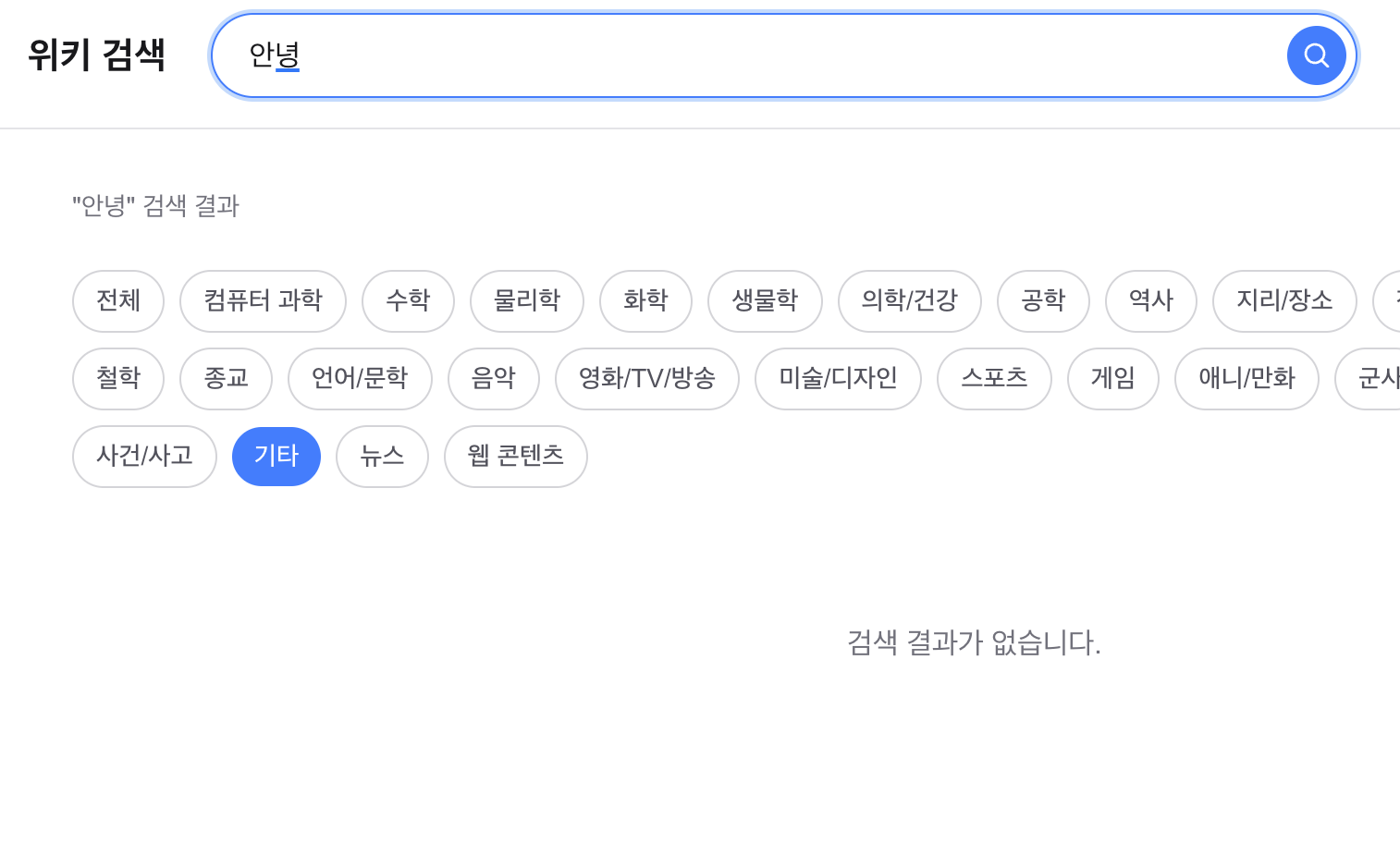
Nori 형태소 분석기 Stop Filter 문제: "안녕" 0건과 "안녕하세" 노이즈 해결
Lucene Nori 분석기에서 "안녕" 검색이 0건이 되는 IC 필터링 문제와, "안녕하세" 검색 시 "하세" 관련 문서만 나오는 형태소 분석 한계를 분석합니다. IC 제거 + title_ngram dis_max + PrefixQuery 폴백 3단계 해결을 적용하고, 자동완성 title_raw fallback까지 포함합니다.
