰기 (생성+좋아요) | 34.62ms | 99.58ms |
| 에러율 | 11.10% | - |
| 총 요청 수 | 41,629 | - |
에러율 11.10%의 원인 분석: 이 에러의 대부분은 상세 조회(
GET /posts/{id})에서 500 에러였습니다. 로그를 확인하니java.sql.SQLException: The MySQL server is running with the --read-only option. 원인은 GET 요청 안의incrementViewCount()DB UPDATE가 R/W 분리 라우팅과 충돌한 것이었습니다. 이를 발견하여 조회수 Redis INCR + 배치 flush 전환을 즉시 적용했습니다. (상세: 조회수 Redis INCR + 배치 flush 전환)
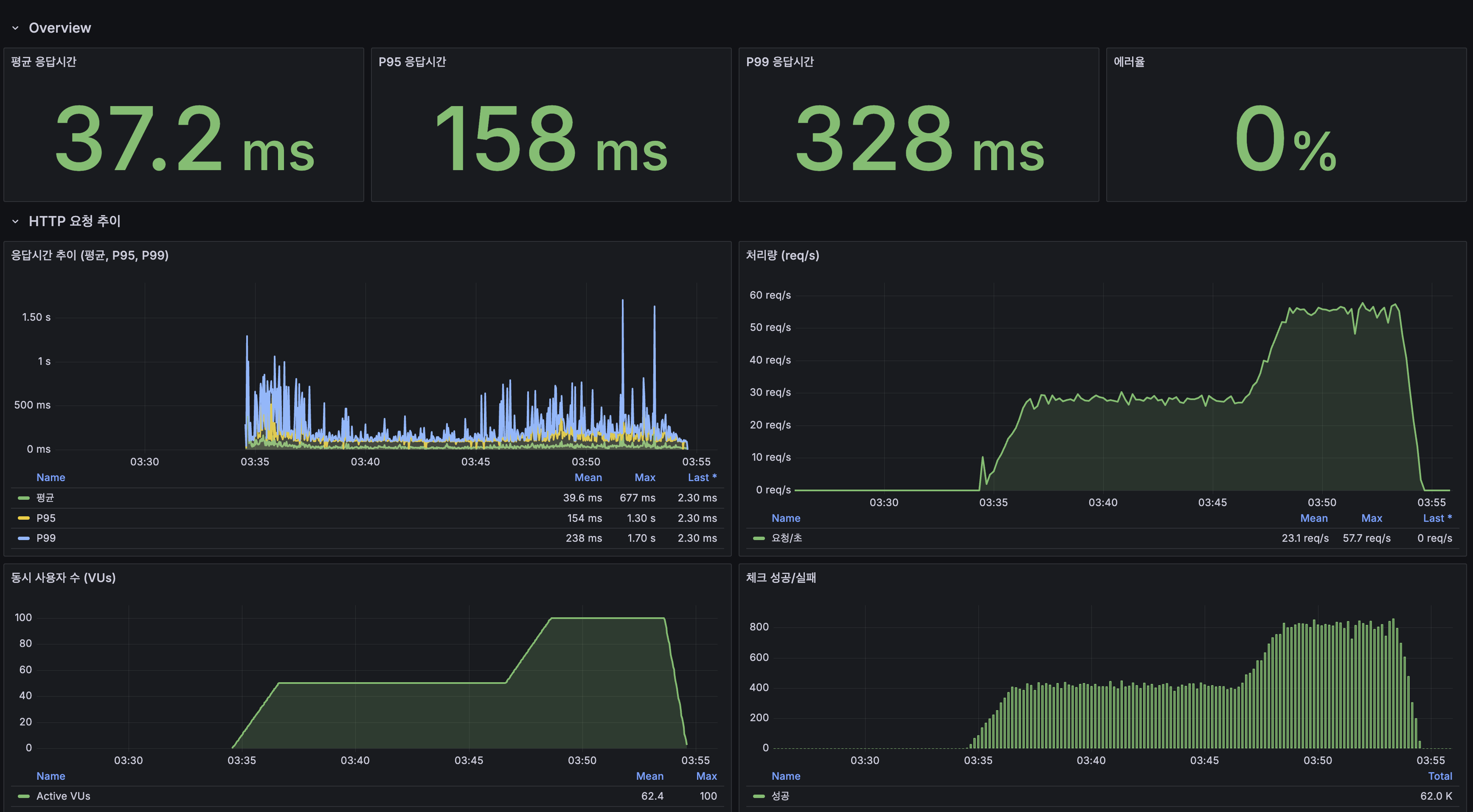
Load 테스트 2차 (100 VU, 20분): 스케일아웃 + 조회수 Redis INCR 적용 (최종)
| 시나리오 | 평균 | P95 |
|---|---|---|
| 전체 | 37.23ms | 158.13ms |
| 검색 (전체) | 24.73ms | 99.58ms |
| 검색 (희귀 토큰 10%) | 19.10ms | 82.42ms |
