쿼리 확장 + Query Understanding: 동의어·오타 교정·snippet 고도화
목차
이전 글
카테고리 검색 필터링 + Facet 집계에서 Lucene Occur.FILTER 절로 카테고리 필터링을 구현하고, DB GROUP BY 간이 Facet으로 카테고리 분포를 제공했습니다.
| 지표 | 결과 |
|---|---|
| 카테고리 필터링 | 기존 LongField(“categoryId”) + Occur.FILTER (재색인 불필요) |
| snippet 마크업 제거 | 위키피디아/나무위키/영문위키 마크업 25개 패턴 제거 |
| Facet 집계 | 현재 namespace 카테고리(“일반 문서” 97%)로는 의미 없어 재색인 후 적용 |
검색 결과 가독성은 개선되었지만, 검색 품질(Recall + Precision) 자체의 한계가 남아 있습니다.
1. 정상 상태: 현재 검색 파이프라인
검색 흐름

BM25 설정
| 파라미터 | 현재 값 | 의미 |
|---|---|---|
| k1 | 1.2 (기본값) | TF 포화 속도, 값이 클수록 term 반복에 민감 |
| b | 0.75 (기본값) | 문서 길이 정규화, 1이면 긴 문서 강하게 페널티 |
| 필드 가중치 | title:3, content:1 | MultiFieldQueryParser로 적용 |
BM25 변형(BM25+, BM25L, BM25F) 검토 결과, 뉴스 코퍼스 3개 실험에서 변형 간 유의미한 성능 차이는 없었다. MultiFieldQueryParser로 title:3, content:1 가중치를 이미 적용 중이므로 BM25F의 효과를 일부 대체하고 있습니다.
결론: 기본 BM25에서 시작하고, 검색 품질 이슈가 실제로 발생하면 변형을 검토합니다.
2. 문제 상황: 세 가지 검색 품질 한계

- 동의어 미지원: “AI” 검색 시 “인공지능” 문서 누락으로 Recall 손실
- 오타 교정 미지원: “프로그래링” 검색 시 결과 0건으로 사용자 이탈
- 복합어 과분해: Nori
DecompoundMode.DISCARD가 “운동화”를 “운동”+“화”로 분해하여 Precision 저하
정리
| 문제 | 영향 | 현재 대응 |
|---|---|---|
| 동의어 미지원 | Recall 손실 | 없음 |
| 오타 교정 미지원 | 검색 실패 (0건) | 없음 |
| 복합어 과분해 | Precision 저하 | 없음 (Nori 기본값 사용) |
3. 문제 분석: 검색 품질 개선의 두 축

이 두 축이 검색 쿼리가 Lucene에 도달하기 전에 처리되어야 합니다. 현재 파이프라인에서 정규화(소문자 변환)만 있고, Query Understanding과 Query Expansion이 누락되어 있습니다.
전제조건: 전체 재색인 인프라
동의어 처리 방식에 따라 전체 재색인이 필요할 수 있다:
- 쿼리 타임 동의어: 재색인 불필요 (검색 시점에 쿼리를 확장)
- 인덱스 타임 동의어 (SynonymGraphFilter): 재색인 필요
- Nori 사용자 사전 변경: 재색인 필요
전체 재색인 + 무중단 교체 인프라를 이 글에서 먼저 구축합니다.
4. 대안 검토
동의어 처리 방식
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| DB 기반 쿼리 확장 | 동의어 추가/삭제 즉시 반영, 가중치 제어, 관리 API 가능 | 매 쿼리마다 DB 조회 (Caffeine 캐시로 완화) | 선택 |
| Lucene SynonymGraphFilter (파일) | 현업 표준, 쿼리 타임이면 재색인 불필요 | 파일 관리 (동적 변경 시 서버 재시작 or reload) | 최종 목표 (재색인 시 전환) |
| SynonymGraphFilter (인덱스 타임) | DB 조회 없음, 분석기 체인 통합 | 동의어 변경 시 전체 재색인 | 탈락 (재색인 비용) |
| 벡터 임베딩 (Word2Vec/BERT) | “AI”↔“인공지능”을 자동 학습, 동의어 테이블 불필요 | 임베딩 모델 + 벡터 DB 필요, ARM 서버 추론 비용 | 탈락 (AI 검색 요약에서 부분 도입 검토) |
| Elasticsearch Synonym API | ES 생태계 네이티브, 동적 관리 | ES 별도 운영 필요, Free Tier 불가 | 탈락 |
선택 근거: Elastic 공식 블로그도 “인덱스 크기 영향 없음, term 통계 불변, 동의어 변경 시 재색인 불필요”를 이유로 쿼리 타임 동의어를 권장한다. DB 기반으로 먼저 운영 유연성을 확보하고, 재색인 시 SynonymGraphFilter 파일로 전환합니다.
쿼리 타임 동의어가 IDF를 왜곡하지 않는 이유: 인덱스 타임 동의어는 인덱스에 동의어 term이 추가되어 document frequency가 인위적으로 높아지고, BM25 IDF 계산을 왜곡한다. 예를 들어 “AI”를 인덱싱할 때 “인공지능”도 함께 추가하면, “인공지능”의 DF가 실제보다 부풀려져 해당 term의 가중치가 낮아진다. 쿼리 타임 확장은 인덱스 term 통계가 불변이므로 이 문제가 없습니다. OpenSource Connections의 “Solr Synonyms Mea Culpa”에서도 인덱스 타임 동의어의 IDF 왜곡을 실사례로 경고합니다.
벡터 방식을 선택하지 않은 이유: Eugene Yan의 “Search: Query Matching”에서 정리한 것처럼 검색 시스템은 Lexical(BM25) → Graph(동의어) → Embedding(벡터) 순서로 진화합니다. 현재 wikiEngine은 BM25까지 완료되었으므로, 다음 단계는 동의어(Graph)입니다. 동의어 테이블 수십 개로 해결되는 문제에 임베딩 모델 + 벡터 DB를 도입하면 현재 요구사항 대비 운영 복잡도와 추론 비용이 더 크게 늘어납니다.
오타 교정 방식
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Lucene DirectSpellChecker | 인덱스가 곧 사전, 별도 구축 불필요 | 편집 거리(Damerau-Levenshtein) 기반이며 한국어 음절 단위 비교라 자모 교정에 약함. lucene-suggest 모듈 의존성 필요 | 선택 |
| 검색 로그 기반 “Did you mean?” | 실제 사용자 쿼리 기반, 정확도 높음 | 로그 축적 필요 (cold start) | 로그 축적 후 보강 |
| SymSpell | O(1) 조회, 매우 빠름 | 메모리 사용 큼, 별도 사전 구축 | 규모 커지면 검토 |
| LLM 기반 교정 | 문맥 이해 가능 | 응답 지연, 비용 | 탈락 (240ms SLA 위반) |
복합어 분리 방식
| 방식 | 장점 | 단점 | 판단 |
|---|---|---|---|
| Nori 사용자 사전 | ”운동화”를 단일 토큰 보존 | 사전 유지보수 필요 | 선택 |
| DecompoundMode.MIXED | 원형+분해 토큰 동시 보존 | position 겹침으로 PhraseQuery 불안정 (검색 품질 평가 분석) | 탈락 |
| Dual Field (title_exact) | 비분석 필드로 정확 매칭 | 인덱스 크기 증가, 쿼리 복잡도 증가 | 사용자 사전으로 부족 시 검토 |
5. 구현
Part 0: 전체 재색인 + 무중단 인덱스 교체 인프라
재색인 전략: 변경사항을 모아서 1회 실행
재색인이 필요한 변경사항이 여러 개 있다:
| 변경사항 | 재색인 필요? |
|---|---|
snippetSource StoredField 추가 | YES |
| 동의어 확장 (쿼리 타임) | NO |
| DirectSpellChecker (기존 인덱스 사용) | NO |
| Nori 사용자 사전 변경 | YES |
| 카테고리 재매핑 + SortedSetDocValuesFacetField | YES |
전략: 코드를 먼저 모두 구현하고, 재색인은 1회만 실행합니다.
| 전략 | 재색인 횟수 | 소요 시간 | 서비스 영향 | 판단 |
|---|---|---|---|---|
| Part별 재색인 | 3회 | ~수십 시간 (수 시간 × 3) | 서비스 영향 3배 | 탈락 |
| 한번에 모아서 | 1회 | ~수 시간 | 최소 | 선택 |
현업에서도 인덱스 변경사항을 모아서 한 번에 재색인하는 것이 표준입니다. Elasticsearch의 Blue-Green 재색인 패턴(Elastic 공식)에서도 “새 인덱스를 새 매핑으로 한 번에 구축 → alias swap”을 권장합니다. 변경마다 재색인하면 1,425만 건 × 여러 번 = 불필요한 시간과 I/O 낭비입니다.
재색인 전까지의 동작:
- snippetSource 없음 → UnifiedHighlighter가 null 반환 →
PostSearchResponse.from(post)fallback (앞 150자) - Nori 사전 미변경 → 기존 분석기로 검색 (정확도는 약간 떨어지지만 동작함)
무중단 인덱스 교체: Directory Swap
// 1. 새 디렉토리에 전체 색인Path newIndexPath = Paths.get("/data/lucene/wiki-index-" + version);Directory newDir = MMapDirectory.open(newIndexPath);IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter newWriter = new IndexWriter(newDir, config);
// 2. DB 전체 스캔 + 배치 색인 (2000건 단위)try (Stream<Post> posts = postRepository.streamAll()) { List<Document> batch = new ArrayList<>(2000); posts.forEach(post -> { batch.add(toDocument(post)); if (batch.size() >= 2000) { newWriter.addDocuments(batch); batch.clear(); } }); if (!batch.isEmpty()) newWriter.addDocuments(batch);}newWriter.commit();newWriter.close();
// 3. 심볼릭 링크 원자적 교체Path symlink = Paths.get("/data/lucene/wiki-index");Path tempLink = Paths.get("/data/lucene/wiki-index-tmp");Files.createSymbolicLink(tempLink, newIndexPath);Files.move(tempLink, symlink, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.ATOMIC_MOVE);
// 4. SearcherManager를 새 Directory로 재생성// MMapDirectory는 파일을 메모리 매핑하므로, 심볼릭 링크 교체만으로는 부족// SearcherManager를 닫고 새 Directory로 다시 생성해야 함searcherManager.close();Directory currentDir = MMapDirectory.open(symlink);searcherManager = new SearcherManager(currentDir, null);주의: MMapDirectory는 파일을 메모리에 매핑하므로, 심볼릭 링크를 교체해도 이미 매핑된 파일은 이전 디렉토리를 계속 참조합니다. 반드시 SearcherManager를 재생성해야 합니다.
