CDC (Change Data Capture): 이벤트 기반 동기화
목차
이전 글
조회수 Redis INCR + Write-Behind 배치 flush 전환에서 GET 요청의 DB UPDATE 충돌을 Redis INCR로 해결했습니다. 이 글은 PostService의 dual-write 구조를 이벤트 기반으로 전환하고, 최종적으로 Debezium + Kafka CDC로 모든 DB 변경을 캡처하는 과정입니다.
이전 글 요약
App 스케일아웃에서 CPU 병목이 해소되었다.
| 지표 | 스케일아웃 결과 |
|---|---|
| 평균 응답시간 | 37ms (482ms → 37ms, 92%↓) |
| P95 | 158ms |
| 에러율 | 0.00% |
| 처리량 (피크) | ~58 req/s (1.9배↑) |
| App CPU (피크) | ~50% (각 2대) |
| 캐시 히트 | L1 64% + L2 17% = 81%, Origin 19% |
인프라는 안정적이다. 하지만 애플리케이션 아키텍처에 구조적 문제가 남아 있다.
1. 정상 상태 인식
현재 아키텍처: PostService의 dual-write 구조
PostService가 MySQL에 쓰기를 하면서 동시에 여러 Read Model을 직접 갱신하고 있다:
// PostService.createPost() — 현재 구조@Transactionalpublic Post createPost(String title, String content, Long authorId, Long categoryId) { Post saved = postRepository.save(post); // 1. MySQL 쓰기 indexSafely(saved); // 2. Lucene 인덱스 직접 호출 return saved;}
// PostService.updatePost()@Transactionalpublic void updatePost(Long id, String title, String content, Long userId) { post.update(title, content); indexSafely(post); // 2. Lucene tieredCacheService.evict(postDetailL1Cache, "post:" + id); // 3. 캐시 무효화}
// PostService.deletePost()@Transactionalpublic void deletePost(Long id, Long userId) { postRepository.delete(post); deleteFromIndexSafely(id); // 2. Lucene tieredCacheService.evict(postDetailL1Cache, "post:" + id); // 3. 캐시 무효화}현재 Read Model 동기화 현황
| Read Model | 동기화 방식 | 호출 위치 | 타이밍 |
|---|---|---|---|
| Lucene 인덱스 | indexSafely() 직접 호출 | PostService 내부, 트랜잭션 안 | 동기, 즉시 |
| 게시글 상세 캐시 | tieredCacheService.evict() | PostService 내부, 트랜잭션 안 | 동기, 즉시 |
| 검색 결과 캐시 | 무효화 없음 | - | 영구 stale |
| 자동완성 Redis KV | hourly @Scheduled 배치 | RedisAutocompleteService | 최대 60분 지연 |
| 조회수 | ViewCountService.increment() + 30초 flush | PostController | 비동기, 30초 |
| 좋아요 수 | incrementLikeCount() 직접 DB UPDATE | PostService | 동기, Lucene/캐시 미갱신 |
의존 관계 그래프

2. 문제 상황 인식
문제 1: Dual-Write 불일치: DB 성공 + Lucene 실패 = 영구 불일치
private void indexSafely(Post post) { try { luceneIndexService.indexPost(post); } catch (Exception e) { log.error("Lucene 인덱스 실패: {}", post.getId(), e); // DB에는 이미 커밋됨 — Lucene에는 없음 // 재시도 없음, DLQ 없음, 알림 없음 // → 영구 불일치 }}현재는 try-catch + log.error()로 처리한다. MySQL 트랜잭션이 커밋되면 데이터는 DB에 있지만, Lucene 인덱스에는 없다. 이 불일치를 감지하거나 복구하는 메커니즘이 없다.
실측: 부하 테스트 튜닝(200 VU)에서 Lucene indexing이 IOException으로 실패한 케이스가 관찰되었다. CPU 포화 상태에서 MMapDirectory I/O 타임아웃 발생.
문제 2: PostService 강결합: 6개 의존성
PostService가 알아야 하는 것:

새로운 Read Model(예: Elasticsearch, 추천 시스템, 알림)을 추가할 때마다 PostService를 수정해야 한다. OCP(Open-Closed Principle) 위반.
문제 3: 불완전한 캐시 무효화
| 연산 | 게시글 캐시 (post:{id}) | 검색 캐시 (search:*) | 자동완성 KV |
|---|---|---|---|
| 게시글 생성 | 해당 없음 | 무효화 안 됨 | 최대 60분 지연 |
| 게시글 수정 | O 무효화 | 무효화 안 됨 | 무효화 안 됨 |
| 게시글 삭제 | O 무효화 | 무효화 안 됨 | 최대 2시간 stale |
| 좋아요 | 무효화 안 됨 | 무효화 안 됨 | 해당 없음 |
게시글을 삭제해도 검색 결과에 최대 30분간 계속 노출된다(검색 결과 캐시 TTL 만료까지). 삭제된 게시글 링크를 클릭하면 404가 떠서 사용자 경험이 나빠진다.
문제 4: Lucene 랭킹 필드 stale
Lucene 인덱스에 FeatureField("features", "viewCount")와 FeatureField("features", "likeCount")가 저장되어 BM25 + 부스팅 랭킹에 사용된다. 하지만:
- 조회수: Redis INCR → 30초 배치 DB flush → Lucene에는 반영 안 됨
- 좋아요: DB UPDATE → Lucene에는 반영 안 됨
검색 결과 랭킹이 stale 데이터 기반. 인기 게시글이 검색 상위에 올라오지 않을 수 있다.
3. 문제 분석: 왜 dual-write가 구조적으로 위험한가
Dual-Write의 본질적 문제
두 개 이상의 데이터 저장소에 애플리케이션이 직접 쓰기를 하면, 분산 트랜잭션 없이는 원자성을 보장할 수 없다. Martin Kleppmann(“Designing Data-Intensive Applications” 저자)은 이를 “dual-write problem”으로 명명하고, race condition과 partial failure 두 가지 근본 문제를 제시한다.
“Two clients may write to System A and System B in different orders. Without a single source of ordering, the systems end up permanently inconsistent with no indication that anything is wrong.”
해결책으로 “Write to a single authoritative system (the database), then use CDC (log extraction) to propagate changes”를 권장한다. Confluent도 “Issues caused by this problem are extremely difficult to spot, and you don’t get any red flags indicating that something has become inconsistent”라고 경고한다.

이 문제를 해결하는 업계 표준 패턴:
| 패턴 | 원리 | 적합 상황 |
|---|---|---|
| Transactional Outbox | DB 트랜잭션에 이벤트 테이블 INSERT 포함 → 별도 폴링으로 발행 | 단일 DB, 추가 인프라 최소 |
| CDC (Change Data Capture) | DB binlog를 외부에서 감지 → 이벤트 스트림 생성 | 애플리케이션 코드 변경 없이 모든 변경 캡처 |
| Event Sourcing | 이벤트 자체가 원본 데이터 | 이벤트 중심 도메인 |
이 프로젝트에 적합한 접근: 점진적 진화
로드맵에서 설계한 3-step 진화:

단, Kafka + Debezium은 최소 5~8G RAM이 필요하여 현재 Free Tier에서는 불가. Spring Event부터 시작하여 구조적 개선을 먼저 달성한다.
4. 대안 검토
방안 1: Spring ApplicationEvent + @TransactionalEventListener
// PostService — 직접 호출 제거, 이벤트 발행으로 전환@Transactionalpublic Post createPost(...) { Post saved = postRepository.save(post); // indexSafely(saved); ← 제거 eventPublisher.publishEvent(new PostEvent.Created(saved.getId(), saved)); return saved;}// 별도 EventHandler — Lucene 인덱스 갱신@Componentpublic class LuceneIndexEventHandler { @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT) public void onPostCreated(PostEvent.Created event) { luceneIndexService.indexPost(event.post()); }}
// 별도 EventHandler — 캐시 무효화// [주의] AFTER_COMMIT 리스너에서 DB 작업이 필요하면 반드시 REQUIRES_NEW 사용@Componentpublic class CacheInvalidationEventHandler { @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT) public void onPostUpdated(PostEvent.Updated event) { tieredCacheService.evict(postDetailL1Cache, "post:" + event.postId()); }}| 장점 | 단점 |
|---|---|
| 추가 인프라 없음 | 앱 재시작/크래시 시 이벤트 유실 (in-memory) |
| PostService 디커플링 (OCP 준수) | AFTER_COMMIT 후 리스너 실패 시 재시도 없음 |
| 트랜잭션 커밋 보장 후 실행 | 커밋~리스너 실행 사이에 짧은 불일치 window |
| 코드 변경만으로 적용 | 멀티 인스턴스에서 이벤트 공유 불가 |
멀티 인스턴스 제약: 스케일아웃에서 이미 App을 2대로 확장했다. Spring
ApplicationEvent는 JVM 내부 이벤트이므로, App 1에서 게시글을 생성하면 App 1의 Lucene만 갱신되고 App 2의 Lucene은 갱신되지 않는다. 이 부분은 기존 5분 주기 rsync가 커버한다.
Spring Modulith 활용: 이 프로젝트는 Spring Modulith 2.0.2를 사용 중이다.
@ApplicationModuleListener는@TransactionalEventListener(AFTER_COMMIT)+ 이벤트 발행 로그(Event Publication Log)를 제공하여, 리스너 실패 시 자동 재시도가 가능하다.
AFTER_COMMIT리스너의 알려진 함정: 리스너에서 예외가 발생해도 트랜잭션은 이미 커밋되었으므로 롤백되지 않는다. Spring 6.x에서@TransactionalEventListener의 기본 동작이 동기(같은 스레드)이므로, 리스너가 느리면 HTTP 응답도 지연된다.
방안 2: Transactional Outbox Pattern
// PostService — 이벤트를 outbox 테이블에 함께 저장@Transactionalpublic Post createPost(...) { Post saved = postRepository.save(post); outboxRepository.save(new OutboxEvent("POST_CREATED", saved.getId(), toJson(saved))); return saved;}
// OutboxPoller — 별도 스케줄러가 outbox 테이블 폴링 → 이벤트 발행// SKIP LOCKED: 멀티 인스턴스에서 같은 이벤트 중복 처리 방지@Scheduled(fixedRate = 1000)@Transactionalpublic void pollAndPublish() { List<OutboxEvent> events = outboxRepository.findUnpublishedForUpdate(BATCH_SIZE); for (OutboxEvent event : events) { try { applicationEventPublisher.publishEvent(toDomainEvent(event)); event.markPublished(); } catch (Exception e) { event.incrementRetryCount(); log.error("Outbox event 처리 실패 (retry {}): {}", event.getRetryCount(), event.getId(), e); } }}| 장점 | 단점 |
|---|---|
| 이벤트 유실 없음 (DB 트랜잭션과 원자적) | outbox 테이블 관리 필요 (정리, 인덱스) |
| 앱 재시작 후에도 미발행 이벤트 처리 | 폴링 주기만큼 지연 (1초) |
| 멀티 인스턴스에서 안전 (DB 기반) | 폴링이 DB 부하 추가 |
| 순서 보장 가능 (ID 기반) |
방안 3: Debezium + Kafka CDC

| 장점 | 단점 |
|---|---|
| 애플리케이션 코드 변경 없이 모든 변경 캡처 | Kafka + Debezium = 최소 5~8G RAM |
| at-least-once 보장 (Kafka offset) | Free Tier에서 자원 부족 |
| 이벤트 리플레이 가능 | 운영 복잡도 증가 |
| dual-write 원천 차단 (binlog 기반) |
Debezium 프로덕션 알려진 한계: Connector가 단일 태스크(단일 스레드)로 binlog를 순차 처리하므로, 대량 DML 시 lag이 누적될 수 있다. 극단적인 경우 15~20분까지 보고됨. 내장 관찰성(Observability)이 없어 별도 Prometheus + Grafana 필요. DDL 발생 시 Connector 재시작이 필요한 경우가 있다.
선택: Spring Event → Outbox → CDC 순서

현업 사례
| 회사 | 패턴 | 참고 |
|---|---|---|
| 배달의민족 | Debezium + Kafka CDC | B2B 알림 서비스에 CDC 적용. “볼륨이 아닌 아키텍처 패턴으로 도입” |
| Netflix | Debezium + Kafka | 마이크로서비스 간 데이터 동기화 |
| Airbnb | Transactional Outbox + Kafka | 이벤트 유실 방지를 위한 2-step 패턴 |
| Debezium 공식 | Outbox + CDC 조합 | ”log-based CDC is a great fit for capturing new entries in the outbox table” |
Outbox + CDC 조합: 업계 best practice는 Outbox 테이블에 이벤트를 저장한 뒤, 폴링 대신 CDC(Debezium)로 outbox 테이블의 변경을 감지하여 Kafka에 전달하는 것이다. 이 프로젝트에서는 폴링 Outbox → CDC Outbox로 자연스럽게 진화할 수 있다.
비용 분석

운영 복잡도 정당화: “일 200건에 Kafka가 필요한가?”
이 질문에 대한 답은 “Kafka를 운영하는 비용”과 “dual-write 불일치를 수동으로 복구하는 비용”의 비교다.
| 항목 | Kafka 없이 (@ApplicationModuleListener) | Kafka 있으면 (CDC) |
|---|---|---|
| 직접 SQL/배치 JPQL 후 Lucene 불일치 복구 | 수동: 전체 재인덱싱 28분 + 불일치 감지 수단 없음 | 자동: binlog에서 캡처, 0.7초 내 반영 |
| Lucene 인덱스 손상 시 복구 | 전체 재인덱싱 28분, 그 동안 검색 품질 저하 | Kafka 토픽 리플레이로 증분 재구축 |
| 앱 장애 중 이벤트 | JVM 내부 이벤트 중단, Event Publication Log에 의존 | Kafka에 보존, 앱 복구 후 이어서 소비 |
| 멀티 인스턴스 L1 캐시 무효화 | App 1 이벤트를 App 2가 모름 (TTL 만료까지 stale) | 양쪽 모두 CDC 이벤트로 즉시 무효화 |
| 주간 운영 시간 | ~0 (하지만 불일치 발생 시 수 시간 디버깅) | ~1시간 (정기 점검) |
Kafka 운영의 핵심 비용은 인프라 자체보다 운영 진입 비용과 장애 대응 복잡도에 가깝습니다. 이 프로젝트에서는 KRaft 단일 브로커 + @ConditionalOnProperty fallback 구조로 운영 부담을 최소화했습니다. Kafka가 죽어도 서비스는 @ApplicationModuleListener 수준으로 자동 전환되어 서비스 중단 없이 동작합니다. Kafka는 “평시의 정확성 보장”이고, fallback은 “장애 시 서비스 연속성 보장”입니다.
”Elasticsearch를 쓰면 CDC 자체가 불필요하지 않나?”
| 관점 | Embedded Lucene + CDC | Elasticsearch |
|---|---|---|
| 인프라 비용 | Kafka 4G + Debezium 2G = 6G RAM | ES 최소 4G × 3노드 = 12G RAM (HA 구성) |
| dual-write 해결 | CDC(binlog)로 원천 차단 | ES도 결국 MySQL → ES 동기화 필요 (같은 문제 발생) |
| 운영 복잡도 | Kafka + Debezium | ES 클러스터 관리 (샤드, 레플리카, JVM 튜닝) |
| 검색 성능 | 7~10배 빠름 (Lucene 직접 접근) | 네트워크 홉 추가 |
| 비용 (AWS) | t3.medium $30/월 | OpenSearch Serverless 최소 ~$200/월 |
Elasticsearch를 도입해도 MySQL → ES 동기화 문제는 동일하다. ES 공식 문서에서도 Logstash JDBC Input이나 Debezium을 사용한 CDC를 권장한다. 즉 ES를 써도 CDC 파이프라인은 필요하고, 인프라 비용은 오히려 더 높다. Embedded Lucene + CDC는 같은 정확성을 훨씬 적은 비용으로 달성하는 선택이다.
5. Spring Event 전환 구현
도메인 이벤트 설계
// sealed interface로 타입 안전성 보장public sealed interface PostEvent { Long postId();
record Created(Long postId, Post post) implements PostEvent {} record Updated(Long postId, Post post) implements PostEvent {} record Deleted(Long postId) implements PostEvent {} record LikeChanged(Long postId) implements PostEvent {}}EventHandler 분리

Consumer 멱등성 (Idempotency)
| EventHandler | 멱등성 보장 방식 | 이유 |
|---|---|---|
| LuceneIndexEventHandler | 자연 멱등 | Lucene updateDocument()는 Term 기준 삭제 후 재삽입. 같은 postId로 여러 번 호출해도 결과 동일 |
| CacheInvalidationEventHandler | 자연 멱등 | evict(key)는 캐시에 키가 없으면 no-op |
| SearchCacheEventHandler | 자연 멱등 | 검색 캐시 전체/부분 무효화도 no-op 안전 |
| 좋아요 카운터 | 주의 필요 | incrementLikeCount()는 멱등적이지 않다. 이벤트에 변경 후 절대값을 포함하여 SET 방식으로 갱신 필요 |
설계 원칙: 이벤트 핸들러는 가능하면 SET(절대값 덮어쓰기) 방식으로 구현하고, INCREMENT(상대값 증가) 방식은 피한다.
Trade-off: 동기 → 비동기 전환의 일시적 불일치 window