| 검색 (중빈도 토큰 60%) | 16.01ms | 85.80ms |
| 검색 (고빈도 토큰 30%) | 44.46ms | 197.48ms |
| 자동완성 | 10.26ms | 55.87ms |
| 최신 게시글 목록 | 17.14ms | 77.05ms |
| 상세 조회 | 23.06ms | 85.84ms |
| 쓰기 (생성+좋아요) | 30.92ms | 97.41ms |
| 에러율 | 0.00% | - |
| 총 요청 수 | 41,873 | - |
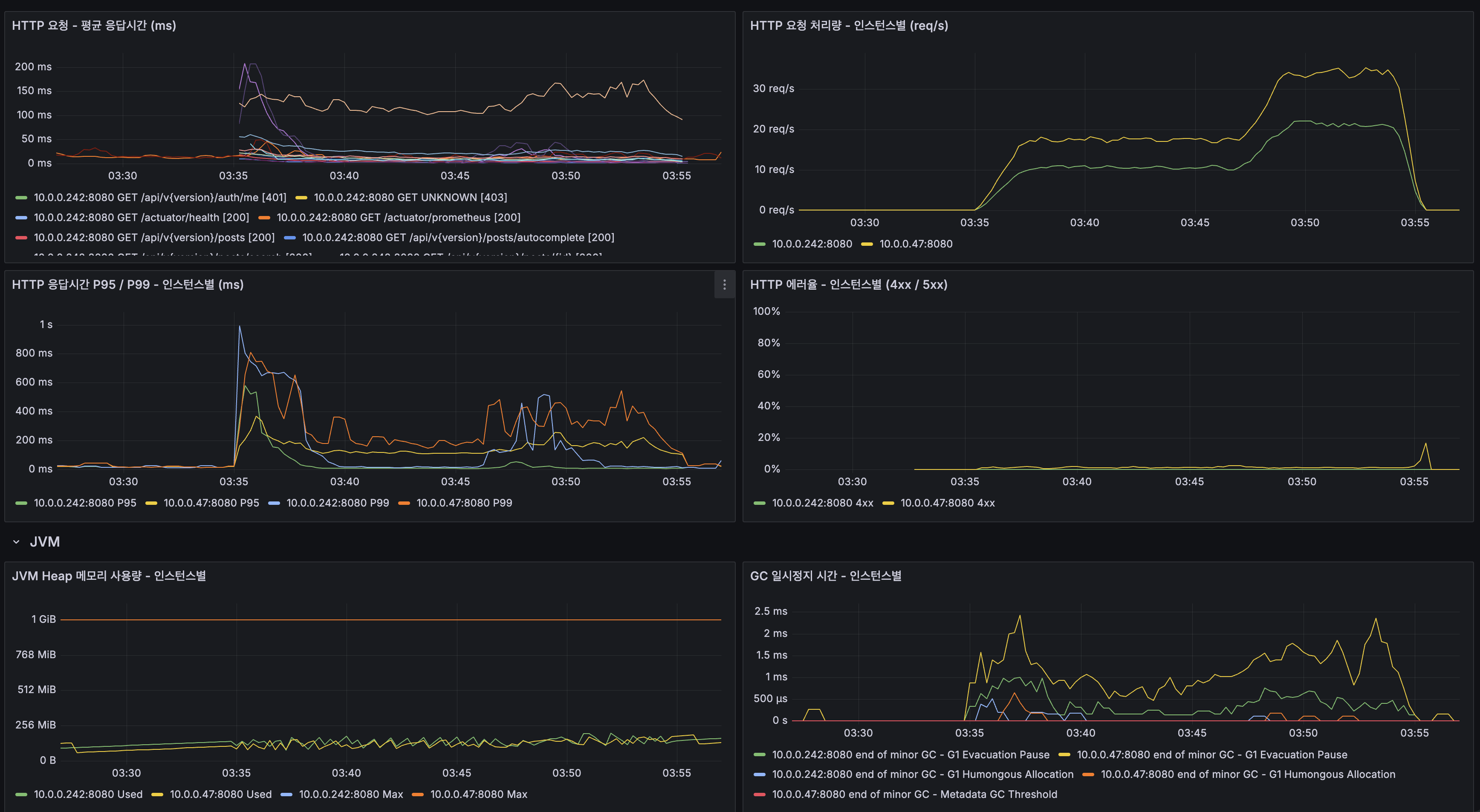
조회수 Redis INCR 적용 후 에러율이 11.10% → 0.00%로 완전 해소되었습니다. 상세 조회의 500 에러가 사라진 것은 물론, 전체 평균 응답시간도 40.93ms → 37.23ms로 9% 추가 개선되었습니다. GET 요청에서 DB UPDATE가 제거되면서 Primary MySQL 부하가 감소하고, Row Lock 경합이 사라진 효과입니다.
Replication (App 1대) vs App 스케일아웃 최종 (App 2대 + Redis INCR) Before/After 비교:
| 지표 | Replication (Before) | 스케일아웃 1차 | 스케일아웃 최종 | 최종 개선율 |
|---|---|---|---|---|