동시 색인 방지
private final AtomicBoolean fullReindexInProgress = new AtomicBoolean(false);
public void incrementalIndex(Post post) throws IOException { if (fullReindexInProgress.get()) { log.warn("Full reindex in progress, skipping incremental for post={}", post.getId()); // CDC 이벤트는 Kafka에 남아있으므로, 재색인 완료 후 자동 재처리 return; } writer.updateDocument( new Term("id", String.valueOf(post.getId())), toDocument(post));}재색인 실측 수치
| 항목 | 수치 |
|---|---|
| 총 문서 수 | 12,156,589건 |
| 인덱스 크기 | 42GB |
| 재색인 소요시간 | ~2시간 (로컬 Mac M2 Pro) |
| 세그먼트 병합 | forceMerge(5) |
| 배치 크기 | 1,000건 (Producer-Consumer 파이프라인) |
Part 0.5: Snippet 개선 (UnifiedHighlighter)
현재 방식의 한계

현업 표준: Lucene UnifiedHighlighter
Elasticsearch의 기본 하이라이터(unified)는 내부적으로 Lucene UnifiedHighlighter를 사용합니다. 텍스트를 문장 단위로 분리한 뒤 BM25로 각 문장을 스코어링하여, 검색 쿼리와 가장 관련도 높은 문장을 snippet으로 반환합니다.
출처: Elasticsearch Highlighting Reference, Reverse Engineering Elasticsearch Highlights
| 방식 | 내부 구현 | 특징 |
|---|---|---|
| unified (기본, 권장) | Lucene UnifiedHighlighter | BM25 문장 스코어링, offset 기반 |
| plain (레거시) | Lucene Highlighter | 단순 term 매칭, 대형 문서에서 느림 |
| fvh | FastVectorHighlighter | TermVector 필요, 빠르지만 인덱스 크기 증가 |
구현
의존성 추가:
implementation 'org.apache.lucene:lucene-highlighter:10.3.2'implementation 'org.apache.lucene:lucene-suggest:10.3.2' // DirectSpellChecker인덱스 필드 변경 (재색인 필요):
// 방안 A: content를 Store.YES로 변경 (단순하지만 인덱스 100GB+)doc.add(new TextField("content", post.getContent(), Field.Store.YES));
// 방안 B: 별도 snippet_source 저장 (앞 500자만, 인덱스 크기 최소화) — 선택String snippetSource = post.getContent().substring( 0, Math.min(post.getContent().length(), 500));doc.add(new StoredField("snippetSource", snippetSource));// content는 Store.NO 유지 (검색용만)방안 B 선택 근거: content 전체를 Store.YES로 하면 1,425만 건 × 평균 6,586자 = 인덱스 크기 100GB+ 폭증. 앞 500자만 저장하면 ~7GB 추가로 인덱스 27GB 수준. 검색어가 문서 앞부분 500자 안에 있을 확률이 높고(제목, 서론, Infobox), 500자 밖의 검색어는 현재 방식(DB 조회 후 자르기)으로 fallback.
검색 시 Highlighter 적용:
UnifiedHighlighter highlighter = UnifiedHighlighter.builder(searcher, analyzer) .withFieldMatcher(field -> "snippetSource".equals(field)) .build();String[] snippets = highlighter.highlight("snippetSource", query, topDocs, 1);
// snippet이 없으면 (500자 밖에 검색어가 있는 경우) DB fallbackfor (int i = 0; i < results.size(); i++) { if (snippets[i] != null && !snippets[i].isBlank()) { results.get(i).setSnippet(snippets[i]); } // else: PostSearchResponse.createSnippet()으로 fallback (현재 방식)}Before/After
| 지표 | Before (앞 150자) | After (UnifiedHighlighter) |
|---|---|---|
| snippet 관련도 | 검색어와 무관한 앞부분 | 검색어 주변 맥락 |
| 검색어 하이라이트 | 없음 | <b>키워드</b> 태그 |
| 인덱스 크기 | ~20GB | ~42GB (+snippetSource 500자 + 기타 필드) |
| 응답시간 추가 비용 | 0ms | ~1-3ms (Highlighter 처리) |
Part 1: 동의어 확장 (Query Expansion)
동의어 사전
CREATE TABLE synonyms ( id BIGINT AUTO_INCREMENT PRIMARY KEY, term VARCHAR(100) NOT NULL, synonym VARCHAR(100) NOT NULL, weight DOUBLE DEFAULT 1.0, INDEX idx_term (term), INDEX idx_synonym (synonym));
-- 수동 등록INSERT INTO synonyms (term, synonym, weight) VALUES ('AI', '인공지능', 1.0), ('인공지능', 'AI', 1.0), ('ML', '머신러닝', 1.0), ('머신러닝', 'ML', 1.0), ('DB', '데이터베이스', 1.0), ('데이터베이스', 'DB', 1.0);위키 리다이렉트 활용: 자동 동의어 추출
위키피디아 데이터에는 리다이렉트 정보가 포함되어 있습니다. 이를 활용하면 동의어를 자동 추출할 수 있습니다.
SELECT redirect_title AS term, title AS synonym, 0.8 AS weightFROM postsWHERE redirect_title IS NOT NULL;-- 예: "인공 지능" → "인공지능", "AI" → "인공지능"QueryExpansionService
@Servicepublic class QueryExpansionService {
private final SynonymRepository synonymRepository;
/** * 원래 쿼리의 각 term에 대해 동의어를 찾아 확장한다. * term당 최대 3개 동의어로 제한하여 쿼리 폭발을 방지한다. */ public List<ExpandedTerm> expandQuery(List<String> originalTerms) { List<ExpandedTerm> expanded = new ArrayList<>();
for (String term : originalTerms) { // 원래 term은 boost=1.0 expanded.add(new ExpandedTerm(term, 1.0, true));
// 동의어는 가중치 적용, 최대 3개 List<Synonym> synonyms = synonymRepository.findByTerm(term); synonyms.stream() .limit(3) .forEach(syn -> expanded.add( new ExpandedTerm(syn.getSynonym(), syn.getWeight(), false) )); } return expanded; }}Lucene 쿼리 빌드에 동의어 통합
// 기존: parser.parse("AI")// → TermQuery("ai")
// 동의어 확장 후: "AI" + "인공지능" (weight=1.0)// → BooleanQuery(// TermQuery("ai")^1.0, SHOULD// TermQuery("인공지능")^1.0 SHOULD// )동의어 확장된 term을 BooleanQuery(SHOULD)로 묶어, 원래 term이나 동의어 중 하나라도 매칭되면 결과에 포함시킨다.
주의사항
| 이슈 | 설명 | 해결 |
|---|---|---|
| 쿼리 폭발 | 동의어가 많으면 term 수 급증 → posting list 조회 증가 | term당 동의어 최대 3개 제한 |
| 의미 변질 | ”Apple” → “사과” vs “애플(회사)“ | 문맥 기반 동의어 선택은 고급 기능, 이 단계에서는 미구현 |
| 성능 저하 | term 수 증가 → 검색 시간 증가 | 동의어에 낮은 가중치, Caffeine 캐싱 활용 |
| DB 조회 비용 | 매 쿼리마다 DB 조회 | 동의어 사전을 Caffeine 캐시에 올림 (TTL 30분). 캐시 미스 시 ~1-2ms 추가 |
Part 2: Query Understanding
2-1. 오타 교정: Lucene DirectSpellChecker
@Servicepublic class SpellCheckService {
private final SearcherManager searcherManager;
/** * Lucene 인덱스의 term dictionary를 사전으로 활용하여 * 편집 거리(Damerau-Levenshtein) 기반 오타 교정을 수행한다. * * DirectSpellChecker는 별도 사전 구축 없이, 인덱스가 곧 사전이다. * * 한국어 한계: * - 음절 단위 비교이므로 "컴퓨텨"→"컴퓨터"(편집 거리 1)는 잡히지만, * "프로그래링"→"프로그래밍"(ㅁ 누락)은 자모 레벨에서 1글자 차이인데 * 음절 레벨에서도 편집 거리 1이라 잡힘. * - 진짜 문제: 인덱스에 해당 term이 없으면 후보를 못 찾음. * Nori가 복합어를 분해하므로 인덱스 term이 원형과 다를 수 있다. * - 이 한계는 검색 로그 기반 "Did you mean?"으로 보강한다. */ public Optional<String> suggestCorrection(String query) throws IOException { IndexSearcher searcher = searcherManager.acquire(); try { DirectSpellChecker spellChecker = new DirectSpellChecker(); spellChecker.setMaxEdits(2); // 최대 편집 거리 2 spellChecker.setMinPrefix(1); // 첫 글자는 일치해야 함 spellChecker.setMinQueryLength(2); // 2글자 미만은 교정 안 함
String[] tokens = tokenize(query); List<String> corrected = new ArrayList<>(); boolean hasCorrected = false;
for (String token : tokens) { SuggestWord[] suggestions = spellChecker.suggestSimilar( new Term("title", token), 1, // 최대 1개 제안 searcher.getIndexReader() );
if (suggestions.length > 0) { corrected.add(suggestions[0].string); hasCorrected = true; } else { corrected.add(token); } }
return hasCorrected ? Optional.of(String.join(" ", corrected)) : Optional.empty(); } finally { searcherManager.release(searcher); } }}2-2. 복합어 보존: Nori 사용자 사전
Nori가 “운동화”를 “운동”+“화”로 분해하는 문제를 사용자 사전으로 해결합니다.
