Deferred Join 적용기: 기대한 40배 vs 현실 13%

목차
이전 글
MySQL 검색을 버리고 Lucene을 선택한 이유에서 Lucene + Nori 형태소 분석기를 적용하고, k6 부하 테스트로 baseline을 측정했습니다.
smoke 테스트 결과, 검색(66ms), 자동완성(25ms), 상세 조회(53ms)는 양호했지만 최신 게시글 목록 조회만 평균 2,518ms, P95 3,372ms로 유독 느렸습니다.
1. 정상 상태: 시스템이 어떻게 돌아가고 있었는가
커뮤니티 게시판의 게시글 목록 API입니다.
- API:
GET /api/v1.0/posts?page={N}&size=20 - 테이블:
posts, 1,475만 건 - 인덱스:
idx_posts_created_at (created_at DESC), Flyway V4에서 생성 - 컬럼:
id(PK),title(VARCHAR 512),content(LONGTEXT),author_id,category_id,view_count,like_count,created_at,updated_at
Spring Data JPA의 메서드 이름 기반 쿼리(findAllByOrderByCreatedAtDesc)가 자동으로 SQL을 생성합니다. Pageable의 page와 size로 LIMIT과 OFFSET이 결정됩니다.
응답 DTO인 PostSummaryResponse는 id, title, authorId, categoryId, viewCount, likeCount, createdAt 7개 필드만 사용합니다. content(LONGTEXT)는 목록에서 사용하지 않습니다.
2. 문제 인식: 어떤 조건에서, 얼마나 느렸는가
k6 smoke 테스트(5 VU, 2분)에서 시나리오별 응답 시간을 측정했습니다.
테스트 환경: ARM 2코어 / 12GB RAM입니다. Spring Boot 2GB(JVM 힙 1GB) + MySQL 4GB(InnoDB BP 2GB) + 모니터링 에이전트 ~1GB이고, 나머지 ~5GB는 OS 페이지 캐시(Lucene MMap)입니다.
| 시나리오 | 평균 | P95 |
|---|---|---|
| 검색 (Lucene) | 66ms | 128ms |
| 자동완성 (Lucene) | 25ms | 37ms |
| 최신 게시글 목록 조회 (MySQL) | 2,518ms | 3,372ms |
| 상세 조회 (MySQL) | 53ms | 93ms |
| 쓰기 (MySQL + Lucene) | 62ms | 124ms |
최신 게시글 목록 조회가 검색보다 38배 느립니다. Lucene 전체 검색(1,475만 건 BM25 스코어링)보다 단순 목록 정렬이 느리다는 건 쿼리 자체에 구조적 문제가 있다는 뜻입니다.
k6 스크립트에서 최신 게시글 목록 조회의 페이지 분포는 다음과 같습니다:
// 70% 확률로 page 0~10, 30% 확률로 page 100~1000const page = randomInt(0, 100) < 70 ? randomInt(0, 10) : randomInt(100, 1000);page 1000이면 OFFSET 20,000입니다. 이 30%의 deep page 요청이 평균을 끌어올리고 있습니다.
3. 문제 분석: 왜 느린가
OFFSET의 동작 원리
SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000
이 쿼리가 실행되면 MySQL은:
idx_posts_created_at인덱스를 타고created_at DESC순서로 탐색 시작- 20,020개 행을 전부 읽음 (OFFSET 20,000 + LIMIT 20)
- 앞의 20,000개를 버림
- 나머지 20개만 반환
created_at DESC 인덱스가 있으므로 filesort(정렬)는 발생하지 않습니다. 문제는 “읽고 버리는” 20,000개 행입니다.
왜 “읽고 버리는” 게 비싼가: InnoDB의 클러스터 인덱스 구조
InnoDB에서 SELECT *가 실행되면:

SELECT *이므로 MySQL은 세컨더리 인덱스에서 PK를 찾고, 다시 클러스터 인덱스로 가서 전체 행을 읽어야 합니다. 이 과정에서 content(LONGTEXT)도 함께 읽힙니다.
위키피디아 문서의 본문은 수 KB에서 수십 KB입니다. 20,000개 행의 LONGTEXT를 읽으면 수백 MB의 데이터를 디스크에서 읽고 버리는 셈입니다. 이것이 핵심 병목입니다.
정리
| 구간 | 비용 | 설명 |
|---|---|---|
| 인덱스 탐색 | 낮음 | idx_posts_created_at로 created_at 순서대로 PK 획득 |
| 클러스터 인덱스 랜덤 I/O | 높음 | PK로 실제 행을 읽음(LONGTEXT 포함) |
| OFFSET 행 버리기 | - | 읽은 20,000개 행을 버림 (I/O는 이미 발생) |
| 결과 반환 | 낮음 | 남은 20개 행 반환 |
쓸모없는 20,000개 행에 대해 클러스터 인덱스 랜덤 I/O가 발생하는 것이 문제입니다. 게다가 PostSummaryResponse는 content를 아예 사용하지 않으므로, 필요하지도 않은 LONGTEXT를 읽고 있는 것입니다.
컬럼이 많을수록, 행이 클수록 느려진다
OFFSET에서 “읽고 버리는” 비용은 행의 크기에 비례합니다. posts 테이블의 컬럼 구성을 보면:

content(LONGTEXT)가 행 크기의 대부분을 차지합니다. 위키피디아 문서 평균 6,586자(약 13KB)이므로, OFFSET 20,000개 행을 읽으면 약 260MB의 데이터를 읽고 버리는 셈입니다. 만약 content 없이 나머지 컬럼만이라면 ~12MB로 1/20 수준입니다.
이것이 Deferred Join의 핵심 동기입니다. OFFSET 구간에서는 id만 읽고, 최종 결과 20개에 대해서만 전체 행을 읽으면 됩니다.