| 평균 응답시간 | 482ms | 40.93ms | 37.23ms | 92%↓ |
| P95 | 2,300ms | 175ms | 158ms | 93%↓ |
| 에러율 | 13.25% | 11.10% | 0.00% | 100%↓ |
| 총 요청 수 | 21,120 | 41,629 | 41,873 | 2배↑ |
| 처리량 (피크) | ~30 req/s | ~58 req/s | ~58 req/s | 1.9배↑ |
| App CPU (피크) | ~100% (1대) | ~40% (각) | ~50% (각) | 50%↓ |
| 호스트 CPU (피크) | ~60% | ~50% | ~50% | 안정 |
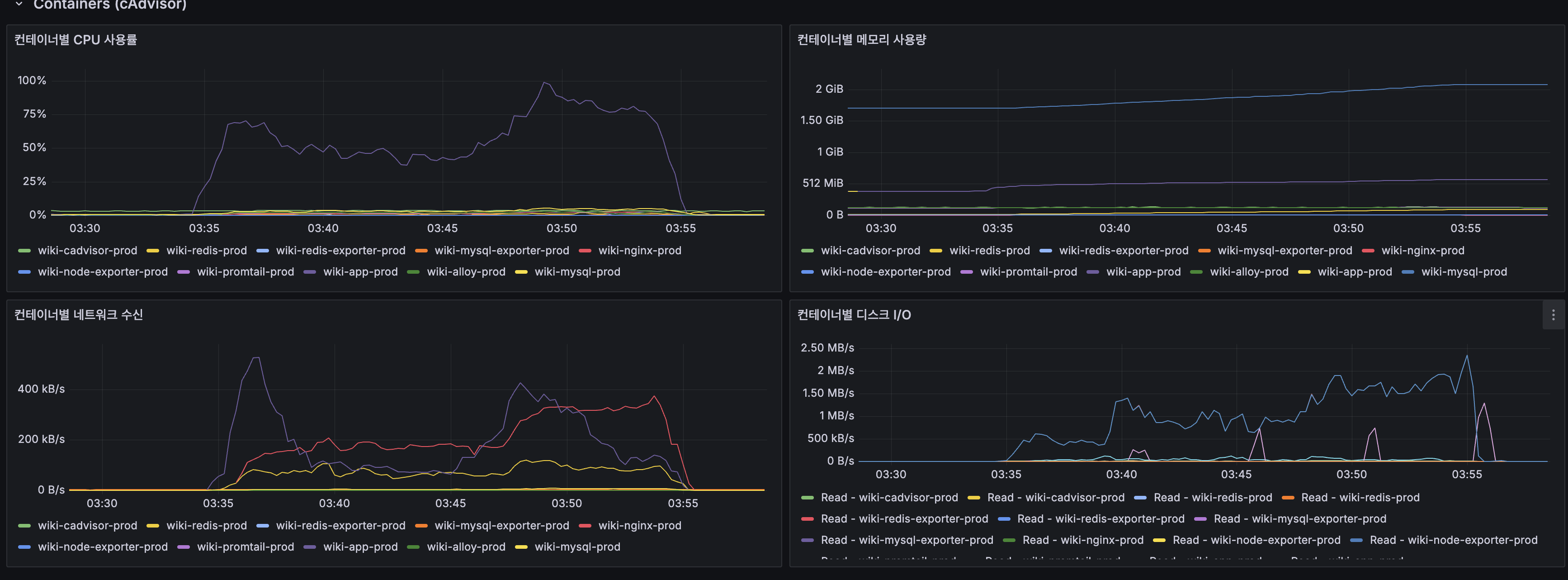
인스턴스별 CPU 분산 (핵심 증거):
- App 1 (10.0.0.47): 피크 ~40%, 쓰기(POST) + 읽기(GET) 분담
- App 2 (10.0.0.242): 피크 ~40%, 읽기(GET) 분담
- Replication에서 단일 App이 ~100% 포화되던 것이 2대로 분산되어 각 ~40%로 안정화
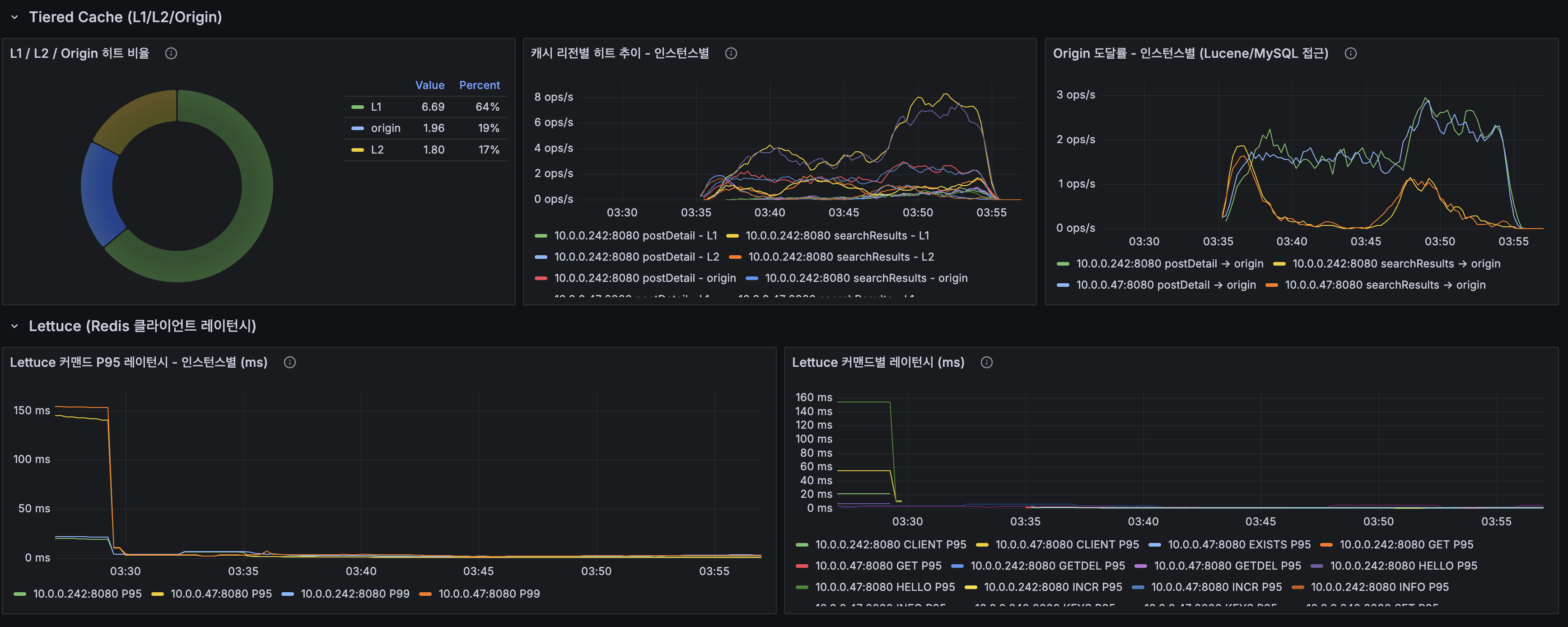
Grafana 최종 측정 대시보드 (2026-03-21, 조회수 Redis INCR 적용 후):