이 window는 수 ms 수준이며, 커뮤니티 게시판에서 허용 가능하다.
코드 변경 Before/After
| Before | After |
|---|---|
indexSafely(post) + tieredCacheService.evict(...) | eventPublisher.publishEvent(new PostEvent.Updated(id, post)) |
deleteFromIndexSafely(id) + tieredCacheService.evict(...) | eventPublisher.publishEvent(new PostEvent.Deleted(id)) |
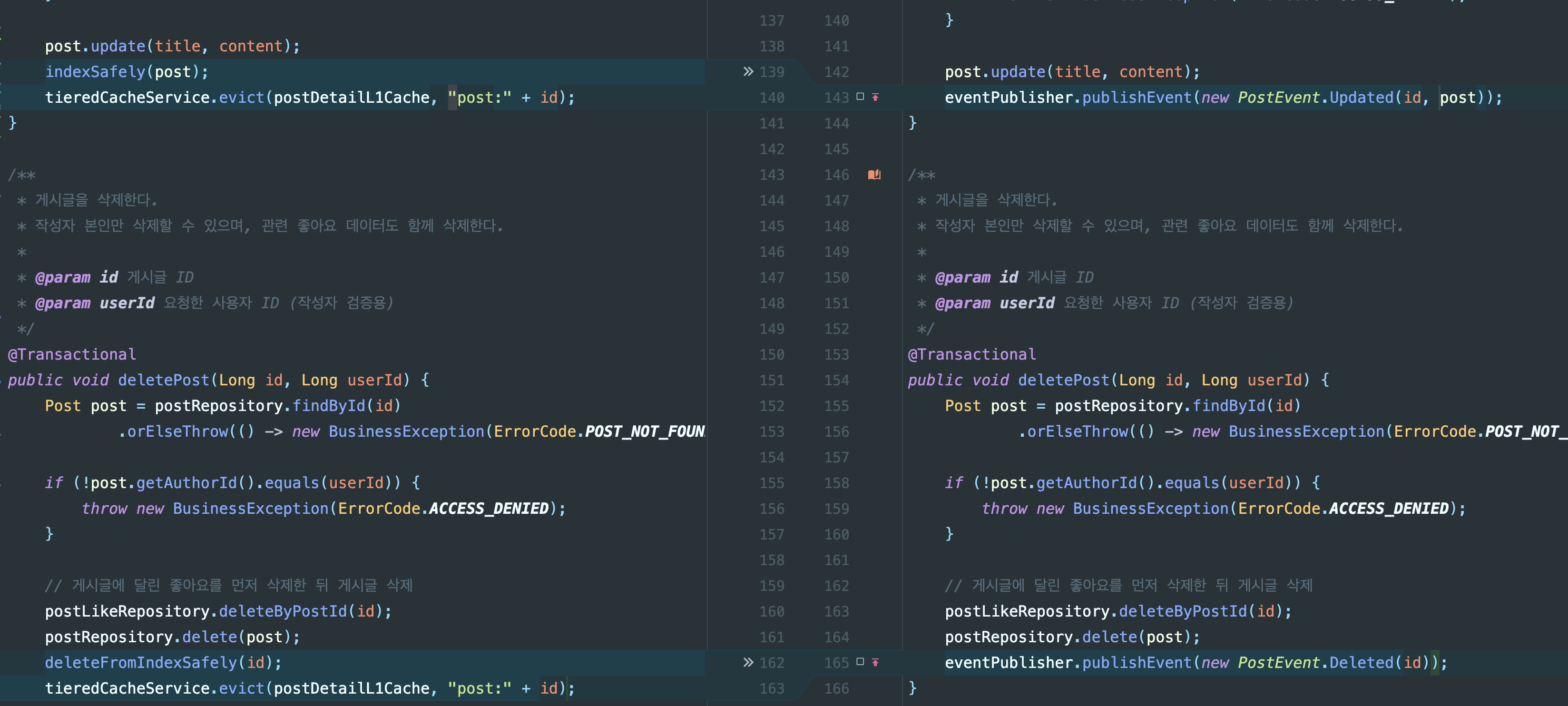
PostService 의존성 변화
| Before | After | |
|---|---|---|
| 생성자 파라미터 | 9개 | 9개 (LuceneIndexService → ApplicationEventPublisher 교체) |
| 쓰기 경로 외부 호출 | Lucene 직접 + 캐시 직접 | 이벤트 발행만 |
| Read Model 추가 시 | PostService 수정 필요 | EventHandler 추가만 (OCP 준수) |
캐시 무효화 개선
| 캐시 | Before | After |
|---|---|---|
게시글 상세 (post:{id}) | 수정/삭제 시만, 좋아요 시 안 됨 | 수정/삭제/좋아요 모두 이벤트로 무효화 |
검색 결과 (search:*) | 무효화 없음 → 영구 stale | L1 즉시 무효화 + L2 TTL(10분) 자연 만료 |
테스트
기존 109개에서 Lucene 직접 호출 테스트 3개 제거 + EventHandler 테스트 11개 추가 = 117개 전체 통과.
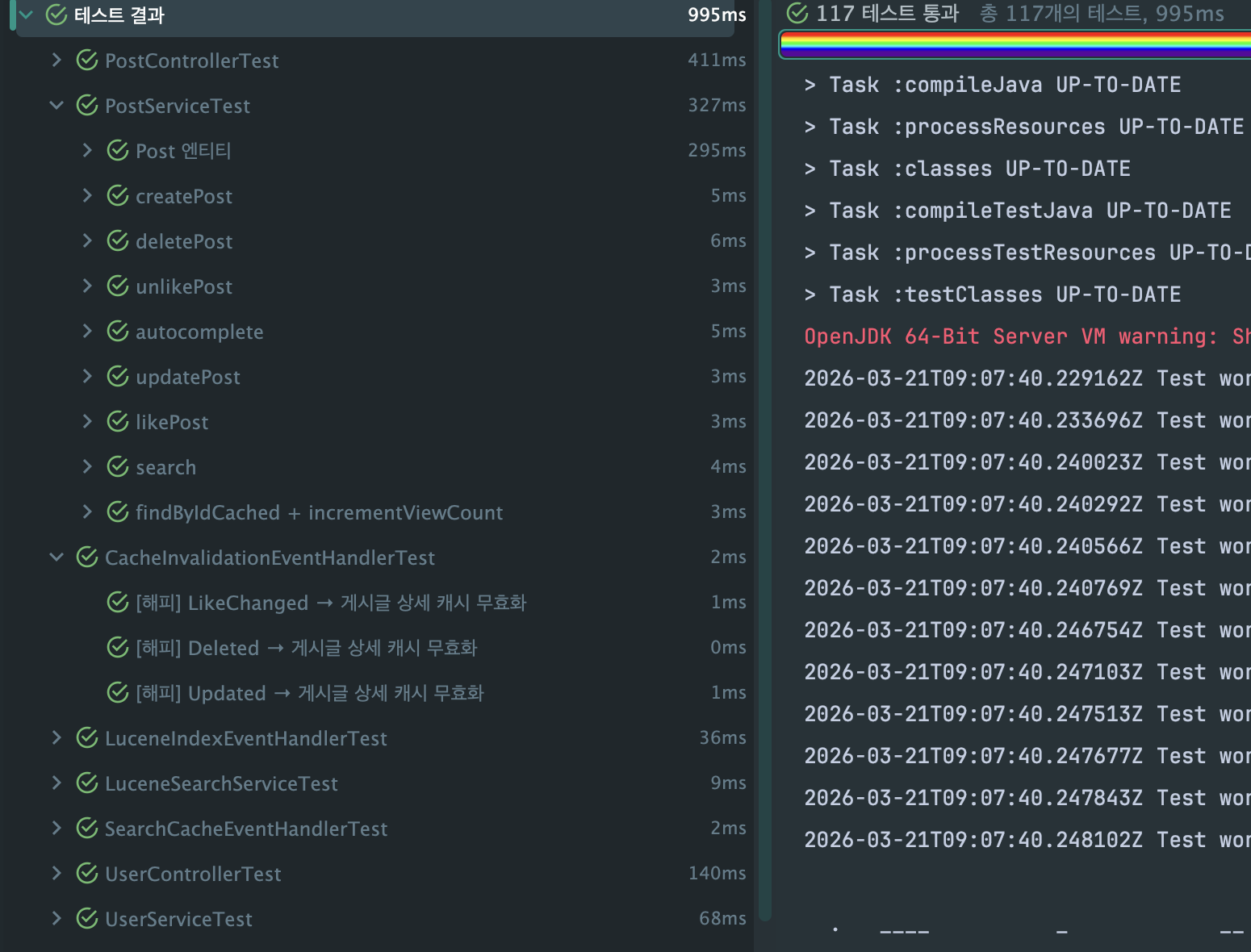
새로 추가된 파일
| 파일 | 역할 |
|---|---|
PostEvent.java | sealed interface: Created, Updated, Deleted, LikeChanged |
LuceneIndexEventHandler.java | @ApplicationModuleListener: 비동기 Lucene 인덱스 갱신 |
CacheInvalidationEventHandler.java | @ApplicationModuleListener: 게시글 상세 캐시(L1+L2) 무효화 |
SearchCacheEventHandler.java | @ApplicationModuleListener: 검색 결과 캐시 L1 무효화 |
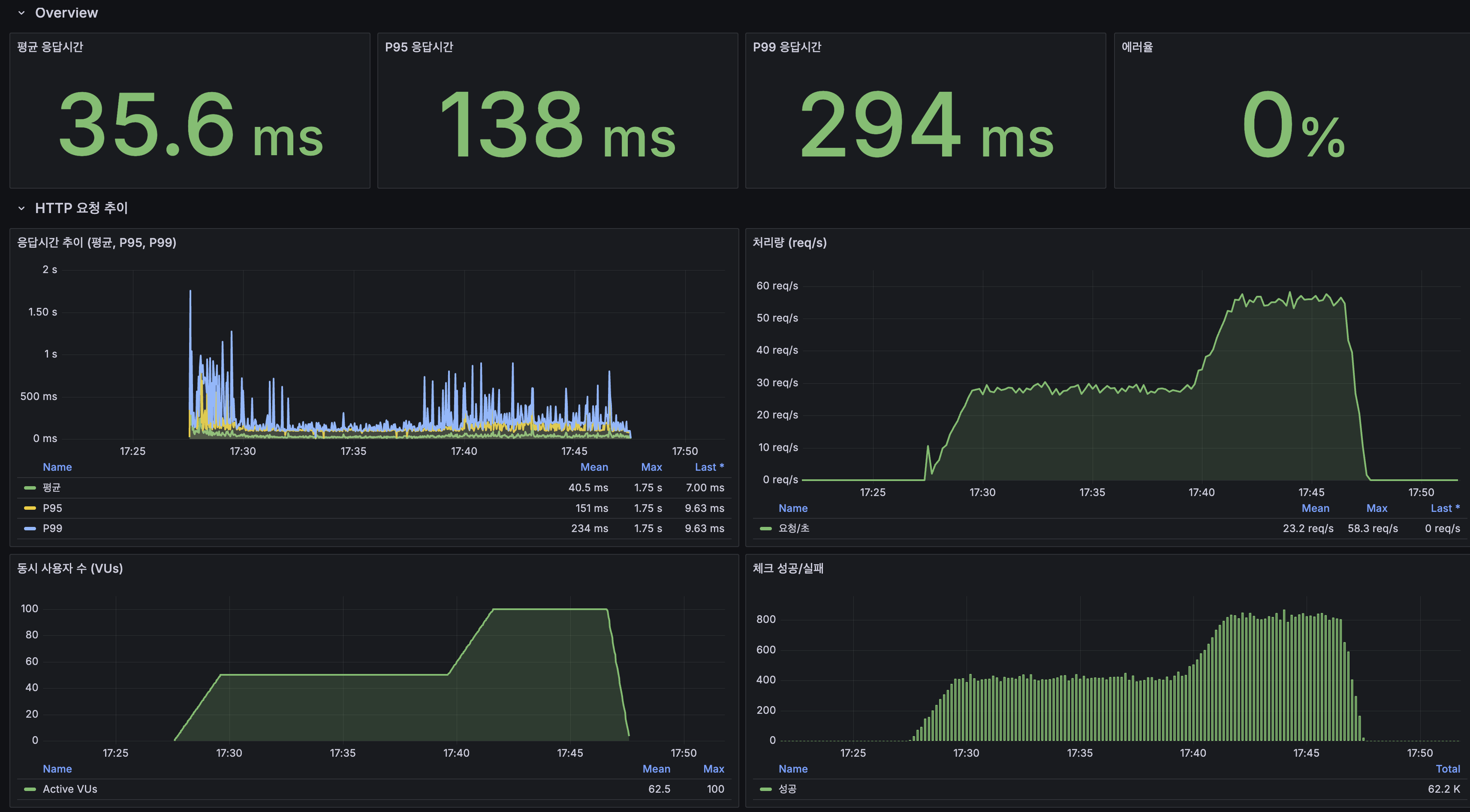
6. k6 부하 테스트: @TransactionalEventListener (100 VU, 20분)
Overview
| 지표 | 스케일아웃 | @TransactionalEventListener | 변화 |
|---|---|---|---|
| 평균 응답시간 | 37ms | 724ms | 악화 (쓰기 경로) |
| P95 | 158ms | 5.01s | 악화 (쓰기 경로) |
| 에러율 | 0.00% | 12.6% | 악화 |
| 처리량 (피크) | ~58 req/s | ~41 req/s | 감소 |
읽기 vs 쓰기 분리 분석
읽기 경로는 스케일아웃 대비 동등하거나 개선:
| 시나리오 | 평균 | P95 | 판정 |
|---|---|---|---|
| 검색 | 28ms | 109ms | 정상 |
| 자동완성 | 8ms | 38ms | 정상 |
| 목록 조회 | 14ms | 67ms | 정상 |
| 상세 조회 | 19ms | 81ms | 정상 |
| 쓰기 (생성+좋아요) | 5,315ms | 13,909ms | 병목 |
에러율 12.6%의 원인은 쓰기 타임아웃. 읽기 경로는 이벤트 전환의 영향 없음.
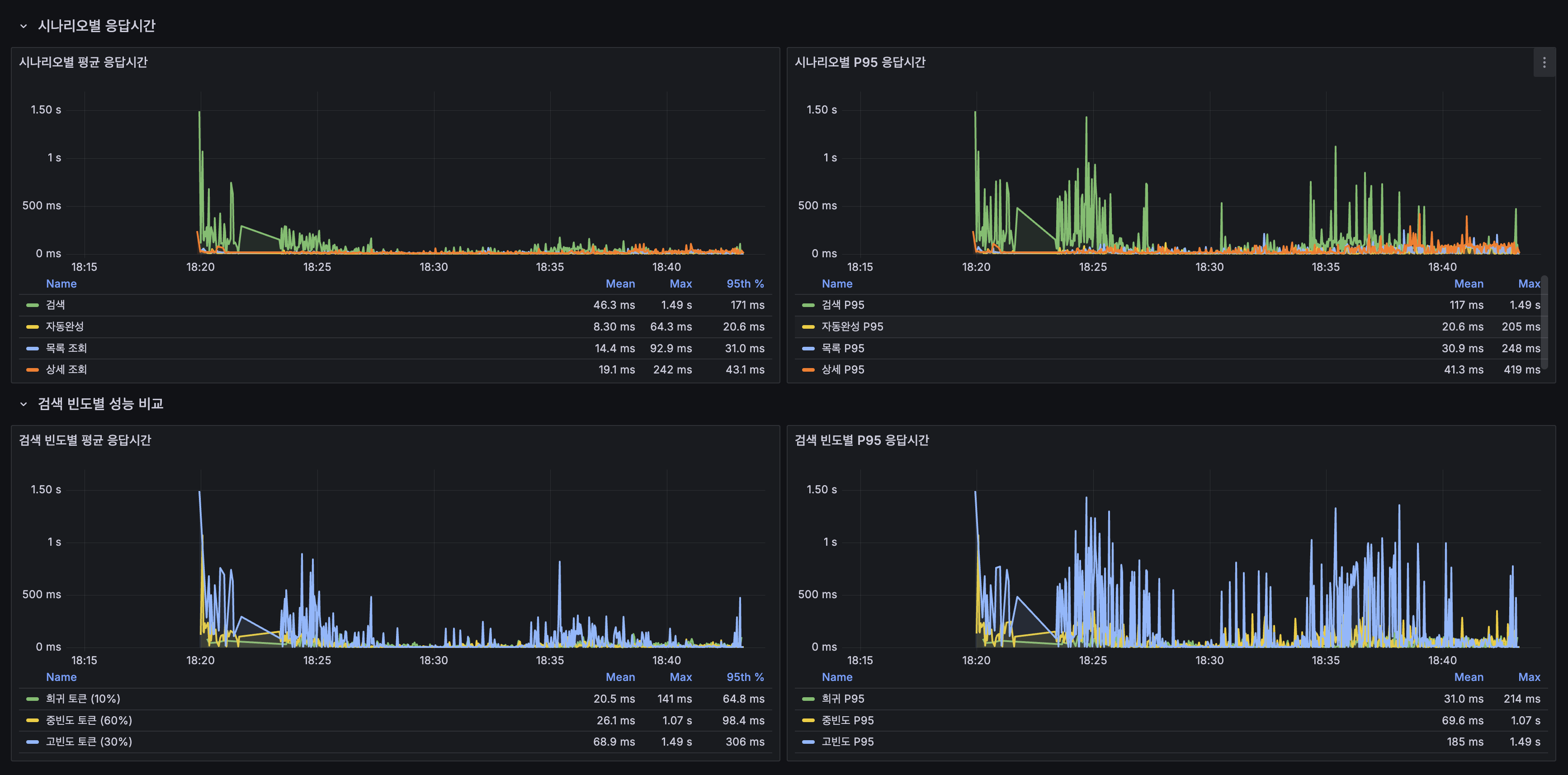
쓰기 병목 분석: HikariCP Primary Pool 고갈
Spring의 AbstractPlatformTransactionManager.processCommit() 소스코드 기준으로, afterCommit() 콜백은 커넥션이 풀에 반환되기 전에 실행된다:
processCommit() { doCommit() // 1. DB 커밋 triggerAfterCommit() // 2. AFTER_COMMIT 리스너 실행 ← 커넥션 아직 점유! cleanupAfterCompletion() // 3. 커넥션 반환 ← 여기서야 반환}Lucene 인덱싱(~100ms)과 캐시 무효화가 끝날 때까지 DB 커넥션이 반환되지 않아, Primary pool(5개)이 고갈되고 후속 쓰기 요청이 4~5초간 커넥션 대기.
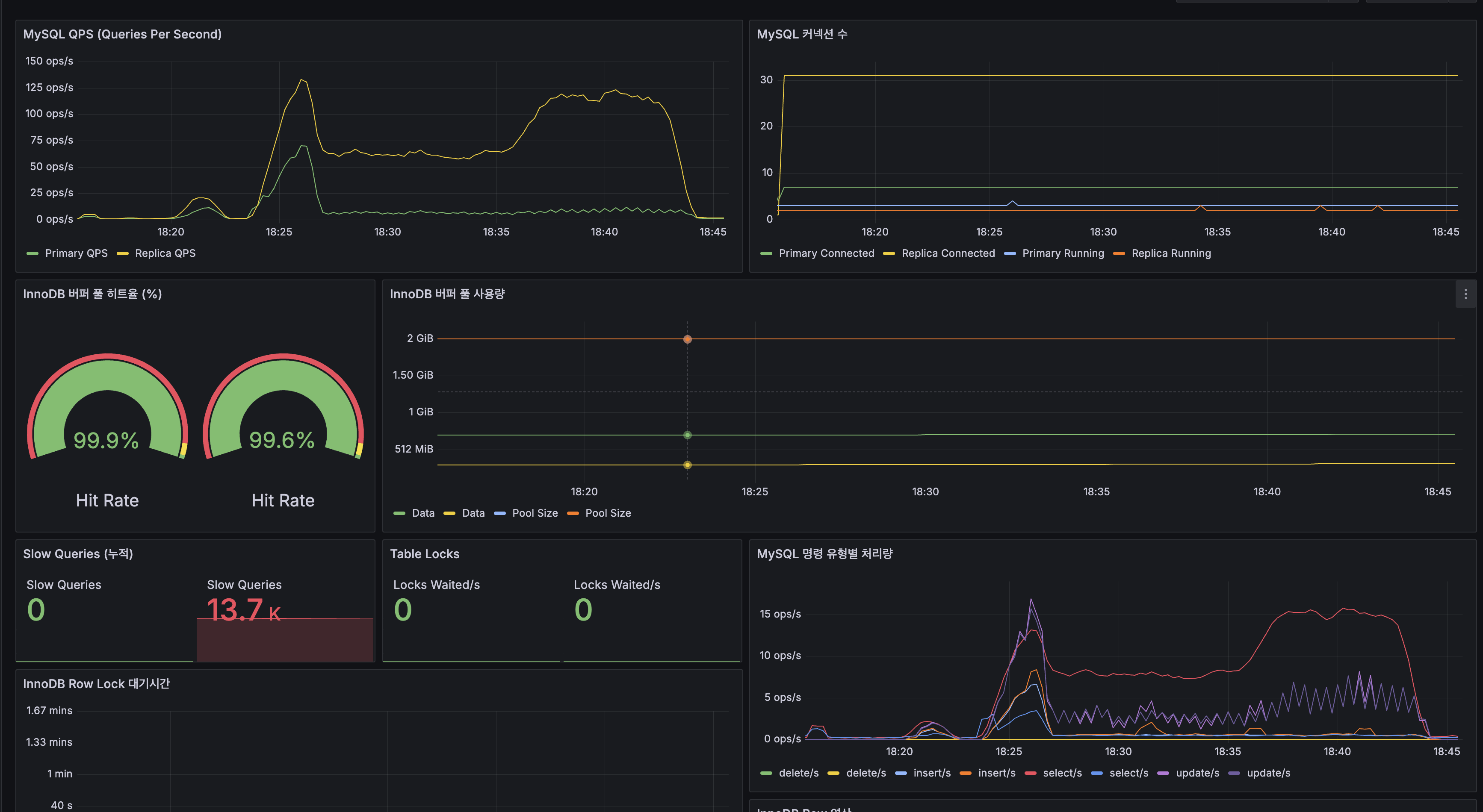
Grafana 대시보드
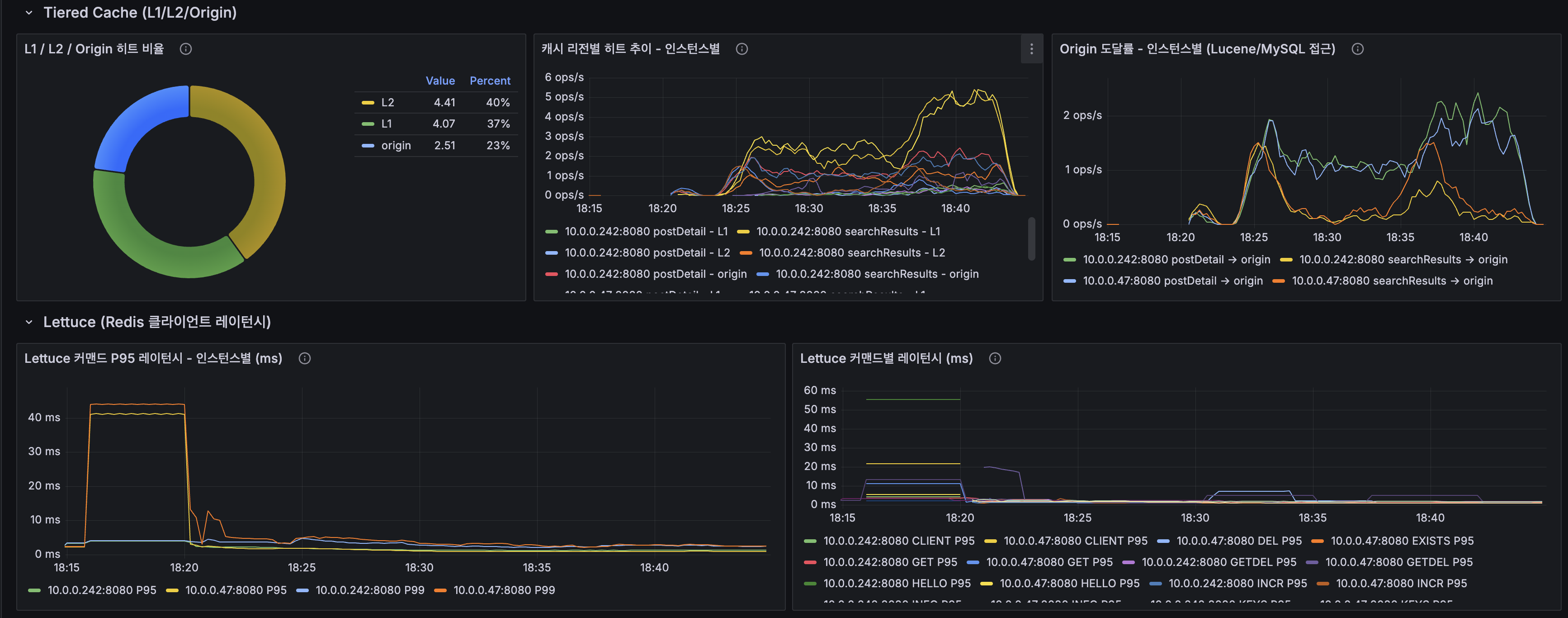
| 계층 | 히트 비율 |
|---|---|
| L1 (Caffeine) | 37% |
| L2 (Redis) | 40% |
| Origin (Lucene/MySQL) | 23% |
L1+L2 합산 77% 히트. 스케일아웃(81%)과 유사.
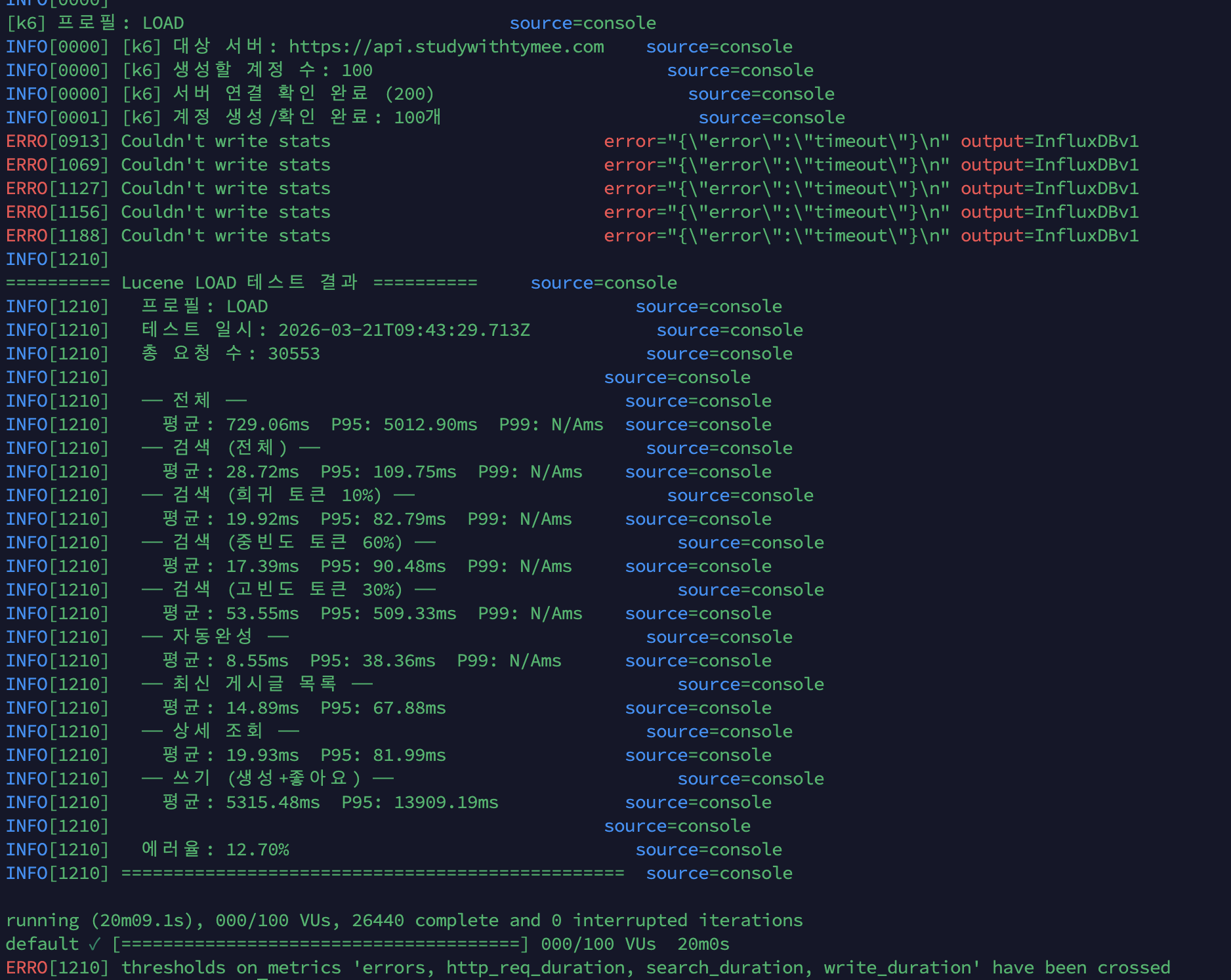

