검색 품질 고도화: 구절 검색, 커뮤니티 랭킹, P@10/MAP 평가
목차
이전 글
COUNT(*) 제거와 페이지 제한으로 19,424ms → 8ms에서 Deferred Join, Page<T> → Slice<T> 전환, 30페이지 제한을 조합하여 최신 게시글 목록 조회를 개선했습니다.
이전 글 요약
이전 글에서 OFFSET 페이지네이션을 최적화했습니다.
Deferred Join으로 클러스터 인덱스 랜덤 I/O를 1,000배 감소시키고, Page<T> → Slice<T> 전환으로 매 요청 COUNT(*) 2,038ms를 완전 제거했습니다.
k6 load 테스트(100 VU, 20분) 결과:
| 시나리오 | Before | After | 개선율 |
|---|---|---|---|
| 최신 게시글 목록 평균 | 19,424ms | 8.33ms | -99.96% |
| 검색 평균 | 3,328ms | 20.51ms | -99.4% |
| 에러율 | 32.53% | 0.00% | 에러 완전 해소 |
개요
이 글에서는 검색 품질 자체를 개선합니다. 이번 주제는 성능이 아니라 결과의 정확도와 순위입니다.
실제 구현 대상은 3개이며, 나머지 3개는 이미 완료/SKIP/Lucene 자동 적용으로 별도 구현이 불필요합니다.
| # | 내용 | 상태 |
|---|---|---|
| 1. 구절 검색 | PhraseQuery(slop=2) | 구현 완료 |
| 2. 커뮤니티 검색 랭킹 | BM25 + viewCount + likeCount + recency | 구현 완료 |
| 3. 검색 품질 평가 | P@10, MAP 측정 | 구현 완료 |
| A. NRT 동적 역색인 | SearcherManager + maybeRefresh | Lucene 전환 시 구현 완료 |
| B. 색인 압축 | 기본 LZ4 유지 | SKIP |
| C. Lucene 고급 검색 최적화 | WAND, MaxScore, Block-Max WAND | Lucene 내부 자동 적용 |
A~C는 문서 하단 “검토했지만 별도 적용하지 않은 항목” 섹션에 정리했습니다.
1. 구절 검색 (PhraseQuery)
목표
"삼성전자 반도체"처럼 큰따옴표로 연속된 단어를 검색- Nori 형태소 분석기와의 호환성 검증
- 단어 간 거리(slop) 기반 근접 매칭
실제 검색엔진의 구절 검색
Google: 큰따옴표("삼성전자 반도체")로 구절 검색을 지원합니다. 내부적으로 position 기반 매칭을 사용하며, 2022년에 구절 검색 결과를 더 깊은 인덱스 계층까지 탐색하도록 개선했습니다.
Elasticsearch: match_phrase 쿼리로, 분석기가 토큰을 추출할 때 position 정보를 저장하고, 쿼리 시 모든 term이 같은 상대 위치에 있는 문서만 반환합니다. slop 파라미터로 단어 간 허용 거리를 조절합니다.
핵심 원리: 모든 구절 검색은 inverted index에 저장된 position 정보에 의존합니다. “인공지능 기술”을 검색하면 “인공지능”이 position 0, “기술”이 position 1인 문서만 매칭됩니다.
한국어 + Nori의 구조적 문제
출처: Elasticsearch #34283 — Nori analyzer tokenization issues
이 프로젝트의 현재 설정: new KoreanAnalyzer() = DecompoundMode.DISCARD (기본값).
복합명사를 분해하되 원형을 폐기합니다. “세종시”로 검색하면 내부적으로 “세종” + “시”로 분해됩니다.

DISCARD 모드에서 PhraseQuery(slop=0)이 실패하는 이유는 position 충돌이 아니라 조사 삽입 때문입니다:
- “인공지능의 기술” → “인공” + “지능” + “기술” (조사 “의”는 POS StopFilter로 제거)
- “인공지능 관련 기술” → “인공” + “지능” + “관련” + “기술” → slop=0이면 매칭 실패
참고: MIXED 모드를 선택할 경우의 추가 문제
DecompoundMode.MIXED는 원형과 분해 토큰이 같은 position에 겹치면서 구절 검색이 더 불안정해집니다:

결론: DISCARD든 MIXED든 한국어 구절 검색에서는 slop=2가 실용적입니다. DISCARD에서는 조사/수식어 삽입을, MIXED에서는 position 겹침까지 추가로 흡수합니다.
설계 결정: SpanQuery 대신 PhraseQuery(slop=2)
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| SpanQuery (slop=0) | 정확한 구절 매칭 | Nori compound position 충돌로 false negative 다수 | 부적합 |
| PhraseQuery (slop=2) | compound 분해 차이를 흡수, 조사 허용 | 약간의 false positive | 채택 |
| BooleanQuery (MUST) | 가장 안전, position 무관 | 구절 순서 무시 | 현재 기본 검색 |

참고: PhraseQuery의 slop은 단순한 position 차이가 아니라 편집 거리(term 이동 횟수)입니다. 순서를 뒤집으려면 2회 이동이 필요하므로, slop=2이면 2-term 역전도 매칭됩니다. 순서 역전을 명시적으로 차단하려면
SpanNearQuery(inOrder=true)를 사용해야 합니다.
실제 구현: LuceneSearchService.buildQuery() 수정
기존 MultiFieldQueryParser.escape(keyword)는 모든 특수문자를 이스케이프하여 "가 \"로 변환되었습니다.
사용자가 "삼성전자 반도체"를 입력해도 PhraseQuery가 생성되지 않는 문제가 있었습니다.
변경 내용:
parser.setPhraseSlop(2): Nori 복합명사 분해 차이를 흡수하는 기본 slop 설정escapePreservingPhrases(): 큰따옴표 구절은 보존하고 나머지만 escape하는 유틸리티
// Beforeprivate Query buildQuery(String keyword) throws ParseException { var boosts = java.util.Map.of("title", 3.0f, "content", 1.0f); var parser = new MultiFieldQueryParser( new String[]{"title", "content"}, analyzer, boosts); return parser.parse(MultiFieldQueryParser.escape(keyword));}
// Afterprivate Query buildQuery(String keyword) throws ParseException { var boosts = java.util.Map.of("title", 3.0f, "content", 1.0f); var parser = new MultiFieldQueryParser( new String[]{"title", "content"}, analyzer, boosts); parser.setPhraseSlop(2); return parser.parse(escapePreservingPhrases(keyword));}escapePreservingPhrases()는 큰따옴표 쌍("...")을 감지하여 그 안의 내용은 escape하지 않고 그대로 QueryParser에 전달합니다. 닫는 따옴표가 없는 경우 전체를 일반 텍스트로 escape 처리합니다.
