카테고리 검색 필터링 + Facet 집계: Lucene FILTER 절 설계
목차
이전 글
분산 안정성 검증: stress 테스트 + 한계점 분석에서 분산 아키텍처(2 App + MySQL Replication + Redis 3샤드 + Kafka CDC)의 한계를 stress 테스트로 확인했습니다.
| 지표 | 100 VU | 200 VU (stress) |
|---|---|---|
| 평균 응답시간 | 42.8ms | 897ms |
| P95 | 190ms | 1,911ms |
| 에러율 | 0.00% | 0.09% |
| 병목 | App CPU ~50% | App CPU 80-100% (Lucene BM25 + Nori) |
100 VU에서 P95 ~200ms로 SLA(300ms)를 충족했고, MySQL/Redis/Kafka 모두 여유가 있었습니다. 인프라 병목이 해소되었으므로, 이 글부터는 검색 기능 자체의 고도화에 집중합니다.
1. 정상 상태: 현재 검색 아키텍처
검색 흐름
사용자 검색 요청: GET /api/v1.0/posts/search?q=프로그래밍&page=0&size=20 → PostService.search(keyword, pageable) → TieredCacheService L1(Caffeine) → L2(Redis) → Origin: → LuceneSearchService.search(keyword, pageable) → buildQuery(keyword): MUST: BM25(title^3, content^1) via MultiFieldQueryParser + Nori SHOULD: FeatureField.saturation(viewCount, w=3.0, pivot=1000) SHOULD: FeatureField.saturation(likeCount, w=2.0, pivot=100) SHOULD: RecencyDecay(halfLife=30일) → TopDocs → Lucene doc에서 ID 추출 → DB findAllById → Slice<Post> → PostSearchResponse(id, title, snippet, viewCount, likeCount, createdAt)Lucene 인덱스 필드 구성 (코드 실측)
LuceneIndexService.toDocument() (LuceneIndexService.java:161-179):
Document doc = new Document();doc.add(new KeywordField("id", post.getId().toString(), Field.Store.YES));doc.add(new TextField("title", post.getTitle(), Field.Store.YES));doc.add(new TextField("content", post.getContent(), Field.Store.NO));
if (post.getCategoryId() != null) { doc.add(new LongField("categoryId", post.getCategoryId(), Field.Store.YES));}
doc.add(new LongField("viewCount", post.getViewCount(), Field.Store.YES));doc.add(new LongField("createdAt", post.getCreatedAt().toEpochMilli(), Field.Store.YES));doc.add(new FeatureField("features", "viewCount", Math.max(post.getViewCount(), 1)));doc.add(new FeatureField("features", "likeCount", Math.max(post.getLikeCount(), 1)));핵심 사실: categoryId가 이미 LongField로 Lucene 인덱스에 포함되어 있습니다. 카테고리 “필터링”은 필드를 추가하는 문제가 아니라, 검색 쿼리(buildQuery)에 필터 절을 추가하는 문제입니다.
카테고리 데이터 현황
posts 테이블: category_id BIGINT (nullable) — FK to categories 테이블
categories 테이블: id BIGINT PK name VARCHAR (NOT NULL, UNIQUE) parent_id BIGINT (nullable) — 계층 구조 지원- Post 엔티티:
private Long categoryId;(nullable, 미분류 게시글 허용) - Category 엔티티:
name+parentId(계층 구조) - 위키피디아 임포트 시 카테고리가 함께 생성됨
기존 카테고리 관련 기능
PostController에 이미 목록 조회 시 카테고리 필터링이 존재합니다 (PostController.java:41-51):
@GetMappingpublic Slice<PostListResponse> getPosts( @RequestParam(required = false) Long categoryId, Pageable pageable) { if (categoryId != null) { return postService.getPostsByCategory(categoryId, pageable); } return postService.getLatestPosts(pageable);}하지만 이건 SQL 기반 필터링 (postRepository.findByCategoryIdOrderByCreatedAtDesc)입니다. 검색 API (GET /posts/search)에는 카테고리 필터링이 없습니다.
2. 문제 상황: 검색에서 카테고리 필터링이 불가능하다
문제 1: 검색 API에 카테고리 필터 파라미터가 없다
PostController.java:128-134의 검색 엔드포인트:
@GetMapping("/search")public Slice<PostSearchResponse> search( @RequestParam String q, Pageable pageable) { return postService.search(q, pageable);}categoryId 파라미터가 없다. 사용자가 “프로그래밍”을 검색하면 1,425만 건 전체에서 결과를 반환하며, 특정 카테고리로 좁히는 방법이 없다.