총 요청 수: 30,553에러율: 12.70%
읽기: 검색 28ms / 자동완성 8ms / 목록 14ms / 상세 19ms쓰기: 평균 5,315ms / P95 13,909ms (HikariCP primary pool 고갈)7. @ApplicationModuleListener 전환: 비동기 이벤트 + Event Publication Log
@TransactionalEventListener(AFTER_COMMIT) → @ApplicationModuleListener로 전환. Spring Modulith가 내부적으로 @Async + @TransactionalEventListener(AFTER_COMMIT) + @Transactional(REQUIRES_NEW)를 결합하여 제공한다.
@TransactionalEventListener (Before) | @ApplicationModuleListener (After) | |
|---|---|---|
| 실행 스레드 | HTTP 스레드 (동기, 블로킹) | 별도 스레드 (비동기) |
| DB 커넥션 | Lucene 끝날 때까지 점유 | 커밋 즉시 반환 |
| HTTP 응답 | Lucene 끝난 후 반환 | 커밋 즉시 반환 |
| 이벤트 유실 | 앱 죽으면 유실 | Event Publication Log로 재시도 |
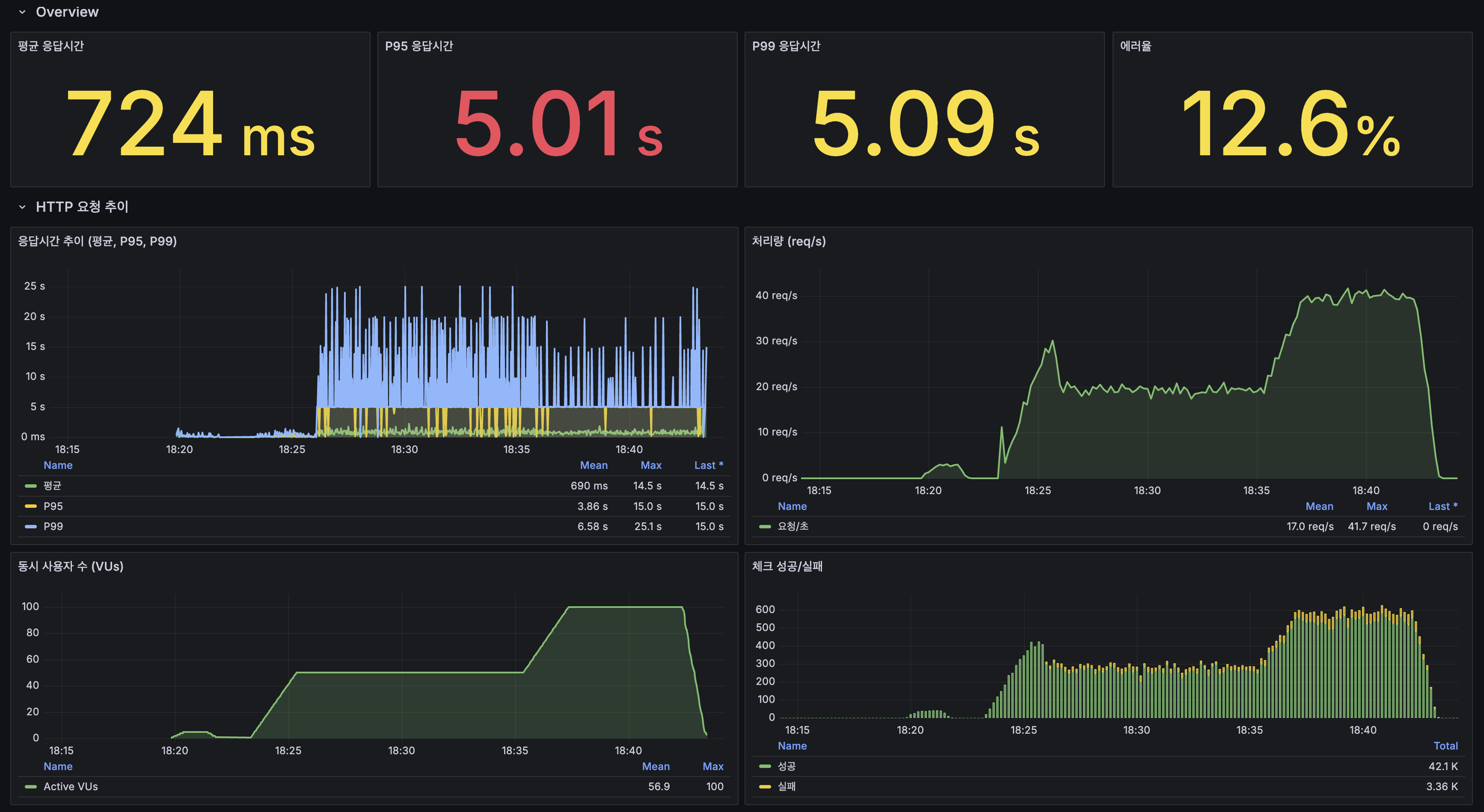
k6 결과: @ApplicationModuleListener 전환 후 (100 VU, 20분)
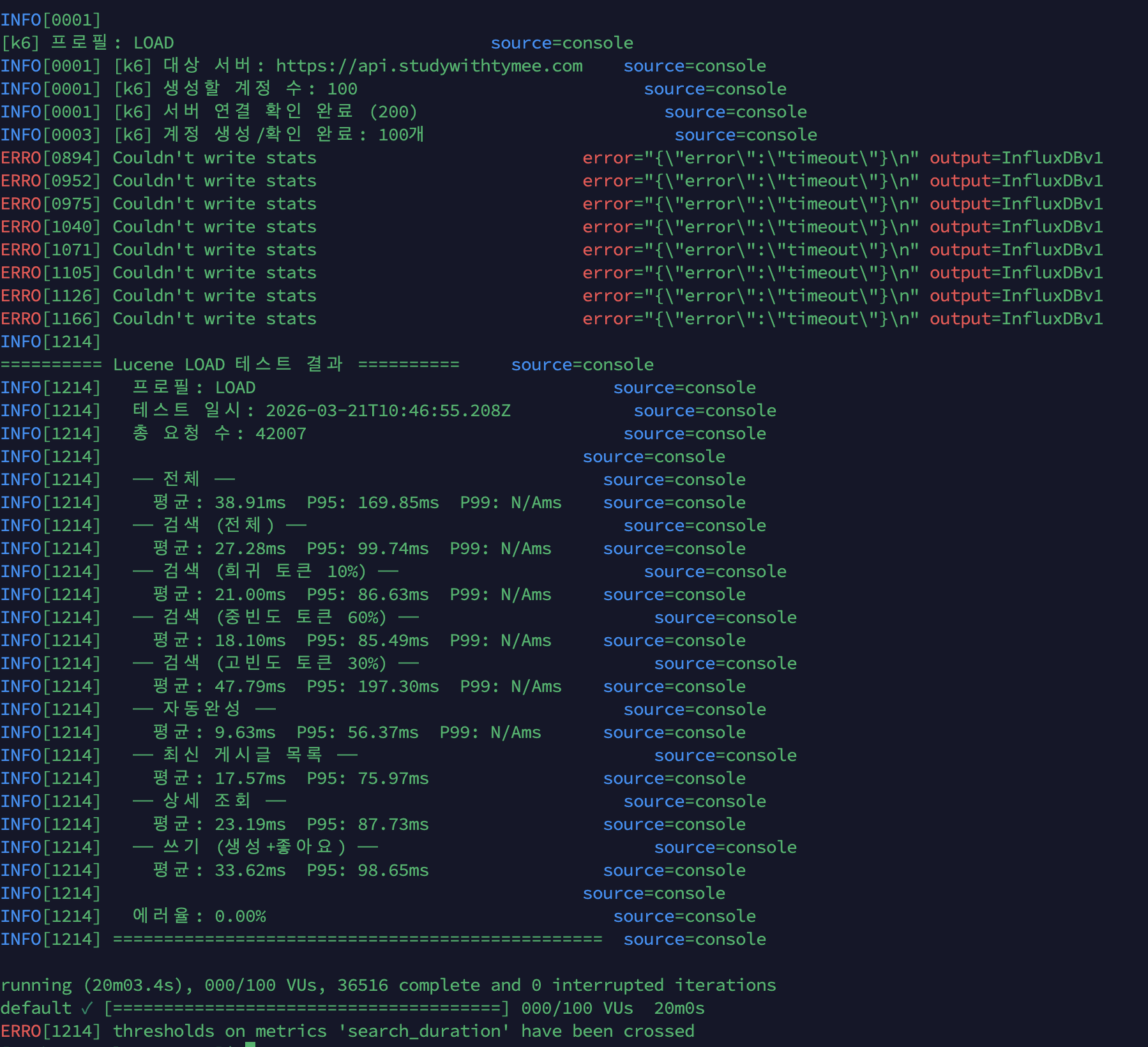
| 지표 | @TransactionalEventListener | @ApplicationModuleListener | 변화 |
|---|---|---|---|
| 평균 응답시간 | 724ms | 38.9ms | 18.6배 개선 |
| P95 | 5.01s | 170ms | 29.5배 개선 |
| P99 | 5.09s | 334ms | 15.2배 개선 |
| 에러율 | 12.6% | 0.00% | 완전 해소 |
| 처리량 (피크) | ~41 req/s | ~58 req/s | 1.4배 증가 |
| 총 요청 수 | 30,553 | 42,007 | 37% 증가 |
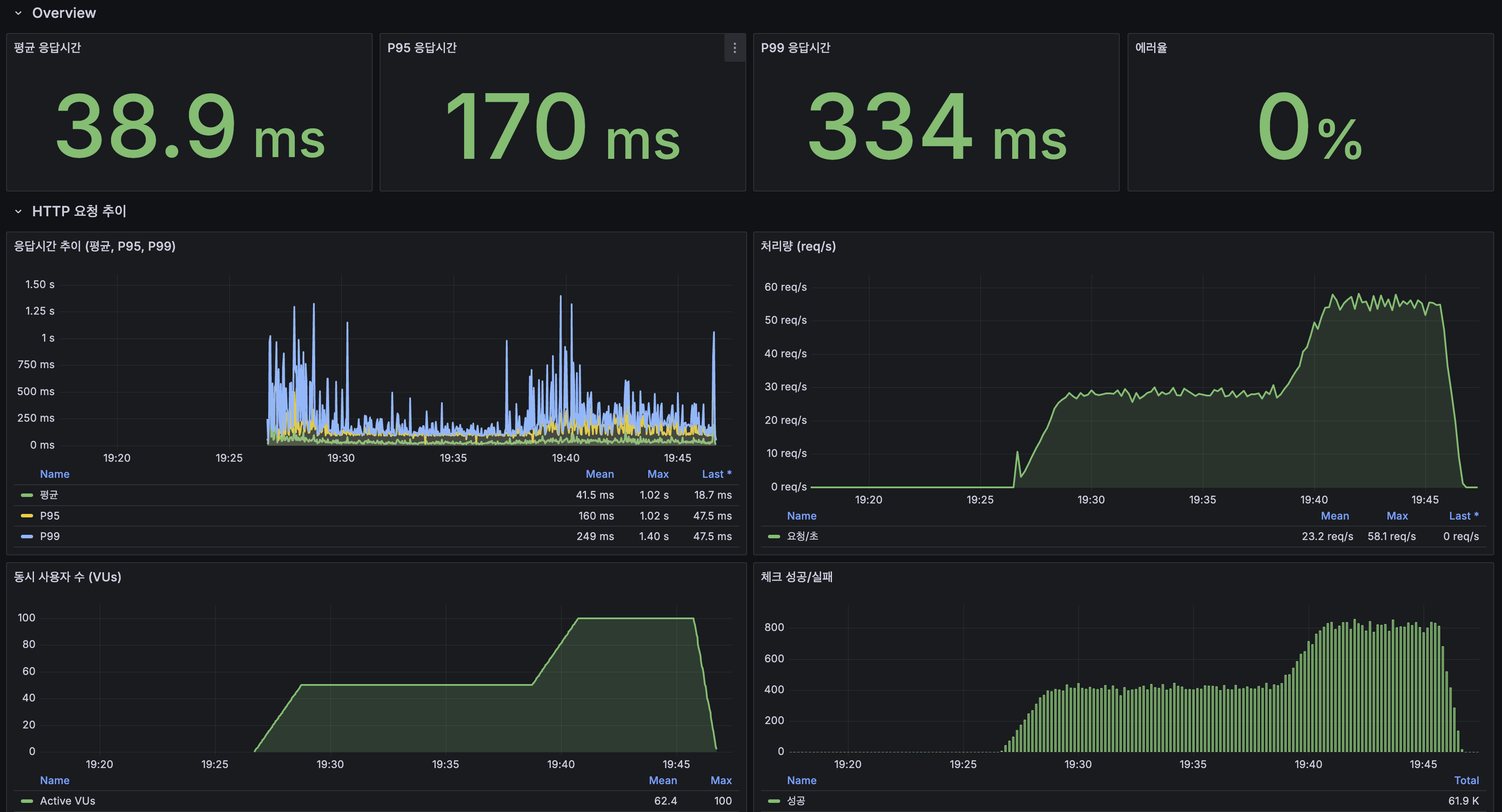
| 시나리오 | Before 평균 | After 평균 | 변화 |
|---|---|---|---|
| 검색 | 28ms | 37ms | 동등 |
| 자동완성 | 8ms | 9ms | 동등 |
| 목록 조회 | 14ms | 16ms | 동등 |
| 상세 조회 | 19ms | 21ms | 동등 |
| 쓰기 (생성+좋아요) | 5,315ms | 33ms | 161배 개선 |
쓰기 병목 완전 해소. 읽기 성능은 동등 유지.
HikariCP: 커넥션 대기 해소
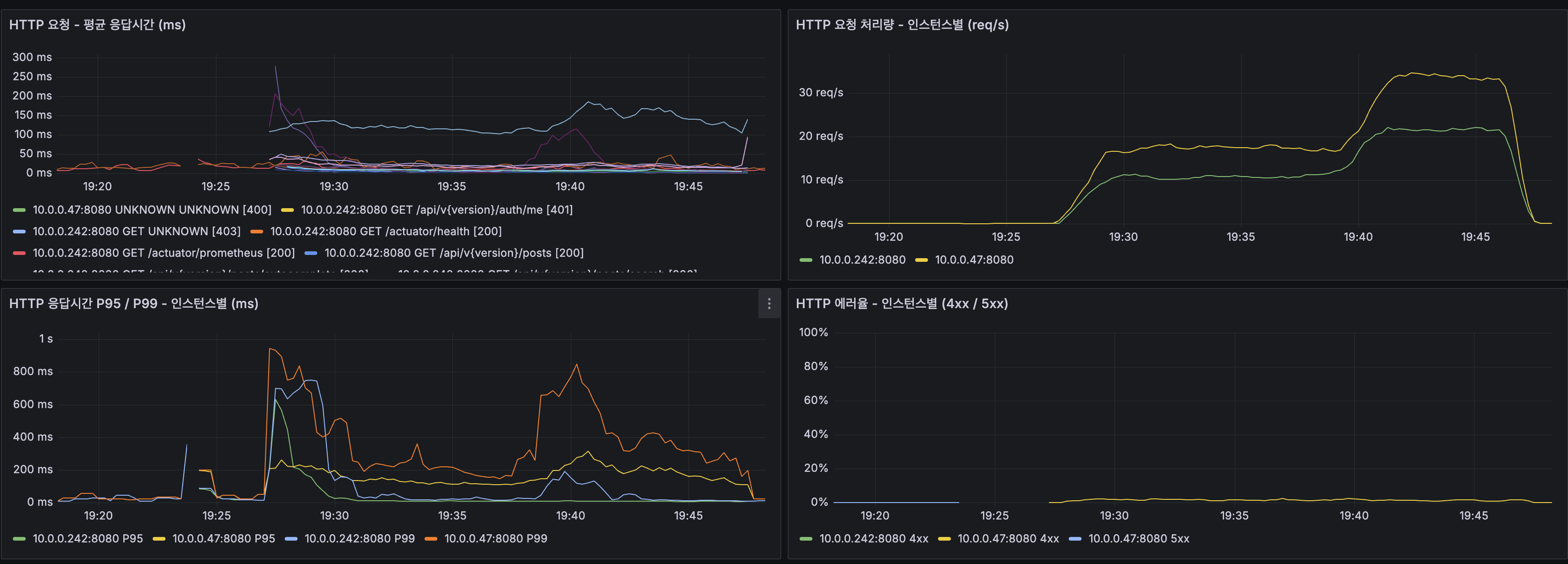
- 커넥션 획득 시간: 4~5초 → ~1ms (즉시 획득)
- DB 커밋 즉시 커넥션 반환 → Lucene 인덱싱은 별도 스레드에서 독립 실행
Grafana 대시보드
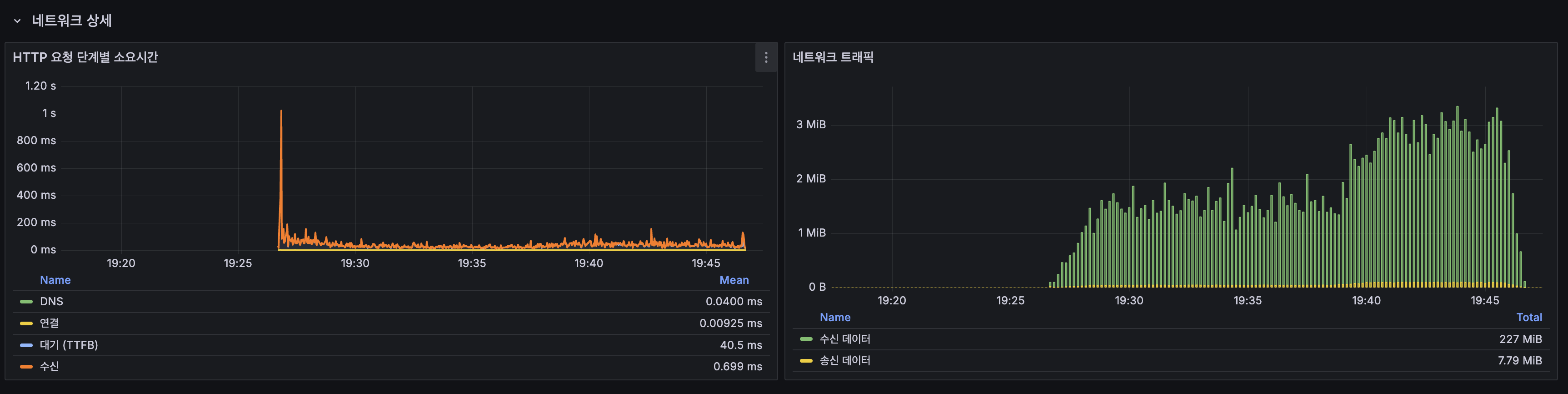
| 계층 | Before | After |
|---|---|---|
| L1 | 37% | 36% |
| L2 | 40% | 43% |
| Origin | 23% | 21% |
L1+L2 합산 79% 히트. 동등.
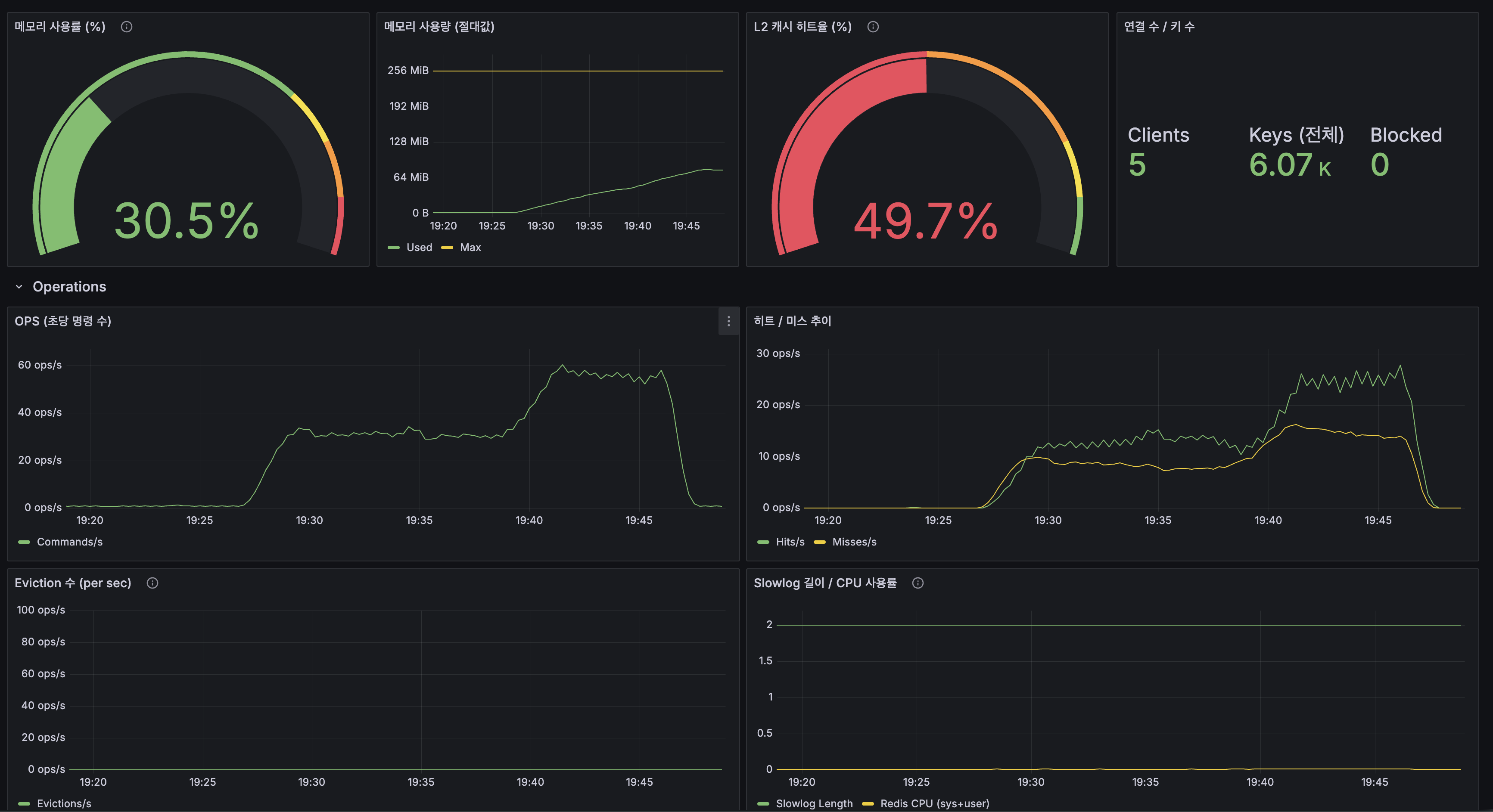
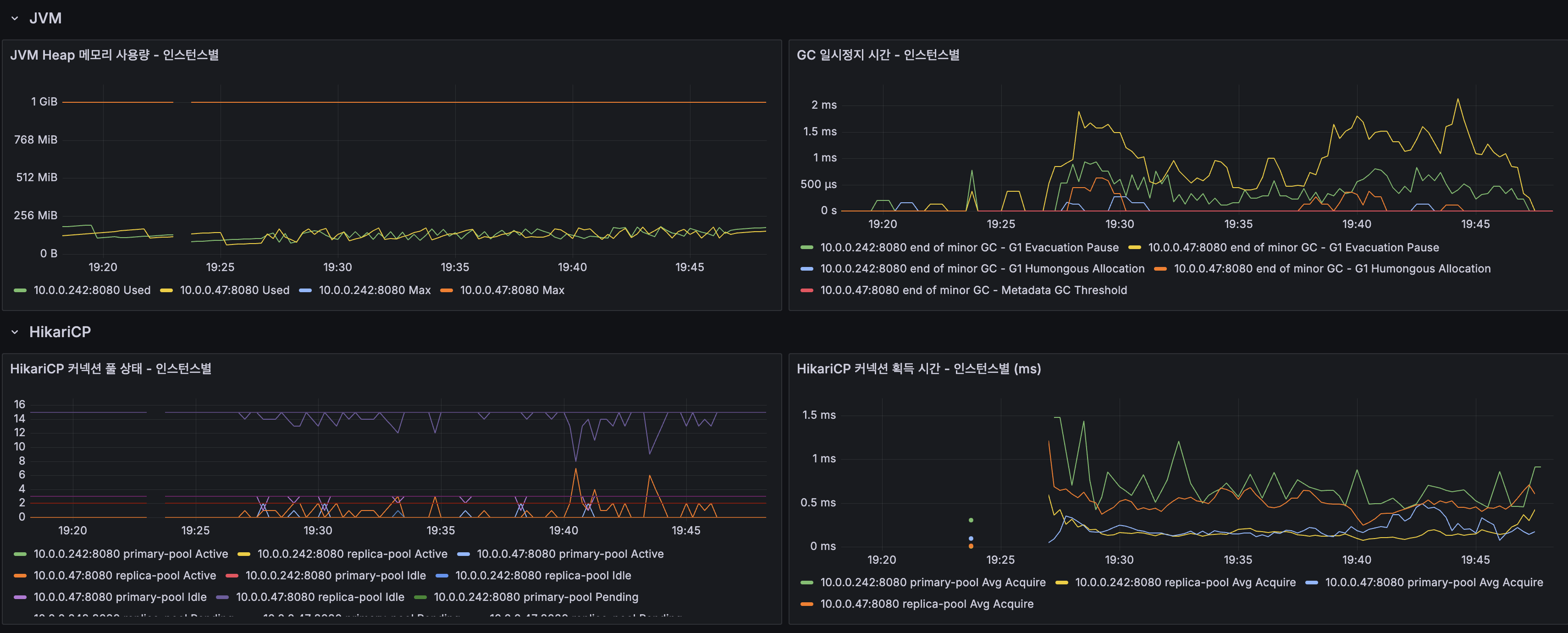
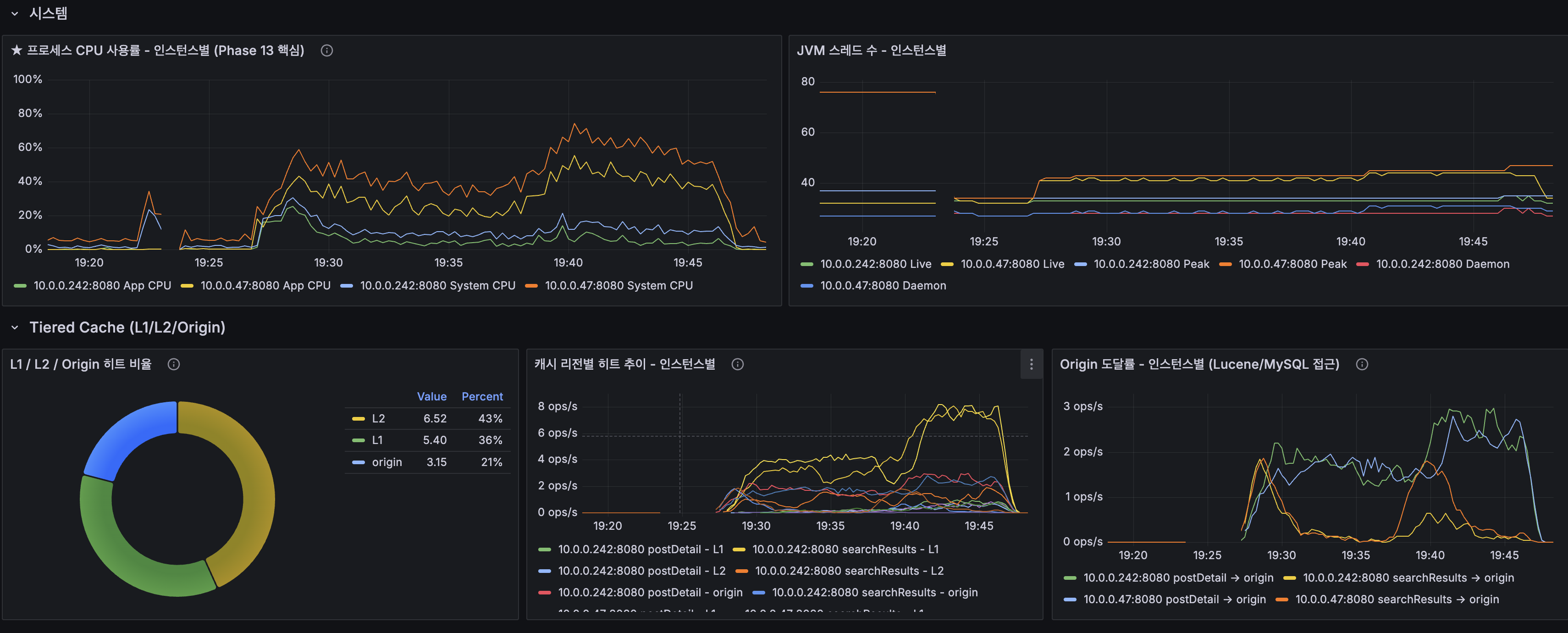
총 요청 수: 42,007에러율: 0.00%
읽기: 검색 27ms / 자동완성 9ms / 목록 17ms / 상세 23ms쓰기: 평균 33ms / P95 98msSpring Event 전환 최종 종합
| 항목 | 결과 |
|---|---|
| 구조 개선 | PostService → Lucene/캐시 직접 호출 제거, 이벤트 기반 디커플링 완료 |
| 비동기 전환 | @ApplicationModuleListener로 HTTP 응답 즉시 반환, Lucene/캐시는 백그라운드 |
| 쓰기 성능 | 5,315ms → 33ms (161배 개선), 에러율 12.6% → 0.00% |
| 읽기 성능 | 스케일아웃 대비 동등 유지 |
| 처리량 | 30,553 → 42,007 요청 (37% 증가) |
| 이벤트 유실 방지 | Event Publication Log로 실패 시 자동 재시도 |
| 검색 캐시 무효화 | 기존 영구 stale → L1 즉시 무효화 + L2 TTL(10분) 자연 만료 |
Event Publication Log 재시도 검증
Spring Modulith의 Event Publication Log가 실제로 재시도에 성공하는지 검증했다.