# userdict_ko.txt — Nori 사용자 사전운동화에어맥스나이키인공지능머신러닝데이터베이스- 수동 복합어 30개 + open-korean-text (Apache 2.0) wikipedia_title_nouns 158,509개 = 총 158,539개
- 사용자 사전 변경 시 전체 재색인 필요 (Analyzer가 바뀌면 인덱스의 term과 쿼리의 term이 불일치)
Part 3: 검색 파이프라인 통합

6. 검증: Before/After 실측
Before 1: “자바 가비지 컬렉션” 검색, snippet이 검색어와 무관
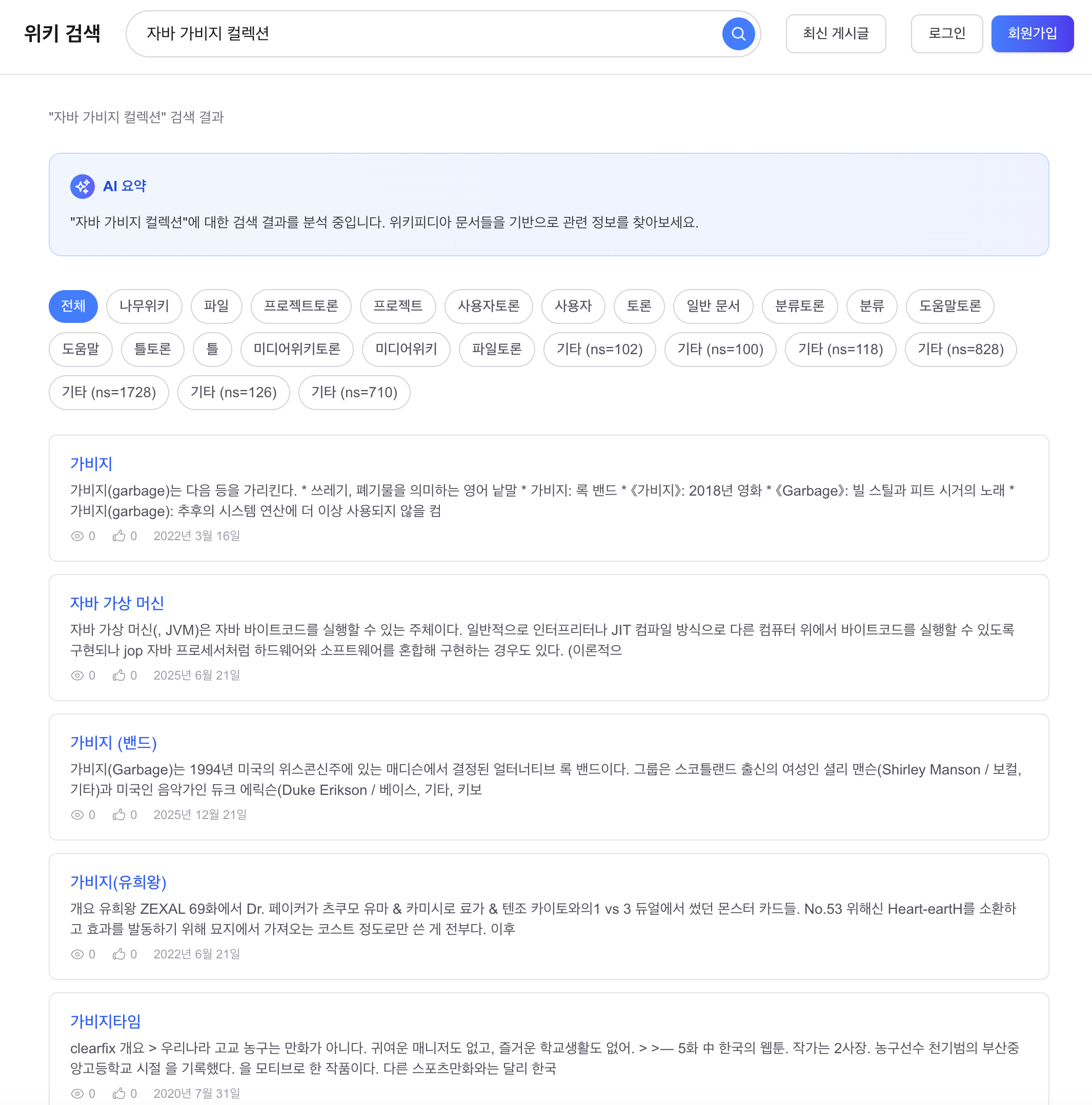
관찰:
- 1위 “가비지”: snippet이 “가비지(garbage)는 다음 등을 가리킨다. 쓰레기, 폐기물을 의미하는 영어 낱말…”로, 자바 GC와 무관한 동음이의어 문서
- 2위 “자바 가상 머신”: snippet이 “자바 가상 머신(, JVM)은 자바 바이트코드를 실행할 수 있는 주체이다…”로, GC와 관련 있지만 snippet 앞 150자에 “가비지 컬렉션”이라는 단어가 없음
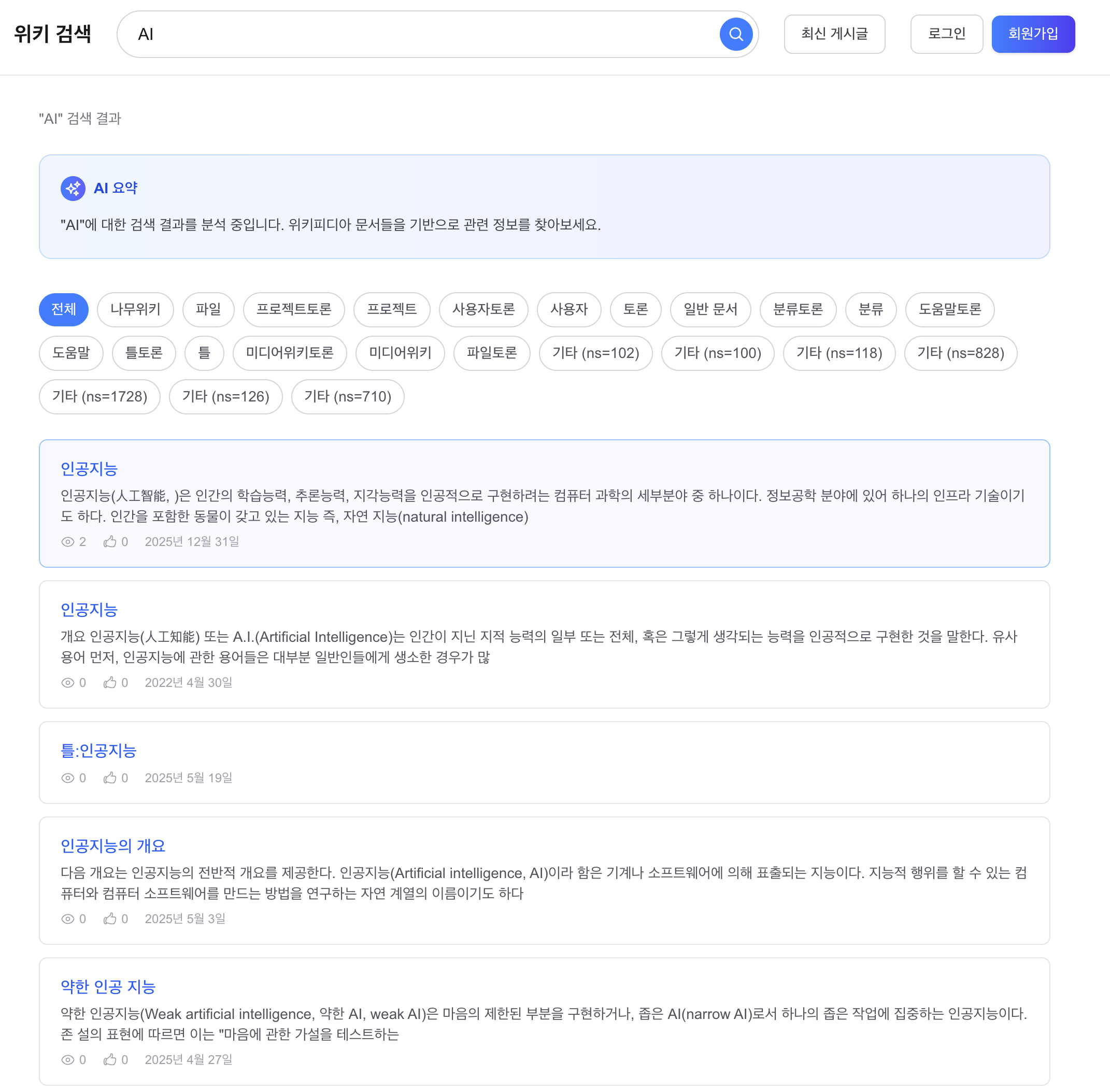
Before 2: “AI” 검색, “인공지능” 문서 미포함
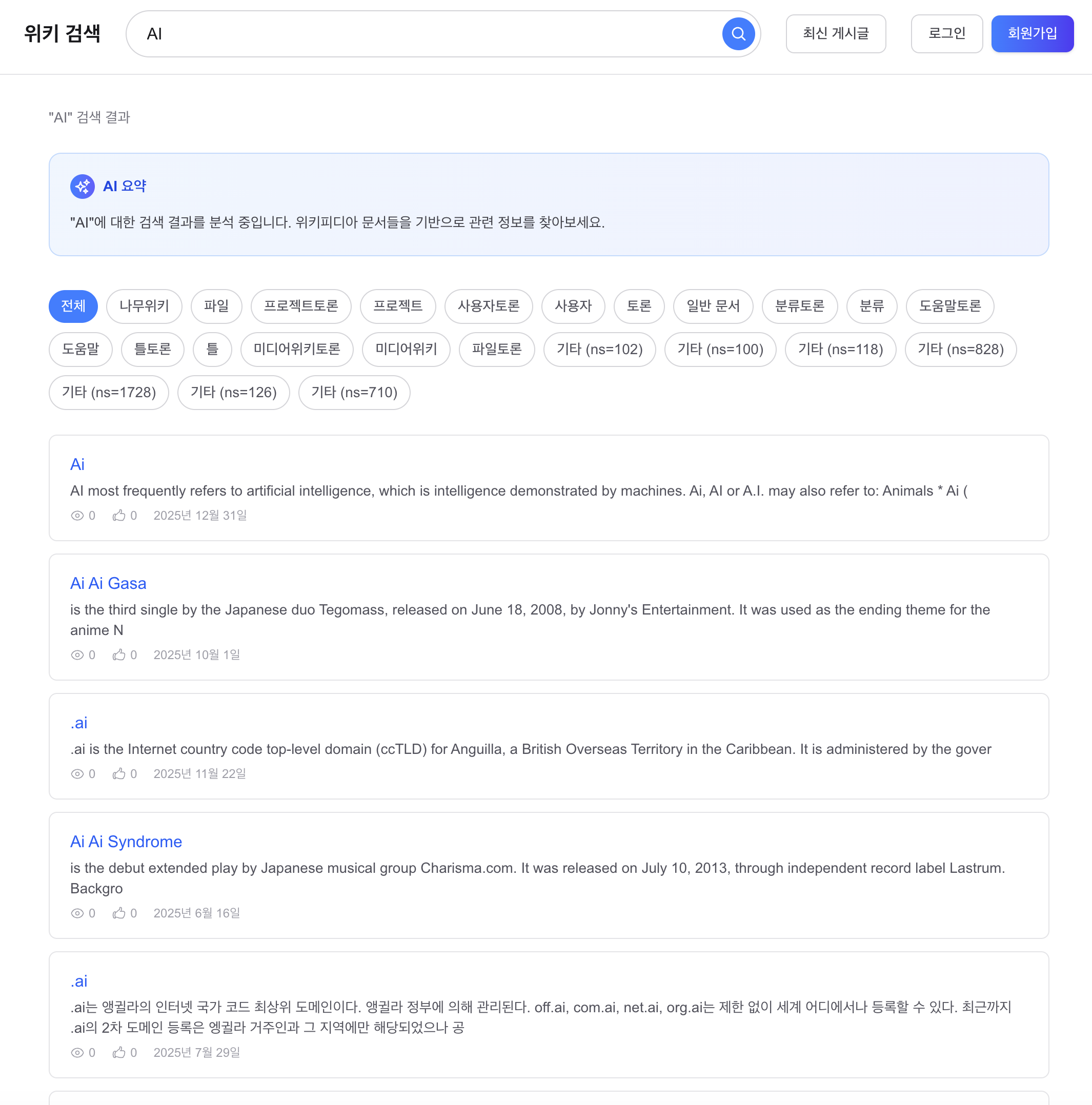
