
프로젝트
위키엔진
1,425만 건 위키 데이터 기반 검색엔진 — Lucene + Nori 형태소 분석, 분산 아키텍처(MySQL Replication, Redis 샤딩, Kafka CDC), k6 부하 테스트로 검증
EEDGate
LLM 워크플로우를 위한 자기 개선 평가 루프 엔진 — 검증 게이트, 실패 분석, 규칙 자동 생성, 회귀 테스트를 하나의 TUI/CLI 도구로 제공

IT Oasis
Astro 5.x 기반 기술 블로그 — CSS View Transitions, 다국어(KO/EN) 토글, 카테고리/태그 시스템, 다크모드




최신 스토리
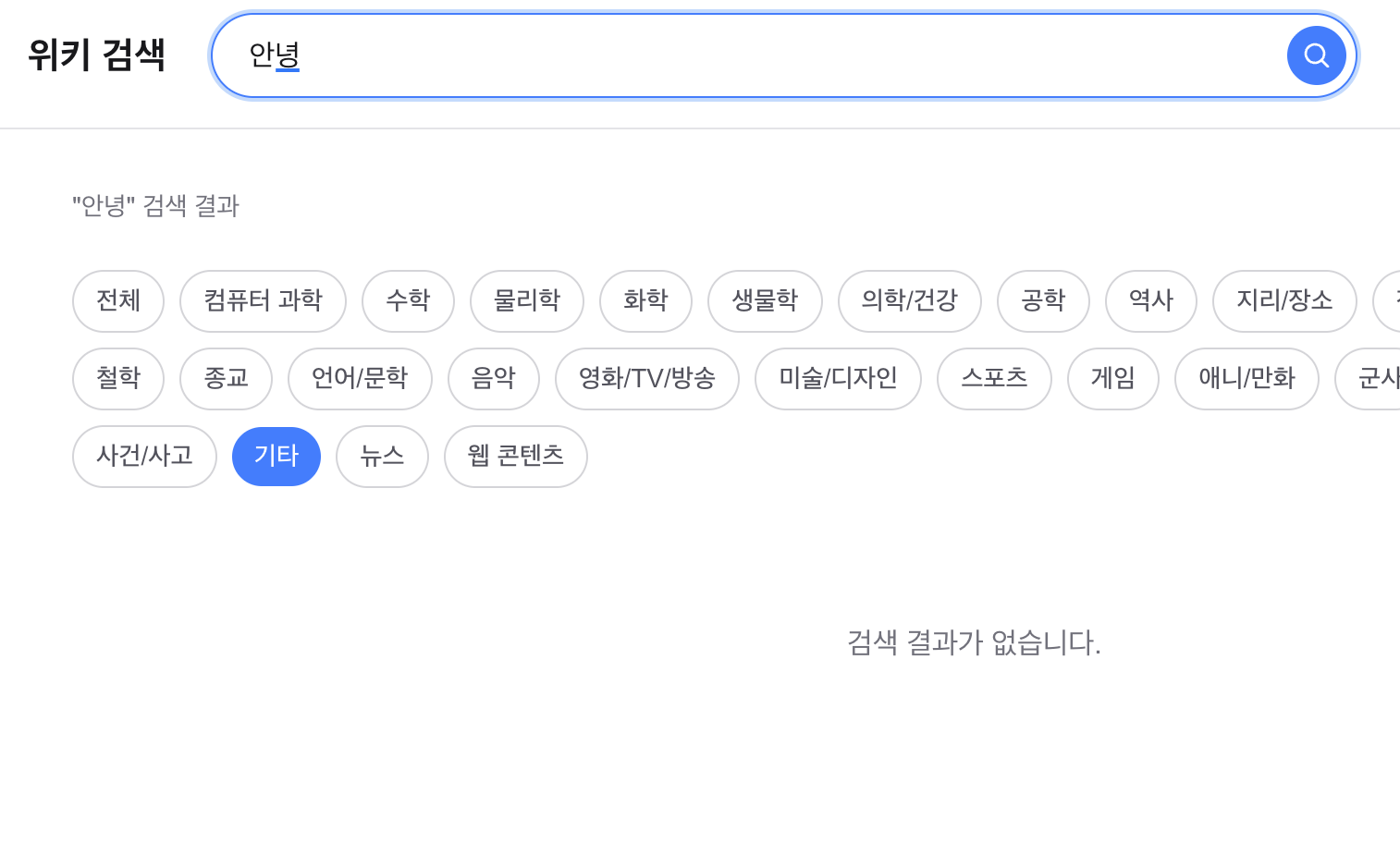
Nori 형태소 분석기 Stop Filter 문제 — "안녕" 0건과 "안녕하세" 노이즈 해결
Lucene Nori 분석기에서 "안녕" 검색이 0건이 되는 IC 필터링 문제와, "안녕하세" 검색 시 "하세" 관련 문서만 나오는 형태소 분석 한계를 분석합니다. IC 제거 + title_ngram dis_max + PrefixQuery 폴백 3단계 해결을 적용하고, 자동완성 title_raw fallback까지 포함합니다.