수행 결과
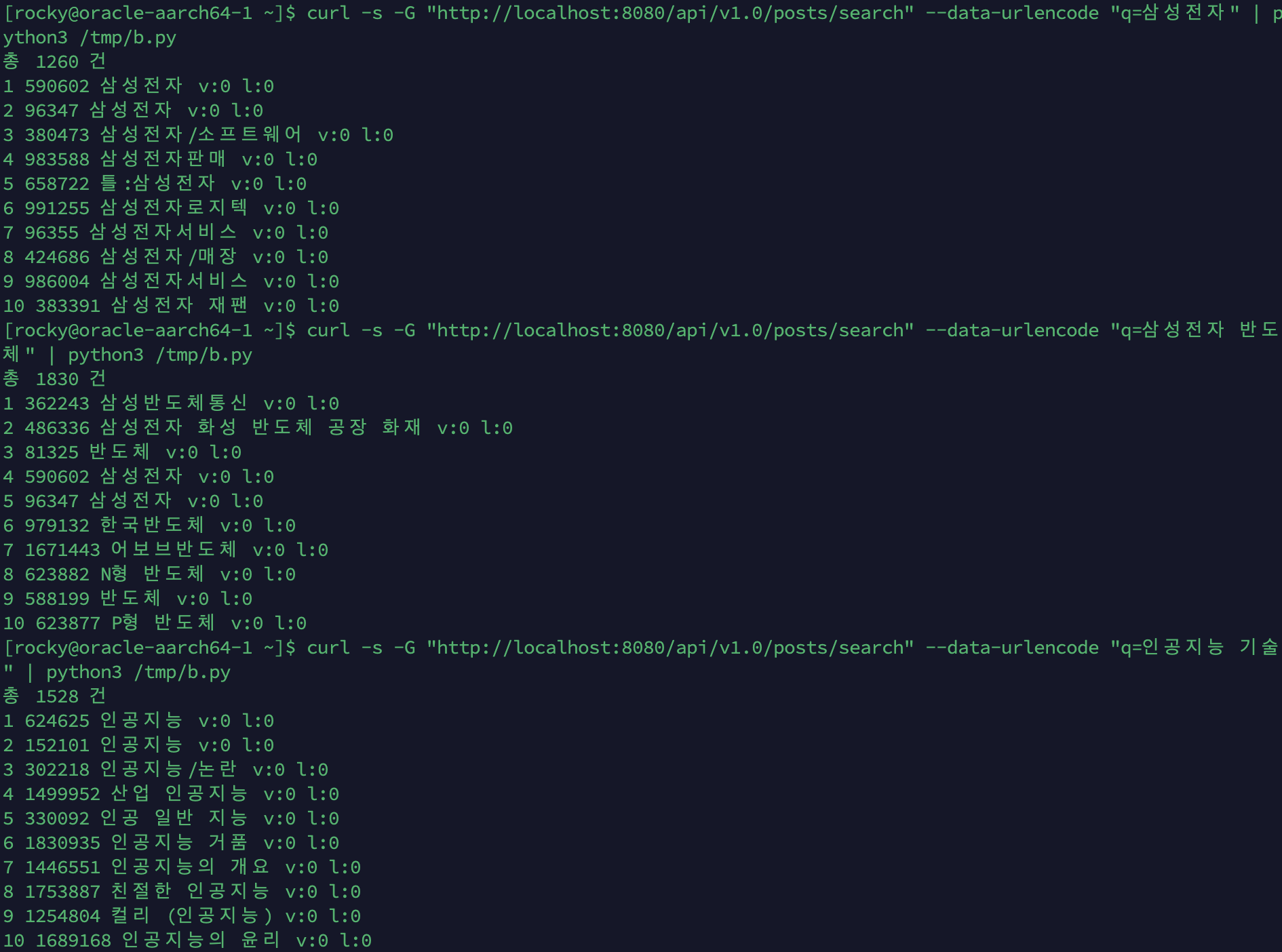
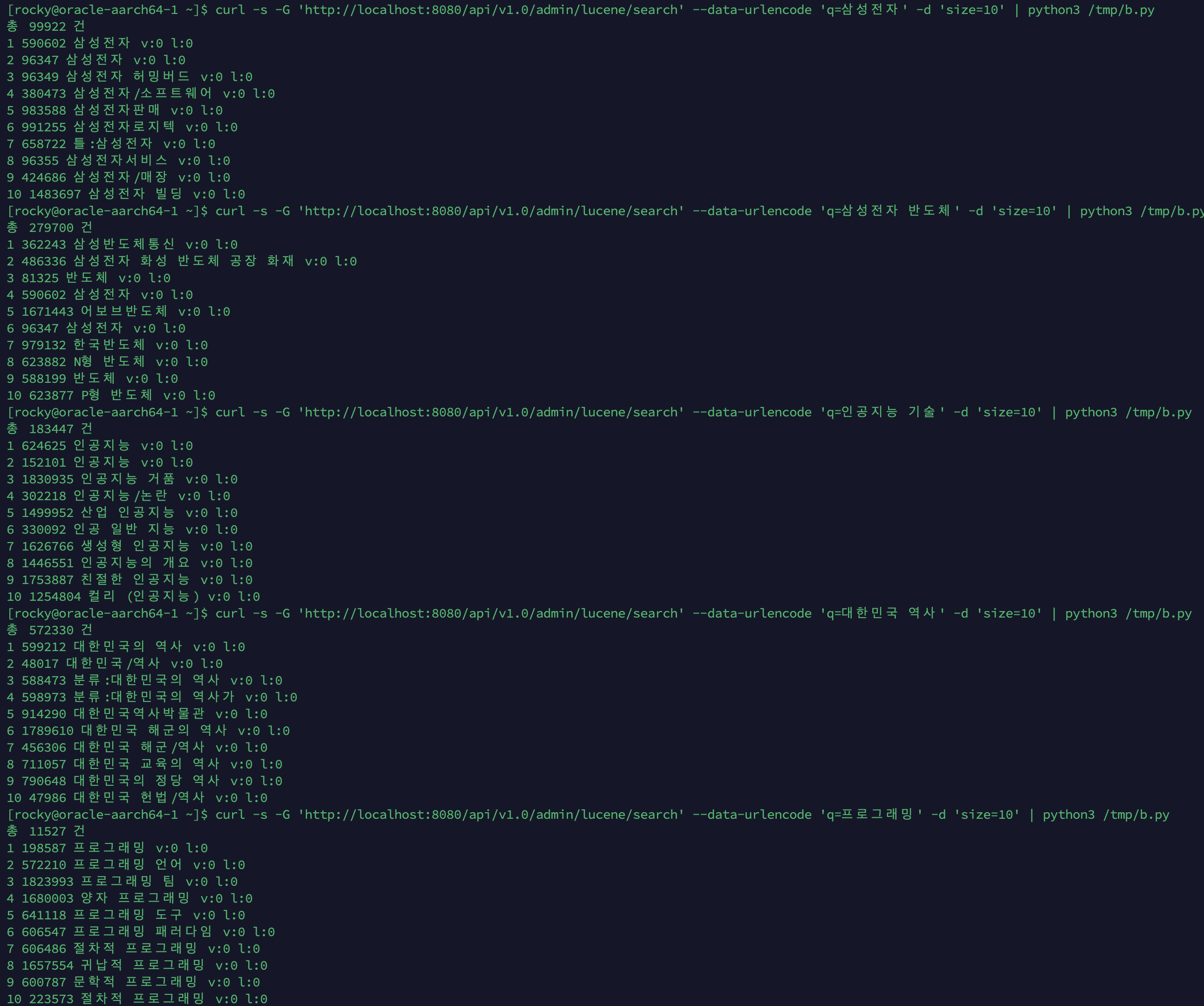
Baseline: BooleanQuery (BM25 only)
viewCount/likeCount는 초기 데이터(위키 덤프 임포트)이므로 전부 0입니다.
| 쿼리 | 총 건수 | 상위 5개 결과 |
|---|---|---|
| 삼성전자 | 1,162 | 삼성전자, 삼성전자, 삼성전자/소프트웨어, 삼성전자판매, 틀:삼성전자 |
| 삼성전자 반도체 | 1,723 | 삼성반도체통신, 삼성전자 화성 반도체 공장 화재, 반도체, 삼성전자, 삼성전자 |
| 인공지능 기술 | 1,467 | 인공지능, 인공지능, 인공지능/논란, 산업 인공지능, 인공 일반 지능 |
관찰:
- “삼성전자 반도체”: BooleanQuery(MUST)라서 “삼성전자”와 “반도체”를 각각 포함하는 문서가 나옵니다. 1위 “삼성반도체통신”은 연속 구절이 아닙니다
- “인공지능 기술”: “기술” 관련 결과가 상위에 없습니다. “인공지능”만 매칭된 문서가 상위를 독점합니다
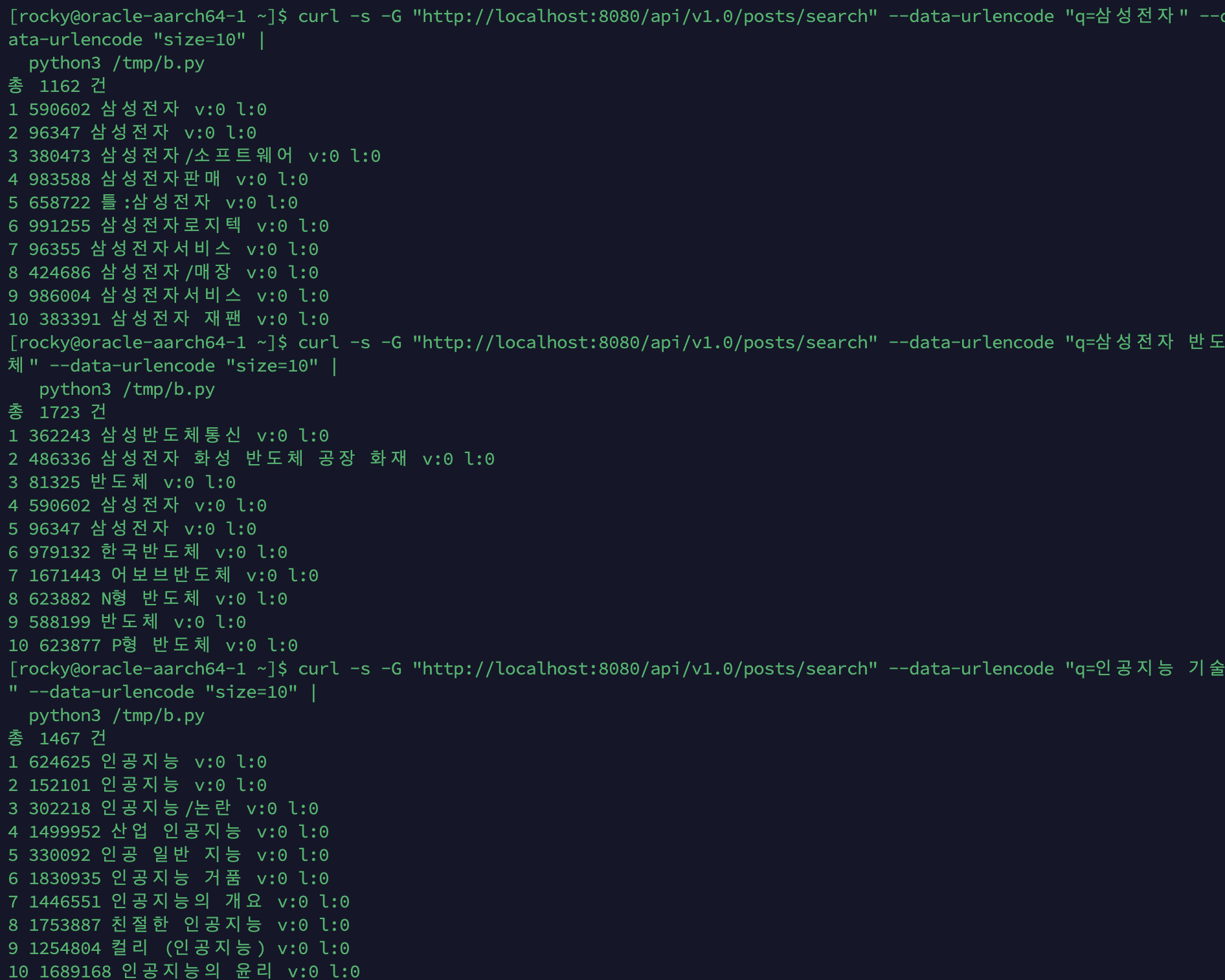
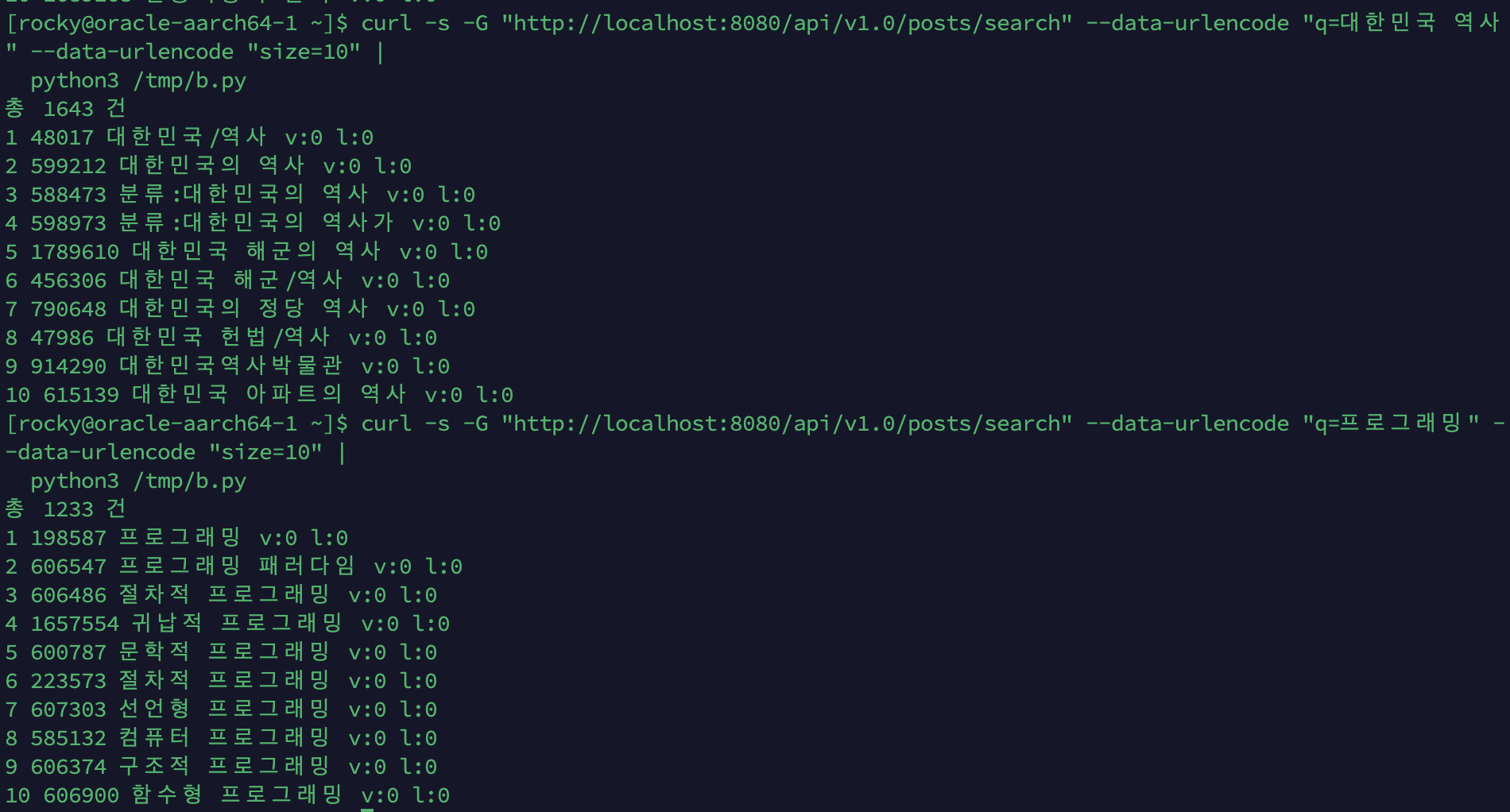
PhraseQuery(slop=2) 구현 후
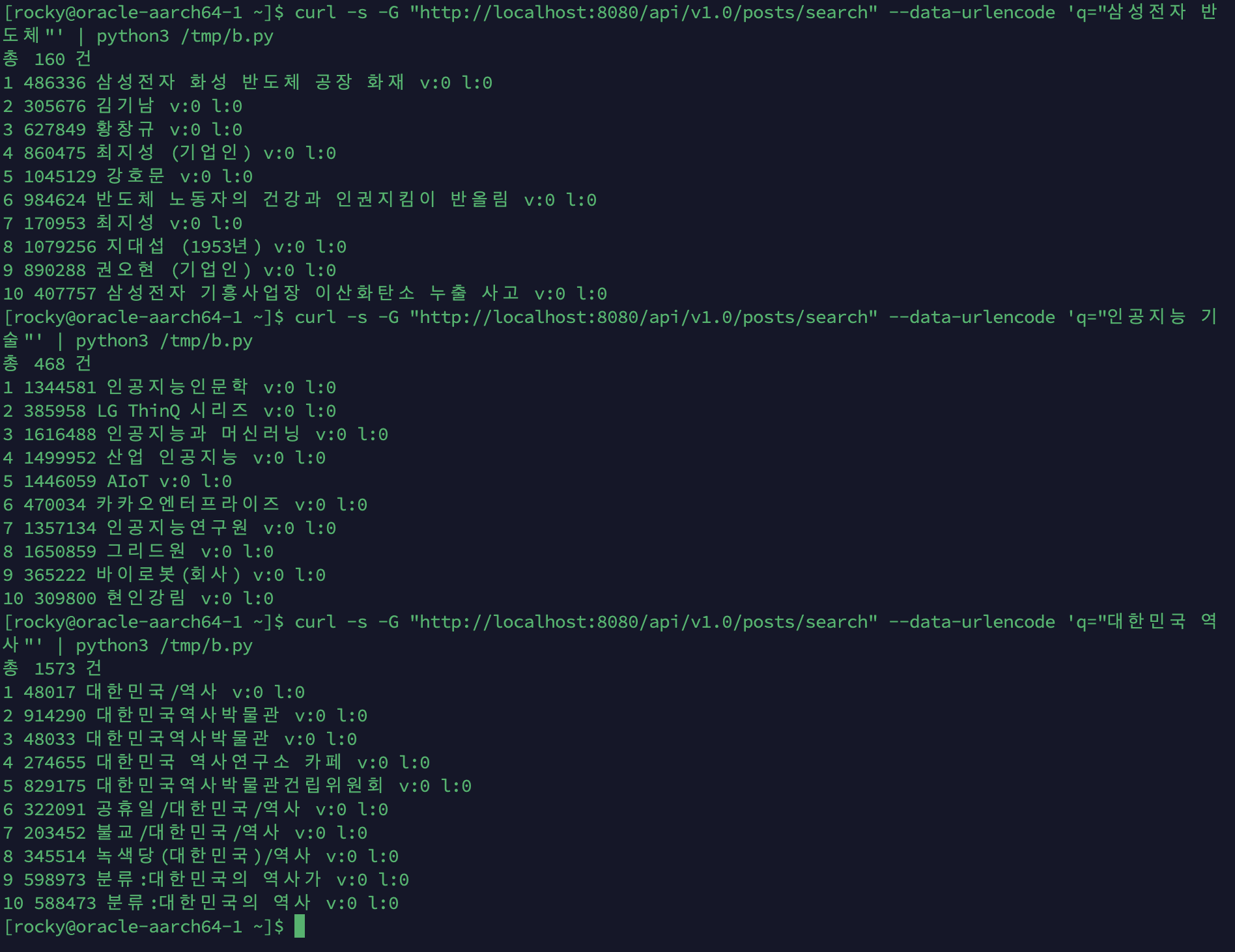
