조회수 Redis INCR + Write-Behind 배치 flush 전환
목차
이전 글
App 스케일아웃에서 Nginx L7 로드밸런싱으로 App 2대 스케일아웃을 구성하고, k6 100 VU 부하 테스트로 검증했습니다. 이 글은 스케일아웃 후 발생한 조회수 UPDATE의 R/W 라우팅 충돌 문제를 Redis INCR로 해결하는 과정입니다.
1. 정상 상태 인식
커뮤니티 게시판(1,215만 건)의 게시글 상세 조회 API(GET /api/v1.0/posts/{id})는 두 가지 작업을 수행했다:
// PostController.getPost()Post post = postService.findByIdCached(id); // ① 게시글 조회 (캐시 or DB)postService.incrementViewCount(id); // ② 조회수 +1 (DB UPDATE)return PostDetailResponse.from(post);조회수 증가는 @Transactional이 붙은 메서드로, JPA @Modifying 쿼리를 실행한다:
UPDATE posts SET view_count = view_count + 1 WHERE id = ?인프라:
- MySQL 8.0 Primary-Replica 구성 (Replication)
AbstractRoutingDataSource+LazyConnectionDataSourceProxy로 R/W 분리@Transactional(readOnly=true)→ Replica,@Transactional→ Primary- Nginx L7 로드밸런싱: GET → App 1 + App 2, POST → App 1 (App 스케일아웃)
2. 문제 상황 인식
App 스케일아웃(App 2대) 후 k6 100 VU 부하 테스트에서 상세 조회 시나리오 38건 전부 실패(pass=0, fail=38).
k6 check 결과: 상세 조회 → 상세 응답 200 또는 404 pass=0 fail=38직접 curl로 확인:
# 존재하는 게시글 — 500 에러$ curl 'https://api.studywithtymee.com/api/v1.0/posts/571474'{"status":500,"message":"서버 내부 오류가 발생했습니다","code":"INTERNAL_ERROR"}
# 존재하지 않는 게시글 — 404 정상$ curl 'https://api.studywithtymee.com/api/v1.0/posts/99999999'{"status":404,"message":"게시글을 찾을 수 없습니다","code":"POST_NOT_FOUND"}서버 로그 에러 메시지:
Caused by: java.sql.SQLException: The MySQL server is running withthe --read-only option so it cannot execute this statementApp 1(서버 1)에서 2건 발생, App 2(서버 2)에서 0건.
3. 문제 분석
구조적 원인: GET 요청에 DB 쓰기(UPDATE)가 포함되어 R/W 분리와 충돌

incrementViewCount()는 @Transactional(readOnly=false)이므로 ReadWriteRoutingDataSource가 “primary”를 반환하고, LazyConnectionDataSourceProxy가 Primary 커넥션을 할당해야 한다. 이론적으로는 정상 동작해야 한다.
하지만 실제로 간헐적으로 Replica에 UPDATE가 도달하여 read-only 에러가 발생했다. Vlad Mihalcea, Baeldung 등 복수의 문서에서 “readOnly GET 요청 안에 write 메서드를 호출하는 구조”가 AbstractRoutingDataSource 기반 R/W 분리에서 알려진 문제(known pitfall)임을 확인했다.
부수적 문제: Row Lock 경합
정상 동작하더라도, 100 VU 동시 접속 시 동일 게시글에 대한 UPDATE posts SET view_count = view_count + 1 WHERE id = ?는 InnoDB의 배타적 행 잠금(X Lock)을 유발한다. 100개 트랜잭션이 같은 행에 UPDATE를 시도하면 직렬화되어 순차 대기 → 처리량이 MySQL 기준 ~500-1,000 ops/s로 제한된다 (SSD + innodb_flush_log_at_trx_commit=1 기준. HDD에서는 ~50 ops/s까지 하락, 내구성 설정 완화 시 수만 ops/s 가능하지만 데이터 유실 위험).
4. 대안 검토
| 방안 | 장점 | 단점 | 판단 |
|---|---|---|---|
| try-catch로 500 방지 | 코드 1줄 추가 | 근본 원인 미해결, 조회수 유실 | 탈락 (임시방편) |
| REQUIRES_NEW 전파 | 별도 트랜잭션으로 Primary 강제 | 여전히 매 요청 DB UPDATE, Row Lock 경합 존재 | 탈락 (아래 상세) |
| DB 락 (SELECT FOR UPDATE / 낙관적 락) | 동시성 해결 | 동시성이 높을수록 성능 저하, 여전히 매 요청 DB UPDATE | 탈락 (아래 상세) |
| @Async 비동기 UPDATE | 응답 지연 제거 | 여전히 매 요청 DB UPDATE, 스레드 풀 관리·에러 전파 복잡 | 탈락 (아래 상세) |
| 로컬 캐시(Caffeine) 카운터 + 배치 flush | DB 쓰기 제거, 추가 인프라 없음 | 멀티 인스턴스에서 카운터 유실 위험 | 탈락 (아래 상세) |
| Redis INCR + 배치 flush | GET에서 DB 쓰기 완전 제거, O(1) 원자적, Row Lock 없음, 인스턴스 공유 | 조회수 최대 30초 지연 | 선택 |
대안별 상세 분석
방안 1: REQUIRES_NEW 트랜잭션 분리
incrementViewCount()에 @Transactional(propagation = REQUIRES_NEW)를 붙이면, 외부 트랜잭션(readOnly=true)과 독립적으로 새 트랜잭션을 열어 Primary로 라우팅한다.