검색 결과를 보고 “이 중에서 Java 관련만 보고 싶다”는 요구를 충족할 수 없다. 목록 조회(GET /posts)에서는 카테고리 필터가 되지만, 검색에서는 안 됩니다. 기능의 비대칭입니다.
문제 2: 검색 결과의 카테고리 분포를 알 수 없다 (Facet 부재)
“프로그래밍” 검색 시 1,233건(검색 품질 평가 실측) 중 어떤 카테고리에 몇 건이 있는지 집계가 안 된다. 사용자는 맹목적으로 결과를 스크롤해야 합니다.
실제 검색엔진의 Faceted Navigation:
Google: "프로그래밍" → 탭(전체/이미지/뉴스/동영상) + 도구(기간 필터)네이버: "프로그래밍" → 탭(통합/블로그/카페/지식iN) + 카테고리 필터Stack Overflow: 태그 기반 필터링 (java, python, etc.) + 태그별 질문 수 표시Amazon: 상품 검색 → 좌측 카테고리 트리 + 각 카테고리별 건수커뮤니티 검색에서 Faceted Navigation은 기본 기능이다.
3. 문제 분석: 구조적 원인
카테고리 필터링이 안 되는 이유
categoryId가 Lucene 인덱스에 이미 있지만, buildQuery() (LuceneSearchService.java:176-197)에 카테고리 필터 절이 없다:
// 현재 buildQuery() — 카테고리 필터 없음return new BooleanQuery.Builder() .add(textQuery, BooleanClause.Occur.MUST) // 텍스트 매칭 .add(viewBoost, BooleanClause.Occur.SHOULD) // 인기도 .add(likeBoost, BooleanClause.Occur.SHOULD) // 좋아요 .add(recencyBoost, BooleanClause.Occur.SHOULD) // 최신성 .build();필드는 있는데 쿼리에서 안 쓰고 있다. LongField.newExactQuery("categoryId", categoryId)를 FILTER 절로 추가하면 필터링이 된다.
Facet 집계가 안 되는 이유
Facet 집계는 전체 매칭 문서의 카테고리별 건수를 세는 것이다. 일반 검색 쿼리는 Top-K만 반환하므로, 별도 Collector가 필요합니다.
Lucene은 lucene-facet 모듈에서 Facet API를 제공하지만, 현재 build.gradle에 lucene-facet 의존성이 없다:
// build.gradle — 현재implementation 'org.apache.lucene:lucene-core:10.3.2'implementation 'org.apache.lucene:lucene-analysis-nori:10.3.2'implementation 'org.apache.lucene:lucene-queryparser:10.3.2'implementation 'org.apache.lucene:lucene-queries:10.3.2'// lucene-facet 없음!Facet을 구현하려면 두 가지 경로가 있다:
| 방식 | 필요한 것 | 장단점 |
|---|---|---|
Lucene Facet API (lucene-facet) | SortedSetDocValuesFacetField + FacetsConfig + SortedSetDocValuesFacetCounts | 네이티브 Facet, 정확한 집계. 인덱스에 SortedSetDocValuesField 추가 + 재색인 필요 |
| 수동 집계 (현재 LongField 활용) | LongField("categoryId") 이미 존재 → 검색 결과 postIds로 DB GROUP BY | 재색인 불필요, 추가 의존성 불필요. 하지만 전체 매칭 문서가 아닌 현재 페이지 결과만 집계 가능 (정확한 Facet 아님) |
4. 대안 검토: 왜 이 방법을 선택했는가
카테고리 필터링 방식
| 방안 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Lucene LongField.newExactQuery + FILTER | 이미 인덱스에 있음, 재색인 불필요, pagination 정확 | - | 선택 |
| DB Post-filter (Lucene 결과 → DB WHERE category_id=?) | Lucene 변경 없음 | pagination 깨짐 (100건 중 50건 필터 → 페이지 절반만 표시) | 탈락 |
| Elasticsearch | 네이티브 필터링 + Aggregation | 별도 클러스터 필요, Free Tier 불가 (최소 6G RAM) | 탈락 |
DB Post-filter를 탈락시킨 구체적 이유: Lucene이 20건을 반환한 뒤 DB에서 카테고리 필터로 10건이 걸러지면, 해당 페이지에 10건만 표시됩니다. 다음 페이지도 같은 문제가 반복됩니다. Lucene에서 FILTER 절로 처리하면 처음부터 해당 카테고리 결과만 정확히 20건 반환합니다.