알려진 한계: (1) 이벤트 클래스의 FQCN이 DB에 저장되므로, 클래스를 리네임/이동하면 기존 미완료 이벤트의 재시도가 ClassNotFoundException으로 실패한다. 이벤트 클래스 변경 전 미완료 이벤트를 반드시 소진해야 한다. (2) GitHub Issue #835에서 런타임 중 리스너가 호출되지 않는 케이스가 보고되었다. 이 프로젝트에서는 재현되지 않았지만, Kafka CDC로 진화하는 추가적인 동기가 된다. (3) 멀티 인스턴스에서 재시작 시 미완료 이벤트 재처리가 인스턴스별로 독립적이므로 중복 처리가 가능하고, 따라서 Consumer 멱등성이 전제조건이다.
8. Debezium + Kafka CDC
Outbox를 별도로 구현하지 않은 이유
로드맵에서는 Spring Event → Outbox → CDC를 계획했지만, Outbox를 건너뛰고 @ApplicationModuleListener에서 바로 Kafka CDC로 진화했다. Spring Modulith의 @ApplicationModuleListener가 Outbox의 핵심 기능을 프레임워크 수준에서 이미 제공하기 때문이다.
| Outbox의 목표 | Spring Modulith 제공 여부 |
|---|---|
| 이벤트 유실 방지 (DB 저장) | Event Publication Log: 이벤트를 DB 테이블에 기록, 미완료 시 재시도 |
| 앱 재시작 후 미발행 이벤트 처리 | 자동 재시도: IncompleteEventPublications 스케줄러가 미완료 이벤트 재처리 |
| 리스너 실패 시 재시도 | 기본 제공: 리스너 예외 시 미완료 상태 유지 후 다음 주기에 재시도 |
왜 이렇게 진화했는가
| 구간 | 방식 | 쓰기 경로 | 문제 |
|---|---|---|---|
| Before | dual-write | save() → indexSafely() → evict() → 커밋 → 응답 | Lucene 실패 시 영구 불일치, OCP 위반 |
| 동기 이벤트 | @TransactionalEventListener | save() → 커밋 → Lucene(동기) → 응답 | 커밋 후에도 커넥션 점유 → 쓰기 5,315ms |
| 비동기 이벤트 | @ApplicationModuleListener | save() → 커밋 → 응답 (Lucene은 별도 스레드) | 비동기로 해결, 쓰기 33ms. 하지만 직접 SQL 미감지, JVM 로컬 |
| Kafka CDC | Kafka CDC | save() → 커밋 → 응답 (publishEvent no-op) | dual-write 원천 차단. binlog 기반으로 모든 변경 캡처 |
Kafka + CDC가 해결하는 구조적 한계
| 한계 | @ApplicationModuleListener | CDC (Kafka + Debezium) |
|---|---|---|
| 직접 SQL 미감지 | PostService를 거치지 않는 변경은 이벤트 미발생 | binlog 레벨에서 모든 경로의 변경 캡처 |
| JVM 로컬 이벤트 | App 1의 이벤트를 App 2가 모름 | Consumer Group으로 자동 분산 |
| 이벤트 리플레이 불가 | 히스토리 없음, 인덱스 손상 시 전체 재인덱싱 | Kafka 토픽에서 리플레이로 재구축 |
| 앱 = 이벤트 인프라 | 앱 죽으면 이벤트 처리도 중단 | Kafka에 보존, 앱 복구 후 이어서 소비 |
| 순서 보장 | 동일 트랜잭션 내에서만 | binlog position 기반 전역 순서 |
”직접 SQL 미감지”가 현실에서 발생하는 시나리오
| 시나리오 | 발생 빈도 | 설명 |
|---|---|---|
| 데이터 마이그레이션 | 스키마 변경 시 | Flyway 마이그레이션 스크립트의 UPDATE 배치. PostService를 거치지 않음 |
| 긴급 데이터 수정 | 장애 발생 시 | 스팸 봇 게시글 일괄 삭제. API로 1,000건 삭제는 비현실적 |
| 배치 작업 | 정기적 | @Modifying JPQL 벌크 연산은 PostService 이벤트 발행을 건너뜀 |
| MySQL Replication | 상시 | Primary/Replica 불일치 순간 존재. CDC는 Primary binlog 직접 읽기 |
| 서비스 확장 | 향후 | 별도 모듈/마이크로서비스가 같은 DB에 접근 시 |
핵심은 “PostService를 통하지 않는 모든 변경 경로를 원천 차단할 수 있는가?”이다. CDC(binlog 기반)는 이 문제를 데이터베이스 레벨에서 해결한다.
Redis Streams를 쓰지 않는 이유
| 관점 | Redis Streams | Kafka |
|---|---|---|
| 내구성 | 메모리 기반, AOF에도 커널 패닉 시 유실 가능 | 디스크 기반 + replication, 브로커 장애에도 보존 |
| 리플레이 | MAXLEN 트리밍 시 영구 소실 | retention으로 수 주~수 개월 보존, 인덱스 재구축 가능 |
| 수평 확장 | 단일 인스턴스 단일 스레드 | 파티션 기반 수평 확장 네이티브 |
인프라 구성