- R/W 라우팅 문제는 해결됨: 새 트랜잭션은
readOnly=false이므로 Primary로 정상 라우팅 - 하지만 근본 문제가 남음: 매 GET 요청마다
UPDATE posts SET view_count = view_count + 1이 Primary MySQL에 실행된다. 100 VU 동시 접속 시 동일 게시글에 대한 UPDATE는 InnoDB의 배타적 행 잠금(X Lock)을 유발하여 트랜잭션이 직렬화된다. 인기 게시글에 조회가 집중되면 Primary MySQL이 조회수 UPDATE의 Row Lock 경합으로 병목이 된다. - 추가 비용: REQUIRES_NEW는 별도 DB 커넥션을 소비한다. HikariCP primary-pool에서 조회수 UPDATE만을 위한 커넥션이 추가로 점유되어, 실제 쓰기(게시글 생성/수정) 요청의 커넥션 획득 대기가 증가할 수 있다.
R/W 라우팅 충돌만 해결하고, 성능 문제(Row Lock)와 DB 부하 문제는 해결하지 못한다.
방안 2: DB 락 (비관적/낙관적)
비관적 락: SELECT view_count FROM posts WHERE id = ? FOR UPDATE → +1 → UPDATE낙관적 락: UPDATE posts SET view_count = view_count + 1 WHERE id = ? AND view_count = ?- 비관적 락(SELECT FOR UPDATE): 트랜잭션이 행에 대한 X Lock을 명시적으로 획득한 뒤 UPDATE한다. 동시성은 보장되지만, SELECT + UPDATE 2회 쿼리가 필요하고, 락을 잡고 있는 동안 다른 트랜잭션이 대기(직렬화)한다. 측정 결과 100건 동시 요청 시 약 400ms 걸렸다.
- 낙관적 락(CAS 패턴):
WHERE view_count = 이전값조건으로 UPDATE하고, 실패 시 재시도한다. 충돌이 적으면 효율적이지만, 인기 게시글에 100 VU가 동시 접속하면 대부분이 충돌하여 재시도 폭증 → 오히려 DB 부하가 증가한다. - 공통 문제: 두 방식 모두 매 GET 요청마다 Primary MySQL에 UPDATE를 실행한다. R/W 라우팅 충돌은 별도 트랜잭션으로 회피할 수 있지만, “GET 요청이 DB 쓰기를 유발한다”는 설계적 문제가 남는다.
동시성 자체는 해결되지만, GET에서 DB 쓰기가 존재하는 구조적 문제와 Row Lock 경합이 그대로다.
방안 3: @Async 비동기 UPDATE
incrementViewCount()에 @Async를 붙이면 호출 즉시 리턴하고 별도 스레드에서 DB UPDATE를 실행한다.
- 응답시간은 개선됨: 사용자 응답에서 UPDATE 대기 시간이 제거
- 하지만 문제가 이동했을 뿐: 별도 스레드에서 매 요청마다 DB UPDATE가 실행되므로 Primary 부하는 동일. 스레드 풀 크기를 어떻게 설정할지(너무 작으면 큐 적체, 너무 크면 커넥션 풀 고갈), 스레드 풀 풀일 때 요청이 드롭되는 문제, 에러 발생 시 호출자에게 전파할 수 없는 문제가 추가된다.
- R/W 라우팅 문제:
@Async메서드는 별도 스레드에서 실행되므로 기존 트랜잭션 컨텍스트를 물려받지 않는다. 별도@Transactional이 필요하고, 이는 REQUIRES_NEW와 동일한 구조.
응답 지연만 제거하고, DB 부하·Row Lock·스레드 풀 관리 복잡성이 추가된다.
방안 4: 로컬 캐시(Caffeine) 카운터 + 배치 flush
각 App 인스턴스에서 ConcurrentHashMap<Long, AtomicLong>으로 조회수를 누적하고, 30초마다 DB에 배치 UPDATE한다.
- 장점: 추가 인프라 없음(Redis 불필요), 로컬 메모리 접근이므로 INCR 속도가 Redis보다 빠름(~1ns vs ~0.1ms)
- 단점 1, App 재시작 시 카운터 유실: JVM 메모리에만 존재하므로 App이 재배포/재시작되면 flush 전 누적분이 소멸한다. 배포가 잦은 CI/CD 환경에서는 배포할 때마다 조회수가 유실된다.