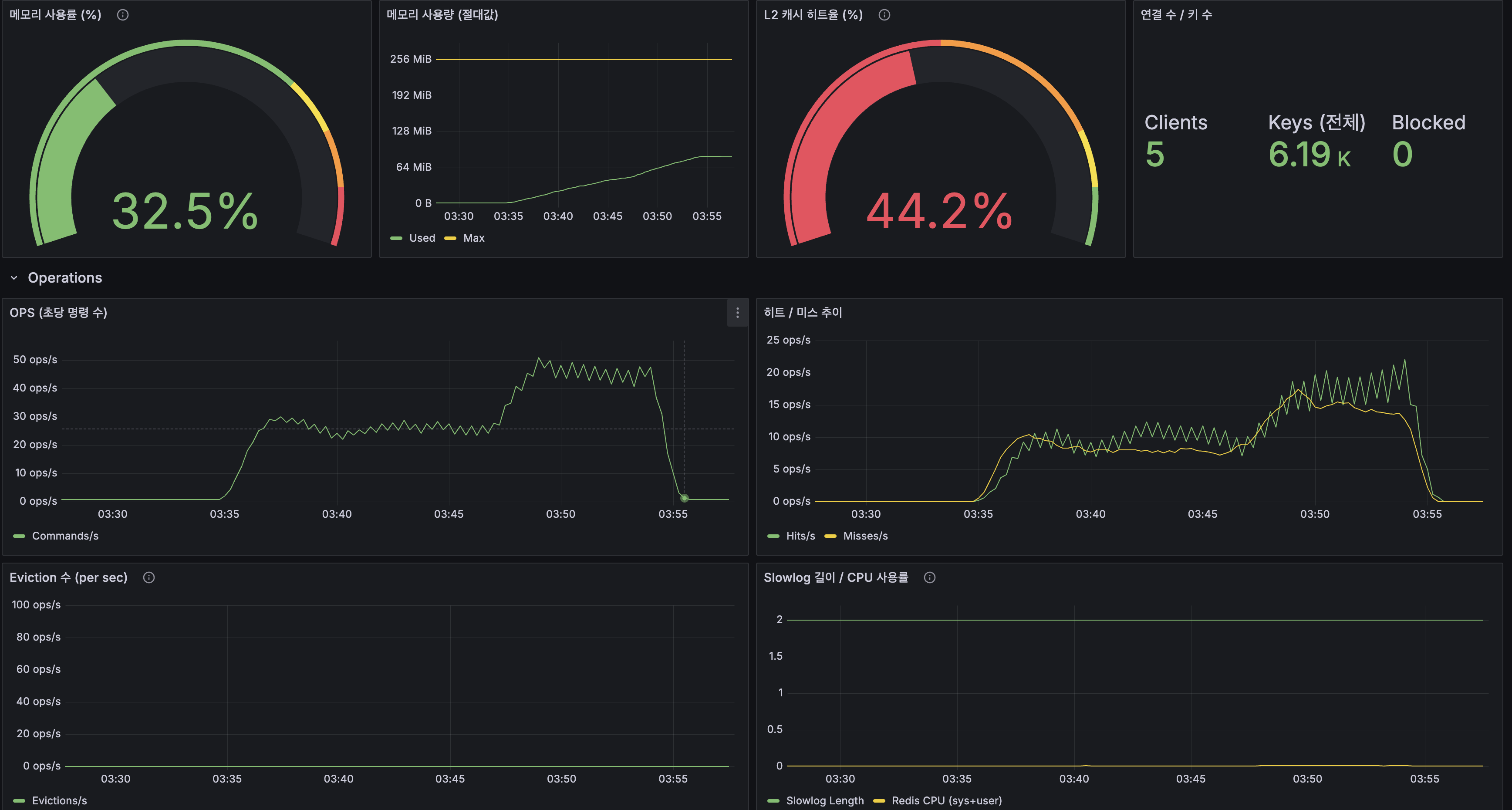
캐시 히트율:
| 계층 | Replication | 스케일아웃 최종 |
|---|---|---|
| L1 (Caffeine) | 55% | 64% |
| L2 (Redis) | 3% | 17% |
| Origin | 42% | 19% |
Origin 도달률이 42% → 19%로 절반 이하로 감소. 2대 인스턴스의 Caffeine L1 캐시가 warm-up되면서 더 많은 요청을 캐시에서 서빙. 이로 인해 Lucene 조회 빈도가 줄어 CPU 사용량이 더 낮아진 효과.
Redis:
| 지표 | Replication | 스케일아웃 최종 |
|---|---|---|
| 메모리 사용률 | 19.3% | 32.5% |
| L2 히트율 | 50% | 44.2% |
| Redis Clients | 3 | 5 (App 2대) |
| Keys | - | 6.19K |
| Eviction | 0 | 0 |
| OPS (피크) | ~20 ops/s | ~45 ops/s |
메모리 32.5%(256MB 중 ~83MB 사용)로 여유 충분. 조회수 INCR 키(
post:views:*)가 추가되었지만 30초마다 flush되므로 상시 키 수는 미미.