MySQL(InnoDB)에서 이 문제가 특히 심한 이유
PostgreSQL이나 Oracle에서는 이 문제가 다른 양상을 보입니다.
| MySQL (InnoDB) | PostgreSQL / Oracle | |
|---|---|---|
| 테이블 구조 | 클러스터 인덱스, PK 순서로 데이터가 물리 저장 | 힙 테이블, 삽입 순서대로 저장 |
| PK 생성 방식 | AUTO_INCREMENT, 테이블 내부에서 관리 | SEQUENCE / SERIAL, 테이블 외부 객체로 관리 |
| 세컨더리 인덱스 | PK 값을 포인터로 저장 → 클러스터 인덱스를 다시 조회해야 전체 행 획득 | 힙 포인터(ctid/rowid)를 저장 → 직접 힙으로 이동 |
| OFFSET 시 | 세컨더리 인덱스 → PK 획득 → 클러스터 인덱스에서 전체 행 읽기 | 인덱스에서 tid 획득 → 힙에서 행 읽기 (Index Only Scan 가능) |
MySQL InnoDB의 세컨더리 인덱스는 힙 포인터가 아닌 PK 값을 저장합니다. 그래서 SELECT *를 하면 세컨더리 인덱스 → PK → 클러스터 인덱스(전체 행)로 두 번의 B-Tree 탐색이 필요합니다. PostgreSQL은 인덱스에 힙 포인터가 있어 바로 행에 접근하고, Index Only Scan으로 인덱스에서 필요한 컬럼만 반환할 수 있습니다.
이 구조적 차이 때문에 MySQL에서는 Deferred Join이 특히 효과적입니다. 내부 서브쿼리가 SELECT id만 하면 세컨더리 인덱스 안에서 완결(Covering Index)되어 클러스터 인덱스 접근을 아예 건너뜁니다.
4. 대안 검토: 어떤 해결책을 검토했는가
후보 1: Keyset Pagination (커서 기반)
SELECT * FROM postsWHERE created_at < :lastCreatedAtORDER BY created_at DESCLIMIT 20OFFSET 없이 WHERE 조건으로 시작점을 지정하므로 항상 O(LIMIT)만큼만 읽습니다. 가장 빠르지만 “N페이지로 바로 이동”이 불가능합니다. 무한 스크롤 UI에만 적합하고, 페이지 번호가 있는 UI에서는 사용할 수 없습니다.
후보 2: Deferred Join (지연 조인)
SELECT p.* FROM posts pINNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000) AS tmp ON p.id = tmp.idORDER BY p.created_at DESCOFFSET 구조를 유지하면서 성능을 개선합니다. 핵심은 내부 서브쿼리가 인덱스만 스캔한다는 점입니다.
- 내부 쿼리:
SELECT id.idx_posts_created_at인덱스에created_at과id(PK)가 모두 포함되어 있으므로 Covering Index Scan으로 처리됩니다. 클러스터 인덱스를 읽을 필요가 없습니다. LONGTEXT를 건드리지 않습니다. - 외부 쿼리: 내부에서 찾은 20개 PK로만 클러스터 인덱스를 조회합니다.
결과적으로 클러스터 인덱스 랜덤 I/O가 20,020회에서 20회로 줄어듭니다.
InnoDB의 세컨더리 인덱스는 PK를 자동으로 포함합니다. 따라서
idx_posts_created_at에는(created_at, id)두 값이 들어 있고,SELECT id ... ORDER BY created_at DESC는 이 인덱스만으로 완결됩니다. 이를 Covering Index라 합니다.
후보 3: 컬럼 프로젝션 (SELECT 필요한 컬럼만)
SELECT id, title, author_id, category_id, view_count, like_count, created_atFROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000content(LONGTEXT)를 SELECT에서 제외하면 행 하나의 크기가 대폭 줄어듭니다. 하지만 OFFSET 20,000개 행에 대해 클러스터 인덱스 랜덤 I/O는 여전히 발생합니다. LONGTEXT 읽기를 피할 수는 있지만, 행 자체를 읽는 비용은 남습니다.
비교
| 방식 | OFFSET 유지 | 페이지 번호 UI | 클러스터 I/O (page=1000) | 구현 난이도 |
|---|---|---|---|---|
| 현재 (SELECT *) | O | O | 20,020회 | - |
| Keyset | X (OFFSET 제거) | X | 20회 | 중 (API 변경) |
| Deferred Join | O | O | 20회 | 하 (쿼리만 변경) |
| 컬럼 프로젝션 | O | O | 20,020회 (단, 행 크기 감소) | 하 |
Deferred Join을 선택했습니다. OFFSET 기반 페이지네이션 구조를 유지하면서 클러스터 인덱스 I/O를 1/1,000로 줄일 수 있고, API 변경 없이 Repository 쿼리만 교체하면 됩니다.
참고: High Performance MySQL (Baron Schwartz 외)에서 이 기법을 “deferred join”으로 소개하고 있습니다.
5. 적용 및 결과
구현
Spring Data JPA의 메서드 이름 기반 쿼리로는 서브쿼리를 만들 수 없습니다. @Query(nativeQuery = true)로 직접 SQL을 작성합니다.
PostRepository.java:
/** 게시글 목록 — Deferred Join으로 OFFSET 최적화 */@Query(value = """ SELECT p.* FROM posts p INNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT :#{#pageable.pageSize} OFFSET :#{#pageable.offset} ) AS tmp ON p.id = tmp.id ORDER BY p.created_at DESC """, countQuery = "SELECT COUNT(*) FROM posts", nativeQuery = true)Page<Post> findAllWithDeferredJoin(Pageable pageable);내부 서브쿼리는 SELECT id만 하므로 idx_posts_created_at 인덱스의 Covering Index Scan으로 처리됩니다. 외부 쿼리는 서브쿼리가 반환한 20개 PK로만 클러스터 인덱스를 조회합니다.
countQuery를 별도로 지정한 이유: Spring Data JPA는 네이티브 쿼리에서 Page 반환 시 자동으로 COUNT 쿼리를 감싸는데, 서브쿼리가 있는 복잡한 SQL에서는 이 자동 래핑이 실패합니다.
PostService.java:
public Page<Post> getPosts(Pageable pageable) { return postRepository.findAllWithDeferredJoin(pageable);}Service와 Controller는 변경 없이 Repository 쿼리만 교체합니다.