- 단점 2, 중복 방지 불가: 향후 동일 사용자의 중복 조회 방지(
SET post:viewed:{sessionId}:{postId} NX EX 86400)를 구현하려면 인스턴스 간 공유 상태가 필요하다. Caffeine은 로컬이므로 App 1에서 조회한 사용자가 App 2에서 다시 조회하면 중복으로 카운트된다. 이 기능을 위해 결국 Redis가 필요하다. - 단점 3, 관측 불가: 현재 조회수가 얼마인지 확인하려면 각 App의 내부 상태를 개별 조회해야 한다. Redis는
GET post:views:123으로 즉시 확인 가능.
단일 인스턴스에서는 유효하지만, 멀티 인스턴스(App 스케일아웃)에서는 유실·중복 방지 불가·관측성 문제로 부적합.
Redis INCR 선택 근거 (종합)
위 5개 대안은 모두 “GET 요청에서 DB 쓰기가 발생한다”는 구조적 문제를 근본적으로 해결하지 못하거나, 멀티 인스턴스 환경에서 한계가 있다. Redis INCR + 배치 flush가 선택된 이유:
- GET에서 DB 쓰기 완전 제거: R/W 분리 라우팅 충돌의 근본 원인을 구조적으로 해결. GET → Redis INCR(읽기 인프라), 배치 flush → DB UPDATE(쓰기 인프라,
@Scheduled에서 별도 트랜잭션) - Redis INCR은 O(1), 싱글스레드 원자적: 별도 락 없이 동시성 보장. MySQL UPDATE의 Row Lock 경합이 완전히 제거된다. 100 VU 동시 접속이든 1,000 VU이든 INCR 한 번이면 끝
- 성능: Redis INCR ~100,000+ ops/s vs MySQL UPDATE ~500-1,000 ops/s (동일 행 동시 접근, SSD +
innodb_flush_log_at_trx_commit=1기준). 약 100배 처리량 차이. Redis 수치는 Redis 공식 벤치마크 기준이며, MySQL 수치는 SSD 환경에서의 단일 hot row 경합 시 업계 참고치이다 (본 프로젝트 환경에서 직접 벤치마크하지 않은 추정값. HDD에서는 ~50 ops/s,innodb_flush_log_at_trx_commit=2완화 시 수만 ops/s 가능) - 멀티 인스턴스 공유 상태: App 1과 App 2가 같은 Redis 키에 INCR하므로, 카운터 유실이나 중복 문제 없음. 향후 중복 방지(
SET NX EX)도 Redis에서 바로 구현 가능 - 이미 Redis 인프라 있음: Redis L2 캐시에서 L2 캐시 + 자동완성 flat KV로 Redis를 이미 운영 중. 추가 인프라 비용 0
현업 사례
| 회사 | 패턴 | flush 주기 | 참고 |
|---|---|---|---|
| Sentry | Redis INCR + Lua Script + SQL 배치 flush | 10초 | Redis INCR로 이벤트 카운팅 후 Lua Script로 원자적 rate limit 판정. “The current model of rate limits generally does an increment in Redis and then uses that result to test things” (Sentry Developer Docs) |
| YouTube | 인메모리 카운터 + 주기적 배치 flush | 수십 초 | ”100 like events might translate to a single UPDATE query, which is much more efficient than 100 separate updates”. 극단적 트래픽에서는 샘플링(INCRBY 10) (Design Gurus) |
| Twitter/Instagram | append-only 이벤트 + denormalized 카운터 | 주기적 | Eventual Consistency 명시적 허용 |
| Stack Overflow | Redis + 로컬 인메모리 2계층 | TTL 기반 | Nick Craver 블로그 |
이 패턴은 Write-Behind (Write-Back) Caching Pattern으로, AWS 공식 캐싱 전략 문서에서도 “write-heavy workloads that can tolerate brief data loss”에 권장하는 표준 패턴이다. 30초 지연은 업계 표준 범위(10~60초) 내이며, 사용자가 새로고침 시 조회수가 정확히 1 증가하는 것을 기대하지 않는다.
Redis 장애 시 데이터 유실 위험에 대해서는, Redis AOF(
appendfsync everysec) 설정으로 최대 1초 분량의 쓰기만 유실된다. 이 프로젝트에서는 조회수 유실이 서비스에 치명적이지 않으므로 AOF 없이도 허용 가능하지만, 프로덕션에서는 “enabling both [RDB + AOF] is the recommended Redis backup strategy” (Redis Persistence Docs).