Facet 집계 방식
| 방안 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Lucene SortedSetDocValuesFacetCounts | 정확한 전체 매칭 문서 집계, 네이티브 | lucene-facet 의존성 추가 + SortedSetDocValuesFacetField 추가 + 전체 재색인 필요 | 재색인 시 함께 적용 |
| DB GROUP BY (검색 결과 ID로) | 재색인 불필요, 즉시 구현 가능 | Top-K 결과만 집계 (전체 매칭 문서 집계 아님), DB 왕복 추가 | 먼저 적용 |
| Taxonomy Index | 계층 Facet 지원 | 별도 인덱스 관리 비용이 큼 | 탈락 |
단계적 접근:
- 현재: 카테고리 필터링 (LongField FILTER, 재색인 불필요) + DB 기반 간이 Facet
- 쿼리 확장 구현 재색인 시:
SortedSetDocValuesFacetField추가 + Lucene 네이티브 Facet으로 전환
이렇게 하면 즉시 기능을 제공하면서, 재색인 인프라 구축과 동시에 정확한 Facet으로 업그레이드할 수 있다.
5. 구현
5-1. 카테고리 필터링: LuceneSearchService 수정
categoryId가 이미 LongField로 인덱싱되어 있으므로, search() 메서드에 categoryId 파라미터를 추가하고 FILTER 절을 추가합니다.
// LuceneSearchService — 변경public Slice<Post> search(String keyword, Long categoryId, Pageable pageable) throws IOException { IndexSearcher searcher = searcherManager.acquire(); try { Query query = buildQuery(keyword, categoryId); // categoryId 전달 // ... 기존 로직 동일 }}
private Query buildQuery(String keyword, Long categoryId) throws ParseException { // 기존 BM25 + 인기도 + 최신성 쿼리 BooleanQuery.Builder builder = new BooleanQuery.Builder() .add(textQuery, BooleanClause.Occur.MUST) .add(viewBoost, BooleanClause.Occur.SHOULD) .add(likeBoost, BooleanClause.Occur.SHOULD) .add(recencyBoost, BooleanClause.Occur.SHOULD);
// 카테고리 필터 추가 if (categoryId != null) { builder.add(LongField.newExactQuery("categoryId", categoryId), BooleanClause.Occur.FILTER); }
return builder.build();}왜 Occur.FILTER인가:
MUST는 스코어에 영향을 준다. 카테고리 필터는 “이 카테고리에 속하는가?”만 판단하면 되고, 관련도 스코어와 무관하다.FILTER는MUST와 동일하게 필수 조건이지만 스코어에 기여하지 않는다. Lucene 내부적으로 FILTER 절은 bitset 캐싱 대상이 되어, 동일 카테고리 반복 검색 시 성능 이점이 있다.- 출처: Lucene BooleanClause.Occur Javadoc
5-2. API 변경: PostController + PostService
// PostController — 검색 엔드포인트에 categoryId 추가@GetMapping("/search")public Slice<PostSearchResponse> search( @RequestParam String q, @RequestParam(required = false) Long categoryId, Pageable pageable) { return postService.search(q, categoryId, pageable);}// PostService — categoryId를 LuceneSearchService에 전달public Slice<PostSearchResponse> search(String keyword, Long categoryId, Pageable pageable) { // 캐시 키에 categoryId 포함 String cacheKey = keyword + ":" + categoryId + ":" + pageable.getPageNumber() + ":" + pageable.getPageSize(); // L1 → L2 → origin 기존 로직 동일, origin에서 categoryId 전달 Slice<Post> posts = luceneSearchService.search(keyword, categoryId, pageable); // ...}캐시 키 변경 주의: categoryId가 캐시 키에 포함되어야 합니다. 같은 키워드라도 카테고리별로 다른 결과를 반환하므로, 기존 캐시 키(keyword:page:size)에 categoryId를 추가해야 캐시 오염이 방지됩니다.
5-3. 간이 Facet: DB GROUP BY
Lucene 네이티브 Facet 대신, 검색 후 DB 집계로 카테고리 분포를 제공한다.