Before / After
k6 smoke 테스트 (5 VU, 2분, 동일 조건): (ARM 2코어, Spring Boot JVM 1GB, MySQL InnoDB BP 2GB)
| 메트릭 | Before | After | 개선율 |
|---|---|---|---|
| 평균 응답시간 | 2,518ms | 2,199ms | -13% |
| P95 | 3,372ms | 2,741ms | -19% |
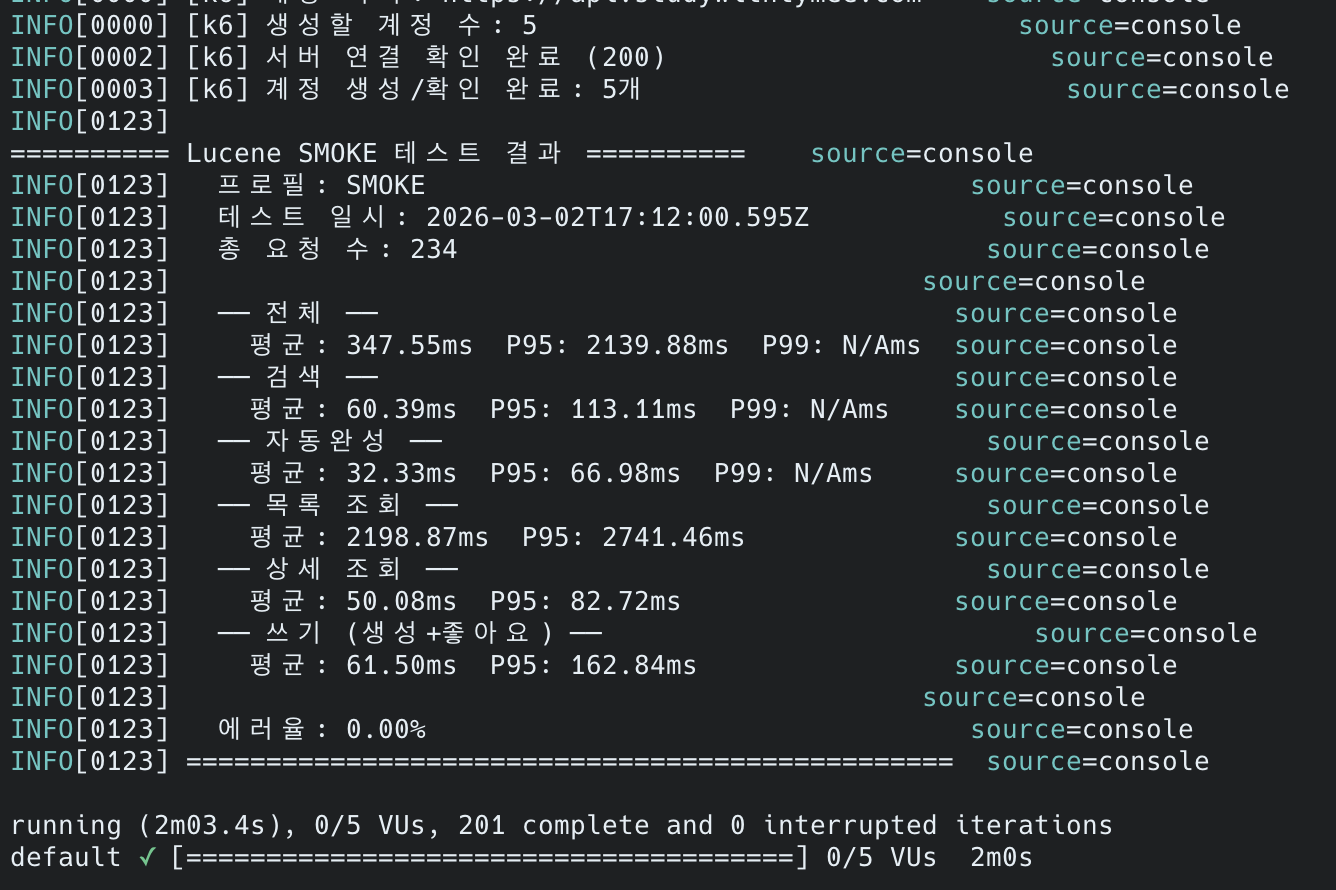
전체 시나리오 결과 (After):
| 시나리오 | 평균 | P95 |
|---|---|---|
| 검색 | 60ms | 113ms |
| 자동완성 | 32ms | 67ms |
| 최신 게시글 목록 조회 | 2,199ms | 2,741ms |
| 상세 조회 | 50ms | 83ms |
| 쓰기 (생성+좋아요) | 62ms | 163ms |
에러율 0%, 총 234건 요청. 최신 게시글 목록 조회 외 시나리오는 변화 없음.
이 수치는 k6 스크립트에서 30% 확률로 page 100~1000(OFFSET 최대 20,000)을 요청하는 조건에서 측정한 것입니다.
페이지 깊이별 효과 분석
Deferred Join의 효과는 페이지 깊이에 따라 다르게 나타납니다.
얕은 페이지 (page 1~10, OFFSET 0~200):
- Before: 인덱스 스캔(~200개) + 클러스터 I/O(~200회, LONGTEXT 포함) → ~50ms
- After: 인덱스 스캔(~200개) + 클러스터 I/O(20회만) → ~20ms
- 전체 비용에서 클러스터 I/O 비중이 크므로, 체감 개선이 큽니다
- OFFSET 자체가 작아서 인덱스 스캔 비용이 낮고, Deferred Join이 제거하는 클러스터 I/O가 전체의 절반 이상을 차지
깊은 페이지 (page 500~1000, OFFSET 10,000~20,000):
- Before: 인덱스 스캔(~20,000개) + 클러스터 I/O(~20,000회) → ~2,500ms
- After: 인덱스 스캔(~20,000개) + 클러스터 I/O(20회만) → ~2,200ms
- 인덱스 스캔이 전체 비용의 ~85%를 차지하므로, 클러스터 I/O를 제거해도 개선폭이 제한적
- 그래도 LONGTEXT 읽기가 사라져 13~19%는 확실히 개선됨

즉, Deferred Join은 OFFSET이 작을수록 효과가 크고, OFFSET이 커질수록 효과가 줄어듭니다. 일반 사용자 트래픽의 대부분(~90%)은 page 1~10이므로, 평균 체감 개선은 k6 측정치(13%)보다 훨씬 클 수 있습니다.
기대와 현실의 차이: 이론적으로 클러스터 인덱스 랜덤 I/O가 20,020회 → 20회로 1,000배 줄어야 했습니다. 그러나 deep page(OFFSET 20,000) 기준 실측 개선은 P95 19%에 그쳤습니다. 이는 전체 비용에서 LONGTEXT I/O가 차지하는 비중이 예상보다 작았기 때문입니다. 왜 그런지 EXPLAIN으로 분석합니다.