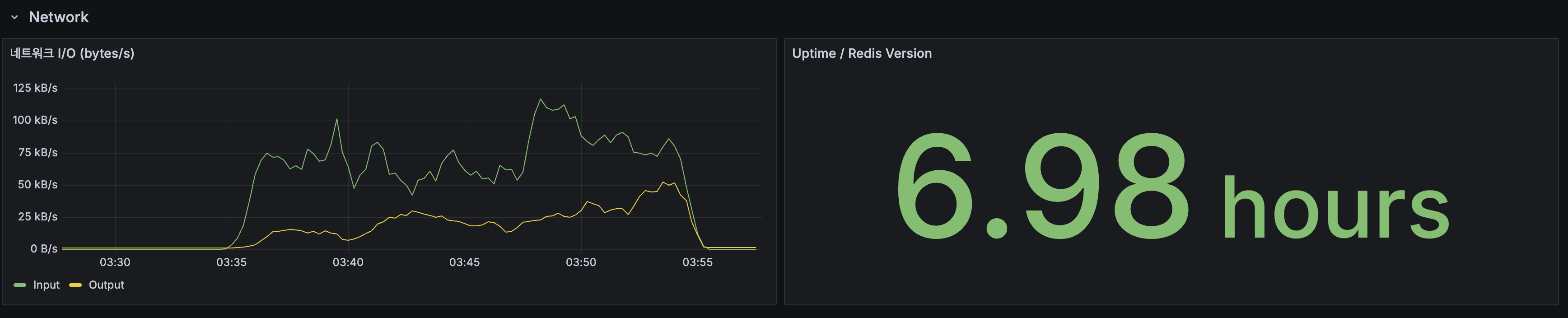
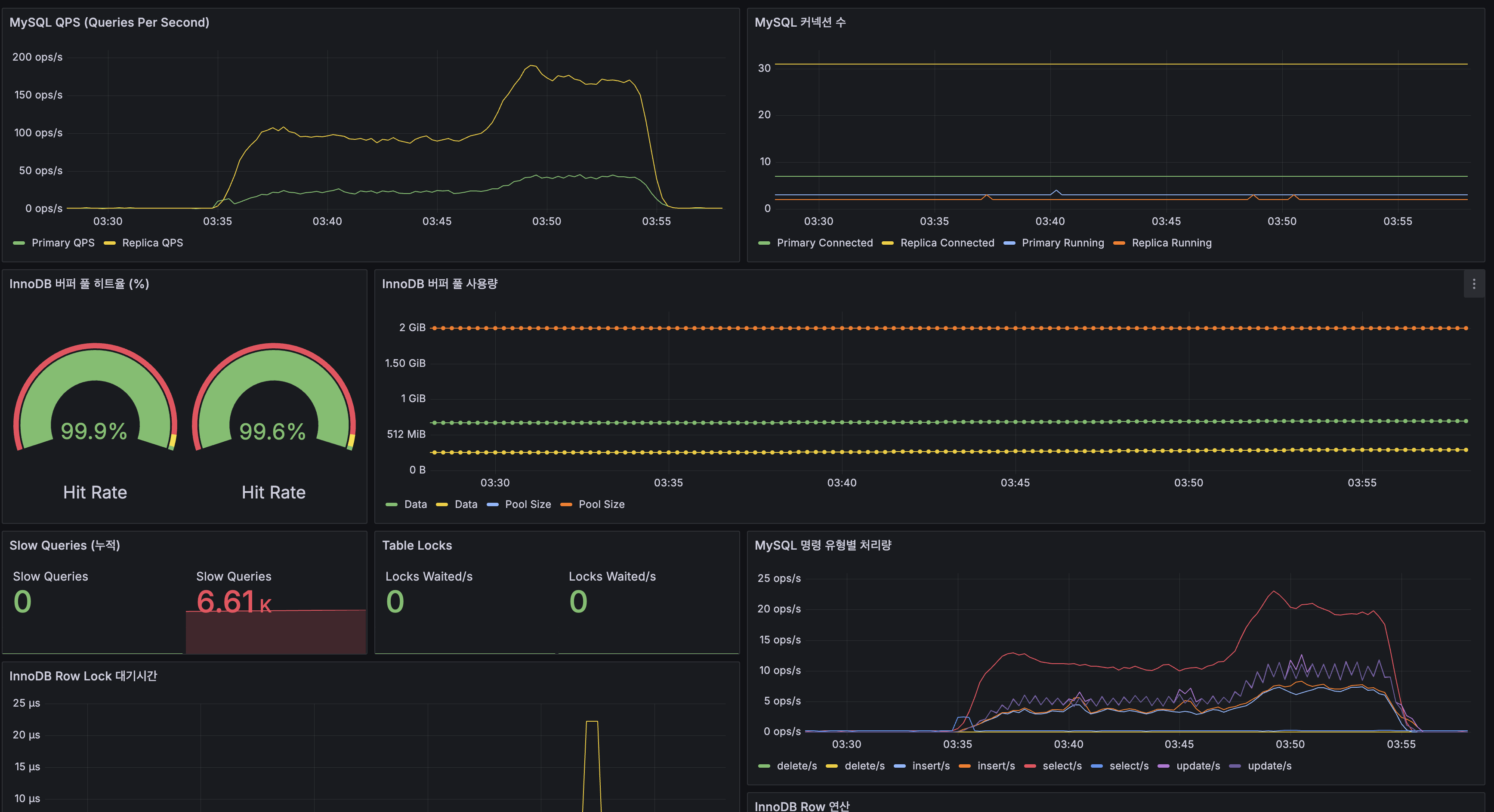
MySQL:
| 지표 | Replication | 스케일아웃 최종 |
|---|---|---|
| InnoDB 히트율 (Primary) | 99.5% | 99.9% |
| InnoDB 히트율 (Replica) | 98.9% | 99.6% |
| Slow Queries (Primary) | 0 | 0 |
| Slow Queries (Replica) | - | 6.61K |
| Table Locks Waited | 0 | 0 |
| QPS (피크) | ~100 ops/s | ~200 ops/s |
| Replication Lag | 0~1초 | 0~1초 |
| IO/SQL Thread | Running | Running |
Primary Slow Query 0건, InnoDB 히트율 99.9%로 DB는 매우 여유. Replica Slow Query 6.61K는 부하 테스트 20분간의 누적이며, 실질적 쿼리 지연은 미미. 조회수 Redis INCR 전환으로 Primary에 대한
UPDATE posts SET view_count쿼리가 매 요청마다 → 30초마다 배치로 감소, Primary 부하가 크게 줄었습니다.