KRaft 단일 브로커의 한계와 방어 전략: Confluent 공식 문서에서 KRaft combined mode(브로커 + 컨트롤러 단일 프로세스)는 개발/테스트 전용이라고 명시하며, 프로덕션에서는 최소 3개 컨트롤러를 권장한다. 현재 단일 브로커 구성에서 Kafka가 죽으면 CDC 파이프라인이 멈추지만, 서비스 자체는 중단되지 않는다.
@ConditionalOnPropertyfallback으로@ApplicationModuleListener가 자동 전환되어 비동기 이벤트 처리 수준으로 동작한다. 이 구조에서 Kafka의 역할은 “평시의 정확성 극대화”이고, fallback은 “장애 시 서비스 연속성 보장”이다. Kafka가 복구되면 Debezium이 마지막 binlog position부터 이어서 캡처하므로 장애 동안의 변경도 소급 반영된다. 프로덕션 확장 시에는 KRaft 3노드 컨트롤러 + 전용 브로커로 HA를 확보해야 한다.
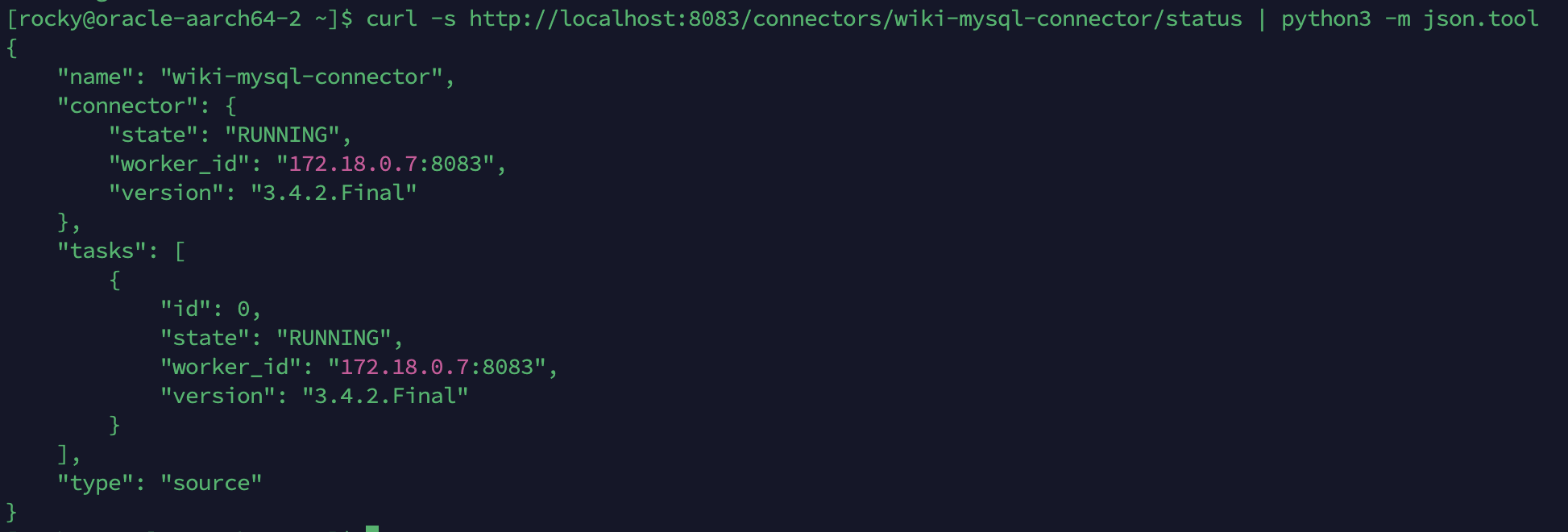
Debezium Connector 상태
Kafka 토픽

| 토픽 | 역할 |
|---|---|
__consumer_offsets | Kafka Consumer Group offset 저장 |
__debezium-heartbeat.dbserver1 | Debezium 헬스체크 heartbeat |
_debezium_configs | Debezium Connect 설정 저장 |
_debezium_offsets | Debezium binlog position 저장 |
_debezium_status | Debezium Connector 상태 저장 |
_schema_history | MySQL 스키마 변경 이력 |
코드 구조: Kafka 유무에 따른 자동 전환

CDC 파이프라인 동작 확인
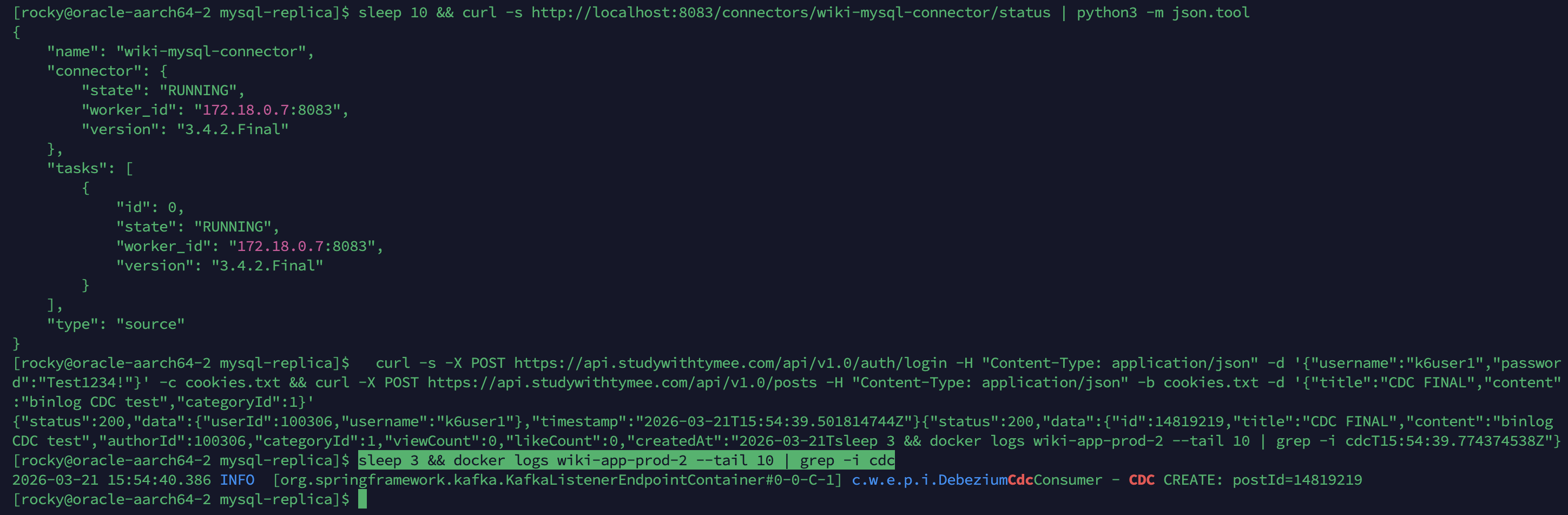

CDC Consumer 아키텍처 버그 발견 및 수정
Kafka CDC 배포 후 게시글 생성 → 검색 노출이 안 되는 문제를 발견했다.

근본 원인: docker-compose.yml.j2(App 1)에서 SPRING_KAFKA_BOOTSTRAP_SERVERS 환경변수 매핑이 빠져 있었다.
수정 후 구조:

현업과의 비교: 프로덕션에서는 Elasticsearch/OpenSearch 같은 별도 검색 클러스터가 자체적으로 Primary/Replica 복제를 관리하므로, “CDC Consumer가 어느 App에서 돌아야 하느냐” 문제가 발생하지 않는다. embedded Lucene은 인프라 비용을 아끼는 대신, 이런 관리 복잡성을 애플리케이션이 부담한다.
Consumer Group 분리 이유: App 1과 App 2가 CDC로 하는 일이 다르므로(인덱싱 vs 캐시 무효화), 브로드캐스트 패턴(별도 Consumer Group)을 적용했다.
CDC 정확성 검증: 직접 SQL DELETE 테스트