비용 분석
이 프로젝트는 OCI 환경이므로 월 과금이 없다. 비용은 고정 자원 배분 트레이드오프로 평가한다:

실무(AWS) 환경 참고:

5. 적용 및 결과
구현
ViewCountService (신규):
@Servicepublic class ViewCountService { private static final String KEY_PREFIX = "post:views:";
/** 조회수 1 증가 — Redis INCR, O(1), ~0.1ms */ public void increment(Long postId) { try { redisTemplate.opsForValue().increment(KEY_PREFIX + postId); } catch (RedisConnectionFailureException e) { log.warn("Redis 조회수 INCR 실패 (무시): postId={}", postId); // Redis 장애 시 조회수만 유실, 게시글 조회는 정상 } }
/** 30초마다 DB에 배치 flush */ @Scheduled(fixedRate = 30_000) @Transactional // readOnly=false → Primary 라우팅 public void flushToDB() { Set<String> keys = redisTemplate.keys(KEY_PREFIX + "*"); for (String key : keys) { String value = redisTemplate.opsForValue().getAndDelete(key); long delta = Long.parseLong(value); postRepository.incrementViewCountBy(postId, delta); } }}PostController 변경:
// Before — 매 GET마다 DB UPDATE (R/W 분리 충돌 + Row Lock)postService.incrementViewCount(id);
// After — Redis INCR (DB 안 탐, O(1), 원자적)viewCountService.increment(id);PostRepository 추가:
/** 배치 flush용: 조회수를 delta만큼 증가 */@Modifying@Query("UPDATE Post p SET p.viewCount = p.viewCount + :delta WHERE p.id = :id")void incrementViewCountBy(@Param("id") Long id, @Param("delta") long delta);Before/After 비교
| 지표 | Before (DB UPDATE) | After (Redis INCR) | 개선 |
|---|---|---|---|
| GET에서 DB 쓰기 | 매 요청마다 UPDATE | 없음 | R/W 라우팅 충돌 해결 |