// PostService — 카테고리 Facet (DB 기반 간이 구현)public List<CategoryFacet> getCategoryFacets(String keyword, int topN) throws IOException { // 1. Lucene에서 검색 결과 전체 ID 추출 (상위 1000건 제한) List<Long> postIds = luceneSearchService.searchIds(keyword, 1000);
// 2. DB에서 카테고리별 건수 집계 return postRepository.countByCategoryIdIn(postIds).stream() .sorted(Comparator.comparing(CategoryFacet::count).reversed()) .limit(topN) .toList();}-- PostRepository — 카테고리별 건수 집계@Query("SELECT new com.wiki.engine.post.dto.CategoryFacet(c.id, c.name, COUNT(p)) " + "FROM Post p JOIN Category c ON p.categoryId = c.id " + "WHERE p.id IN :postIds " + "GROUP BY c.id, c.name " + "ORDER BY COUNT(p) DESC")List<CategoryFacet> countByCategoryIdIn(@Param("postIds") List<Long> postIds);한계 인지: 이 방식은 상위 1,000건에 대한 집계이므로, 전체 매칭 문서에 대한 정확한 Facet은 아닙니다. 하지만 검색 엔진에서 사용자가 관심 있는 건 상위 결과의 분포이지, 10만 번째 결과의 카테고리가 아닙니다. 상위 1,000건의 카테고리 분포는 전체와 유사한 경향을 보이므로 UX 관점에서 충분합니다. 쿼리 확장 구현의 재색인 시 Lucene Facet API로 전환합니다.
5-4. 응답 DTO 확장
// PostSearchResponse — categoryId 추가public record PostSearchResponse( Long id, String title, String snippet, Long viewCount, Long likeCount, Instant createdAt, Long categoryId // 추가) {}
// CategoryFacet — Facet 집계 결과public record CategoryFacet( Long id, String name, Long count) {}
// SearchWithFacetsResponse — 검색 + Facet 통합 응답public record SearchWithFacetsResponse( Slice<PostSearchResponse> results, List<CategoryFacet> facets) {}5-5. 전체 API 설계
기존: GET /api/v1.0/posts/search?q=프로그래밍&page=0&size=20변경: GET /api/v1.0/posts/search?q=프로그래밍&category=42&page=0&size=20