검색 결과가 없습니다
제목, 태그, 카테고리로 검색
Lucene Nori 분석기에서 "안녕" 검색이 0건이 되는 IC 필터링 문제와, "안녕하세" 검색 시 "하세" 관련 문서만 나오는 형태소 분석 한계를 분석합니다. IC 제거 + title_ngram dis_max + PrefixQuery 폴백 3단계 해결을 적용하고, 자동완성 title_raw fallback까지 포함합니다.

나무위키+한국어 위키백과+영어 위키백과+뉴스+웹텍스트+C4 한국어 코퍼스 1,215만 건 검색 엔진 프로젝트를 2개월간 26편의 기술 블로그로 기록하고 총정리합니다. MySQL LIKE 5,000ms 타임아웃에서 시작하여 임베디드 Lucene + Nori 한국어 형태소 분석으로 전환하고, Caffeine+Redis 2계층 캐시(82% 히트율), MySQL Replication R/W 분리, Nginx 스케일아웃(에러율 13.25%→0%), Debezium+Kafka CDC, Redis 3노드 Consistent Hashing까지 분산 아키텍처를 완성합니다. 검색 품질은 동의어 확장, 오타 교정, UnifiedHighlighter snippet, LTR(NDCG +4.8%p), 카테고리 28개 자동 분류, Aho-Corasick 금칙어 필터링으로 고도화하고, RAG(Gemini SSE 스트리밍)로 AI 검색 요약을 제공합니다. 자동완성 시스템 설계(CQRS + MapReduce + CDC)의 이론과 실제 구현의 매핑, 26편 전체 시리즈 링크, 핵심 수치 총정리를 포함합니다.
BM25 수동 가중치(title:3, content:1)의 한계를 Learning to Rank(LTR)로 극복합니다. 카테고리 28개 자동 분류(키워드 기반, 정확도 83%) → SortedSetDocValuesFacetCounts 네이티브 Facet 전환 → 태그 216만 건 인덱싱을 1회 재색인으로 통합 반영합니다. LLM-as-a-Judge(Gemini)로 학습 데이터 900쌍을 생성하고(1차 실패 98% → 5초 딜레이+지수 백오프로 해결), XGBoost LambdaMART 14개 피처로 학습하여 NDCG@10을 0.6910 → 0.7387(+4.8%p) 개선합니다. XGBoost4J ARM64 네이티브 추론, Rescorer Top-200 재랭킹, RefreshListener 기반 FacetState 캐싱, MultiCollectorManager 단일 패스 수집까지 구현하지만, 2코어 ARM Free Tier에서 LTR ON 시 CPU 포화(72배 악화)를 k6로 실측하여 LTR_ENABLED=false로 비활성화합니다.
Lucene 기반 검색 엔진의 Recall과 Precision을 동시에 개선합니다. 동의어 확장(DB 기반 쿼리 타임)으로 "AI" 검색 시 "인공지능" 문서를 포함시키고, DirectSpellChecker로 "프로그래링" → "프로그래밍" 오타 교정을 구현합니다. UnifiedHighlighter + snippetSource 500자 StoredField로 검색어 주변 맥락 snippet을 제공하고, 무중단 전체 재색인 인프라(Directory Swap + SearcherManager 재생성)를 구축하여 12,156,589건(42GB)을 ~2시간 만에 재색인합니다. 인덱스 타임 동의어가 IDF를 왜곡하는 원리, Nori 사용자 사전 158,539개 적용, BM25 변형(BM25+/L/F) 불필요 판단 근거까지 정리합니다.
