Nori 형태소 분석기 Stop Filter 문제: "안녕" 0건과 "안녕하세" 노이즈 해결
목차
이전 글
AI 검색 요약 — RAG 파이프라인 + SSE 스트리밍 + 비용 모니터링에서 Lucene BM25 검색 결과를 LLM 컨텍스트에 주입하는 RAG 파이프라인을 구축했다. 검색 기능이 모두 갖춰진 상태에서, 특정 키워드가 검색되지 않거나 엉뚱한 결과가 나오는 문제를 발견했다.
1. 정상 상태
wikiEngine은 Lucene 10.3.2 + Nori 한국어 형태소 분석기 기반의 검색 시스템이다.
| 항목 | 상세 |
|---|---|
| 데이터 규모 | 1,215만 건 (위키 845만 + 뉴스 16만 + 웹 354만) |
| 인덱스 크기 | 약 36GB (MMapDirectory) |
| 분석기 | Nori KoreanAnalyzer + UserDictionary 158K 엔트리 |
| 랭킹 | BM25 + viewCount/likeCount saturation + recency decay |
| 서버 | ARM 2코어 / 12GB RAM × 2대 (Primary + Replica) |
“삼성전자”, “인공지능”, “자바스크립트” 등 일반 명사 검색은 정상 동작한다.
2. 문제: 두 가지 증상
증상 1: “안녕” 검색 시 0건
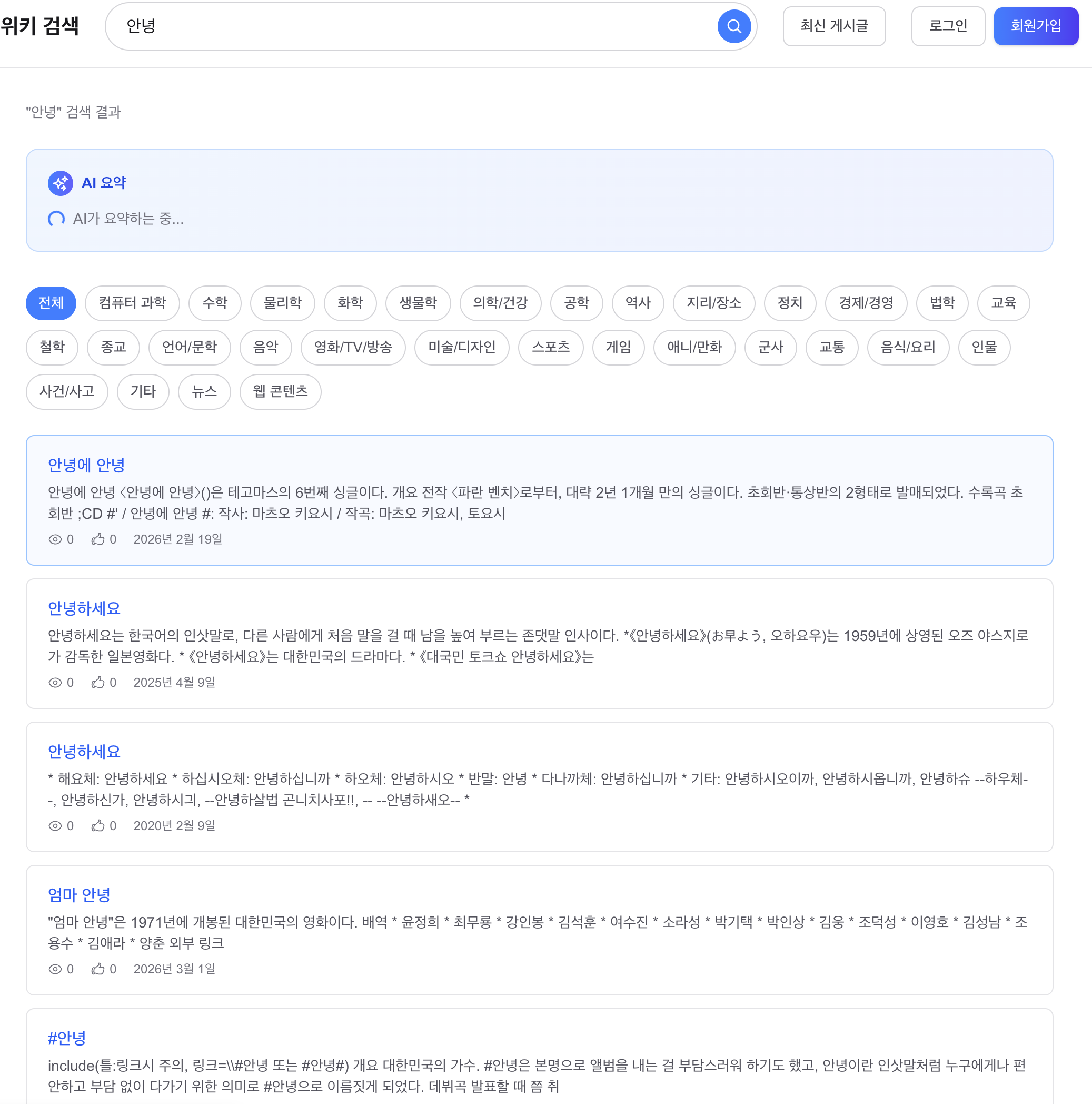
“안녕하세요”를 검색하면 결과가 나오지만, “안녕”만 입력하면 결과가 없다.