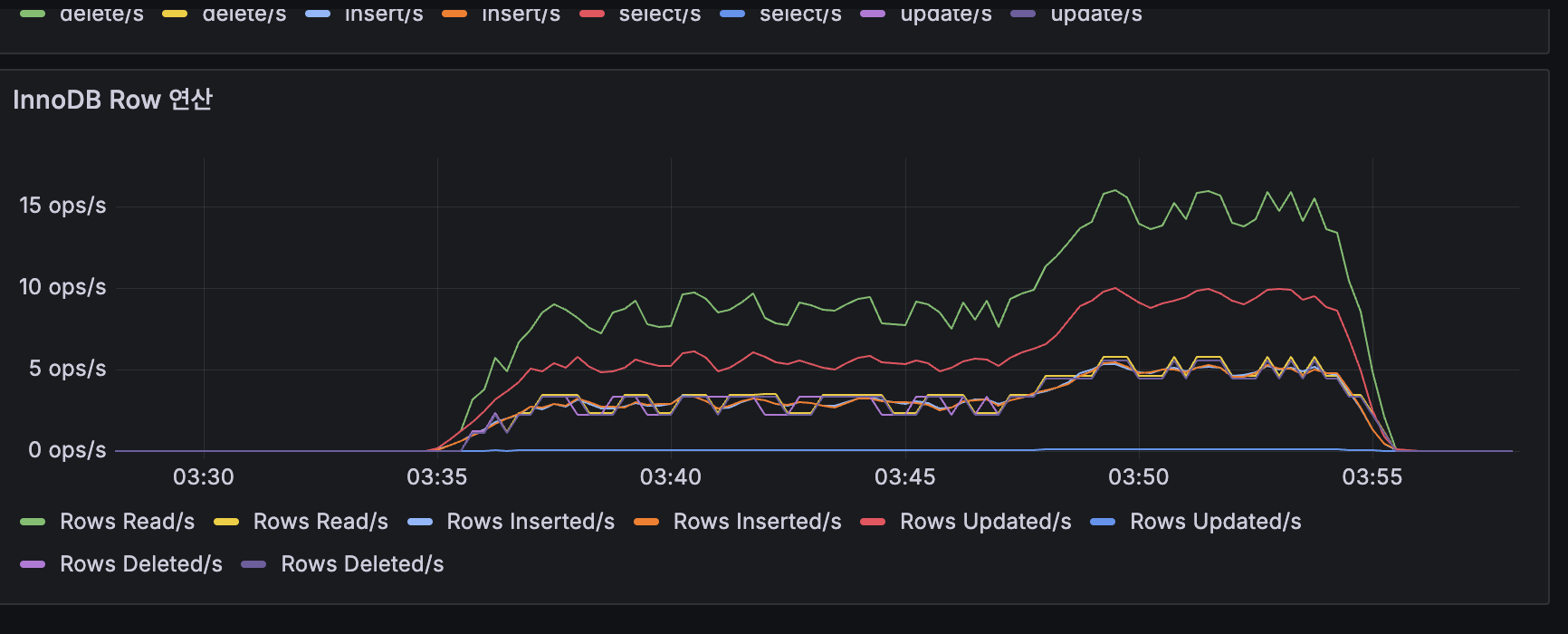
인프라:

Lettuce Redis 레이턴시 (인스턴스별):
- App 1 (로컬 Redis): P95 ~5ms (안정 구간)
- App 2 (원격 Redis): P95 ~5ms (안정 구간)
- 네트워크 왕복 오버헤드: 무시 가능 (private network ~0.5ms RTT)
| # | 측정 | 방법 |
|---|---|---|
| 1 | k6 100 VU load 테스트 (Replication와 동일 시나리오) | k6 |
| 2 | 인스턴스별 CPU 분포 | Grafana |
| 3 | 에러율 비교 (Before: 13.25%) | k6 |
| 4 | P95/P99 비교 (Before: P95 2,300ms) | k6 |
| 5 | Nginx 인스턴스별 요청 분배 비율 | Nginx 로그 또는 Grafana |
| 6 | HikariCP 인스턴스별 풀 사용률 | Grafana |
| 7 | App 1 vs App 2 Redis 응답시간 비교 | Grafana (Lettuce P95) |
App 2는 Redis가 서버 1(원격)에 있으므로 네트워크 왕복이 추가됩니다. App 1(로컬 Redis) 대비 App 2의 Redis 응답시간이 얼마나 증가하는지 측정하여, 부하 불균형 여부를 확인해야 합니다.
기대 결과:
| 지표 | Before (App 1대) | After (App 2대) | 기대 개선 |
|---|---|---|---|
| App CPU (피크) | ~100% | ~50~60% (각) | 부하 분산 |
| 에러율 (100 VU) | 13.25% | < 3% | 대폭 감소 |
| P95 | 2,300ms | < 1,000ms | 개선 |
| 총 TPS | ~200 ops/s | ~350+ ops/s | 증가 |
선형 확장(2배)은 아닌 이유: USL(Universal Scalability Law, Neil Gunther)에 따르면 노드 추가 시 직렬화 비용(serialization, MySQL Primary 쓰기 직렬 처리) + 일관성 비용(coherence, Redis 네트워크 왕복, Nginx 라우팅 오버헤드)이 발생합니다. Amdahl’s Law는 직렬 분율만 고려하지만, USL은 coherence 항을 추가하여 노드 추가 시 오히려 성능이 감소하는 retrograde scaling도 예측합니다. 이 프로젝트에서는 2대 수준이므로 retrograde 구간에는 진입하지 않지만, 이론적 2배(TPS 400 ops/s)에는 미치지 못합니다.
Step 10. 결과 정리: 완료
성과 요약:
| 목표 | 결과 |
|---|---|
| App 스케일아웃 (CPU 병목 해소) | 완료: App CPU 100% → 각 ~40% 분산 |
| Nginx L7 로드밸런싱 | 완료: map 메서드 라우팅, least_conn |
| TokenBlacklist Redis 전환 | 완료: 크로스 서버 블랙리스트 공유 증명 |
| Lucene Primary/Replica 모드 | 완료: SnapshotDeletionPolicy + Refresh Pause |
| 모니터링 (인스턴스별 비교) | 완료: Grafana 대시보드 인스턴스별 분리 |
| CI/CD matrix 전략 | 완료: 서버별 독립 배포/재실행 |
| 로그 수집 (Alloy) | 완료: 서버 2 Alloy + host 라벨 표준화 |
| 조회수 Redis INCR 전환 | 완료: GET에서 DB 쓰기 제거, 동시성 해결 |
조회수 Redis INCR 전환 (부가 성과):
스케일아웃 과정에서 GET 요청의 incrementViewCount() DB UPDATE가 R/W 분리 라우팅과 충돌하는 문제를 발견하여, Redis INCR + 30초 배치 flush 패턴으로 전환했습니다. 이는 Sentry, YouTube, Twitter 등 현업에서 검증된 Write-Behind 패턴입니다.