6. EXPLAIN 분석: 왜 기대만큼 빠르지 않았는가
Deferred Join 쿼리의 실행 계획
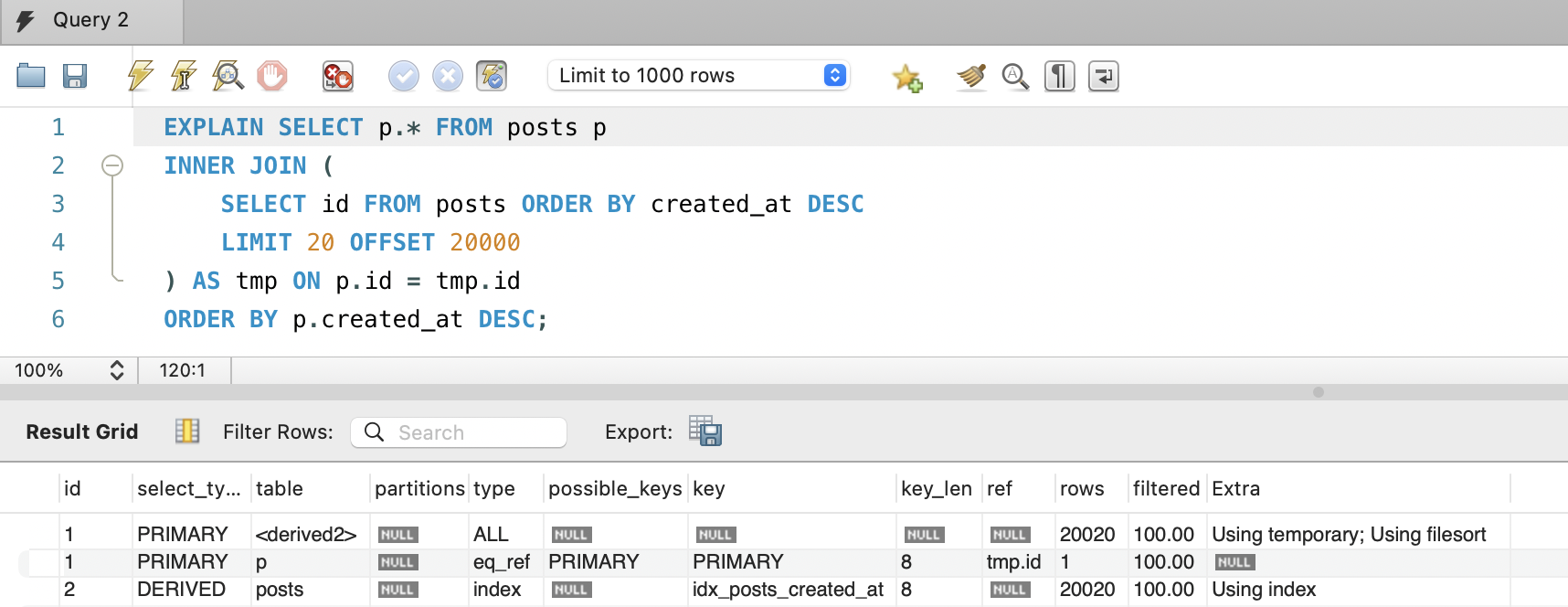
EXPLAIN SELECT p.* FROM posts pINNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000) AS tmp ON p.id = tmp.idORDER BY p.created_at DESC;| id | select_type | table | type | key | rows | Extra |
|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | ALL | NULL | 20,020 | Using temporary; Using filesort |
| 1 | PRIMARY | p | eq_ref | PRIMARY | 1 | |
| 2 | DERIVED | posts | index | idx_posts_created_at | 20,020 | Using index |
행별 해석
id=2 (DERIVED, 내부 서브쿼리):
type=index,key=idx_posts_created_at,Extra=Using index- Covering Index Scan: 인덱스만으로 20,020개 PK를 획득. 클러스터 인덱스를 읽지 않음
- 이 부분은 의도대로 동작하고 있음
id=1 (PRIMARY, 외부 조인):
<derived2>테이블:type=ALL,Using temporary; Using filesortp테이블:type=eq_ref,key=PRIMARY,rows=1- 서브쿼리 결과를 임시 테이블로 실체화(materialize)한 뒤, filesort로 정렬
병목 분석
Deferred Join이 절약한 비용과 남은 비용을 분리하면:
| 구간 | Before (SELECT *) | After (Deferred Join) | 변화 |
|---|---|---|---|
| 인덱스 스캔 (20,020개) | O(N) | O(N) | 동일 |
| 클러스터 인덱스 I/O | 20,020회 (LONGTEXT 포함) | 20회 | 1,000배 감소 |
| 임시 테이블 + filesort | 없음 | 20,020행 임시 테이블 생성 | 추가 비용 |
| 최종 PK 조회 | 결과에 포함 | 20회 eq_ref | 동일 |
핵심: 클러스터 인덱스 랜덤 I/O(LONGTEXT 읽기)가 전체 비용에서 차지하는 비중이 생각보다 작았습니다.
원래 쿼리의 시간 구성을 추정하면:
- 인덱스 스캔 (20,020개): ~85% (인덱스가 있어도 14.75M 건 테이블에서 20,020개를 순차 탐색)
- LONGTEXT 읽기: ~15% (Deferred Join이 제거한 부분)
추정의 한계: 이 비율은 13% 개선율에서 역산한 추정치입니다. MySQL 8.0.18+의
EXPLAIN ANALYZE를 사용하면 각 단계의 actual time을 측정하여 정확한 비율을 확인할 수 있지만, 이번 분석에서는 사용하지 않았습니다. 또한 InnoDB Buffer Pool(2GB)이 warm된 상태에서 테스트했으므로, 최근 데이터의 LONGTEXT가 이미 메모리에 있어 클러스터 I/O 비용이 실제 디스크 랜덤 I/O보다 낮았을 가능성이 있습니다. BP가 cold 상태라면 Deferred Join 효과가 더 크게 나타날 수 있습니다.
Deferred Join은 15%에 해당하는 LONGTEXT 읽기를 제거했지만, 85%에 해당하는 OFFSET 자체의 비용(인덱스 20,020개 엔트리 스캔)은 건드리지 못합니다. 추가로 임시 테이블 생성 오버헤드가 일부 상쇄하여, 순수 개선이 13%로 나타난 것입니다.
COUNT(*) 비용 미분리:
Page<Post>를 반환하므로 매 요청마다SELECT COUNT(*) FROM posts가 함께 실행됩니다. InnoDB는 정확한 row count를 메타데이터에 저장하지 않아, COUNT()도 인덱스 전체를 스캔해야 합니다. Before 2,518ms와 After 2,199ms에는 COUNT() 시간이 포함되어 있으므로, Deferred Join 자체의 순수 개선율은 13%보다 높을 수 있습니다. COUNT(*) 제거는 후속 단계에서Page<T>→Slice<T>전환으로 해결했습니다.