증상 2: “안녕하세” 검색 시 “하세” 문서만 나옴
“안녕하세”를 검색하면 “안녕하세요” 관련 문서가 아니라 “하세”(일본 성씨) 관련 문서가 최상위에 노출된다.
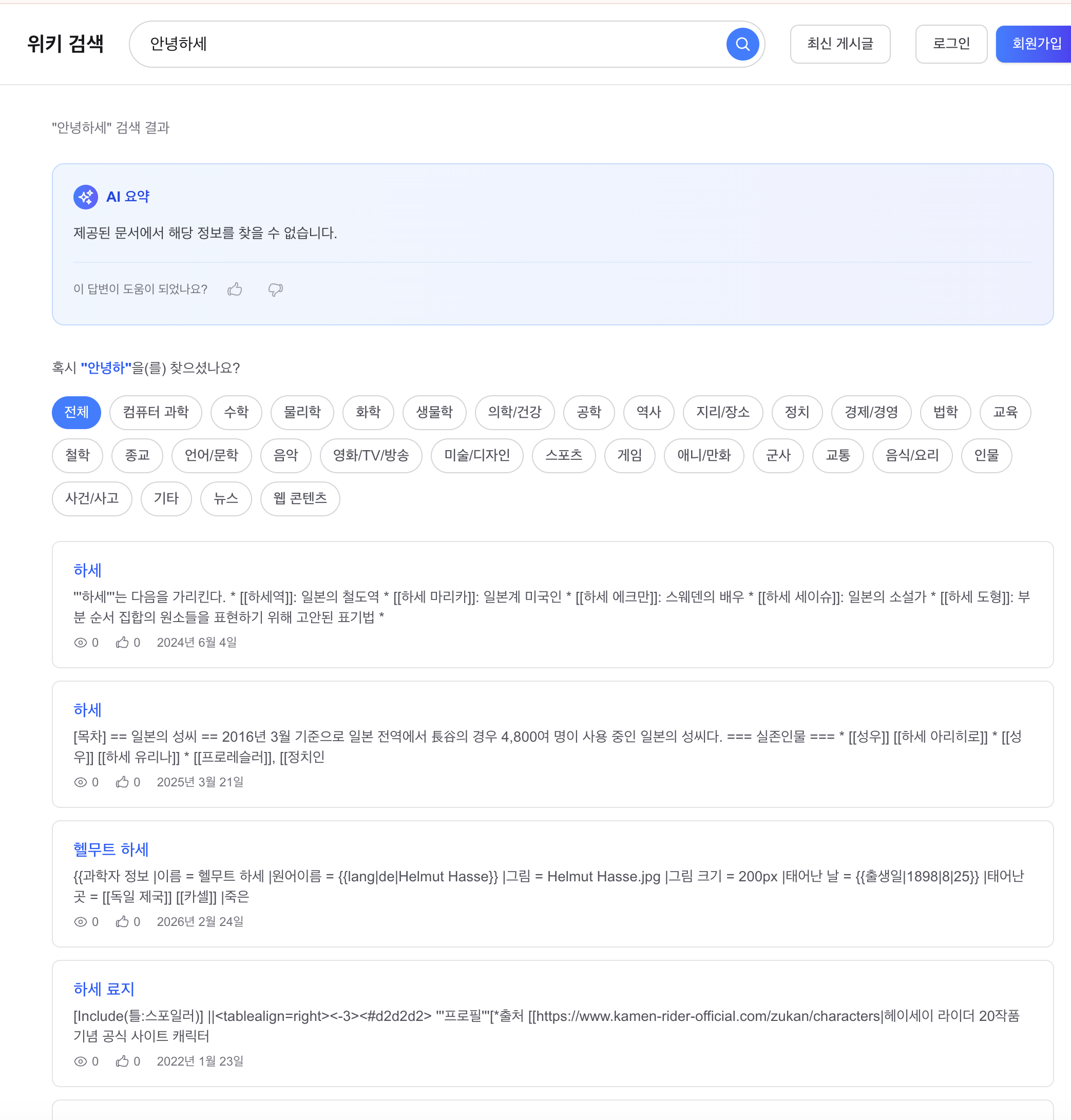
Did-you-mean은 “안녕하”를 제안하지만, 검색 결과는 “하세”, “하세쿠라”, “하세 히로시” 등 관련 없는 문서가 점령한다.