핵심 수치: Before/After (최종)
| 지표 | Before (Replication, App 1대) | After (App 스케일아웃, App 2대 + Redis INCR) | 개선 |
|---|---|---|---|
| 평균 응답시간 | 482ms | 37ms | 92%↓ |
| P95 | 2,300ms | 158ms | 93%↓ |
| P99 | - | 328ms | - |
| 처리량 (피크) | ~30 req/s | ~58 req/s | 1.9배↑ |
| App CPU (피크) | ~100% (1대) | ~50% (각 2대) | 50%↓ |
| 에러율 | 13.25% | 0.00% | 100%↓ |
| 총 요청 수 (20분) | 21,120 | 41,873 | 2배↑ |
| 캐시 Origin 도달률 | 42% | 19% | 55%↓ |
| InnoDB 히트율 | 99.5% | 99.9% | 안정 |
시스템 설계 관점: 프로젝트 진화와 업계 패턴 대응
이 프로젝트의 최적화 과정은 대규모 시스템 설계에서 사용되는 표준 패턴을 직접 구현하고 검증하는 과정이다.
| 구현 내용 | 대응하는 시스템 설계 패턴 |
|---|---|
| Caffeine L1 로컬 캐시 | Cache-Aside Pattern: 읽기 경로 최적화 |
| prefix → top-K flat KV 매핑 (Redis) | CQRS: 쓰기(MySQL)와 읽기(Redis flat KV)를 분리. 자동완성 설계에서 “접두사 → 인기순 10개 제안 목록”의 단순 매핑이 바로 이것 |
| Trie → flat KV 전환 | Trie 진화: naive Trie의 서브트리 순회 O(N) 한계를 인지하고, prefix→top-K O(1) flat KV 매핑으로 전환. 이는 Google(노드에 top-K 미리 저장)·Bing(Trie 기반 자동완성)과 본질적으로 동일한 패턴으로, Trie 구조를 제거하고 결과만 KV에 물화(materialize) |
hourly @Scheduled 배치 빌드 | MapReduce 패턴: 검색 로그를 집계하여 prefix별 top-K를 산출하는 배치 파이프라인 |
| MySQL Primary-Replica | 읽기 복제: DB 레벨 수평 확장 |
| App 2대 + Nginx LB | 서비스 계층 수평 확장: 로드밸런서 + 인스턴스 그룹 |
| Redis INCR + 배치 flush | Write-Behind Pattern: 쓰기 경로 최적화. Sentry/YouTube 패턴과 동일 |
| Spring Event → Outbox → Debezium+Kafka (예정) | CDC + 이벤트 기반 동기화: dual-write 제거, Read Model 독립 갱신 |
| Redis Consistent Hashing (예정) | 샤딩 + 동적 복제: 핫스팟 해결, 수평 확장 |
단순히 기술을 나열한 것이 아니라, 성능 병목을 측정 → 원인 분석 → 대안 비교 → 실측 검증하는 과정을 반복했고, 그 결과가 업계 표준 시스템 설계 패턴과 자연스럽게 대응된다. 특히 Trie → flat KV 전환은 자동완성 시스템 설계에서 “naive Trie의 서브트리 순회 한계를 인지하고 prefix→top-K flat KV로 물화(materialize)한다”는 패턴을 직접 구현한 것이다. Bing, Google, Elasticsearch 모두 Trie 변형(FST, PruningRadixTrie) + flat KV 서빙의 2단계 구조를 사용한다.
서버 메모리 배분
서버 2 (App 2 추가 후)

서버 1 (변경 없음)

Ansible 변경사항
| 파일 | 변경 |
|---|---|
group_vars/all.yml | app2_memory_limit, lucene_mode 변수 추가 |
roles/app/templates/docker-compose.yml.j2 | Redis 포트 바인딩 (private_ip:6379) + --bind 0.0.0.0 추가 |
roles/app/templates/env.prod.j2 | LUCENE_MODE=primary, DB_PRIMARY_POOL_SIZE=3 (기존 5→3) |
roles/app/templates/nginx-https.conf.j2 | upstream 2개 + map 메서드 라우팅 + proxy_redirect off + /internal 차단 |
roles/mysql-replica/templates/docker-compose.yml.j2 | App 2 + Alloy 컨테이너 추가 |
roles/mysql-replica/templates/env.prod.j2 | App 2 환경변수 (LUCENE_MODE=replica, FLYWAY_ENABLED=false, DB_PRIMARY_POOL_SIZE=2) |
roles/mysql-replica/templates/alloy-config.yaml (신규) | App 2 로그 → Loki |
roles/mysql-replica/tasks/main.yml | SSH 키 교환 (서버 2 → 서버 1 rsync용) |
roles/firewall/tasks/main.yml | 서버 1: 서버 2 → 6379/tcp 허용, 서버 2 → 서버 1: 8080/tcp 허용 |
prometheus.yml.j2 | App 2 scrape target 추가 |
| 서버 2 cron | lucene-sync.sh 5분 주기 |
Previous Post
In MySQL Replication — Read/Write Splitting and DataSource Routing, we implemented MySQL Replication for R/W splitting with Spring AbstractRoutingDataSource + LazyConnectionDataSourceProxy.