요즘 재밌는 걸 하고 있습니다.
지인에게 추천받은 PretextBreaker를 계기로, AI와 함께 정규식보다 빠른 문자열 검사 방식을 끝없이 실험해보고 있는 요즘의 기록입니다.
기술보다 문제가 먼저다
기술 이름이 아니라 문제를 먼저 보는 개발자가 되고 싶다는 생각을 정리한 글입니다. 왜 그 기술이 필요했는지, 어떤 trade-off를 거쳤는지를 설명할 수 있는 것이 진짜 실력이라고 느낀 과정을 기록합니다.
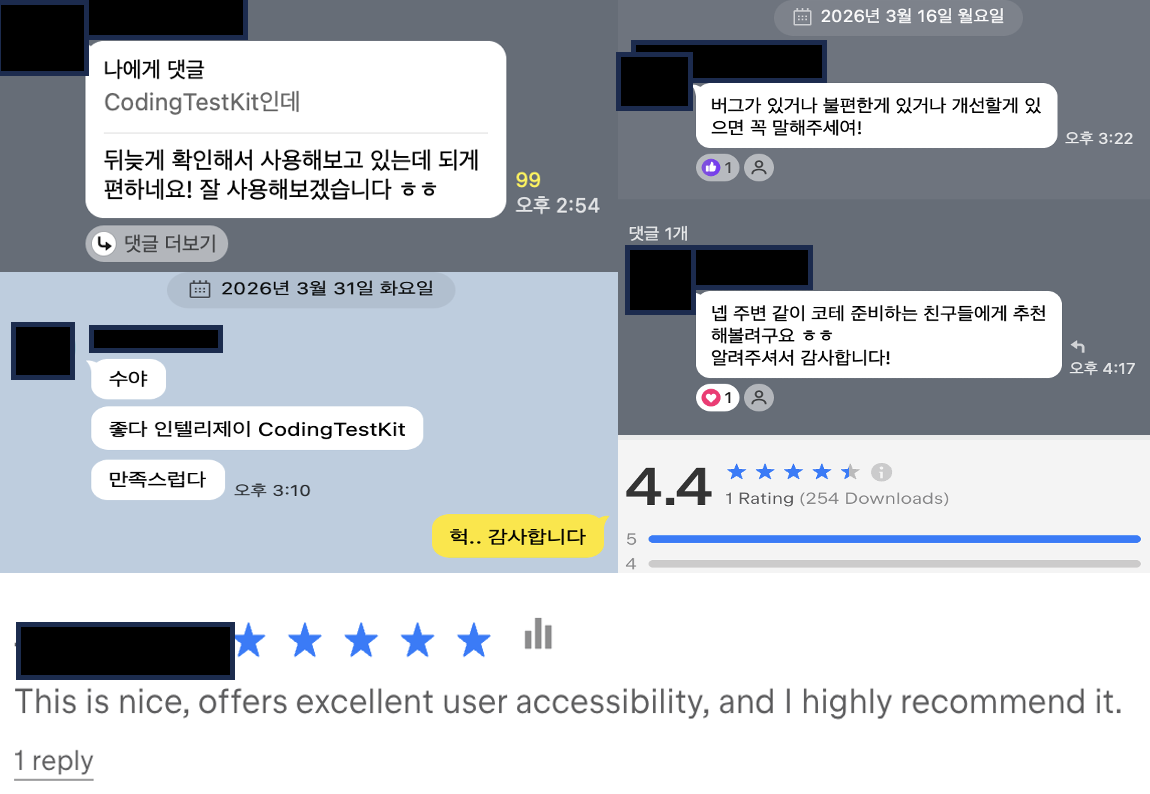
CodingTestKit - 감사 후기를 받고 정말 뿌듯했다
카카오톡 메시지와 마켓플레이스 리뷰를 통해, CodingTestKit이 실제로 누군가에게 도움이 되고 있다는 걸 느끼며 개발자로서 뿌듯함을 느낀 기록입니다.