| 상세 조회 에러율 | 100% (38/38 실패) | 0% | 500 에러 해결 |
| 조회수 동시성 | InnoDB Row Lock 직렬화 | Redis 싱글스레드 원자적 | Lock 경합 제거 |
| 처리량 (이론) | ~500-1,000 ops/s | ~100,000+ ops/s | ~100배 |
| Primary DB 부하 | 매 GET마다 UPDATE 1회 | 30초마다 배치 1회 | 99%+ 감소 |
| 조회수 정확도 | 실시간 | 최대 30초 지연 | 허용 가능 (Eventual Consistency) |
| Redis 장애 시 | 해당 없음 | 조회수만 유실, 조회 정상 | 안전 |
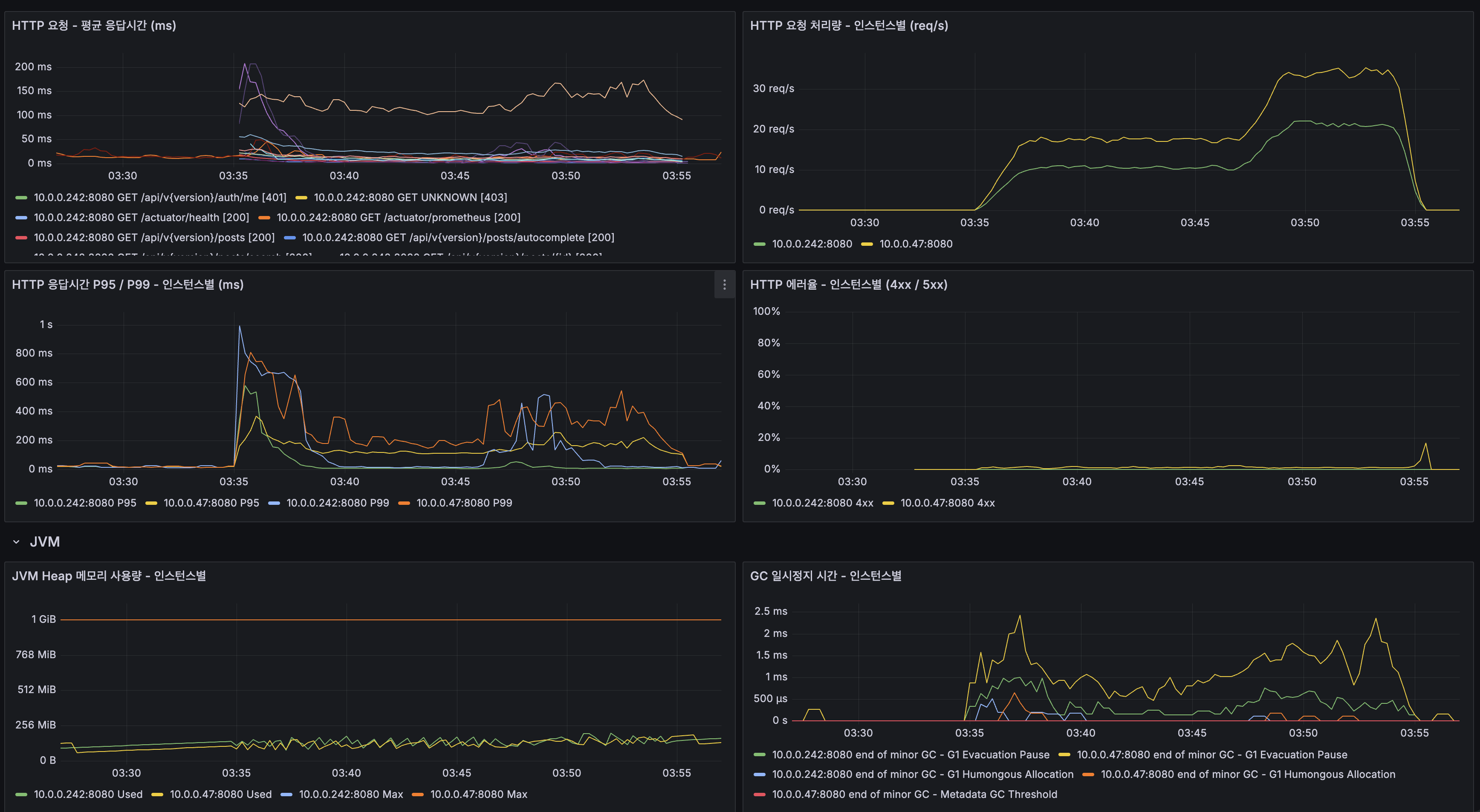
k6 100 VU 부하 테스트 실측 비교
조회수 Redis INCR 적용 전후로 동일 조건(100 VU, 20분, HTTPS 경유)의 k6 부하 테스트를 실행하여 측정했다.
| 지표 | Before (DB UPDATE) | After (Redis INCR) | 개선 |
|---|---|---|---|
| 전체 평균 응답시간 | 40.93ms | 37.23ms | 9%↓ |
| 전체 P95 | 174.53ms | 158.13ms | 9%↓ |
| 에러율 | 11.10% | 0.00% | 100%↓ |
| 총 요청 수 | 41,629 | 41,873 | 동등 |
| 상세 조회 평균 | 36.28ms | 23.06ms | 36%↓ |
| 상세 조회 P95 | 97.66ms | 85.84ms | 12%↓ |
| 검색 평균 | 28.94ms | 24.73ms | 15%↓ |
에러율 11.10% → 0.00%가 가장 핵심적인 개선이다. 이 에러의 대부분은 상세 조회에서 발생하던 500 에러(
read-only라우팅 충돌)였으며, Redis INCR 전환으로 GET에서 DB 쓰기가 완전히 제거되면서 해소되었다.응답시간도 전반적으로 개선되었다. 특히 상세 조회의 평균이 36.28ms → 23.06ms로 36% 개선된 것은, 매 요청마다 실행되던
UPDATE posts SET view_count = view_count + 1쿼리(MySQL InnoDB Row Lock 경합 포함)가 Redis INCR(~0.1ms)로 대체된 효과다.
k6 Before (조회수 DB UPDATE, 에러율 11.10%):
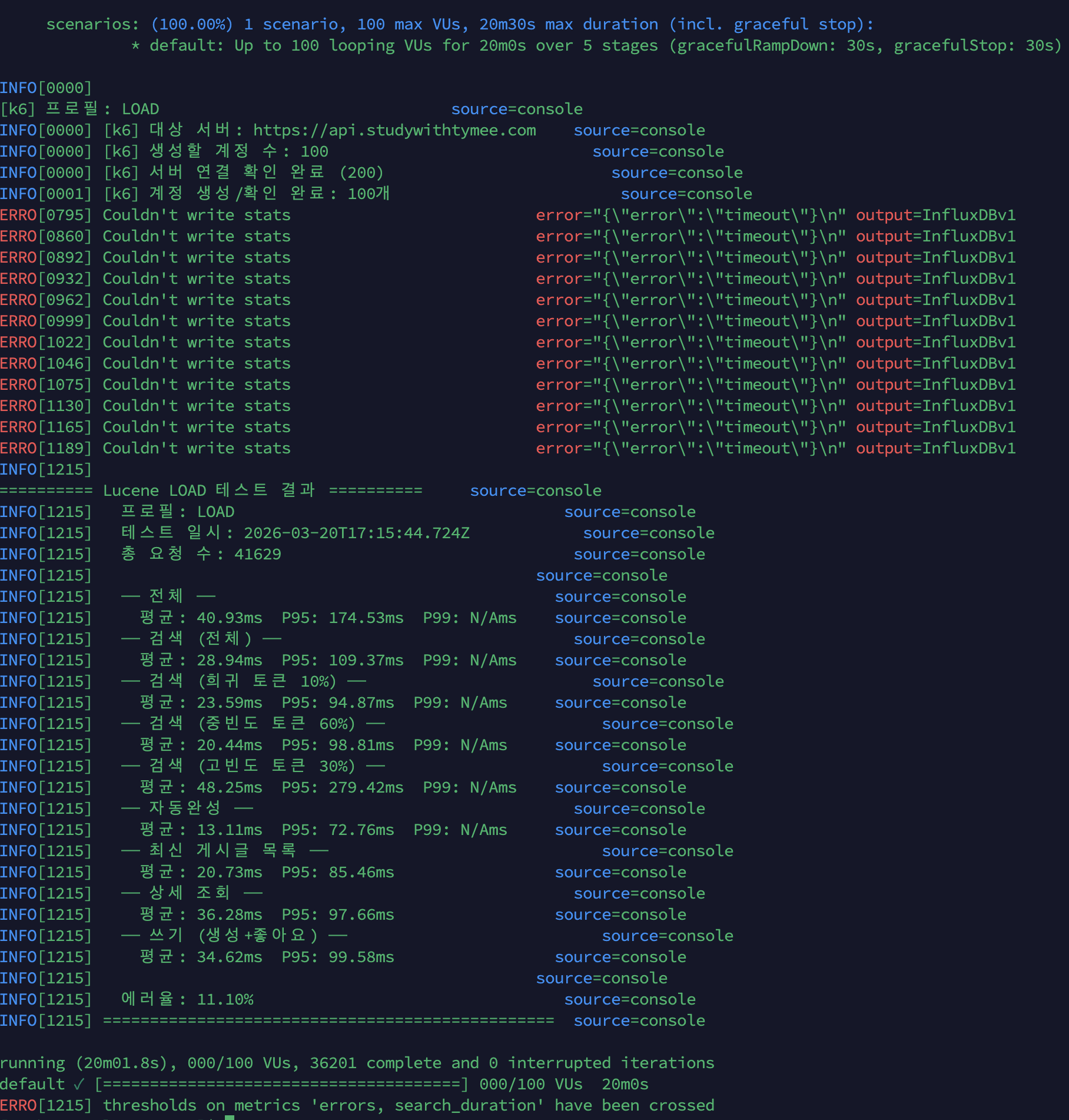
k6 After (조회수 Redis INCR, 에러율 0.00%):
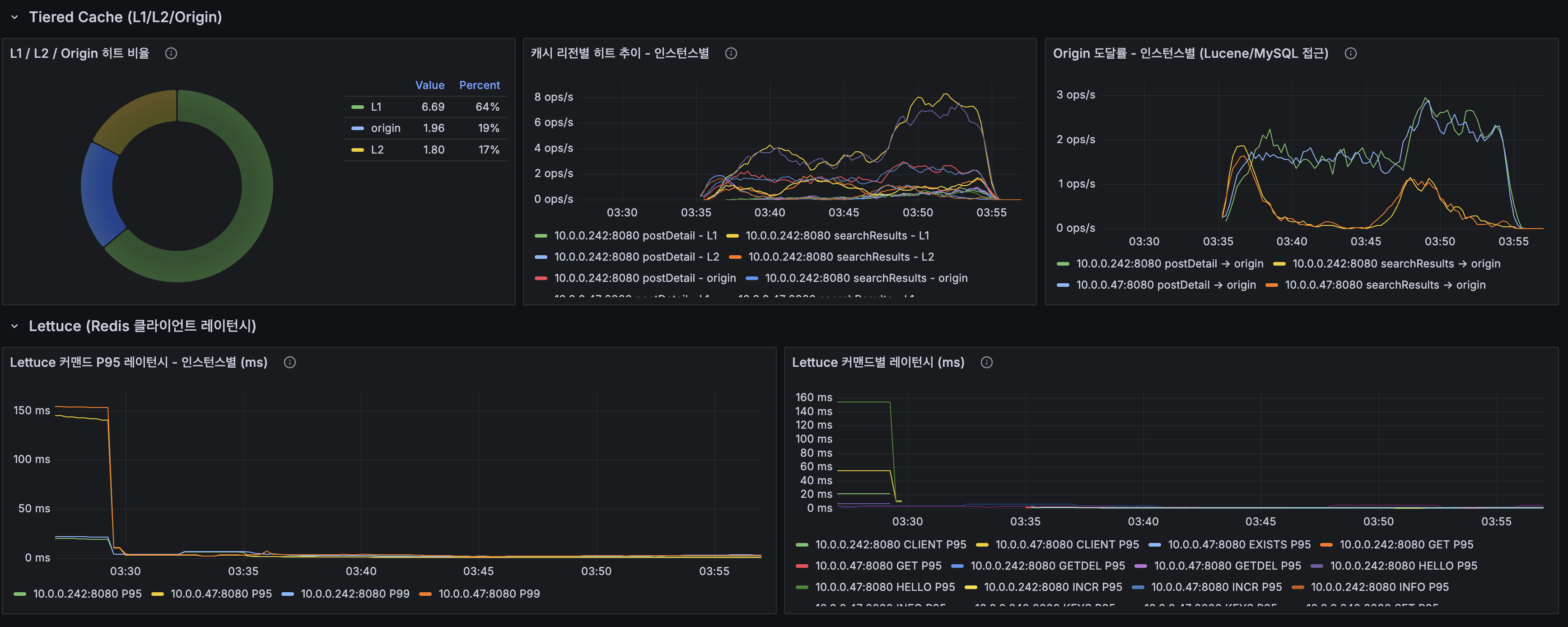
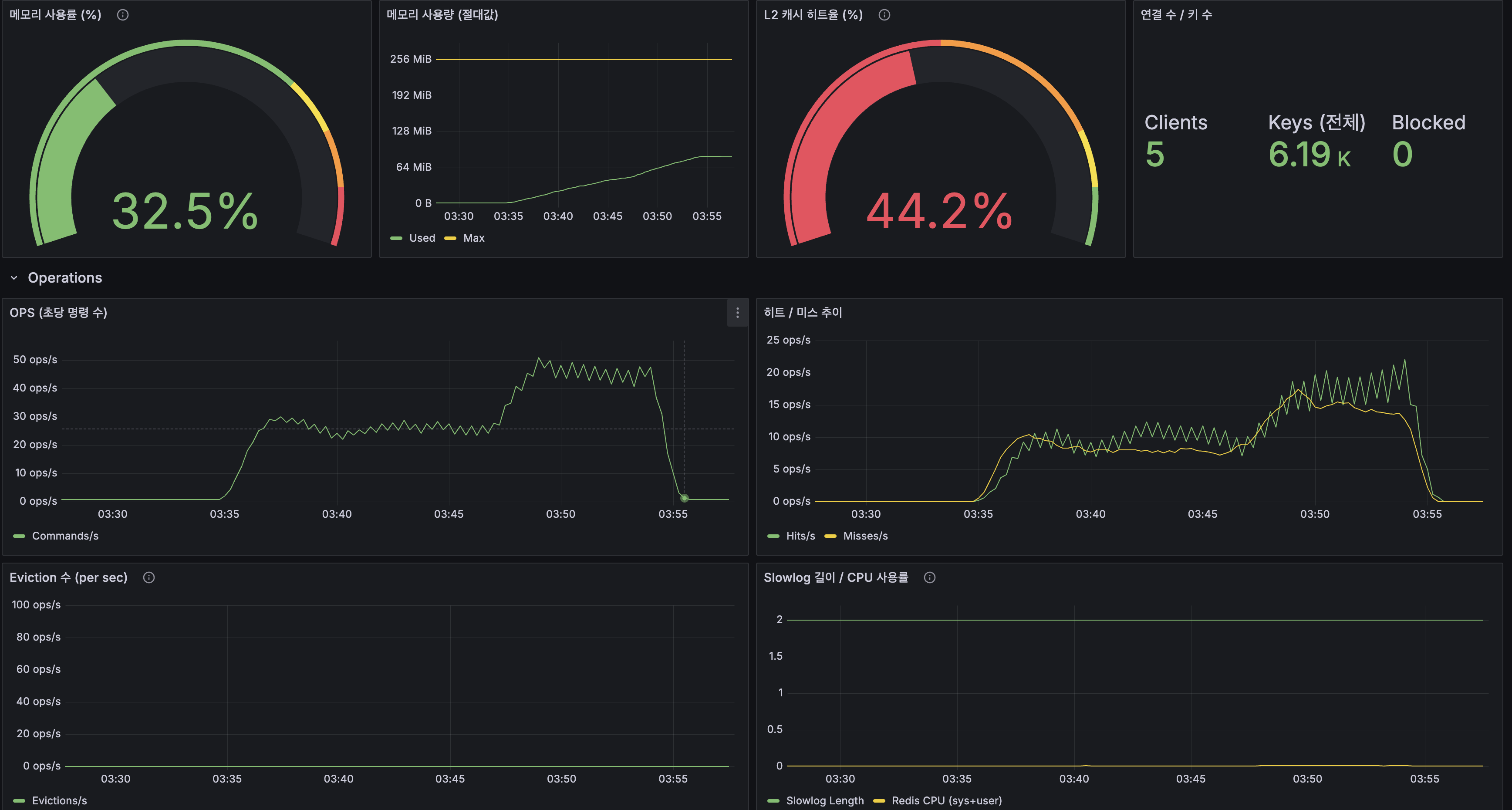
Grafana After 대시보드:
향후 개선: 검토 결과
| 항목 | 검토 결과 | 판단 |