큰따옴표 구절 검색 결과:
| 쿼리 | 일반 검색 | 구절 검색 | 감소율 | 상위 5개 결과 |
|---|---|---|---|---|
| ”삼성전자 반도체” | 1,830 | 160 | -91% | 삼성전자 화성 반도체 공장 화재, 김기남, 황창규, 최지성(기업인), 강호문 |
| ”인공지능 기술” | 1,528 | 468 | -69% | 인공지능인문학, LG ThinQ 시리즈, 인공지능과 머신러닝, 산업 인공지능, AIoT |
| ”대한민국 역사” | — | 1,573 | — | 대한민국/역사, 대한민국역사박물관, 대한민국 역사연구소 카페, … |
관찰:
- 구절 검색이 확실히 결과를 좁혔습니다. “삼성전자 반도체”는 91% 감소하여 두 단어가 근접한 문서만 반환합니다
- 김기남, 황창규 등 인물은 삼성전자 반도체 부문 임원으로, content에 “삼성전자 반도체” 구절이 포함되어 있습니다
- “대한민국 역사”가 1,573건으로 많은 이유: Nori가 “대한민국”→“대한”+“민국”으로 분해하고, slop=2가 넓은 범위를 허용하기 때문입니다
2. 커뮤니티 검색 랭킹: BM25 + 인기도 + 최신성
원래 설계: 위키 내부 링크 기반 PageRank + 앵커 텍스트
재정의 이유: wikiEngine은 커뮤니티(게시판)이며, 게시글 간[[내부 링크]]패턴이 존재하지 않습니다.