관찰:
- 1위 “Ai”: 영문 위키 “AI most frequently refers to artificial intelligence…”
- 2~5위 “Ai Ai Gasa”, “.ai”, “Ai Ai Syndrome”: “인공지능”이라는 한국어 문서가 상위에 없음
Before 3: “컴퓨터” 검색, 오타 교정 Before 기준
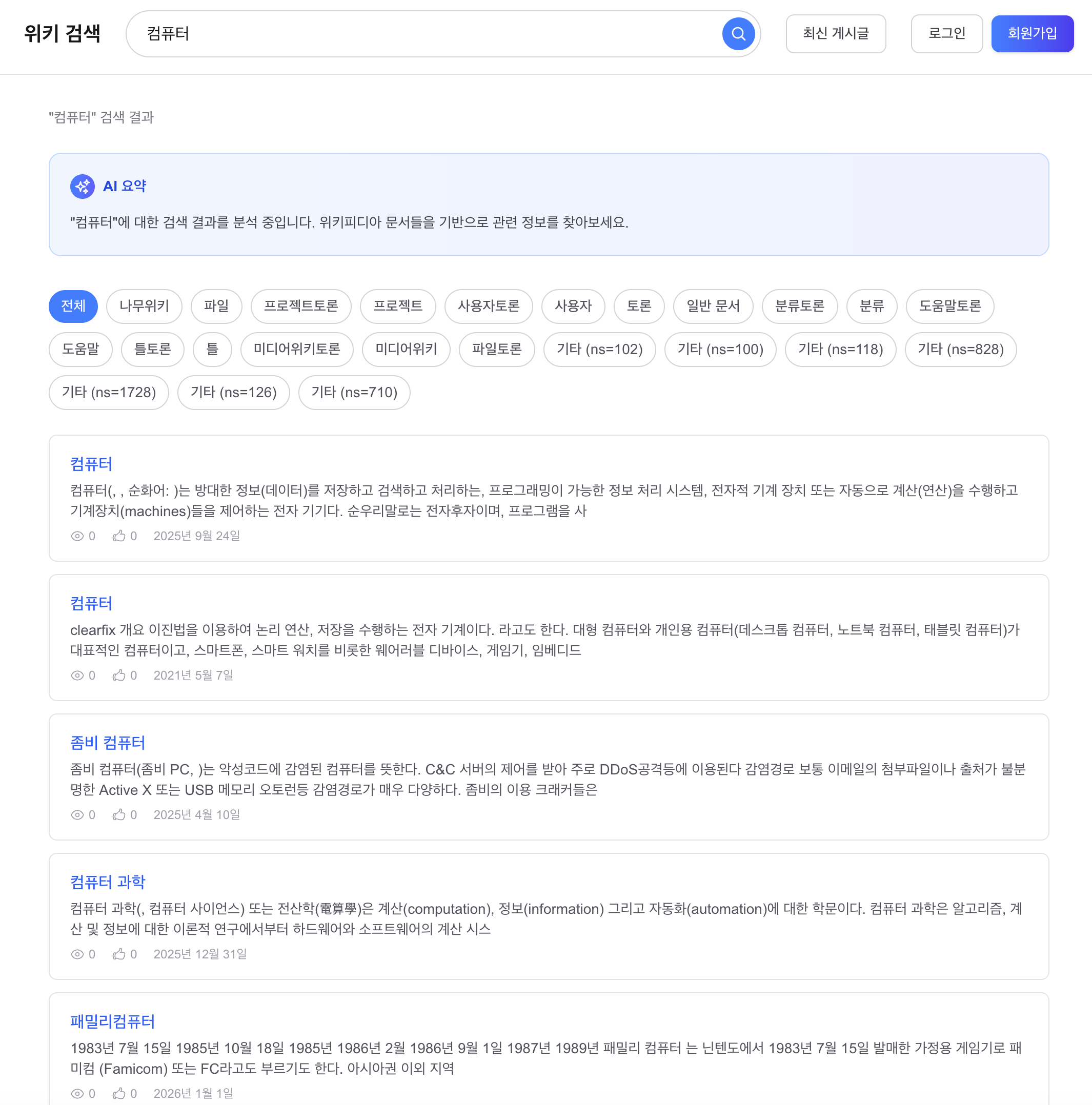
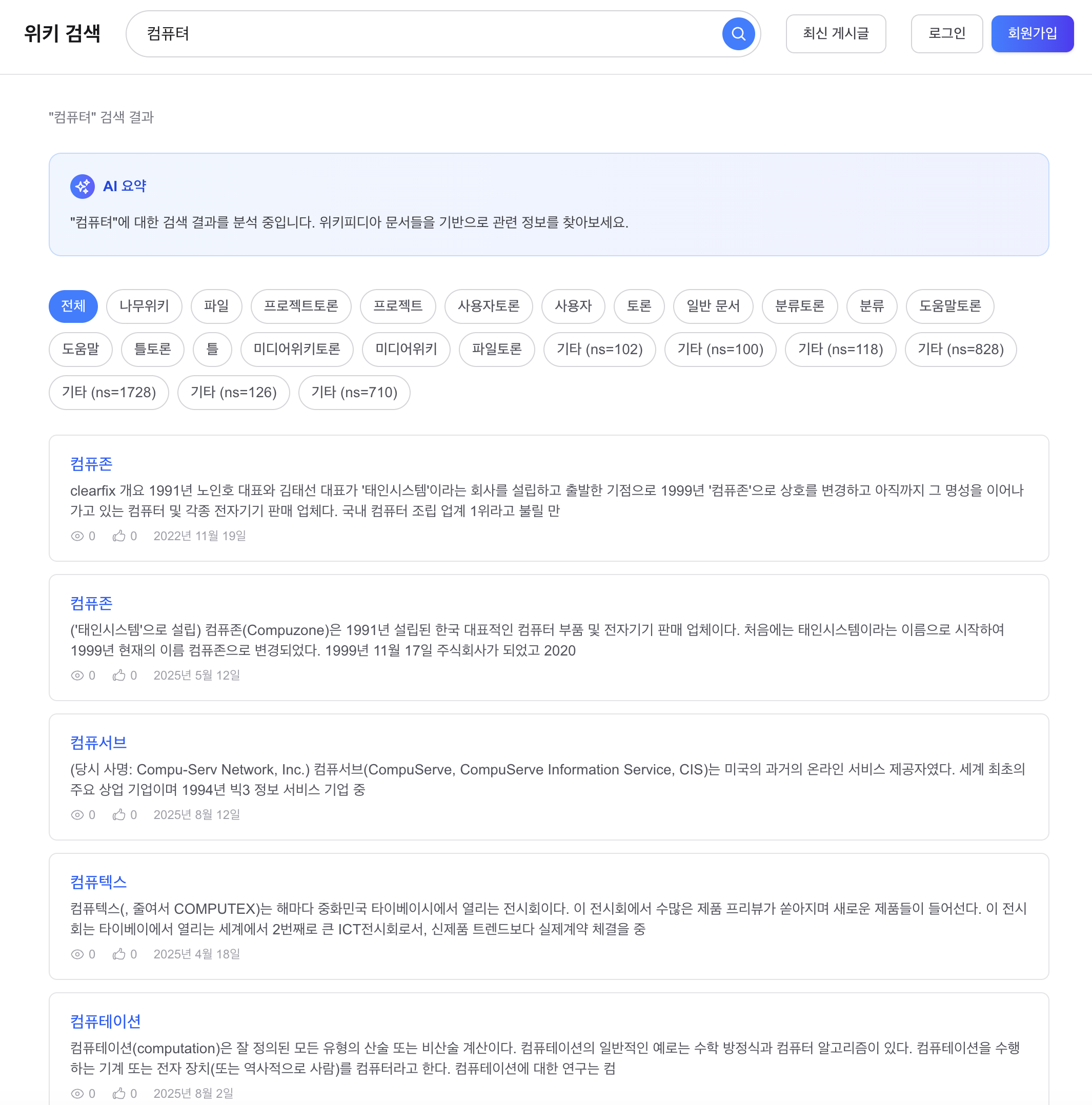
“컴퓨터” 정상 검색 시 관련 문서 반환됨. 이 상태에서 “컴퓨텨” (오타)를 검색하면 결과 0건.
After 1: “AI” 검색, 동의어 확장 성공
| Before | After | |
|---|---|---|
| 1위 | ”Ai” (영문 동음이의어) | “인공지능” (한국어 위키피디아) |
| 2위 | ”Ai Ai Gasa” (일본 음악) | “인공지능” (나무위키) |
| 3위 | ”.ai” (도메인) | “틀:인공지능” |
| 4위 | ”Ai Ai Syndrome" | "인공지능의 개요” |
| 5위 | ”.ai” (한국어) | “약한 인공 지능” |
결과: “AI” 검색 시 동의어 “인공지능”이 확장되어, 한국어 인공지능 관련 문서가 상위에 노출됩니다. Recall이 대폭 개선되었다.