CDC End-to-End 지연 측정

커뮤니티 게시판에서 “게시글 작성 후 2초 뒤 검색 가능”은 허용 가능한 수준이며, CDC의 이점(직접 SQL 감지, 이벤트 리플레이, 양쪽 L1 캐시 무효화)이 이 지연을 상회한다.
9. k6 부하 테스트: Kafka CDC (100 VU, 20분)
성능 비교
| 지표 | @TransactionalEventListener | @ApplicationModuleListener | Kafka CDC |
|---|---|---|---|
| 평균 응답시간 | 724ms | 38.9ms | 35.6ms |
| P95 | 5.01s | 170ms | 138ms |
| P99 | 5.09s | 334ms | 294ms |
| 에러율 | 12.6% | 0.00% | 0.00% |
| 쓰기 평균 | 5,315ms | 33ms | 24ms |
| 처리량 (피크) | ~41 req/s | ~58 req/s | ~58 req/s |
| 총 요청 수 | 30,553 | 42,007 | 42,084 |
@ApplicationModuleListener와 Kafka CDC의 읽기/쓰기 성능이 동등하다. CDC를 도입한 핵심 이유는 성능보다 아키텍처 정확성(correctness)에 있다.
k6 터미널 결과
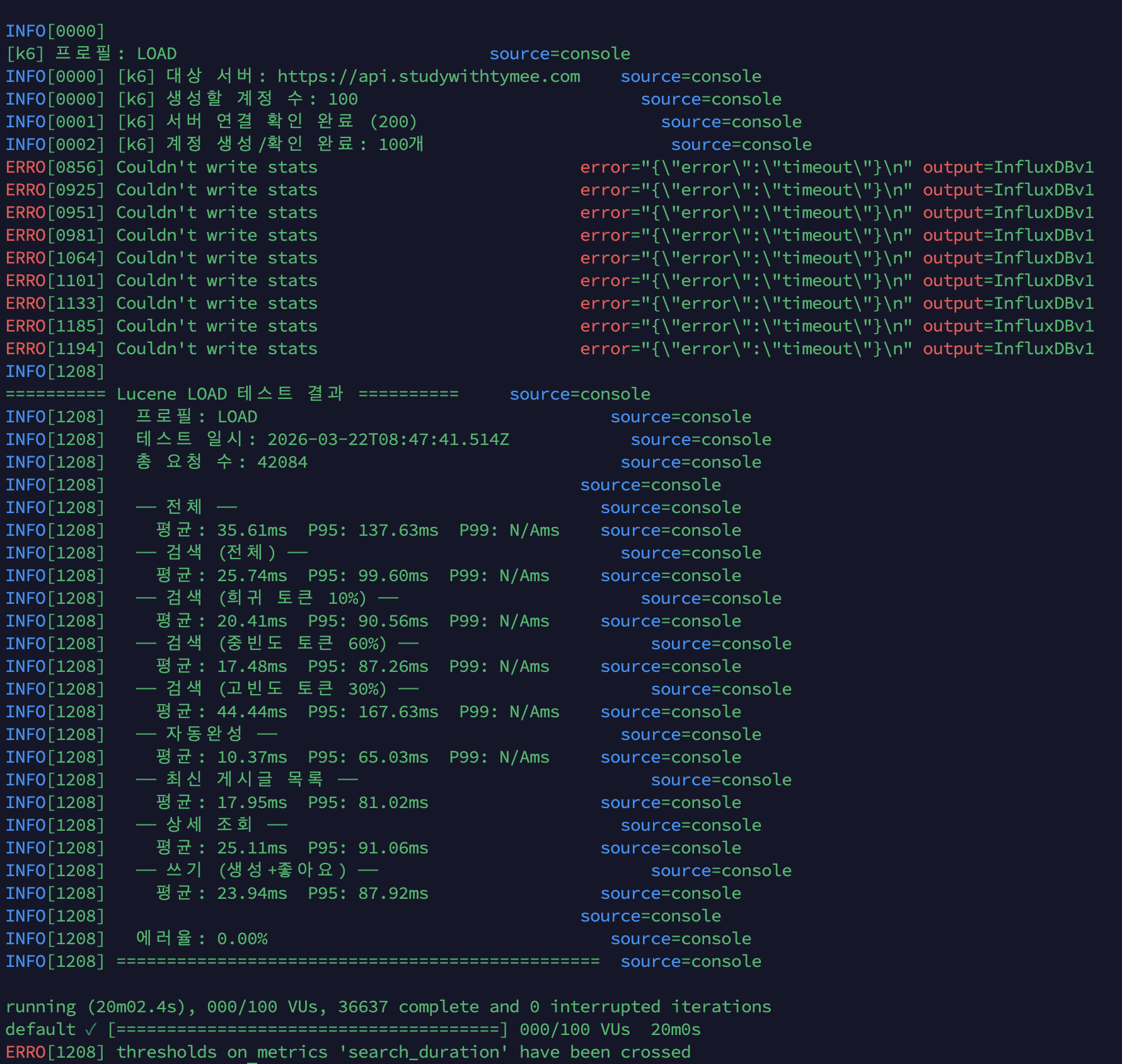
프로필: LOAD (100 VU, 20분)총 요청 수: 42,084에러율: 0.00%
전체: 평균 35.61ms P95 137.63ms검색 (전체): 평균 25.74ms P95 99.60ms 희귀 토큰 (10%): 평균 20.41ms P95 90.56ms 중빈도 토큰 (60%): 평균 17.48ms P95 87.26ms 고빈도 토큰 (30%): 평균 44.44ms P95 167.63ms자동완성: 평균 10.37ms P95 65.03ms최신 게시글: 평균 17.95ms P95 81.02ms상세 조회: 평균 25.11ms P95 91.06ms쓰기 (생성+좋아요): 평균 23.94ms P95 87.92msOverview
시나리오별 응답시간
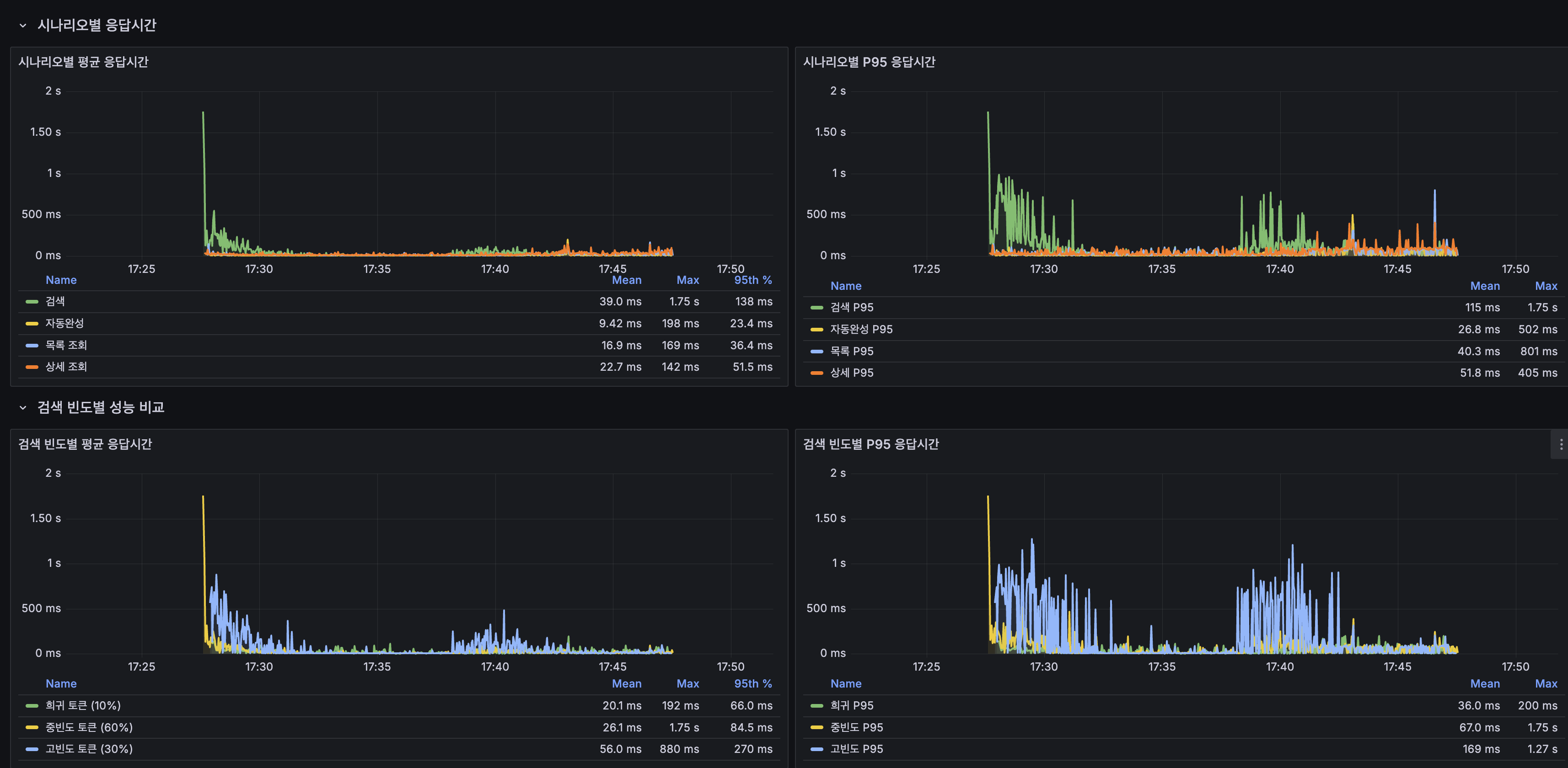
| 시나리오 | @ApplicationModuleListener 평균 | Kafka CDC 평균 | P95 | 판정 |
|---|---|---|---|---|
| 검색 | 37ms | 39ms | 138ms | 동등 |
| 자동완성 | 9ms | 9.4ms | 23ms | 동등 |
| 목록 조회 | 16ms | 16.9ms | 36ms | 동등 |
| 상세 조회 | 21ms | 22.7ms | 52ms | 동등 |
| 쓰기 | 33ms | 24ms | 88ms | 개선 |
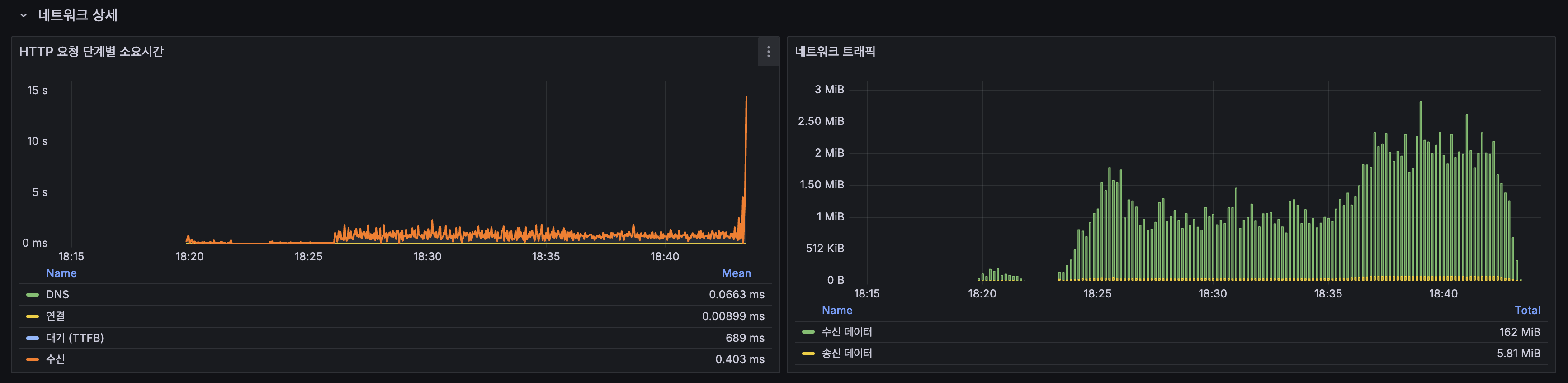
네트워크 상세
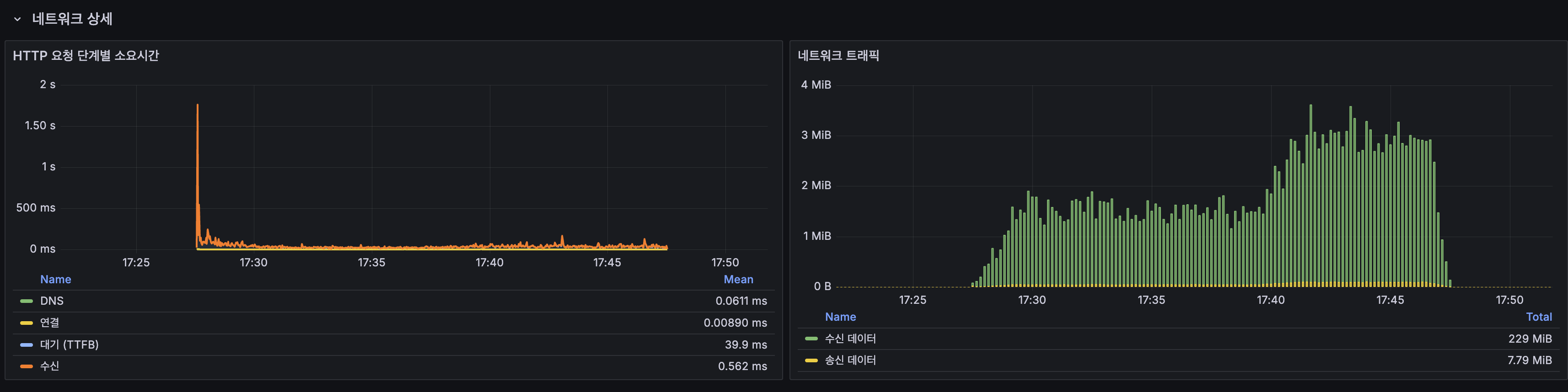
| 단계 | 평균 |
|---|---|
| DNS | 0.06ms |
| 연결 | 0.009ms |
| 대기 (TTFB) | 39.9ms |
| 수신 | 0.56ms |
Debezium CDC 모니터링
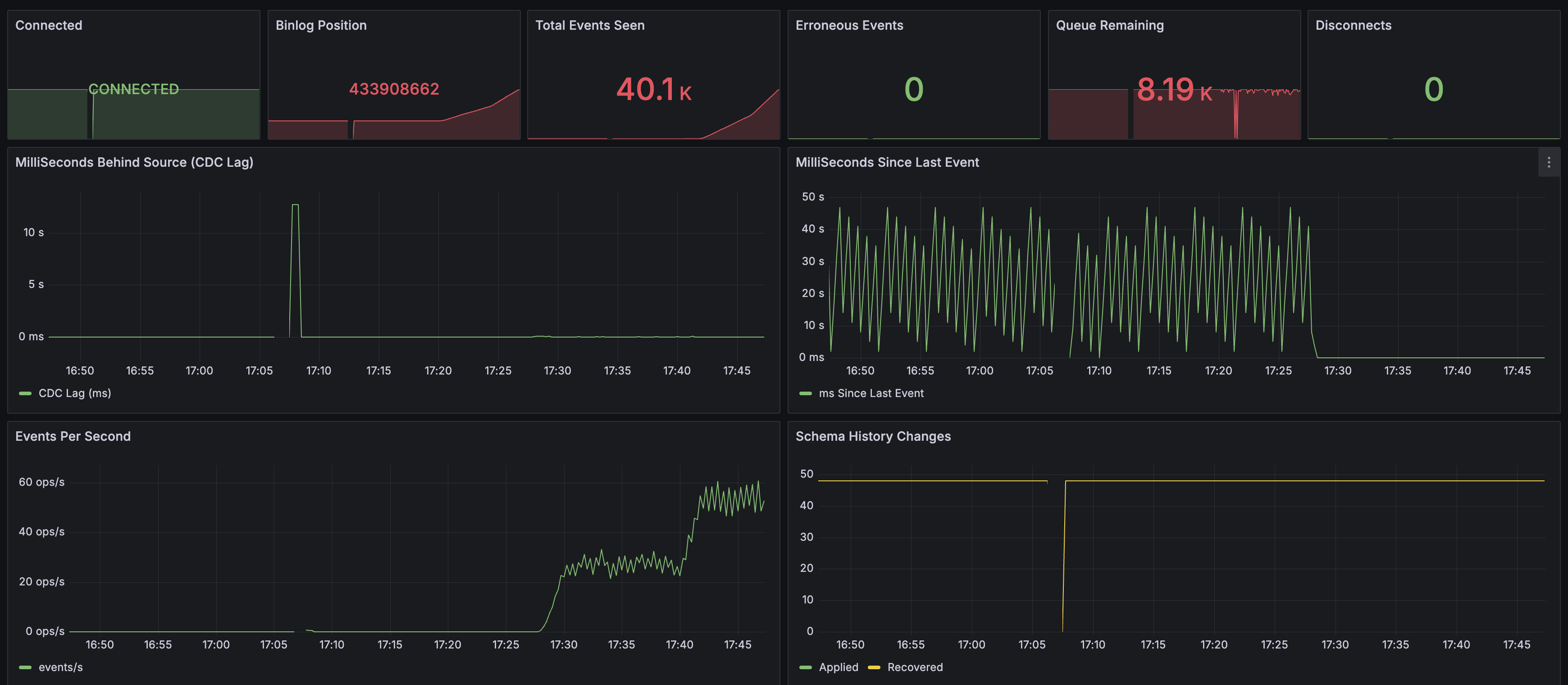
| 지표 | 값 | 의미 |
|---|---|---|
| Connected | CONNECTED | Debezium ↔ MySQL binlog 연결 정상 |
| Total Events Seen | 40.1K | 부하 테스트 동안 감지한 총 이벤트 수 |
| Erroneous Events | 0 | 에러 없음 |
| Disconnects | 0 | 연결 끊김 없음 |
- CDC Lag: 초기 ~10초 스파이크 후 0ms 근처로 수렴
- Events Per Second: 부하에 따라 0 → ~60 ops/s까지 선형 증가
Kafka 모니터링
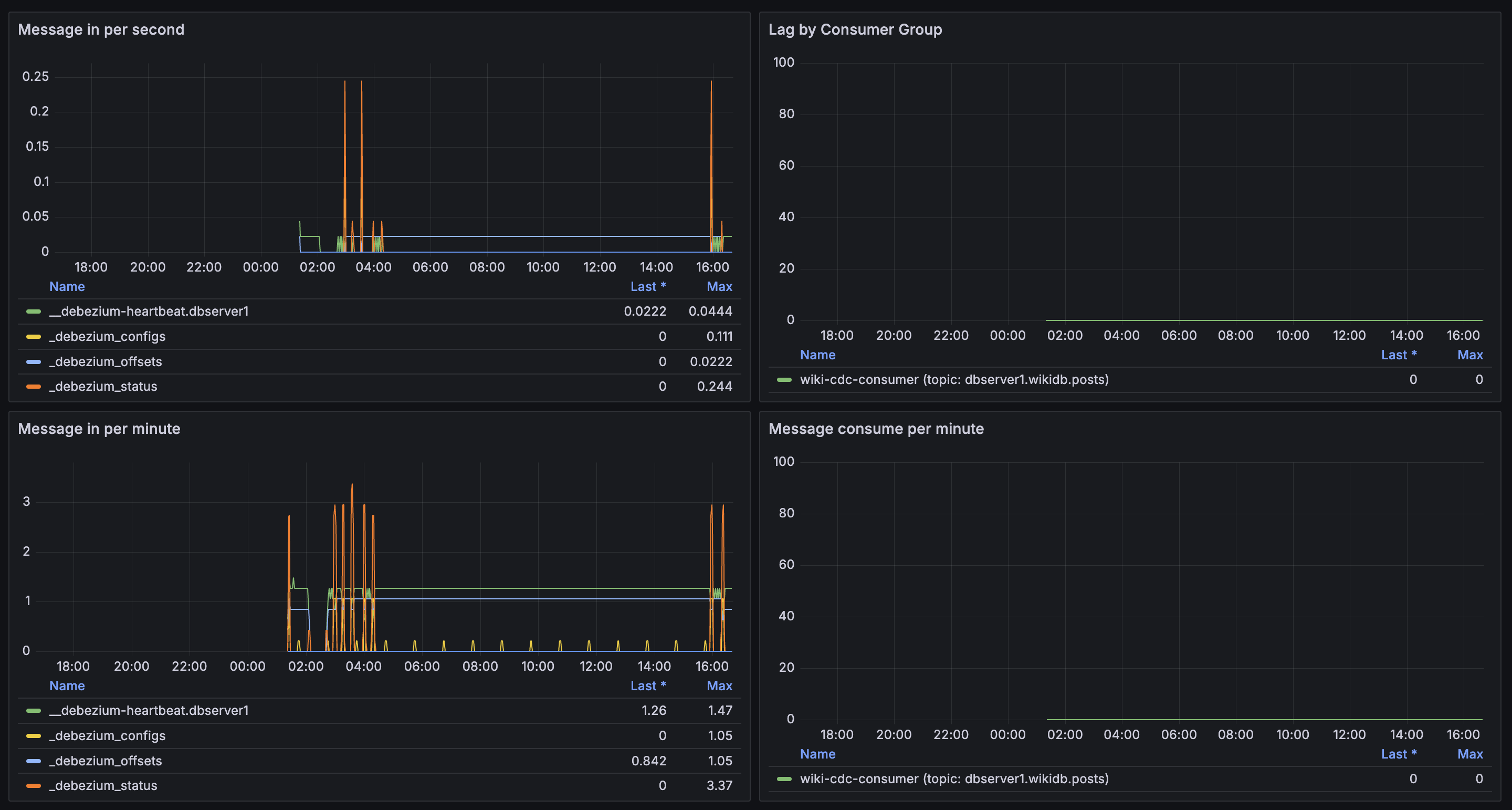
- Lag by Consumer Group:
wiki-cdc-consumer의 lag 0. Consumer가 메시지를 즉시 소비