|---|---|---|
| 조회수 중복 방지 | 커뮤니티 게시판에서 조회수는 “정확한 유니크 방문자 수”가 아닌 대략적인 인기도 지표다. 디시인사이드·에펨코리아·네이버 블로그도 새로고침 시 조회수가 올라간다. 유튜브처럼 조회수가 수익과 직결되는 서비스가 아니므로 구현의 ROI가 낮다. SET NX EX를 추가하면 매 조회마다 Redis 명령 2개(INCR + SET NX), 24시간 TTL 키 대량 누적(256MB 제한), VPN/시크릿 모드 우회 가능 | 불필요 |
| Lua Script 원자적 flush | 현재 getAndDelete()는 Redis GETDEL 명령으로 이미 원자적이다. keys() → getAndDelete() 사이에 새 INCR이 들어와도 유실이 없다 (GETDEL이 새 값을 포함하여 반환하거나, 키가 재생성되어 다음 flush에서 처리) | 불필요, 현재 코드가 이미 안전 |
| Redis Pipeline | ~1,000개 키 × private network 0.5ms RTT = ~500ms 절약이지만, 30초마다 실행되는 배치이므로 사용자 응답에 영향 없음 | 현재 불필요 |
KEYS → SCAN 전환 | KEYS는 O(N) 블로킹. 현재 ~6,190개 키에서는 ~0.1ms로 무시 가능. 수만 개로 늘면 SCAN 커서 기반으로 전환 필요 | 규모 확대 시 |
Previous Post
This post follows App Scale-Out, where Nginx L7 load balancing distributed traffic across 2 App instances. After scale-out, a critical issue emerged: the view count UPDATE inside GET requests conflicted with the R/W splitting DataSource routing.
Problem
The GET /api/v1.0/posts/{id} endpoint performed two operations: reading the post (routed to Replica via @Transactional(readOnly=true)) and incrementing the view count via UPDATE posts SET view_count = view_count + 1 (intended for Primary via @Transactional).
After App Scale-Out with 2 App instances, k6 100 VU load testing revealed all 38 detail-view checks failed (pass=0, fail=38) with HTTP 500:
Caused by: java.sql.SQLException: The MySQL server is running withthe --read-only option so it cannot execute this statementRoot cause: The AbstractRoutingDataSource-based R/W splitting intermittently routed the view count UPDATE to the Replica (which is read-only). This is a known pitfall when a write method is called inside a read-only GET request context.
Secondary issue: Even when routed correctly, 100 concurrent UPDATE statements on the same row caused InnoDB exclusive row locks (X Lock), serializing transactions and limiting throughput to ~500-1,000 ops/s (SSD + innodb_flush_log_at_trx_commit=1; could be as low as ~50 on HDD).
Alternatives Considered
| Approach | Verdict |
|---|---|
| REQUIRES_NEW propagation | Fixes routing but Row Lock contention and per-request DB UPDATE remain |
| Pessimistic/Optimistic locking | Concurrency safe but 100 concurrent requests = ~400ms; CAS retries explode under load |
| @Async UPDATE | Moves latency off response path but DB load identical; thread pool management complexity |
| Caffeine local counter + flush | No extra infra, but counter lost on App restart; no cross-instance dedup in multi-instance setup |
| Redis INCR + batch flush | Selected — eliminates DB writes from GET entirely |
Solution: Redis INCR + Write-Behind Batch Flush
// Before — DB UPDATE on every GET (R/W routing conflict + Row Lock)postService.incrementViewCount(id);