After 2: “ML” 검색, 동의어 확장 성공
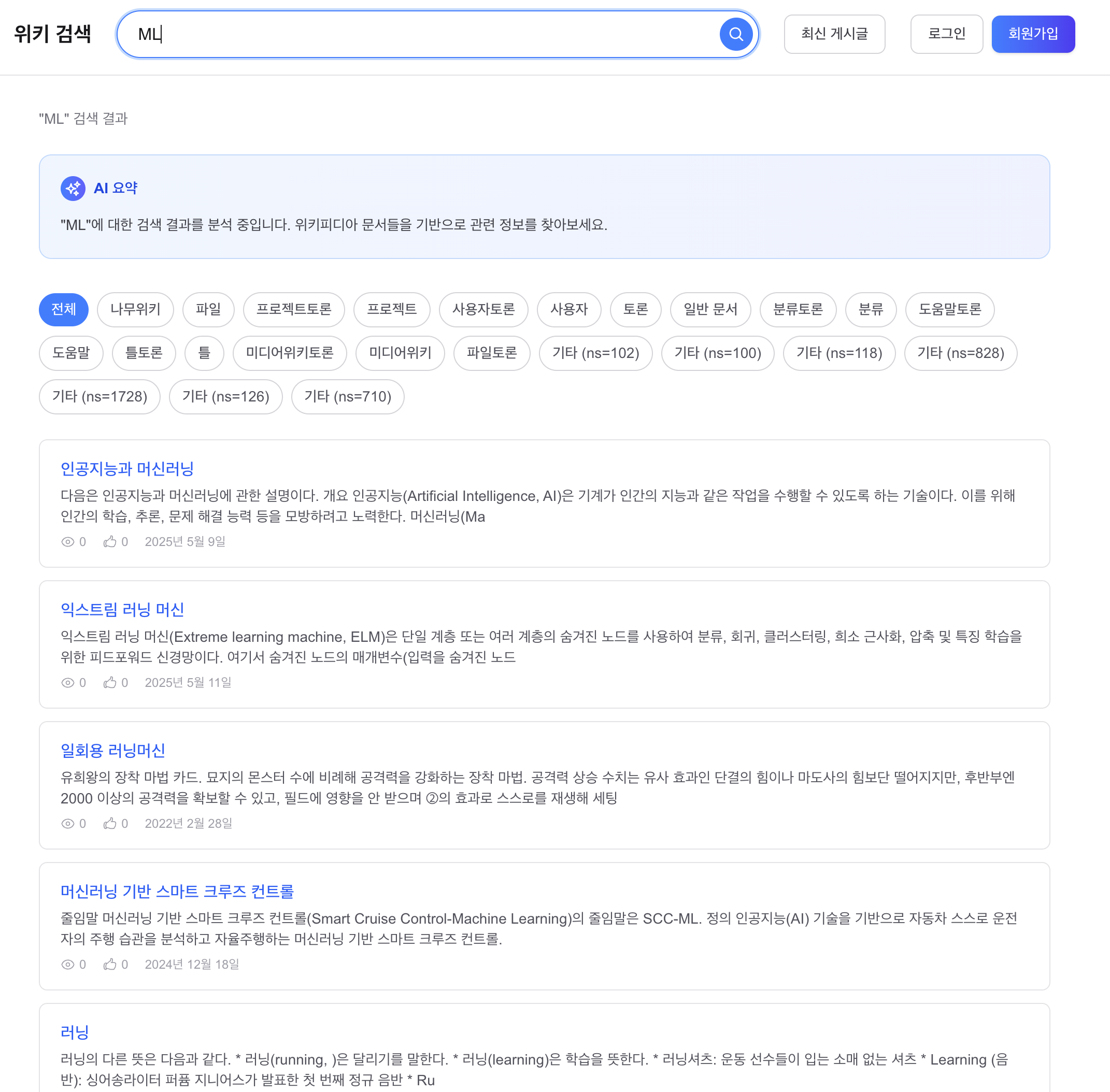
- 1위 “인공지능과 머신러닝”: ML의 동의어 “머신러닝”이 매칭
- 4위 “머신러닝 기반 스마트 크루즈 컨트롤”: “머신러닝” 직접 매칭
After 3: “프로그래링” 검색, 오타 교정
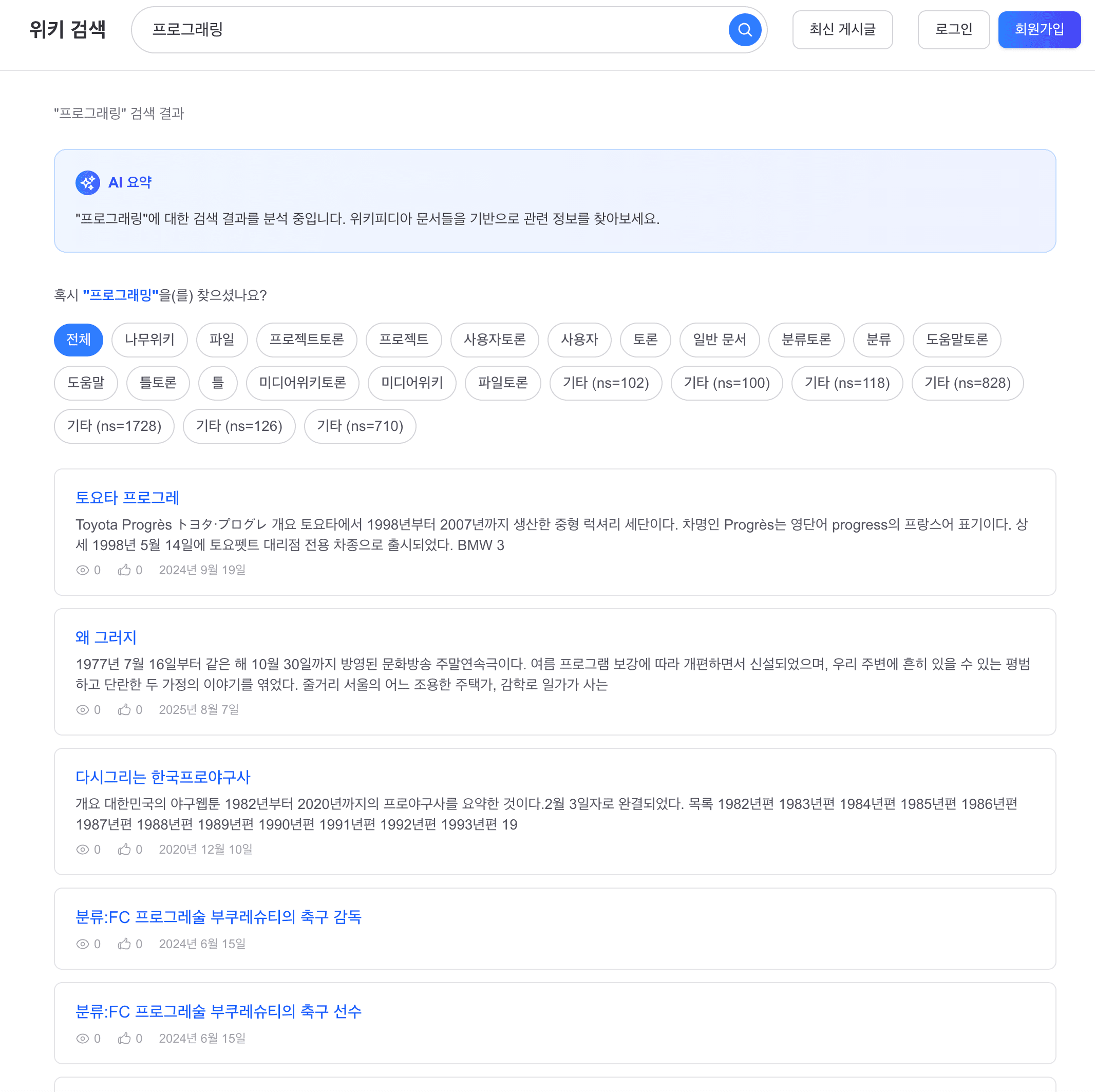
“혹시 ‘프로그래밍’을(를) 찾으셨나요?” 제안이 검색 결과 위에 표시됨. DirectSpellChecker가 “프로그래링” 전체를 “프로그래밍”으로 교정 성공 (편집 거리 1).
트리거 조건 개선: 최초에는 “결과 3건 미만일 때만 교정”이었지만, Google의 “Did you mean?” 패턴에서는 결과 유무와 무관하게 교정 제안을 표시합니다. 항상 교정 시도 + 원본과 다르면 제안 방식으로 변경했다.
After 4: “컴퓨터” 검색, 정상 결과 (교정 미발생)
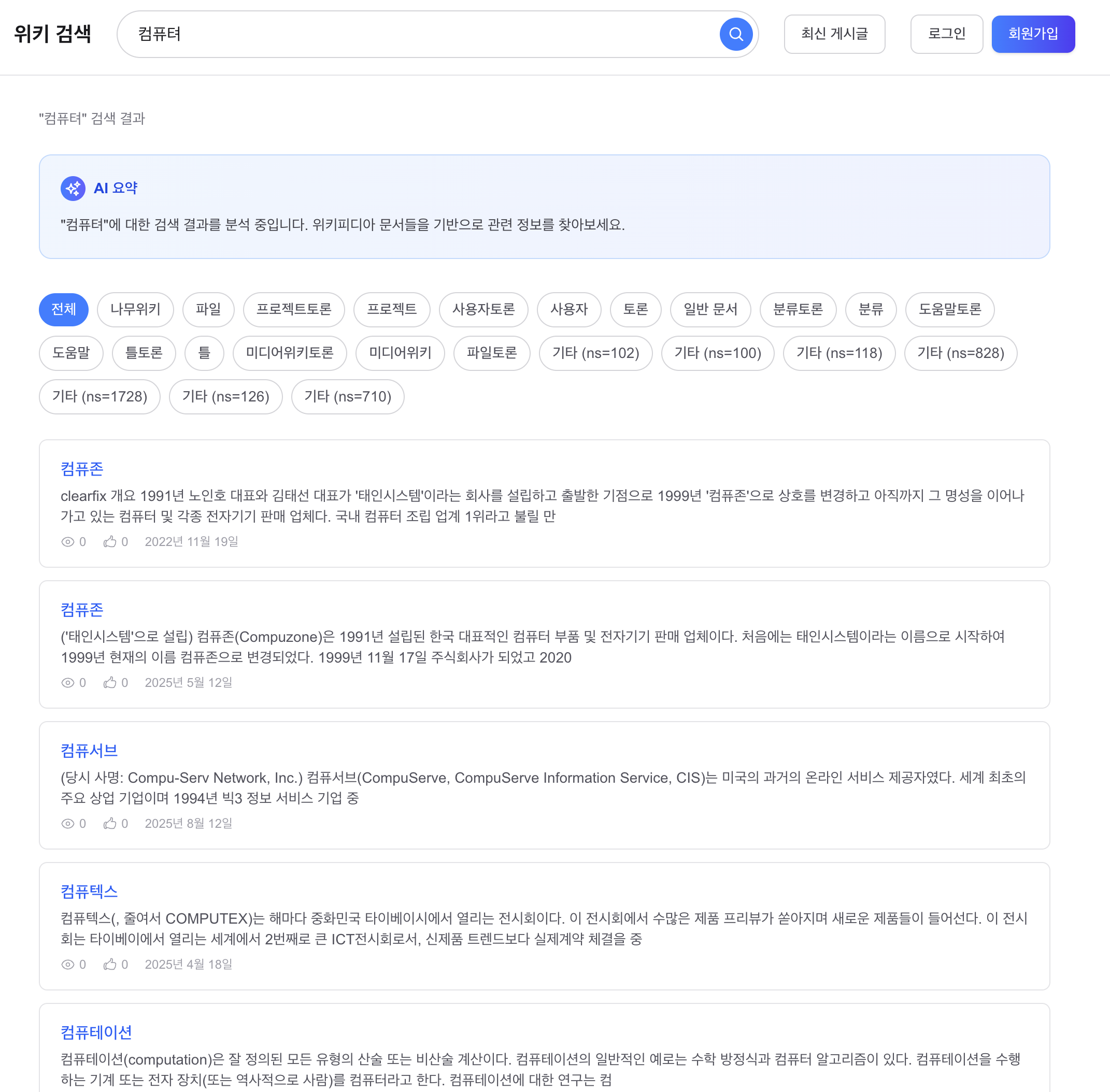
정상 검색어에 대해서는 교정 제안이 뜨지 않는다 (정상 동작).