Spring Boot / JVM
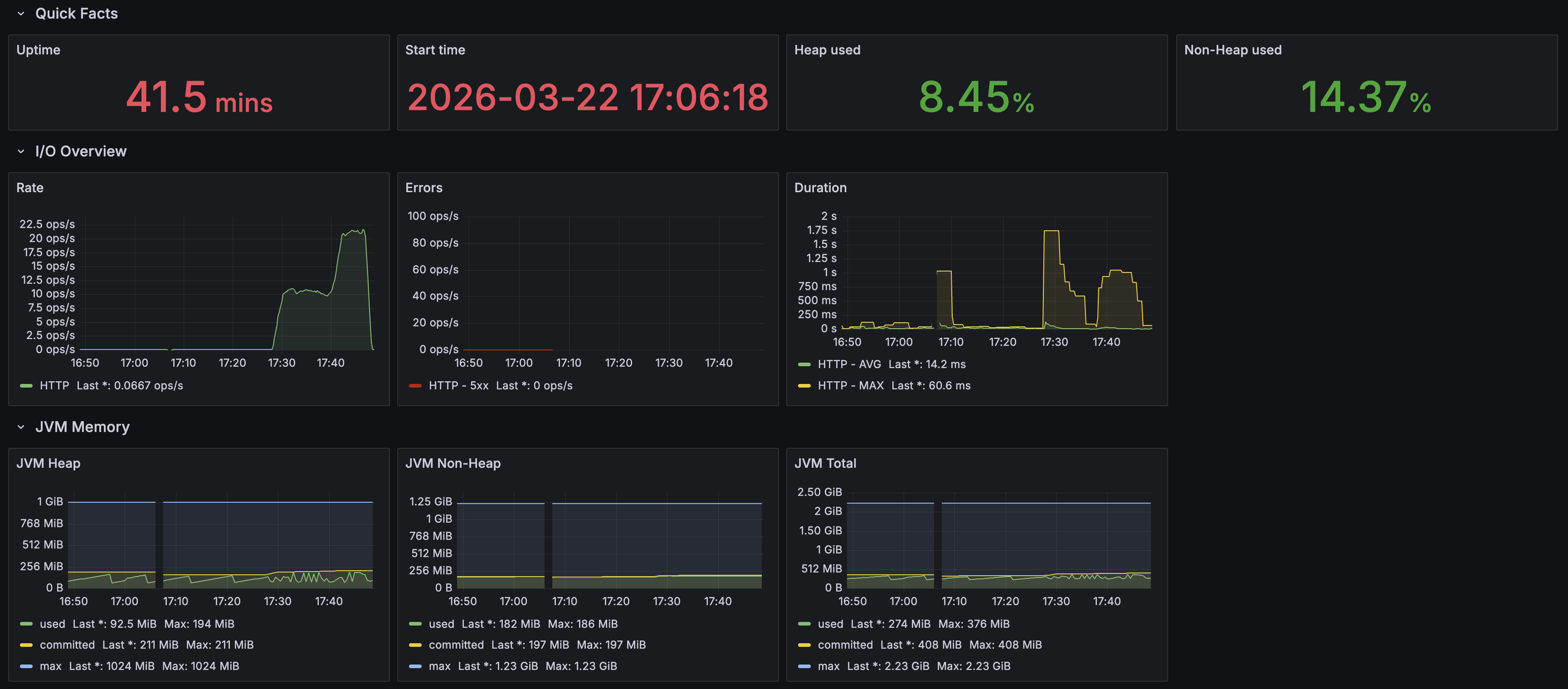
- Heap used: 8.45% (92.5 MiB / 1 GiB)
- HTTP Errors (5xx): 0 ops/s
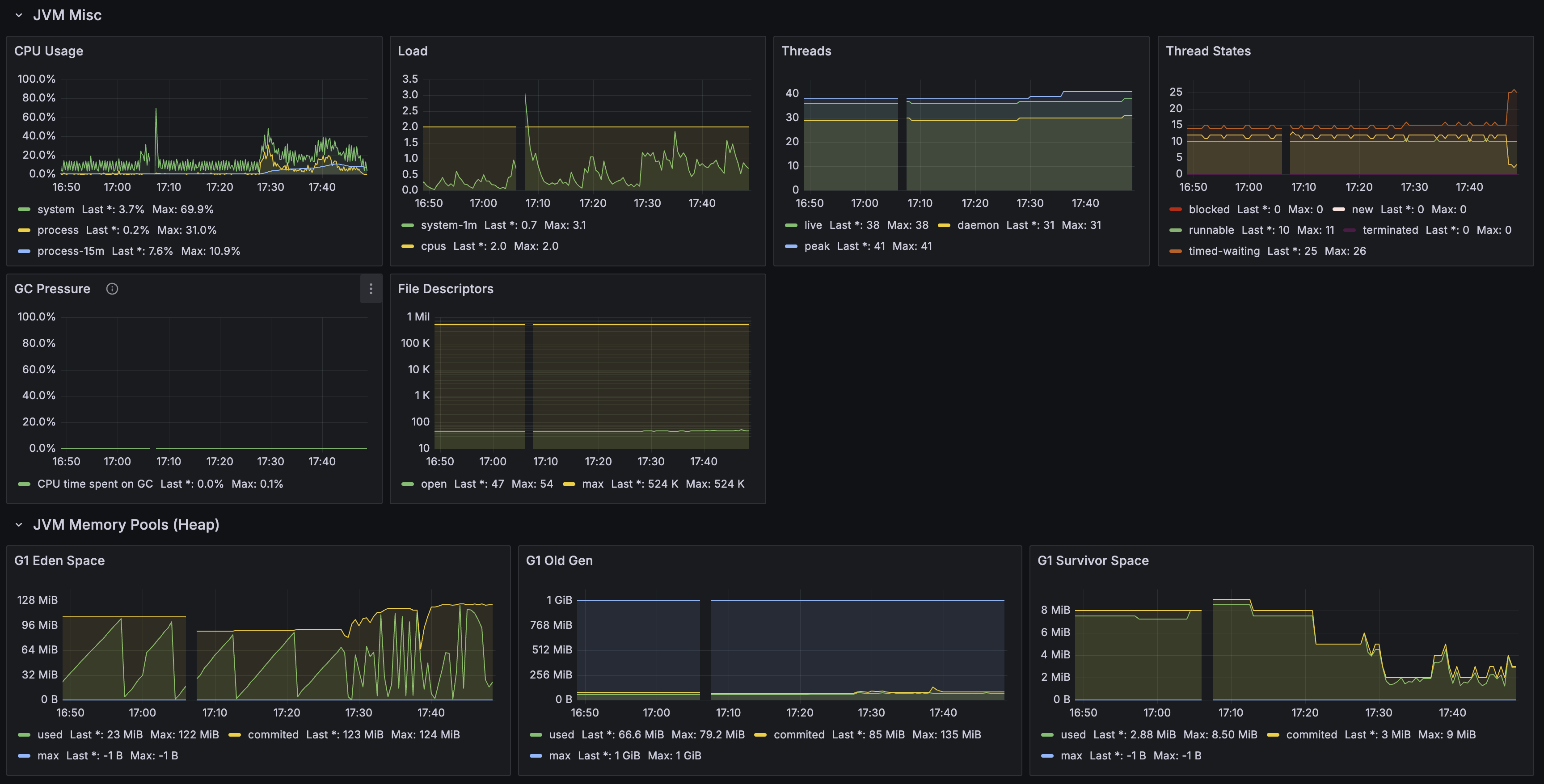
- GC Pressure: 0.1%
- Threads: live 38, daemon 31, peak 41
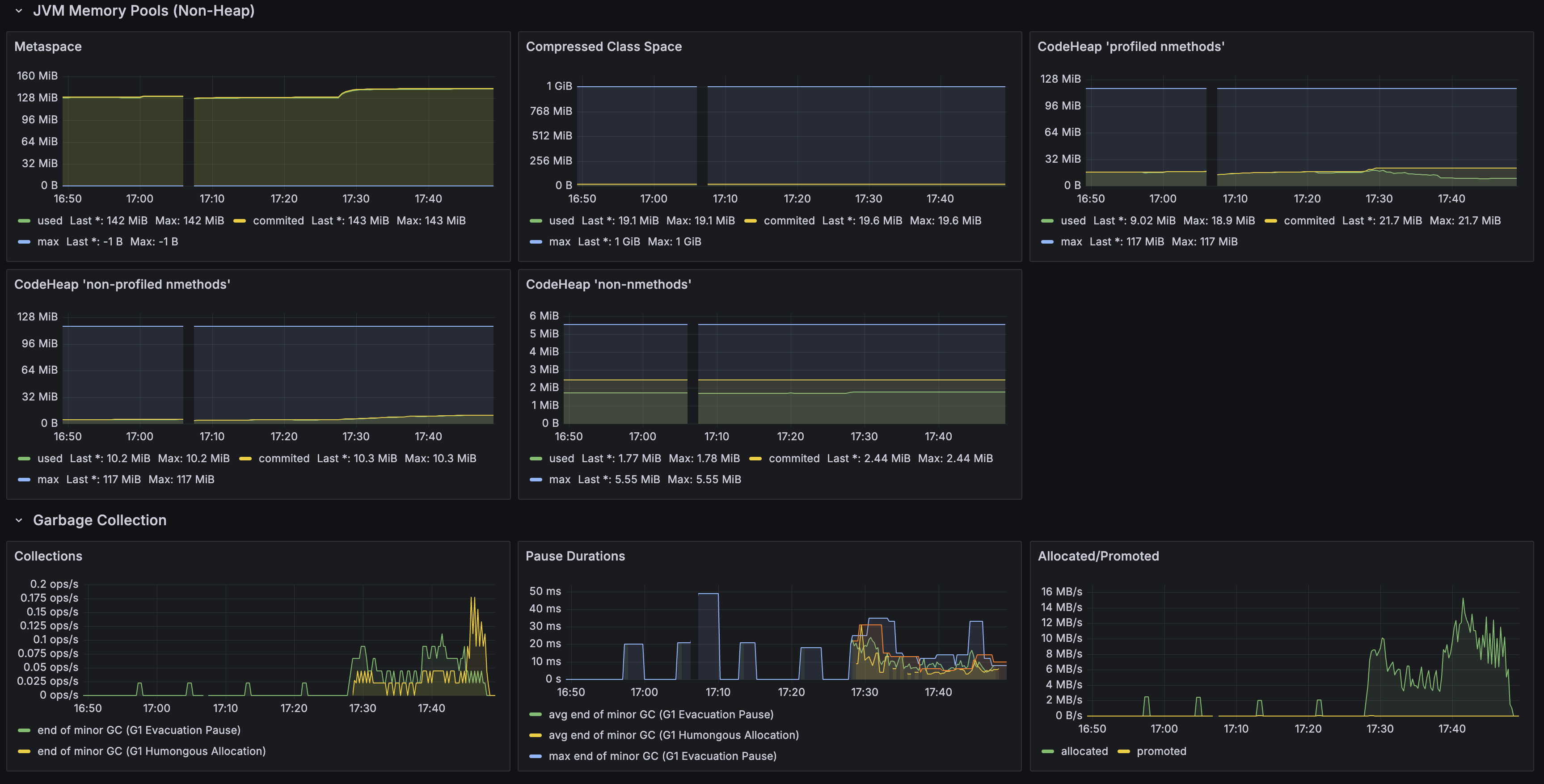
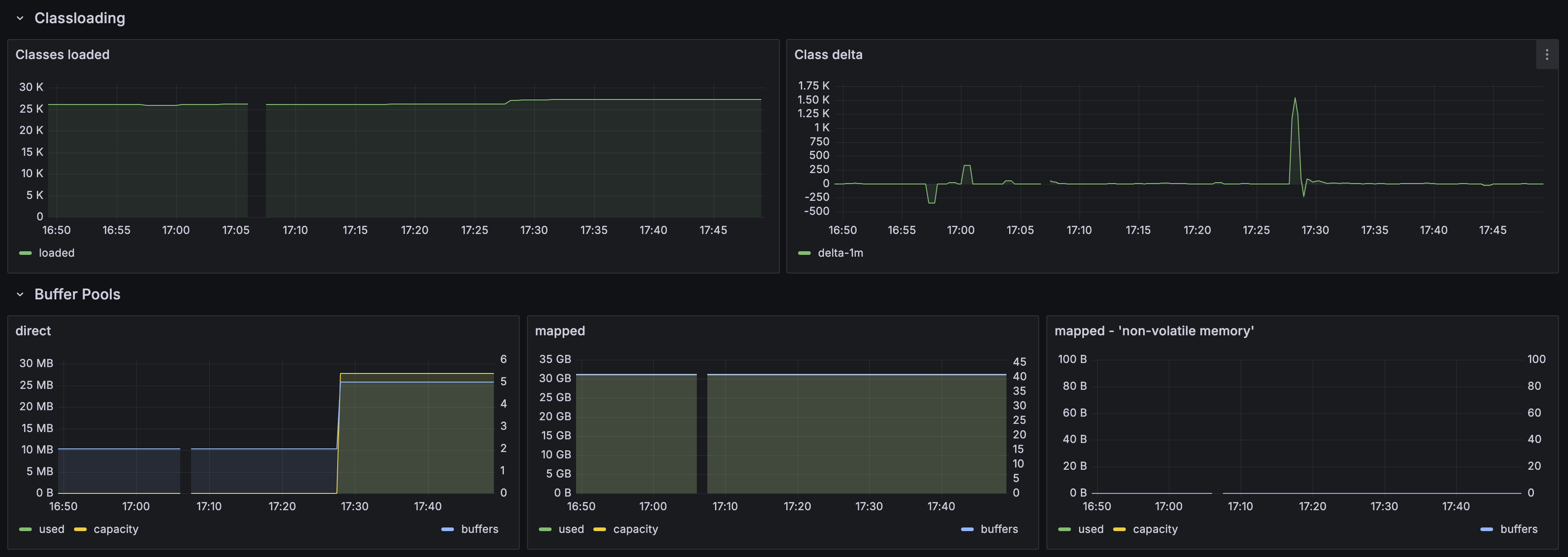
- Mapped buffer: ~30 GB, Lucene 인덱스 파일의 memory-mapped I/O. 1,215만 건 인덱스
Nginx
인프라 (Host)
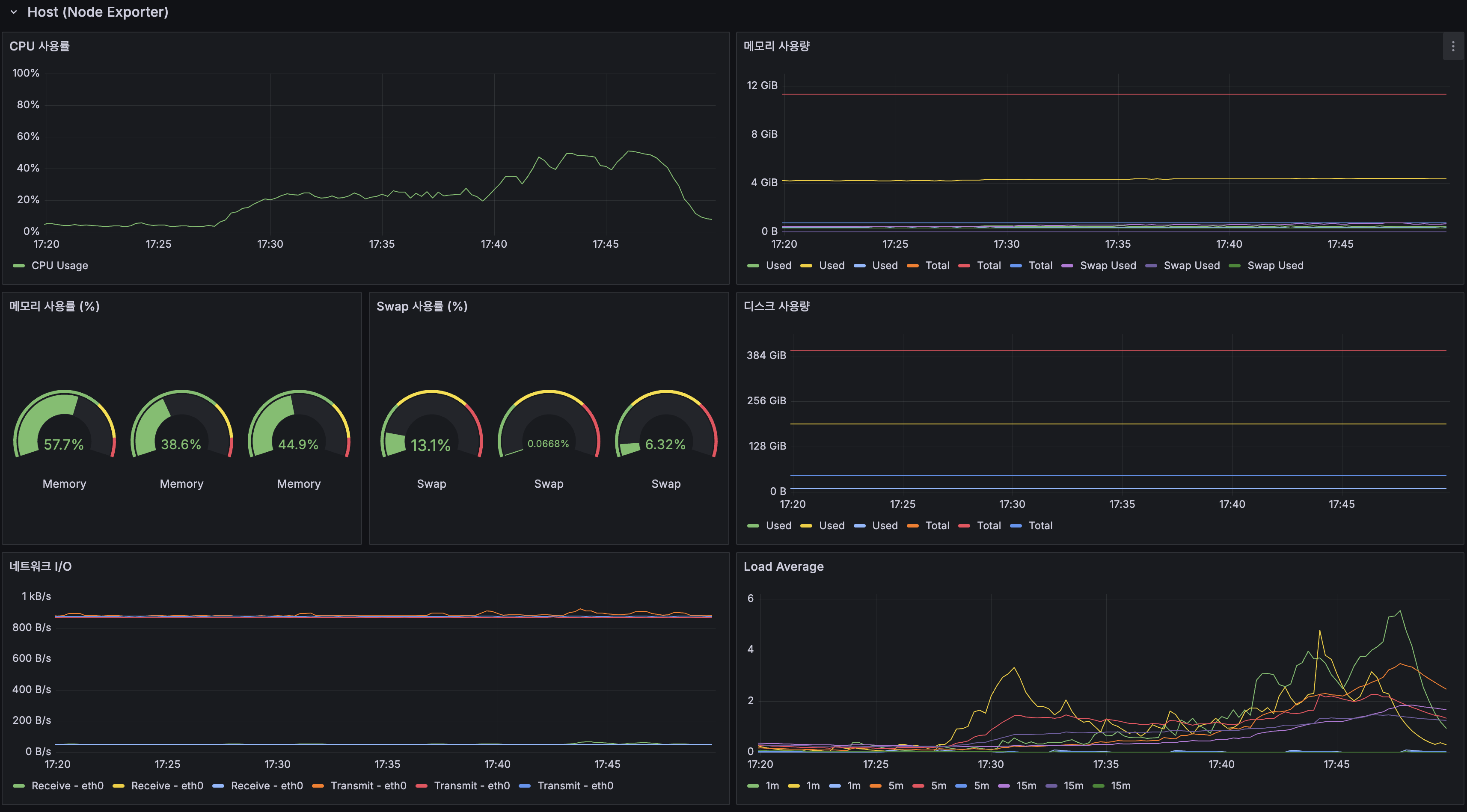
| 서버 | CPU 피크 | 메모리 | Swap |
|---|---|---|---|
| 서버 1 (App 1 + MySQL Primary + Redis) | ~40% | 57.7% | 13.1% |
| 서버 2 (App 2 + MySQL Replica + Kafka + Debezium) | 38.6% | 38.6% | 0.07% |
| 서버 3 (Grafana + Prometheus + InfluxDB) | 44.9% | 44.9% | 6.32% |
컨테이너별 리소스
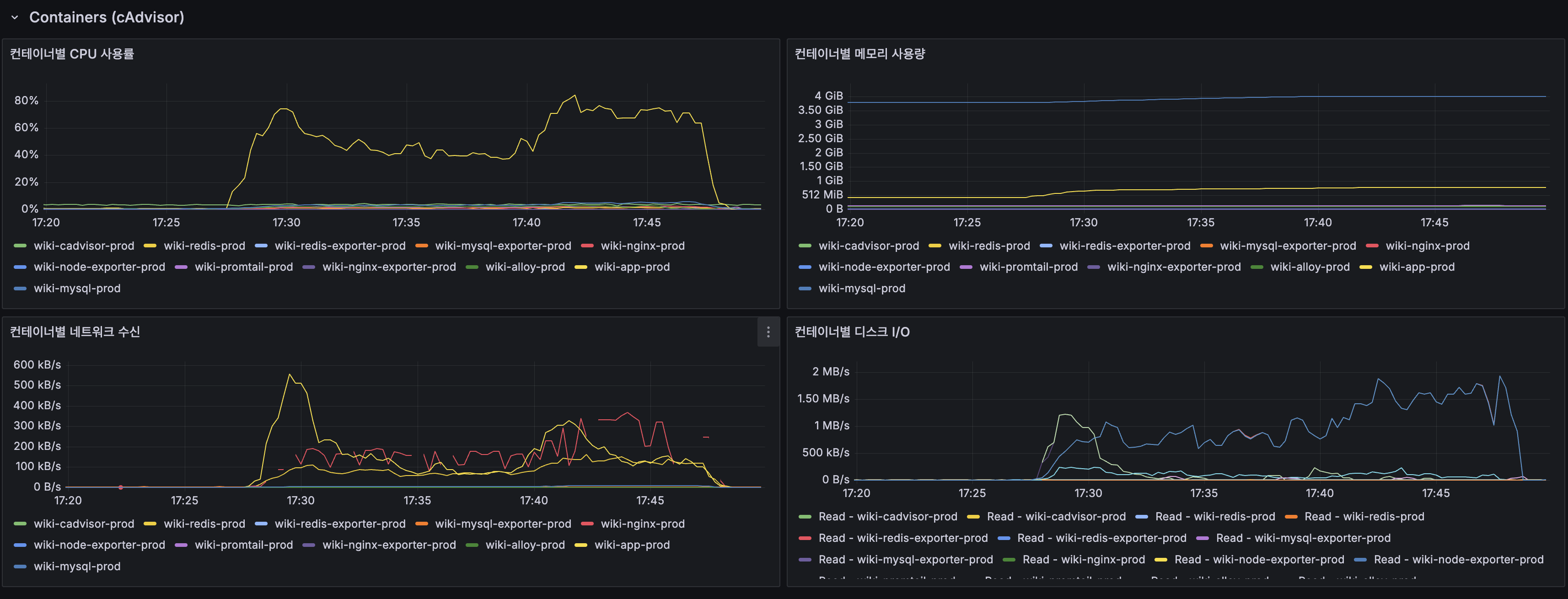
- wiki-app-prod CPU: 피크 ~70%로 @ApplicationModuleListener(~100%)보다 낮음. CDC가 Lucene 인덱싱을 분리
MySQL
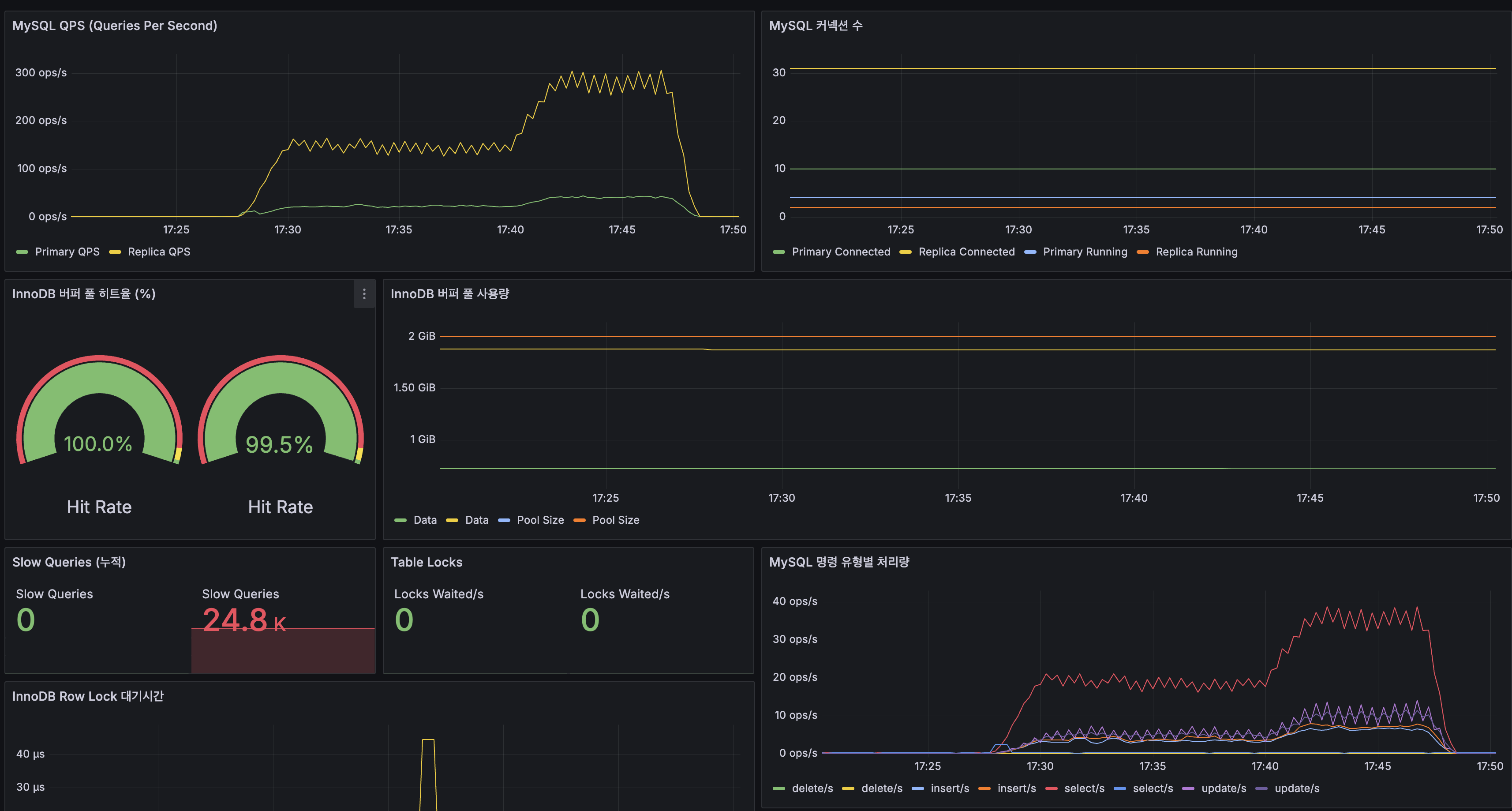
| 지표 | Primary | Replica |
|---|---|---|
| QPS (피크) | ~150 ops/s | ~300 ops/s |
| InnoDB 버퍼 풀 히트율 | 100.0% | 99.5% |
| Slow Queries (누적) | 0 | 24.8K |
MySQL Replication