응답:{ "data": { "results": { "content": [ { "id": 123, "title": "...", "snippet": "...", "categoryId": 42, ... } ], "hasNext": true }, "facets": [ { "id": 42, "name": "프로그래밍 언어", "count": 342 }, { "id": 15, "name": "소프트웨어 공학", "count": 189 }, { "id": 7, "name": "운영체제", "count": 127 } ] }}Facet은 category 파라미터 없이 검색할 때만 반환합니다. 이미 카테고리가 선택된 상태에서 Facet을 보여주는 건 의미 없다 (드릴다운된 상태에서는 해당 카테고리만 나옴).
6. 검증: Before/After
Before: 카테고리 필터 없는 검색
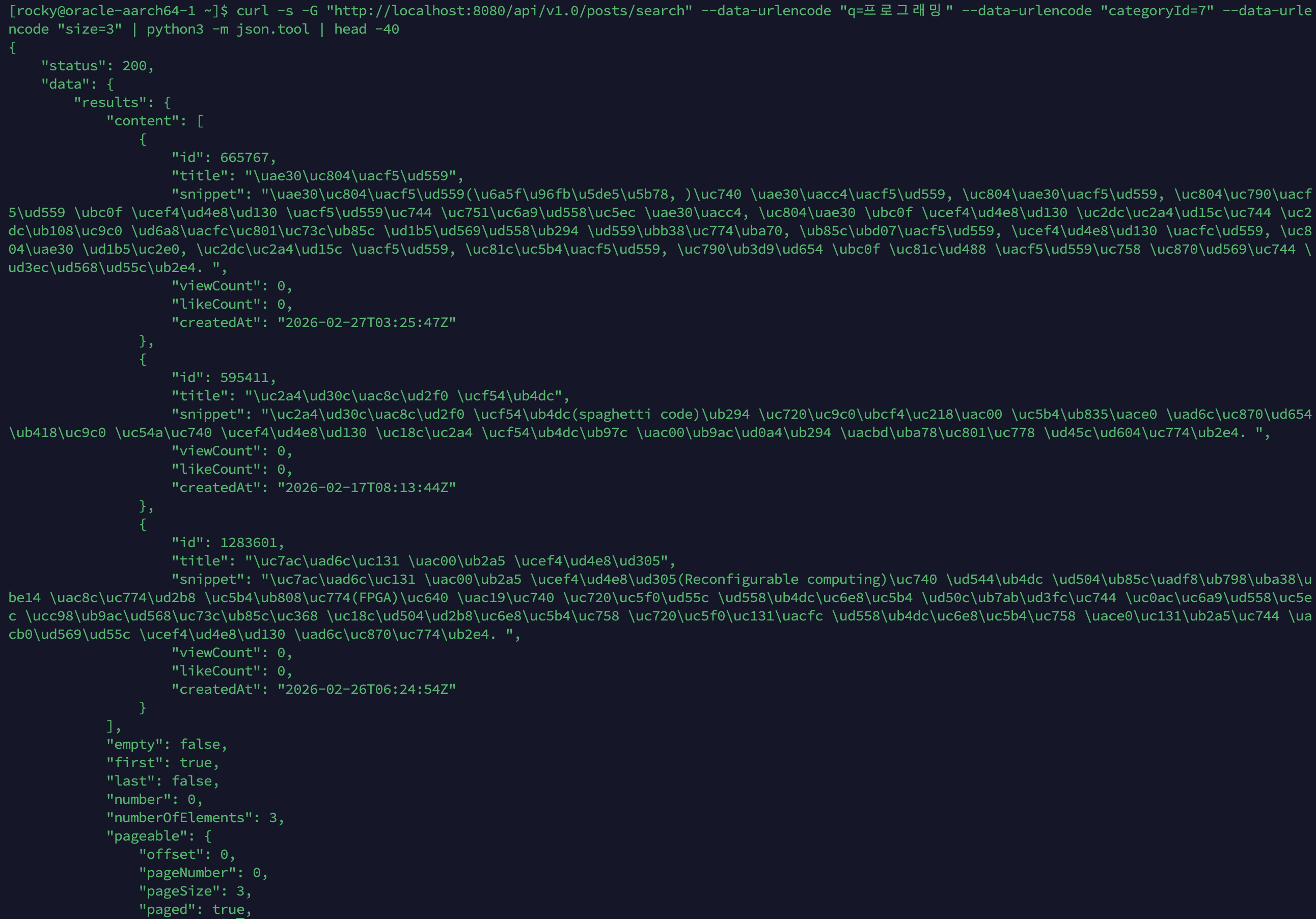
After: categoryId=7 필터 적용
“프로그래밍” 검색에
categoryId=7(컴퓨터 과학) 필터 적용 →LongField.newExactQuery("categoryId", 7)+Occur.FILTER로 해당 카테고리 결과만 반환. 기전공학, 스파게티 코드, 재구성 가능 컴퓨팅 등 컴퓨터 과학 카테고리 게시글만 노출됨.
재색인 시 함께 반영된 사항
lucene-facet의존성 추가 (org.apache.lucene:lucene-facet:10.3.2)SortedSetDocValuesFacetField("category", categoryName)인덱스 추가FacetsConfig설정 +config.build(doc)적용SortedSetDocValuesFacetCounts기반 정확한 Facet으로 전환lucene-highlighter추가 +snippetSourceStoredField + UnifiedHighlighter 전환- 전체 재색인 완료 (12,156,589건, 42GB, ~2시간)
다음 글
쿼리 확장 + Query Understanding: 검색 품질 고도화에서 동의어 확장(“AI” → “인공지능”), 오타 교정(DirectSpellChecker), Nori 사용자 사전, UnifiedHighlighter 기반 snippet 개선, 그리고 전체 재색인 인프라를 구축합니다.
출처
- Lucene BooleanClause.Occur — FILTER vs MUST
- Lucene Facet API — SortedSetDocValuesFacetCounts
- Apache Lucene SimpleSortedSetFacetsExample
Previous
In Distributed Stability — Stress Test + Limit Analysis we validated the limits of the distributed architecture (2 App + MySQL Replication + Redis 3-shard + Kafka CDC) under stress.
| Metric | 100 VU | 200 VU (stress) |
|---|---|---|
| Avg response | 42.8ms | 897ms |
| P95 | 190ms | 1,911ms |
| Error rate | 0.00% | 0.09% |
| Bottleneck | App CPU ~50% | App CPU 80-100% (Lucene BM25 + Nori) |
At 100 VU, P95 ~200ms met the 300ms SLA, and MySQL/Redis/Kafka all had headroom. With infra bottlenecks resolved, this post starts focusing on enhancing the search functionality itself.