After 5: Snippet 개선 (재색인 후)
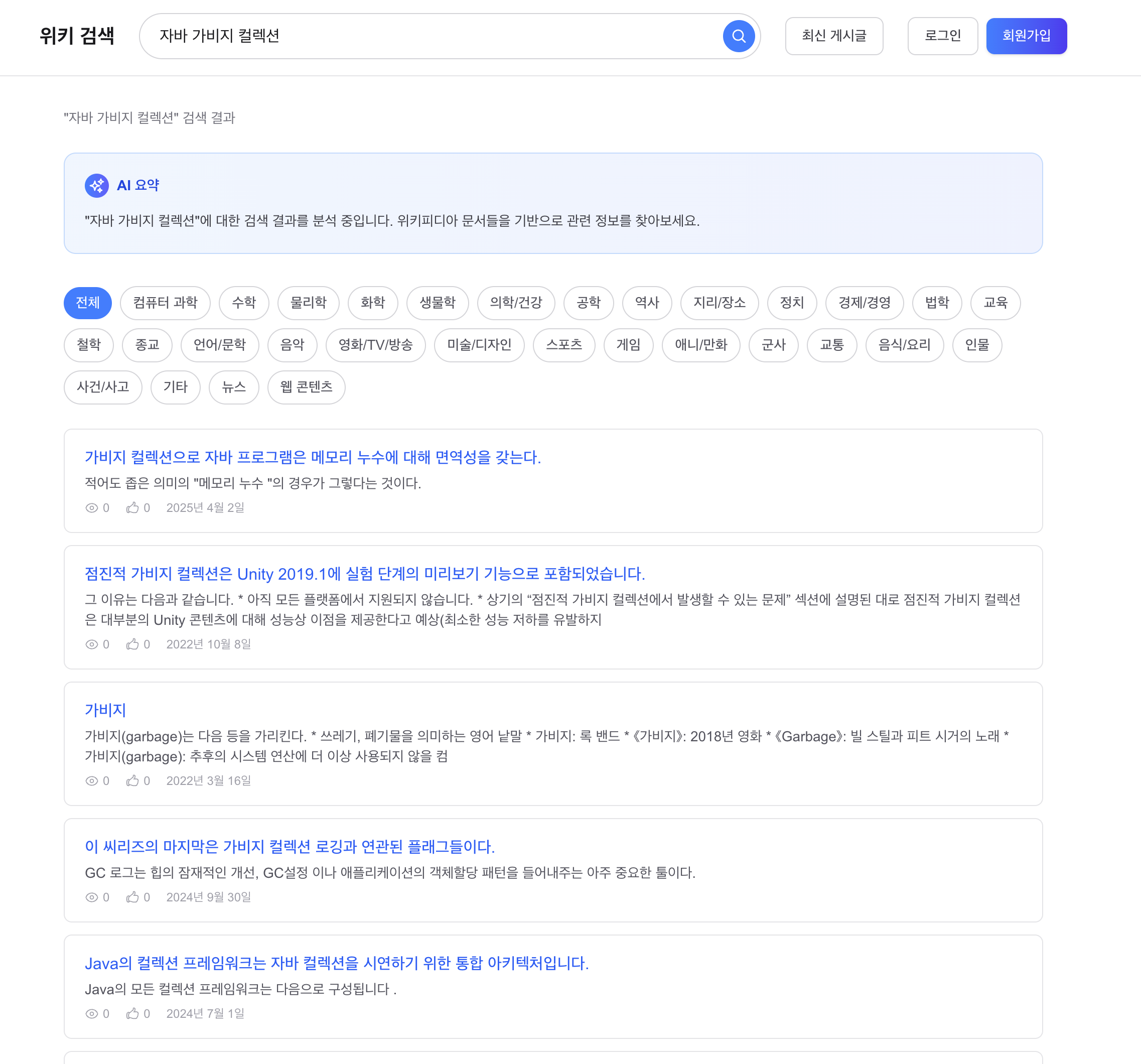
| Before (앞 150자) | After (UnifiedHighlighter) | |
|---|---|---|
| 1위 snippet | ”가비지(garbage)는 다음 등을 가리킨다. 쓰레기…" | "가비지 컬렉션으로 자바 프로그램은 메모리 누수에 대해 면역성을 갖는다” |
| 2위 snippet | ”자바 가상 머신(JVM)은…” (GC 미언급) | “점진적 가비지 컬렉션은 Unity 2019.1에 실험 단계의 미리보기 기능…” |
snippetSource(앞 500자) + UnifiedHighlighter 조합으로, 검색어 주변 맥락이 snippet에 정확히 표시됩니다.
After 6: “AI” 검색 + snippet (재색인 후)
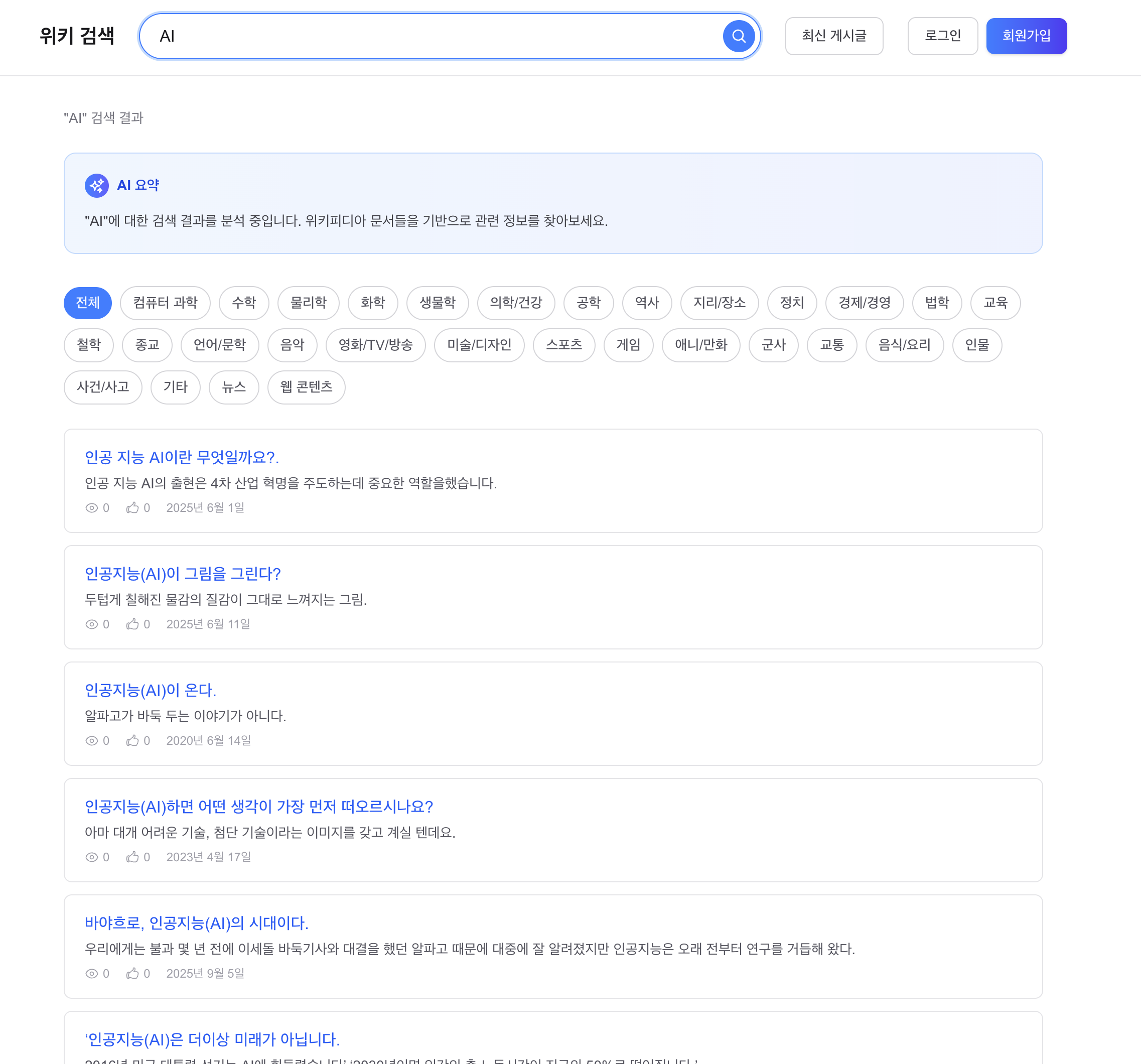
동의어 확장(“AI” → “인공지능”)이 유지되면서, snippet도 검색어 맥락을 반영. 동의어 확장 + snippet 개선이 동시에 동작 확인.
종합
| 검색어 | Before | After | 상태 |
|---|---|---|---|
| ”AI" | "Ai”, “.ai” 등 영문만 | ”인공지능” 1위 | 성공 (동의어 확장) |
| “ML” | ML 관련 영문만 | ”인공지능과 머신러닝” 1위 | 성공 (동의어 확장) |
| “컴퓨터” | 정상 결과 | 정상 결과 (변화 없음) | 정상 |
| ”프로그래링” | 무관 결과만 | ”혹시 ‘프로그래밍’을 찾으셨나요?” 제안 | 성공 (오타 교정) |
| “자바 가비지 컬렉션” | 앞 150자 (GC 미언급) | 검색어 주변 맥락 snippet | 성공 (UnifiedHighlighter) |
다음 글
LTR 재랭킹 + 카테고리 자동 분류에서 XGBoost LambdaMART로 BM25 수동 가중치를 ML 모델로 대체하고, 카테고리 28개 자동 분류 + Lucene 네이티브 Facet을 구현합니다.