자동완성도 이상
| 입력 | 자동완성 결과 | 비고 |
|---|---|---|
| ”안” | 안경, 안녕, 안녕하 | 정상 |
| ”안녕” | 없음 | 비정상 |
| ”안녕하세요” | 다수 결과 | 정상 |
| ”황치열” | 없음 | 비정상 |
3. 원인 분석
증상 1 원인: IC(감탄사) Stop Filter
Nori의 DEFAULT_STOP_TAGS에 IC(감탄사)가 포함되어 있다. 같은 “안녕”이라도 문맥에 따라 품사 태깅이 달라진다:
"안녕하세요" → Nori: '안녕'(NNG, 명사) + '하'(XSV) + '세요'(EF) → Stop Filter: '안녕' 생존 ✓ → 인덱스: ['안녕']
"안녕" → Nori: '안녕'(IC, 감탄사) → Stop Filter: '안녕' 제거 ✗ → 쿼리: [] (빈 쿼리 → 0건)핵심: “안녕”이 단독으로 쓰이면 감탄사(IC)로 태깅되어 필터링된다. 하지만 인덱스에는 “안녕하세요”의 일부로 ‘안녕’(NNG)이 저장되어 있다. 인덱싱은 됐는데 검색이 안 되는 비대칭 문제.
증상 2 원인: 불완전 입력의 비표준적 토큰화
“안녕하세”는 Nori 사전에 없는 미완성 형태다. Nori는 이를 비표준적으로 분리한다:
"안녕하세" → Nori: '안녕'(NNG) + '하세'(???) → 쿼리: ['안녕', '하세'] (OR)OR 기반 쿼리에서 “하세”라는 제목의 문서(일본 성씨)가 title^3 boost로 완전 일치하여 BM25 점수가 극도로 높다. 반면 “안녕하세요” 문서의 인덱스 토큰은 ‘안녕’ 하나뿐이라 ‘하세’ 토큰과 매칭되지 않는다.
| 문서 | 인덱스 토큰 | 쿼리 ‘안녕’ 매칭 | 쿼리 ‘하세’ 매칭 | BM25 |
|---|---|---|---|---|
| ”하세” (일본 성씨) | [‘하세’] | X | O (title 완전 일치) | 매우 높음 |
| ”안녕하세요” | [‘안녕’] | O (부분 매칭) | X | 낮음 |
자동완성 원인: title_jamo PrefixQuery의 한계
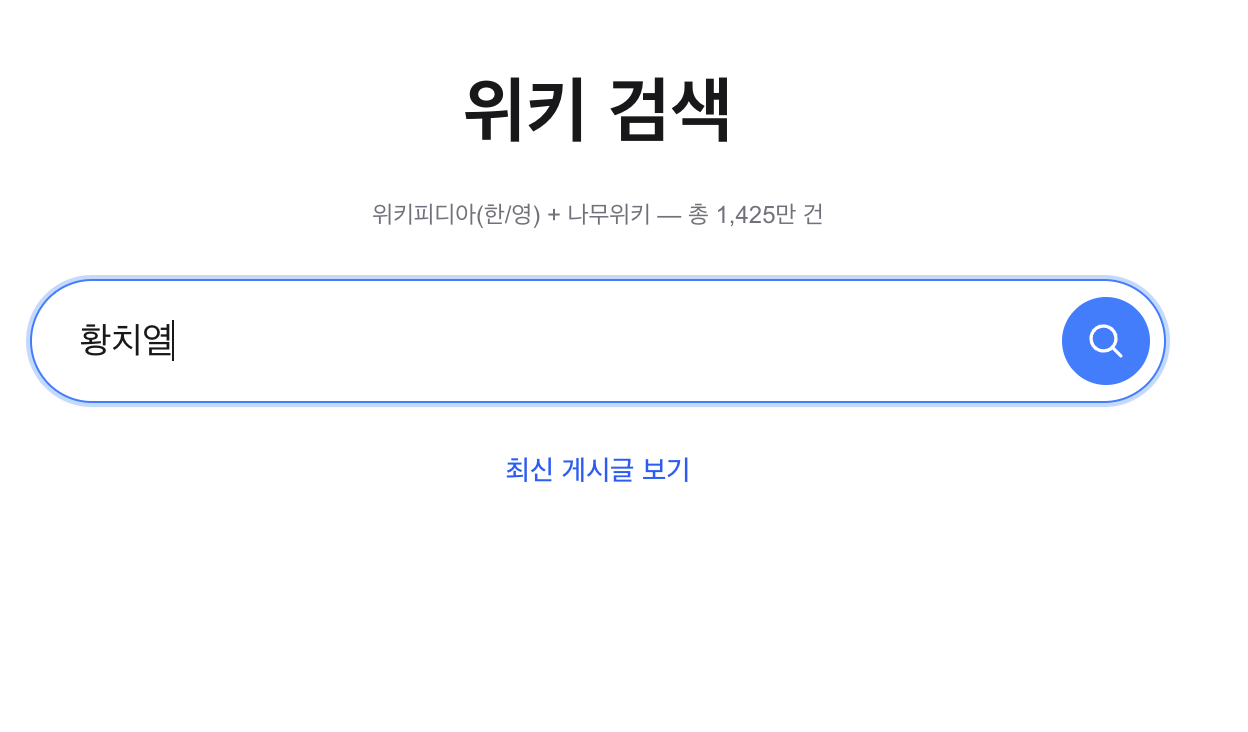
Lucene fallback에서 title_jamo 필드의 PrefixQuery를 사용하는데, 12M건의 자모 분해 term이 너무 많아 완성 한글(“황치열”) 검색이 실패한다.