1. Steady State — Current Search Architecture
Search flow
User search: GET /api/v1.0/posts/search?q=프로그래밍&page=0&size=20 → PostService.search(keyword, pageable) → TieredCacheService L1(Caffeine) → L2(Redis) → Origin: → LuceneSearchService.search(keyword, pageable) → buildQuery(keyword): MUST: BM25(title^3, content^1) via MultiFieldQueryParser + Nori SHOULD: FeatureField.saturation(viewCount, w=3.0, pivot=1000) SHOULD: FeatureField.saturation(likeCount, w=2.0, pivot=100) SHOULD: RecencyDecay(halfLife=30 days) → TopDocs → extract IDs from Lucene docs → DB findAllById → Slice<Post> → PostSearchResponse(id, title, snippet, viewCount, likeCount, createdAt)Lucene index field layout (verified in code)
LuceneIndexService.toDocument() (LuceneIndexService.java:161-179):
Document doc = new Document();doc.add(new KeywordField("id", post.getId().toString(), Field.Store.YES));doc.add(new TextField("title", post.getTitle(), Field.Store.YES));doc.add(new TextField("content", post.getContent(), Field.Store.NO));
if (post.getCategoryId() != null) { doc.add(new LongField("categoryId", post.getCategoryId(), Field.Store.YES));}
doc.add(new LongField("viewCount", post.getViewCount(), Field.Store.YES));doc.add(new LongField("createdAt", post.getCreatedAt().toEpochMilli(), Field.Store.YES));doc.add(new FeatureField("features", "viewCount", Math.max(post.getViewCount(), 1)));doc.add(new FeatureField("features", "likeCount", Math.max(post.getLikeCount(), 1)));Key fact: categoryId is already in the Lucene index as a LongField. Adding category “filtering” is not about adding a field — it is about adding a filter clause to the search query (buildQuery).
Category data state
posts table: category_id BIGINT (nullable) — FK to categories table
categories table: id BIGINT PK name VARCHAR (NOT NULL, UNIQUE) parent_id BIGINT (nullable) — supports hierarchy- Post entity:
private Long categoryId;(nullable — uncategorized posts allowed) - Category entity:
name+parentId(hierarchical) - Categories are created together with the Wikipedia import
Existing category-related features
PostController already supports category filtering on the listing endpoint (PostController.java:41-51):
@GetMappingpublic Slice<PostListResponse> getPosts( @RequestParam(required = false) Long categoryId, Pageable pageable) { if (categoryId != null) { return postService.getPostsByCategory(categoryId, pageable); } return postService.getLatestPosts(pageable);}But that is SQL-based filtering (postRepository.findByCategoryIdOrderByCreatedAtDesc). The search API (GET /posts/search) has no category filtering.
2. Problem — No Category Filtering in Search
Problem 1: search API has no category filter parameter
PostController.java:128-134 search endpoint:
@GetMapping("/search")public Slice<PostSearchResponse> search( @RequestParam String q, Pageable pageable) { return postService.search(q, pageable);}No categoryId parameter. Searching “프로그래밍” returns results from all 14.25M docs with no way to narrow to a category.
The user cannot satisfy “show me only Java-related ones from these results.” Listing (GET /posts) supports category filtering, but search does not — an asymmetry.
Problem 2: no insight into category distribution of results (no Facet)
Among the 1,233 hits (measured in search-quality) for “프로그래밍”, we cannot aggregate how many fall in each category. The user has to scroll blindly.
Faceted Navigation in real search engines:
Google: "프로그래밍" → tabs (All/Images/News/Video) + tools (date filter)Naver: "프로그래밍" → tabs (Integrated/Blog/Cafe/Knowledge iN) + category filtersStack Overflow: tag-based filtering (java, python, etc.) + count per tagAmazon: product search → left category tree + count per categoryIn community search, Faceted Navigation is a baseline feature.
3. Analysis — Structural Cause
Why category filtering does not work
categoryId exists in the Lucene index, but buildQuery() (LuceneSearchService.java:176-197) has no category filter clause:
// current buildQuery() — no category filterreturn new BooleanQuery.Builder() .add(textQuery, BooleanClause.Occur.MUST) // text matching .add(viewBoost, BooleanClause.Occur.SHOULD) // popularity .add(likeBoost, BooleanClause.Occur.SHOULD) // likes .add(recencyBoost, BooleanClause.Occur.SHOULD) // recency .build();The field exists but is not used in the query. Adding LongField.newExactQuery("categoryId", categoryId) as a FILTER clause makes filtering work.