OFFSET이 근본적으로 느린 이유

OFFSET은 “N개를 건너뛰어라”가 아니라 “N개를 읽고 버려라”입니다. 인덱스가 있어도, B-Tree의 리프 노드를 하나씩 따라가며 20,020개를 카운트해야 합니다. 이건 Deferred Join으로 해결할 수 없는 구조적 한계입니다.
7. 추가 조치: 최대 페이지 깊이 제한
EXPLAIN 분석 결과, 병목의 85%가 OFFSET 자체(인덱스 N개 스캔)였습니다. Keyset Pagination으로 전환하기 전에 즉시 적용 가능한 조치로 최대 페이지를 200으로 제한했습니다.
왜 200인가
| 최대 페이지 | 최대 OFFSET | 예상 worst-case | 비고 |
|---|---|---|---|
| 1,000 (기존) | 20,000 | ~2,200ms | 현재 |
| 200 | 4,000 | ~400~500ms | 적용 |
| 100 | 2,000 | ~200ms | 접근성 제한 과도 |
- page 200 × size 20 = 최대 4,000건까지 탐색 가능. 1,475만 건 중 상위 4,000건이면 충분히 넓은 범위
- OFFSET이 20,000 → 4,000으로 5배 줄어들면, 인덱스 스캔 비용도 비례하여 감소
- 구글 검색도 결과를 ~30페이지까지만 제공. 그 이상은 검색어를 세분화하도록 유도
구현
// PostController 또는 PostService에서 page 상한 적용private static final int MAX_PAGE = 200;
public Page<Post> getPosts(Pageable pageable) { if (pageable.getPageNumber() > MAX_PAGE) { throw new IllegalArgumentException("최대 " + MAX_PAGE + "페이지까지 조회 가능합니다."); } return postRepository.findAllWithDeferredJoin(pageable);}API 응답으로 totalPages를 반환하되, 프론트엔드에서 200페이지 이상의 버튼을 렌더링하지 않도록 합니다.
효과
Deferred Join(13%)과 페이지 제한을 합치면:
- 평균 응답시간: deep page 요청이 사라지므로 평균이 대폭 하락
- P95: worst-case가 ~2,741ms → ~500ms 수준으로 제한
- 사용자 영향: 200페이지 이상을 조회하는 사용자는 사실상 없음. 깊은 탐색이 필요하면 검색(Lucene)을 사용하도록 유도
후속 최적화: 이후 COUNT(*) 제거(
Page<T>→Slice<T>전환) + 페이지 제한을 Google/네이버 기준 30페이지로 축소하여 2,518ms → 12.70ms(-99.5%)까지 개선했습니다.
8. 실무에서는 어떻게 하는가: Keyset Pagination
주요 서비스의 페이지네이션 전략
대규모 서비스들은 OFFSET 기반 페이지네이션을 사용하지 않습니다.
Slack:
“Originally designed to return several hundred records, our endpoints now return hundreds of thousands, requiring evolution from no pagination, to offset pagination, to a new cursor-based pagination scheme.”
— Evolving API Pagination at Slack
Slack은 초기에 OFFSET을 사용하다 데이터가 늘어나면서 커서 기반으로 전환했습니다.
Twitter, GitHub, Facebook:
모두 API에서 커서 기반 페이지네이션을 사용합니다. next_cursor 토큰을 응답에 포함하고, 클라이언트는 이 토큰으로 다음 페이지를 요청합니다.
Keyset Pagination이 빠른 이유
-- OFFSET 기반: O(OFFSET + LIMIT) — 페이지가 깊을수록 느림SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000;
-- Keyset 기반: O(LIMIT) — 항상 일정한 속도SELECT * FROM postsWHERE created_at < '2024-01-15T10:30:00'ORDER BY created_at DESCLIMIT 20;Keyset은 인덱스에서 created_at < X 조건으로 바로 시작점을 찾아가므로 (B-Tree에서 O(log N)), 앞의 20,000개를 건너뛸 필요가 없습니다. 페이지 깊이와 무관하게 항상 20개만 읽습니다.
트레이드오프
| OFFSET + Deferred Join | Keyset Pagination | |
|---|---|---|
| 성능 (deep page) | O(OFFSET), 깊을수록 느림 | O(1), 항상 일정 |
| ”N번째 페이지로 점프” | 가능 | 불가능 |
| UI 패턴 | 페이지 번호 (1, 2, 3…) | 이전/다음, 무한 스크롤 |
| API 변경 | 없음 | 커서 파라미터 추가 필요 |
| 실시간 데이터 정합성 | 삽입/삭제 시 페이지 밀림 발생 | 커서 기준이므로 안정적 |
정리
| 단계 | 조치 | 효과 |
|---|---|---|
| 1 | Deferred Join | 클러스터 인덱스 랜덤 I/O 1,000배 감소 → 13% 개선 |
| 2 | 최대 페이지 200 제한 | worst-case OFFSET 5배 감소 → P95 대폭 개선 |
Deferred Join은 OFFSET 구조를 유지하면서 LONGTEXT 읽기 비용만 제거하는 최적화이고, 페이지 깊이 제한은 worst-case를 줄이는 운영 조치입니다. 두 가지 모두 OFFSET의 근본적 한계(O(N) 스캔)는 해결하지 못합니다.
Keyset Pagination은 왜 안 쓰는가
Keyset Pagination(WHERE created_at < :cursor)은 OFFSET을 제거하여 O(1) 성능을 보장합니다. 그러나 “N번째 페이지로 바로 이동”이 불가능합니다. 커서는 현재 위치에서 다음/이전만 알 수 있으므로, 순차 탐색만 가능합니다.
Slack, Twitter, Instagram이 커서 기반을 쓰는 이유는 UI가 무한 스크롤이기 때문입니다. 페이지 번호가 있는 게시판 UI에서는 “3페이지 → 7페이지”로 바로 이동하는 게 당연한 기대이고, 커서 방식은 이를 지원할 수 없습니다.

현재 서비스는 페이지 번호 UI를 사용하고 있으므로, Deferred Join + 최대 페이지 제한 조합이 현 요구사항에 맞는 선택입니다. 무한 스크롤 UI를 도입하게 되면 Keyset Pagination을 재검토할 예정입니다.
출처
- High Performance MySQL, 3rd Edition — O’Reilly (Deferred Join 기법)
- MySQL InnoDB Clustered and Secondary Indexes
- MySQL Explaining MySQL’s Slow Pagination (PlanetScale — MySQL OFFSET 성능 분석 및 Deferred Join)
- Use The Index, Luke — Pagination Done The Right Way
- Evolving API Pagination at Slack
- Paginating Large Datasets in Production — Sentry
- A Developer’s Guide to API Pagination — Gusto
Previous Post
In Why We Chose Lucene Over MySQL Search, we applied Lucene + Nori morphological analyzer and measured baselines with k6 load tests.