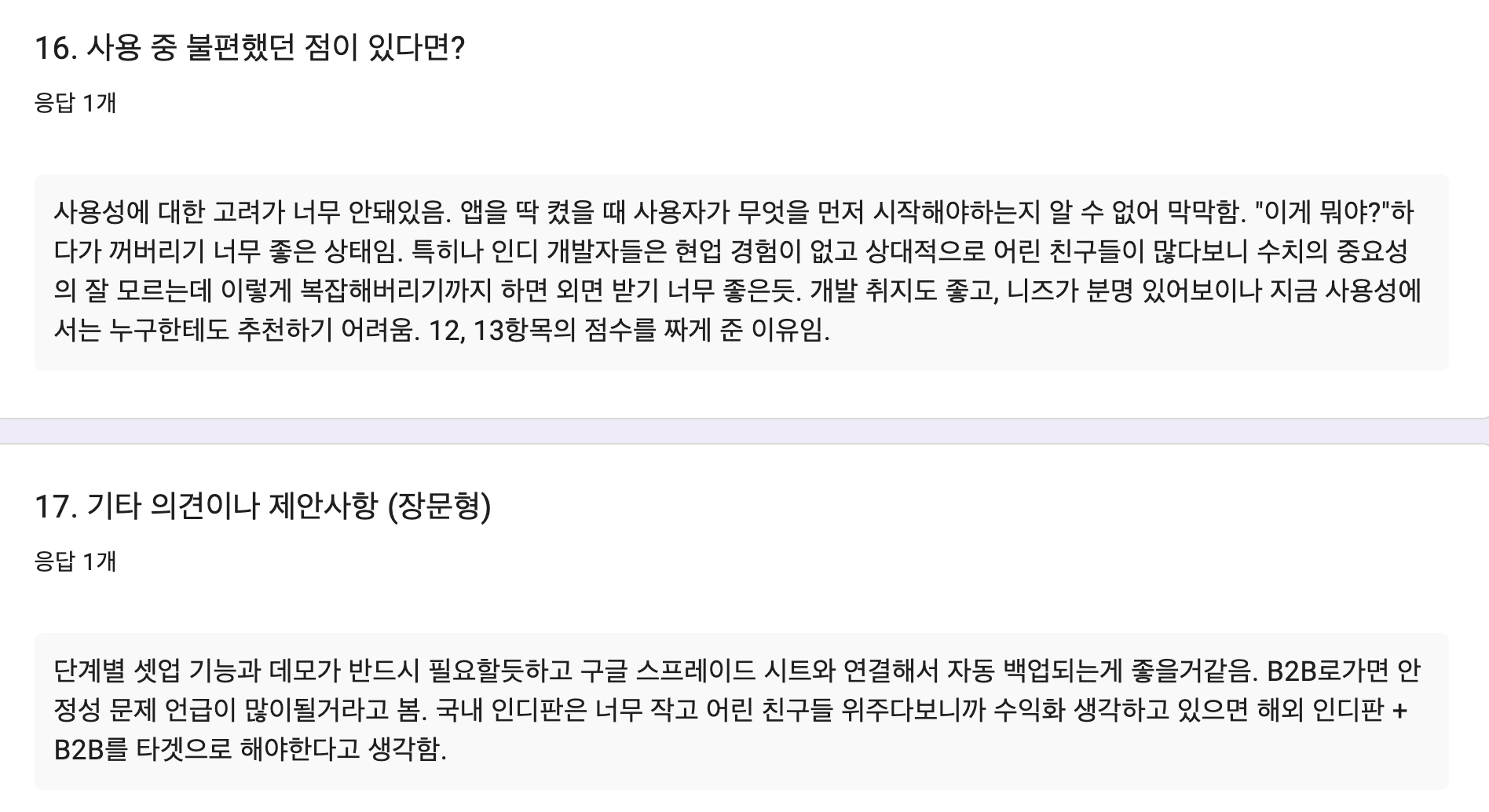
PowerBalance를 만들고 나서 배운 것
인디게임 밸런싱 도구 PowerBalance를 만들며 느꼈던 가능성과, 실제 사용자 반응이 기대와는 달랐던 경험, 그리고 그 배움이 이후 CodingTestKit에 어떻게 이어졌는지를 정리한 글입니다.