4. 선택지
두 증상이 원인이 다르므로 각각 해결책이 필요하다.
증상 1 해결: IC 제거
| 선택지 | 장점 | 단점 |
|---|---|---|
| A. Stop Tags에서 IC 제거 | 근본 해결, 1줄 수정 | IC 전체가 인덱싱됨 |
| 사전에 ‘안녕’ NNG 등록 | IC 유지 | 모든 감탄사를 수동 등록 불가 |
IC를 제거하면 감탄사가 인덱싱되어 인덱스가 약간 커지지만, 한국어에서 감탄사 비중은 미미하다.
증상 2 해결: n-gram 보완
| 선택지 | ”안녕하세” → “안녕하세요” | 기존 검색 영향 | 비용 |
|---|---|---|---|
| B. title_ngram + dis_max | O | 없음 | +8% 인덱스 |
| AND 연산자 전환 | X (recall 감소) | 심각 | 없음 |
| PhraseQuery boost | X (토큰 1개라 구절 불가) | 없음 | 없음 |
| 현상 유지 + Did-you-mean | X | 없음 | 없음 |
title 필드에만 2-3gram 분석기를 추가하고 dis_max로 결합하면, 형태소 분석이 실패해도 n-gram이 문자 시퀀스 매칭으로 관련 문서를 올린다. 콘텐츠 전체를 n-gram으로 하면 토큰 6.5배 폭발이 발생하지만, title만 적용하면 36GB → 39GB(+8%)로 최소화된다.
보험: 토큰 전멸 폴백
| 선택지 | 설명 |
|---|---|
| C. PrefixQuery 폴백 | Nori 분석 후 토큰이 0개면 원본 키워드로 PrefixQuery 실행 |
A와 B로 커버되지 않는 미지의 엣지 케이스에 대한 보험이다.
5. 구현: A + B + C
세 레이어가 각각 다른 실패 모드를 커버한다:
- A(IC 제거): 감탄사가 필터링되는 문제
- B(dis_max): 형태소 분석이 불완전한 입력을 잘못 토큰화하는 문제
- C(PrefixQuery): 토큰이 전부 사라지는 미지의 케이스
A. Stop Tags 커스터마이징
private Analyzer createNoriAnalyzer() { UserDictionary userDict = loadUserDictionary(); Set<POS.Tag> stopTags = EnumSet.copyOf( KoreanPartOfSpeechStopFilter.DEFAULT_STOP_TAGS); stopTags.remove(POS.Tag.IC); // IC(감탄사) 제거 return new KoreanAnalyzer(userDict, KoreanTokenizer.DEFAULT_DECOMPOUND, stopTags, false);}B. title_ngram + dis_max
PerFieldAnalyzerWrapper:
@BeanAnalyzer luceneAnalyzer() { Analyzer noriAnalyzer = createNoriAnalyzer(); Analyzer ngramAnalyzer = createNgramAnalyzer(); // 2-3gram return new PerFieldAnalyzerWrapper(noriAnalyzer, Map.of("title_ngram", ngramAnalyzer));}인덱싱 시 title_ngram 필드 추가:
doc.add(new TextField("title_ngram", post.getTitle(), Field.Store.NO));dis_max 쿼리:
new DisjunctionMaxQuery( List.of( textQuery, // Nori 형태소 분석 new BoostQuery(ngramQuery, 2.0f) // 2-3gram ), 0.1f // tie_breaker);dis_max 튜닝 과정
처음부터 이 구조가 나온 게 아니라 시행착오가 있었다.
1차, MUST + SHOULD 구조:
textQuery(MUST) + ngramQuery(SHOULD)textQuery가 MUST이므로 형태소 분석 결과가 검색을 지배한다. “안녕하세”에서 ‘하세’ 토큰이 title^3 boost로 “하세” 문서를 상위에 올리고, n-gram은 SHOULD라서 순위를 뒤집지 못했다.
2차, dis_max로 전환하고 textQuery에 3.0 boost:
dis_max([BoostQuery(textQuery, 3.0), ngramQuery], tie_breaker=0.1)textQuery 3.0 × title 내부 3.0 = 9배 부스트. “하세” 완전 일치가 n-gram을 압도해서 결과가 동일했다.
3차, dis_max에 boost 없이:
title^3 내부 boost만으로도 “하세” title 완전 일치의 BM25 점수가 너무 높아 n-gram 부분 매칭으로는 부족했다.