Smoke test results showed search (66ms), autocomplete (25ms), and detail view (53ms) were satisfactory, but list queries alone averaged 2,518ms with P95 of 3,372ms — notably slow.
1. Normal State — How the System Was Operating
This is the post list API for the community board.
- API:
GET /api/v1.0/posts?page={N}&size=20 - Table:
posts— 14.75 million rows - Index:
idx_posts_created_at (created_at DESC)— created in Flyway V4 - Columns:
id(PK),title(VARCHAR 512),content(LONGTEXT),author_id,category_id,view_count,like_count,created_at,updated_at
Spring Data JPA’s method-name-based query (findAllByOrderByCreatedAtDesc) auto-generates the SQL. Pageable’s page and size determine LIMIT and OFFSET.
The response DTO PostSummaryResponse uses only 7 fields: id, title, authorId, categoryId, viewCount, likeCount, createdAt. content (LONGTEXT) is not used in the list.
2. Problem Identification — Under What Conditions and How Slow
We measured response times per scenario in k6 smoke tests (5 VU, 2 minutes).
Test environment: ARM 2 cores / 12GB RAM — Spring Boot 2GB (JVM heap 1GB) + MySQL 4GB (InnoDB BP 2GB) + monitoring agents ~1GB. Remaining ~5GB for OS page cache (Lucene MMap).
| Scenario | Avg | P95 |
|---|---|---|
| Search (Lucene) | 66ms | 128ms |
| Autocomplete (Lucene) | 25ms | 37ms |
| List query (MySQL) | 2,518ms | 3,372ms |
| Detail view (MySQL) | 53ms | 93ms |
| Write (MySQL + Lucene) | 62ms | 124ms |
List queries were 38x slower than search. The fact that simple list sorting is slower than Lucene full-text search (BM25 scoring across 14.75M rows) indicates a structural problem with the query itself.
The page distribution for list queries in the k6 script was:
// 70% chance page 0~10, 30% chance page 100~1000const page = randomInt(0, 100) < 70 ? randomInt(0, 10) : randomInt(100, 1000);At page 1000, that’s OFFSET 20,000. The 30% deep page requests were pulling up the average.
3. Problem Analysis — Why Is It Slow
How OFFSET Works
SELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000
When this query executes, MySQL:
- Traverses
idx_posts_created_atindex increated_at DESCorder - Reads all 20,020 rows (OFFSET 20,000 + LIMIT 20)
- Discards the first 20,000
- Returns only the remaining 20
Since the created_at DESC index exists, no filesort occurs. The problem is the 20,000 rows that are “read and discarded.”
Why “Read and Discard” Is Expensive — InnoDB’s Clustered Index Structure
When SELECT * is executed in InnoDB:
Since it’s SELECT *, MySQL finds the PK in the secondary index, then goes to the clustered index to read the full row. In the process, content (LONGTEXT) is also read.
Wikipedia article bodies range from several KB to tens of KB. Reading LONGTEXT from 20,000 rows means reading and discarding hundreds of MB from disk. This is the core bottleneck.
Summary
| Phase | Cost | Description |
|---|---|---|
| Index traversal | Low | Obtain PKs in created_at order via idx_posts_created_at |
| Clustered index random I/O | High | Read actual rows by PK — includes LONGTEXT |
| OFFSET row discard | - | Discard 20,000 read rows (I/O already occurred) |
| Result return | Low | Return remaining 20 rows |
The problem is that clustered index random I/O occurs for 20,000 useless rows. Moreover, PostSummaryResponse doesn’t use content at all, so LONGTEXT that isn’t even needed is being read.
The Larger the Columns, the Larger the Rows, the Slower It Gets
The “read and discard” cost in OFFSET is proportional to row size. Looking at the column composition of the posts table:
content (LONGTEXT) accounts for most of the row size. With an average Wikipedia article of 6,586 characters (~13KB), reading 20,000 OFFSET rows means reading and discarding ~260MB of data. Without content, the remaining columns would be ~12MB — 1/20th the size.
This is the core motivation for Deferred Join — read only id during the OFFSET phase, then read full rows only for the final 20 results.
Why This Problem Is Especially Severe in MySQL (InnoDB)
In PostgreSQL or Oracle, this problem manifests differently.
| MySQL (InnoDB) | PostgreSQL / Oracle | |
|---|---|---|
| Table structure | Clustered index — data physically stored in PK order | Heap table — stored in insertion order |
| PK generation | AUTO_INCREMENT — managed inside the table | SEQUENCE / SERIAL — managed as external objects |
| Secondary index | Stores PK value as pointer → must re-lookup clustered index to get full row | Stores heap pointer (ctid/rowid) → directly accesses heap |
| During OFFSET | Secondary index → get PK → read full row from clustered index | Get tid from index → read row from heap (Index Only Scan possible) |
InnoDB’s secondary indexes store PK values instead of heap pointers. So SELECT * requires two B-Tree lookups: secondary index → PK → clustered index (full row). PostgreSQL has heap pointers in the index for direct row access and can use Index Only Scan to return only needed columns from the index.
Because of this structural difference, Deferred Join is especially effective in MySQL. When the inner subquery does only SELECT id, it completes within the secondary index (Covering Index), completely skipping clustered index access.
4. Learning Process — What Solutions Were Evaluated
Candidate 1: Keyset Pagination (Cursor-Based)
SELECT * FROM postsWHERE created_at < :lastCreatedAtORDER BY created_at DESCLIMIT 20Without OFFSET, the starting point is specified via a WHERE condition, so it always reads only O(LIMIT). It’s the fastest but “jump to page N” is impossible. Only suitable for infinite scroll UIs; cannot be used with page-number UIs.
Candidate 2: Deferred Join
SELECT p.* FROM posts pINNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000) AS tmp ON p.id = tmp.idORDER BY p.created_at DESCImproves performance while maintaining the OFFSET structure. The key is that the inner subquery scans only the index.
- Inner query:
SELECT id— Sinceidx_posts_created_atcontains bothcreated_atandid(PK), it’s processed as a Covering Index Scan. No need to read the clustered index. LONGTEXT is never touched. - Outer query: Queries the clustered index with only the 20 PKs found by the inner query.
As a result, clustered index random I/O drops from 20,020 to 20.