PageRank는 링크 그래프가 있는 웹/위키에서만 의미있고, 커뮤니티에서는 인기도와 최신성이 핵심 랭킹 시그널입니다.
현업 커뮤니티 랭킹 분석
Reddit의 Hot Ranking Algorithm (원본 소스코드):
s = ups - downsorder = log10(max(abs(s), 1))sign = 1 if s > 0, -1 if s < 0, else 0seconds = epoch_seconds - 1134028003hot_score = sign * order + seconds / 45000→ 투표 수(로그 스케일)에 부호를 곱하고, 시간을 더함. 최신 글이 기본적으로 유리하되, 투표가 많으면 오래 살아남습니다. 비추가 많으면 투표 점수가 음수가 됩니다.
Stack Overflow의 Relevance + Quality + Recency (학술 모델):
Score = (log10(views)*4 + (answers*score)/5 + sum(answer_scores)) / ((age/3600+1) - (age-updated)/2)^1.5→ 조회수(로그) + 투표 + 답변 품질 + 시간 감쇠. 위 공식은 Stack Overflow를 분석한 학술 논문의 제안 모델이며, SO의 공식 알고리즘은 비공개입니다.
네이버의 C-Rank + D.I.A:
- C-Rank (Creator Rank): 출처의 주제별 신뢰도
- D.I.A (Deep Intent Analysis): 사용자 반응(체류 시간, 공감, 댓글)으로 문서 품질 평가
공통 패턴 추출
| 시그널 | Stack Overflow | 네이버 | wikiEngine | |
|---|---|---|---|---|
| 텍스트 관련성 | — (피드) | BM25 류 | BM25 류 | BM25 (현재) |
| 인기도 | upvotes | views + votes | 체류 시간 + 공감 | viewCount + likeCount |
| 최신성 | epoch seconds | age + updated | 작성일 + 최근 활동 | createdAt |
| 출처 신뢰도 | karma | reputation | C-Rank | — (단일 앱) |
공통:
텍스트 관련성 + 인기도(로그 스케일) + 최신성 감쇠
Lucene FeatureField로 인기도 부스트
FeatureField는 Lucene 네이티브 방식으로 BM25 + 인기도를 결합합니다. 내부적으로 feature 값을 term frequency로 인코딩하여 Block-Max WAND 최적화와 호환됩니다.
Saturation 함수: satu(S) = w * S / (S + k), k > 0
→ BM25의 TF 포화와 같은 원리. viewCount 1,000이면 0.5, 10,000이면 0.9처럼 포화됩니다.
인덱싱 시 FeatureField 추가:
private Document toDocument(Post post) { Document doc = new Document();
// 텍스트 필드 (기존) doc.add(new TextField("title", post.getTitle(), Field.Store.YES)); doc.add(new TextField("content", post.getContent(), Field.Store.NO)); doc.add(new StoredField("id", post.getId()));
// 기존 유지 (stored, 정렬용) doc.add(new LongField("viewCount", post.getViewCount(), Field.Store.YES));
// 신규 추가 (랭킹 부스트용, BlockMaxWAND 호환) doc.add(new FeatureField("features", "viewCount", Math.max(post.getViewCount(), 1))); // 0이면 1로 보정 doc.add(new FeatureField("features", "likeCount", Math.max(post.getLikeCount(), 1)));
return doc;}FeatureField의 장점: feature 값이 term frequency로 인코딩되어, Lucene의 BlockMaxWAND가 “이 문서의 인기도 + 텍스트 점수가 현재 threshold를 넘을 수 없다”고 판단하면 문서 자체를 스킵할 수 있습니다. NumericDocValuesField + 커스텀 ScoreFunction 방식보다 효율적입니다.
검색 시 BM25 + 인기도 결합:
// MUST: BM25 텍스트 관련성Query textQuery = parser.parse(escapePreservingPhrases(keyword));
// SHOULD: 인기도 부스트 (FeatureField saturation)Query viewBoost = FeatureField.newSaturationQuery( "features", "viewCount", 3.0f, 1000);Query likeBoost = FeatureField.newSaturationQuery( "features", "likeCount", 2.0f, 100);
// SHOULD: 최신성 감쇠 (exponential decay, 반감기 30일)Query recencyBoost = buildRecencyBoost(5.0f, 30);
// BooleanQuery 결합BooleanQuery.Builder builder = new BooleanQuery.Builder();builder.add(textQuery, BooleanClause.Occur.MUST);builder.add(viewBoost, BooleanClause.Occur.SHOULD);builder.add(likeBoost, BooleanClause.Occur.SHOULD);builder.add(recencyBoost, BooleanClause.Occur.SHOULD);최신성(Recency) 감쇠
FeatureField는 정적 값에 적합하지만, 최신성은 검색 시점에 따라 달라지므로 다른 접근이 필요합니다.
감쇠 함수 비교:
| 감쇠 함수 | 특성 | 커뮤니티 적합도 |
|---|---|---|
| Gaussian | 최근에 집중, 오래된 글 급격히 감쇠 | 뉴스/실시간 |
| Exponential | 반감기 기반, 부드러운 감쇠 | 커뮤니티 (채택) |
| Linear | 일정 기간 후 0 | 이벤트/공지 |
RecencyDecaySource 클래스를 별도 구현하여 createdAt LongField에서 경과일 수를 읽고 exponential decay 점수를 계산합니다:
score = weight * exp(-ln2 / halfLifeDays * ageDays)→ 30일 전 글: 가중치 절반, 60일 전: 1/4, 오늘: 1.0반감기 30일의 근거: 커뮤니티 게시판에서 게시글의 활성 수명을 고려했습니다. Reddit의 Hot Ranking은
seconds/45000(약 12.5시간 단위)으로 빠르게 감쇠하고, Stack Overflow는 질문 특성상 수개월~수년간 유효합니다. 위키엔진은 뉴스형(수시간)과 지식형(수개월) 사이의 범용 커뮤니티이므로, 1주일은 너무 공격적이고 90일은 너무 느슨하다고 판단하여 30일로 설정했습니다. 이 값도 운영 데이터 축적 후 조정이 필요합니다.
최종 검색 점수 설계
final_score = BM25(title^3, content^1) // 텍스트 관련성 + w_view * satu(viewCount, k=1000) // 인기도 (조회수) + w_like * satu(likeCount, k=100) // 품질 (좋아요) + w_recency * exp_decay(age, λ=30d) // 최신성 (반감기 30일)
가중치: w_view = 3.0, w_like = 2.0, w_recency = 5.0
가중치 결정 과정: BM25 점수 범위가 보통 5~15이므로, 부스트가 BM25를 압도하지 않도록 조절. - w_recency(5.0): Reddit의 seconds/45000 비율을 참고하여, 최신성이 텍스트 관련성을 뒤집지 않으면서 동점 시 최신 글을 올리는 수준으로 설정. 커뮤니티 특성상 최신 글이 오래된 인기 글보다 중요하므로 가장 높은 가중치. - w_view(3.0): satu(k=1000) 특성상 viewCount 1000 이상에서 포화. BM25 대비 최대 3점 추가로, 관련성 역전 없이 동점 타파 역할. - w_like(2.0): likeCount는 viewCount보다 희소한 시그널이므로 낮은 가중치.