Why Facet aggregation does not work
Facet aggregation means counting matching docs per category across the entire matching set. A normal search query returns only top-K, so a separate Collector is needed.
Lucene provides a Facet API in the lucene-facet module, but the current build.gradle has no lucene-facet dependency:
// build.gradle — currentimplementation 'org.apache.lucene:lucene-core:10.3.2'implementation 'org.apache.lucene:lucene-analysis-nori:10.3.2'implementation 'org.apache.lucene:lucene-queryparser:10.3.2'implementation 'org.apache.lucene:lucene-queries:10.3.2'// no lucene-facet!Two paths to implement Facets:
| Approach | Required | Pros / Cons |
|---|---|---|
Lucene Facet API (lucene-facet) | SortedSetDocValuesFacetField + FacetsConfig + SortedSetDocValuesFacetCounts | native Facet, exact aggregation. Requires adding SortedSetDocValuesField to the index + full reindex |
| Manual aggregation (use existing LongField) | LongField("categoryId") already exists → DB GROUP BY on result postIds | no reindex, no extra dependencies. But aggregates only the current page, not the full match set (not exact Facet) |
4. Alternatives — Why I Picked This
Category filtering approach
| Option | Pro | Con | Verdict |
|---|---|---|---|
| Lucene LongField.newExactQuery + FILTER | already in index, no reindex, pagination correct | - | chosen |
| DB Post-filter (Lucene results → DB WHERE category_id=?) | no Lucene change | breaks pagination (100 → 50 after filter → page shows half) | rejected |
| Elasticsearch | native filter + Aggregation | needs separate cluster, impossible on Free Tier (≥6GB RAM) | rejected |
Why DB Post-filter is rejected, concretely: Lucene returns 20, then DB filtering by category drops it to 10 — only 10 shown on that page. Same problem repeats on the next page. Doing it in Lucene with FILTER returns exactly 20 results from that category from the start.
Facet aggregation approach
| Option | Pro | Con | Verdict |
|---|---|---|---|
| Lucene SortedSetDocValuesFacetCounts | exact full-match aggregation, native | adds lucene-facet dependency + SortedSetDocValuesFacetField + full reindex required | applied during reindex |
| DB GROUP BY (over result IDs) | no reindex, instant to implement | aggregates only top-K, not the whole match set, extra DB round-trip | applied first |
| Taxonomy Index | supports hierarchical Facets | high cost of managing a separate index | rejected |
Phased approach:
- Now: category filtering (LongField FILTER, no reindex) + DB-based approximate Facet
- At the query expansion reindex: add
SortedSetDocValuesFacetField+ switch to native Lucene Facet
This way we deliver the feature instantly while upgrading to exact Facets together with the reindex infrastructure build-out.
5. Implementation
5-1. Category filtering — modifying LuceneSearchService
Since categoryId is already indexed as LongField, we add a categoryId parameter to search() and a FILTER clause.
// LuceneSearchService — changepublic Slice<Post> search(String keyword, Long categoryId, Pageable pageable) throws IOException { IndexSearcher searcher = searcherManager.acquire(); try { Query query = buildQuery(keyword, categoryId); // pass categoryId // ... existing logic identical }}
private Query buildQuery(String keyword, Long categoryId) throws ParseException { // existing BM25 + popularity + recency BooleanQuery.Builder builder = new BooleanQuery.Builder() .add(textQuery, BooleanClause.Occur.MUST) .add(viewBoost, BooleanClause.Occur.SHOULD) .add(likeBoost, BooleanClause.Occur.SHOULD) .add(recencyBoost, BooleanClause.Occur.SHOULD);
// add category filter if (categoryId != null) { builder.add(LongField.newExactQuery("categoryId", categoryId), BooleanClause.Occur.FILTER); }
return builder.build();}Why Occur.FILTER:
MUSTaffects scoring. Category filter is a “is it in this category?” decision — relevance score is irrelevant.FILTERis required likeMUSTbut does not contribute to scoring. Internally Lucene treats FILTER clauses as bitset-cacheable, giving a perf benefit on repeated queries with the same category.- Source: Lucene BooleanClause.Occur Javadoc
5-2. API change — PostController + PostService
// PostController — add categoryId to the search endpoint@GetMapping("/search")public Slice<PostSearchResponse> search( @RequestParam String q, @RequestParam(required = false) Long categoryId, Pageable pageable) { return postService.search(q, categoryId, pageable);}// PostService — pass categoryId down to LuceneSearchServicepublic Slice<PostSearchResponse> search(String keyword, Long categoryId, Pageable pageable) { // include categoryId in the cache key String cacheKey = keyword + ":" + categoryId + ":" + pageable.getPageNumber() + ":" + pageable.getPageSize(); // L1 → L2 → origin same logic; pass categoryId at origin Slice<Post> posts = luceneSearchService.search(keyword, categoryId, pageable); // ...}Cache-key caveat: categoryId must be in the cache key. The same keyword returns different results per category, so without adding categoryId to the existing key (keyword:page:size), cache pollution would occur.