최종, ngramQuery에 2.0 boost:
n-gram에 2.0 boost를 줘서 title^3과 경쟁할 수 있게 했다.
| textQuery 점수 | ngramQuery 점수 | dis_max 결과 | |
|---|---|---|---|
| ”하세” 문서 | 높음 (title 완전일치) | 낮음 | textQuery 선택 |
| ”안녕하세요” 문서 | 낮음 (‘안녕’만 매칭) | 높음 (4글자 n-gram × 2.0) | ngramQuery 선택 → 상위 |
C. 토큰 전멸 PrefixQuery 폴백
if (allTokens.isEmpty()) { return new PrefixQuery(new Term("title", queryStr.toLowerCase()));}D. 자동완성 title_raw fallback
기존 Lucene fallback이 title_jamo PrefixQuery만 사용해서 완성 한글 검색(“황치열”)이 실패했다. 완성 한글과 자모 입력을 분리했다:
if (JamoDecomposer.isCompleteHangul(prefix)) { // "황치열" → title_raw PrefixQuery return luceneSearchService.autocompleteFallback(prefix, "title_raw");} else { // "ㅎㅊㅇ" → title_jamo PrefixQuery return luceneSearchService.autocompleteFallback( JamoDecomposer.decompose(prefix), "title_jamo");}title_raw는 분석기를 타지 않는 StringField로 이미 인덱싱되어 있어 추가 비용이 없다.
6. 검증: Before / After
Before
“안녕하세” 검색, “하세” 문서만:
“황치열” 자동완성, 빈 결과:
After
“안녕” 검색, 정상 반환 + AI 요약:
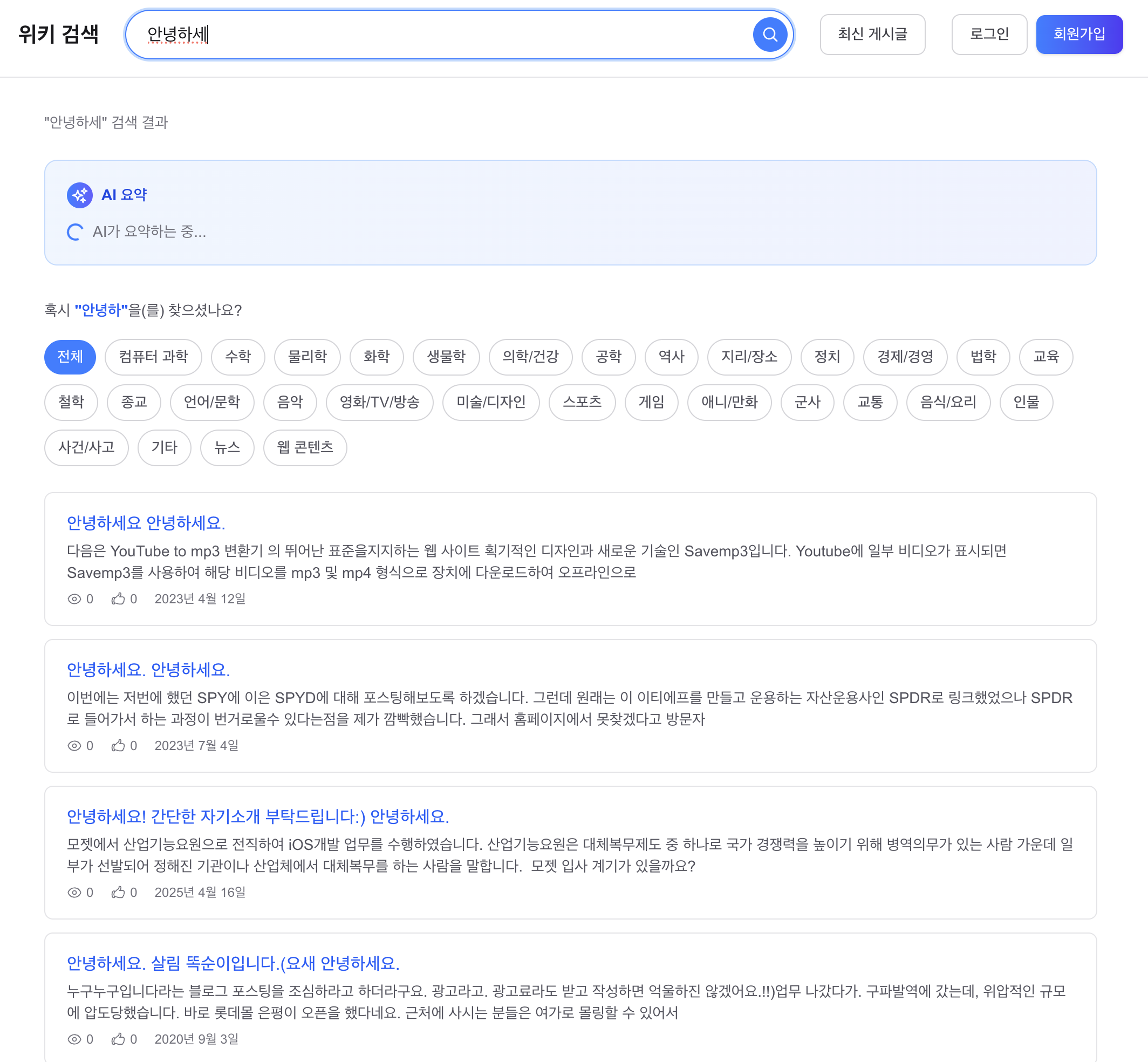
“안녕하세” 검색, “안녕하세요” 관련 문서 상위:
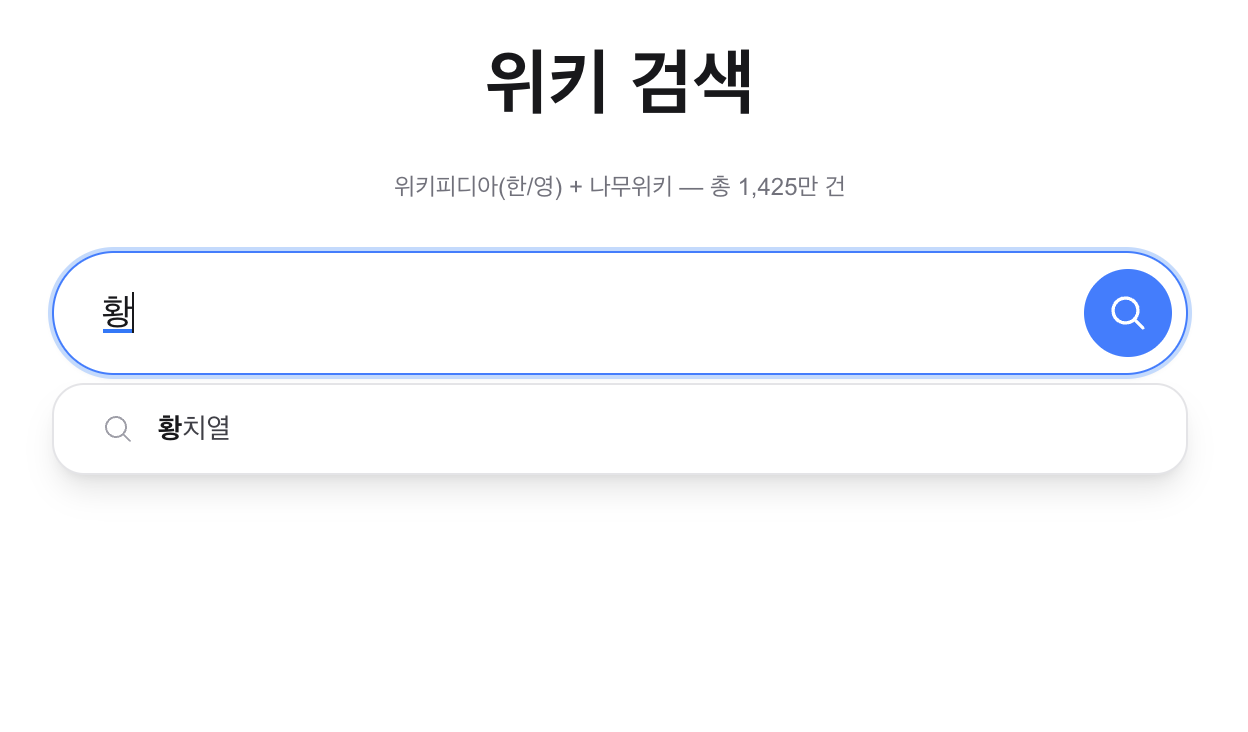
“황” 자동완성, “황치열” 정상:
개선 요약
| 항목 | Before | After |
|---|---|---|
| ”안녕” 검색 | 0건 | 정상 반환 |
| ”안녕하세” 검색 | ”하세” 문서만 | ”안녕하세요” 문서 상위 |
| ”황치열” 자동완성 | 빈 결과 | 정상 제안 |
| 인덱스 크기 | 36GB | 39GB (+8%) |
| 재색인 | - | 필수 (12M건, 69분) |
수정 파일: LuceneConfig.java (IC 제거 + PerFieldAnalyzerWrapper), LuceneIndexService.java (title_ngram 필드), LuceneSearchService.java (dis_max 쿼리 + PrefixQuery 폴백), RedisAutocompleteService.java (title_raw fallback).
7. Nori의 구조적 한계
이번에 발견한 문제들은 Nori에 국한되지 않는, 사전 기반 형태소 분석기의 공통 한계다.
| 한계 | 설명 |
|---|---|
| IC 품사 과필터링 | stop tags에 IC가 포함되어 standalone 감탄사가 검색 불가 |
| 불완전 입력 | 미완성 활용형(“안녕하세”)을 비표준적으로 토큰화 |
| OOV(미등록어) | 신조어, 고유명사를 처리하지 못함 |
| 조사/어미 세분화 부족 | ”J”, “E” 대분류만 존재하여 특정 조사/어미만 제거 불가 |
이 프로젝트에서는 Nori의 성능(3,000+ docs/sec)과 메모리 효율이 12M 규모에 적합하므로 Nori를 유지하되, IC 제거 + title_ngram dis_max + PrefixQuery 폴백 + 자동완성 title_raw fallback으로 한계를 보완하는 접근을 선택했다.