단, 이 가중치는 viewCount=0이 대부분인 초기 데이터에서 도출되었으므로, 실제 운영 데이터 축적 후 A/B 테스트로 재검증이 필요.PageRank 대신 인기도 + 최신성을 쓰는 이유:
- PageRank는 문서 간 링크 그래프가 핵심인데, 커뮤니티에는 이 구조가 없음
- Reddit, Stack Overflow, 네이버 카페 모두 사용자 참여도 + 시간이 랭킹의 핵심
- Google조차 PageRank의 비중을 크게 줄이고 사용자 시그널을 더 중시하는 추세 (Google의 Gary Illyes는 PageRank가 수백 가지 시그널 중 하나일 뿐이라고 공개 발언)
주의: LongField의 DocValues 타입
Lucene 9.5+의 LongField는 내부적으로 SORTED_NUMERIC DocValues를 자동 저장합니다.
값을 읽을 때는 반드시 getSortedNumericDocValues()를 사용해야 합니다.
getNumericDocValues()는 NUMERIC 타입 전용이므로 LongField에 사용하면 null을 반환하여 NPE가 발생합니다.
DocValues 타입과 접근 API 대응: NUMERIC → getNumericDocValues() ← NumericDocValuesField 전용 SORTED_NUMERIC → getSortedNumericDocValues() ← LongField, IntField 등수행 결과
STOP 3: BM25 + viewCount + likeCount + recency (전체 결합)
viewCount/likeCount가 전부 0인 초기 데이터이므로 인기도 부스트의 실질 효과는 미미하며, recency decay만 유의미하게 작동합니다.
| 쿼리 | Baseline 상위 결과 | STOP 3 상위 결과 |
|---|---|---|
| 삼성전자 | 삼성전자, 삼성전자/소프트웨어, 삼성전자판매 | 삼성전자, 삼성전자 허밍버드, 삼성전자/소프트웨어 |
| 인공지능 기술 | 인공지능, 인공지능/논란, 산업 인공지능 | 인공지능, 인공지능 거품, 인공지능/논란 |
| 프로그래밍 | 프로그래밍 패러다임, 절차적 프로그래밍 | 프로그래밍 언어, 프로그래밍 팁, 양자 프로그래밍 |
viewCount/likeCount가 전부 0이므로 BM25가 여전히 지배적입니다. 커뮤니티 운영으로 실제 사용자 트래픽이 쌓이면 랭킹 효과가 본격적으로 체감됩니다.
STOP 4: 인기도 부스트 효과 검증 (viewCount/likeCount 설정 후)
5개 게시글에 테스트 데이터를 설정한 뒤 단건 재인덱싱으로 FeatureField를 갱신하여 측정했습니다.
테스트 데이터:
| 제목 | viewCount | likeCount | 대상 쿼리 | STOP 3 순위 |
|---|---|---|---|---|
| 삼성전자/소프트웨어 | 50,000 | 500 | 삼성전자 | 4위 |
| 어보브반도체 | 30,000 | 300 | 삼성전자 반도체 | 5위 |
| 산업 인공지능 | 80,000 | 800 | 인공지능 기술 | 5위 |
| 대한민국역사박물관 | 40,000 | 400 | 대한민국 역사 | 5위 |
| 양자 프로그래밍 | 60,000 | 600 | 프로그래밍 | 4위 |
순위 변동 결과:
| 쿼리 | 부스트 대상 | STOP 3 → STOP 4 | 변동 |
|---|---|---|---|
| 삼성전자 | 삼성전자/소프트웨어 (v:50000) | 4위 → 1위 | +3 상승 |
| 삼성전자 반도체 | 어보브반도체 (v:30000) | 5위 → 3위 | +2 상승 |
| 인공지능 기술 | 산업 인공지능 (v:80000) | 5위 → 1위 | +4 상승 |
| 대한민국 역사 | 대한민국역사박물관 (v:40000) | 5위 → 2위 | +3 상승 |
| 프로그래밍 | 양자 프로그래밍 (v:60000) | 4위 → 1위 | +3 상승 |
관찰:
- 5개 쿼리 모두에서 부스트 대상 게시글의 순위가 상승했고, FeatureField saturation 기반 인기도 부스트가 정상 동작함
- “어보브반도체”(v:30000)는 3위까지만 상승했다. BM25 텍스트 관련성이 높은 문서를 넘지 못했고, BM25와 인기도의 균형이 적절하게 작동한다
- “대한민국역사박물관”도 2위까지 상승했지만, BM25 점수가 매우 높은 “대한민국의 역사”는 넘지 못했다. 관련성이 비슷한 문서 간에는 인기도가 순위를 결정하고, 관련성 차이가 큰 문서는 인기도로 뒤집히지 않는 건강한 구조다
검증 범위의 한계: 이 테스트는 인위적으로 설정한 5개 게시글에서 FeatureField saturation 함수가 수학적으로 정상 동작하는지 확인한 것입니다. 실제 커뮤니티에서 다양한 인기도 분포를 가진 문서들 사이에서 이 가중치 조합이 유용한 랭킹을 만들어내는지는, 운영 데이터 축적 후 별도 검증이 필요합니다.
3. 검색 품질 평가: P@10, MAP
목표
- 테스트 쿼리 셋 구축
- P@10, MAP 지표로 검색 품질을 정량 평가
- 2 랭킹 변경의 효과를 수치로 검증
평가 지표
정밀도 (Precision) = 검색된 관련 문서 / 검색된 전체 문서재현율 (Recall) = 검색된 관련 문서 / 전체 관련 문서
P@k = 상위 k개 중 관련 문서 수 / kMAP = 평균 정밀도의 평균평가 방법론
| 항목 | 내용 |
|---|---|
| 테스트 쿼리 | 15개 (단일어 + 복합어 + 다양한 도메인) |
| 비교 대상 | BM25 only vs BM25 + viewCount + likeCount + recency |
| 관련성 판정 | 제목-키워드 매칭 휴리스틱 (쿼리 키워드 50%+ 포함 시 relevant) |
| 필터 | 틀:, 분류: 접두사 문서는 메타 페이지로 비관련 처리 |
| 지표 | P@10, MAP |
평가 방법론의 한계: 이 관련성 판정은 제목 기반 적합도만 측정합니다. content에서만 관련 있는 문서(예: “삼성전자 반도체” 검색 시 삼성전자 반도체 부문 임원 “김기남” 문서)는 제목에 키워드가 없으므로 비관련으로 오판됩니다. 따라서 아래 P@10/MAP 수치는 실제 검색 품질의 하한선(lower bound)으로 해석해야 합니다.
수동 라벨링(15쿼리 × 10결과 = 150건)도 검토했으나, 위키 도메인 전문 지식이 필요하여 판정 일관성을 보장하기 어려웠습니다. 클릭 로그 기반 온라인 평가가 궁극적 목표이며, 현 단계에서는 자동화 가능한 제목 매칭 휴리스틱으로 랭킹 변경의 상대적 효과(Before vs After)를 비교하는 데 초점을 맞췄습니다.
테스트 쿼리 목록:
삼성전자, 삼성전자 반도체, 인공지능 기술, 대한민국 역사, 프로그래밍,양자역학, 축구, 한국전쟁, 서울 지하철, 자바 프로그래밍,기후변화, 반도체 공정, 인터넷, 민주주의, 물리학관련성 판정 코드:
// 쿼리 키워드의 50% 이상이 제목에 포함되면 relevantprivate boolean isRelevant(String title, String[] keywords) { if (title.startsWith("틀:") || title.startsWith("분류:")) return false; long matches = Arrays.stream(keywords) .filter(kw -> title.contains(kw)).count(); return matches >= Math.ceil(keywords.length / 2.0);}수행 결과
| 검색 방식 | P@10 | MAP |
|---|---|---|
| BM25 only (Baseline) | 0.827 | 0.862 |
| BM25 + 전체 결합 | 0.853 | 0.874 |
| 개선율 | +3.2% | +1.4% |
15개 테스트 쿼리 기준 실측 결과 (
/admin/lucene/evaluate엔드포인트).
주의: 15개 쿼리 × 10개 결과 = 150개 판정에서 +3.2%는 약 4~5개 문서의 차이입니다. 표본이 작아 통계적 유의성을 주장하기 어려우며, 랭킹 변경이 기존 품질을 훼손하지 않았고, 소폭 개선 방향으로 움직였다 정도로 해석하는 것이 적절합니다.