출처
- Nori: The Official Elasticsearch Plugin for Korean — Elastic
- NHN FORWARD 22 — Elasticsearch를 이용한 상품 검색 엔진
- 오늘의집 — 데이터 엔지니어의 좌충우돌 검색 개발기
- BM25 변형 비교 논문
- Elastic — Boosting the Power of Elasticsearch with Synonyms
- OpenSource Connections — Solr Synonyms Mea Culpa
- Eugene Yan — Search: Query Matching
- Google — ABCs of Spelling in Google Search
- Elasticsearch Highlighting Reference
Previous
In Category Search Filtering + Facet Aggregation we added category filtering with Lucene Occur.FILTER and provided category distribution via DB GROUP BY approximate Facets.
| Metric | Result |
|---|---|
| Category filter | existing LongField(“categoryId”) + Occur.FILTER (no reindex) |
| Markup-stripped snippet | 25 patterns of Wikipedia / Namuwiki / Enwiki markup removed |
| Facet aggregation | meaningless under namespace categories (“general doc” 97%) — apply after reindex |
Result readability improved, but the search-quality limits (Recall + Precision) remained.
1. Steady State — Current Search Pipeline
Search flow
BM25 settings
| Param | Current | Meaning |
|---|---|---|
| k1 | 1.2 (default) | TF saturation rate — higher = more sensitive to term repeats |
| b | 0.75 (default) | Doc-length normalization — 1 strongly penalizes long docs |
| Field weights | title:3, content:1 | applied via MultiFieldQueryParser |
For BM25 variants (BM25+, BM25L, BM25F), a 3-corpus news experiment found no meaningful difference. With MultiFieldQueryParser already applying title:3, content:1, we partly cover BM25F’s effect.
Conclusion: start with stock BM25 and only consider variants when search-quality issues actually surface.
2. Problems — Three Search-Quality Limits
- No synonyms: searching “AI” misses “인공지능” docs — Recall loss
- No typo correction: searching “프로그래링” returns 0 — user churn
- Over-decomposition of compounds: Nori’s
DecompoundMode.DISCARDsplits “운동화” into “운동”+“화” — Precision loss
Summary
| Issue | Impact | Current handling |
|---|---|---|
| No synonyms | Recall loss | none |
| No typo correction | search fails (0) | none |
| Compound over-decomp | Precision loss | none (Nori default) |
3. Analysis — Two Axes for Quality Improvement
These two axes must be processed before the query reaches Lucene. The current pipeline only normalizes (lowercase) — Query Understanding and Query Expansion are missing.
Prerequisite: full reindex infrastructure
Depending on synonym strategy, full reindex may be required:
- Query-time synonyms: no reindex (expanded at search)
- Index-time synonyms (SynonymGraphFilter): reindex required
- Nori user dictionary change: reindex required
We build the full reindex + zero-downtime swap infrastructure in this post first.
4. Alternatives
Synonym strategies
| Approach | Pro | Con | Verdict |
|---|---|---|---|
| DB-based query expansion | additions/removals reflected immediately, weight control, admin API possible | DB lookup per query (mitigated by Caffeine) | chosen |
| Lucene SynonymGraphFilter (file) | industry standard; query-time means no reindex | file management (server restart or reload on dynamic change) | end-state goal (switch at reindex) |
| SynonymGraphFilter (index-time) | no DB lookup, integrated in analyzer chain | full reindex on synonym change | rejected (reindex cost) |
| Vector embeddings (Word2Vec/BERT) | learns “AI”↔“인공지능” automatically, no synonym table | needs embedding model + vector DB; ARM inference cost | rejected (partial adoption considered later) |
| Elasticsearch Synonym API | native to ES, dynamic management | requires ES, impossible on Free Tier | rejected |
Why this: Elastic’s official blog also recommends query-time synonyms — “no impact on index size, term statistics unchanged, no reindex needed when synonyms change.” DB-based first for operational flexibility, then switch to SynonymGraphFilter file at reindex time.
Why query-time synonyms do not distort IDF: index-time synonyms add the synonym terms into the index, artificially inflating document frequency and distorting BM25 IDF — when “AI” is indexed as “인공지능” too, the DF of “인공지능” balloons and its weight drops. Query-time expansion keeps index term statistics intact, avoiding that. OpenSource Connections’ “Solr Synonyms Mea Culpa” warns about index-time IDF distortion with real cases.
Why not vector: per Eugene Yan’s “Search: Query Matching”, search systems evolve Lexical (BM25) → Graph (synonyms) → Embedding (vector). WikiEngine completed BM25, so the next step is synonyms (Graph). Bringing in an embedding model + vector DB for a problem that a few synonym tables solve adds operational complexity and inference cost greater than the requirement.
Typo correction
| Approach | Pro | Con | Verdict |
|---|---|---|---|
| Lucene DirectSpellChecker | index is the dictionary, no setup | edit-distance (Damerau-Levenshtein) — Korean is syllable-level so jamo correction is weak. Requires lucene-suggest | chosen |
| Log-based “Did you mean?“ | based on real user queries, accurate | needs accumulated logs (cold start) | reinforce after logs accumulate |
| SymSpell | O(1) lookup, very fast | high memory, separate dictionary | revisit at scale |
| LLM-based | context-aware | latency, cost | rejected (240ms SLA violation) |
Compound splitting
| Approach | Pro | Con | Verdict |
|---|---|---|---|
| Nori user dictionary | preserves “운동화” as a single token | dictionary maintenance | chosen |
| DecompoundMode.MIXED | preserves both base and split tokens | position overlap makes PhraseQuery unstable (analysis in search-quality) | rejected |
| Dual Field (title_exact) | unanalyzed field for exact match | index growth + query complexity | revisit if user dictionary is insufficient |
5. Implementation
Part 0: full reindex + zero-downtime swap infrastructure
Reindex strategy: bundle changes into a single run
Several reindex-needing changes:
| Change | Reindex needed? |
|---|---|
snippetSource StoredField add | YES |
| Synonym expansion (query-time) | NO |
| DirectSpellChecker (uses existing index) | NO |
| Nori user dictionary change | YES |
| Category remapping + SortedSetDocValuesFacetField | YES |
Strategy: implement all the code first, run the reindex only once.
| Strategy | Reindexes | Time | Service impact | Verdict |
|---|---|---|---|---|
| Per-part reindex | 3 | tens of hours (hours × 3) | 3× impact | rejected |
| Bundle into one | 1 | ~hours | minimal | chosen |
Industry standard is to bundle index changes into one reindex. Elasticsearch’s Blue-Green reindex pattern (Elastic official) recommends “build a fresh index with new mapping in one shot → alias swap.” Reindexing per change wastes time and I/O at 14.25M-doc scale.
Behavior until the reindex:
- No snippetSource → UnifiedHighlighter returns null →
PostSearchResponse.from(post)fallback (first 150 chars) - Nori dict unchanged → existing analyzer (slightly worse accuracy but works)
Zero-downtime index swap — Directory Swap
// 1. full index into a fresh directoryPath newIndexPath = Paths.get("/data/lucene/wiki-index-" + version);Directory newDir = MMapDirectory.open(newIndexPath);IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter newWriter = new IndexWriter(newDir, config);
// 2. full DB scan + batch indexing (2000-doc batches)try (Stream<Post> posts = postRepository.streamAll()) { List<Document> batch = new ArrayList<>(2000); posts.forEach(post -> { batch.add(toDocument(post)); if (batch.size() >= 2000) { newWriter.addDocuments(batch); batch.clear(); } }); if (!batch.isEmpty()) newWriter.addDocuments(batch);}newWriter.commit();newWriter.close();
// 3. atomic symlink swapPath symlink = Paths.get("/data/lucene/wiki-index");Path tempLink = Paths.get("/data/lucene/wiki-index-tmp");Files.createSymbolicLink(tempLink, newIndexPath);Files.move(tempLink, symlink, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.ATOMIC_MOVE);
// 4. recreate SearcherManager on the new Directory// MMapDirectory maps files into memory; symlink swap alone is not enough// must close SearcherManager and recreate on the new DirectorysearcherManager.close();Directory currentDir = MMapDirectory.open(symlink);searcherManager = new SearcherManager(currentDir, null);Caveat: MMapDirectory maps files into memory, so swapping the symlink does not redirect already-mapped files. SearcherManager must be recreated.
Preventing concurrent indexing
private final AtomicBoolean fullReindexInProgress = new AtomicBoolean(false);
public void incrementalIndex(Post post) throws IOException { if (fullReindexInProgress.get()) { log.warn("Full reindex in progress, skipping incremental for post={}", post.getId()); // CDC events remain in Kafka — auto-reprocessed after reindex return; } writer.updateDocument( new Term("id", String.valueOf(post.getId())), toDocument(post));}Reindex measurements
| Item | Value |
|---|---|
| Total docs | 12,156,589 |
| Index size | 42GB |
| Reindex time | ~2 hours (local Mac M2 Pro) |
| Segment merge | forceMerge(5) |
| Batch size | 1,000 (Producer-Consumer pipeline) |
Part 0.5: Snippet Improvement — UnifiedHighlighter
Limits of the current approach
Industry standard: Lucene UnifiedHighlighter
Elasticsearch’s default highlighter (unified) internally uses Lucene UnifiedHighlighter. It splits text into sentences, scores each sentence with BM25 relative to the query, and returns the most relevant sentences as the snippet.
Sources: Elasticsearch Highlighting Reference, Reverse Engineering Elasticsearch Highlights
| Type | Internals | Notes |
|---|---|---|
| unified (default, recommended) | Lucene UnifiedHighlighter | BM25 sentence scoring, offset-based |
| plain (legacy) | Lucene Highlighter | simple term match, slow on large docs |
| fvh | FastVectorHighlighter | needs TermVector, fast but bigger index |
Implementation
Dependencies:
implementation 'org.apache.lucene:lucene-highlighter:10.3.2'implementation 'org.apache.lucene:lucene-suggest:10.3.2' // DirectSpellCheckerIndex field change (reindex required):
// Option A: change content to Store.YES (simple but index 100GB+)doc.add(new TextField("content", post.getContent(), Field.Store.YES));
// Option B: separate snippet_source store (first 500 chars, minimizes growth) — chosenString snippetSource = post.getContent().substring( 0, Math.min(post.getContent().length(), 500));doc.add(new StoredField("snippetSource", snippetSource));// content stays Store.NO (search only)Why Option B: storing all content as Store.YES inflates the index to 100GB+ for 14.25M × ~6,586 chars. Storing only the first 500 chars adds ~7GB → ~27GB total. Queries are highly likely to appear in the first 500 chars (title, intro, infobox); for queries beyond 500 chars, fall back to the current method (DB lookup + snip).