출처
- Lucene 10.3.2 — KoreanPartOfSpeechStopFilter.java
- Elastic Blog — Nori: The Official Elasticsearch Plugin for Korean
- Elastic Blog — How to Search CJK Text Part 2: Multi-fields
- Sease — When and How to Use N-grams in Elasticsearch
Previous
In AI Search Summary — RAG Pipeline + SSE Streaming + Cost Monitoring we built a RAG pipeline that injects Lucene BM25 results into LLM context. With search functionality complete, we discovered an issue where certain keywords either return nothing or surface the wrong results.
1. Steady State
WikiEngine is a search system on Lucene 10.3.2 + the Nori Korean morphological analyzer.
| Item | Detail |
|---|---|
| Data scale | 12.15M docs (8.45M wiki + 160K news + 3.54M web) |
| Index size | ~36GB (MMapDirectory) |
| Analyzer | Nori KoreanAnalyzer + UserDictionary with 158K entries |
| Ranking | BM25 + viewCount/likeCount saturation + recency decay |
| Servers | ARM 2-core / 12GB RAM × 2 (Primary + Replica) |
Common-noun searches like “삼성전자”, “인공지능”, “자바스크립트” work fine.
2. The Problem — Two Symptoms
Symptom 1: searching “안녕” returns 0 results
Searching “안녕하세요” returns results, but typing just “안녕” returns nothing.
Symptom 2: searching “안녕하세” surfaces only “하세” docs
Searching “안녕하세” surfaces docs about “하세” (a Japanese surname) on top instead of docs about “안녕하세요”.
Did-you-mean suggests “안녕하” but the actual results are dominated by unrelated docs like “하세”, “하세쿠라”, “하세 히로시”.
Autocomplete is broken too
| Input | Autocomplete | Note |
|---|---|---|
| ”안” | 안경, 안녕, 안녕하 | OK |
| ”안녕” | none | broken |
| ”안녕하세요” | many results | OK |
| ”황치열” | none | broken |
3. Root Cause
Symptom 1 — IC (Interjection) Stop Filter
Nori’s DEFAULT_STOP_TAGS includes IC (interjection). The same string “안녕” gets a different POS tag depending on context:
"안녕하세요" → Nori: '안녕'(NNG, noun) + '하'(XSV) + '세요'(EF) → Stop filter: '안녕' kept → Index: ['안녕']
"안녕" → Nori: '안녕'(IC, interjection) → Stop filter: '안녕' removed → Query: [] (empty query → 0 results)The crux: standalone “안녕” gets tagged as an interjection (IC) and gets filtered out. But the index contains ‘안녕’ (NNG) as part of “안녕하세요”. Indexed but not searchable — an asymmetry problem.
Symptom 2 — Non-standard tokenization of incomplete input
“안녕하세” is an unfinished form not in Nori’s dictionary, and Nori splits it non-standardly:
"안녕하세" → Nori: '안녕'(NNG) + '하세'(???) → Query: ['안녕', '하세'] (OR)In the OR query, a doc whose title is “하세” (Japanese surname) gets a perfect title match with title^3 boost, so its BM25 score is extremely high. Meanwhile, the “안녕하세요” doc only has ‘안녕’ indexed and does not match the ‘하세’ token at all.
| Doc | Indexed tokens | Match ‘안녕’ | Match ‘하세’ | BM25 |
|---|---|---|---|---|
| ”하세” (Japanese surname) | [‘하세’] | no | yes (title exact) | very high |
| ”안녕하세요” | [‘안녕’] | yes (partial) | no | low |
Autocomplete cause — limits of title_jamo PrefixQuery
The Lucene fallback used PrefixQuery on the title_jamo field, but with 12M docs the jamo-decomposed term space is too large, so completed-Hangul searches like “황치열” fail.
4. Options
The two symptoms have different root causes, so each needs its own fix.
Symptom 1 fix — remove IC
| Option | Pro | Con |
|---|---|---|
| A. Remove IC from Stop Tags | root-cause fix, 1-line change | all interjections get indexed |
| Add ‘안녕’ as NNG to user dictionary | keep IC | cannot manually register every interjection |
Removing IC bloats the index slightly, but interjections are a tiny fraction of Korean text.
Symptom 2 fix — n-gram supplement
| Option | ”안녕하세” → “안녕하세요” | Impact on existing search | Cost |
|---|---|---|---|
| B. title_ngram + dis_max | yes | none | +8% index |
| Switch to AND operator | no (recall drops) | severe | none |
| PhraseQuery boost | no (only 1 token, no phrase possible) | none | none |
| Status quo + Did-you-mean | no | none | none |
Adding a 2-3gram analyzer to the title field only and combining via dis_max means even when morphological analysis fails, n-gram raises related docs through character-sequence matching. Applying n-gram to all content would explode tokens 6.5×, but title-only keeps it at 36GB → 39GB (+8%).
Insurance — token-wipeout fallback
| Option | Description |
|---|---|
| C. PrefixQuery fallback | If Nori produces 0 tokens after analysis, fall back to PrefixQuery on the raw keyword |
This is insurance for edge cases not covered by A and B.