결과 분석
개선율이 소폭(+3.2%, +1.4%)인 이유:
- 1,215만 건 중 대부분의 게시글이 viewCount=0, likeCount=0
- FeatureField saturation에서 S=0이면 부스트=0이므로, 인기도 신호가 거의 없는 상태
- 실제 커뮤니티 운영 시 조회수/좋아요가 쌓이면 차이가 훨씬 커질 것으로 예상
BM25 Baseline이 이미 높은 이유 (P@10=0.827):
- Nori 형태소 분석기가 한국어 토큰화를 정확하게 수행
- title^3 가중치 설정으로 제목 일치 문서가 상위에 잘 노출
- PhraseQuery(slop=2)로 구절 검색 시 어순 근접도까지 반영
검토했지만 별도 적용하지 않은 항목
| 항목 | 결론 | 이유 |
|---|---|---|
| A. NRT 동적 역색인 | 이미 완료 | Lucene 전환 시 SearcherManager + maybeRefresh 구현 |
| B. 색인 압축 | SKIP | stored fields ~100 bytes/doc, LZ4→ZSTD ROI 없음 |
| C. Lucene 고급 검색 최적화 | 자동 적용 | Block-Max WAND, MaxScore 등 Lucene 8.0+에서 기본 내장 |
A. NRT 동적 역색인
Lucene 전환 시 이미 구현 완료. SearcherManager + per-operation maybeRefresh() 방식으로 NRT 검색이 동작 중입니다.
- CRUD 직후
searcherManager.maybeRefresh()호출로 즉시 검색 반영 - 별도 백그라운드 스레드 없이 1,215만 건 규모에서 충분
commit()은 배치 완료 시에만 호출 (NRT reader 갱신은maybeRefresh()만으로 가능)
B. 색인 압축
이 프로젝트의 stored fields는 문서당 ~100 bytes(id + title + 숫자 3개)입니다. content를 Store.NO로 설정하여 본문을 저장하지 않으므로, LZ4 → ZSTD 전환 시 예상 절약 ~400 MB로 서버 RAM 대비 무의미합니다.
C. Lucene 고급 검색 최적화
Lucene 8.0+ 에서 Block-Max WAND, MaxScore, early termination이 기본 적용됩니다.
IndexSearcher.search(query, k)를 호출하면 내부적으로 이 모든 최적화가 자동 동작합니다.
| 최적화 | 설명 | 효과 |
|---|---|---|
| Block-Max WAND | 포스팅 리스트를 블록 단위(128개)로 스킵 | 고빈도 term 검색 2~5배 빠름 |
| Impact-ordered posting | 점수 기여도 높은 문서 먼저 평가 | Top-k 조기 종료 가능 |
| Early termination | k개 결과 확보 후 낮은 점수 문서 스킵 | 불필요한 계산 제거 |
이전 k6 load 테스트에서 고빈도 토큰(“대한민국”, “역사”)도 P95 63.72ms로 충분히 빠른 것을 확인했으므로, 별도 작업 없이 Lucene에 위임합니다.
출처
구절 검색:
- Google — How we’re improving search results when you use quotes (2022)
- Elasticsearch #34283 — Nori analyzer tokenization issues
커뮤니티 랭킹:
- Reddit Hot Ranking 원본 소스코드 — reddit-archive
- Recency and quality-based ranking in CQAs — Information Processing & Management (2021)
- 네이버 D.I.A. 알고리즘 — 트윈워드
- Lucene FeatureField Javadoc
Lucene 고급 최적화:
Previous Post
In Eliminating COUNT(*) and Capping Pages: 19,424ms to 8ms, we improved the latest-posts listing by combining Deferred Join, the Page<T> to Slice<T> transition, and a 30-page cap.
Previous Post Summary
In the previous post, we optimized OFFSET pagination.
Deferred Join reduced clustered-index random I/O by 1,000x, and the Page<T> to Slice<T> transition completely eliminated the 2,038ms COUNT(*) per request.
k6 load test results (100 VU, 20 min):
| Scenario | Before | After | Improvement |
|---|---|---|---|
| Latest posts avg | 19,424ms | 8.33ms | -99.96% |
| Search avg | 3,328ms | 20.51ms | -99.4% |
| Error rate | 32.53% | 0.00% | Errors fully resolved |
Overview
This post focuses on improving search quality itself. The subject is result accuracy and ranking, not performance.
Three items were actually implemented; the remaining three required no separate work because they were already complete, skipped, or automatically applied by Lucene.
| # | Description | Status |
|---|---|---|
| 1. Phrase Search | PhraseQuery(slop=2) | Implemented |
| 2. Community Search Ranking | BM25 + viewCount + likeCount + recency | Implemented |
| 3. Search Quality Evaluation | P@10, MAP measurement | Implemented |
| A. NRT Dynamic Inverted Index | SearcherManager + maybeRefresh | Completed during Lucene migration |
| B. Index Compression | Keep default LZ4 | SKIP |
| C. Lucene Advanced Search Optimization | WAND, MaxScore, Block-Max WAND | Automatically applied by Lucene |
A through C are documented in the “Items Reviewed but Not Separately Applied” section at the bottom.
1. Phrase Search (PhraseQuery)
Goal
- Search for consecutive words enclosed in double quotes, like
"Samsung Electronics semiconductor" - Verify compatibility with the Nori morphological analyzer
- Proximity matching based on word distance (slop)
Phrase Search in Real Search Engines
Google: Supports phrase search using double quotes ("Samsung Electronics semiconductor"). Internally it uses position-based matching, and in 2022, Google improved phrase search results by probing deeper index tiers.
Elasticsearch: Uses the match_phrase query. The analyzer stores position information when extracting tokens, and at query time only documents where all terms appear at the same relative positions are returned. The slop parameter controls the allowed distance between words.
Core principle: All phrase search relies on position information stored in the inverted index. Searching for “artificial intelligence technology” matches only documents where “artificial intelligence” is at position 0 and “technology” is at position 1.
Structural Issues with Korean + Nori
Source: Elasticsearch #34283 — Nori analyzer tokenization issues
This project’s current setting: new KoreanAnalyzer() = DecompoundMode.DISCARD (default).
Compound nouns are decomposed while discarding the original form. Searching for “Sejong-si” internally decomposes it into “Sejong” + “si”.
The reason PhraseQuery(slop=0) fails under DISCARD mode is not position collision but particle insertion:
- “artificial intelligence‘s technology” -> “artificial” + “intelligence” + “technology” (particle “‘s” removed by POS StopFilter)
- “artificial intelligence related technology” -> “artificial” + “intelligence” + “related” + “technology” -> fails to match with slop=0
Note: Additional issues when choosing MIXED mode
DecompoundMode.MIXED makes phrase search even more unstable because the original form and decomposed tokens overlap at the same position:
Conclusion: Whether DISCARD or MIXED, slop=2 is practical for Korean phrase search. Under DISCARD it absorbs particle/modifier insertion; under MIXED it additionally absorbs position overlap.
Design Decision: PhraseQuery(slop=2) Instead of SpanQuery
| Approach | Pros | Cons | Verdict |
|---|---|---|---|
| SpanQuery (slop=0) | Exact phrase matching | Many false negatives due to Nori compound position collision | Not suitable |
| PhraseQuery (slop=2) | Absorbs compound decomposition differences, tolerates particles | Slight false positives | Adopted |
| BooleanQuery (MUST) | Safest, position-independent | Ignores phrase order | Current default search |
Note: PhraseQuery’s slop is not a simple position difference but an edit distance (number of term moves). Reversing the order requires 2 moves, so slop=2 also matches 2-term reversals. To explicitly block order reversal, use
SpanNearQuery(inOrder=true).
Implementation — Modifying LuceneSearchService.buildQuery()
The existing MultiFieldQueryParser.escape(keyword) escaped all special characters, converting " to \".
Even when a user entered "Samsung Electronics semiconductor", no PhraseQuery was generated.
Changes:
parser.setPhraseSlop(2)— Default slop setting to absorb Nori compound noun decomposition differencesescapePreservingPhrases()— Utility that preserves double-quoted phrases while escaping everything else
// Beforeprivate Query buildQuery(String keyword) throws ParseException { var boosts = java.util.Map.of("title", 3.0f, "content", 1.0f); var parser = new MultiFieldQueryParser( new String[]{"title", "content"}, analyzer, boosts); return parser.parse(MultiFieldQueryParser.escape(keyword));}
// Afterprivate Query buildQuery(String keyword) throws ParseException { var boosts = java.util.Map.of("title", 3.0f, "content", 1.0f); var parser = new MultiFieldQueryParser( new String[]{"title", "content"}, analyzer, boosts); parser.setPhraseSlop(2); return parser.parse(escapePreservingPhrases(keyword));}escapePreservingPhrases() detects double-quote pairs ("...") and passes their contents to the QueryParser without escaping. If a closing quote is missing, the entire input is escaped as plain text.