- Replication Lag: 0~1초 사이 진동 (정상)
- CDC(Debezium)는 Primary의 binlog를 직접 읽으므로, Replication Lag과 무관하게 동작
Redis
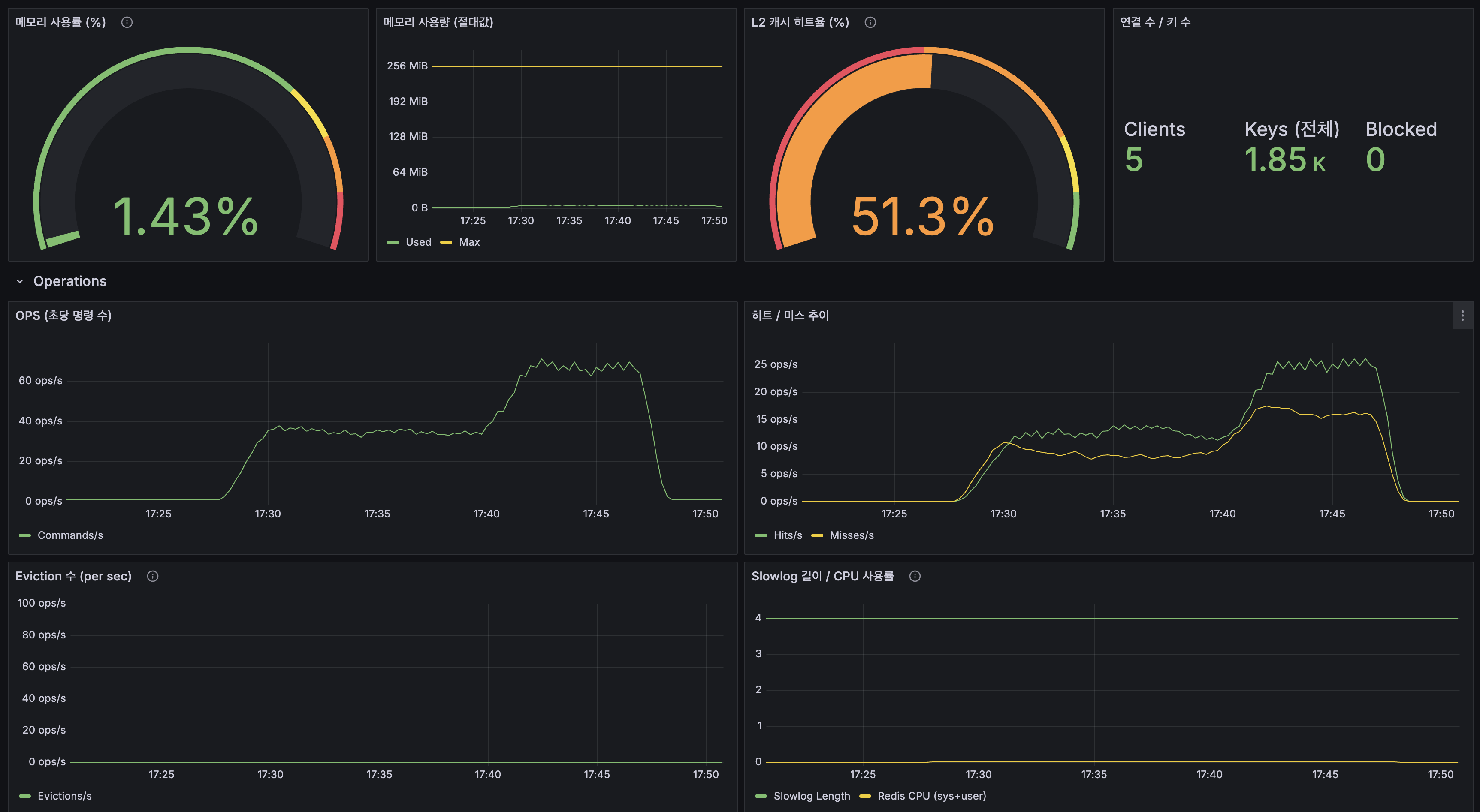
| 지표 | 값 |
|---|---|
| 메모리 사용률 | 1.43% |
| L2 캐시 히트율 | 51.3% |
| Keys (전체) | 1.85K |
| OPS (피크) | ~60 ops/s |
| Eviction | 0 |
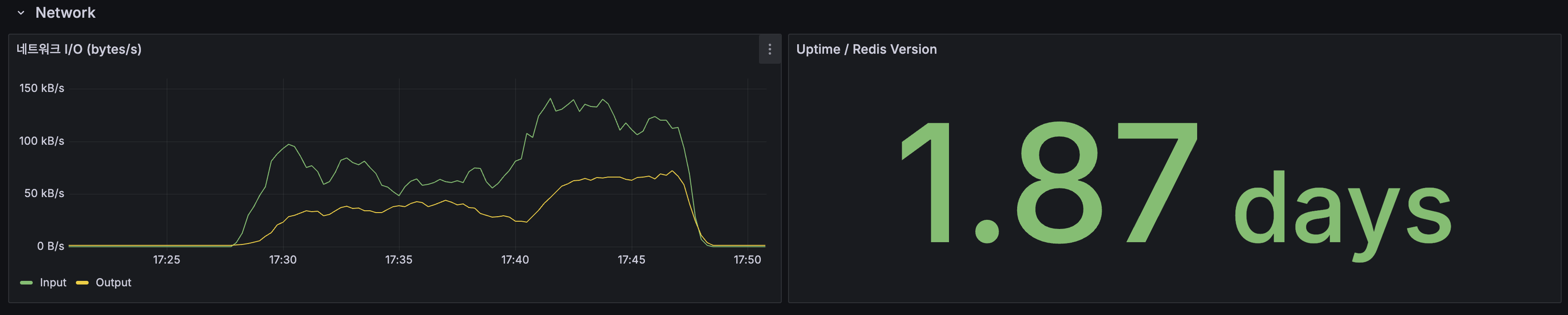
Application HTTP
- 두 인스턴스 모두 안정 구간에서 ~50ms 이하
- HTTP 에러율: 초기 시점 후 0%
HikariCP
- 커넥션 획득 시간: ~1ms 이하
- 프로세스 CPU: 피크 ~50% (@ApplicationModuleListener ~100% 대비 감소)
Tiered Cache
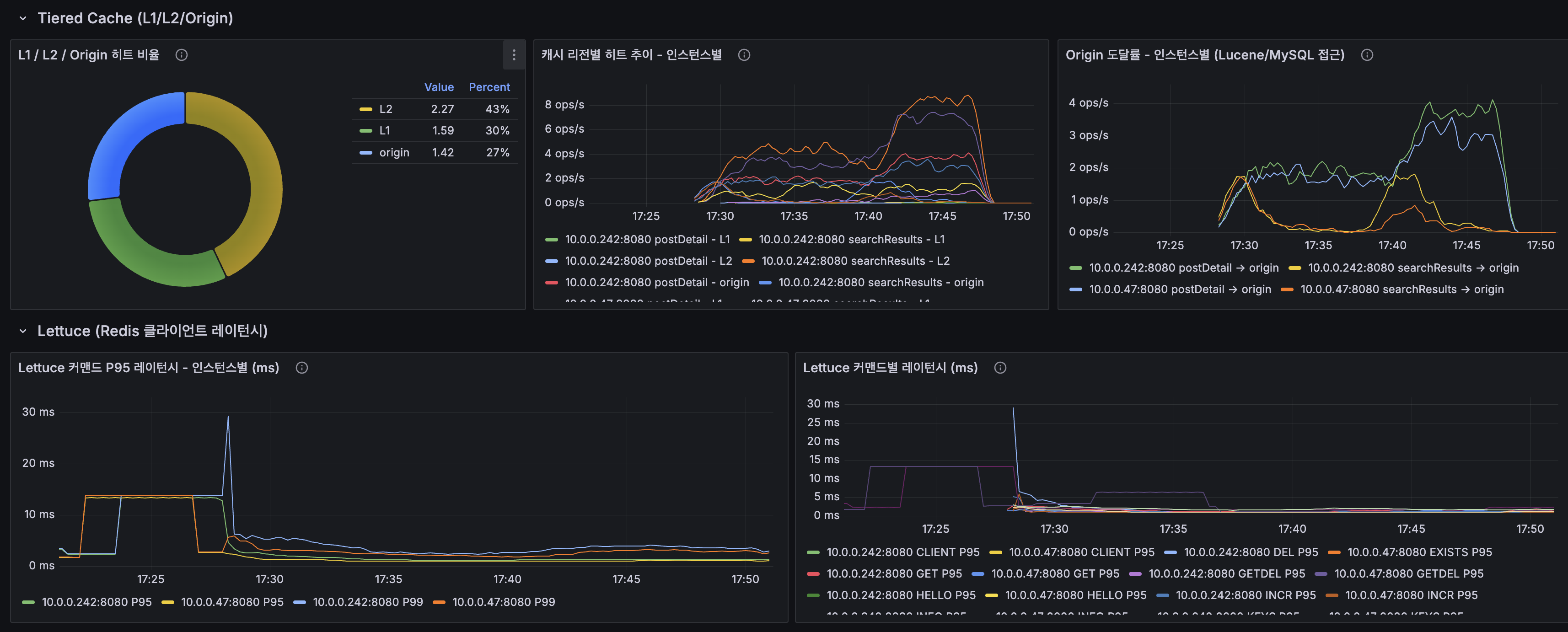
| 계층 | @ApplicationModuleListener | Kafka CDC | 변화 |
|---|---|---|---|
| L1 (Caffeine) | 36% | 30% | 소폭 하락 |
| L2 (Redis) | 43% | 43% | 동등 |
| Origin | 21% | 27% | 소폭 상승 |
L1+L2 합산: 79% → 73%. CDC Consumer가 캐시를 더 적극적으로 무효화하기 때문.
10. CDC 전환 최종 종합
| 항목 | 결과 |
|---|---|
| dual-write 원천 차단 | MySQL binlog → Debezium → Kafka 경로로 모든 DB 변경 캡처. 직접 SQL도 감지 |
| 이벤트 기반 디커플링 | PostService → Lucene/캐시 직접 호출 제거. OCP 준수 |
| 비동기 실행 | 쓰기 응답에서 Lucene/캐시 완전 분리. HTTP 스레드 점유 없음 |
| 성능 | 평균 35.6ms / P95 138ms / P99 294ms / 에러율 0%, 쓰기 33ms → 24ms 소폭 개선 |
| CDC 파이프라인 안정성 | Debezium CDC Lag ~0ms 수렴, Consumer Lag 0, Erroneous Events 0, Disconnects 0 |
| 이벤트 유실 방지 | Kafka 디스크 기반 보존 (7일). 앱 장애 시에도 이벤트 보존 |
| 이벤트 리플레이 | Kafka 토픽에서 리플레이하여 Lucene 인덱스 재구축 가능 |
| App CPU 감소 | Lucene 인덱싱이 CDC Consumer로 분리되어 App CPU 피크 100% → ~50% |
| Kafka 없는 환경 fallback | @ConditionalOnProperty로 @ApplicationModuleListener 자동 전환 |
| 모니터링 | kafka-exporter + Debezium JMX + kafka-ui + Grafana 대시보드 4개 자동 배포 |
| CI/CD 자동화 | GitHub Actions → Ansible → Docker Compose build + Debezium Connector 등록까지 완전 자동화 |
CDC E2E 지연 SLA와 대응 전략
| 지표 | 현재 값 | SLA 기준 | 초과 시 대응 |
|---|---|---|---|
| CDC E2E 지연 (생성 → 검색 가능) | 평균 2.1초 | 5초 | Debezium MilliSecondsBehindSource 알림 → Connector 재시작 |
| Debezium CDC Lag | ~0ms (정상), 피크 ~10초 | 60초 | 대량 DML 원인 확인 → off-peak 시간으로 배치 이동 |
| Kafka Consumer Lag | 0 | 100 messages | Consumer 스레드 수 확인, 파티션 추가 검토 |
주간 운영 체크리스트

운영 비용 총평: Kafka + Debezium의 주간 운영 시간은 약 30분~1시간이다. 대부분 Grafana 알림이 자동으로 커버하고, 수동 점검은 주 1회 5분 수준이다. 이 비용은 dual-write 불일치 발생 시 디버깅 + 전체 재인덱싱(28분) + 사용자 불만 대응에 소모되는 시간보다 확실히 작다.
부록: 검색엔진 자동완성 시스템 설계: 대규모 아키텍처 관점
이 부록은 시스템 디자인 인터뷰 대비 정리이며, wikiEngine의 현재 구현과는 규모가 다르다.
요구사항
| 항목 | 결정 사항 |
|---|---|
| 지원 언어 | 한국어, 영어 |
| 자동완성 제안 수 | 10개 |
| 제안 기준 | 최근 24시간 내 가장 인기 있는 검색어 기반 |
| 최대 접두사 길이 | 60자 |
| 규모 | 매일 수십억 개의 검색 쿼리 |
| 최대 응답 시간 | 240ms |
| 일관성 모델 | 최종 일관성(Eventual Consistency) |
읽기와 쓰기의 요구사항 분리
자동완성 시스템을 설계할 때 먼저 본 것은 “같은 검색 기능처럼 보여도 실제 요구사항은 다르다”는 점이었습니다. 자동완성 제안은 사용자가 입력할 때마다 즉시 반응해야 하므로 매우 빠른 읽기 경로가 중요하지만, 검색어 빈도를 누적하는 경로는 약간의 지연을 허용하더라도 안정적으로 기록되는 편이 더 중요합니다.
이 둘을 하나의 데이터 구조로 함께 처리하면, 빠르게 보여주는 일과 정확하게 누적하는 일이 서로를 방해할 수 있습니다. 그래서 조회 경로와 집계 경로를 분리해, 자동완성은 이미 준비된 결과를 즉시 반환하고, 검색어 집계는 뒤에서 안정적으로 누적·정리하는 구조가 더 적합하다고 판단했습니다.
Trie 자료구조: naive 구현의 한계와 프로덕션 최적화
자동완성을 생각하면 가장 먼저 떠오르는 건 Trie입니다. 소규모에서는 접두사 탐색에 자연스러운 선택이지만, 규모가 커질수록 모든 후보를 메모리에 유지하는 비용이 커지고, 특히 1~2글자 접두사에서는 분기 수가 급격히 늘어나 원하는 순서로 다시 정렬하는 과정까지 포함하면 응답 시간을 안정적으로 맞추기 어려워집니다.
그래서 이 프로젝트에서는 입력 시마다 후보를 다시 탐색하는 방식보다, 접두사마다 상위 추천 결과를 미리 정리해두고 요청이 오면 바로 반환하는 구조가 더 적합하다고 판단했습니다. 즉, 접두사마다 정렬된 추천 결과를 미리 대응시켜 두는 단순한 조회 구조로 바꾼 것입니다. 이 방식은 조회 경로를 예측 가능하게 만들고, 분산 환경에서도 같은 기준의 추천 결과를 일관되게 제공하기 쉽다는 장점이 있습니다.
물론 Trie 계열 자체가 항상 부적합한 것은 아닙니다. 규모가 큰 서비스는 Trie 변형이나 FST처럼 메모리와 탐색 비용을 줄인 자료구조를 사용하기도 합니다. 다만 이 글에서 강조하고 싶은 건 “어떤 자료구조가 더 멋진가”보다, 요구사항과 운영 제약 안에서 어떤 조회 방식이 더 단순하고 안정적인가를 먼저 판단했다는 점입니다.
데이터 처리 파이프라인: MapReduce 패턴과 현대 구현
자동완성 결과는 검색처럼 매 요청마다 즉시 다시 계산해야 하는 기능은 아니라고 봤습니다. 최신 결과가 약간 늦게 반영되어도 괜찮다는 전제가 있었기 때문에, 모든 입력을 실시간으로 처리하는 복잡한 구조보다 일정 주기로 모아 집계하는 방식이 더 적합했습니다.
그래서 사용자가 입력한 검색어는 먼저 모아두고, 일정 주기마다 최근 데이터를 기준으로 접두사별 상위 추천 결과를 다시 계산하는 흐름으로 설계했습니다. 어떤 검색어가 많이 입력되면 그 검색어는 자신의 모든 접두사 후보에 반영되고, 각 접두사마다 상위 추천 결과만 남기는 식입니다. 이렇게 하면 조회 시점에는 이미 정렬이 끝난 결과를 바로 반환할 수 있고, 무거운 계산은 뒤에서 주기적으로 처리할 수 있습니다.
여기서 말하는 MapReduce는 특정 프레임워크 이름이 아니라, “데이터를 나누고, 같은 키끼리 모으고, 다시 집계한다”는 사고 패턴에 가깝습니다. 핵심은 대규모 처리 기술을 과시하는 것이 아니라, 요구사항이 허용하는 지연 범위 안에서 가장 단순하고 운영 가능한 흐름을 선택했다는 점입니다.
데이터 동기화: 변경 전파 구조

자동완성 데이터의 원천은 사용자의 검색 행동이고, 게시글 데이터의 원천은 서비스의 저장소입니다. 이 둘은 성격이 다르기 때문에 같은 방식으로 다루지 않았습니다. 검색어 순위는 집계 흐름으로 만들고, 게시글 제목 변경처럼 자동완성 결과 자체에 영향을 주는 데이터는 변경 사항이 뒤에서 자동으로 전파되도록 설계했습니다.
즉, “사용자 행동은 모아서 다시 계산하고, 데이터 상태 변경은 필요한 곳에 자동 반영한다”는 식으로 경로를 나눈 것입니다. 이렇게 해야 전체를 실시간으로 처리하지 않아도 필요한 최신성은 유지하면서 복잡도를 통제할 수 있습니다.
설계 하이라이트
| # | 설계 포인트 | wikiEngine 적용 |
|---|---|---|
| 1 | Trie → flat KV 진화 | Trie 자동완성에서 소규모 Trie 구현 → Redis L2에서 flat KV O(1) 전환. 프로덕션 시스템(Bing, Google)은 Trie 변형(FST, PruningRadixTrie) + flat KV 서빙의 2단계 구조 |
| 2 | 읽기/쓰기 분리 | 조회는 즉시 반환에, 집계는 주기적 정리에 맞춰 서로 다른 경로로 분리 |
| 3 | 공유 조회 구조 | 접두사별 추천 결과를 여러 인스턴스가 같은 기준으로 조회하도록 구성 |
| 4 | 주기적 집계 파이프라인 | 검색어를 모아 접두사별 상위 추천 결과를 다시 계산하는 흐름으로 단순화 |
| 5 | 변경 전파 구조 | 데이터 저장소 변경이 검색 인덱스와 캐시에 뒤에서 자연스럽게 반영되도록 구성 |
후속 개선: CDC 에러 핸들링 강화
DLQ(Dead Letter Topic) + 재시도 로직
| 항목 | 변경 전 | 변경 후 |
|---|---|---|
| 예외 처리 | catch(Exception) { log.error(); }: 예외 삼킴, 메시지 유실 | throw new RuntimeException(e): Spring Kafka DefaultErrorHandler가 재시도 |
| 재시도 | 없음 | 1초 간격 9회 = 총 10회 시도 (FixedBackOff) |
| 실패 후 처리 | 로그만 | DLT({토픽}.DLT)로 격리, 사후 분석/재처리 가능 |
| offset 커밋 | enable-auto-commit 미명시 | enable-auto-commit=false + ack-mode=RECORD 명시 |
왜 예외를 throw해야 하는가: Spring Kafka의 DefaultErrorHandler는 리스너가 예외를 throw할 때만 동작합니다. catch에서 예외를 삼키면 Kafka 입장에서 “정상 처리”로 간주되어 offset이 커밋되고, 재시도도 DLQ 격리도 일어나지 않습니다. Confluent 공식 문서에서도 DLQ를 “운영 관찰성 시그널”로 보고, DLT에 메시지가 쌓이면 알림을 보내 원인을 분석하는 패턴을 권장합니다.
AckMode.RECORD를 명시한 이유: enable-auto-commit=true(기본값)면 poll() 주기마다 자동 커밋되어, 처리 실패한 메시지도 커밋될 수 있습니다. enable-auto-commit=false + ack-mode=RECORD로 설정하면 각 레코드 처리 완료 후에만 offset이 커밋되어, 실패 시 해당 레코드부터 재처리됩니다.
관련 파일:
CdcErrorHandlerConfig.java:DefaultErrorHandler+DeadLetterPublishingRecovererDebeziumCdcConsumer.java: catch에서 throw 추가application.yml:enable-auto-commit: false,ack-mode: RECORD
Previous Post
This post follows View Count Redis INCR + Write-Behind Batch Flush, where DB UPDATE conflicts in GET requests were resolved with Redis INCR. This post covers the evolution from PostService’s dual-write architecture to event-driven synchronization and ultimately Debezium + Kafka CDC for capturing all database changes.

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.