5. Implementation — A + B + C
The three layers cover three different failure modes:
- A (remove IC): interjection getting filtered
- B (dis_max): morphological analysis mis-tokenizing incomplete input
- C (PrefixQuery): unknown cases where all tokens disappear
A. Customize Stop Tags
private Analyzer createNoriAnalyzer() { UserDictionary userDict = loadUserDictionary(); Set<POS.Tag> stopTags = EnumSet.copyOf( KoreanPartOfSpeechStopFilter.DEFAULT_STOP_TAGS); stopTags.remove(POS.Tag.IC); // remove IC (interjection) return new KoreanAnalyzer(userDict, KoreanTokenizer.DEFAULT_DECOMPOUND, stopTags, false);}B. title_ngram + dis_max
PerFieldAnalyzerWrapper:
@BeanAnalyzer luceneAnalyzer() { Analyzer noriAnalyzer = createNoriAnalyzer(); Analyzer ngramAnalyzer = createNgramAnalyzer(); // 2-3gram return new PerFieldAnalyzerWrapper(noriAnalyzer, Map.of("title_ngram", ngramAnalyzer));}Add title_ngram field at indexing time:
doc.add(new TextField("title_ngram", post.getTitle(), Field.Store.NO));dis_max query:
new DisjunctionMaxQuery( List.of( textQuery, // Nori analysis new BoostQuery(ngramQuery, 2.0f) // 2-3gram ), 0.1f // tie_breaker);dis_max tuning steps
This shape did not appear from the start — there was trial and error.
Pass 1 — MUST + SHOULD:
textQuery(MUST) + ngramQuery(SHOULD)Since textQuery is MUST, morphological analysis dominates. In “안녕하세” the ‘하세’ token raised the “하세” doc to the top via title^3, and n-gram being SHOULD could not flip the order.
Pass 2 — dis_max with 3.0 boost on textQuery:
dis_max([BoostQuery(textQuery, 3.0), ngramQuery], tie_breaker=0.1)textQuery 3.0 × inner title 3.0 = 9× boost. The exact “하세” match still dominated n-gram. Same result.
Pass 3 — dis_max, no boost:
Even with only the inner title^3 boost, the BM25 for the “하세” exact title match was so high that n-gram partial matching was not enough.
Final — 2.0 boost on ngramQuery:
Boosting n-gram by 2.0 lets it compete with title^3.
| textQuery score | ngramQuery score | dis_max picks | |
|---|---|---|---|
| ”하세” doc | high (title exact) | low | textQuery |
| ”안녕하세요” doc | low (only ‘안녕’ matches) | high (4-char n-gram × 2.0) | ngramQuery → top |
C. Token-wipeout PrefixQuery fallback
if (allTokens.isEmpty()) { return new PrefixQuery(new Term("title", queryStr.toLowerCase()));}D. Autocomplete title_raw fallback
The existing Lucene fallback used only title_jamo PrefixQuery, so completed-Hangul queries like “황치열” failed. We split completed-Hangul vs jamo input:
if (JamoDecomposer.isCompleteHangul(prefix)) { // "황치열" → title_raw PrefixQuery return luceneSearchService.autocompleteFallback(prefix, "title_raw");} else { // "ㅎㅊㅇ" → title_jamo PrefixQuery return luceneSearchService.autocompleteFallback( JamoDecomposer.decompose(prefix), "title_jamo");}title_raw is a StringField indexed without analyzer, already in the index — no extra cost.
6. Verification — Before / After
Before
“안녕하세” — only “하세” docs:
“황치열” autocomplete — empty:
After
“안녕” — returns results + AI summary:
“안녕하세” — “안녕하세요” docs on top:
“황” autocomplete — “황치열” appears:
Improvement summary
| Item | Before | After |
|---|---|---|
| Search “안녕” | 0 | normal |
| Search “안녕하세” | only “하세” docs | ”안녕하세요” docs on top |
| Autocomplete “황치열” | empty | normal suggestions |
| Index size | 36GB | 39GB (+8%) |
| Reindex | - | required (12M docs, 69 min) |
Files modified: LuceneConfig.java (IC removal + PerFieldAnalyzerWrapper), LuceneIndexService.java (title_ngram field), LuceneSearchService.java (dis_max query + PrefixQuery fallback), RedisAutocompleteService.java (title_raw fallback).
7. Structural Limits of Nori
The issues found here are not Nori-specific — they are common limits of dictionary-based morphological analyzers.
| Limit | Description |
|---|---|
| IC over-filtering | IC is in stop tags, so standalone interjections are unsearchable |
| Incomplete input | inflectional fragments like “안녕하세” get tokenized non-standardly |
| OOV (out-of-vocab) | new coinages and proper nouns are not handled |
| Coarse particle/ending tags | only “J” and “E” supercategories — cannot remove specific particles/endings |
For this project, Nori’s throughput (3,000+ docs/sec) and memory efficiency suit the 12M scale, so we kept Nori and chose to patch its limits with IC removal + title_ngram dis_max + PrefixQuery fallback + autocomplete title_raw fallback.
Sources

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.