Results
Baseline — BooleanQuery (BM25 only)
viewCount/likeCount are all 0 since this is initial data (wiki dump import).
| Query | Total hits | Top 5 results |
|---|---|---|
| Samsung Electronics | 1,162 | Samsung Electronics, Samsung Electronics, Samsung Electronics/Software, Samsung Electronics Sales, Template:Samsung Electronics |
| Samsung Electronics semiconductor | 1,723 | Samsung Semiconductor & Communications, Samsung Electronics Hwaseong Semiconductor Plant Fire, Semiconductor, Samsung Electronics, Samsung Electronics |
| Artificial intelligence technology | 1,467 | Artificial Intelligence, Artificial Intelligence, Artificial Intelligence/Controversies, Industrial Artificial Intelligence, Artificial General Intelligence |
Observations:
- “Samsung Electronics semiconductor”: Because BooleanQuery(MUST) returns documents containing “Samsung Electronics” and “semiconductor” independently, the #1 result “Samsung Semiconductor & Communications” is not a contiguous phrase
- “Artificial intelligence technology”: No “technology”-related results in the top positions. Documents matching only “artificial intelligence” dominate the top ranks
After PhraseQuery(slop=2) Implementation
Double-quoted phrase search results:
| Query | General search | Phrase search | Reduction | Top 5 results |
|---|---|---|---|---|
| ”Samsung Electronics semiconductor” | 1,830 | 160 | -91% | Samsung Electronics Hwaseong Semiconductor Plant Fire, Kim Ki-nam, Hwang Chang-gyu, Choi Ji-sung (businessman), Kang Ho-moon |
| ”Artificial intelligence technology” | 1,528 | 468 | -69% | AI Humanities, LG ThinQ Series, AI and Machine Learning, Industrial AI, AIoT |
| ”Republic of Korea history” | — | 1,573 | — | Republic of Korea/History, National Museum of Korean Contemporary History, Republic of Korea History Research Institute Cafe, … |
Observations:
- Phrase search clearly narrowed the results. “Samsung Electronics semiconductor” was reduced by 91%, returning only documents where the two words appear in close proximity
- Kim Ki-nam, Hwang Chang-gyu, and others are Samsung Electronics semiconductor division executives whose content includes the phrase “Samsung Electronics semiconductor”
- “Republic of Korea history” returned 1,573 results because Nori decomposes “Republic of Korea” into “Republic” + “of” + “Korea”, and slop=2 allows a wide range
2. Community Search Ranking — BM25 + Popularity + Recency
Original design: PageRank based on internal wiki links + anchor text
Reason for redefinition: wikiEngine is a community (bulletin board), and the[[internal link]]pattern between posts does not exist.
PageRank is only meaningful for web/wiki with a link graph; in a community, popularity and recency are the core ranking signals.
Analysis of Real-World Community Ranking
Reddit — Hot Ranking Algorithm (original source code):
s = ups - downsorder = log10(max(abs(s), 1))sign = 1 if s > 0, -1 if s < 0, else 0seconds = epoch_seconds - 1134028003hot_score = sign * order + seconds / 45000-> Vote count (log scale) multiplied by sign, plus time. Newer posts have an inherent advantage, but highly voted posts survive longer. Posts with many downvotes get a negative vote score.
Stack Overflow — Relevance + Quality + Recency (academic model):
Score = (log10(views)*4 + (answers*score)/5 + sum(answer_scores)) / ((age/3600+1) - (age-updated)/2)^1.5-> Views (log) + votes + answer quality + time decay. The formula above is a proposed model from an academic paper analyzing Stack Overflow; SO’s official algorithm is not publicly disclosed.
Naver — C-Rank + D.I.A:
- C-Rank (Creator Rank): The source’s topic-specific credibility
- D.I.A (Deep Intent Analysis): Evaluating document quality through user engagement (dwell time, likes, comments)
Common Patterns Extracted
| Signal | Stack Overflow | Naver | wikiEngine | |
|---|---|---|---|---|
| Text relevance | — (feed) | BM25-like | BM25-like | BM25 (current) |
| Popularity | upvotes | views + votes | dwell time + likes | viewCount + likeCount |
| Recency | epoch seconds | age + updated | created date + recent activity | createdAt |
| Source credibility | karma | reputation | C-Rank | — (single app) |
Common pattern:
Text relevance + Popularity (log scale) + Recency decay
Popularity Boost with Lucene FeatureField
FeatureField is the Lucene-native way to combine BM25 + popularity. Internally it encodes feature values as term frequency, making it compatible with Block-Max WAND optimization.
Saturation function: satu(S) = w * S / (S + k), k > 0
-> Same principle as BM25’s TF saturation. viewCount 1,000 yields 0.5; 10,000 yields 0.9, and so on.
Adding FeatureField during indexing:
private Document toDocument(Post post) { Document doc = new Document();
// Text fields (existing) doc.add(new TextField("title", post.getTitle(), Field.Store.YES)); doc.add(new TextField("content", post.getContent(), Field.Store.NO)); doc.add(new StoredField("id", post.getId()));
// Existing (stored, for sorting) doc.add(new LongField("viewCount", post.getViewCount(), Field.Store.YES));
// Newly added (for ranking boost, BlockMaxWAND compatible) doc.add(new FeatureField("features", "viewCount", Math.max(post.getViewCount(), 1))); // Correct 0 to 1 doc.add(new FeatureField("features", "likeCount", Math.max(post.getLikeCount(), 1)));
return doc;}Advantage of FeatureField: Since feature values are encoded as term frequency, Lucene’s BlockMaxWAND can skip entire documents when it determines that “this document’s popularity + text score cannot exceed the current threshold.” This is more efficient than the NumericDocValuesField + custom ScoreFunction approach.
Combining BM25 + popularity at search time:
// MUST: BM25 text relevanceQuery textQuery = parser.parse(escapePreservingPhrases(keyword));
// SHOULD: Popularity boost (FeatureField saturation)Query viewBoost = FeatureField.newSaturationQuery( "features", "viewCount", 3.0f, 1000);Query likeBoost = FeatureField.newSaturationQuery( "features", "likeCount", 2.0f, 100);
// SHOULD: Recency decay (exponential decay, half-life 30 days)Query recencyBoost = buildRecencyBoost(5.0f, 30);
// BooleanQuery combinationBooleanQuery.Builder builder = new BooleanQuery.Builder();builder.add(textQuery, BooleanClause.Occur.MUST);builder.add(viewBoost, BooleanClause.Occur.SHOULD);builder.add(likeBoost, BooleanClause.Occur.SHOULD);builder.add(recencyBoost, BooleanClause.Occur.SHOULD);Recency Decay
FeatureField is well-suited for static values, but recency varies depending on when the search is performed, so a different approach is needed.
Decay function comparison:
| Decay Function | Characteristics | Community Suitability |
|---|---|---|
| Gaussian | Concentrated on recent items, sharp decay for older posts | News/real-time |
| Exponential | Half-life based, smooth decay | Community (adopted) |
| Linear | Drops to 0 after a fixed period | Events/announcements |
A separate RecencyDecaySource class was implemented to read the elapsed days from the createdAt LongField and compute an exponential decay score:
score = weight * exp(-ln2 / halfLifeDays * ageDays)-> 30 days old: half weight, 60 days: 1/4, today: 1.0Rationale for a 30-day half-life: We considered the active lifespan of posts in a community forum. Reddit’s Hot Ranking decays rapidly at
seconds/45000(roughly 12.5-hour units), while Stack Overflow questions remain valid for months to years. Since wikiEngine is a general-purpose community between news-type (hours) and knowledge-type (months), we judged 1 week too aggressive and 90 days too lenient, settling on 30 days. This value will need adjustment after accumulating operational data.
Final Search Score Design
final_score = BM25(title^3, content^1) // Text relevance + w_view * satu(viewCount, k=1000) // Popularity (views) + w_like * satu(likeCount, k=100) // Quality (likes) + w_recency * exp_decay(age, lambda=30d) // Recency (half-life 30 days)
Weights: w_view = 3.0, w_like = 2.0, w_recency = 5.0
Weight determination process: BM25 scores typically range from 5 to 15, so boosts are calibrated not to overwhelm BM25. - w_recency(5.0): Referencing Reddit's seconds/45000 ratio, set so that recency does not override text relevance but lifts newer posts when scores are tied. Given community characteristics, recent posts matter more than old popular ones, hence the highest weight. - w_view(3.0): Due to satu(k=1000), viewCount saturates above 1000. Adds at most 3 points over BM25 — breaks ties without reversing relevance. - w_like(2.0): likeCount is a sparser signal than viewCount, hence lower weight.
However, these weights were derived from initial data where viewCount=0 for most posts, so re-validation via A/B testing after accumulating real operational data is necessary.Why popularity + recency instead of PageRank:
- PageRank’s core is link graphs between documents — this structure does not exist in a community
- Reddit, Stack Overflow, and Naver Cafe all use user engagement + time as the core of their ranking
- Even Google has significantly reduced PageRank’s weight in favor of user signals (Google’s Gary Illyes has publicly stated that PageRank is just one of hundreds of signals)
Note: LongField’s DocValues Type
In Lucene 9.5+, LongField automatically stores SORTED_NUMERIC DocValues internally.