// After — Redis INCR (no DB touch, O(1), atomic)viewCountService.increment(id);ViewCountService.increment(): CallsredisTemplate.opsForValue().increment("post:views:" + postId). On Redis failure, catches exception and logs warning — post viewing continues normally.@Scheduled(fixedRate = 30_000) flushToDB(): Reads allpost:views:*keys, atomically gets and deletes each, then batch-updates MySQL viaincrementViewCountBy(id, delta).
This is the Write-Behind (Write-Back) Caching Pattern, recommended by AWS Caching Strategies for write-heavy workloads tolerating brief data lag. Used in production by Sentry (10s flush), YouTube (sampling + batch), Stack Overflow (Redis + local 2-tier).
Results: k6 100 VU Load Test
| Metric | Before (DB UPDATE) | After (Redis INCR) | Improvement |
|---|---|---|---|
| Error rate | 11.10% | 0.00% | Eliminated |
| Avg response | 40.93ms | 37.23ms | 9% |
| P95 | 174.53ms | 158.13ms | 9% |
| Detail avg | 36.28ms | 23.06ms | 36% |
| Detail P95 | 97.66ms | 85.84ms | 12% |
| Search avg | 28.94ms | 24.73ms | 15% |
The most critical improvement is the error rate dropping from 11.10% to 0.00%. The 36% latency reduction in detail views reflects replacing the per-request MySQL UPDATE (with InnoDB Row Lock contention) with Redis INCR (~0.1ms).
k6 Before (DB UPDATE, error rate 11.10%):
k6 After (Redis INCR, error rate 0.00%):
Grafana After Dashboard:

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.