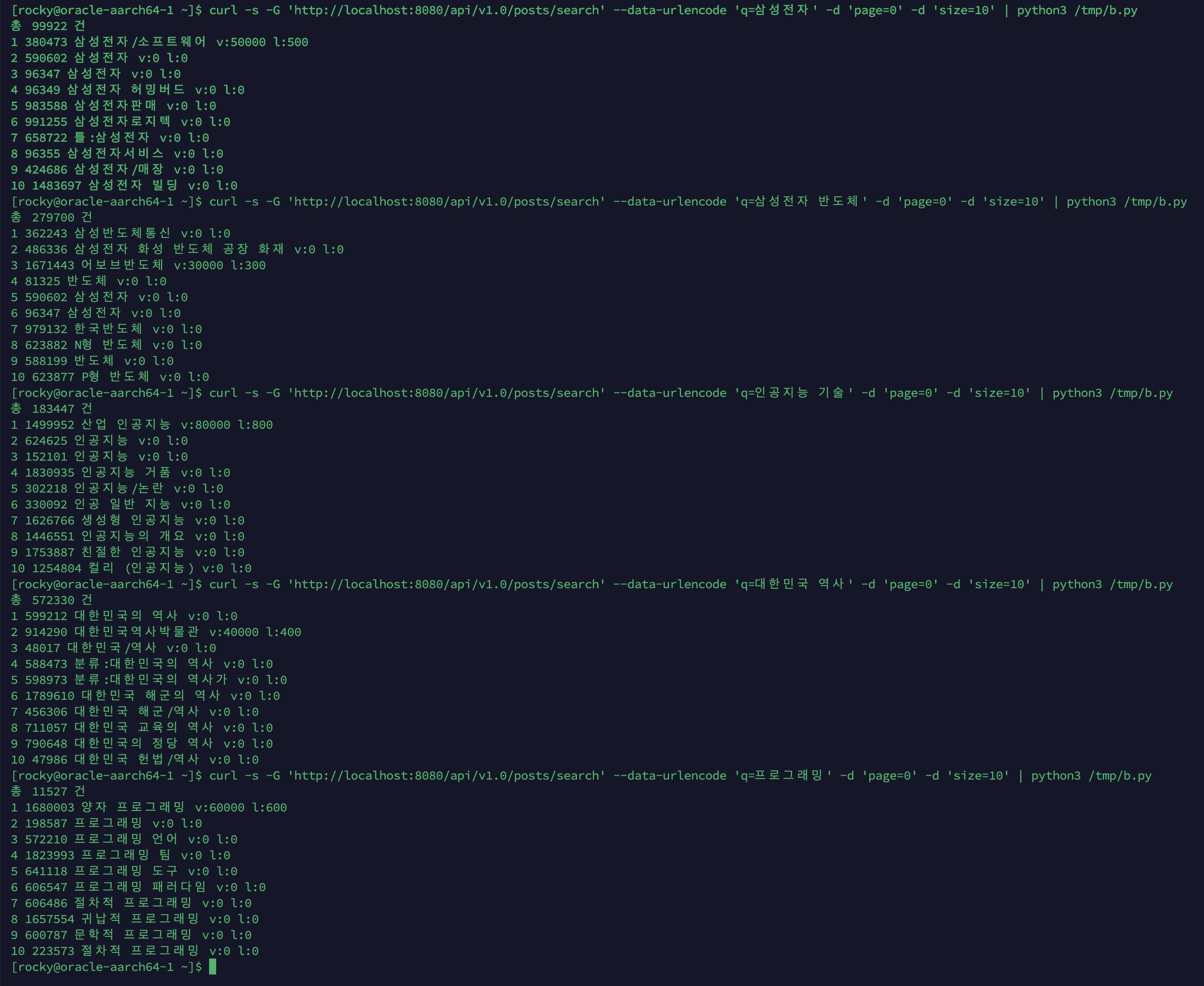
PhraseQuery(slop=2)로 구절 검색을 구현하고, FeatureField 기반 BM25 + 인기도 + 최신성 커뮤니티 랭킹을 적용한 뒤, P@10/MAP 지표로 검색 품질을 정량 평가한 과정을 정리합니다.

MySQL FULLTEXT ngram의 구조적 한계(고빈도 토큰 타임아웃, 300GB+ 인덱스, false positive)를 분석하고, Lucene·Elasticsearch·벡터DB를 비용 관점에서 비교하여 임베디드 Lucene + Nori 형태소 분석기를 선택한 기술 결정 과정을 정리합니다.