When reading values, you must use getSortedNumericDocValues().
getNumericDocValues() is for the NUMERIC type only, and using it with LongField returns null, causing an NPE.
DocValues type and access API mapping: NUMERIC -> getNumericDocValues() <- NumericDocValuesField only SORTED_NUMERIC -> getSortedNumericDocValues() <- LongField, IntField, etc.Results
STOP 3 — BM25 + viewCount + likeCount + recency (full combination)
Since viewCount/likeCount are all 0 in the initial data, the practical effect of the popularity boost is minimal; only recency decay operates meaningfully.
| Query | Baseline top results | STOP 3 top results |
|---|---|---|
| Samsung Electronics | Samsung Electronics, Samsung Electronics/Software, Samsung Electronics Sales | Samsung Electronics, Samsung Electronics Hummingbird, Samsung Electronics/Software |
| Artificial intelligence technology | Artificial Intelligence, AI/Controversies, Industrial AI | Artificial Intelligence, AI Bubble, AI/Controversies |
| Programming | Programming Paradigm, Procedural Programming | Programming Language, Programming Tips, Quantum Programming |
Since viewCount/likeCount are all 0, BM25 remains dominant. Once the community operates and real user traffic accumulates, the ranking effect will become much more noticeable.
STOP 4 — Popularity Boost Verification (after setting viewCount/likeCount)
We set test data on 5 posts and updated the FeatureField via single-document re-indexing, then measured the results.
Test data:
| Title | viewCount | likeCount | Target query | STOP 3 rank |
|---|---|---|---|---|
| Samsung Electronics/Software | 50,000 | 500 | Samsung Electronics | 4th |
| Above Semiconductor | 30,000 | 300 | Samsung Electronics semiconductor | 5th |
| Industrial Artificial Intelligence | 80,000 | 800 | Artificial intelligence technology | 5th |
| National Museum of Korean Contemporary History | 40,000 | 400 | Republic of Korea history | 5th |
| Quantum Programming | 60,000 | 600 | Programming | 4th |
Ranking change results:
| Query | Boost target | STOP 3 -> STOP 4 | Change |
|---|---|---|---|
| Samsung Electronics | Samsung Electronics/Software (v:50000) | 4th -> 1st | +3 rise |
| Samsung Electronics semiconductor | Above Semiconductor (v:30000) | 5th -> 3rd | +2 rise |
| Artificial intelligence technology | Industrial AI (v:80000) | 5th -> 1st | +4 rise |
| Republic of Korea history | National Museum of Korean Contemporary History (v:40000) | 5th -> 2nd | +3 rise |
| Programming | Quantum Programming (v:60000) | 4th -> 1st | +3 rise |
Observations:
- The boosted post rose in ranking across all 5 queries — the FeatureField saturation-based popularity boost works correctly
- “Above Semiconductor” (v:30000) rose only to 3rd — it could not surpass documents with high BM25 text relevance. The balance between BM25 and popularity works appropriately
- “National Museum of Korean Contemporary History” also rose to 2nd but could not surpass “History of the Republic of Korea” which has a very high BM25 score — popularity determines ranking among documents with similar relevance, while documents with large relevance gaps are not flipped by popularity alone — a healthy structure
Limitations of verification scope: This test verified that the FeatureField saturation function operates mathematically correctly on 5 artificially configured posts. Whether this weight combination produces useful rankings among documents with diverse popularity distributions in a real community requires separate verification after accumulating operational data.
3. Search Quality Evaluation — P@10, MAP
Goal
- Build a test query set
- Quantitatively evaluate search quality using P@10 and MAP metrics
- Numerically verify the effect of the ranking changes from Section 2
Evaluation Metrics
Precision = Relevant documents retrieved / Total documents retrievedRecall = Relevant documents retrieved / Total relevant documents
P@k = Relevant documents in top k / kMAP = Mean of Average PrecisionsEvaluation Methodology
| Item | Details |
|---|---|
| Test queries | 15 (single words + compound words + various domains) |
| Comparison | BM25 only vs BM25 + viewCount + likeCount + recency |
| Relevance judgment | Title-keyword matching heuristic (relevant if 50%+ of query keywords appear in title) |
| Filter | Documents with Template: or Category: prefixes are treated as non-relevant meta pages |
| Metrics | P@10, MAP |
Limitations of the evaluation methodology: This relevance judgment measures title-based relevance only. Documents relevant only in content (e.g., “Kim Ki-nam,” a Samsung Electronics semiconductor division executive, when searching for “Samsung Electronics semiconductor”) are misjudged as non-relevant because the title lacks the keywords. Therefore, the P@10/MAP figures below should be interpreted as a lower bound of actual search quality.
Manual labeling (15 queries x 10 results = 150 judgments) was also considered, but ensuring judgment consistency was difficult as it requires wiki domain expertise. Click-log-based online evaluation is the ultimate goal; at this stage, we focused on comparing the relative effect of ranking changes (Before vs After) using an automatable title-matching heuristic.
Test query list:
Samsung Electronics, Samsung Electronics semiconductor, artificial intelligence technology,Republic of Korea history, programming, quantum mechanics, soccer, Korean War,Seoul subway, Java programming, climate change, semiconductor process, internet,democracy, physicsRelevance judgment code:
// Relevant if 50% or more of query keywords appear in the titleprivate boolean isRelevant(String title, String[] keywords) { if (title.startsWith("틀:") || title.startsWith("분류:")) return false; long matches = Arrays.stream(keywords) .filter(kw -> title.contains(kw)).count(); return matches >= Math.ceil(keywords.length / 2.0);}Results
| Search method | P@10 | MAP |
|---|---|---|
| BM25 only (Baseline) | 0.827 | 0.862 |
| BM25 + full combination | 0.853 | 0.874 |
| Improvement | +3.2% | +1.4% |
Actual measurements from 15 test queries (
/admin/lucene/evaluateendpoint).
Caveat: With 15 queries x 10 results = 150 judgments, +3.2% represents a difference of roughly 4-5 documents. The sample is too small to claim statistical significance; it is more appropriate to interpret this as the ranking change did not degrade existing quality and moved in a slightly improved direction.
Results Analysis
Why the improvement is modest (+3.2%, +1.4%):
- Among the 14.25 million documents, the vast majority have viewCount=0 and likeCount=0
- In FeatureField saturation, when S=0, boost=0, so there is virtually no popularity signal
- Once the community is in operation and views/likes accumulate, the gap is expected to be much larger
Why the BM25 Baseline is already high (P@10=0.827):
- The Nori morphological analyzer performs accurate Korean tokenization
- The title^3 weighting ensures title-matching documents surface well
- PhraseQuery(slop=2) additionally reflects word-order proximity in phrase searches
Items Reviewed but Not Separately Applied
| Item | Conclusion | Reason |
|---|---|---|
| A. NRT Dynamic Inverted Index | Already completed | SearcherManager + maybeRefresh implemented during Lucene migration |
| B. Index Compression | SKIP | stored fields ~100 bytes/doc, no ROI for LZ4 to ZSTD switch |
| C. Lucene Advanced Search Optimization | Automatically applied | Block-Max WAND, MaxScore, etc. built into Lucene 8.0+ by default |
A. NRT Dynamic Inverted Index
Already implemented during Lucene migration. NRT search operates via SearcherManager + per-operation maybeRefresh().
searcherManager.maybeRefresh()is called immediately after CRUD operations for instant search reflection- Sufficient for 14.25 million documents without a separate background thread
commit()is called only at batch completion (NRT reader refresh requires onlymaybeRefresh())
B. Index Compression
This project’s stored fields are approximately 100 bytes per document (id + title + 3 numbers). Since content is set to Store.NO and the body is not stored, the expected savings from switching LZ4 to ZSTD (~400 MB) are negligible relative to server RAM.
C. Lucene Advanced Search Optimization
In Lucene 8.0+, Block-Max WAND, MaxScore, and early termination are applied by default.
When you call IndexSearcher.search(query, k), all these optimizations operate automatically under the hood.
| Optimization | Description | Effect |
|---|---|---|
| Block-Max WAND | Skips posting lists in block units (128 entries) | 2-5x faster for high-frequency term searches |
| Impact-ordered posting | Evaluates documents with higher score contributions first | Enables top-k early termination |
| Early termination | Skips low-scoring documents after securing k results | Eliminates unnecessary computation |
In the previous k6 load test, even high-frequency tokens (“Republic of Korea”, “history”) achieved P95 of 63.72ms, confirming sufficient performance, so we delegate to Lucene without additional work.
References
Phrase search:
- Google — How we’re improving search results when you use quotes (2022)
- Elasticsearch #34283 — Nori analyzer tokenization issues
Community ranking:
- Reddit Hot Ranking original source code — reddit-archive
- Recency and quality-based ranking in CQAs — Information Processing & Management (2021)
- Naver D.I.A. Algorithm — Twinword
- Lucene FeatureField Javadoc
Lucene advanced optimization:

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.