5-3. Approximate Facet — DB GROUP BY
Instead of native Lucene Facets, provide category distribution via DB aggregation after search.
// PostService — category Facet (DB-based approximate impl)public List<CategoryFacet> getCategoryFacets(String keyword, int topN) throws IOException { // 1. extract all result IDs from Lucene (cap at 1000) List<Long> postIds = luceneSearchService.searchIds(keyword, 1000);
// 2. aggregate counts per category in DB return postRepository.countByCategoryIdIn(postIds).stream() .sorted(Comparator.comparing(CategoryFacet::count).reversed()) .limit(topN) .toList();}-- PostRepository — counts per category@Query("SELECT new com.wiki.engine.post.dto.CategoryFacet(c.id, c.name, COUNT(p)) " + "FROM Post p JOIN Category c ON p.categoryId = c.id " + "WHERE p.id IN :postIds " + "GROUP BY c.id, c.name " + "ORDER BY COUNT(p) DESC")List<CategoryFacet> countByCategoryIdIn(@Param("postIds") List<Long> postIds);Acknowledged limit: this aggregates only the top-1,000 results, so it is not an exact Facet over the full match set. But in search engines what users actually care about is the distribution of top results, not the category of the 100,000th. The top-1,000 distribution mirrors the overall trend, so it is good enough UX-wise. Will switch to the Lucene Facet API during the query expansion reindex.
5-4. Response DTO extension
// PostSearchResponse — add categoryIdpublic record PostSearchResponse( Long id, String title, String snippet, Long viewCount, Long likeCount, Instant createdAt, Long categoryId // added) {}
// CategoryFacet — facet aggregation resultpublic record CategoryFacet( Long id, String name, Long count) {}
// SearchWithFacetsResponse — combined search + facet responsepublic record SearchWithFacetsResponse( Slice<PostSearchResponse> results, List<CategoryFacet> facets) {}5-5. Full API design
Before: GET /api/v1.0/posts/search?q=프로그래밍&page=0&size=20After: GET /api/v1.0/posts/search?q=프로그래밍&category=42&page=0&size=20
Response:{ "data": { "results": { "content": [ { "id": 123, "title": "...", "snippet": "...", "categoryId": 42, ... } ], "hasNext": true }, "facets": [ { "id": 42, "name": "Programming Languages", "count": 342 }, { "id": 15, "name": "Software Engineering", "count": 189 }, { "id": 7, "name": "OS", "count": 127 } ] }}Facets are returned only when no
categoryis selected. Showing Facets when a category is already selected is meaningless (the drilled-down result is just that category).
6. Verification — Before/After
Before: search without category filter
After: with categoryId=7 filter
Searching “프로그래밍” with
categoryId=7(Computer Science):LongField.newExactQuery("categoryId", 7)+Occur.FILTERreturns only that category’s results. Posts on mechatronics, spaghetti code, reconfigurable computing, etc. — only Computer Science posts.
Items applied together at the reindex
- Added
lucene-facetdependency (org.apache.lucene:lucene-facet:10.3.2) - Added
SortedSetDocValuesFacetField("category", categoryName)to the index FacetsConfigsetup +config.build(doc)applied- Switched to exact Facets via
SortedSetDocValuesFacetCounts - Added
lucene-highlighter+snippetSourceStoredField + UnifiedHighlighter - Full reindex completed (12,156,589 docs, 42GB, ~2 hours)
Next
In Query Expansion + Query Understanding — Search Quality Enhancement we add synonym expansion (“AI” → “인공지능”), typo correction (DirectSpellChecker), the Nori user dictionary, snippet improvements via UnifiedHighlighter, and the full reindex infrastructure.
Sources

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.