InnoDB’s secondary indexes automatically include the PK. Therefore,
idx_posts_created_atcontains both(created_at, id)values, andSELECT id ... ORDER BY created_at DESCcompletes entirely within this index. This is called a Covering Index.
Candidate 3: Column Projection (SELECT Only Needed Columns)
SELECT id, title, author_id, category_id, view_count, like_count, created_atFROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000Excluding content (LONGTEXT) from SELECT drastically reduces per-row size. However, clustered index random I/O still occurs for the 20,000 OFFSET rows. While it avoids reading LONGTEXT, the cost of reading the rows themselves remains.
Comparison
| Method | OFFSET preserved | Page number UI | Clustered I/O (page=1000) | Implementation difficulty |
|---|---|---|---|---|
| Current (SELECT *) | O | O | 20,020 | - |
| Keyset | X (OFFSET removed) | X | 20 | Medium (API change) |
| Deferred Join | O | O | 20 | Low (query change only) |
| Column projection | O | O | 20,020 (but smaller row size) | Low |
We chose Deferred Join. It reduces clustered index I/O to 1/1,000 while maintaining the OFFSET-based pagination structure, requiring only a Repository query replacement without API changes.
Reference: High Performance MySQL (Baron Schwartz et al.) introduces this technique as “deferred join.”
5. Implementation and Results
Implementation
Spring Data JPA’s method-name-based queries cannot create subqueries. We write the SQL directly with @Query(nativeQuery = true).
PostRepository.java:
/** Post list — OFFSET optimization with Deferred Join */@Query(value = """ SELECT p.* FROM posts p INNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT :#{#pageable.pageSize} OFFSET :#{#pageable.offset} ) AS tmp ON p.id = tmp.id ORDER BY p.created_at DESC """, countQuery = "SELECT COUNT(*) FROM posts", nativeQuery = true)Page<Post> findAllWithDeferredJoin(Pageable pageable);The inner subquery does only SELECT id, so it’s processed as a Covering Index Scan on idx_posts_created_at. The outer query accesses the clustered index with only the 20 PKs returned by the subquery.
Reason for specifying countQuery separately: Spring Data JPA automatically wraps a COUNT query for Page returns on native queries, but this auto-wrapping fails on complex SQL with subqueries.
PostService.java:
public Page<Post> getPosts(Pageable pageable) { return postRepository.findAllWithDeferredJoin(pageable);}Only the Repository query is replaced; Service and Controller remain unchanged.
Before / After
k6 smoke test (5 VU, 2 minutes, identical conditions): (ARM 2 cores, Spring Boot JVM 1GB, MySQL InnoDB BP 2GB)
| Metric | Before | After | Improvement |
|---|---|---|---|
| Avg response time | 2,518ms | 2,199ms | -13% |
| P95 | 3,372ms | 2,741ms | -19% |
Full scenario results (After):
| Scenario | Avg | P95 |
|---|---|---|
| Search | 60ms | 113ms |
| Autocomplete | 32ms | 67ms |
| List query | 2,199ms | 2,741ms |
| Detail view | 50ms | 83ms |
| Write (create + like) | 62ms | 163ms |
Error rate 0%, 234 total requests. No change in scenarios other than list queries.
These numbers were measured under conditions where the k6 script requests pages 100–1000 (OFFSET up to 20,000) with 30% probability.
Effect Analysis by Page Depth
The effect of Deferred Join varies depending on page depth.
Shallow pages (page 1–10, OFFSET 0–200):
- Before: index scan (~200 entries) + clustered I/O (~200 times, including LONGTEXT) → ~50ms
- After: index scan (~200 entries) + clustered I/O (only 20 times) → ~20ms
- Clustered I/O accounts for a large portion of total cost, so perceived improvement is significant
- Since OFFSET itself is small, index scan cost is low, and the clustered I/O that Deferred Join eliminates accounts for more than half of total cost
Deep pages (page 500–1000, OFFSET 10,000–20,000):
- Before: index scan (~20,000 entries) + clustered I/O (~20,000 times) → ~2,500ms
- After: index scan (~20,000 entries) + clustered I/O (only 20 times) → ~2,200ms
- Index scan accounts for ~85% of total cost, so even eliminating clustered I/O has limited improvement
- Still, removing LONGTEXT reads provides a definite 13–19% improvement
In other words, Deferred Join is more effective with smaller OFFSETs and less effective as OFFSET grows. Since the majority (~90%) of real user traffic is pages 1–10, the average perceived improvement can be much greater than the k6 measurement (13%).
Gap between expectation and reality: In theory, clustered index random I/O should have decreased 1,000x from 20,020 to 20. However, the measured improvement at deep pages (OFFSET 20,000) was only 19% at P95. This is because LONGTEXT I/O accounted for a smaller proportion of total cost than expected. We analyze why with EXPLAIN.
6. EXPLAIN Analysis — Why Wasn’t It As Fast As Expected
Execution Plan for the Deferred Join Query
EXPLAIN SELECT p.* FROM posts pINNER JOIN ( SELECT id FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000) AS tmp ON p.id = tmp.idORDER BY p.created_at DESC;| id | select_type | table | type | key | rows | Extra |
|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | ALL | NULL | 20,020 | Using temporary; Using filesort |
| 1 | PRIMARY | p | eq_ref | PRIMARY | 1 | |
| 2 | DERIVED | posts | index | idx_posts_created_at | 20,020 | Using index |
Row-by-Row Interpretation
id=2 (DERIVED — inner subquery):
type=index,key=idx_posts_created_at,Extra=Using index- Covering Index Scan: Obtains 20,020 PKs from the index alone. Does not read the clustered index
- This part is working as intended
id=1 (PRIMARY — outer join):
<derived2>table:type=ALL,Using temporary; Using filesortptable:type=eq_ref,key=PRIMARY,rows=1- Materializes the subquery result into a temporary table, then sorts with filesort
Bottleneck Analysis
Separating the costs that Deferred Join saved versus those that remain:
| Phase | Before (SELECT *) | After (Deferred Join) | Change |
|---|---|---|---|
| Index scan (20,020 entries) | O(N) | O(N) | Same |
| Clustered index I/O | 20,020 (including LONGTEXT) | 20 | 1,000x reduction |
| Temporary table + filesort | None | 20,020-row temp table created | Added cost |
| Final PK lookup | Included in result | 20 eq_ref lookups | Same |
Key insight: The proportion of clustered index random I/O (LONGTEXT reads) in total cost was smaller than expected.