WikiEngine 총정리 — 1,215만 건 검색 엔진의 설계부터 RAG까지
나무위키+한국어 위키백과+영어 위키백과+뉴스+웹텍스트+C4 한국어 코퍼스 1,215만 건 검색 엔진 프로젝트를 2개월간 26편의 기술 블로그로 기록하고 총정리합니다. MySQL LIKE 5,000ms 타임아웃에서 시작하여 임베디드 Lucene + Nori 한국어 형태소 분석으로 전환하고, Caffeine+Redis 2계층 캐시(82% 히트율), MySQL Replication R/W 분리, Nginx 스케일아웃(에러율 13.25%→0%), Debezium+Kafka CDC, Redis 3노드 Consistent Hashing까지 분산 아키텍처를 완성합니다. 검색 품질은 동의어 확장, 오타 교정, UnifiedHighlighter snippet, LTR(NDCG +4.8%p), 카테고리 28개 자동 분류, Aho-Corasick 금칙어 필터링으로 고도화하고, RAG(Gemini SSE 스트리밍)로 AI 검색 요약을 제공합니다. 자동완성 시스템 설계(CQRS + MapReduce + CDC)의 이론과 실제 구현의 매핑, 26편 전체 시리즈 링크, 핵심 수치 총정리를 포함합니다.
AI 검색 요약 — RAG 파이프라인 + SSE 스트리밍 + 비용 모니터링
Lucene BM25 검색 결과 Top-5 문서를 LLM 컨텍스트에 주입하는 RAG(Retrieval-Augmented Generation) 파이프라인을 구축합니다. Spring AI 2.0 + Gemini 2.0 Flash로 SSE 스트리밍 답변을 생성하고, 인라인 출처 배지를 파싱하여 게시글 링크로 연결합니다. 할루시네이션 방지(문서 기반 답변 제한 + 인용 강제), AI 요약 트리거 조건(네비게이션 의도 스킵), Redis Token Bucket rate limiting(10 RPM 전역), 동일 쿼리 캐싱(TTL 30분, LLM 비용 40-60% 절감), Grafana 7패널 대시보드(RPM, 응답시간, 토큰, 피드백, 비용 추정)까지 포함합니다. BM25가 이 프로젝트에서 Dense Retrieval보다 적합한 근거와, Hybrid Retrieval 전환 로드맵도 정리합니다.
콘텐츠 필터링 — Aho-Corasick 금칙어 탐지와 운영 안전장치
커뮤니티 검색 서비스의 운영 안전장치를 구축합니다. 16,090개 금칙어를 Aho-Corasick O(N+Z) 알고리즘으로 탐지하여 자동완성 결과에서 유해 검색어를 필터링하고, 블라인드 게시글을 Lucene Occur.MUST_NOT으로 검색에서 제외합니다. 영어 금칙어의 Scunthorpe 문제(단어 경계 매칭), Negative Caching(빈 결과 30초 TTL)으로 cache penetration 방지, title_raw StringField로 자동완성 Lucene fallback 품질을 개선합니다.