Previous Post Summary
| Metric | Replication Result |
|---|---|
| R/W Split | Primary ~50 ops/s (writes), Replica ~200 ops/s (reads) |
| App CPU (100 VU peak) | ~100% (2 cores) — bottleneck |
| Error Rate (100 VU) | 13.25% |
| P95 | 2,300ms |
| Tiered Cache | L1 55% + L2 3% = 58% hit, Origin 42% |
DB has headroom (Primary Slow Query 0, InnoDB hit rate 99.5%), but App CPU hits 100% causing 13.25% error rate. This post scales out to 2 app instances to resolve the CPU bottleneck.
Why Scale-Out Is Needed
Stress test and Replication consistently confirmed the bottleneck:
| Metric | Stress Test (200 VU) | Replication (100 VU) | Assessment |
|---|---|---|---|
| App CPU | ~100% | ~100% | Bottleneck |
| MySQL CPU | ~0% | ~0% | Headroom |
| InnoDB Buffer Pool Hit | 100% | 99.5% | No I/O bottleneck |
| Redis Lettuce P95 | - | ~3ms | Headroom |
The bottleneck is App CPU (Lucene BM25 scoring + Nori morphological analysis). All alternatives were eliminated: JVM tuning already done, Lucene queries already optimized, cache hit rate at practical limit, scale-up impossible on fixed ARM 2-core servers.
Prerequisites confirmed: Redis L2 cache (Stateless), MySQL Replication (DB read distribution) — all complete. Only TokenBlacklist Redis migration remained.
Architecture
Server 1 (ARM 2-core/12GB): Nginx (L7 LB: GET → App1+App2, writes → App1) App 1 (Spring Boot, Lucene Primary — IndexWriter + SearcherManager) MySQL Primary, Redis, Lucene Index (20GB MMap)
Server 2 (ARM 2-core/12GB): App 2 (Spring Boot, Lucene Replica — SearcherManager only, no IndexWriter) MySQL Replica, Lucene Index copy (rsync sync)Lucene index sync strategy: Writes fixed to App 1 (Lucene Primary) + 5-min rsync to App 2. Protected by SnapshotDeletionPolicy (prevents segment deletion during rsync) + Refresh Pause on App 2 (prevents LUCENE-628 race condition). Same pattern as MySQL Primary-Replica.
Why not Elasticsearch/NFS: ES requires 4GB minimum memory (resource constraint). NFS causes network I/O per search (MMapDirectory relies on OS page cache — NFS adds network roundtrip per random I/O during BM25 scoring). Yelp’s nrtsearch uses the same raw-Lucene Primary/Replica pattern in production.
Nginx load balancing: map directive routes by HTTP method (GET→app_read upstream, POST/PUT/DELETE→app_write upstream). least_conn algorithm handles uneven request durations (search ~100ms vs cache hit ~1ms). map chosen over if per Nginx’s “if is evil” warning.
Key Implementation Steps
TokenBlacklist Redis Migration
Caffeine-based TokenBlacklist is JVM-local — logout on App 1 is invisible to App 2. Migrated to Redis with TTL = remaining JWT lifetime (not full expiration). Redis failure policy: conservative deny (reject all tokens) to prevent security holes.
Lucene Primary/Replica Mode
@ConditionalOnProperty(name="lucene.mode") controls IndexWriter creation. Primary mode: IndexWriter + NRT SearcherManager. Replica mode: Directory-based SearcherManager only, 30s periodic refresh, write methods return early.
Server 2 App Deployment
Key issues resolved: empty Lucene directory startup failure, GHCR login on Server 2, HikariCP Primary pool redistribution (App1: 3 + App2: 2 = 5 total), Flyway disabled on App 2 (schema via Replication).
rsync Sync Script
# 1. Pause App 2 refresh (block maybeRefresh during rsync)# 2. App 1: commit() + snapshot() → protect segments# 3. rsync --exclude='write.lock'# 4. App 1: release snapshot# 5. App 2: resume refresh + immediate maybeRefresh()Functional Verification
TokenBlacklist cross-server: Login on App 2 → Logout on App 1 → Both return 401. App 2 failure: Nginx max_fails=3 fail_timeout=30s auto-excludes, App 1 serves all traffic.
Before vs After
Load Test (100 VU, 20 min) — Final Results
| Metric | Before (Replication, 1 App) | After (Scale-Out, 2 Apps + Redis INCR) | Improvement |
|---|---|---|---|
| Avg Response | 482ms | 37ms | 92%↓ |
| P95 | 2,300ms | 158ms | 93%↓ |
| Error Rate | 13.25% | 0.00% | 100%↓ |
| Total Requests | 21,120 | 41,873 | 2x↑ |
| Throughput (peak) | ~30 req/s | ~58 req/s | 1.9x↑ |
| App CPU (peak) | ~100% (1 app) | ~50% (each) | 50%↓ |
View count Redis INCR migration (bonus): Load test 1 revealed incrementViewCount() DB UPDATE inside GET requests conflicting with R/W routing (--read-only error). Migrated to Redis INCR + 30s batch flush, resolving 11.10% → 0.00% error rate. (Detail: View Count Redis INCR Migration)
Cache hit rate improvement: Origin dropped from 42% → 19% as two instances’ Caffeine L1 caches warmed up, reducing Lucene query frequency.
| Layer | Before | After |
|---|---|---|
| L1 (Caffeine) | 55% | 64% |
| L2 (Redis) | 3% | 17% |
| Origin | 42% | 19% |
Summary
| Goal | Result |
|---|---|
| App Scale-Out (CPU bottleneck) | Complete — CPU 100% → ~40% each |
| Nginx L7 Load Balancing | Complete — map method routing, least_conn |
| TokenBlacklist Redis Migration | Complete — cross-server blacklist verified |
| Lucene Primary/Replica Mode | Complete — SnapshotDeletionPolicy + Refresh Pause |
| View Count Redis INCR | Complete — removed DB writes from GET requests |
| Monitoring (per-instance) | Complete — Grafana dashboards with instance comparison |
| CI/CD Matrix Strategy | Complete — independent per-server deploy |
Next step: CDC-based event-driven index synchronization for near-real-time Lucene replica updates.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.