Apply Highlighter at search:
UnifiedHighlighter highlighter = UnifiedHighlighter.builder(searcher, analyzer) .withFieldMatcher(field -> "snippetSource".equals(field)) .build();String[] snippets = highlighter.highlight("snippetSource", query, topDocs, 1);
// if no snippet (query lies beyond first 500 chars), fall back to DBfor (int i = 0; i < results.size(); i++) { if (snippets[i] != null && !snippets[i].isBlank()) { results.get(i).setSnippet(snippets[i]); } // else: fallback via PostSearchResponse.createSnippet() (current method)}Before/After
| Metric | Before (first 150 chars) | After (UnifiedHighlighter) |
|---|---|---|
| Snippet relevance | unrelated lead | context around query |
| Highlight | none | <b>keyword</b> tags |
| Index size | ~20GB | ~42GB (+ snippetSource 500 chars + others) |
| Extra latency | 0ms | ~1-3ms (Highlighter) |
Part 1: Synonym Expansion (Query Expansion)
Synonym dictionary
CREATE TABLE synonyms ( id BIGINT AUTO_INCREMENT PRIMARY KEY, term VARCHAR(100) NOT NULL, synonym VARCHAR(100) NOT NULL, weight DOUBLE DEFAULT 1.0, INDEX idx_term (term), INDEX idx_synonym (synonym));
-- manual entriesINSERT INTO synonyms (term, synonym, weight) VALUES ('AI', '인공지능', 1.0), ('인공지능', 'AI', 1.0), ('ML', '머신러닝', 1.0), ('머신러닝', 'ML', 1.0), ('DB', '데이터베이스', 1.0), ('데이터베이스', 'DB', 1.0);Auto-extraction via wiki redirects
Wikipedia data includes redirects. We can mine synonyms automatically:
SELECT redirect_title AS term, title AS synonym, 0.8 AS weightFROM postsWHERE redirect_title IS NOT NULL;-- e.g., "인공 지능" → "인공지능", "AI" → "인공지능"QueryExpansionService
@Servicepublic class QueryExpansionService {
private final SynonymRepository synonymRepository;
/** * Find synonyms for each term in the original query and expand. * Cap synonyms per term at 3 to prevent query explosion. */ public List<ExpandedTerm> expandQuery(List<String> originalTerms) { List<ExpandedTerm> expanded = new ArrayList<>();
for (String term : originalTerms) { // original term has boost=1.0 expanded.add(new ExpandedTerm(term, 1.0, true));
// synonyms: weighted, max 3 List<Synonym> synonyms = synonymRepository.findByTerm(term); synonyms.stream() .limit(3) .forEach(syn -> expanded.add( new ExpandedTerm(syn.getSynonym(), syn.getWeight(), false) )); } return expanded; }}Integrate synonyms into Lucene query build
// Before: parser.parse("AI")// → TermQuery("ai")
// After expansion: "AI" + "인공지능" (weight=1.0)// → BooleanQuery(// TermQuery("ai")^1.0, SHOULD// TermQuery("인공지능")^1.0 SHOULD// )Wrap expanded terms in BooleanQuery(SHOULD) so a match on either the original or any synonym puts the doc into the result.
Caveats
| Issue | Description | Mitigation |
|---|---|---|
| Query explosion | many synonyms → posting list lookups balloon | cap synonyms at 3 per term |
| Semantic drift | ”Apple” → “사과” vs “Apple Inc.” | context-aware selection is advanced; not in this stage |
| Performance | more terms → longer search | low weights, Caffeine caching |
| DB-lookup cost | per-query DB lookup | cache synonym dictionary in Caffeine (TTL 30 min). Cache miss adds ~1-2ms |
Part 2: Query Understanding
2-1. Typo correction — Lucene DirectSpellChecker
@Servicepublic class SpellCheckService {
private final SearcherManager searcherManager;
/** * Use the Lucene index's term dictionary as the spell-check dictionary. * Edit-distance (Damerau-Levenshtein) corrections. * * DirectSpellChecker needs no separate dictionary build — the index is the dictionary. * * Korean limits: * - Comparison is syllable-level: "컴퓨텨"→"컴퓨터" (edit distance 1) is caught. * "프로그래링"→"프로그래밍" (missing ㅁ) is jamo-level 1, but also syllable-level 1, so caught. * - Real issue: if the index has no such term, no candidate. * Nori decomposes compounds, so the indexed term may differ from the original. * - Reinforce later with log-based "Did you mean?". */ public Optional<String> suggestCorrection(String query) throws IOException { IndexSearcher searcher = searcherManager.acquire(); try { DirectSpellChecker spellChecker = new DirectSpellChecker(); spellChecker.setMaxEdits(2); // max edit distance 2 spellChecker.setMinPrefix(1); // first char must match spellChecker.setMinQueryLength(2); // skip <2 chars
String[] tokens = tokenize(query); List<String> corrected = new ArrayList<>(); boolean hasCorrected = false;
for (String token : tokens) { SuggestWord[] suggestions = spellChecker.suggestSimilar( new Term("title", token), 1, // 1 suggestion max searcher.getIndexReader() );
if (suggestions.length > 0) { corrected.add(suggestions[0].string); hasCorrected = true; } else { corrected.add(token); } }
return hasCorrected ? Optional.of(String.join(" ", corrected)) : Optional.empty(); } finally { searcherManager.release(searcher); } }}2-2. Compound preservation — Nori user dictionary
Solve Nori’s “운동화” → “운동”+“화” decomposition with a user dictionary.
# userdict_ko.txt — Nori user dictionary운동화에어맥스나이키인공지능머신러닝데이터베이스- 30 manual compounds + open-korean-text (Apache 2.0) wikipedia_title_nouns 158,509 = 158,539 total
- Changing the user dictionary requires full reindex (Analyzer change → indexed terms vs query terms diverge)
Part 3: Search pipeline integration
6. Verification — Before/After Measured
Before 1: “자바 가비지 컬렉션” (snippet unrelated to the query)
Observations:
- #1 “가비지”: snippet says “가비지(garbage)는 다음 등을 가리킨다. 쓰레기, 폐기물…” — a homonym doc unrelated to Java GC
- #2 “자바 가상 머신”: snippet says “자바 가상 머신(, JVM)은 자바 바이트코드를 실행할 수 있는 주체이다…” — GC-related but the first 150 chars do not contain “가비지 컬렉션”
Before 2: “AI” (“인공지능” docs missing)
Observations:
- #1 “Ai”: English Wikipedia “AI most frequently refers to artificial intelligence…”
- #2-5: “Ai Ai Gasa”, “.ai”, “Ai Ai Syndrome” — no Korean “인공지능” doc on top
Before 3: “컴퓨터” (typo-correction baseline)
Searching “컴퓨터” returns related docs normally. From this state, searching “컴퓨텨” (typo) returns 0 results.
After 1: “AI” search — synonym expansion success
| Before | After | |
|---|---|---|
| #1 | ”Ai” (English homonym) | “인공지능” (Korean Wikipedia) |
| #2 | ”Ai Ai Gasa” (Japanese music) | “인공지능” (Namuwiki) |
| #3 | ”.ai” (domain) | “Template:인공지능” |
| #4 | ”Ai Ai Syndrome" | "인공지능 개요” |
| #5 | ”.ai” (Korean) | “약한 인공지능” |
Result: searching “AI” expands to “인공지능” so Korean AI docs surface on top. Recall improves substantially.
After 2: “ML” search — synonym expansion success
- #1: “인공지능과 머신러닝” — ML synonym “머신러닝” matched
- #4: “머신러닝 기반 스마트 크루즈 컨트롤” — direct “머신러닝” match
After 3: “프로그래링” search (typo correction)
“Did you mean ‘프로그래밍’?” appears above the results. DirectSpellChecker corrects the entire “프로그래링” to “프로그래밍” (edit distance 1).
Trigger improvement: initially “only suggest when fewer than 3 results,” but Google’s “Did you mean?” pattern shows suggestions regardless of result count. Switched to always attempt + suggest if differs from input.
After 4: “컴퓨터” search, normal results (no correction)
For valid queries, no correction suggestion appears (correct).
After 5: snippet improvement (after reindex)
| Before (first 150 chars) | After (UnifiedHighlighter) | |
|---|---|---|
| #1 snippet | ”가비지(garbage)는 다음 등을 가리킨다. 쓰레기…" | "가비지 컬렉션으로 자바 프로그램은 메모리 누수에 대해 면역성을 갖는다” |
| #2 snippet | ”자바 가상 머신(JVM)은…” (no GC mention) | “점진적 가비지 컬렉션은 Unity 2019.1에 실험 단계의 미리보기 기능…” |
snippetSource (first 500 chars) + UnifiedHighlighter combined: snippets now show context around the query.
After 6: “AI” search + snippet (after reindex)
Synonym expansion (“AI” → “인공지능”) preserved while snippets reflect query context. Both work together.
Summary
| Query | Before | After | Status |
|---|---|---|---|
| ”AI” | only English (“Ai”, “.ai”) | “인공지능” #1 | success (synonym expansion) |
| “ML” | only English ML refs | ”인공지능과 머신러닝” #1 | success (synonym expansion) |
| “컴퓨터” | normal results | normal (unchanged) | OK |
| ”프로그래링” | only unrelated | ”Did you mean ‘프로그래밍’?“ | success (typo correction) |
| “자바 가비지 컬렉션” | first 150 chars (no GC) | context-around-query snippet | success (UnifiedHighlighter) |
Next
In LTR Re-ranking + Auto Category Classification we replace BM25’s manual weights with an ML model via XGBoost LambdaMART, and implement 28 auto-categorization + native Lucene Facets.
Sources
- Nori: The Official Elasticsearch Plugin for Korean — Elastic
- NHN FORWARD 22 — Search engine for products with Elasticsearch
- Today’s House — A data engineer’s bumpy search-development story
- BM25 variants comparison paper
- Elastic — Boosting the Power of Elasticsearch with Synonyms
- OpenSource Connections — Solr Synonyms Mea Culpa
- Eugene Yan — Search: Query Matching
- Google — ABCs of Spelling in Google Search
- Elasticsearch Highlighting Reference

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.