Estimating the time composition of the original query:
- Index scan (20,020 entries): ~85% (sequential traversal of 20,020 entries in a 14.75M-row table even with an index)
- LONGTEXT reads: ~15% (the part eliminated by Deferred Join)
Limitations of this estimate: These ratios are back-calculated from the 13% improvement, not directly measured. MySQL 8.0.18+‘s
EXPLAIN ANALYZEcould provide actual time per phase but was not used in this analysis. Additionally, the InnoDB Buffer Pool (2GB) was warm during testing, so LONGTEXT data for recent rows may already have been in memory, making clustered I/O cheaper than true disk random I/O. Deferred Join’s effect could be larger with a cold Buffer Pool.
Deferred Join eliminated the 15% LONGTEXT read cost, but cannot touch the 85% that is the OFFSET itself (scanning 20,020 index entries). The temporary table creation overhead partially offsets the gain, resulting in a net improvement of 13%.
COUNT(*) cost not separated: Since
Page<Post>is returned,SELECT COUNT(*) FROM postsruns with every request. InnoDB doesn’t store exact row counts in metadata, so COUNT() also requires a full index scan. Both the Before (2,518ms) and After (2,199ms) measurements include COUNT() time, so Deferred Join’s actual improvement for the main query alone may be higher than 13%. COUNT(*) elimination is addressed in the next step viaPage<T>→Slice<T>conversion.
Why OFFSET Is Fundamentally Slow
OFFSET is not “skip N entries” but “read N entries and discard them.” Even with an index, the B-Tree leaf nodes must be followed one by one to count 20,020. This is a structural limitation that Deferred Join cannot solve.
7. Additional Measure — Maximum Page Depth Limit
EXPLAIN analysis showed 85% of the bottleneck was OFFSET itself (scanning N index entries). Before transitioning to Keyset Pagination, we limited the maximum page to 200 as an immediately applicable measure.
Why 200
| Max page | Max OFFSET | Expected worst-case | Note |
|---|---|---|---|
| 1,000 (previous) | 20,000 | ~2,200ms | Current |
| 200 | 4,000 | ~400–500ms | Applied |
| 100 | 2,000 | ~200ms | Overly restrictive |
- page 200 × size 20 = up to 4,000 rows browsable. Top 4,000 out of 14.75M is a sufficiently broad range
- OFFSET decreasing from 20,000 to 4,000 (5x reduction) proportionally reduces index scan cost
- Google Search also limits results to ~30 pages, guiding users to refine their search terms beyond that
Implementation
// Apply page cap in PostController or PostServiceprivate static final int MAX_PAGE = 200;
public Page<Post> getPosts(Pageable pageable) { if (pageable.getPageNumber() > MAX_PAGE) { throw new IllegalArgumentException("Maximum " + MAX_PAGE + " pages can be queried."); } return postRepository.findAllWithDeferredJoin(pageable);}totalPages is still returned in the API response, but the frontend does not render buttons beyond page 200.
Effect
Combining Deferred Join (13%) and page limit:
- Avg response time: Dramatic drop since deep page requests are eliminated
- P95: Worst-case bounded from ~2,741ms to ~500ms level
- User impact: Virtually no users browse beyond page 200. Users needing deep exploration are guided to use search (Lucene)
8. How Production Services Handle This — Keyset Pagination
Pagination Strategies of Major Services
Large-scale services do not use OFFSET-based pagination.
Slack:
“Originally designed to return several hundred records, our endpoints now return hundreds of thousands, requiring evolution from no pagination, to offset pagination, to a new cursor-based pagination scheme.”
— Evolving API Pagination at Slack
Slack initially used OFFSET but transitioned to cursor-based as data grew.
Twitter, GitHub, Facebook:
All use cursor-based pagination in their APIs. A next_cursor token is included in the response, and the client requests the next page with this token.
Why Keyset Pagination Is Fast
-- OFFSET-based: O(OFFSET + LIMIT) — slower as pages get deeperSELECT * FROM posts ORDER BY created_at DESC LIMIT 20 OFFSET 20000;
-- Keyset-based: O(LIMIT) — constant speed alwaysSELECT * FROM postsWHERE created_at < '2024-01-15T10:30:00'ORDER BY created_at DESCLIMIT 20;Keyset finds the starting point directly via a created_at < X condition in the index (O(log N) in B-Tree), so there’s no need to skip the first 20,000. Regardless of page depth, it always reads only 20 rows.
Trade-offs
| OFFSET + Deferred Join | Keyset Pagination | |
|---|---|---|
| Performance (deep page) | O(OFFSET) — slower as deeper | O(1) — always constant |
| ”Jump to page N” | Possible | Impossible |
| UI pattern | Page numbers (1, 2, 3…) | Previous/Next, infinite scroll |
| API change | None | Cursor parameter addition required |
| Real-time data consistency | Page shifting on insert/delete | Stable based on cursor position |
Summary
| Step | Action | Effect |
|---|---|---|
| 1 | Deferred Join | Clustered index random I/O reduced 1,000x → 13% improvement |
| 2 | Max page 200 limit | Worst-case OFFSET reduced 5x → significant P95 improvement |
Deferred Join is an optimization that eliminates only the LONGTEXT read cost while maintaining the OFFSET structure, and the page depth limit is an operational measure to reduce worst-case. Neither solves OFFSET’s fundamental limitation (O(N) scan).
Why Not Use Keyset Pagination
Keyset Pagination (WHERE created_at < :cursor) eliminates OFFSET to guarantee O(1) performance. However, “jump directly to page N” is impossible. A cursor only knows next/previous from the current position, so only sequential navigation is possible.
The reason Slack, Twitter, and Instagram use cursor-based is that their UI is infinite scroll. In a board UI with page numbers, jumping from “page 3 → page 7” directly is a natural expectation, and the cursor approach cannot support this.
Since the current service uses a page-number UI, Deferred Join + max page limit is the appropriate choice for the current requirements. Keyset Pagination will be reconsidered if an infinite scroll UI is introduced.
References
- High Performance MySQL, 3rd Edition — O’Reilly (Deferred Join technique)
- MySQL InnoDB Clustered and Secondary Indexes
- MySQL Explaining MySQL’s Slow Pagination (PlanetScale — MySQL OFFSET performance analysis and Deferred Join)
- Use The Index, Luke — Pagination Done The Right Way
- Evolving API Pagination at Slack
- Paginating Large Datasets in Production — Sentry
- A Developer’s Guide to API Pagination — Gusto

댓글
댓글 수정/삭제는 GitHub Discussions에서 가능합니다.